
CH3
국내 대기업 LLM 개발현황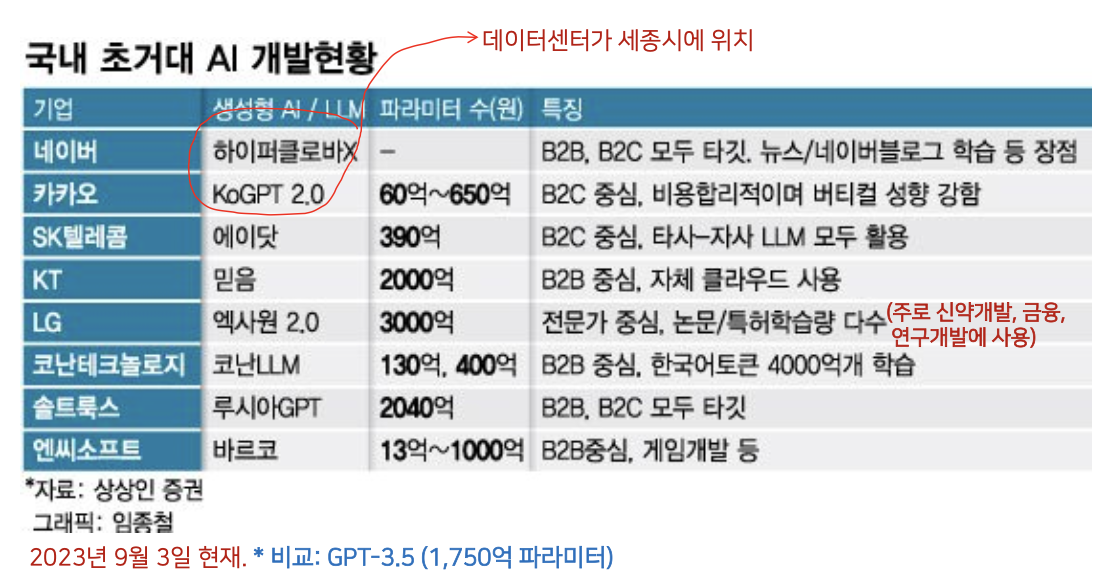

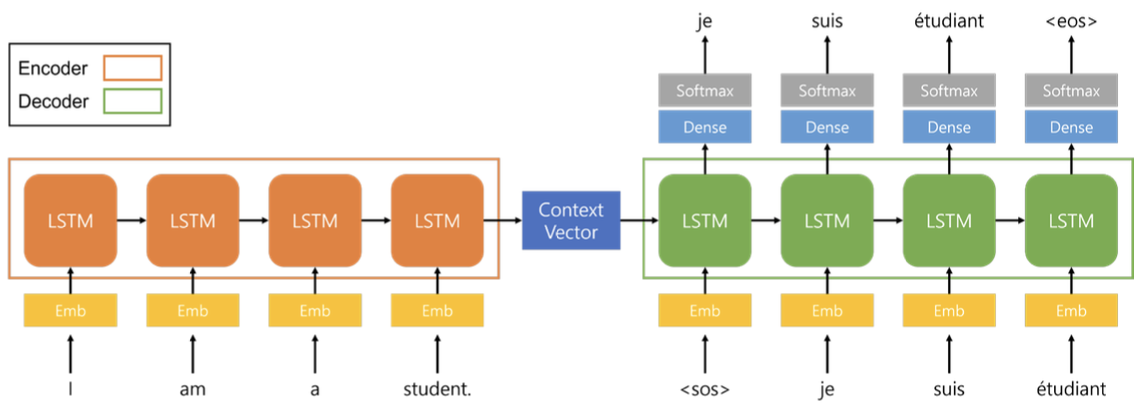
Teacher Forcing Training in Seq2Seq
- Teacher Forcing Training Method
- 이전 시점의 디코더 출력(결과=Values) 단어를 다시 디코더 입력값으로 사용하는 방식으로는 디코더가 잘 학습되지 않는다.
- 모델 학습 시에는 디코더의 입력값으로 이전 시점의 디코더 출력 단어가 아닌 실제 정답 단어(Target)를 입력해 줘야 한다.
- 이 방식은 Teacher Forcing 이라고 한다.
- 실제 정답지 타겟 즉, Teacher 를 입력으로 해서 실제 정답 단어를 해줘야만이 학습이 더 잘됨
- 선생님이 직접 강제적으로 정답을 입력을 해서 훈련 시킨다는 개념
Motivation of Transformer
트랜스포머가 왜 개발이 됬을까?
2014년에 발표한 논문 : 인코더에서 계산한 결과가 고정 길이로 하나의 벡터로만 정보를 담아내다보ㅓ니 정확한 정보를 담아내지 못함. 이런 문제를 해결하기 위해 트랜스포머를 발표
-
RNN 기반의 LLM 은 Long term dependency(긴 문장간의 상호 의존성 문재점 - 이전의 단어들을 잊어버린다.) 문제가 있다.
-
긴 문장 안에 단어들간의 상호의존성 문제
1) 문장이 길 수록 정보를 더 많이 잃어버린다
2) RNN 을 역전파를 해야하는데, 활성화함수가 1보다 작기 떄문에, 문장이 길면은 활성화함수를 계속해서 짧은 시간에 감소가 심해진다. 그러다보면 활성함수들이 작아지고 그 결과에 따라서 파라미터들이 업데이트가 잘 안되는 문제가 발생. -
Attention Mechanism 을 발표함
-
딥러닝에서 어텐션 메커니즘
- 1) 각각의 단어를 동등하게 보지 않는다.
