
내가 만든 검색 엔진에서 가지고 싶었던 기능 중에 하나가 [한영 오타 자동 전환 검색 기능]이다. 이게 용어가 맞는지는 잘 모르겠지만,

이런 식으로 사용자의 경험을 향상 시키는 검색 엔진이고 싶었다.
그래서 만들었다..!
1) 영어 -> 한글 오타수정

2) 한글 -> 영어 오타수정

어떻게 만들었는가?
- 일단은 말해두고 가야하는 것은 java-cafe에서 개발한 elasticSearch 플러그인 코드 중에 convert 부분을 활용 했다. 그래서 알고리즘을 개발 했다고는 하지 못한다.
https://github.com/javacafe-project/elasticsearch-plugin
그럼에도 내가 한것은?
영어를 한글로 바꿔주는 코드를 가져다 사용함에도 그대로 사용하지 못하는 큰 문제가 발생 했다.
정상적인 영어 단어를 convert 했을 때, 검색이 제대로 되지 않는다.
"java"를 가지고 변환하게 되면 '갘맇'이라는 단어로 변환되게 된다. 물론 'wkqk'를 변환하면 의도에 맞게 '자바'로 바뀌지만 말이다.
'갘맇'이나 '자바'나 유효한 단어라고 어떻게 판별 할 것인가??
이 문제를 해결 하는 것이 나의 역할이였다.
어떻게 해결 했는가?
아이디어를 하나 짜냈다. 유효한 단어를 판별할 사전이 필요 했고, 그 사전은 검색 엔진을 위한 명사 단위 토큰 칼럼에 다 담겨져 있었다.
그것들을 CSV 파일로 export하고, 데이터 정제 등을 거쳐서 46만개의 키워드 사전 table을 만들었다.
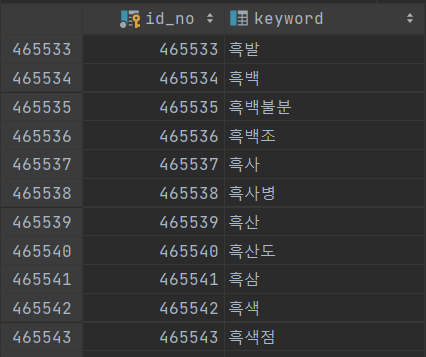
이제 남은건 저 테이블을 사전처럼 활용해서 저 DB에 있으면 유효, 없으면 유효하지 않은 단어인 것이다. (어차피 저기에 없으면 도서도 못 찾는다)
