Intro
https://github.com/tony9402/baekjoon/blob/main/picked.md
- 알고리즘 스터디에 합류하게 되었다.
- 위 사이트의 데일리 문제를 매일 하나씩 푸는데 아직은 알고리즘과 친하지 않아 당분간은 가장 쉬운 문제를 풀 예정이다.
2월 28일
- 이 때부터 시작이었으나..
- 백신 맞고 아플 것 같아서 안풀었다(핑계)
3월 1일
- 이 날은 진짜 아팠으나 전 날에 대한 죄책감 때문에 몸이 조금 좋아지고 밤 11시에 풀었다.
- BOJ 1181번 단어 정렬 문제를 풀었다.
https://www.acmicpc.net/problem/1181
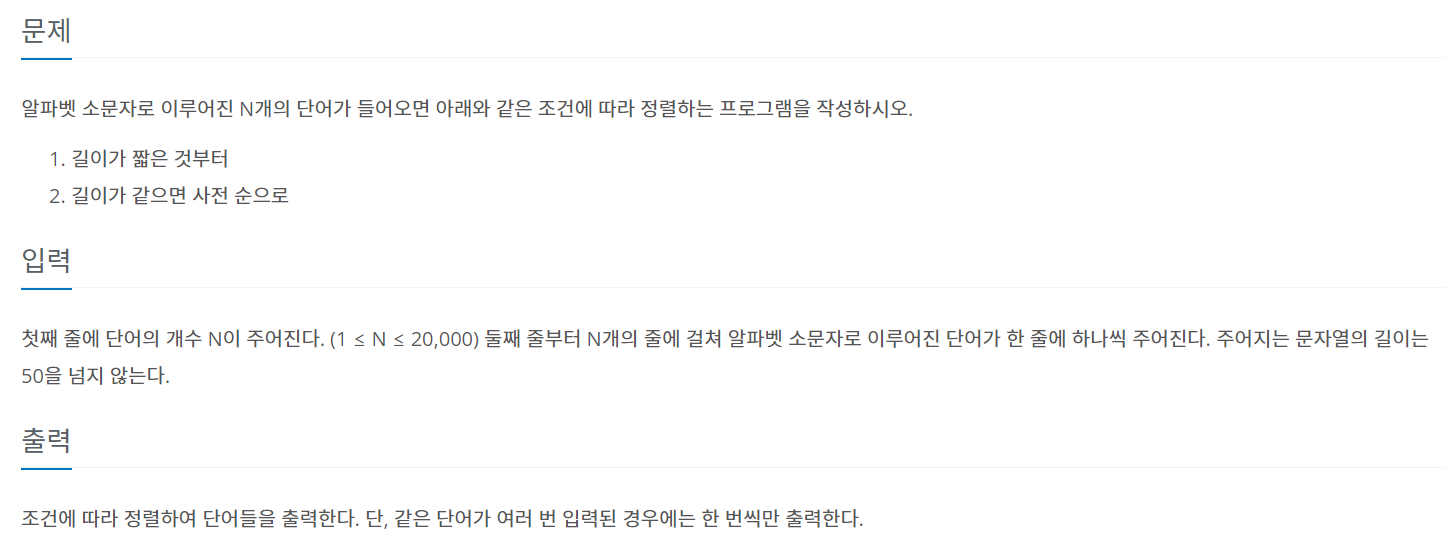
풀이 과정
- 처음에는 딕셔너리를 이용해 같은 길이의 단어들을 하나의 정렬된 하나의 리스트로 묶어 문자의 길이 순서대로 정렬한 2차원 리스트를 생성해서 출력하려고 했다.
- 예제 테스트는 통과했으나 왜인지 틀렸다. (이 때는 BOJ의 질문 기능을 몰랐다.) 아직 머리가 띵했던 상태라 바로 검색을 했다.
