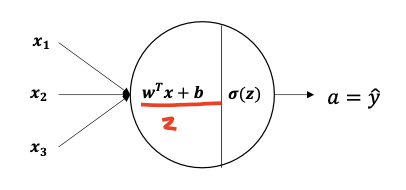
신경망(Shallow Neural Network)
- 입력 특성들의 층을 입력층이라 하며 라 표기한다
- 은닉층이랑 입력층과 츨력층 사이에 있는 모든 층을 의미한다. 번쨰 은닉층의 번째 유닛은 으로 표기한다.
- 예를 들어 첫 번째 은닉층은 로 표현하며 첫 번째 은닉층에 있는 번째 은닉층의 번째 유닛은
- 첫 번째 은닉층에 있는 두 번째 유닛은 로 표현가능
- 출력 특성들의 층을 출력층이라 한다
- 신경망 층의 개수를 세 때는 입력 층은 제외한다.
- 예를 들어 은닉층 1개, 출력층 1개의 경우 2층 신경망이라 한다.
hidden layer 가 필요한 이유?
- , 가 입력으로 들어왔을 때 logistic regression으로 파란색과 빨간색으로 100% 분류할 수 없다.
- hidden layer 를 하나 추가해서 높이면 분류 가능.
- 하지만 이와 같은 입력이 있다면 은닉층을 추가해도 빨간색을 바깥으로 뺴내는 것은 불가능하다. 따라서 은닉층의 노드의 개수를 증가시키므로써 차원을 높여 해결한다.

2-layer 신경망 네트워크(NN) 출력의 계산
-
표기법
-
입력층 : {}
-
은닉층 : = , 몇번째 층인지 해당 층의 몇 번째 노드인지
-
번째 은닉층의 번째 행렬 :
-
번째 은닉층의 번째 bias :
-
출력층 :
-
-
입력값이 노드를 통과할 때, 각 노드에서 두과지 과정을 거치게 된다.
- 선형회귀
- 활성함수 적용
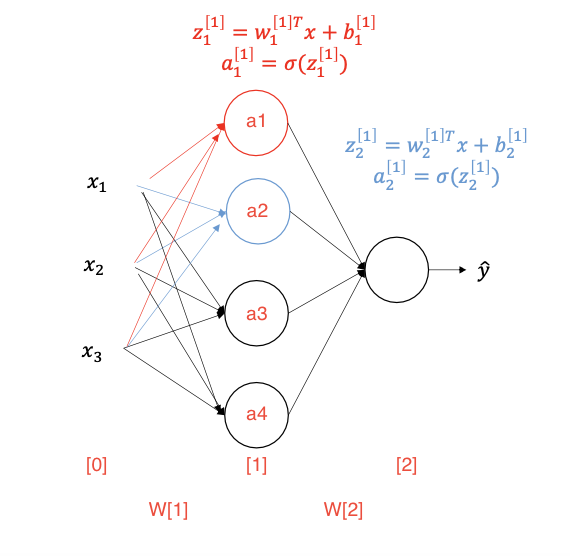
-
첫 번째 은닉층의 첫번쨰 노드 연산
-
첫번째 노드 :
-
-
첫 번째 은닉층의 전체 노드에 대해 계산
-
- 차원 :
-
- 차원 :
-
많은 샘플에 대한 벡터화
-
표기법
- : 몇 번째 층인지 의미
- : 몇 번째 훈련 샘플인지 의미
