
이 게시물은 내가 airflow를 local상에서 설치하고 오류난 과정들을 기록한 결과이며 해결과정까지 나타낸 내용임.
앞에 설치하거나 틀을 다루는 과정은 github에 작성됌.
링크
Test - 1
DAG Tutorial - Chrawling
1. 대그 틀 생성하기
# 필요한 모듈 Import
from datetime import datetime
import json
from airflow import DAG
from pandas import json_normalize
# 사용할 Operator Import
from airflow.providers.sqlite.operators.sqlite import SqliteOperator
from airflow.providers.http.sensors.http import HttpSensor
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
# 디폴트 설정
default_args = {
"start_date": datetime(2022, 1, 1) # 2022년 1월 1일 부터 태그 시작-->
# 현재는 23년 1월이므로 태그를 실행하면 무조건 한번은 돌아갈 것
}
NAVER_CLI_ID = "<MU4487CE1mRkX3THqT42>"
NAVER_CLI_SECRET = "<tUmVdjRQ3z>"
# DAG를 설정
with DAG(
dag_id="naver-search-pipeline",
# crontab 표현 사용 가능
schedule_interval="@daily",
default_args=default_args,
#태그는 원하는대로
tags=["naver", "search", "local", "api", "pipeline"],
# catchup을 True로 하면, start_date부터 현재까지 못돌린 날들을 채운다.
catchup=False) as dag:
pass2. DAG안에 입력 -1
task_id=<작업을 구분할 아이디>sqlite_conn_id=<나의 Sqlite 인스턴스와 연결할 때 필요한 커넥션 아이디>sql=<sql 쿼리문>
# sqliteOperator 저장할 테이블 생성
# 네이버 API로 지역 식당을 검색
# 지역 식당명, 주소, 카테고리, 설명, 링크를 저장할 것이므로 다음과 같이 테이블을 구성
creating_table = SqliteOperator(
task_id="creating_table",
sqlite_conn_id="db_sqlite", # 웹UI에서 connection을 등록해줘야 함.
# naver_search_result 라는 테이블이 없는 경우에만 만들도록 IF NOT EXISTS 조건을 넣어주자.
sql='''
CREATE TABLE IF NOT EXISTS naver_search_result(
title TEXT,
address TEXT,
category TEXT,
description TEXT,
link TEXT
)
'''
)자주 쓰는 명령어
# 디렉터리 이동
cd /mnt/c/Users/mink/Desktop/docker/
# airflow 실행
docker-compose up
# airflow bash 실행
./airflow.sh bash
sudo -i
cd /mnt/wsl/docker-desktop-data/version-pack-data/community/docker/overlay2/f73d790ceef9aed2789810e9ada3685c9c2478c4286804fc09bdc556a17e0654/diff/root/airflow/- docker 상에 compose를 통한 airflow 설치와 container를 자동으로 생성했지만 airflow.db를 찾지 못 하고 하나씩 container를 설치하여 postgres와 db를 연결하는 container 생성 및 airflow container를 생성하여 크롤링 진행.
Test - 2
Airflow 설치 및 Dag 생성 크롤링 자동화
# linux 상에 sh 파일을 windows에있는 공유 폴더에서 받아오면
# sh Miniconda3-latest-Linux-x86_64.sh <- 이 방식이 된다면 실행하지만
# 이런식으로 에러가 나온다면 bash Miniconda3-latest-Linux-x86_64.sh로 실행
Conda File IO Error: '/shared/miniconda3/pkgs/envs/*/env.txt'. [Errno 2] No such file or directory: '/shared/miniconda3/pkgs/envs/*/env.txt'fail
Test - 3 성공 -local
PART3. 가까스로 성공한 크롤링 자동화 후 데이터 저장
DOCKER - AIRFLOW - MYSQL < NAVER-API, Linux(wsl )>
필요한 S/W
- Window(wsl2)
- Docker
- Docker compose
- Mysql
- Linux
- Visual Studio
- Airflow
리눅스에서 Docker를 이용하여 Local에서 Airflow 구축 후 Naver api를 이용하여 Mysql로 데이터를 옮기는 실습을 할 것이다.
참고로 airflow.cfg 폴더위치 바꿀것
dags_folder = /home/mink/airflow/dags
base_log_folder = /home/mink/airflow/logs
실습 전 세팅
1. VSC 설치
간략설명
-
Visual Studio를 먼저 설치
-
Linux에서 airflow 폴더로 이동 (cd /airflow)
-
비쥬얼 스튜디오 실행 명령어 입력(code .)

설치하는 이유 : 리눅스에선 vi로 코드를 편집할 수 있지만 내가 불편해서 vsc를 깔고 code로 보게되면 편해지고 코드를 보기 편하다..(특히 자동입력최고..★)
2. 샘플 DAG들 정리
docker와 airflow를 설치했다면 airflow 폴더에 docker-compose.yaml을 들어가자.
(code docker-compose.yaml 실행)

들어가게 된다면 AIRFLOW__CORE__LOAD_EXAMPLES: 'true'라고 되어있어서
true -> false로 설정하고 저장 후 airflow를 다시 실행하면 없어져있을 것이다.
