
이진 분류 :: Binary Classification
- 이진 분류(Binary Classification)는 구분하고자 하는 결과 값이 2가지 인 경우를 말한다.
- 입력 : 이미지
- 출력 : 고양이다, 고양이가 아니다

- Color 이미지는 3채널 R, G, B 각각의 Layer 에 대한 데이터가 들어있다.
- 입력 데이터 는 개의 픽셀로 Color 이미지 전체를 구성 (각 픽셀은 ~ 의 특정 값 가짐)
- 이 12288 개의 데이터를 가진 를 다음과 같이 열 벡터로 변환해야 컴퓨터가 받아들일 수 있다.
- 입력 가 어떤 DNN 알고리즘을 거쳐 라는 출력이 나오는데 Binary Classification 이 를 과 로 표현한다.
- Notation
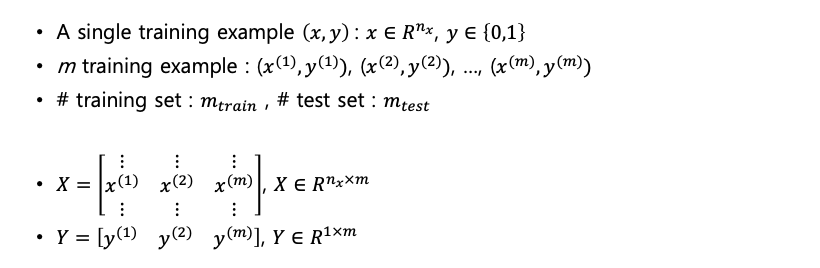
- single training example
supervised Learning 에서는 인풋 X 와 그에 상응하는 아웃풋 y의 여러가지 예시를 학습하는것이다.
(A,B,C 는 고양이로 라벨링, D,E,F 는 개로 라벨링되어있는 예시를 학습) - m training example : 학습에 사용될 (x,y) 쌍이 m 개
- : m 개의 train data, : m 개의 test data
- 각각 m 쌍의 x, y를 따로 행렬로 표현(행렬을 항상 대문자로 표기)
- 행렬 X : x 의 집합으로 n 차원의 열벡터를 m 개 만큼 늘어놓은 (n,m)
- 행렬 Y : y 의 집합으로, 0 또는 1의 표현을 늘어놓는다면 (1,m)
로지스틱 회귀 :: Logistic Regression

-
이진분류에 사용할 수 있는 학습 알고리즘이 바로 로지스틱 회귀
-
가 주어지면, 그 에 대한 예측값 즉, 출력값
- 가 n 차원 열벡터일 떄 다음 두 파라미터 사용
- 와 마찬가지로 w 는 n 차원 열벡터
- 는 실수
-
출력값은 다음과 같이 표현
- (선형회귀)
- 이와같은 1차 선형 함수로 표현된다면 이는 의 값에 따라서 ~ 사이를 벗어나는 값을 가지게 될 수가 있다.
- 따라서 이 or 로 표현되도록 시그모이드 함수 사용
: 차원 열벡터인 와 의 각 행의 값을 (element wise) 하게 곱한 것.
(각 행렬의 원소끼리만 곱 -> 과 의 행렬을 곱해 을 만든다.)
- 이 결과 또한 차원 열벡터가 된다.
즉, + + ... + 와 같은 모든 합을 구해야 하므로
- :
시그모이드 함수를 에 대한 함수로 본다면, z 가 크다면 1에 가까운 값, 음으로 작다면 0에 가까운 값을 나타내게 되어 1과 0으로 표현 가능 하기 떄문에
Binary Classification 의 아웃풋을 나타낼 수 있는 이른바 Activation function(활성 함수)이다.
로지스틱 회귀의 Cost function
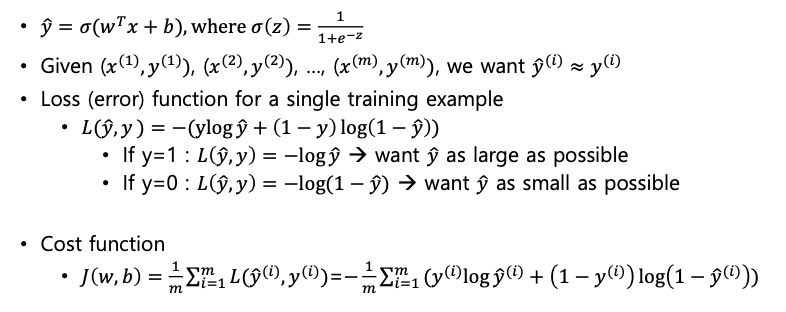
- 일떄,
- 딥러닝이란 알고리즘이 에측한 값 과 정답 의 차이, 즉 가 적도록 , 와 같은 파라미터를 학습하는것이다.