- 2) 각 단어에 가중치를 다르게 준다 (분리된 단어간의 관계에 따라서, 괸계가 높으면 가중치를 높게, 관계가 작으면 가중치를 낮게)
- attention : 관심을 더 많이 가져줘! 중요한 단어에 대해 다른 단어들과 비교하여 더 집중하라는 것이 매커니즘의 핵심
어텐션이 무엇인가?
- 어텐션은 네트워크 아키텍쳐의 하나의 컴포넌트이다. 그리고 관계성, 유사도를 가중치를 부여하여 관리하는 역할을 한다.
- 1) 인풋과 아웃푹 토큰 사이에서의 관계성에 가중치를 부여하는 General Attention
- 2) 입력 단어들에 대해서만 어텐션 즉 가중치를 부여하는 것은 Self-Attention
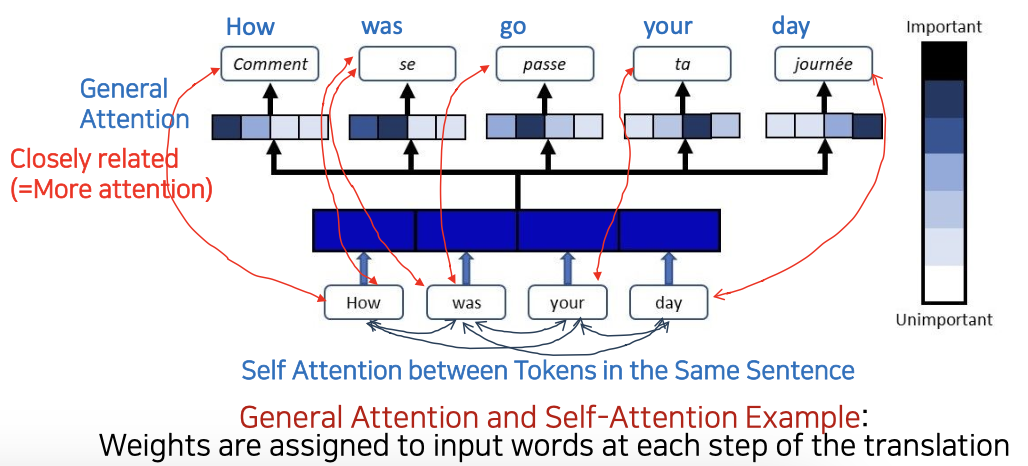
General Attention
- 문장의 How, was, your, day 각각 유사도가 어느정도 인지에 따라서 가중치를 매겨준다(여기선 색으로).
- Comment: How 라는 뜻이므로 인덱스 상의 How 부분이 가장 진한색
- se: was 라는 뜻으로 문장의 was 부분과 유사도가 크므로 진한색
Self-Attention
- 인풋 토큰(How, was, your, day)들사이에서 관계가 어떻냐
- 밀접한 관계가 있는 단어들은 유사도가 높고 관계성이 높다.
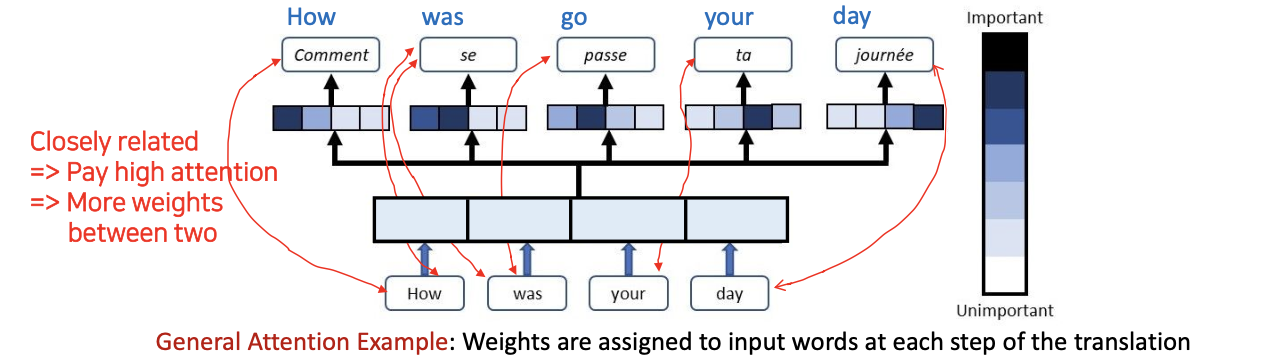
-
각 스텝마다 Target 단어와 인풋간의 얼마만큼의 유사도가 있느냐에 따라서 weight 값이 매겨진다. 그리고 현재 디코더의 히든 스테이트(메모리셀)과 인코더의 히든 스테이트(메모리셀) 간 유사성을 매 스텝마다 계산한다.
-
소프트맥스에 의해 유사도를 확률로 변환한다. 그리고 인코더의 히든 스테이트의 가중치가 부여된 합을 사용하므로써 수정된 컨텍스트 벡터 포함한다.
-
수정된 컨텍스트 벡터를 기반으로 다음 단어가 무엇이 오는지 예측한다.