- 파이썬의 튜플을 이용하면 sort()만 사용해도 첫 번째 원소를 기준으로 오름차순 정렬하고, 첫 번째 원소가 같은 경우 두 번째 원소로 오름차순 정렬한다.
number = [(3, 5), (1, 2), (7, 2), (3, -1), (2, 3), (9, 6)]
# 첫 번째 원소를 기준으로 오름차순 정렬하고
# 첫 번째 원소가 같은 경우 두 번째 원소로 오름차순 정렬
number.sort()
print(number)
# 두 번째 원소를 기준으로 오름차순 정렬하고
# 두 번째 원소가 같은 경우 첫 번째 원소로 오름차순 정렬
number.sort(key=lambda x:(x[1], x[0]))
print(number)
# 첫 번째 원소를 기준으로 내림차순 정렬하고
# 첫 번째 원소가 같은 경우 두 번째 원소로 오름차순 정렬
number.sort(key=lambda x:(-x[0], x[1]))
print(number)
# 두 번째 원소를 기준으로 내림차순 정렬하고
# 두 번째 원소가 같은 경우 첫 번째 원소로 내림차순 정렬
number.sort(key=lambda x:(-x[1], -x[0]))
print(number)출력 결과
[(1, 2), (2, 3), (3, -1), (3, 5), (7, 2), (9, 6)]
[(3, -1), (1, 2), (7, 2), (2, 3), (3, 5), (9, 6)]
[(9, 6), (7, 2), (3, -1), (3, 5), (2, 3), (1, 2)]
[(9, 6), (3, 5), (2, 3), (7, 2), (1, 2), (3, -1)]정답 코드
N = int(input())
words = []
for i in range(N):
words.append(input())
set_words = list(set(words))
sort_words = []
for i in set_words:
sort_words.append((len(i), i))
sort_words.sort()
for len, word in sort_words:
print(word)3월 2일
- BOJ 9996번 단어 정렬 문제를 풀었다.
https://www.acmicpc.net/problem/9996

풀이 과정
- 문제를 잘못 이해해서 패턴의 한글자씩 순서대로 파일 이름에 포함되는지를 확인했다. 반례를 찾으러 질문 게시판에 들어가서야 문제가 정규 표현식임을 깨달았다.
- 이후 pattern에서 *을 기준으로 앞(start), 뒤(end) 글자로 나누고
- start와 pattern의 맨 앞부터 start의 길이만큼 자른 문자열과
- end와 pattern의 맨 뒤부터 end의 길이만큼 자른 문자열이
- 각각 같은지 확인 후 같으면 "DA", 다르면 "NE"를 출력했다.
- 하지만 pattern이 abcd*cdef이고 파일명이 abcdef 경우가 반례로 나타났다.
- 어떻게 처리할까 고민하다가.. pattern의 앞+뒤 길이보다 파일명이 짧은 경우 어짜피 답이 될 수 없으므로 "NE"를 출력했다.
정답 코드
N = int(input())
pattern = input()
file = []
for i in range(N):
file.append(input())
pattern = pattern.split('*')
for i in file:
if len(i) >= len(pattern[0]) + len(pattern[1]) :
start = i[0:len(pattern[0])]
end = i[-len(pattern[1]):]
if pattern[0]==start and pattern[1]==end:
print("DA")
else:
print("NE")
else:
print("NE")3월 3일
- BOJ 1251번 단어 나누기 문제를 풀었다. (어째 문자열 문제만 계속 푸는거 같다..?)