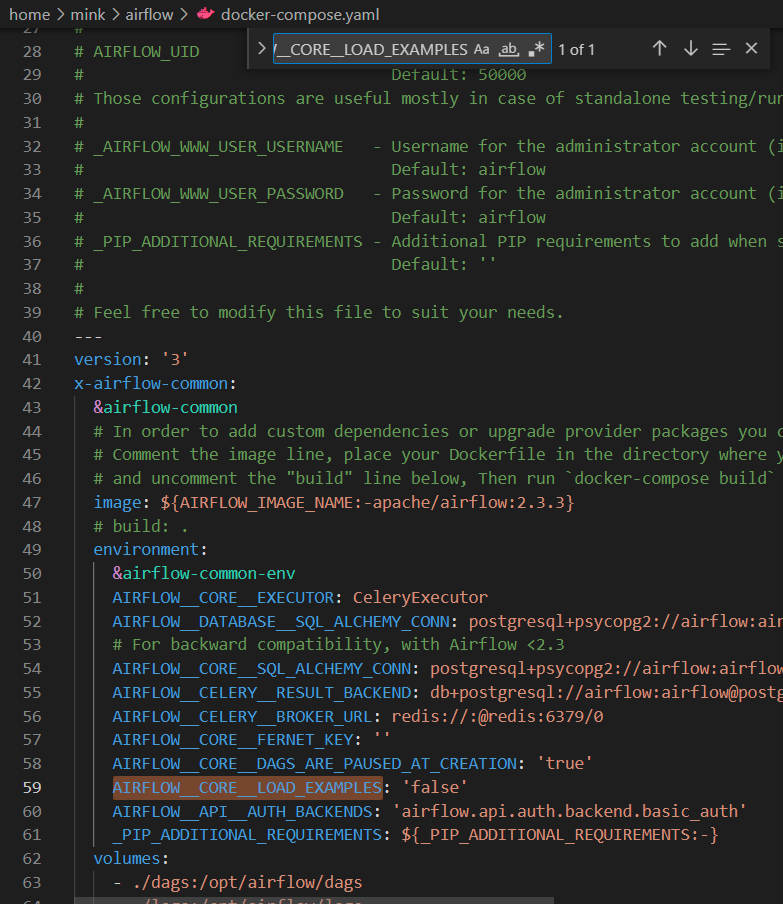
하는 이유 : 기존에 있던 dag들을 확인해봤다면 없애고 내가 테스트 및 실습 할 dag들로만 구성해야 보기 편하다.
3. MYSQL 및 Dbeaver 설치
참고 : 검색창에 mysql를 쳐서 MYSQL SHELL이 나온다면 이 과정은 넘겨도 된다.
간략설명
-
mysql 설치
-
다운로드 가이드 사이트를 보면서 설치
-
Dbeaver 설치하기(가이드 참고)
-
환경변수 설정
-
mysql
-
시스템 속성 -> 환경 변수 -> 시스템 변수 -> 변수 Path 편집 -> 새로 만들기 -> C:\Program Files\MySQL\MySQL Server 8.0\bin 입력(각자 다른 폴더에 있을 수도 있으니 확인바람.)
-
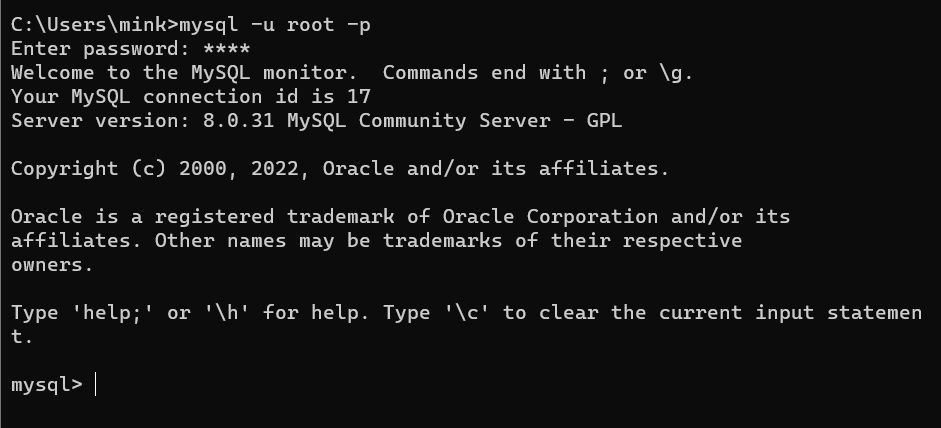
cmd 창을 열어 mysql -u [계정] -p [비밀번호] 입력
-
접속 완료
-
-
-
dbeaver
-
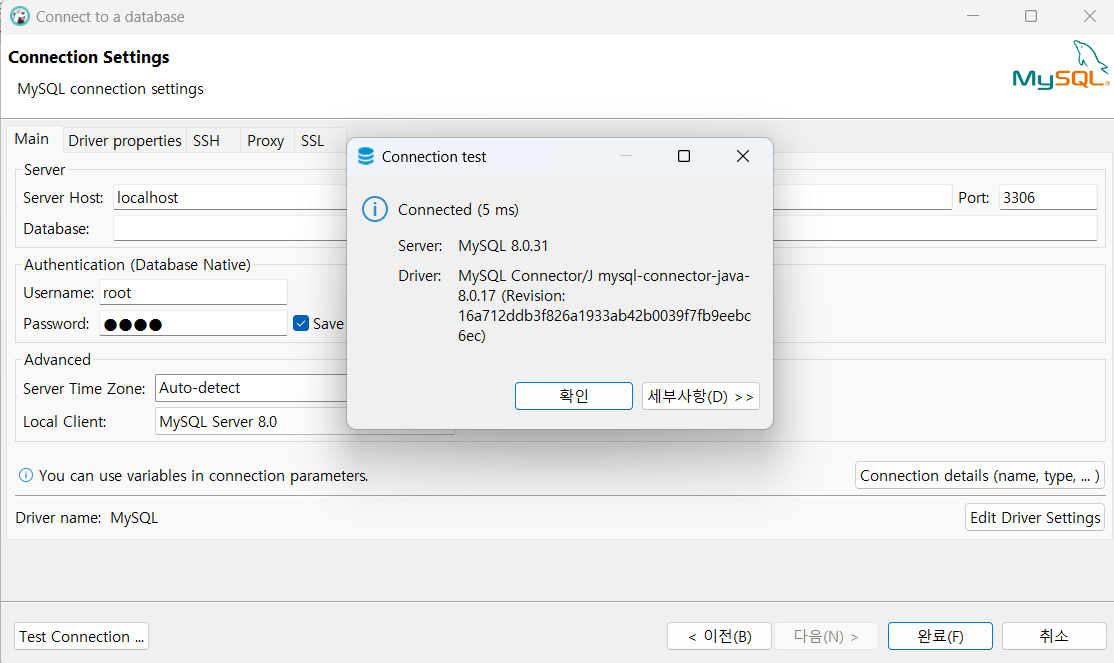
dbeaver를 열어 새 데이터베이스 연결 -> mysql -> settings부분에서 username과 password 입력 -> test connection 클릭 -> 하단 이미지처럼 완성됐다면 완료버튼 클릭
-
2. script창을 새로 만들어 `select * from mysql.user;` 입력하고 mysql에 입력된 user리스트들을 한눈에 보여준다.
3. 외부에서 접속할 수 있도록 계정을 먼저 설정해준다.
`create user '[사용자명]'@'%' identified by '[비밀번호]';`