즉, 함수 정의가 필요하다.
로그 함수를 이용한 Convex 한 Loss 함수 구현
손실함수 =
- 해석
- 1) 일떄 = - : loss 가 최소(0)에 가까워지도록 은 0에 수렴한다 이 작아져야한다.
- 2) 일떄 = - : loss 가 최소(0)에 가까워지도록 은 1에 수렴한다. 이 커져야한다.
- 다음과 같이 오목한 함수를 구현할 수 있고 를 찾아가는 알고리즘이 더 빠르게 작동.
Cost 함수는 Loss 의 평균이다
- logistic regression 의 cost function 은 cross entropy 을 모두 더한것이다.
- 하나의 입력에 대한 오차를 계산하는 함수를 손실함수(Loss function), 모든 입력에 대한 오차를 계산하는 함수는 비용함수(Cost function)
- 따라서 비용함수는 모든 입력에 대해 계산한 손실함수의 평균 값으로 구할 수 있다.
- Loss 함수 하나하나가 1, 2, ..., m 번쨰 training set 마다 계산되는데 이들의 총합의 평균을 의미
- (i) 는 i번째 data set 을 의미
비용함수 :
- liklihood function 을 최대화 하므로써 추정
- 우리가 구하고 싶은 값이 인데, 우리의 모델에서 예측한 들이 일어날 확률을 maximize 하는 방향으로 정하기
일떄
엔트로피
-
청취자에게 날씨 정보를 보내기 위해서 최소 몇 비트가 요구되는가?
-
만약 날씨 상태의 개수가 8개라면, 몇 비트가 필요한가?
- , 즉 날씨 하나를 구별 하기 위해서 3번 질문하면 된다.
- 질문개수 가능한 결과의 수
- 가능한 결과의 수 = 그 사건 발생확률의 역수 ( 의 역수 )
엔트로피 사건 발생확률 질문개수
= 사건 발생확률
=
=
- 필요한 비트(엔트로피)
- (확률 ) (질문개수) (각각의 날씨) bit
- 날씨의 상태가 같은 확률을 가져 모두 확률을 가진다면
- 모두 동일한 확률

-
사건 발생확률
- 해가 뜬다는 메세지는 bits
- 비가 온다는 메세지는 bits
- 평균적으로 bits

-
엔트로피
-
평균 정보량을 측정
-
기계 Y 가 불확실성이 더 작다(모든 사건이 같은 확률로 일어나는 것이 가장 불확실) 이를 식으로 정리하여 샤넌은 이 불확실성의 측정을 "Entropy" 라고 불렀으며 이를 H 로 표시하고 단위는 bit 로 하였다.
-
불확실하면 불확실할수록 우리가 사용하는 정보량, 비트수는 즉 엔트로피는 높아진다.
-
즉 엔트로피란 최적의 전략하에서 그 사건을 예측하는데 필요한 질문의 개수를 의미한다 다른 표현으로는 최적의 전략 하에서 필요한 질문의 개수에 대한 기댓값이다. 따라서 이 엔트로피가 감소한다는것은 우리가 그 사건을 맞히기 위해서 필요한 질문의 개수가 줄어드는 것을 의미한다. 질문의 개수가 줄어는다는 사실은 정보량도 줄어든다는 사실.
-
-
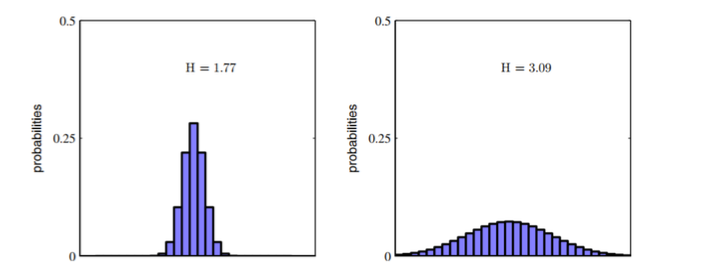
극단적인 경우를 생각해보자
- 적은 값들을 중심으로 급격하게 정점을 이루는 분포 들은 상대적으로 낮은 엔트로피를 가질것이고
- 반면, 많은 값들에 더 고르게 분포된 분포들은 더 높은 엔트로피를 가질것이다.