-
각 은닉층 에서 각 노드 에 대하여 ~ 번 반복
-
첫 번쨰 은닉층 에서 개의 노드들의 를 구하고 대입
-
-
두 번째 은닉층 에서 개의 노드들의 를 구하고 대입
-
-
수도코드
-
요약
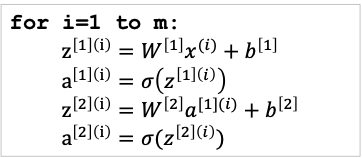
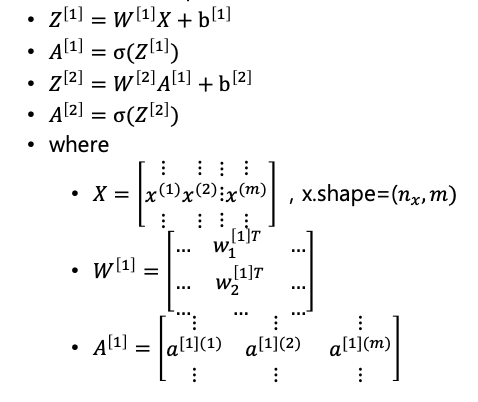
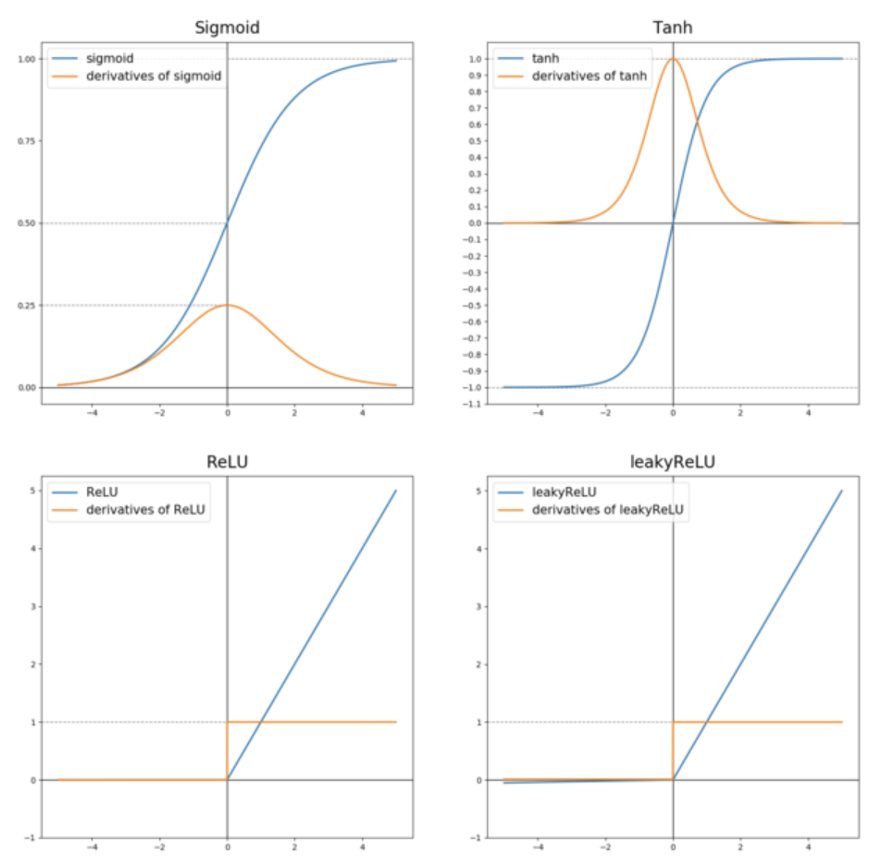
활성화 함수
-
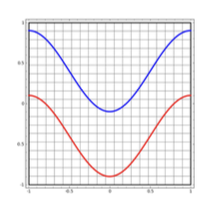
Sigmoid
-
-
- 의 절댓값이 크다면 미분값은 거의 0 이 된다.
- 일떄의 미분값
-
이진 분류의 출력층 이외에는 쓰지 않는 것이 좋다.
-
-
Tanh
-
-
-
의 절대값이 크다면 의 미분값이 거의 0 이 된다.
-
일때의 미분값은 이 된다
-
장점 : tanh 의 값이 사이에 있고 평균이 0 이기 때문에 데이터를 원점으로 이동하는 효과가 있다. 이는 평군이 인 보다 더 효율적이다.
-
-
예외 : output layer 에 사용 불가
-
tanh 와 sigmoid 의 단점
- z 가 커질수록 기울기가 작아져서 학습 속도가 떨어짐 따라서 주로 은닉층으로는 ReLU 를 많이 쓴다.
- z 가 음수일 때는 기울기가 0 이 되지만 실제로는 충분한 은닉 유닛의 z는 0보다 크기 때문에 실제로는 잘 동작한다.
-
ReLU
-
-
일떄, 미분값
- 장점 : z 가 0 보다 크면 미분값이 1 이 되고, 0 보다 큰 활성 함수의 미분값이 다른 함수에 비해 빠르게 학습할 수 있다.
-
일떄, 미분값
- 단점 : z 가 0 보다 작다면, 미분값이 0 이 된다. 따라서 leaky ReLU 사용 권장
-
-
leaky ReLU
-
-
일떄, 미분값
-
일떄, 미분값
-
왜 비선형 활성화 함수를 써야 하는지?