Kep Concept of Attention with an Example
-
Query : "Who is the singer"
-
주어진 컨텍스트(text) : "They love a song by The Cranberries, singer from their hometown, Ireland"
- 더 크렌베리스를 모르는 사람들은, 먹는 크렌베리인지, 열매를 이야기하는지 모름
- 지피티한테 singer 가 무엇인지 찾으라 한다면
-
Attnetion 매커니즘 적용
- 질문과 답변의 관계에서 어떤 토큰(단어)에 가장 높은 집중(높은 Attention = Weight)을 해야 할까? -> 붉은색
- Attention 알고리즘은 주어진 입력 값(토큰) 중 모델이 정확한 답변을 위해서 어떤 것에 집중해야 하는지 돕는 역할
Overview of 4 Type of Attention in Transformer
1) Self-Attention
2) Encoder Multi-Head Attention
3) Encoder-Decoder Multi-Head Attention
4) Masked Multi-Head Attention
Self-Attention in Transformer
- RNN 기반의 seq2seq 는 앞 뒤의 tear 를 모두 "눈물을 흘리다" 로 해석했을 것이다.
- Self-Attention : 같은 문장 내 토큰들 사이의 유사성을 기반으로 attention 을 수치화 하는, 계산하는 방법이다.
- 앞의 tear 는 paper 와 high attention(유사하다), 뒤의 tear 는 shed 와 high attention
- tear 와 paper 는 high attnetiohn (높은 유사성)을 갖기 때문에, 이떄의 tear 는 찢다 라는 것을 해석됨.
1) 모델은 위 컨텍스트에서 tear(찢다)와 tear(눈물)을 구별해야한다.
2) 모델은 같은 문장 내의 토큰들 사이의 관계(유사성)에 의한 차이를 알 수 있다.
3) 두 토큰, 'paper', 'tear'(찢다) 사이에는 high attention (관계=유사성)이, 'tear'(눈물)과 'shed' 사이에는 high attention 이 있다.
Multi-Head Attention in Transformer
- Multi-head attention
- 하나의 attention 을 계산하는 것이 아니라 여러 개의 attention 을 따로 독립적으로 학습 할 수 있게 해줍니다
- 모델이 features(특징=핵심사항) 를 더 풍부하게 학습할 수 있도록 합니다
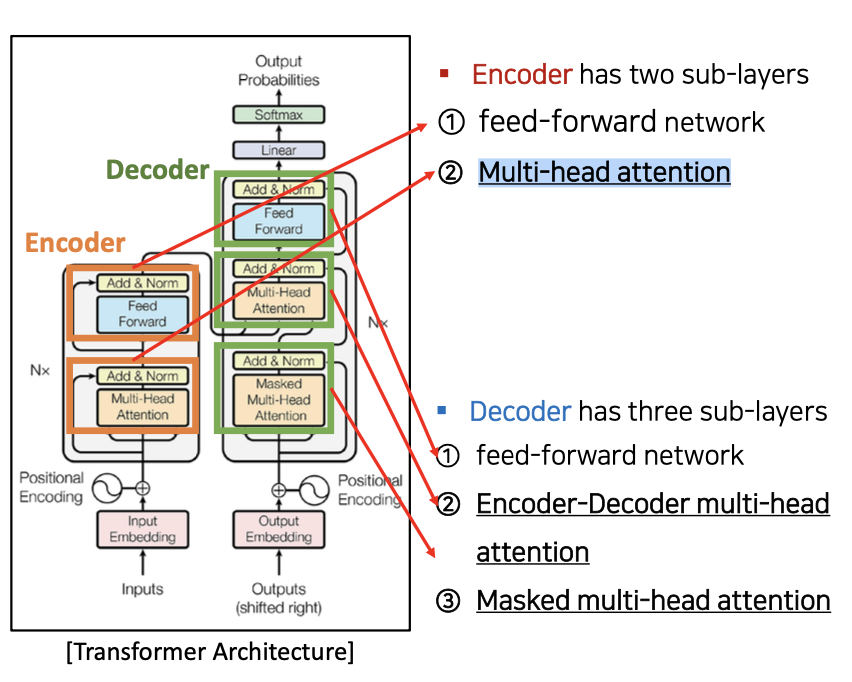
- Encoder 는 두 개의 sub-layers 를 가진다.
- ❶ feed-forward network
- ❷ Multi-head attention
- Decoder 는 세 개의 sub-layers 를 가진다
- ❶ feed-forward network
- ❷ Encoder-Decoder multi-head attention
- ❸ Masked multi-head attention
Muti-Head(다중 독자)
Which do you like the better, coffee or tea?
하나의 문장에 대해서 여러 Head 를 나눠 각각 어느 토큰에 더 많은 attention 을 주느냐를 나누어 독립적으로 학습하는 것이 바로 Muti-Head Attention- 첫번쨰 Head(사람) : 문장 형태(Type)에 더 집중하는 Attention
- Which do you like the better, coffee or tea?
- 두번째 Head(사람) : 명사에 다 집중하는 Attention
- Which do you like the better, coffee or tea?
- 세번째 Head(사람) : 관계에 더 집중하는 Attention
- Which do you like the better, coffee or tea?
- 네번째 Head(사람) : 강조에 더 집중하는 Attention
- Which do you like the better, coffee or tea?
Muti-Head Attention 이 왜 필요한가?
