🎓 CartPole 실험 개요
본 실험은 OpenAI Gym의 CartPole-v1 환경에서 DQN(Deep Q-Network)을 적용하여 강화 학습을 진행한 실험이다.
이전 실험에서는 Q-learning을 기반으로 한 학습 방법을 적용하였으며, 행동 선택 방식(Exploration Strategy)으로 Epsilon-Greedy와 Softmax를 비교하였다. 그 결과, Epsilon-Greedy 방식이 더 효과적인 학습 성능을 보였다. 따라서 이번 실험에서는 추가적인 행동 선택 방식 실험 없이 Epsilon-Greedy 탐색법을 적용하여 DQN 학습을 진행하였다.
본 글에서는 실험 과정과 결과 분석에 집중하며, 구체적인 코드 구현보다는 실험의 핵심 개념 및 구조를 설명하는 데 초점을 맞춘다.
🎓 CartPole 환경 정보 및 설명 (DQN 적용)
CartPole 환경은 강화 학습 실험에서 고전 제어(Classic Control) 문제로 널리 사용되며, DQN(Deep Q-Network)을 활용한 학습 실험에 적합한 구조를 가지고 있다. 이 환경에서는 수레(Cart) 위에 막대(Pole)를 세운 상태에서 균형을 유지하는 것이 목표이다.
🛠 실습 환경
사용한 환경 : Anaconda, PyCharm
강화 학습 환경 : OpenAI Gym
파이썬 버전 : 3.8
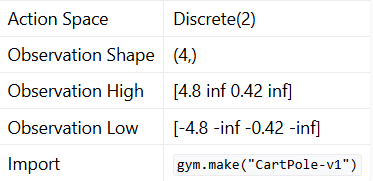
Action Space (이산적 행동 공간)
CartPole은 이산적인 행동 공간(Discrete Action Space)을 가진다.
- Discrete(2): 두 개의 행동(0 또는 1)만 선택 가능
가능한 행동:- 0: 수레(Cart)를 왼쪽으로 이동
- 1: 수레(Cart)를 오른쪽으로 이동
DQN은 연속적인 상태 공간(Continuous State Space)을 처리할 수 있는 신경망 모델을 사용하기 때문에, 기존 Q-learning처럼 상태를 이산화(Discretization)할 필요 없이 그대로 네트워크의 입력으로 활용할 수 있다.
Observation Space (연속적인 상태 공간)
CartPole 환경의 관측 공간(Observation Space)은 연속적인 상태 변수로 이루어져 있으며, 신경망을 통해 직접 학습할 수 있다.
- 상태 벡터는 4차원 연속값 벡터 형태로 제공됨
- 각 상태(State)는 다음과 같은 요소를 포함
1. Cart Position (수레의 위치)
2. Cart Velocity (수레의 속도)
3. Pole Angle (막대의 각도)
4. Pole Angular Velocity (막대의 각속도)
- 상태 변수 값의 범위는 다음과 같다.
- 최댓값(Observation High): [4.8, ∞, 0.42, ∞]
- 최솟값(Observation Low): [-4.8, -∞, -0.42, -∞]
DQN에서는 연속적인 상태를 직접 입력으로 받아 신경망을 통해 Q값을 예측한다. 따라서 Q-learning에서 필요했던 이산화(Discretization) 과정이 불필요하며, 보다 정밀한 학습이 가능하다.
DQN과 CartPole의 특징
-
이전 실험(Q-learning)과의 차이점
- Q-learning에서는 이산화된 Q-table을 사용 → DQN은 신경망을 이용하여 Q값을 근사
- 연속적인 상태 공간을 그대로 학습 가능 → Q-table이 필요 없음
-
DQN을 활용한 장점
- 연속적인 상태 변수를 그대로 입력할 수 있어 더 세밀한 학습 가능
- 경험 재현(Replay Buffer)과 타겟 네트워크(Target Network)를 활용하여 더 안정적인 학습 가능
- Q-learning보다 더 높은 성능과 확장성 제공
🎓 강화 학습 알고리즘 적용 (DQN)
본 실험에서는 DQN(Deep Q-Network) 알고리즘을 적용하여 CartPole 환경에서 학습을 진행하였다. 기존의 Q-learning과 달리, DQN은 신경망(Neural Network)을 활용하여 Q값을 근사하며, 이를 통해 연속적인 상태 공간을 직접 처리할 수 있다.