-
예를 들어 라는 선형 활성화 함수를 사용한다고 가정했을 때, 3 개의 은닉층을 쌓아도 로 아무런 혜택을 얻지 못한다.
-
따라서 등과 같은 비선형 함수를 사용해야 한다
-
은닉층에서는 선형 활성화 함수를 사용하는 경우는 굉장히 드물다
활성화 함수의 미분
신경망 네트워크와 경사하강법
- 단일층 신경망에서 경사 하강법을 구현하기 위한 방법
- 단일층이 아닐 때는 1 뿐만 아니라 1,2, ..., m 까지의 계산을 반복하면 된다.
- , , , 를 구해야한다.
- , , , 를 구해야한다.
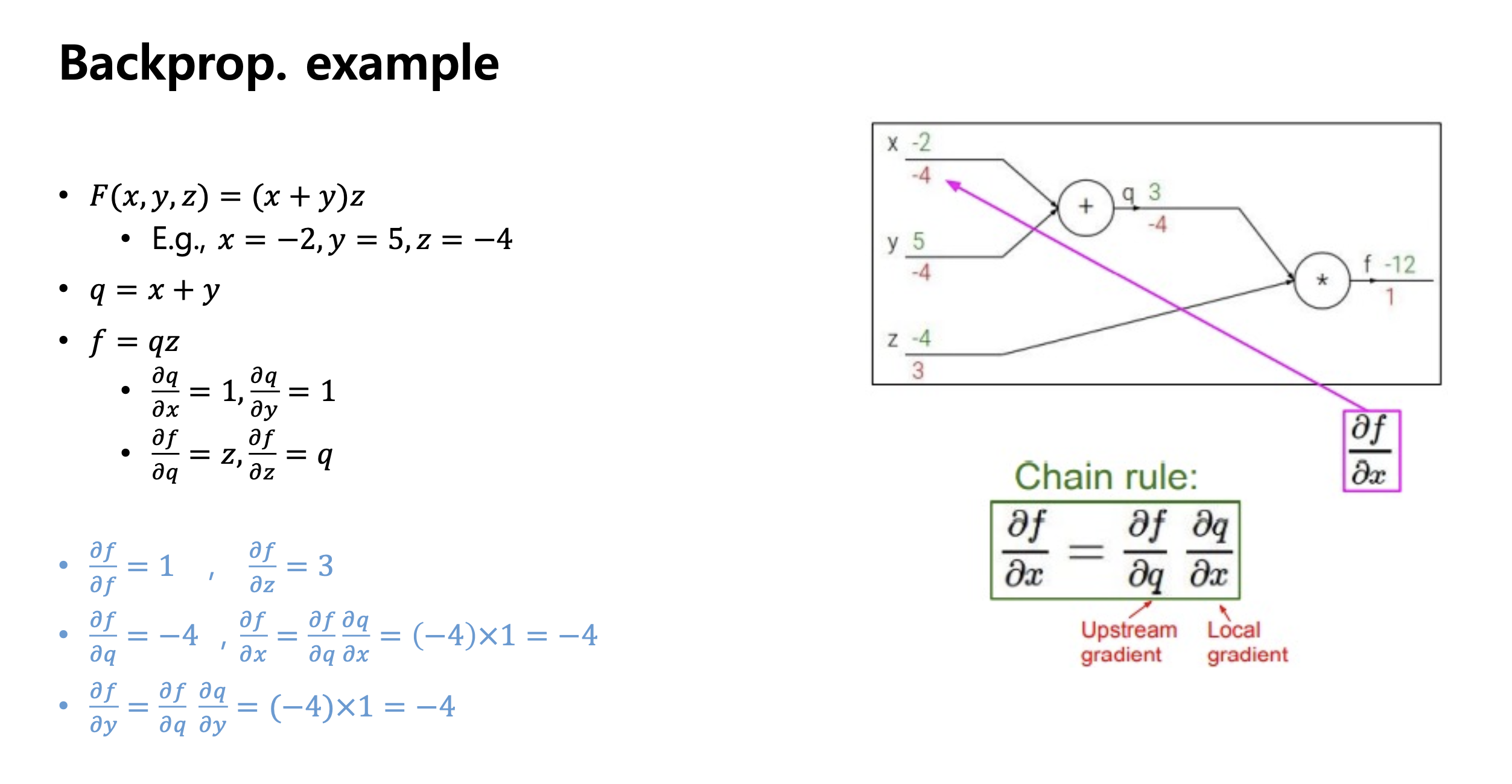
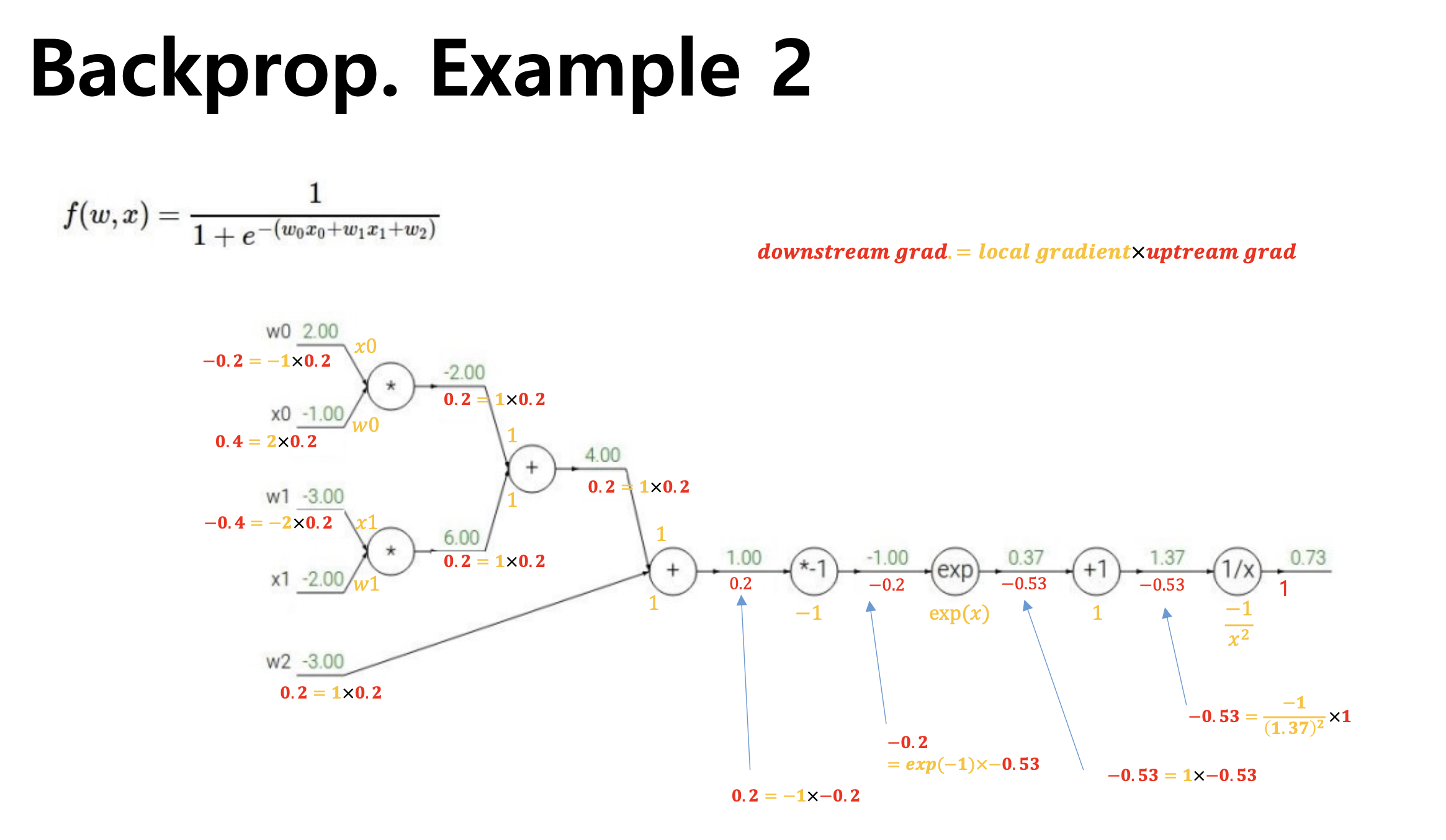