https://www.acmicpc.net/problem/1251
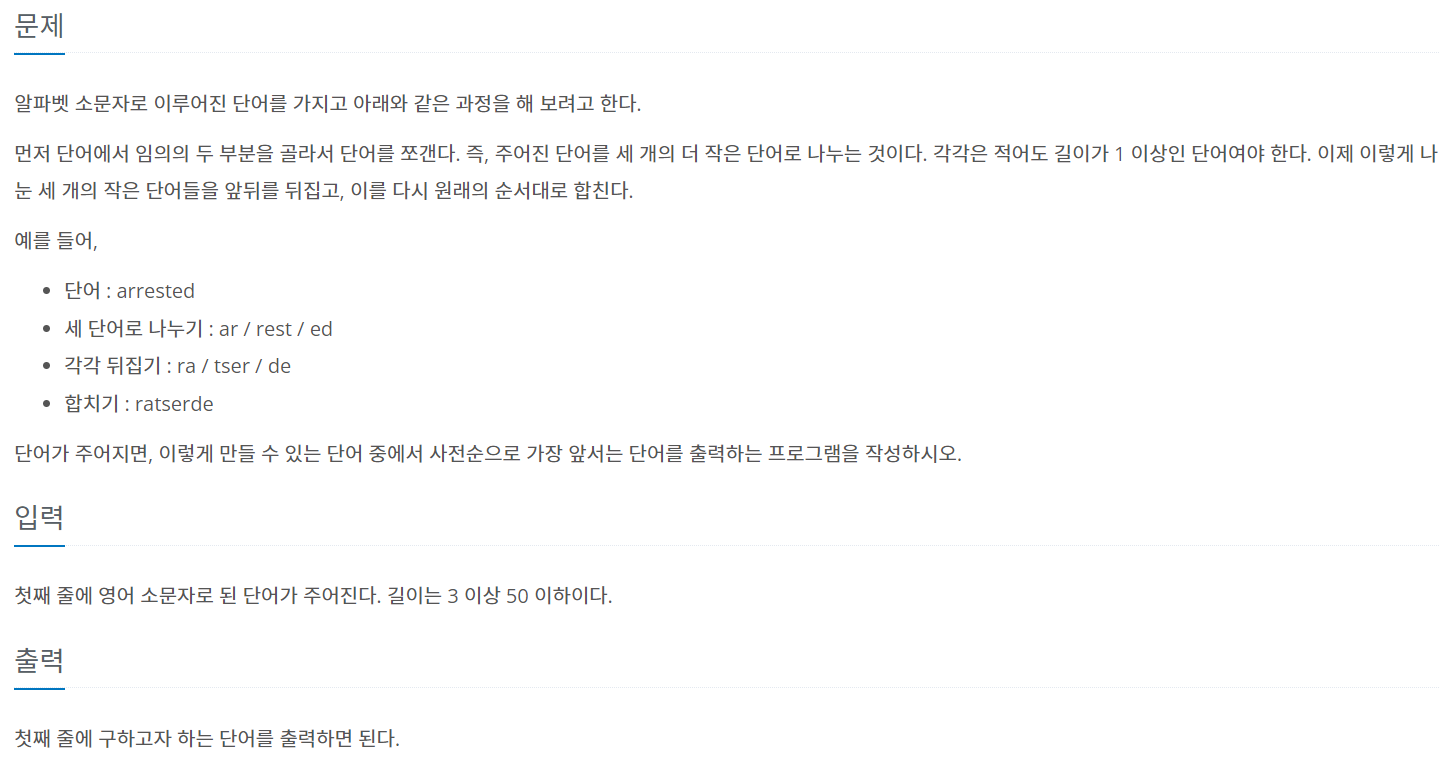
풀이 과정
- 처음에는 어떻게 풀까.. 하면서 머리가 지끈했다. 문제 분류를 보니 브루트포스 알고리즘이었다. 모든 경우의 수를 구해야 하는구나!
- 꼭 세 단어로 나누어야 했기에 범위를 나누는데 머리가 또 한번 지끈했다. 무작정 내 생각대로 첫번째 분류의 마지막은 글자수-2, 두번째 분류의 마지막은 글자수-1로 해야 그 전 범위까지 들어가니까..라고 생각했는데 그 아래에 문자열 split 부분까지 고려하지 못했다. 그래서 중간중간 출력할 때 뭔가 적은데.. 싶었던 것이다.