- 앞 페이지처럼 한 head는 문장 타입에 집중하는 어텐션을 줄 수도 있고, 다른 head는 명사에 집중하는 Attention, 또다른 head는 관계에 집중하는 Attention 등등 multi-head 는 같은 문장 내 다양한 Relation 또는 다양한 Source Information 나타내는 정보들에 집중하는 Attention 제공 기능.
- Multi-head attention 을 사용하게 되면 각 head 는 input 시퀀스의 서로 다른 부분에 Attention을 주기 떄문에 모델이 입력 토큰 간의 더 복잡한 관계를 다룰 수 있다.
- 따라서 더 많은 입력 시퀀스의 정보를 뽑아 낼 수 있음. 또는 다양한 유형의 Dependency를 알 수 있어 표현력이 향상되고 토큰(단어) 간의 미묘한 관계 역시 더 쉽게 알 수 있게 해줌
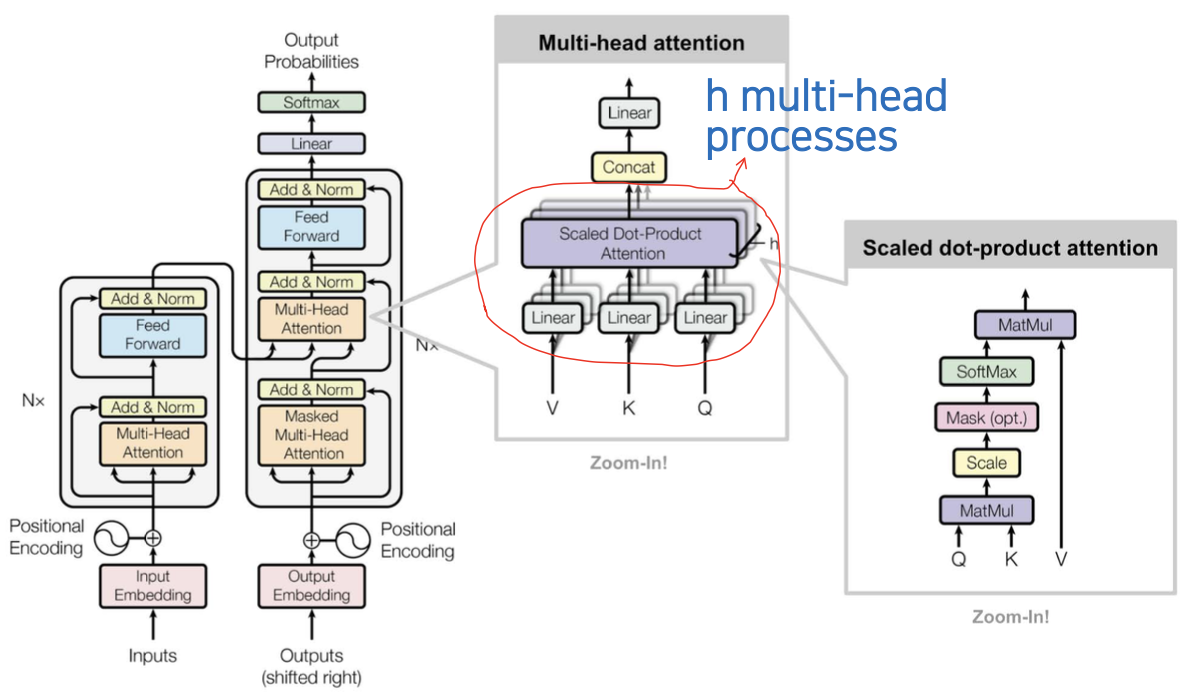
- Muti-head attention 부분을 보면 h개의 head 들이 독립적으로 병렬적으로 처리가 된다는 것을 알 수 있다.
- Scaled dot-product attention : 다음 챕터에서 배울 것
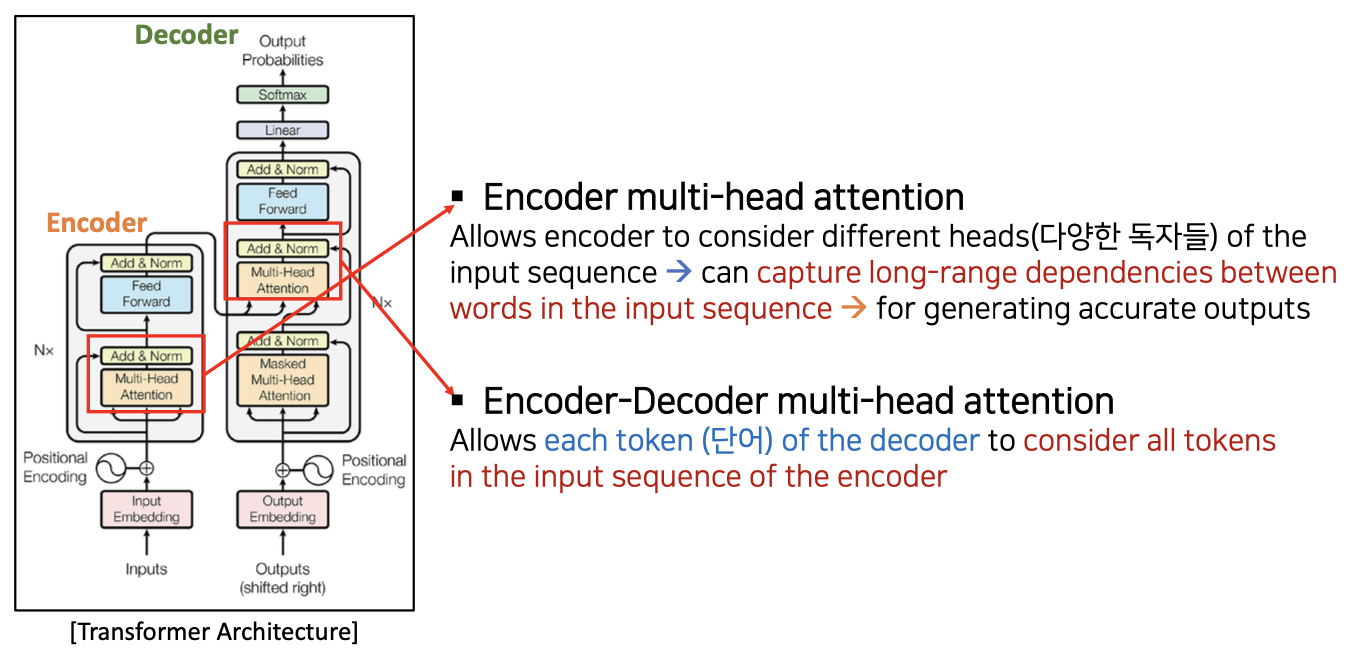