| 비교 항목 | Q-learning | DQN |
|---|---|---|
| 상태 공간 | 이산화(Discretization) 필요 | 연속적인 상태를 그대로 사용 |
| Q-값 저장 방식 | Q-table 사용 (메모리 제한 존재) | 신경망을 통해 Q값 근사 |
| 일반화 능력 | 낮음 (본 적 없는 상태를 처리하기 어려움) | 높음 (비슷한 상태에서도 유사한 행동을 예측 가능) |
| 경험 재현 (Replay Buffer) | X (단일 경험 기반 학습) | O (과거 경험을 활용하여 학습 안정화) |
| 타겟 네트워크 (Target Network) | X | O (Q값의 급격한 변화 방지, 학습 안정성 증가) |
DQN 학습 과정
본 벨로그에서는 소스코드를 제공하지는 않지만 실험에 진행한 코드 구성도는 다음과 같다.
1️⃣ 환경 초기화 (env.reset())
CartPole 환경을 초기화하고, 초기 상태를 가져온다.
환경에서 반환된 연속적인 상태 벡터(위치, 속도, 각도, 각속도)를 학습에 활용한다.
2️⃣ 신경망을 통한 Q값 예측
현재 상태를 신경망(Policy Network)에 입력하여 각 행동(0 또는 1)에 대한 Q값을 예측한다.
- 신경망의 입력(Input):
- 연속적인 상태 벡터 (Cart 위치, 속도, 막대 각도, 각속도)
- 신경망의 출력(Output):
- 각 행동에 대한 Q값 [Q(s, 0), Q(s, 1)]
3️⃣ 탐색(Exploration)과 활용(Exploitation) 선택
- Epsilon-Greedy 탐색법을 적용하여 무작위 행동(탐색)과 최적 행동(활용) 중 하나를 선택한다.
- 탐색률(ε, Exploration Rate)은 점진적으로 감소하여 학습 초반에는 탐색을 많이 수행하고, 후반에는 최적 정책(10%)을 설정하여 최소 10% 확률로 탐색을 하도록 하였다.
4️⃣ 환경 상호작용 (env.step(action))
선택한 행동을 환경에 적용하고, 다음 상태, 보상, 종료 여부를 확인한다.
- 보상 시스템:
- 매 타임스텝마다 +1 보상 부여
- 막대가 쓰러지지 않는 동안 보상이 지속적으로 증가
- 막대가 빨리 쓰러질 경우 패널티를 부여
reward = min(-(200 - cnt), -100)
5️⃣ 경험 저장 (Replay Buffer 활용)
- (현재 상태, 행동, 보상, 다음 상태, 종료 여부) 정보를 Replay Buffer[50000]에 저장한다.
- 일정 크기 이상 저장되면, 미니배치를 샘플링하여 학습을 진행한다.
6️⃣ Q값 업데이트 (DQN 손실 함수 적용)
손실 함수로 Huber Loss (Smooth L1 Loss)를 적용하여 Q값을 안정적으로 업데이트한다. Playing Atari with Deep Reinforcement Learning, 2015에도 Huber Loss를 사용하여 적용해보았다.
-
DQN의 업데이트 공식 :
-
타겟 네트워크(Target Network)를 활용하여 Q값의 급격한 변화를 방지하고 학습 안정성을 확보한다.
7️⃣ 타겟 네트워크 업데이트
- 일정 에피소드마다 타겟 네트워크의 가중치를 업데이트하여 학습 안정성을 증가시킨다.
