ABSTRACT
Deep Neural Network (DNNs)은 시퀀스(sequence)를 시퀀스로 매핑하는데는 사용할 수 없는데 이를 해결하기위해 시퀀스 구조에 대한 최소한의 가정을 하는 일반적인 end-to-end 접근방식을 제시하고 있다.
그 방법은 다중 LSTM(Long Short-Term Memory)을 사용해 입력 시퀀스를 고정된 차원의 백터로 매핑하고, 다른 LSTM을 사용해 타겟 시퀀스를 디코딩하는 것이다.
➕WMT'14 dataset 사용하여 영어 -> 프랑스어 번역
➕ 입력 데이터를 반전시킴으로서 학습 속도를 개선하였음.
1. INTRODUCTION
Deep Neural Networks (DNNs)의 특징
- 적은 단계로 병렬 계산을 수행할수 있다.
- 2개 은닉층만 사용하여 N bit 숫자를 정렬할 수 있다.
- 충분한 정보를 제공하는 경우 대규모 DNNs는 supervised backpropagation(지도 역전파)으로 학습시킬 수 있다.
하지만, input과 target이 고정된 차원의 벡터로 인코딩 된 문제에만 적용할 수 있으므로 문장의 길이를 알지 못하는 문제애 대해서는 적용할수 없다는 한계가 있다.
=> Long Short-Term Memory (LSTM) 아키텍처를 적용함으로서 일반적인 sequence to sequence problems를 해결
Idea
입력 시퀀스를 읽는데에 하나의 LSTM을 사용하여 큰 고정차원벡터의 표현을 얻고,
출력 시퀀스를 추출하기위해 또 다른 LSTM을 사용한다.
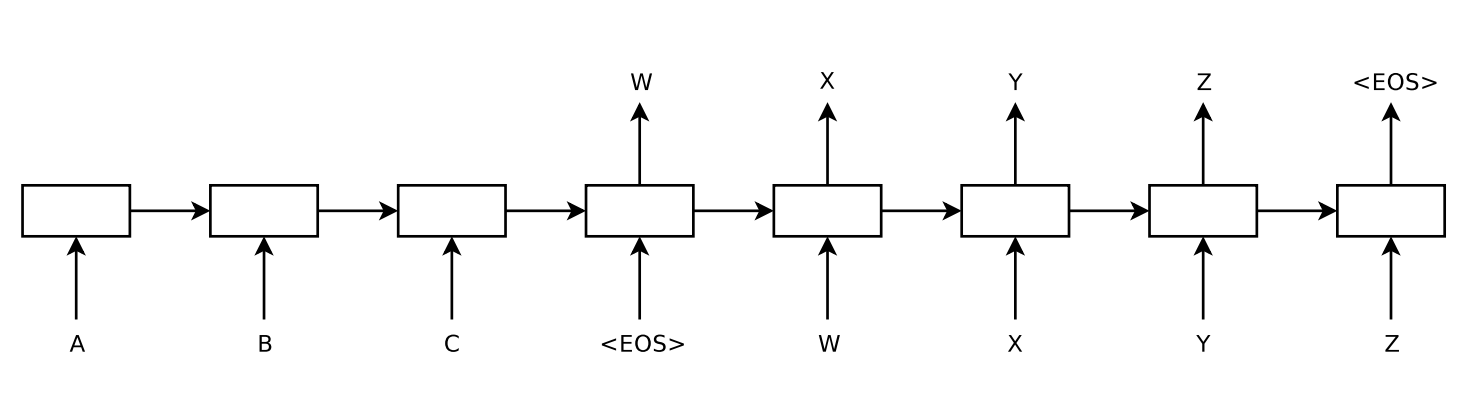
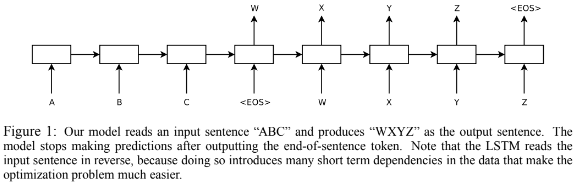 <그림1>
<그림1>
=> 입력시퀀스 : 'ABC' ,출력시퀀스 : 'WXYZ'
📌주요 연구결과
80k(80,000) 단어로 학습된 LSTM을 사용하여 34.81 BLEU score 기록 (번역에 포함되지 않은 단어가 있을경우 패널티 부과)
=> 최적화된 SMT system 보다 일반적인 LSTM구조가 더 성능이 좋음을 알수 있었다.같은 Task에 대해서 LSTM을 사용해 최적화된 SMT baseline 중 1000개를 재점수화 했을때 3.2 score가 더 향상된 결과를 얻었고 36.5 BLEU score를 기록.