- Encoder multi-head attention
- 인코더가 input sequence 의 여러 heads (다양한 독자들)를 고려할 수 있습니다 input sequence 에서 단어들 사이의 긴문장의 의존성을 포착할 수 있습니다 정확한 Output 생성을 위해
- Encoder-Decoder multi-head attention
- 디코더의 각 토큰(단어)이 인코더 input sequence 에 있는 모든 토큰(인코더로부터 온 모든 토큰들)을 고려하도록 허용합니다
Masked Multi-Head Attention in Transformer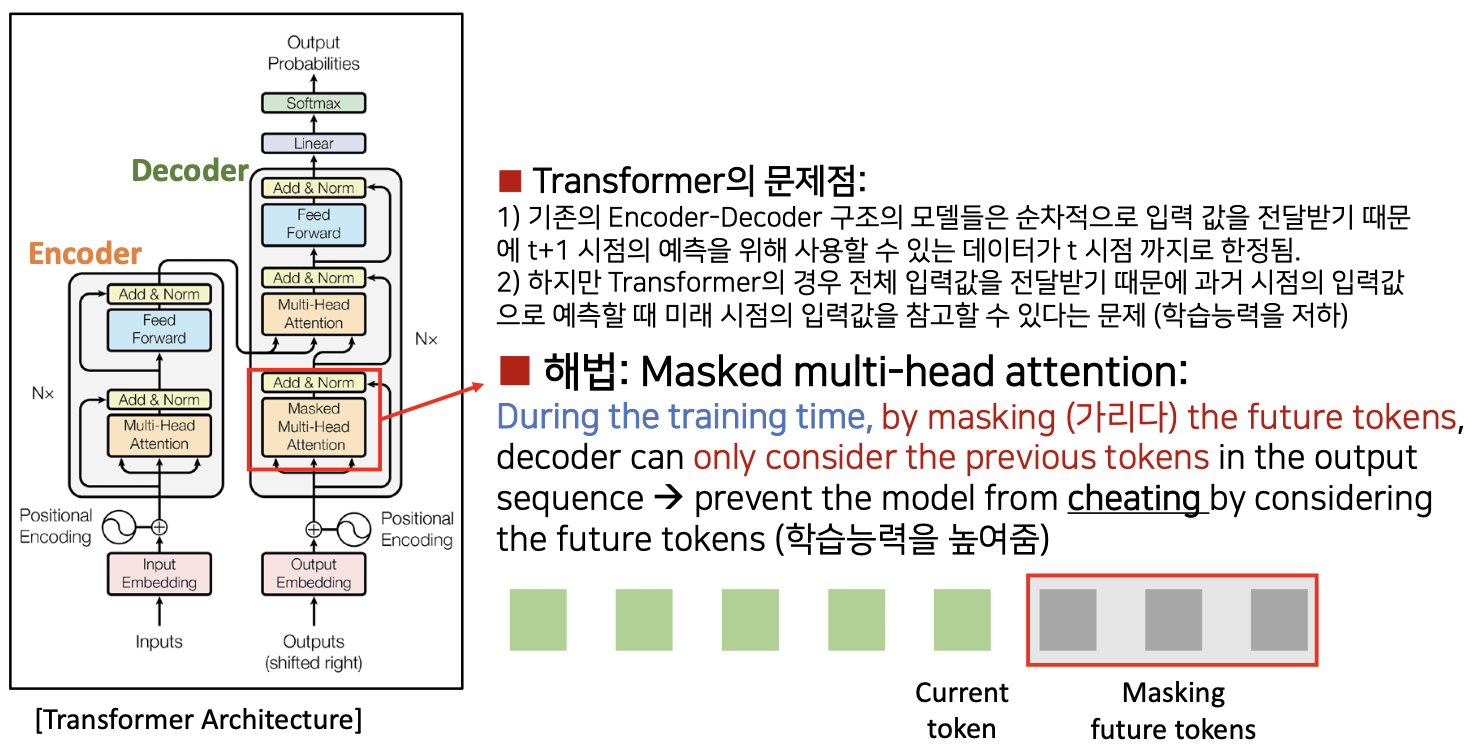
Transformer 의 문제점
- 1) 기존의 Encoder-Decoder 구조의 모델(seq2seq)들은 순차적으로 입력 값을 전달받기 때문에 t+1 시점(미래)의 예측을 위해 사용할 수 있는 데이터가 t 시점 까지로 한정됨
- 2) 하지만 Transformer 의 경우 전체 입력값을 전달받기 떄문에 과거 시점의 입력값으로 예측할 때 미래 시점의 입력값을 참고할 수 있다는 문제(학습 능력 저하)
- 그러니까 즉 내가 t+1 의 단어를 예측하려면 t 시점까지의 과거의 모든 데이터가 하나의 벡터로 뭉쳐서 사용한다.