8️⃣ 종료 조건 충족 시 에피소드 종료
막대가 기울어지거나 수레가 범위를 벗어나면 에피소드 종료
- 목표: 에이전트가 600 스텝 이상 유지하도록 학습
🎓 DQN 학습 결론
결과적으로 DQN을 활용한 학습이 원활하게 진행되었다. 하지만 생각보다 초반에 성능이 좋지 않게 나왔지만 학습 시간을 늘려 CartPole 환경의 목표를 성공적으로 달성할 수 있었다.
그중에서도 Epsilon-Greedy 방식이 학습 속도와 최종 성능 측면에서 우수한 결과를 보였다.
반면, ε-탐색을 사용하지 않고 신경망 기반으로 행동을 선택하는 방법(Dueling DQN, Double DQN 등)을 추가 실험할 필요가 있다. 현재의 방식은 학습이 진행되면서도 일정 확률로 탐색을 유지하지만, 보다 정교한 방식이 추가된다면 학습 효율이 더 향상될 가능성이 크다.
또한, 타겟 네트워크를 활용한 업데이트가 학습 안정성을 증가시키는 데 효과적이었으며, Huber Loss를 적용함으로써 Q값의 급격한 변화가 줄어들고 학습 과정이 더욱 부드러워지도록 하였다.
반대로, Replay Buffer의 메모리값이 낮을 경우 학습이 불안정해지는 경향을 보였다. Replay Buffer를 활용하여 과거 경험을 재사용함으로써 Q값을 더 많이 학습할 수 있었으며, 이는 학습 성능 향상에 기여한 요소 중 하나였다.
이러한 특성 덕분에 DQN을 기반으로 한 Epsilon-Greedy 방식이 보다 유연한 학습을 가능하게 하였으며, 최적의 정책을 찾는 데 있어 효과적인 결과를 보였다.
하지만 너무 과도한 학습(episode 50000)으로 인해 오버피팅 경향이 나타났다.
결과적으로 목표는 달성했으니 만족...
밑에 영상은 렉이 아니고 진짜 저렇게 학습됨...

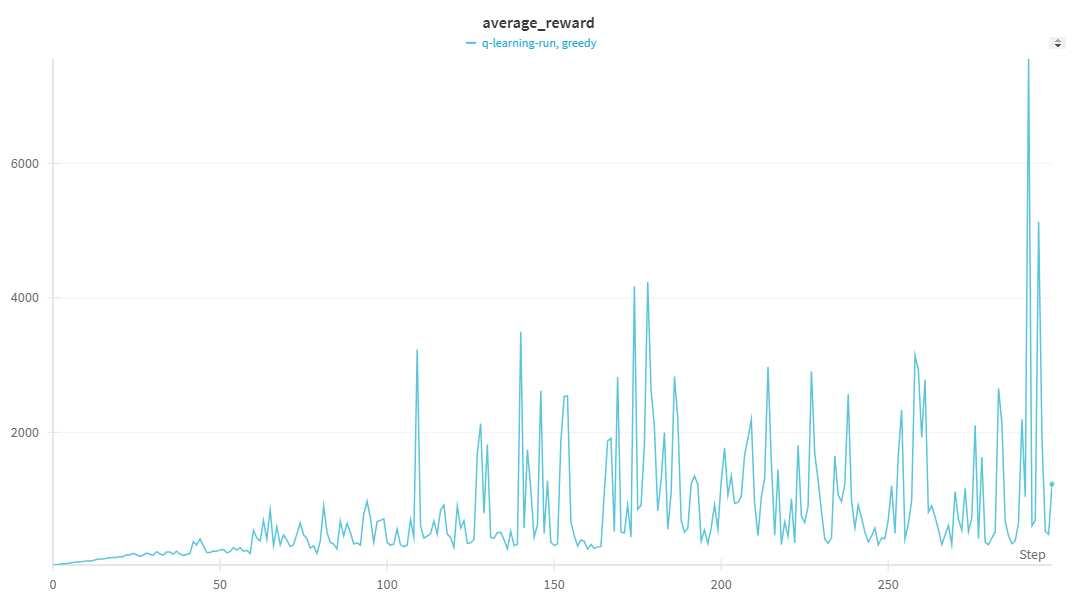
초반 학습(episode 10000): Q-learning이 더 빠르게 학습 진행
이전 Q-learning과 DQN을 적용하여 CartPole 환경에서 학습 성능을 비교하였다.