- `@'localhost'` : 로컬에서만 접근 가능
- `@'%'` : 어떤 client에서든 접근 가능
- `@'[특정 IP]` : 특정 IP에서만 접근 가능
- `223.101.%` : `223.101.X.X` 대역의 IP에서 접근 가능
- `223.101.13.21` : `223.101.13.21` IP에서만 접근 가능
4. 해당 계정에 권한 부여
`grant all privileges on [DB].[Table] to '사용자명'@'%';`
**대상 객체**
- 모든 DB와 Table을 대상으로 할 경우 `*.*` 입력
- `test` DB의 모든 Table을 대상으로 할 경우 : `test.*`
- `test` DB의 `abc` Table을 대상으로 할 경우 : `test.abc`
**DML 권한**
- 모든 DML 권한을 주기 위해서는 `all` 입력
- `select` 권한만 줄 경우
`grant select privileges ~`
- `select`, `insert`, `update` 권한을 줄 경우
`grant select, insert, update privileges ~`
5. 변경된 내용 반영
`flush privileges`
6. 다시 user리스트를 조회하는 명령어를 사용 및 cmd로 mysql에 새로운 계정 접속 확인4. MYSQL과 Airflow 연결 < test과정>
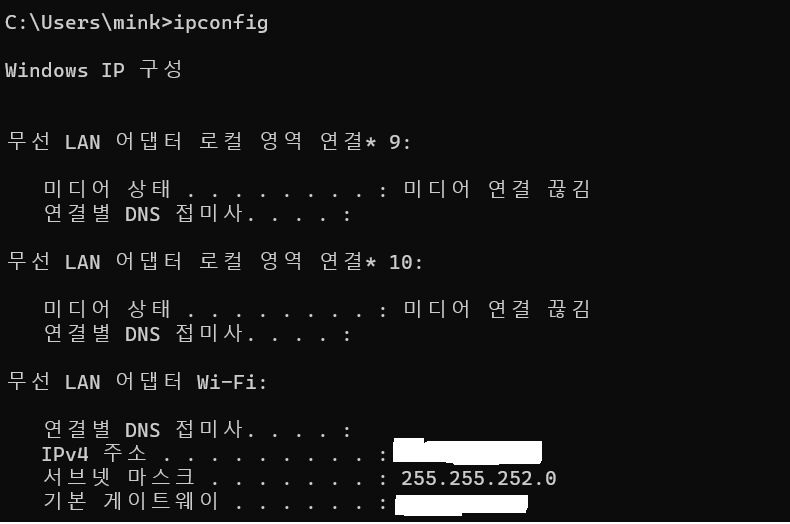
aiirflow와 연결하려면 Mysql local에서 사용하고 있는 Ip를 알아야함.
- 새 cmd창에서 ipconfig입력 주소 확인하기.