- 하지만 Tranformer 는 전체 입력값을 전달받고(인코더에 있는 모든 인풋값+예측해야되는 타겟값), t+1을 예측하려고 하면, t+1 이라는 미래의 값까지 미리 알아버림, 정답을 예측하면서 학습해야되는데, 정답을 알려주기 때문에 학습 능력 저하
해법: Masked multi-head attention:
- 위 문제를 미래에 내가 예측할 토큰들을 숨겨버리므로써 해결 : Masked
- training 시간동안, 미래 토큰을 마스킹(가리다) 함으로써, 디코더는 출력 시퀀스의 이전 토큰만을 고려할 수 있습니다 미래의 토큰을 고려하여 모델이 부정행위(cheating)를 하는 것을 막습니다 (학습 능력을 높여줌)
Masked Self Attention Example: Translation from English to French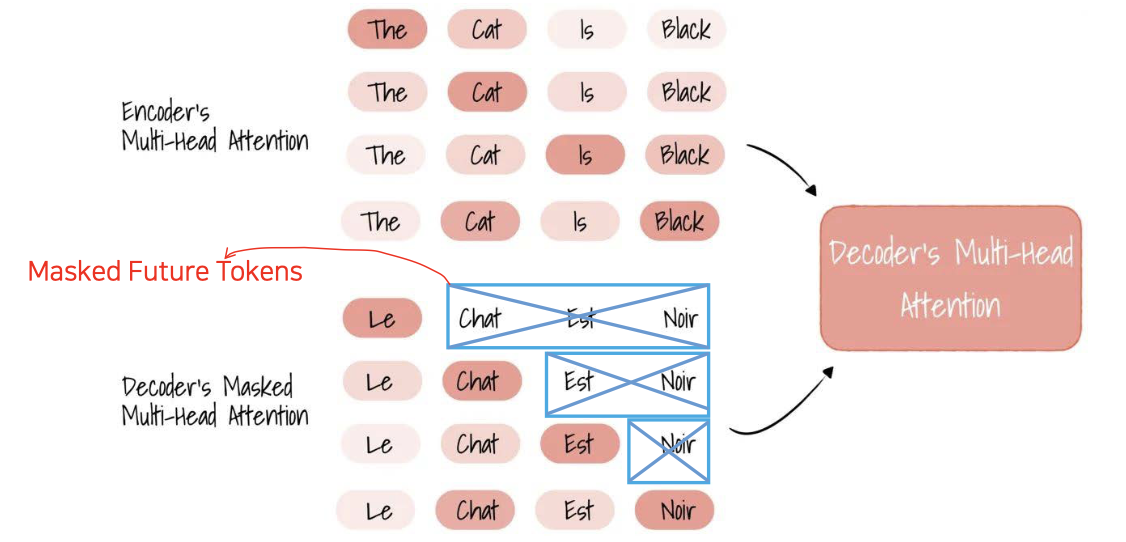
- 인풋 인코더의 멀티 헤드 어텐션이 있다. (첫번째 어텐션은 The 와 Cat 에 어탠션을 많이 주었고, 두번째 ...)
- 인코더로부터 넘어올때, 멀티 헤드 어텐션 뿐만아니라 미래의 정답지 타겟값도 같이 넘어옴
- 디코더에서 첫번째 입력값인 Le 를 가지고, 과거의 값(인코더로부터 온 값)을 가지고 Le 다음에 올 값을 예측하는 상황
- Le 다음에
chat,Est,Noir를 다 줘버리면 안되기 때문에 마스크로 감춰서 학습 시킨다. - 그렇게 해서 chat 이라는 값이 두번쨰에 온다는 것을 알았다. 그럼 그 다음에는
Est,Noir. 를 숨기고 학습한다.
self 인 이유?
디코더의 입력으로 들어온 정답지 "프랑스어 문장" 에서 디코더의 위치 이후의 토큰들을 마스킹하여 자기자신인 "영어문장" 과 대조해 Attention 을 구하는 것이다.
