
CH4
트랜스포머의 전체 아키텍쳐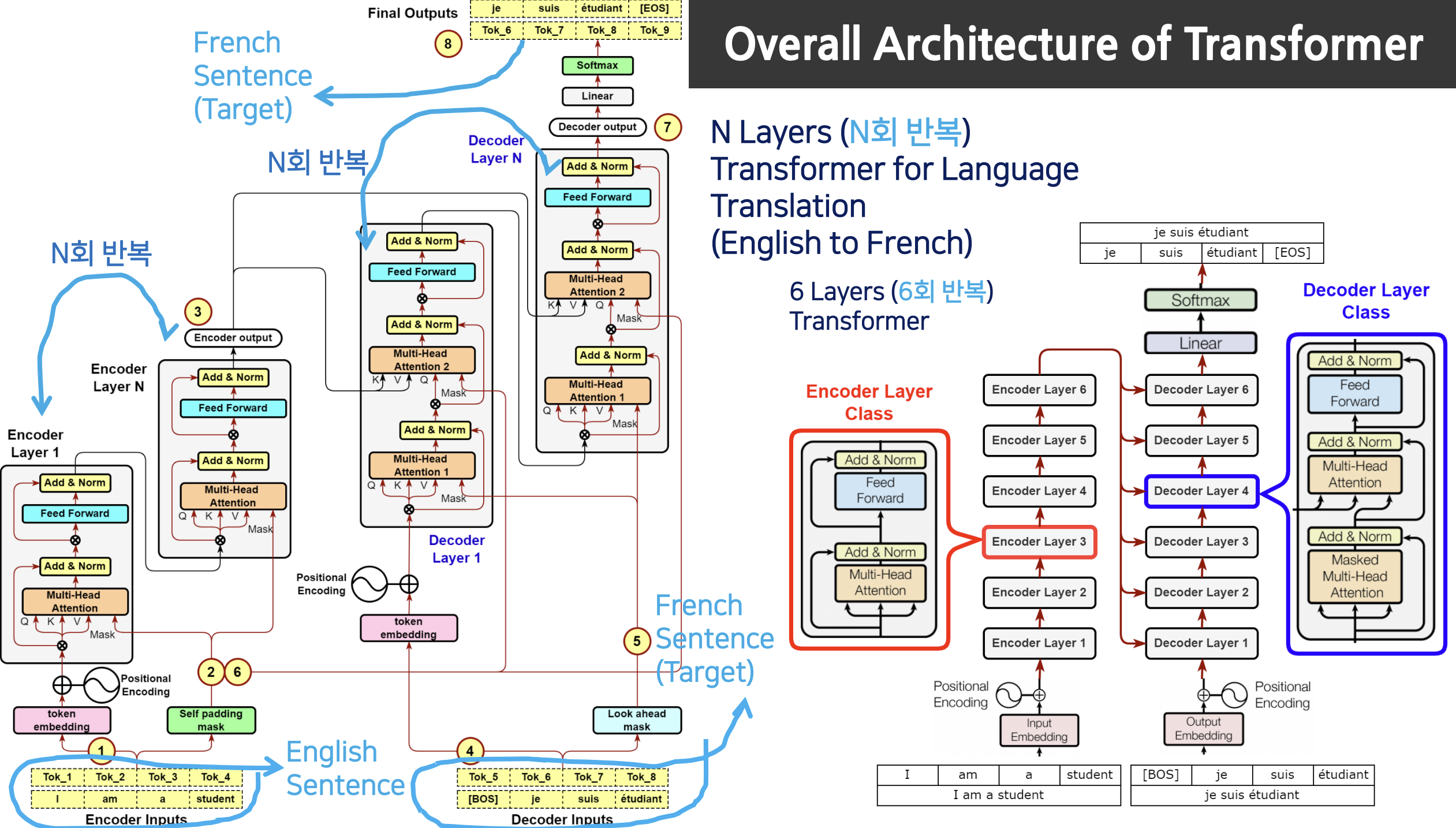
-
인코더 레이어 부분을 N회 반복해 디코더의 멀티 헤더 어텐션 2 부분에 합류한다.