- localhost:8080(airflow)에서 Admin -> connections -> +버튼 클릭
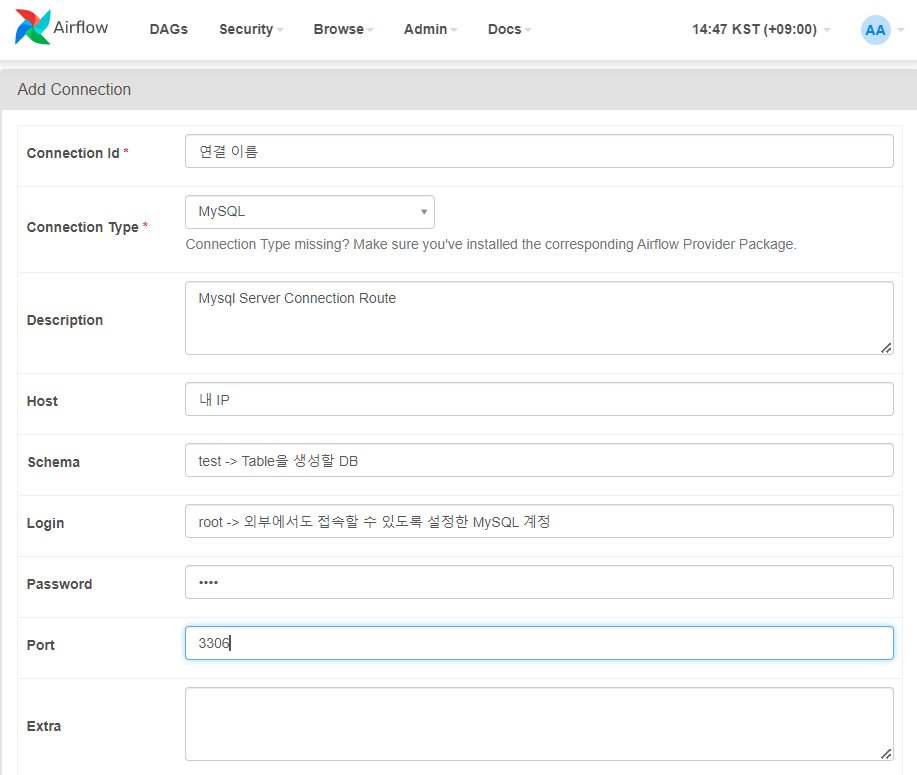
- connection에 지금까지 설정해둔 내용들 입력 후 test해보고 저장
-
DAG 작성
# import할 패키지들 기존에 제공되는 패키지는 1번이고 2번은 새로 설치해야하는 패키지들 # 1 from datetime import datetime, timedelta from email.policy import default from textwrap import dedent # 2(MysqlOperator설치) from airflow import DAG from airflow.providers.mysql.operators.mysql import MySqlOperator # default_args은 dag를 실행할때 횟수나 빈도를 설정하는 변수 default_args = { 'depends_on_past': False, 'retires': 1, 'retry_delay': timedelta(minutes=5) } # employees 테이블 생성구문 변수 sql_create_table = """ CREATE TABLE `employees` ( `employeeNumber` int(11) NOT NULL, `lastName` varchar(50) NOT NULL, `firstName` varchar(50) NOT NULL, `extension` varchar(10) NOT NULL, `email` varchar(100) NOT NULL, `officeCode` varchar(10) NOT NULL, `reportsTo` int(11) DEFAULT NULL, `jobTitle` varchar(50) NOT NULL, PRIMARY KEY (`employeeNumber`) ); """ # employees 테이블 데이터 추가구문 변수 sql_insert_data = """ insert into `employees`(`employeeNumber`,`lastName`,`firstName`,`extension`,`email`,`officeCode`,`reportsTo`,`jobTitle`) values (1002,'Murphy','Diane','x5800','dmurphy@classicmodelcars.com','1',NULL,'President'), (1056,'Patterson','Mary','x4611','mpatterso@classicmodelcars.com','1',1002,'VP Sales'), (1076,'Firrelli','Jeff','x9273','jfirrelli@classicmodelcars.com','1',1002,'VP Marketing'), (1088,'Patterson','William','x4871','wpatterson@classicmodelcars.com','6',1056,'Sales Manager (APAC)'), (1102,'Bondur','Gerard','x5408','gbondur@classicmodelcars.com','4',1056,'Sale Manager (EMEA)'), (1143,'Bow','Anthony','x5428','abow@classicmodelcars.com','1',1056,'Sales Manager (NA)'), (1165,'Jennings','Leslie','x3291','ljennings@classicmodelcars.com','1',1143,'Sales Rep'), (1166,'Thompson','Leslie','x4065','lthompson@classicmodelcars.com','1',1143,'Sales Rep'), (1188,'Firrelli','Julie','x2173','jfirrelli@classicmodelcars.com','2',1143,'Sales Rep'), (1216,'Patterson','Steve','x4334','spatterson@classicmodelcars.com','2',1143,'Sales