[논문 리뷰] Unifying Architectures, Tasks, and Modalities through a Simple Sequence-to-Sequence Learning Framework
논문리뷰
0. Abstract
이 연구에서 우리는 multimodal pretraining을 위한 통합된 패러다임을 추구한다. 우리는 OFA(One-for-All)라는 unified multimodal pretrained model을 제시한다. OFA는 단순한 sequence-to-sequence 학습 프레임워크를 기반으로 하고 인코더-디코더 구조를 사용한다. OFA는 fine-tuning시 task-specific한 레이어를 요구하지도 않는다. OFA는 다양한 multimodal task에서 SOTA를 달성함은 물론이고 unimodal task 에서조차 unimodal 만을 위해 학습된 모델들과 동등한 수준의 성능을 보여준다.
1. Introduction
사람처럼 다양한 과제와 양식(modality)를 다룰 수 있는 전능한(omnipotent) 모델을 만드는 것은 AI 커뮤니티에서 다루는 목표 중 하나이다. 이 목표를 다루는데 있어 가장 큰 문제는 다양한 종류의 양식, 과제(task), 그리고 훈련 방식(training regime)을 한 모델에 담아야 한다는 것이다.
최근 등장한 Transformer 아키텍쳐는 universal computation engine으로서의 가능성을 보여줬고, pretrain-finetune 패러다임은 많은 도멘인과 few/zero-shot learning 에서도 훌륭한 성능을 보여준다. 이러한 발전이 전능한 모델의 등장을 가능케하고 있다.
우리는 전능한 모델이 다음의 세 가지 조건을 충족시켜야 한다고 주장한다.
1. Task-Agnostic(TA): 분류, 생성, self-supervised pretext task 등의 다양한 과제에 공통적으로 사용할 수 있는 unified task representation를 활용해야한다.
2. Modality-Agnostic(MA): 여러 가지 양식(modality)를 다룰 수 있는 unified input and output representation
3. Task Comprehensiveness(TC): generalization 능력을 얻을 수 있을 만큼의 과제(task) 다양성
현재의 multimodal pretrained 모델들은 몇 가지 design choice들 때문에 위의 세 조건을 충족시키지 못한다.
- Extra learnable components for finetuning: task-specific heads, adapters[11], soft prompts[12] 와 같은 디자인은 TA를 어긴다.
- Task-specific formulation: 대부분의 모델들은 pretraining, finetuning, zero-shot task마다 task formulation과 training objective가 다르다. 이런 디자인은 TA를 어기고 task의 다양성을 늘리기 어렵기 때문에 TC 를 달성하기 어렵다.
- Modality-specific design for varieties of I/O: VL-pretrained 모델들은 detected object features를 input feature로 사용하는 경우가 많다. 그러나 이런 modality-specific 디자인에서 이미지는 '사물(object)'이라는 컨셉과 얽혀버린다. 그렇게 되면 모델을 이미지 생성(image genearation)이나 object-detection과 같은 과제에 훈련하기 어려워진다.
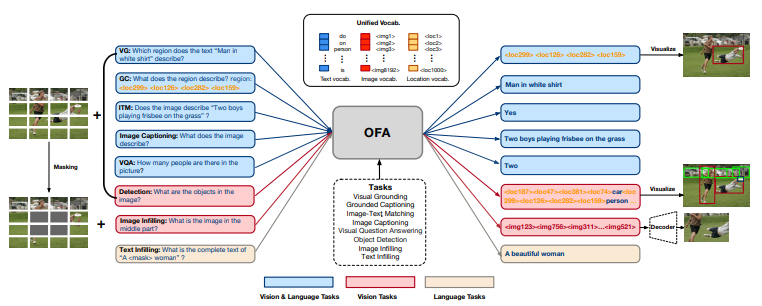
그러므로 우리는 OFA(One For All)을 제안한다. OFA는 architecture, task, modality를 통합해 위의 세 조건을 모두 충족시킨다. pretrain과 finetuning을 sequence-to-sequence 방식으로 통일하면서 TA를 만족한다. Transformer를 modality-agnostic 연산 엔진으로 채택하면서 task-specific, modality-specific 요소가 downstream task 에서 추가되지 않도록 한다. 모든 과제에서 globally shared multimodal vocabulary를 사용해 다른 modality에서 나온 정보를 표현한다.