-
연속된 변수에 걸쳐 정의된 밀도에 대해 벡터 x로 집합적으로 나타낸다면, 미분 엔트로피는 다음과 같이 주어진다.
크로스 엔트로피
-
예) 우리가 날씨에 대해서 (8개의 날씨 상태가 모두 같은 확률로 일어날 떄)의 메세지를 사용한다고 가정하자
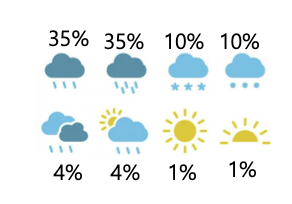
-
불행하게도, 각 날씨 상태의 확률은 균등하지 않다.
-
엔트로피 ... bits
-
날씨 상태를 3 bit 메시지로 보낼 필요가 없다는 뜻이다.
-
만약 우리가 이 경우에 다른 코드를 사용한다면, 우리가 필요로 하는 비트는 다음과 같이 계산된다.
- 사용중인 코드가 크로스 엔트로피를 줄이기 위해 확률 분포에 대한 올바른 가정을 해야한다는 것을 의미한다.
-
즉 크로스 엔트로피란?
- 확률분포로 된 어떤 문제 (확률이 균등하지 않은 경우) 에 대해, 확률분포로 된 어떤 전략 (모든 사건이 같은 확률로 일어나는 경우)를 사용할 떄의 질문 개수의 기댓값.
-
는 특정 확률에 대한 목표 확률, 는 우리가 학습한 확률값
-
즉, 실제 분포 와 예측 확률 분포 가 다르면 크로스 엔트로피가 증가한다.
- 해당 문제(문제도 확률분포로 표현)에 대한 최적의 전략을 사용할 때 cross entropy 값이 최소가 된다.
- 우리가 어떤 예측 분포 를 학습하고 있는 상태라면 실제 분포 에 가까워질수록 cross entropy 값은 작아지게 됩니다.
-
크로스 엔트로피
- 만약 라면
- KL-divergence
- 하나의 확률 분포가 두 번쨰, 기대 확룰 분포와 어떻게 다른지에 대한 척도
Gradient Descent
Binary Classification 과 이를 구현하기 위한 Logistic Regression 알고리즘과 sigmoid 함수, 그리고 Loss 함수 및 Cost function 등 알아보았고, 이제 우리가 학습시켜야할 w(weight) 와 b(bias)를 어떻게 학습 시켜야 하는지 알아본다.
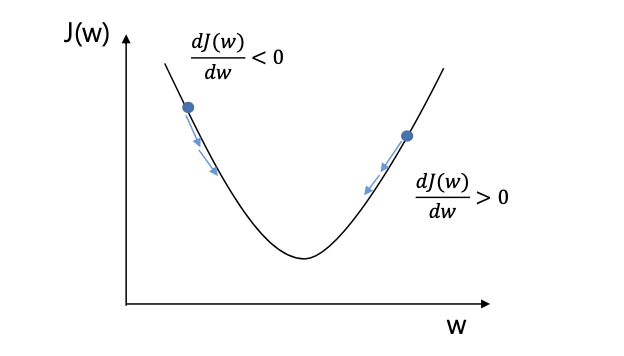
Gradient Descent 는 Cost j(w,b)가 최소가 되는 w, b의 값을 찾아가는 과정이다.
- 비용함수 는 볼록한 형태여야 한다. 볼록하지 않은 함수를 쓰게 되면, 경사하강법을 통해 최적의 파라미터를 찾을 수 없다.
- 함수의 최솟갑슬 모르기 떄문에 임의의 점을 골라서 시작한다.
- 경사하강법은 가장 가파른 방향. 즉, 함수의 기울기를 따라서(Cost 가 낮은 쪽으로 이동) 최적의 값(global optima)으로 학습의 반복 과정을 거쳐 한 스텝씩 업데이트한다.
- 학습을 통해 w, b 값도 변하고 global optima 에 도달했을 떄의 w, b 가 최종 우리가 학습을 통해 찾고자 하는 값이다.