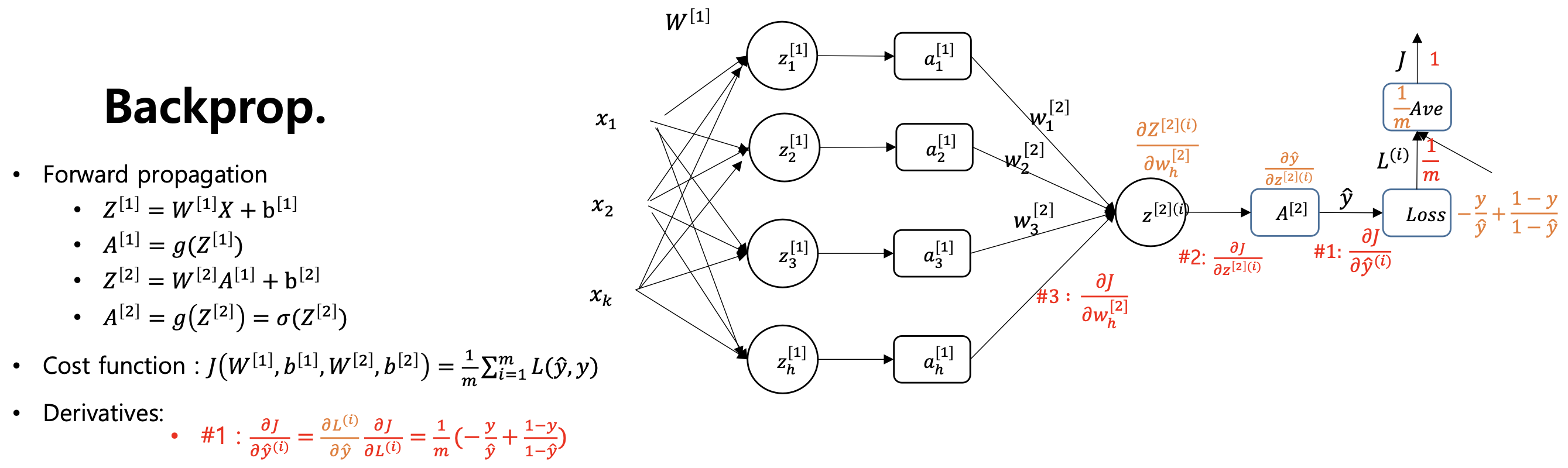
역전파에 대한 이해
- 로지스틱 회귀의 역전파를 구하면 다음과 같다.
- 는 고정값이기에 는 계산하지 않는다.
- 랜덤 초기화
- 신경망에서 의 초기값을 으로 설정한 후 경사하강법을 적용할 경우 올바르게 작동하지 않는다.
- 를 계산했을 때 모든 층이 같은 값을 갖게 되기 때문
- 따라서
np.random.rand()를 이용해 이 아닌 랜덤한 값을 부여해줘야 한다.
- 신경망에서 의 초기값을 으로 설정한 후 경사하강법을 적용할 경우 올바르게 작동하지 않는다.
의 초기값으로 0을 설정해주면 대칭 회피 문제로 인하여 학습이 되지 않는다.
W = np.random.rand((2,2))*0.01과 같이 해주는데 0.01을 곱해주는 이유는 z를 작게 하기 위함이다. Z 가 크면 tanh 혹은 sigmoid 함수에서 기울기가 0에 가까워지기 때문에 학습속도가 느려진다. 학습 속도가 느려지는 것을 방지하기 위해 0.01 을 곱해준다. Tanh 나 Sigmoid 가 활성함수가 아닌 경우에는 괜찮다.

?
if
ReLU 미분값인데 0보다 크면 자기 자신, 0보다 작으면 0

코드
#우라가 다루는 데이터 set
#빨간색 y=0, 파란색 y=1 로 레이블링이 되어있다.
#목표는 이 데이터에 맞는 모델을 설계하는 것.