- 코드 자체는 짧고 쉬웠다. 세 부분으로 나눌 수 있는 모든 경우의 수에 대해 문제의 세 부분으로 나누기→각각 뒤집기→합치기 한 것을 한 리스트에 담아놓고 정렬 후 가장 작은 것을 출력하면 된다.
- 결론 : 반복문이나 split을 함께 사용할 때는 끝 범위를 한번 더 생각하자!
정답 코드
word = input()
split= []
for i in range(1, len(word)-1):
for j in range(i + 1, len(word)):
first = "".join(reversed(word[:i]))
second = "".join(reversed(word[i:j]))
third = "".join(reversed(word[j:]))
split.append(first+second+third)
split.sort()
print(split[0])3월 4일
- BOJ 18311번 왕복 문제를 풀었다. (오늘은 문자열이 아닌 구현 문제!)
https://www.acmicpc.net/problem/18311

풀이 과정
- K에서 코스를 지날 때마다 코스 길이만큼을 빼주며 코스 번호를 구했다.
- 반환하기 전에는 num = 1에서 코스를 지날 때마다 1씩 더해주었고, 코스 길이가 0보다 작아지면 반복문을 탈출했다.
- 반환 이후에는 num = 코스 갯수에서 코스를 지날 때마다 1씩 빼주었고, 마찬가지로 코스 길이가 0보다 작아지면 반복문을 탈출했다.
- 단 이때 반환 전 길이를 무시하기 위해 K값을 K에서 전체 길이를 빼고 반복문 탈출 조건이 0보다 작을 때(같거나 작을 때XXX)로 설정하여 1을 더 빼준 값으로 설정하고 반복문을 돌렸다.
정답 코드
N, K = map(int, input().split())
course = list(map(int, input().split()))
length = sum(course) - 1
if K <= length:
num = 1
for i in course:
K = K - i
if K < 0:
break
else:
num += 1
else:
K = K - length - 1
num = N
for i in list(reversed(course)):
K = K - i
if K < 0:
break
else:
num -= 1
print(num)3월 5일