-
디코더의 인풋, 아웃풋 모두 정답지가 들어가있다 -> 학습이 더 잘되더라
Review of Self Attention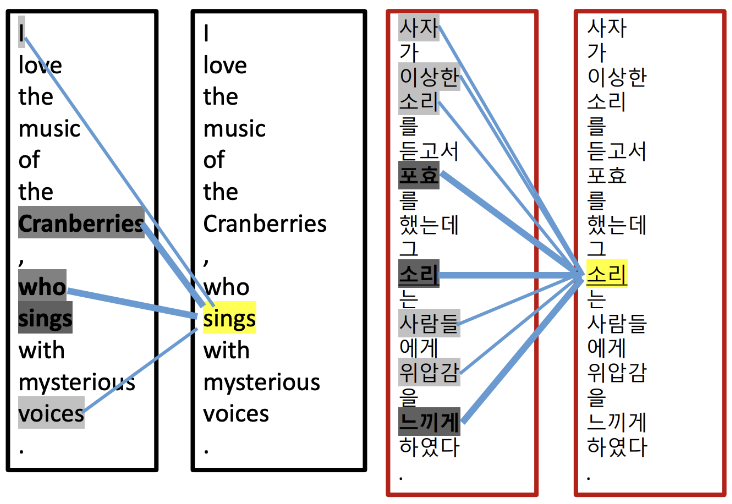
주어진 3개의 예시 문장
I love the music of the Cranberries, who sings with mysterious voices.The Cranberries had cranberries too much, so they look for a hospital.사자가 이상한 소리를 듣고서 포효를 했는데 그 소리는 사람들에게 위압감을 느끼게 하였다
Self Attention 의 기능
- 위의 3 문장은 한 문장이지만 문장내에서 동사의 주어가 무엇인지 대명사는 어떤 명사를 가리키는지 Transformer 는 모름
- 따라서 같은 문장을 서로 비교하게 하여서 토큰(단어)간 관계 또는 유사도(Relation=Similarity) 에 가중치를 부여하여서 혼동을 피하게 해줌.
- 왼쪽의 'sing'의 주체가 'i' 인지 'Cranberries' 인지 매우 혼동스러움. 인간은 'sings'의 주체가 'Cranberries' 임을 알 수 있고 두 토큰에 가중치를 높에 배정. 'who' 도 관계대명사로 동사 'sings' 와 관계가 높음
- 두 번째의 '소리'도 첫번째 '소리'와 밀접한 관계가 있는지 '포효'의 소리를 가리키는지 딥러닝은 모름. 따라서 사람이 높은 가중치를 사용하여 두번째 '소리'와 '포효' 토큰을 연결
- ‘sings’토큰과 왼쪽 모든 토큰들간 유사도는 책정됨 (비록 관계가 ‘0’이더라도) 그림에서는 연결선이 없는 것은 Similarity ‘0’
- 그림을 보면 연결선이 없는 부분도 있다. 사실 트랜스포머의 셀프 어텐션은 관계가 매우 적은 경우에도 관계가 있다고 본다(관계가 없다고 하지 않는다)
Encoder and Encoder-Decoder Attention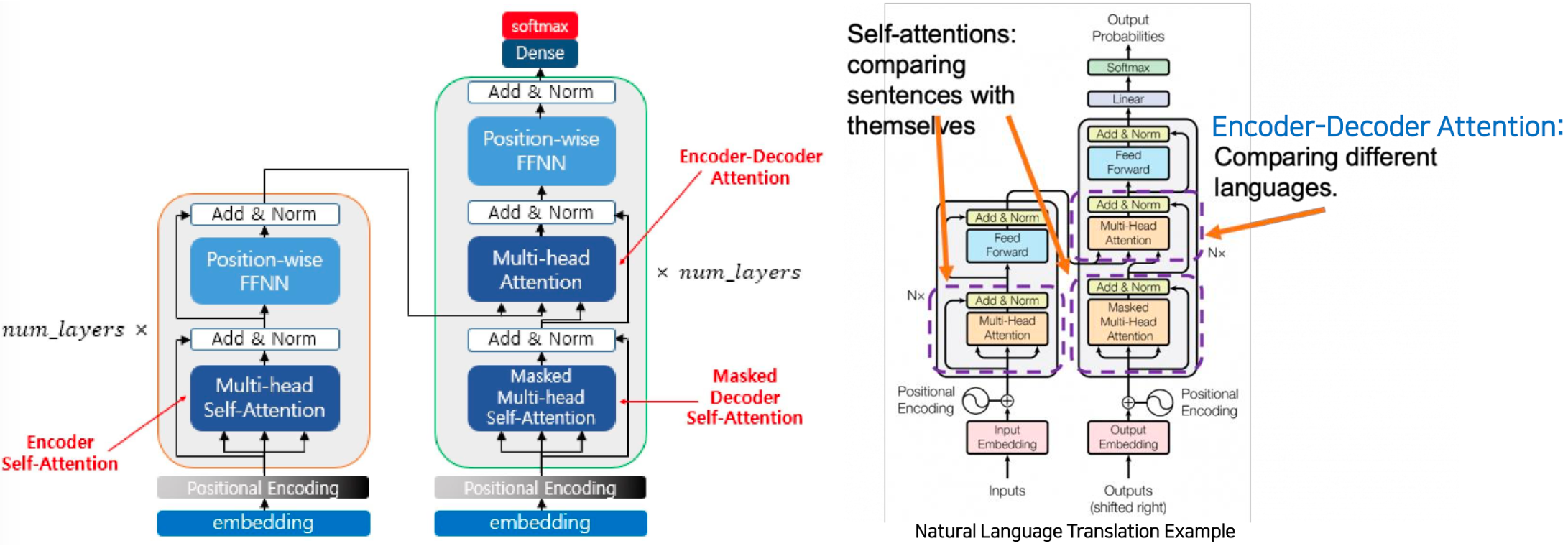