2. Related Work
Language Pretraining & Vision Pretraining
NLP 분야에서 natural language pretraining은 혁신적이었다. BERT와 GPT의 출현이 이를 증명한다. 비젼 분야에서도 이를 모방해 self-supervised learning을 활용하고 있다. 최근 Masked Language Model(MLM)과 유사한 방식으로 ViT 아키텍쳐를 활용한 generative pretrainig[34, 35]가 downstream 성능을 증가시키고 있다.
Multimodal Pretraining
연구자들은 generation task에 masking 전략과 인코더-디코더 아키텍쳐를 사용한다. preprocessing을 단순화하기 위해 patch projection을 사용한다. text-to-image synthesis라는 연구 분야도 존재한다.
Unified Frameworks
unified framework를 사용하려는 여러 시도들이 존재하지만 이런 모델들은 downstream task(VQA, image captioning)에서 성능이 저하되는 모습을 보인다. image generation 능력은 아예 없다.
3. OFA
3.1 I/O & Structure

I/O
multimodal pretraining을 가능하게 하기 위해선, visual 정보와 linguistic 정보가 Transformer에서 동시에 처리될 수 있도록 데이터를 전처리해야한다. object detection을 통해 이미지에서 feature extraction을 진행하는 것은 복잡하고 많은 자원과 시간이 요구된다. 그래서 우리는 간단하게 이미지를 개의 패치(patches)로 나눈 뒤 은닉 층의 사이즈인 로 project하는 방식을 채택한다.
lingustic 정보를 처리하는 방식은 GPT와 BART의 방식을 따른다. byte-pair encoding(BPE)를 적용하고 feature embedding을 사용한다.
다른 modality들을 task-specific output schema 없이 처리하기 위해선 다양한 modality의 데이터를 통일된 공간에 표현하는 것이 필수적이다. 한 가지 해결 방법은 텍스트, 이미지, 물체(object)를 통일된 output vocabulary로 이산화(discretize)하는 것이다. Sparse coding은 이미지 representation의 길이를 줄이는데 효과적이다. 예를 들어 의 해상도를 갖는 이미지는 크기의 code sequence로 나타내질 수 있다. 각각의 code는 대응되는 patch와 강한 상관관계를 갖는다.[34]
region-related task에선 이미지 뿐만 아니라 사물(object)를 표현할 수 있어야 한다. 우린 [61]을 따라 사물을 discrete token들의 연속으로 나타낸다. 각각의 사물에 대해 우린 사물의 label과 bounding box를 추출한다. bounding box의 실수 형태 모서리 정보들은 형태의 loaction token으로 정수화된다.
간단함을 위해, 우리는 subwords, image codes, location tokens들에 대해 unified vocabulary를 사용한다.
Architecture
Transformer를 사용한다.
3.2 Task & Modalities
unseen task에도 모델이 generalize할 수 있기 위해선 다른 modality를 아우르는 여러가지 downstream task를 통일된 패러다임으로 표현해야한다.
task와 modality를 통합하기 위해서 우리는 통합된 sequence-to-sequnce 학습 패러다임을 pretraining, finetuning, inference 전 과정에 걸쳐 적용한다. Seq2Seq generation task는 cross-modal understanding, uni-modal understanding, generation 모두를 아우를 수 있다. 모든 task에서 이 구성을 사용하고, handcrafted instructions(e.g. "[Image] What does the image describe?")를 사용해 각각의 task를 구분한다.
Cross-modal task는 총 5가지를 다룬다.
1. Visual Grounding(VG)
input: image, instruction("Which region does the text
describe?
output: region position
2. Grounded Captioning(GC)
inverse task of VG
input: image, instruction("What does the region describe? region: ")
output: description of the region
3. Image-Text Matching(ITM)
input: image, instruction("Does the image describe ?")
output: "Yes" or "No"
4. Image Captioning(IC)
input: image, instruction("What does the image describe?")
output: caption
5. Visual Question Answering(VQA)
input: image, question
output: answer
uni-modal task는 vision 2가지, language 1가지를 다룬다.
vision representation learning으로는 image infilling과 object detection으로 모델을 pretrain한다. 최근 generative self-supervised learning for computer vision 분야에선 masked image modeling이 효과적인 pretraining task라는 것이 알려졌다.[34, 35]
Vision 1. Image Infilling
input: 중간 부분이 masking된 이미지, instruction("What is the image in the middle part?")
output: generated sparse codes for th central part of the image
pixel level representation에 대한 이해도 강화
Vision 2. Object Detection
input: image, instruction("What are the objects in the image?")
output: sequence of object positions and label
obeject level representation에 대한 이해도 강화
Language 1. Text Infilling
3.3 Pretraining Datasets
Vision & Language data (i.e., image-text pairs)
Vision data (i.e., raw image data, object-labeled data)
Language data (i.e., plain texts)
3.4 Training & Inference
cross-entroy loss를 활용해 모델을 최적화(optimize)한다.