알고리즘 (2차원 - 편미분)
- # 계속 업데이트
- # 계속 업데이트
- α 는 학습률, 얼만큼의 스텝으로 나아갈 것인가를 정한다.
- : 를 로 미분한 값 ( 에서의 함수의 기울기 정확히는 3차원 평면의 기울기)이다.
- 이 변수들이 업데이트 되는 주기를 iteration 이라고 하면, literation 은 단위로 학습이 반복됨.
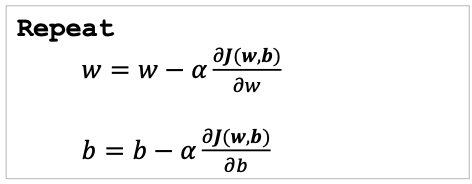
계산 그래프 에제
-
forward propagation
- 의 계산 그래프를 만드는 과정
- 입력 :
- 의 계산 그래프를 만드는 과정
-
라는 함수를 왼쪽에서 오른쪽으로 순차적 계산을 통해 아웃풋 산출.
-
컴퓨터가 인풋을 받았고 최종 아웃풋 를 계산하기 위해 3단계로 순차적 계산을 해나간다. 이것이 딥러닝에서의 Forward Propagation 이다.
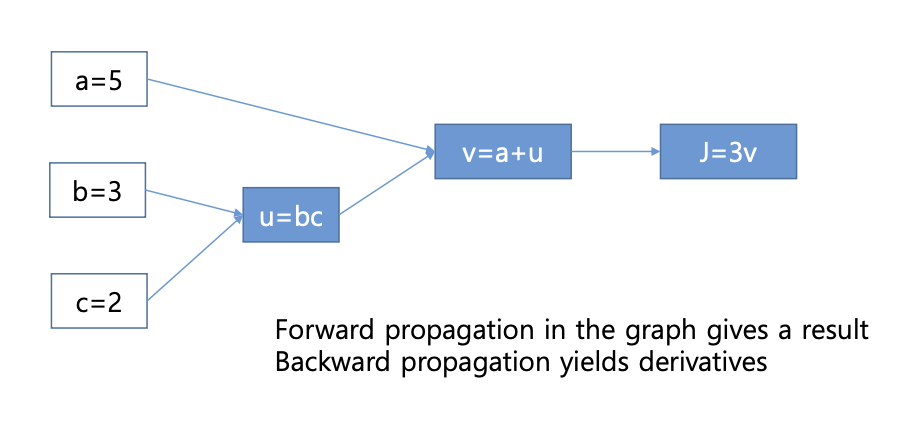
-
Backward Propagation
- backward propagation은 신경망에서의 오차를 역전파하여 각 가중치들이 오차에 미치는 영향을 계산하고, 이를 이용해 경사 하강법을 이용하여 가중치를 업데이트하는 과정을 말합니다.
- 를 에 대해서 미분하고, 를 와 에 대해서 미분하고, 를 와 에 대해서 미분을 해서 최종적으로 를 에 대해서 미분한 값을 찾아가는 과정이다.
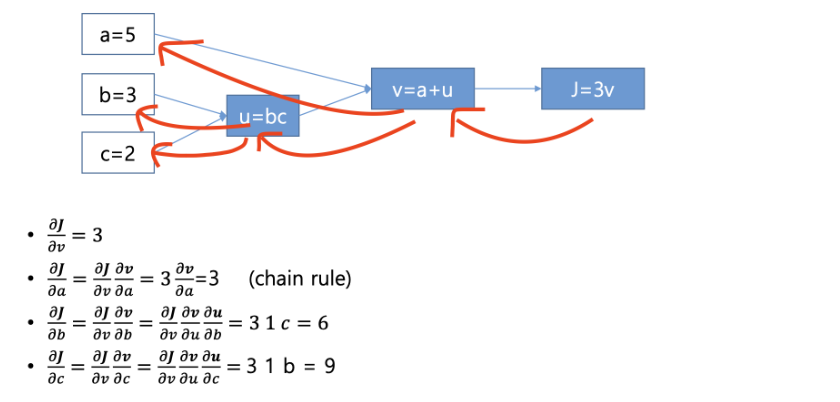
한 개의 데이터에 대한 로지스틱 회귀 및 경사하강법
-
Forward propagation 을 통해 를 구했고 로 표기
-
이제 Backward propagation 을 통해 달성하고자 하는 것이 무엇인지 생각해보자 학습의 대상이 되는 파라미터 의 최적값을 찾아 업데이트 해 나가는 것이 목적이다.