Rep'), (1286,'Tseng','Foon Yue','x2248','ftseng@classicmodelcars.com','3',1143,'Sales Rep'), (1323,'Vanauf','George','x4102','gvanauf@classicmodelcars.com','3',1143,'Sales Rep'), (1337,'Bondur','Loui','x6493','lbondur@classicmodelcars.com','4',1102,'Sales Rep'), (1370,'Hernandez','Gerard','x2028','ghernande@classicmodelcars.com','4',1102,'Sales Rep'), (1401,'Castillo','Pamela','x2759','pcastillo@classicmodelcars.com','4',1102,'Sales Rep'), (1501,'Bott','Larry','x2311','lbott@classicmodelcars.com','7',1102,'Sales Rep'), (1504,'Jones','Barry','x102','bjones@classicmodelcars.com','7',1102,'Sales Rep'), (1611,'Fixter','Andy','x101','afixter@classicmodelcars.com','6',1088,'Sales Rep'), (1612,'Marsh','Peter','x102','pmarsh@classicmodelcars.com','6',1088,'Sales Rep'), (1619,'King','Tom','x103','tking@classicmodelcars.com','6',1088,'Sales Rep'), (1621,'Nishi','Mami','x101','mnishi@classicmodelcars.com','5',1056,'Sales Rep'), (1625,'Kato','Yoshimi','x102','ykato@classicmodelcars.com','5',1621,'Sales Rep'), (1702,'Gerard','Martin','x2312','mgerard@classicmodelcars.com','4',1102,'Sales Rep'); """ # DAG 설정 with DAG( 'connect_to_local_mysql', default_args = default_args, description = """ 1) create 'employees' table in local mysqld 2) insert data to 'employees' table """, schedule_interval = '@daily', start_date = datetime(2022, 1, 1), catchup = False, tags = ['mysql', 'local', 'test', 'employees'] ) as dag: t1 = MySqlOperator( task_id="create_employees_table", mysql_conn_id="mysql_local_test", sql=sql_create_table, ) t2 = MySqlOperator( task_id="insert_employees_data", mysql_conn_id="mysql_local_test", sql=sql_insert_data ) # 순서 t1 >> t2 -
DAG를 실행시켜 파일이 잘 되었는지 확인
mink@PMK-HS1HH67:~/airflow/dags$ python3 connect_to_local_mysql.py -
실행이됐다면 airflow에 들어가서 dag 실행한 후 결과가 하단처럼 나와야함<안 됐을 시 오류난 곳 확인하기.>
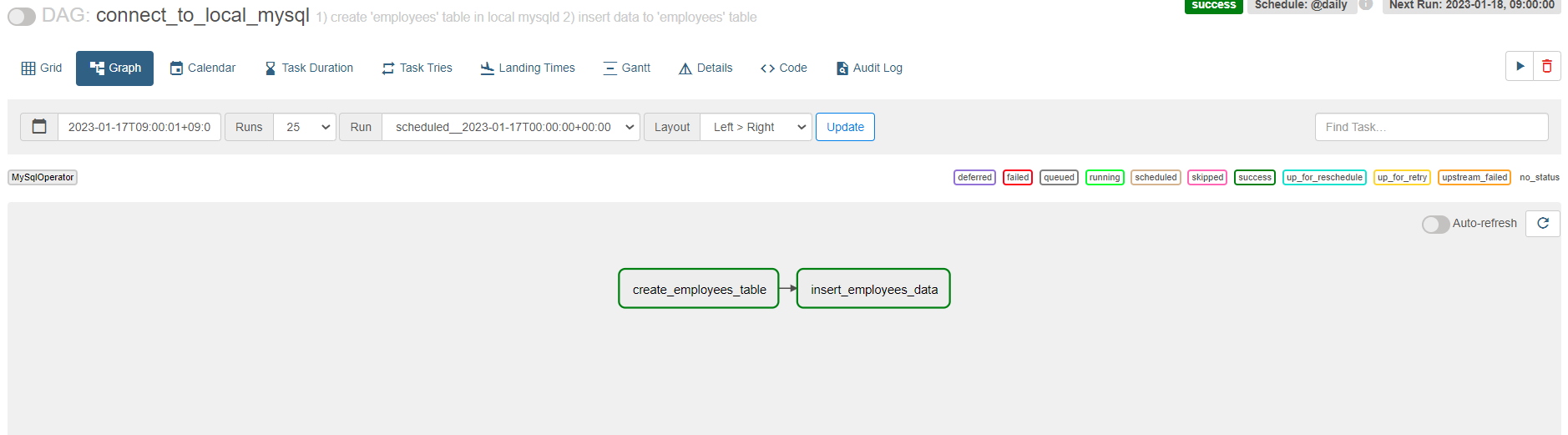
- **오류는 다음과 같은 곳에서 확인가능**
Details -> failed -> log url 확인하면 어느 부분에서 에러가 났는 지 확인 가능.