- BOJ 2644번 촌수계산 문제를 풀었다. 그래프 문제를 풀어보고 싶어서 오늘의 문제 레포의 문제가 아닌 다른 문제를 풀었다.
https://www.acmicpc.net/problem/2644
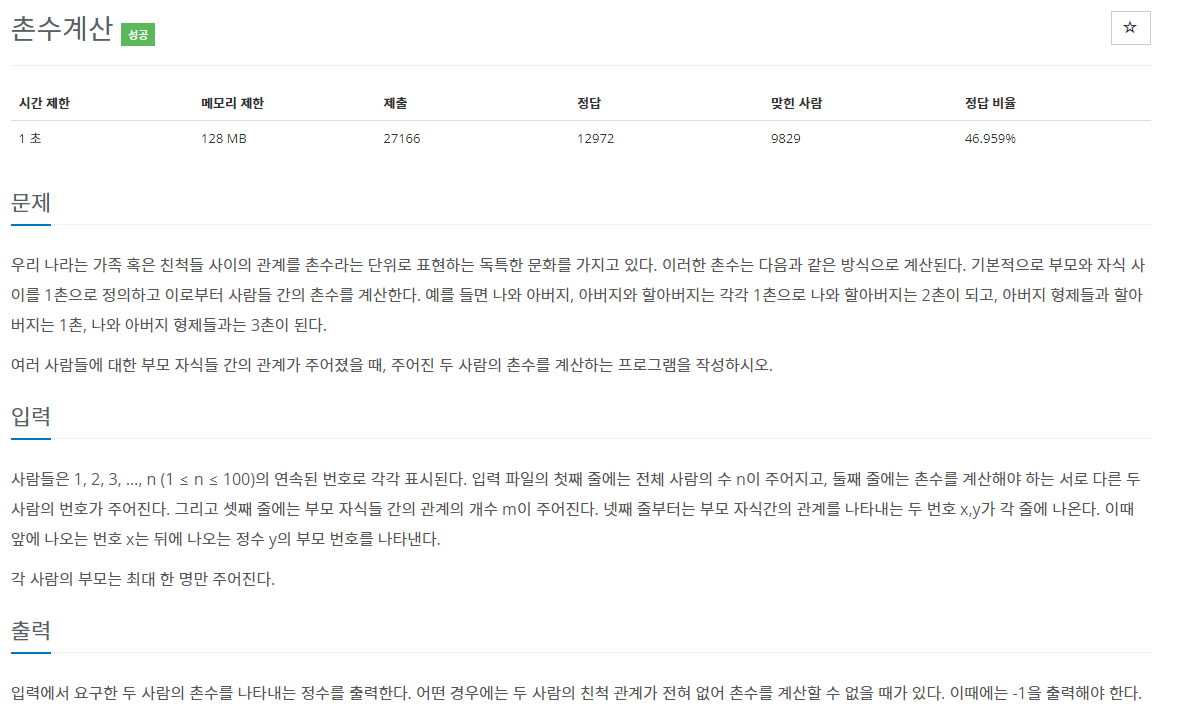
풀이 과정
- 처음에는 어떻게 그래프 탐색으로 구현하지.. 생각했지만 그래프 그림을 그려보며 이해가 됐다. 그래프 탐색 문제는 꼭 그래프 그림을 그려보자!
- bfs로 탐색을 하면서 반복문 숫자가 target number와 일치하면 cnt를 리턴하고, 아니면 cnt를 증가시키고 반복문 숫자를 큐에 넣으려 했다.
- 하지만 이렇게 하면 단계별(?)로 cnt가 증가하는 것이 아닌 인접하는 것을 탐색할 때마다 cnt가 증가하므로 이렇게 하는게 아님을 깨달았다.
- 고민을 하다가 다른 분이 구현한 것을 봤는데 큐에 숫자를 넣을 때 단계(?)를 증가시키며 넣는 것을 보고 비슷하게 구현해보았더니 target number와 일치했을 때 원하는 값이 나왔고 그 값을 리턴 시켰다.
- 마지막으로 예외 처리를 위해 while문 밖에 -1을 리턴하도록 추가시켰다.
정답 코드
from collections import deque
n = int(input())
one, two = map(int, input().split())
m = int(input())
graph = [[] for _ in range(n+1)]
for i in range(m):
x, y = map(int, input().split())
graph[x].append(y)
graph[y].append(x)
visited = [False] * (n+1)
visited[one] = True
queue = deque()
queue.append((0, one))
def bfs():
while queue:
cnt, x = queue.popleft()
for i in graph[x]:
if not visited[i]:
if i == two:
return cnt+1
else:
visited[i] = True
queue.append((cnt+1, i))
return -1
print(bfs())3월 6일
- BOJ 1325번 효율적인 해킹 문제를 풀었다. 그래프 문제를 풀어보고 싶어서 오늘의 문제 레포의 문제가 아닌 다른 문제를 풀었다 22..
