
Contents
- Abstract
- Introduction
- Related work
- Formulation
- Implementation
- Results
- Limitations and Discussion
0. Abstract
Image-to-Image translation의 목적은 input 이미지들에서 output 이미지로 가는 매핑을 이해하는 것이다. 이 연구의 의의는 짝지어진 이미지 쌍들 없이, 이미지를 source domain X에서 target domain Y로 변환한다는 것이다. 이 연구의 목적은 도메인 X에서 Y로 가는 매핑 을 배우는 것이다. 손실로는 adversarial loss와 cycle consistency loss를 사용한다. cycle consistency loss를 위해서 반대의 매핑 을 학습시켜 가 되도록 강제한다
1. Introduction
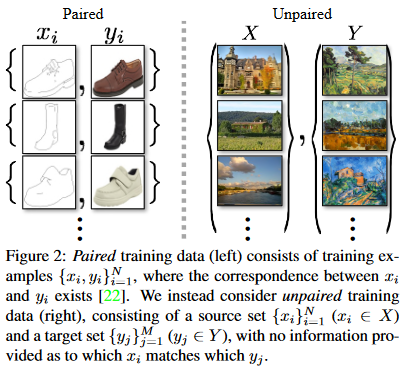
Figure 2 를 보면 왼쪽 그림이 일반적인 Image-to-Image translation의 학습 데이터이다. 그러나 짝지어진(paired) 이미지를 구하기는 쉽지 않다. 이 논문에서는 하나의 이미지 집단의 특징을 파악해서 다른 이미지 집단으로 변환하는 방법을 택한다.
매핑을 훈련시켜서 에 의해 변환된 이미지들의 집합인 가 와 일치하도록 하는 것이 목적인 것이다. 그러나 우리는 짝지어진 이미지 데이터 쌍으로 학습하지 않기 때문에, 앞서 언급한 목적을 달성한다고 해도 에 대해 와 가 의미 있게 짝지어졌을거라고 단정할 수 없다. 또한, 학습 시 mode collapse 문제를 종종 맞닥뜨리는데, 이는 모든 input 이미지가 하나의 output 이미지로 매핑되는 문제이다.
이러한 문제들을 해결하기 위해 cycle consistent loss를 도입한다. cycle consistant loss는 가 되도록 장려한다.
2. Related work
Generative Adversarial Networks (GANs)
GAN이 성공할 수 있었던 이유는 adversarial loss라는 아이디어 덕분이다. adversarial loss는 새롭게 생성된 이미지가 실세 사진과 구별할 수 없도록 강제한다.
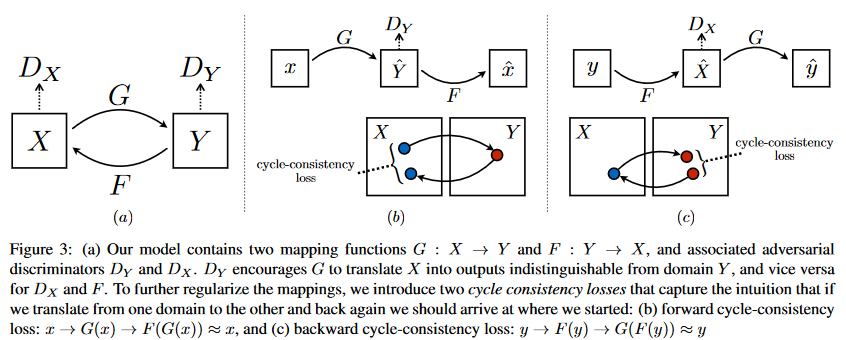
Figure 3를 보면 본 연구에서는 두 개의 cycle consistency loss를 도입하고 있음을 알 수 있다.
3. Formulation
Figure 3에서 볼 수 있듯이 매핑을 두 개가 존재한다. adversarial discriminator도 두 개가 존재하는데, 는 와 를 구분하고 는 와 를 구분한다. 손실로는 adversarial loss와 cycle consistency loss를 사용한다.
3.1 Adversarial Loss
매핑 관점에서의 adversarial loss에 대한 설명이다. 는 실제 에 대해서는 모든 픽셀 값이 1인 이미지를 반환하고, 가짜 이미지라고 판단하면 모든 픽셀 값이 0인 이미지를 반환한다.
는 위 목적함수를 최소화하려고 하고, 는 위 목적함수를 최대화하려고 한다.
3.2 Cycle Consistency Loss