-
다시 말해 가 최저점일떄의 의 값을 말한다. 그러면 우리는 최종적으로 Gradient Descent 알고리즘을 통해 각 변수가 값에 미치는 영향(혹은 기울기)를 구해서 여기에 를 곱해준 후 이 값을 다시 에 업데이트 하면 된다.
-
Loss function
- =
-
Gradient Descent
-
우리는 결국 를 편미분과 체인룰을 이용하여 구해야 한다. 앞서 Forward propagation 에서 구한 를 대상으로 미분 한 , 를 구해야 한다. 편의상 공통 요소인 와 을 표기에서 생략하여 간단히 로 나타낸다.
-
-
값의 직접적인 변수인 미분 부터 즉, 부터 차례대로 곱해 나가야 한다.
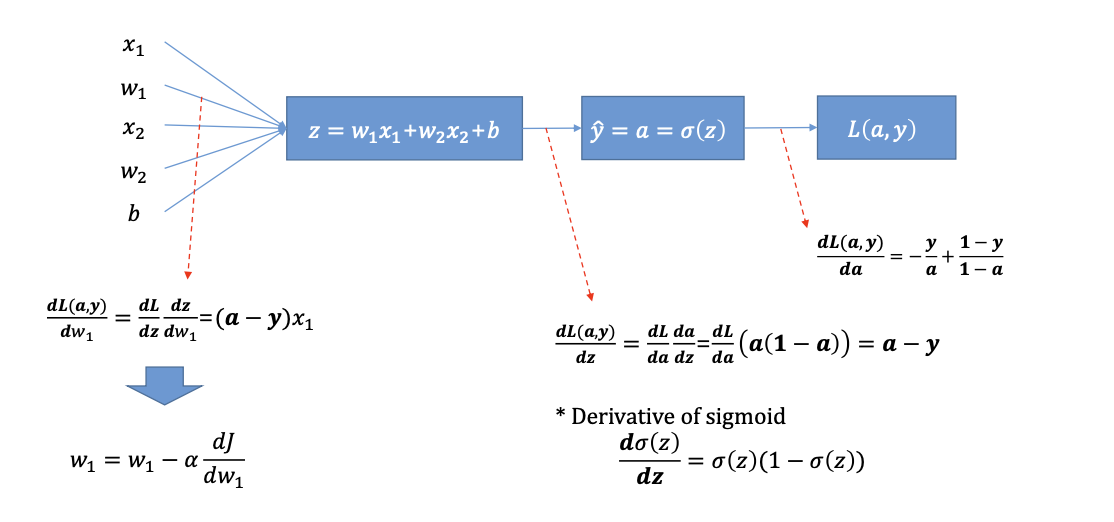
-
-
첫 번째) 를 로 미분한 값
-
두 번째) 를 로 미분
- 시그모이드의 미분값은 이다.
-
를 로 미분하여 Gradient 알고리즘에 의해 업데이트할 구하기
-
업데이트

m 개의 데이터에 대한 경사하강법
-
데이터의 개수가 개 일떄의 logistic regression 과정을 알아보자.
-
개의 데이터에 대한 Cost 함수는 다음과 같이 구한다.
-
1 번쨰 데이터에 대한 값, 2 번쨰 데이터에의 값, ..., 번쨰 데이터의 값을 모두 합하여 평균을 구하는것이다.
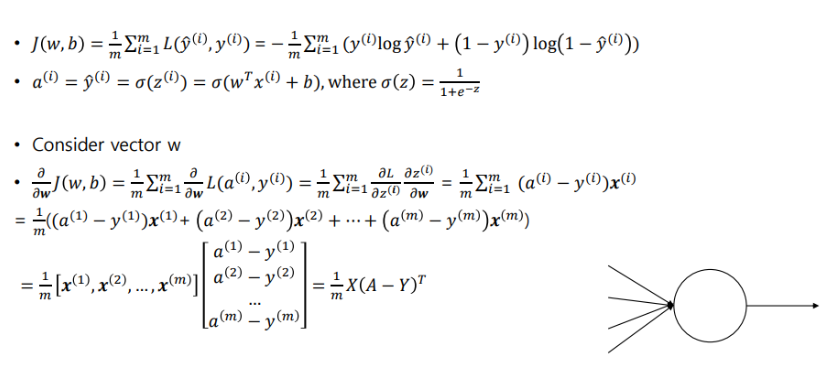
-
Cost function
-
-
미분
-
수도코드 분석

-
를 모두 으로 초기화를 시킨다.
