1. Introduction
pre-trained language representation을 downstream task에 적용하는 방식은 'feature based'와 'fine-tuning'방식이 있다.
ELMo와 같은 feature based 방식에선 task-specific architecture를 사용하고, pre-trained representation을 추가적인 feature로 사용한다.
OpenAI GPT와 같은 fine-tuning 접근법은 최소한만의 task-specific feature를 사용한다. downstream task에 활용하기 위해선 그저 사전 학습된 모든 parameter를 fine-tuning하면 된다.
현재 이 두 방식의 공통적인 문제점은 standard language model들이 unidirectional하다는 것이다. 이런 unidirectional한 모델의 문제점은 question answering과 같은 token-level task에서 더 두드러진다.
이 논문에선 BERT: Bidirectional Encoder Representations from Transformers를 제안한다.
BERT는 앞서 언급한 unidirectional 문제를 masked language model(MLM)으로 해결한다. MLM은 input에서 token들을 랜덤하게 mask해서 model이 masked된 단어를 문맥(context)으로부터 추측하게 하는 pre-training objective이다.
3. BERT
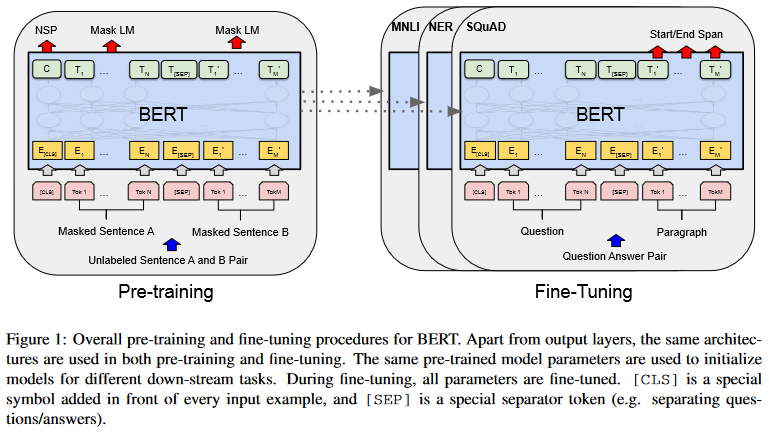
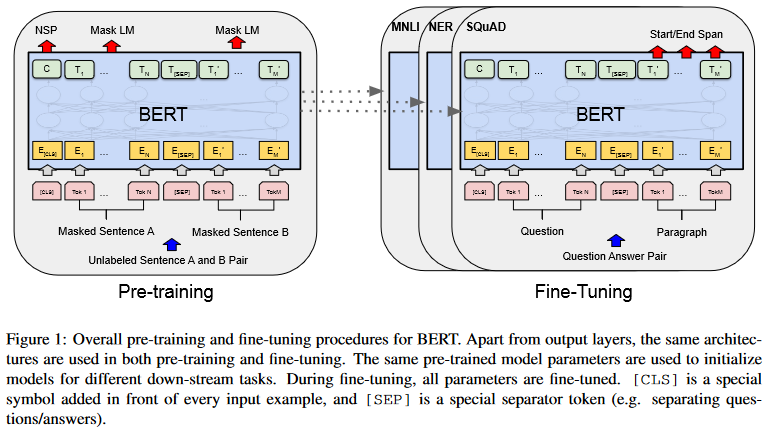
BERT의 프레임워크는 pre-training과 fine-tuning의 두 단크로 이루어져있다. pre-training 단계에서는 모델이 unlabeled data로 pre-training된다. fine-tuning 단계에서는 모델이 pre-trained parameter로 초기화된 후, downstream task에 맞게 labeled data로 fine-tuning 된다. 이 때 모든 parameter들이 fine-tuning된다.
Model Architecture
BERT의 모델 구조는 multi-layer bidirectional Transformer이다. BERT는 모델의 사이즈에 따라 BERT-Base와 BERT-Large로 나뉜다.
Input/Output Representations
BERT는 다양한 downstream task를 다루기 위해, input으로 하나만의 문장을 받을 수도 있고, (Question, Answer)과 같은 두 개의 문장 쌍을 받을 수도 있다.
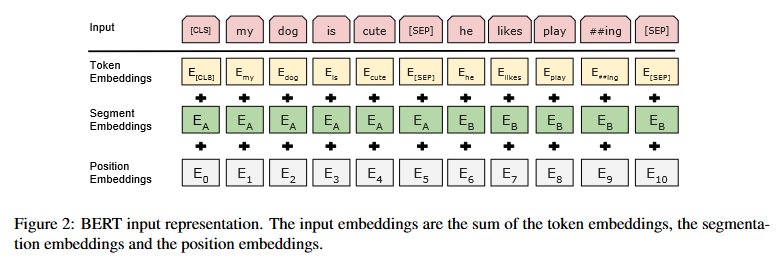
모든 input sequence의 첫 토큰은 [CLS]토큰으로 이 토큰에 대응되는 마지막 hidden state는 분류 task에서 input sequence의 representation으로 사용된다.
앞서 언급했듯이 두 개의 문장 쌍이 하나의 sequence로 합쳐졌을 때는 [SEP]토큰으로 두 문장을 구분한다. 추가적으로, 학습된 embedding을 모든 토큰에 더해 해당 토큰이 문장A에 속하는지 문장B에 속하는지 모델에 전달한다. 아래 그림에서 볼 수 있듯이 한 토큰의 input representation은 token embedding + segment embedding + position embedding으로 이루어진다.
3.1 Pre-training BERT
Task #1: Masked LM
standard LM(Language Model)들은 left-to-right혹은 right-to-left의 단방향 학습만 가능한다.
양방향 학습을 가능케하기 위해 BERT는 input의 15%를 랜덤하게 mask한다. 그러나 이 방식은 pre-training과 fine-tuning 사이에서 mismatch를 불러일으킬 수 있다. fine-tuning시에는 [MASK]토큰이 등장하지 않기 때문이다. 이 부작용을 완화하기 위해 15%의 선택된 토큰 중, 1)80%는 [MASK]토큰으로 대체한다 2)10%는 랜덤한 토큰으로 대체한다 3)10%는 본래의 토큰을 그대로 사용한다.
Task #2: Next Sentence Prediction(NSP)
Question Answering(QA)와 Natural language Inference(NLI)등의 task들은 두 문장 사이의 관계를 파악하는 것이 중요하다. 문장 사이의 관계를 학습하기 위해 pre-train 과정에서 binarized next sentence prediction task를 학습한다.
input의 50%는 문장 A와 B가 실제로 연결된 문장이고(IsNext로 label), 나머지 50%는 두 문장이 랜덤하게 선택된다(NotNext로 label).
출처: Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