-
dbeaver로 데이터 들어갔는 지 확인
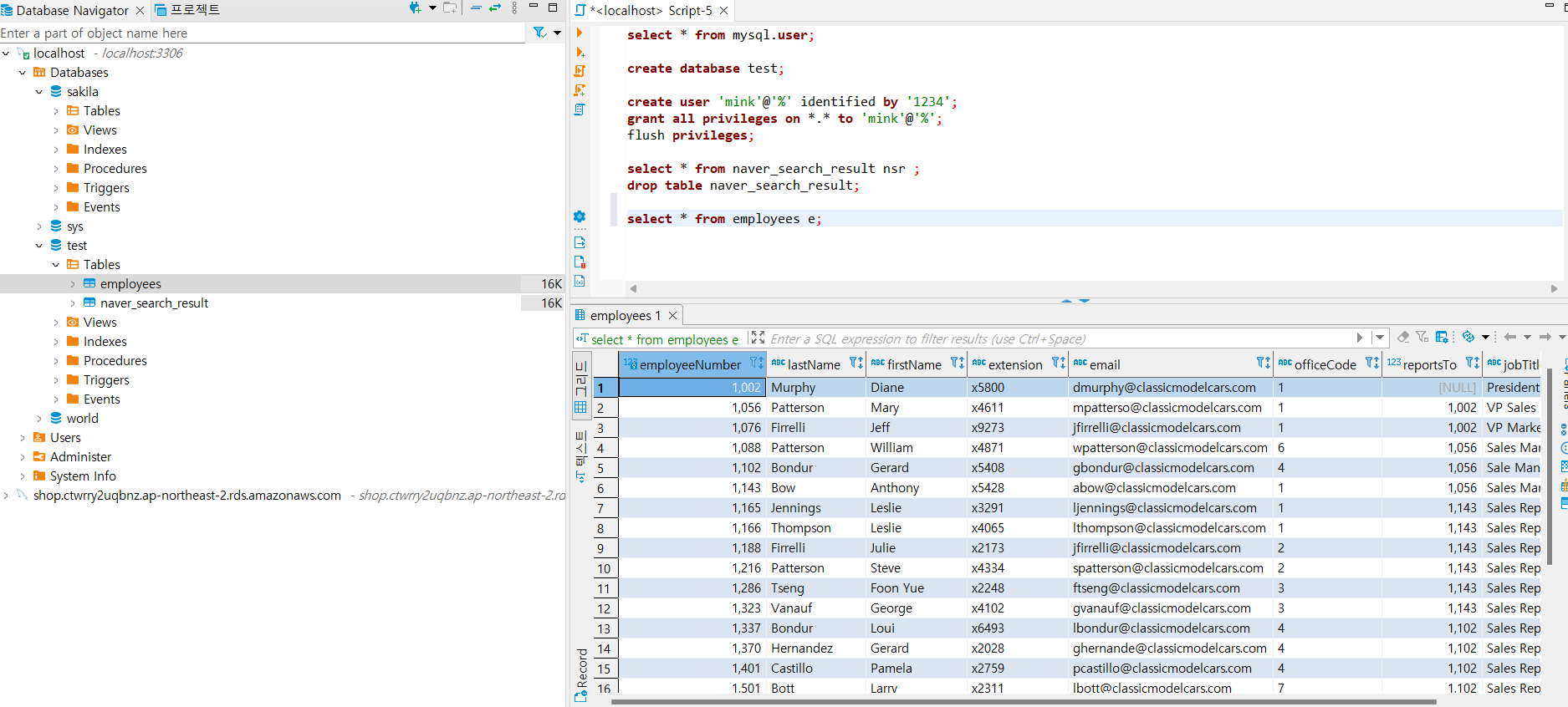
5. Naver api를 이용한 자동 크롤링 및 db 생성, 데이터 추가
-
네이버 api를 등록
-
NAVER DEVELOPERS 접속 후 로그인
-
애플리케이션 등록
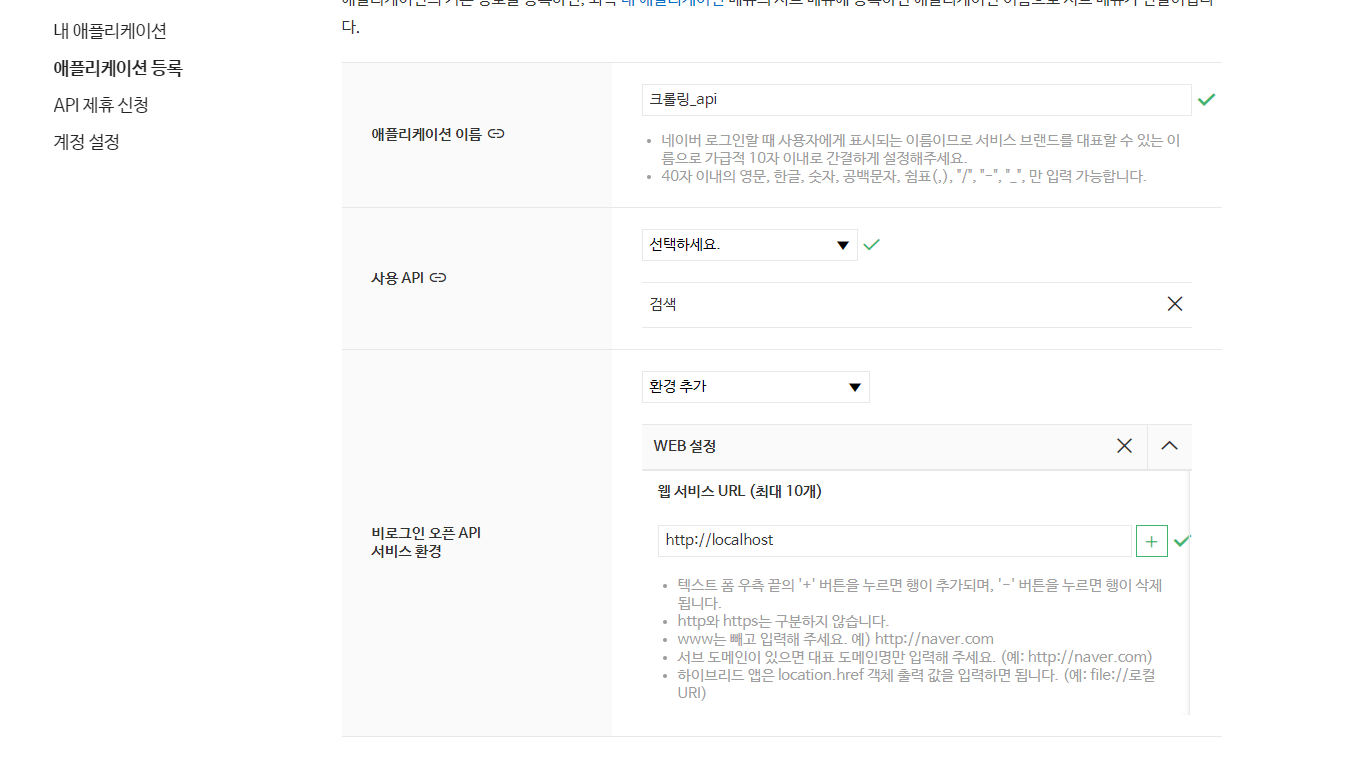
-
-
등록하게되면 Client ID, Client Secret을 발급받게 됌.