https://www.acmicpc.net/problem/1325
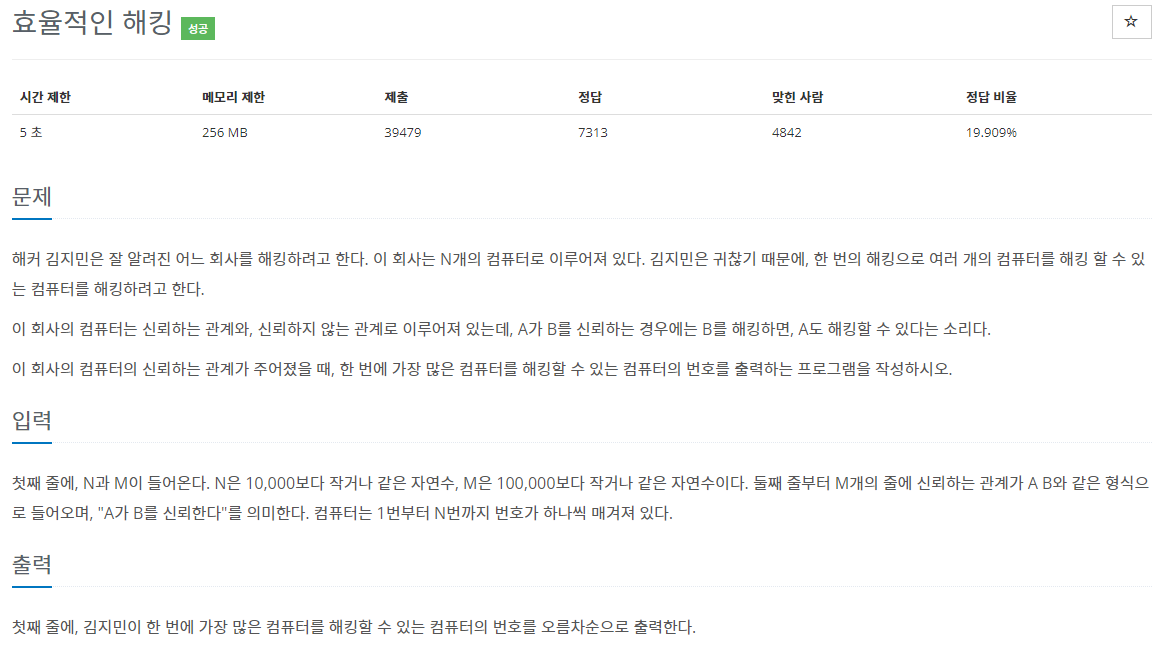
풀이 과정
- 그래프 탐색을 위해 신뢰하는 관계에 대해 그래프를 생성했다.
- bfs를 통해 연결된 컴퓨터의 갯수를 리턴하는 함수를 만들었다.
- 모든 컴퓨터에 대해 위의 함수를 돌려 연결된 갯수를 저장하고, 가장 많은 갯수를 가지는 컴퓨터의 번호를 출력했다.
- 구현 자체는 bfs 기본 틀에서 크게 벗어나지 않아 금방 했다.
- 문제는 자꾸 메모리 초과가 났다.
- 질문 게시판을 보니 Python3가 아닌 PyPy3로 제출하라길래 다시 제출해봤지만 여전히 메모리 초과가 났다.
- 다른 사람의 풀이를 보니 큰 차이가 없어서 뭐지.. 했는데 내가 visited를 안했길래 혹시나 하고 추가로 구현해서 제출하니까 통과했다.
(메모리 226200KB, 시간 15032ms로..ㅋㅋㅋㅋㅋㅋㅋㅋ)
정답 코드
from collections import deque
N, M = map(int, input().split())
graph = [[] for _ in range(N+1)]
for i in range(M):
A, B = map(int, input().split())
graph[B].append(A)
def counting(num):
visited = [False] * (N+1)
queue = deque()
visited[num] = True
queue.append(num)
cnt = 1
while queue:
x = queue.popleft()
for i in graph[x]:
if not visited[i]:
visited[i] = True
queue.append(i)
cnt += 1
return cnt
hack = []
for i in range(1, N+1):
count = counting(i)
hack.append(count)
max_count = max(hack)
max_list = [i for i, value in enumerate(hack) if value == max_count]
max_list.sort()
for i in max_list:
print(i+1, end=' ')Outro
- 그 전에는 안그랬는데 주말에 그래프 문제들을 풀면서 현타가 많이 왔다.. 남들은 쉽게 쉽게 풀 문제들인데 나는 왜 자꾸 에러나고 답도 제대로 안나올까..
- 뭔가 하루에 한 문제씩만 풀자 생각을 해서 대충 쉬운 문제를 풀고 넘어가니까 제대로 공부가 안되는거 같았다.
- 결론 : 담주부터는 1일 1문제가 아닌, 1주일에 2일정도 알고리즘에만 집중하면서 한 유형씩 풀어볼까 생각했다.

🤗🤗🤗