논문리뷰
1.[논문리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

Contents Abstract Introduction Related work Formulation Implementation Results Limitations and Discussion Appendix 0. Abstract Image-to-Image transl
2022년 1월 9일
2.[논문리뷰]BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
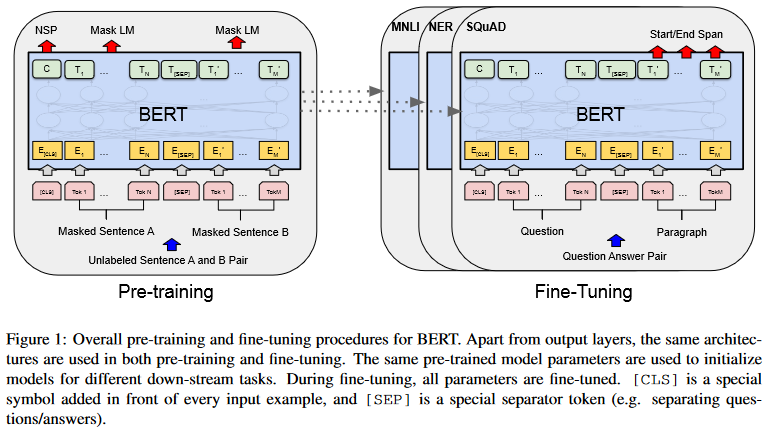
pre-trained language representation을 downstream task에 적용하는 방식은 'feature based'와 'fine-tuning'방식이 있다. ELMo와 같은 feature based 방식에선 task-specific archite
2022년 3월 18일
3.[논문리뷰]Language Models are Unsupervised Multitask Learners

https://wikidocs.net/22592 https://supkoon.tistory.com/25
2022년 4월 3일
4.[논문 리뷰]Fast R-CNN

https://herbwood.tistory.com/8 https://herbwood.tistory.com/5
2022년 4월 3일
5.[논문 리뷰] Unifying Architectures, Tasks, and Modalities through a Simple Sequence-to-Sequence Learning Framework
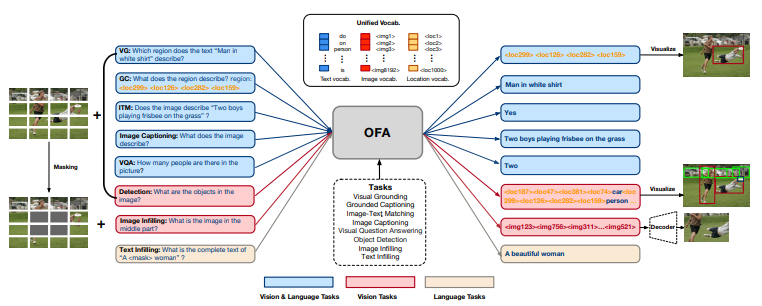
0. Abstract 이 연구에서 우리는 multimodal pretraining을 위한 통합된 패러다임을 추구한다. 우리는 OFA(One-for-All)라는 unified multimodal pretrained model을 제시한다. OFA는 단순한 sequence-
2022년 4월 28일