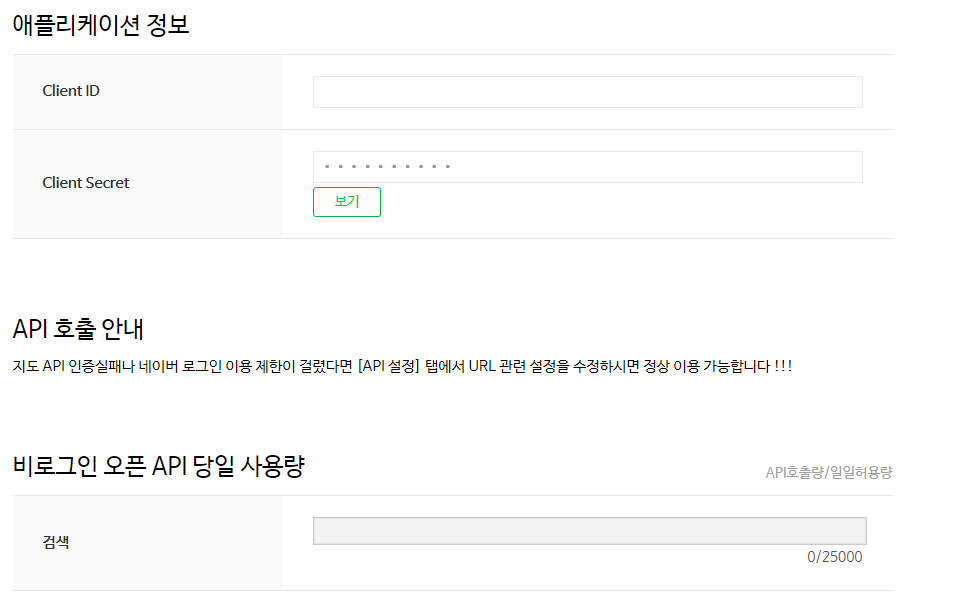
-
pipeline과 preprocessing 두 부분으로 나눠서 py로 생성
-
~/airflow/dags 폴더 안에 naver_search_pipeline.py 파일을 만든다.(vi로 하든 code로 들어가서 생성하든 상관없다.)
# 필요한 모듈 Import from datetime import datetime import json import pandas as pd from airflow import DAG from pandas import json_normalize from naver_preprocess import abc # 사용할 Operator Import from airflow.providers.http.sensors.http import HttpSensor from airflow.providers.http.operators.http import SimpleHttpOperator from airflow.operators.python import PythonOperator from airflow.operators.bash import BashOperator from airflow.providers.mysql.operators.mysql import MySqlOperator # 디폴트 설정 default_args = { "start_date": datetime(2023, 1, 1) # 2023년 1월 1일 부터 태그 시작--> # 현재는 23년 1월이므로 태그를 실행하면 무조건 한번은 돌아갈 것 } NAVER_CLI_ID = "<발급받은 번호입력>" NAVER_CLI_SECRET = "<발급받은 번호입력>" # naver_search_result 테이블 생성 쿼리 sql_create_table=""" CREATE TABLE `naver_search_result`( `title` TEXT, `address` TEXT, `category` TEXT, `description` TEXT, `link` TEXT ); """ # DAG를 설정 with DAG( dag_id="naver-search-pipeline", # 스케쥴을 매일 갱신 schedule_interval="@daily", default_args=default_args, #태그는 원하는대로 tags=["naver", "search", "local", "api", "pipeline"], # catchup을 True로 하면, start_date부터 현재까지 못돌린 날들을 채운다. catchup=False) as dag: # mysqloperator - mysql로 테이블을 생성 create_naver_table = MySqlOperator( task_id = "create_naver_table", mysql_conn_id = "mysql_local_test", sql=sql_create_table, ) # HttpSensor - 데이터 가져오는 것이 가능한지 확인하기 is_api_available = HttpSensor( task_id = "is_api_available", http_conn_id="naver_search_api", endpoint="v1/search/local.json", headers={ "X-Naver-Client-Id" : f"{NAVER_CLI_ID}", "X-Naver-Client-Secret" : f"{NAVER_CLI_SECRET}", }, request_params={ "query" : "김치찌개", "display" : 5 }, response_check=lambda response: response.json() ) # SimpleHttpOperator - 크롤링한 데이터를 json형태로 설정 crawl_naver = SimpleHttpOperator( task_id='crawl_naver', http_conn_id='naver_search_api', endpoint="v1/search/local.json", headers={ "X-Naver-Client-Id" : f"{NAVER_CLI_ID}", "X-Naver-Client-Secret" : f"{NAVER_CLI_SECRET}", }, data={ "query":"김치찌개", "display" : 5 }, method="GET", response_filter=lambda res : json.loads(res.text), log_response=True ) # PythonOperator - 크롤링된 가공되지않은 데이터 전처리 preprocess_result = PythonOperator( task_id="preprocess_result", python_callable=abc) def _success(): print("네이버 검색 DAG 완료") # 대그 완료 출력 print_complete = PythonOperator( task_id="print_complete", python_callable=_success ) # 파이프라인 구성하기 create_naver_table >> is_api_available >> crawl_naver >> preprocess_result >> print_complete -
~/airflow/dags 폴더 안에 naver_preprocess.py 파일을 만든다.(vi로 하든 code로 들어가서 생성하든 상관없다.)