➕LSTM은 긴 문장에서도 문제가 발생하지 않는다. (source 문장에서는 단어의 순서를 반대로 바꾸었지만 target 문장에서는 단어의 순서를 반대로 하지 않았기때문)
➕LSTM은 가변길이의 임력 문장을 고정 차원의 벡터 포현으로 매핑한다.
2. The model
-
RNN
input 시퀀스가 주어질때 RNN은 아래의 수식을 이용해 output 시퀀스를 계산한다.
ht = sigm(Whxxt + Whhht-1)
yt = Wyhht특징 및 한계
- 입출력 시퀀스의 alignment(정렬?)이 미리 알려져 있을때엔 쉽게 시퀀스 매킹이 가능하다.
- 입출력 시퀀스가 서로 다른 길이를 가지고 있는 문제에서 적용방법이 명확하지 않다.
- 일반적인 시퀀스 학습의 간단한 전략은 하나의 RNN을 사용하여 input시퀀스를 고정 크기의 벡터로 매핑한다음, 다른 RNN을 사용하여 백터를 target 시퀀스로 매핑하는것이다.
- 하지만 이는 Long term dependency(장기의존성) 문제를 일으킬수 있고 이는 LSTM으로 해결할 수 있다.
-
LSTM
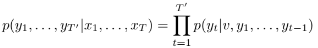
- 입줄력의 길이가 다른 문장의 조건부 확룰을 추정하는 것을 목표로 한다.
- 마지막 hidden state의 입력 시퀀스의 고정 차원 v를 구하고 초기 hidden state가 v설정된 LSTM-LM 공식을 사용해 조건부 확룰을 추정한다.
- 위 식에서 각 p는 모든 단어에 대한 softmax로 표현된다.
- 각 문장은 \로 끝맺어야한다.
- <그림1>은 전체 구조를 표현한 것으로 "A","B","C","\"를 계산하고 활용하여 "W", "X", "Y", "Z", "\"의 확률을 계산한다.
-
특징
- 입력 시퀀스와 출력 시퀀스 각각에 대해 두개의 다른 LSTM을 사용했다.
- 4개의 layer를 가진 LSTM을 사용했다.(깊은 LSTM보다 얕은 LSTM이 더 우수한 성능을 가졌기때문)
- 입력 시퀀스의 단어 순서를 반대로 바꾸는 것이 매우 유용하다
3. Experiments
3.1. Dataset details
- WMT'14 영어 -> 프랑스어 dataset 사용.
- 12M(천이백만)개의 문장으로 구성된 subset(348M개의 프랑스어단어, 304M개의 영어단어)으로 모델 훈련.
- 각각 가장 빈번하게 사용되는 16만개의 source language와 8만개의 target language를 사용해 단어 사전 구성(그 외 단어는 모두 "UNK" 토큰으로 대체)
3.2. Decoding and Rescoring
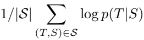
T : 올바른 번역 , S : source 문장 , log 확률을 최대화 하도록 학습
3.3. Reversing the Source Sentences
LSTM은 source 문장을 반전시킴으로서 test난이도는 5.8 -> 4.7로, BLEU score는 25.9 -> 30.6으로 변화하였다.
이러한 결과가 나오는 이유에 대해서 정확히 설명할순 없지만 아래와 같은 이유라고 짐작하고 있다.
source 문장의 단어는 해당되는 target문장의 단어와 멀리 떨어져 있고 minimal time lag(최소지연시간)문제가 있었다. source 문장의 단어를 반대로 뒤집음으로서 각 단어 사이의 평균거리가 줄어들면서 long term dependency문제가 해결되어 성능이 향상된다.
3.4. Training details
- LSTM의 parameter를 -0.08 ~ 0.08 사이로 균일하게 초기화 시켰다.
- learning rate를 0.7로 고정하여 경사하강법 사용(momentum x) , 1/2 epoch 마다 learning rate 절반으로(총 7.5 epochs)
- batch size : 128
- exploding gradients(기울기 복주)를 대비해 제한을 둠.
- 학습되는 일부 긴 문장 때문에 minibatch의 낭비가 생기므로 모든 문장이 비슷한 길이가 되도록 함.
