[논문리뷰] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION :: VGG

ABSTRACT
이 논문에서는 깊이가 증가하는 convolutional network이 large-scale 이미지 인식의 정확도에 어떤 영향을 미치는지에 대해 서술하고 있다.
- 주요관점 : 3x3 크기의 매우 작은 convolution filter를 사용하여 깊이를 증가시키는 네트워크의 성능을 확인하는 것
기존의 아키텍처의 구성보다 깊이를 16-19 weight layer로 늘리면서 성능에 많은 개선을 보이며 다른 Datasets에서도 일반화되어 유의미한 성과를 냈다.
1. INTRODUCTION
setc2 : ConvNet의 구성
sect3 : image classification training 및 결과
sect4 : ILSVRC 분류 작업
sect5 : 논문 마무리
Appendix A : ILSVRC-2014 object localisation system
Appendix B : very deep features를 다른 데이터 셋으로 일반화 하는 것
Appendix C : 주요 논문 개정 목록
2. CONVNET CONFIGURATION
2.1 ARCHITECTURE
Input
- 224 x 224 RGB images
전처리 과정으로 training set에서 계산된 RGB값의 평균을 각 픽셀에서 뺀 후 convolutional layer에 전달된다.
Convolution layer
- 3x3 filter 사용
입력 채널의 비선형성을 위해 1x1 filter를 일부 사용하기도 한다.
- stride : 1 pixel
- 3x3 conv layer에 대한 padding : 1 pixel
Pooling layer
- 총 5개, max-pooling layer 로 구성
- 2x2 pixel window에서 stride : 2 pixel
Fully-Connected(FC) layer
- 3개의 FC layer
첫번째,두번째 FC layer는 4096개의 채널\
세번째 FC layer는 1000개의 채널을 포함하여 1000-way ILSVRC 분류 수행\
마지막 layer에서 softmax 수행
모든 Hidden layer는 ReLU를 활성화 함수로 사용한다.
2.2 CONFIGURATIONS
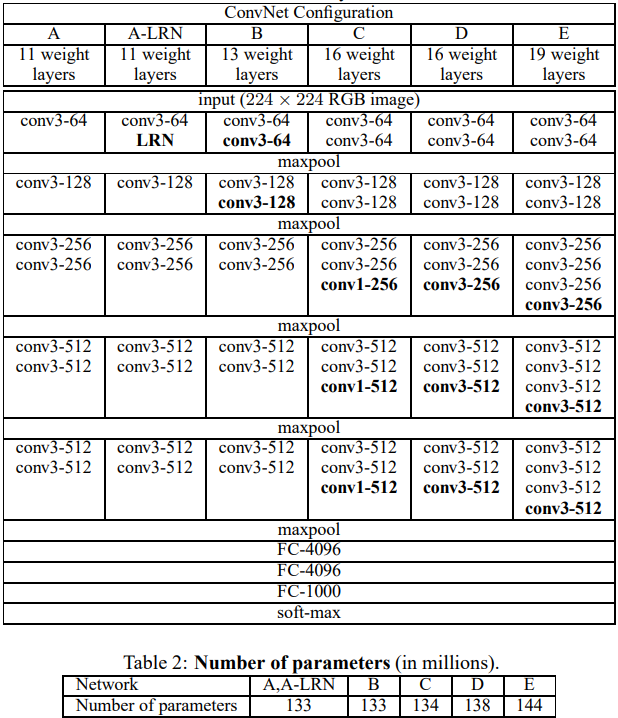
-
table1 : 각 network를 A-E로 구성
A network의 경우 11개의 weight layers(conv layers 8개, FC layers 3개)
E network의 경우 19개의 weightlayers(conv layers 16개, FC layers 3개)로 표현채널 수는 64개에서 시작하여 max-pooling layer마다 2배 증가하여 최종적으로 512개에 도달
-
하나의 network 외에는 LRN(정규화)를 사용하지 않는데 이는 메모리소비와 시간복잡도의 증가로 이어지기 때문이다.
-
table2 : 각 network의 parameter 수 표현
2.3 DISCUSSION
본 논문에서는 11x11 with stride 4 in (Krizhevsky et al., 2012), or 7x7 with stride 2 in (Zeiler & Fergus,2013; Sermanet et al., 2014) 와는 다르게 3x3 conv layer stack을 사용하였다.
이러한 방식의 장점은 아래와 같다.
- 비선형성의 증가(conv연산이 ReLU를 포함하고 layer의 수가 늘어남)
- prameter의 감소(ex. 3(32C2)= 27C2 < 72C2 = 49C2)
본 논문과 그 외 논문의 비교점을 아래에 서술 하였다.
Ciresan et al(2011)
작은 필터를 사용했지만 VGG-16보다 얕은 깊이를 가졌고 the large-scale ILSVRC dataset에서 평가되지 않음.
Goodfellow et al. (2014)
깊은 convnet(11 weight layers)를 적용하고 깊이에 따른 성능 향상을 보임.
GoogLeNet (Szegedy et al., 2014)
- 당시 기존에 발표된 것 중의 최고의 성능
- convnet(22 weight layers)와 작은 filter(3x3 외에도 1x1, 5x5 convolution etc) 사용을 기반으로 하는 것이 유사함.
- 하지만 더 복잡하게 설계되어있고 계산양을 줄이기 위해 처음 몇개의 레이어에서 피처맵의 공간정보가 확 줄어든다는 특징 .
3 CLASSIFICATION FRAMEWORK
3.1 TRAINING
- ConvNet training 은 Krizhevsky et al. (2012) 를 따른다.
- momentum을 사용한 mini-batch gradient descent로 the multinomial logistic regression object를 최적화 하여 수행한다. (batch size : 256 , momentum : 0.9)
- 처음 두개의 fully-connected layer에 대한 가중치 감소와 dropout(dropout ratio : 0.5)은 정규화되어있다.
- learning rate는 초기 10-2로 설정
- validation set의 정확도가 향상되지 않을 때 마다 10의 배수로 감소된다.\
-> 총 3번의 감소가 있었고 370K번의 반복(74 epoch)후 중지되었다. - 이전의 네트워크 Krizhevsky et al. (2012)와 비교했을 때 더 많은 수의 parameter와 깊이를 가졌지만 더 큰 깊이와 작은 conv filter에 의해서 목표에 도달하는데 필요한 epoch가 적다.
❔ 왜 3x3 을 썼는가 ? 또 1x1은 왜 썼는가? 를 추후..알아봅시다..