-
for 문을 사용해 1~m 까지 반복하여 Cost 함수 구하기
-
, 그리고 활성 함수를 통하여 의 값을 구하고 Cost 함수인 J 를 구해야 한다.
-
뒤이어 Back propagation 과 Gradient Descent 실행을 위해 의 값을 구한다.
-
가 여러개 일 때, 이에 대한 반복이 이루어질 수 있다.
-
그리고 개의 데이터에 대한 것이므로, 마지막에 각각의 값을 으로 나누어 평균을 구한다.
-
마지막으로는 m 개의 데이터에 대해서 업데이트 된 dw1, dw2, db 를 Gradient Descent 알고리즘을 통해서 최종적이로 w1, w2, b를 업데이트 하게 된다.
-
벡터화
-
많은 데이터에 대한 딥러닝 알고리즘을 학습하는것은 오랜 시간이 걸린다.
벡터화는 딥러닝 알고리즘의 속도 향상의 중요한 역할을 한다. -
부터 번쨰의 데이터에 대한 반복, 그리고 가 여러개일 때 이에 대한 반복으로 인한 시간복잡도 증가
vectorization(벡터화)를 통해 for 구문 삭제
logistic regression 의 정의
벡터화 되지 않은 경우
- 가 개일때, 를 구현하려면, 와 는 각각 차원의 열벡터 이므로 내적을 위해 를 Transpose 시켜주고 곱해줘야 한다. 그리고 를 으로 초기화 시킨 뒤 for loop 을 통해 반복적으로 계산해야 한다.
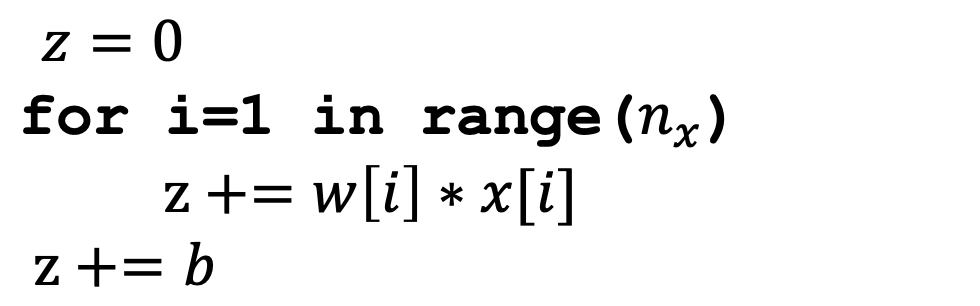
벡터화 시키기
- 를 벡터화 시켜서 두개의 열벡터간의 곱을 np.dot 으로 해결
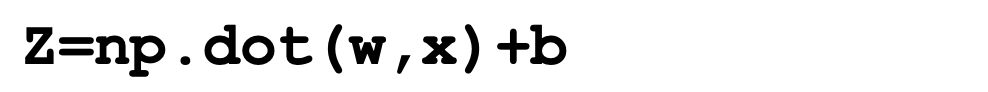
로지스틱 회귀 미분

[분석]
- cost 가 최소가 되는 w, b 를 찾아가는것이 목표
- J 와 모든 가중치를 초기화하고 1~m 까지 반복을 실행(m 개의 training data - batch 단위로
- 주어진 입력값에 대한 예측값을 구하기 위해 로지스틱 선형회귀식을 가지고 z 를 구한뒤 시그모이드 함수에 집어넣어 0과 1로 된 값으로 변환해준다. 그것이 바로
- 그런 다음 실제값와 우리가 예측한 값과의 차이를 Loss 함수로 계산하고 그 값을 J 에 업데이트
- 그런다음 를 로 미분한 dz 는 a-y 라는 식으로 계산하고
- 바로 위의 식과 체인룰을 이용하여 를 로 미분한 값을 구해보면 이다. 이를 통해 경사하강법에 업데이트할 dw1 과 dw2 를 계산한다.
- 업데이트를 하기 전에 우리가 구한 은 개의 데이터에 대한 것이므로, 마지막에 각각의 값을 으로 나어주고 업데이트 된 값을 가지고 다시 루프를 반복한다.
Logistic regression derivative – much further vectorization