이제 이 테이블을 keyword_dic 이라고 부른다. 이제 남은 것은 keyword에 대한 repository와 service 계층 구현이 남았다. 추가로 나는 데코레이션 패션을 활용하여 Filter를 추가하는 식으로 필터를 설계 했다.
-
우선은 Filter중 하나인 ConvertFilter이다. 이거 앞단 filter는 현재 SimpleFilter가 존재 한다.(소문자로 변환, 특수문자 제거)
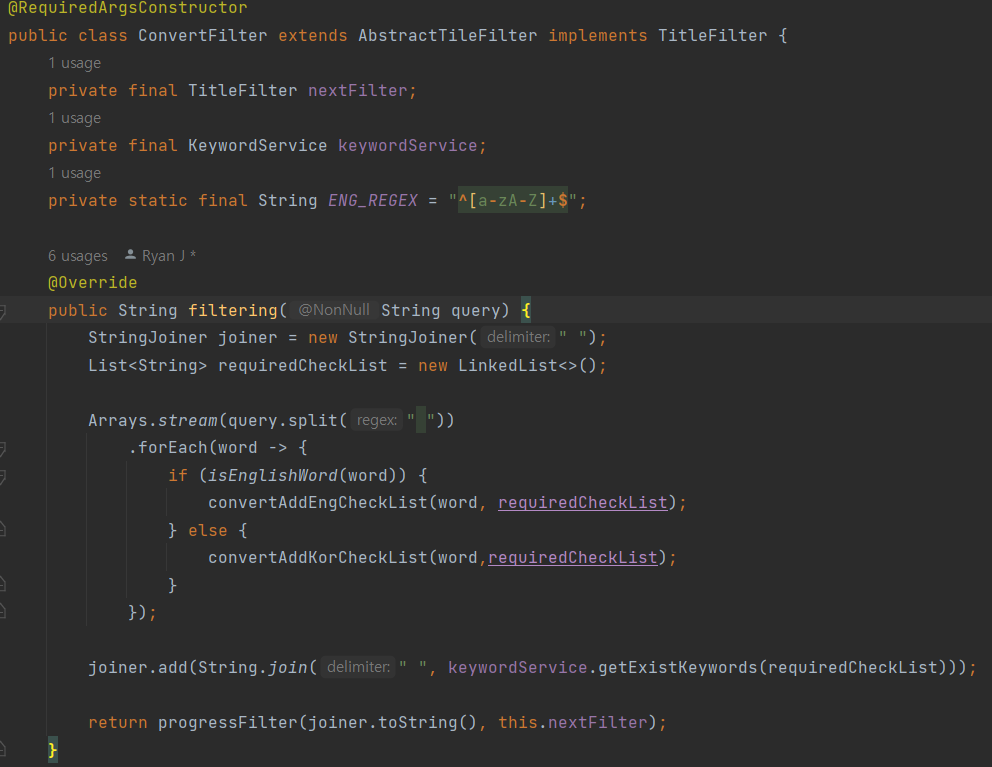
-
그 다음엔 keywordService이다. service는 간단하다. filter에게서 전달 받는 단어들 모음을 queryDsl을 사용하는 repo를 통해 쿼리를 날려 DB에 존재하는 단어만 바꿔서 다시 반환 하는 것이다.
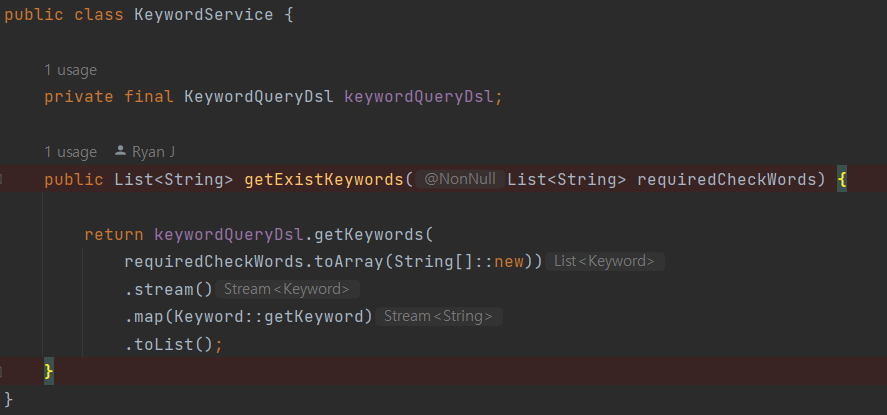
만약 'wkqk wjdtjr' [자바 정석]을 검색어가 들어오면,
select keyword
from keyword_dic
where keyword in('wkqk','자바','wjdtjr','정석');이런 식의 SQL문이 날라가고, '자바' '정석'만 검색 되기 때문에 나머지 유효하지 않은 단어는 모두 제거 되고, 유효한 단어로만 검색이 된다.
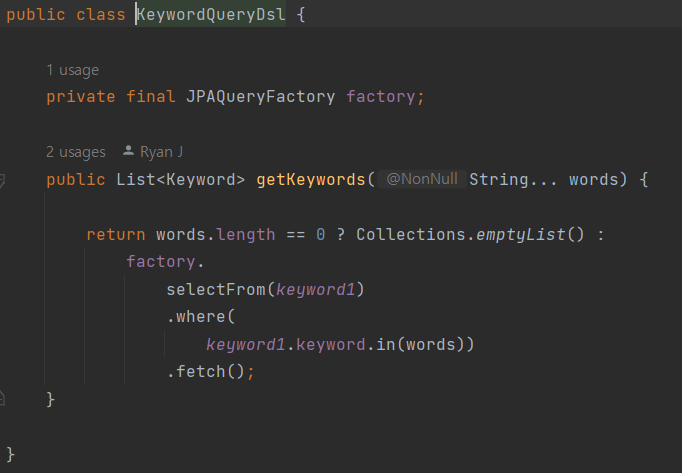
요런식이다. 원래는 BooleanBuilder를 통해서 where에 or절을 통해서 검색 했는데, 성능 이슈에 대한 피드백을 받고 in절로 개선 했다. 그 관련 내용은 아래에 있다. 그리고 이 프로세스는 처음에 쿼리를 너무 비효율적으로 날려서 1개면 될 것을 13번이나 쿼리를 날렸었는데, 그것도 위에 코드를 통해서 개선이 됐다. 그 내용도 아래 링크에 포함 된다.

좋은 글 감사합니다! 사전은 어떻게 구축하셨나요? 실제로 배포되어 있는 사전이 있나요?