실험 결과, 초기 학습 구간에서는 Q-learning이 DQN보다 더 빠르게 보상을 증가시키는 경향을 보였다.
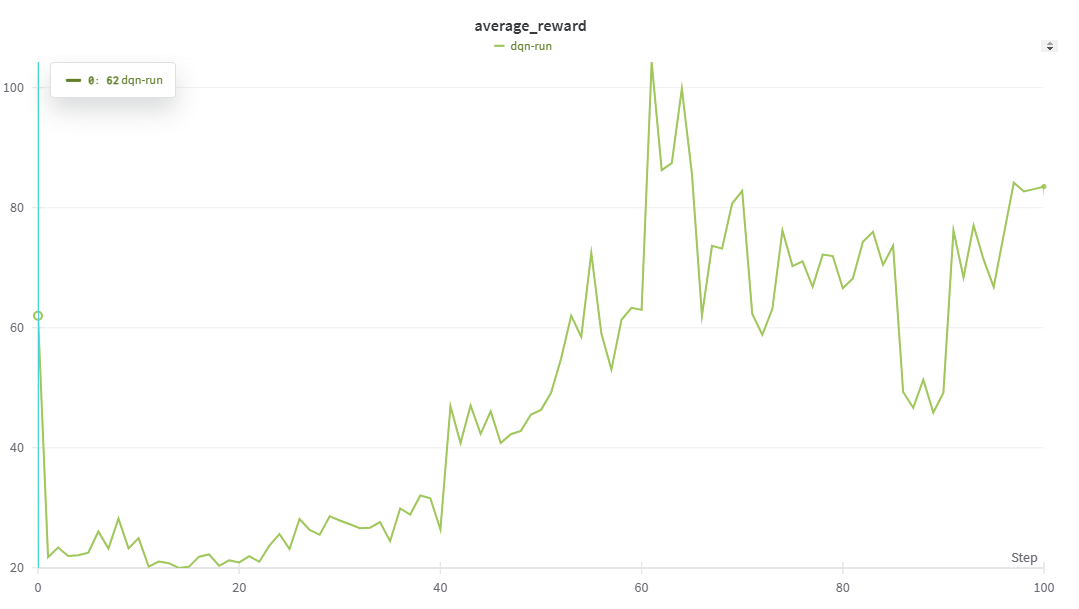
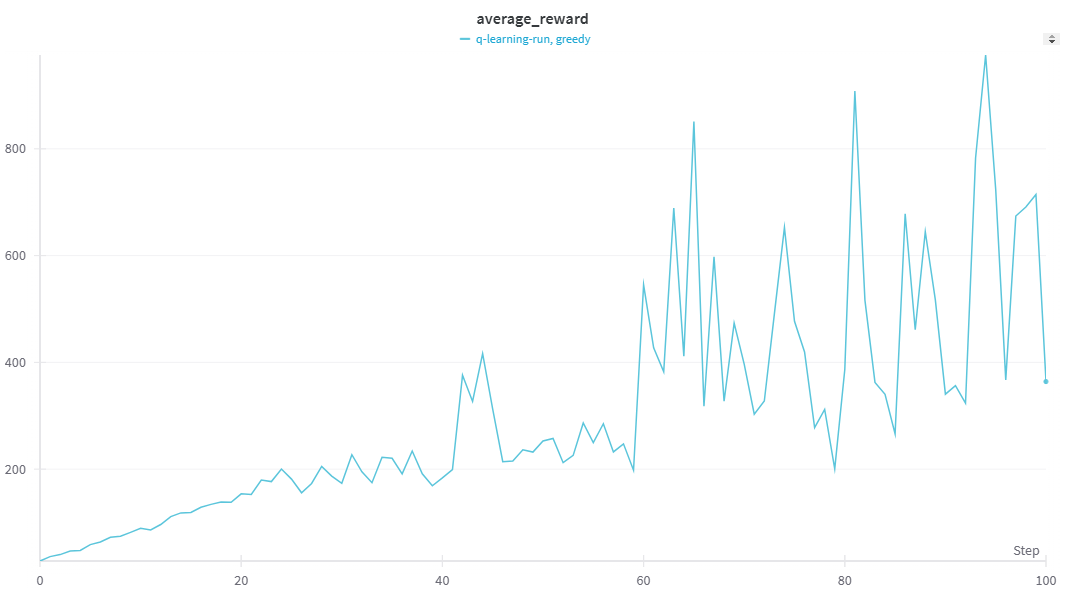
후반 학습(episode 20000~): DQN이 압도적인 성능 향상
일정 에피소드 이후, DQN이 급격하게 높은 보상을 얻으며 Q-learning을 압도하는 성능을 기록하였다.