X, Y = load_planar_dataset()
# 우리가 다루는 데이터의 모양
shape_X = X.shape # The shape of X is: (2, 400)
shape_Y = Y.shape # The shape of X is: (2, 400)
m = X.shape[1] # I have m = 400 training examples!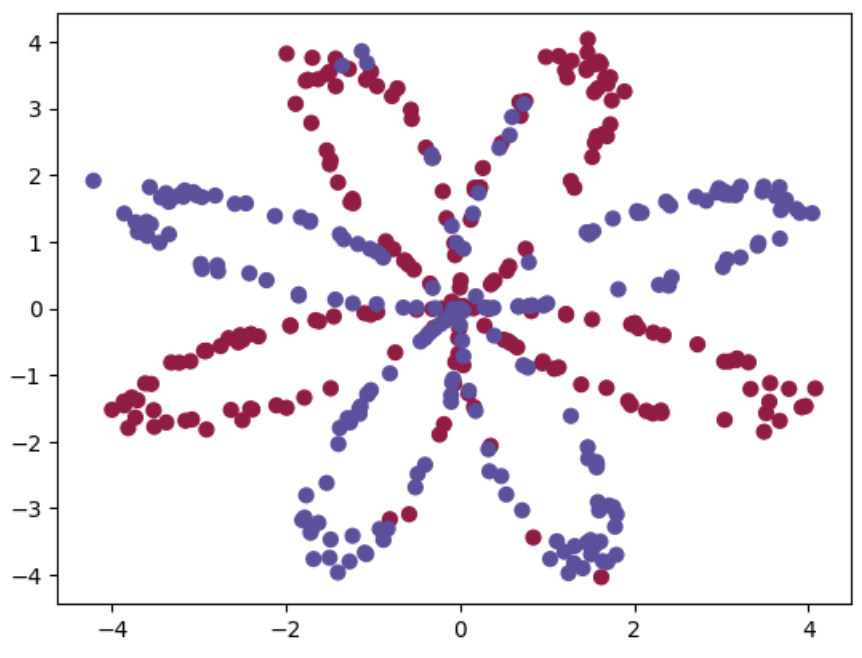
# 단순 로지스틱 회귀 적용
# 꽉찬 Neural Net 을 만들기 전에, 우선 로지스틱 회가가 어떻게 이 문제를 푸는지 살펴본다.
# 데이터세트가 선형으로 분리할 수 없기 떄문에 로지스틱 회귀는 이 문제를 잘 수행하지 못한다.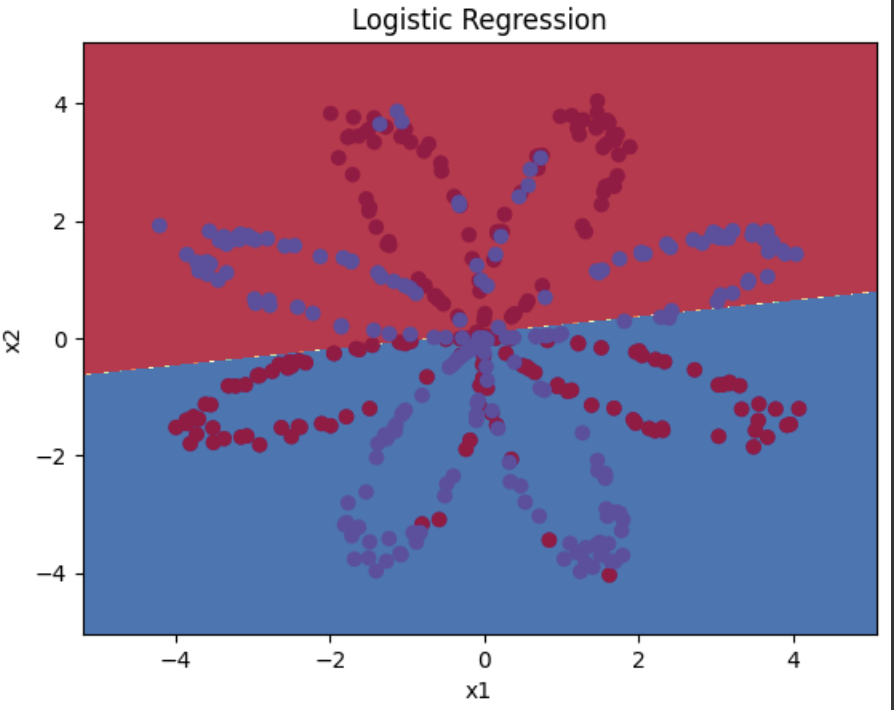
# 로지스틱 회귀는 이 꽃 데이터에 대해 잘 동작하지 못하므로, 하나의 은닉층을 가진 신경망으로 문제 해결
'''
# 알고리즘
# 1. 신경망의 구조를 정의한다. (입력층의 유닛의 개수, 은닉층의 유닛의 개수 등)
# 2. 모델의 파라미터를 초기화
# 3. 루프
# - Forward propagation 구현
# - gradient 를 얻기 위한 backward propagation 구현
# - 파라미터 업데이트(gradient)
'''
# 1) 신경망 구조 정의
def layer_sizes(X, Y):
n_x = X.shape[0] # 입력층의 사이즈 : 5
n_h = 4
n_y = Y.shape[0] # 출력층의 사이즈 : 2
return (n_x, n_h, n_y) # 인풋 사이즈, 히든레이어 사이즈, 아웃풋 사이즈 출력
# 2) 파라미터 초기화 -> 파라미터 딕셔너리에 저장
# w 행렬을 랜덤 값으로 초기화
# bias 행렬은 0 으로 초기화
def initialize_parameters(n_x, n_h, n_y):
W1 = np.random.randn(n_h, n_x) * 0.01 # 입력층의 weight (4,2)
b1 = np.zeros((n_h,1)) # (4,1)
W2 = np.random.randn(n_y, n_h) * 0.01 # 출력층의 weight (1,4)
b2 = np.zeros((n_y,1)) # (1,1)