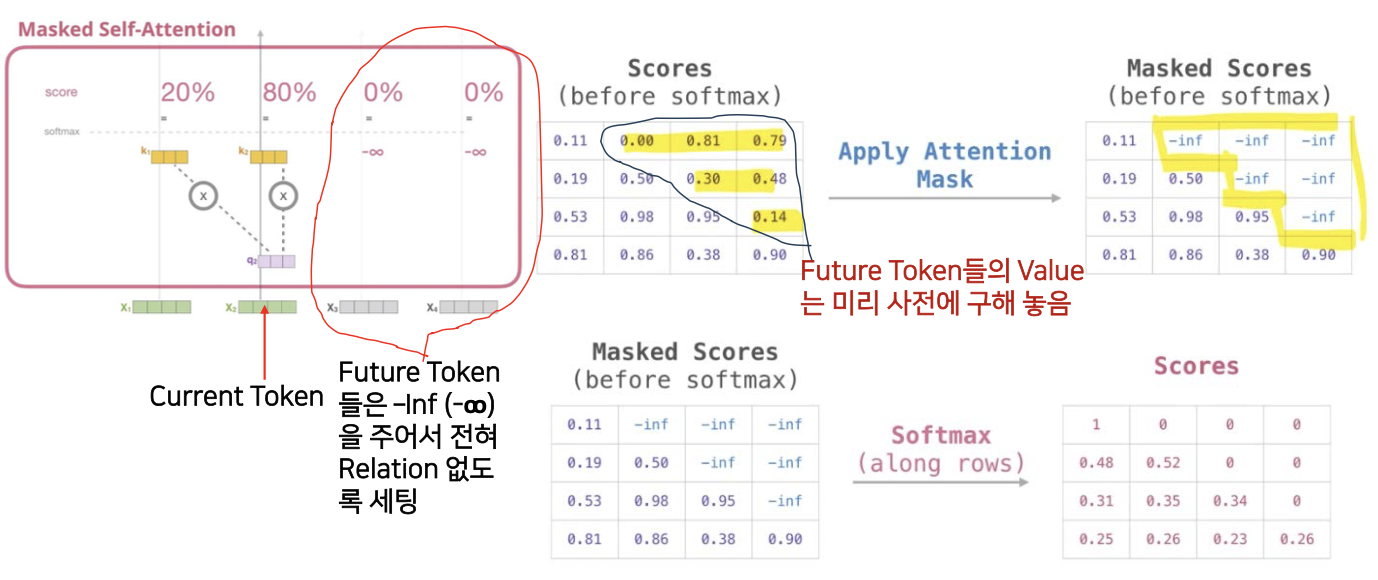
- 관계성이 없도록 만들어주므로써 마스킹을 한다.
- 숫자가 높으면 관계성이 높은데, 이 언텐션 높은 부분에다가 를 주어 0%로 만든다.
- Socore 에 마스크를 적용하였고 소프트맥스를 적용하여 확률값으로 계산하면 오른쪽 아래와 같은 표가 나온다.
Feedforward in Transformer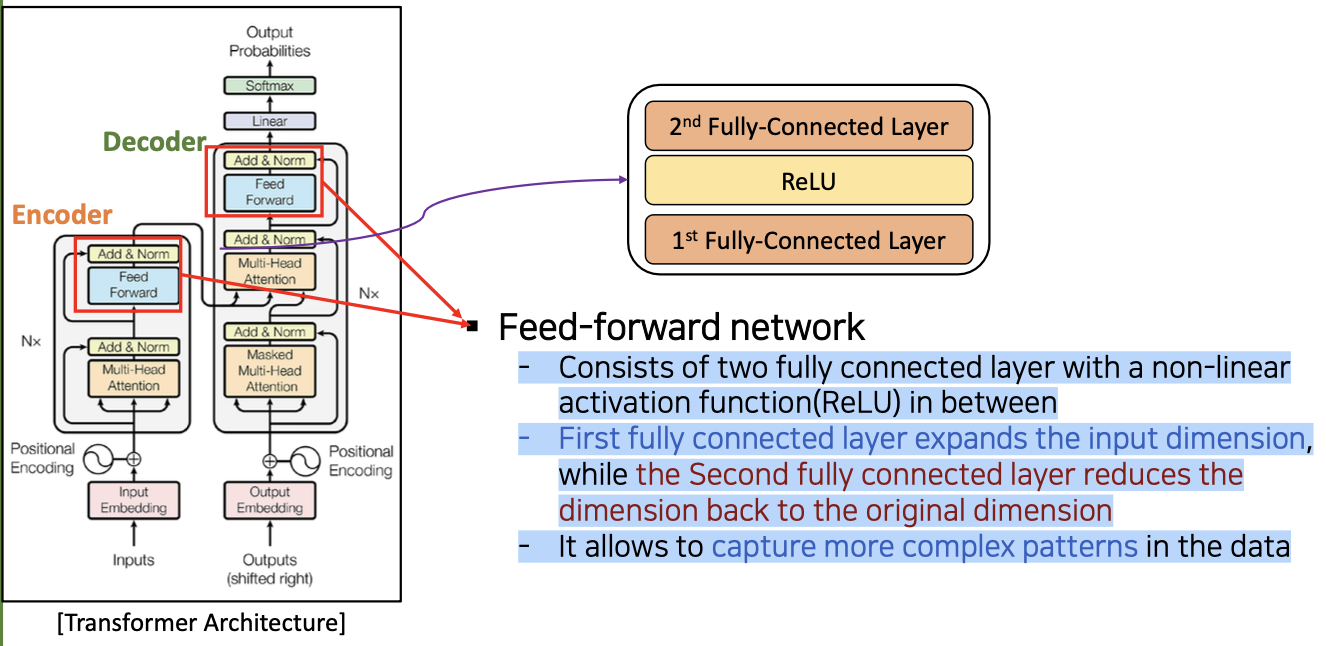
- Feed-forward network
- 비선형 활성화 함수(ReLU)를 사이에 두고 완전하게 연결된 두 레이어로 구성됨
- 첫 번째 완전 연결 레이어는 입력 차원을 확장 하는 반면 두 번째 완전 연결 레이어는 차원를 원래 차원으로 다시 줄입니다
- Fully connected layer를 두개를 쓰는 이유는 데이터 내의 보다 복잡한 패턴을 포착할 수 있도록 해준다.