특히 DQN은 특정 시점에서 30만 이상의 보상을 기록하였으며, 이후 평균적으로 1만 이상의 보상을 지속적으로 유지하였다.
그래프에서도 DQN의 급격한 보상 상승으로 인해 일부 값이 잘 보이지 않을 정도로 학습 성능이 급증하는 모습을 확인할 수 있었다.
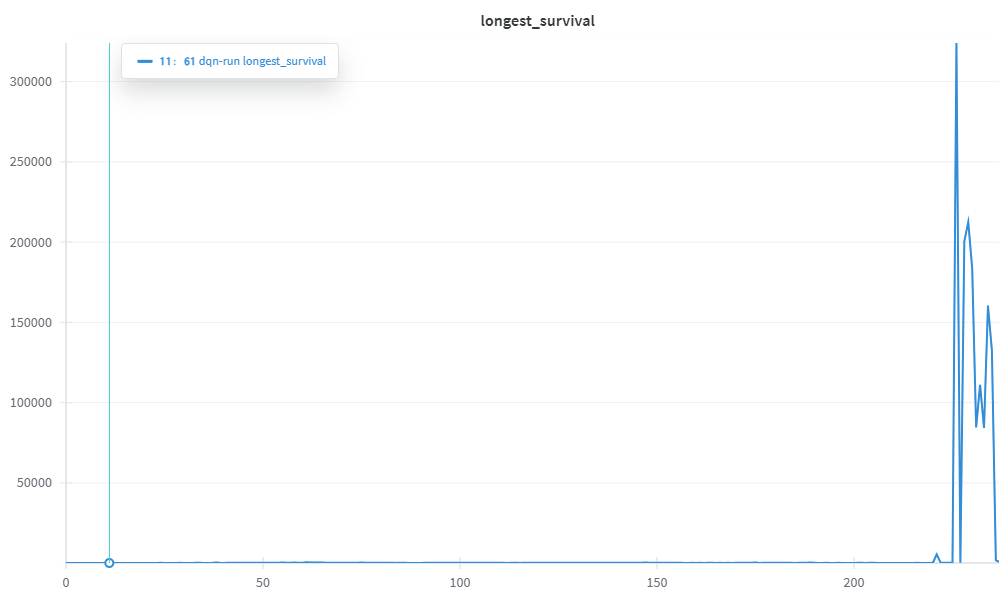
🎓 향후 연구 계획
이번 실험을 통해 DQN이 장기적으로 Q-learning보다 뛰어난 성능을 보이며, 일정 기점 이후 폭발적인 학습 성능을 기록하는 것을 확인할 수 있었다. 그러나 몇 가지 한계점이 존재하므로, 이를 개선하기 위한 추가 연구가 필요하다.
🛠 Double DQN 적용
✅ Q값 과추정(Overestimation) 문제 해결
- DQN은 학습 과정에서 Q값이 과대평가되는 경향이 있음
- Double DQN을 적용하면, 액션 선택과 Q값 평가를 분리하여 Q값의 과대평가 문제를 완화할 수 있음
✅ Q-learning보다 안정적인 학습 가능
- Double DQN을 적용하면, Q-learning의 단점(불안정한 업데이트)이 줄어들어 학습이 더욱 안정적이 될 것으로 예상됨