parameters = {"W1": W1, # 딕셔너리
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
# 3) 루프
# 역전파 함수 구현
# 시그모이드와 tanh 사용
# 1. 딕셔너리로부터 각 파라미터를 꺼낸다. (파라미터 초기화의 출력값들)
# 2. 순전파 진행하여 Z^[1], A^[1], Z^[2], A^[2] 계산
# 역전파에 사용될 값들은 캐시에 저장되고 그 캐시는 역전파의 인풋으로 주어질것이다.
def foward_propagation(x, parameters):
# 딕셔너리 parameters 에서 각 파라미터 가져오기
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
# A2 를 계산하기 위해 순전파 구현
Z1 = np.dot(W1, X) + b1 #linear transformation
A1 = np.tanh(Z1) #non linear transformation
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
# 캐시에 저장
cache = {"Z1": Z1, #linear, not linear trans 를 캐시에 할당.
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
# GRADED FUNCTION: compute_cost # 코스트 계산 -> 위 J 는 cross entropy 식 사용
def compute_cost(A2, Y, parameters): #A2 : yhat, Y : 정답지
m = Y.shape[1] # number of example
# 크소르 엔트로피 코스트 게산
logprobs = np.multiply(np.log(A2),Y) + np.multiply(np.log(1-A2),(1-Y))
cost = np.sum(logprobs) * (1/m)
cost = np.squeeze(cost) #1x1 인것들 제외
return cost
def backward_propagation(parameters, cache, X, Y):
m = X.shape[1]
# 딕셔너리 parameters 로부터 W1, W2 가져오기
W1 = parameters["W1"]
W2 = parameters["W2"]
# 캐시로부터 A1 과 A2 가져오기
A1 = cache['A1']
A2 = cache['A2']
# 역전파 : dW1, db1, dW2, db2 계산
dZ2 = A2 - Y
dW2 = (1/m)*(np.dot(dZ2, A1.T))
db2 = (1/m)*(np.sum(dZ2, axis=1, keepdims = True))
dZ1 = np.dot(W2.T, dZ2) * (1 - np.power(A1, 2))
dW1 = (1/m) * np.dot(dZ1, X.T)
db1 = (1/m) * np.sum(dZ1, axis=1, keepdims = True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
def update_parameters(parameters, grads, learning_rate = 1.2):
# 딕셔너리 parameters 로 부터 각 파라미터 가져오기
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
# grads 딕셔너리로부터 각 gradient 값 가져오기
dW1 = grads['dW1']
db1 = grads['db1']
dW2 = grads['dW2']
db2 = grads['db2']
# 각 파라미터 업데이트
W1 = W1 - learning_rate*dW1
b1 = b1 - learning_rate*db1
W2 = W2 - learning_rate*dW2
b2 = b2 - learning_rate*db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters# GRADED FUNCTION: nn_model
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
"""
Arguments:
X -- dataset of shape (2, number of examples)
Y -- labels of shape (1, number of examples)
n_h -- size of the hidden layer
num_iterations -- Number of iterations in gradient descent loop
print_cost -- if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters, then retrieve W1, b1, W2, b2. Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
### START CODE HERE ### (≈ 5 lines of code)
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
### START CODE HERE ### (≈ 4 lines of code)
# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache".
A2, cache = forward_propagation(X, parameters)
# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost".
cost = compute_cost(A2, Y, parameters)
# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads".
grads = backward_propagation(parameters, cache, X, Y)
# Gradient descent parameter update. Inputs: "parameters, grads". Outputs: "parameters".
parameters = update_parameters(parameters, grads, learning_rate = 1.2)
### END CODE HERE ###
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
공부한 것 기록용