from pandas import json_normalize from airflow.operators.python import PythonOperator import pandas as pd import sqlalchemy from airflow import DAG __all__ = ["abc"] def abc(ti): # ti(task instance) - dag 내의 task의 정보를 얻어 낼 수 있는 객체 # xcom(cross communication) - Operator와 Operator 사이에 데이터를 전달 할 수 있게끔 하는 도구 naver_search = ti.xcom_pull(task_ids=["crawl_naver"]) # xcom을 이용해 가지고 온 결과가 없는 경우 if not len(naver_search): raise ValueError("검색 결과 없음") # for i in naver_search: naver_data = i['items'] <- 이 방식으로 해도 dictionary형태인 item들을 # 제대로된 배치로 저장함. items = naver_search[0]['items'] processed_items = pd.json_normalize([ {"title": i["title"], "address" : i["address"], "category": i["category"], "description": i["description"], "link": i["link"]} for i in items ]) # db info user_name = 'mysql외부계정' pass_my = '비밀번호' host_my = 'airflow connection에 사용된 포트(ex.172.16.0.1:3306)' db_name = '데이터베이스 이름' # to_sql, mysql connector connection= sqlalchemy.create_engine(f"mysql+mysqlconnector://{user_name}:{pass_my}@{host_my}/{db_name}") table_name = 'naver_search_result' processed_items.to_sql(name = table_name ,con = connection ,index = False ,if_exists = 'append') -
결과가 이렇게 나와야함
-
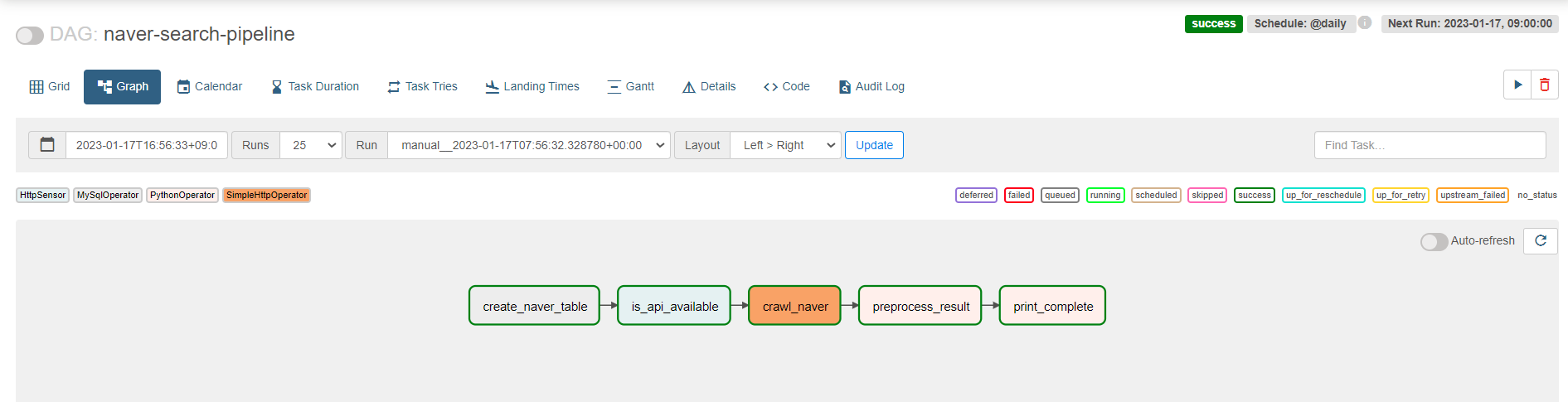
- 에러 모음집
# 모듈이 제대로 설치가 안 되서 해당 에러 발생
# setup 도구들을 업그레이드
$ pip install --upgrade setuptools
# mysql설치 시 필요한 의존성 라이브러리들을 다시 설치
$ sudo apt-get install python3-dev default-libmysqlclient-dev build-essential
# Debian / Ubuntu