- 차원을 늘리면 더 복잡한 패턴을 알아낼 수 있는것
Positional Encoding in Transformer
- seq2seq 에서는 사용하지 않은 요소 -> seq2seq 는 모든 단어들이 순차적으로 들어오는데, transformer 는 모든 단어들이 병렬로 들어오기 때문, 그러다보니 순서를 잃어버리는 문제가 발생(인풋의 순서륾 몰라버리면 중요한 정보를 잃어버리는것과 마찬가지)
- Positional Encoding
- 1) Transformer는 입력 순서를 병렬로 처리합니다: 데이터의 순서를 고려하지 않습니다
그것은 입력의 순서에 대한 정보를 잃는 결과를 낳습니다 - 2) 데이터의 순서를 고려(기록)하기 위해 Transformer 는 Positional Encoding 을 사용합니다
- 1) Transformer는 입력 순서를 병렬로 처리합니다: 데이터의 순서를 고려하지 않습니다
Self-Attention 과정
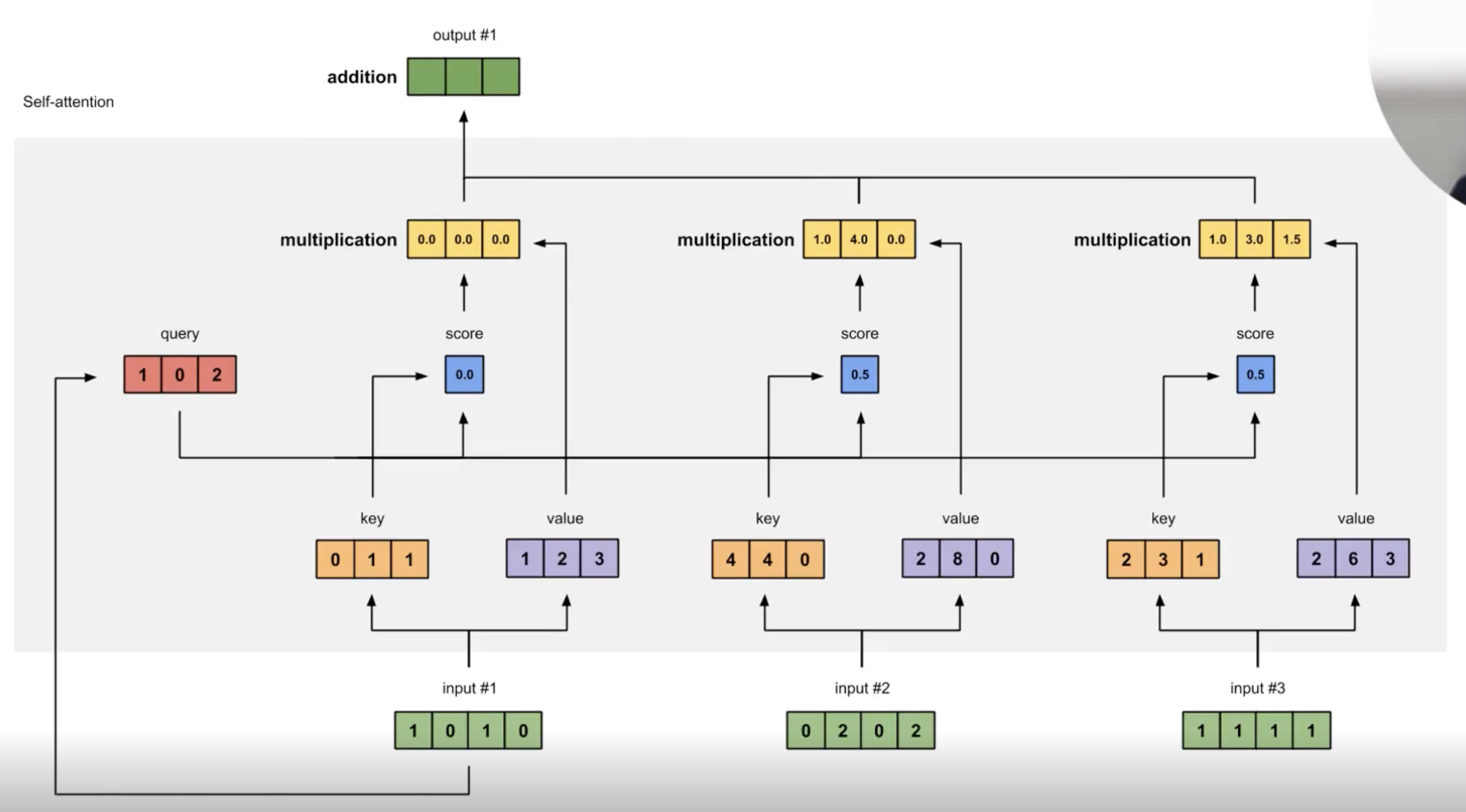
빨간색 부분인 쿼리가 들어오면은 첫번째 토큰에 대한 Input 이 들어오게 되면 (1, 0은 어텐션의 값) 개별적으로 올라가면서 업데이트