위의 식을 활용해 OFA를 학습한다. 는 input, 는 instruction, 는 output, 는 모델 파라미터이다.
inference 시에는 beam search와 같은 decoding strategy를 적용한다. 그러나, 이 패러다임은 분류 task들에서 두 가지 문제를 갖는다.
- 전체 vocabulary에 대해 optimize하는 것은 불필요하고 비효율적이다.
- 모델이 closed label set에 있지 않은 invalid label을 생성할 수도 있다.
이 문제들을 해결하기 위해 우리는 prefix tree(Trie, [67])에 기반한 search strategy를 소개한다.
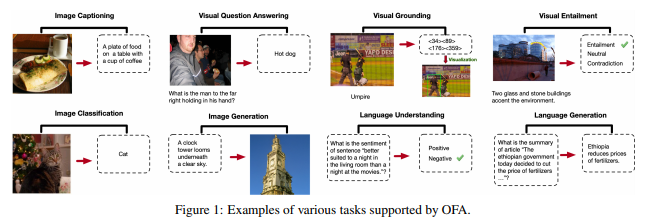
4. Experiments

위 task들이 OFA의 downstream performance를 측정하기 위해 사용된 task들이다.
experiments 결과는 몇 가지 qualitative analysis 사진들로 대체한다.


4.3 Zero-shot Learning & Task Transfer
instruction-guided pretraining 방식 덕분에 OFA는 zero-shot inference를 수행할 수 있다. 실험 결과 OFA 는 Uni-Perceiver보다 좋은 성능을 보인다.
OFA는 new task instruction을 갖는 unseen task에도 transfer할 수 있다. 우리는 "grounded question answering"이라는 새로운 task를 설계했다. (Figure 4) 이미지의 특정 지역에 대한 질문이 주어지고, 모델은 정답을 말해야한다. OFA는 이 task에서 훌륭한 성능을 보인다.
OFA는 out-of-domain input들에 대해서도 잘 작동한다. Figure 5를 보면 OFA 는 에니메이션 사진, 합성 사진 등에 대해서도 VQA와 visual grounding을 훌륭히 소화해낸다.
4.4 Ablation on Multitask Pretraining
prtraining에 사용된 각각의 task의 영향력을 파헤친다.
먼저 uni-modal pretraining task들이 성능에 어떤 영향을 미쳤는지 확인한다. Text infilling은 image caption 성능을 향상시키다. 그러나, language pretraining task가 image classification의 성능을 저하한다는 것과 text-to-image generation 성능을 향상시키는 것 또한 확인할 수 있다.
Image infilling은 image classification과 text-to-image generation의 성능을 눈에 띄게 발전시킨다. 그러나, image infilling은 image captioning과 VQA 성능은 떨어뜨린다.
더 나아가 우리는 multimodal task들이 성능에 어떤 영향을 미쳤는지도 확인한다. 실험 결과 region을 예측하도록 요구하는 task가 multimodal task에 결정적이라는 사실을 확인할 수 있다. 이는 detection, visual grounding, 그리고 grounded captioning이 모델이 vision과 language 사이의 alignment를 학습하게끔 돕는다는 것을 암시한다. 또한 놀랍게도 detection이 visual understanding 성능을 향상시킨다. 이 결과는 region information을 사용하는 것이 visual understanding에 필수적일 수도 있음을 나나탠다.
5. Conclusion
OFA는 architecture, tasks, modalities의 통합을 이루어낸다.
이를 통해 추가적인 레이어어 없이 multimodal & uni-modal 이해와 generation을 가능케한다. 실험 결과 OFA는 captioning, text-to-image generation, VQA, SNLI-VE, 그리고 referring expression comprehension에서 SOTA를 달성한다. OFA는 또한 uni-modal에서만 학습된 모델들과도 견줄만한 uni-modal task 성능을 보인다.