cycle consistency loss에서는 L1 norm을 사용한다. L1 norm 대신 adversarial loss를 사용하는 것이 성능 향상으로 이어지진 않았다고 한다.
3.3 Full Objective
우리의 모델을 두 개의 'autoencoder'를 학습시키는 것으로 바라볼 수도 있다. 각각이 autoencoder가 되는 것이다.각각의 autoencoder는 이미지를 자기자신으로 매핑하는데, 그 중간의 형상이 다른 도메인에 있는 이미지가 되는 것이다.
4. Implementation
Training details
에서 negative log likelihood 부분을 least-square loss로 변경하여 사용했다. 또한, model oscillation을 줄이기 위해서 discriminators를 업데이트할 때 generator들이 생산한 최신 이미지만을 사용하는 것이 아니라 최근 50개의 이미지를 사용했다.
optimizer은 Adam을 사용했고, batch의 크기는 1로 설정했다. learning rate은 0.0002로 첫 100 에폭을 학습한 후 다음 100 에폭동안 0으로 선형적으로 감소시켰다.
5. Results
5.1 Evaluation
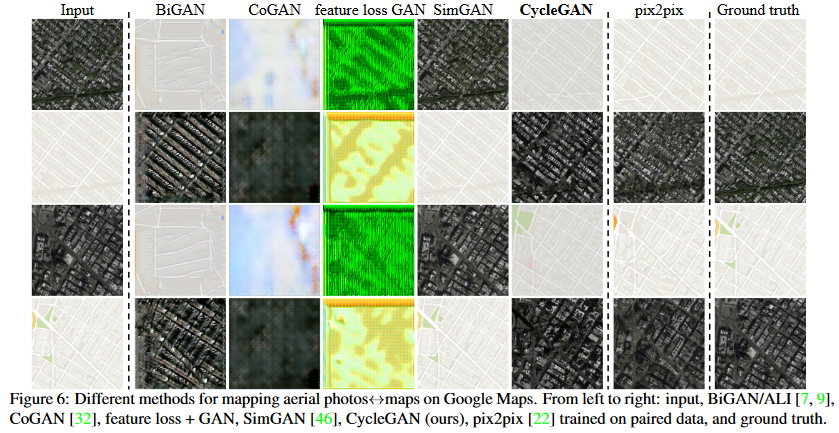
다른 Baseline들과 비교했을 때 모든 Evaluation Metrics에 걸쳐 우수한 성적을 냈다. 그러나 짝지어진 이미지들을 pixel 단위로 변환한 pix2pix와는 어느정도 성능 차이를 보였다.
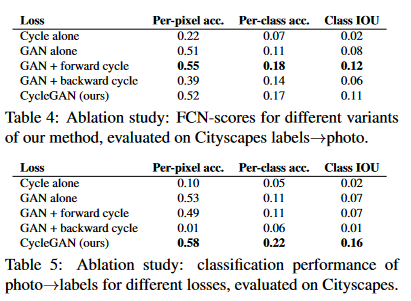
cycle consistency loss를 완전히 제거했을 땐 성능이 저하되는 양상을 보였으며, cycle consistency loss를 한 방향만 사용했을 땐 훈련 시 불안정한 모습이 나타났으며 model collapse를 일으켰다.

GAN alone 과 GAN + forward 를 보면 다른 input image에 대해서 동일한 output image를 반환하는 model collapse가 발생한 것을 확인할 수 있다.
5.2 Applications
Photo generation from paintings (Figure 12)
페인팅을 그림으로 변환하는 작업에서는 색을 보존하기 위해 추가적인 손실 함수가 필요했다. 추가된 identity mapping loss는 generator가 target domain의 이미지를 받았을 때 input을 그대로 반환하도록 강제한다.

Figure 9를 보면 identity mapping loss가 색을 보존하는데 도움이 된 것을 확인할 수 있다.
6. Limitations and Discussion
많은 과제에서 우리의 연구가 주목할만한 결과를 보여주지만, 모든 경우에 균일하게 성능이 좋은 것은 아니다. 색이나 텍스쳐의 변환을 요구하는 과제에선 보통 좋은 결과를 보여준다. 그러나 개를 고양이로 바꾸는 등의 'geometric change'를 요구하는 과제에서는 대부분 실패한다.
또한 짝지어진 이미지 쌍으로 훈련한 모델의 성능과는 상당한 수준 차이를 보인다. 이 차이는 좁히는 것이 불가능하게 느껴지기도 한다. 이 연구에서처럼 완전히 non-supervised 데이터로 훈련을 진행하기보단 weak 혹은 semi-supervised 데이터를 추가한다면 더 강력한 translator을 만들 수 있을 것이다.






출처: J. Zhu, T. Park, P. Isola and A. A. Efros, "Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks," 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2242-2251