- 트랜스포머 아키텍처는 3가지 종류의 다른 Attention 을 사용한다.(중요)
- 인코더
- Multi-head Self-Attention = Encoder Self-Attention
"영어문장"(자기자신) 에서 어디에 어텐션을 주어야하는지 자기자신과 self 비교하여 답이 여러개(멀티헤드)로 나뉠 수 있다.
- Multi-head Self-Attention = Encoder Self-Attention
- 디코더
- Multi-head Self-Attention = Masked Decoder Self-Attention
디코더의 입력으로 들어온 정답지 "프랑스어 문장" 에서 디코더의 위치 이후의 토큰들을 Masking 하여 자기자신인 "영어문장" 과 대조해 Attention 을 구하는 것이다. - Multi-head Attention = Encoder-Decoder Attention
- 인코더에서는 입력 문장(영어 문장)을 토큰화하고 각 토큰을 임베딩 벡터로 변환합니다. 이러한 임베딩 벡터는 Multi-head Self-Attention 계층에 입력으로 주어져 입력 문장 내의 토큰 간의 상호 작용을 모델링합니다. 이 과정을 통해 얻은 결과는 "context vector" 또는 "인코더의 출력"으로, 입력 문장의 정보를 요약한 것입니다.
- 디코더에서는 프랑스어 문장을 생성하는 작업을 수행합니다. 디코더의 현재 위치에서는 생성할 프랑스어 문장의 이전 단어를 인코더의 출력과 유사한 방식으로 임베딩 벡터로 변환합니다. 그런 다음 이전 단어의 임베딩 벡터와 인코더의 출력 간의 어텐션을 계산하여 현재 위치에서의 입력 문장(영어)과 출력 문장(프랑스어) 간의 관계를 모델링합니다. 이러한 어텐션을 사용하여 다음 단어를 예측하고 번역 작업을 수행합니다.
- Multi-head Self-Attention = Masked Decoder Self-Attention
- 인코더
Query-Key-Value in Attention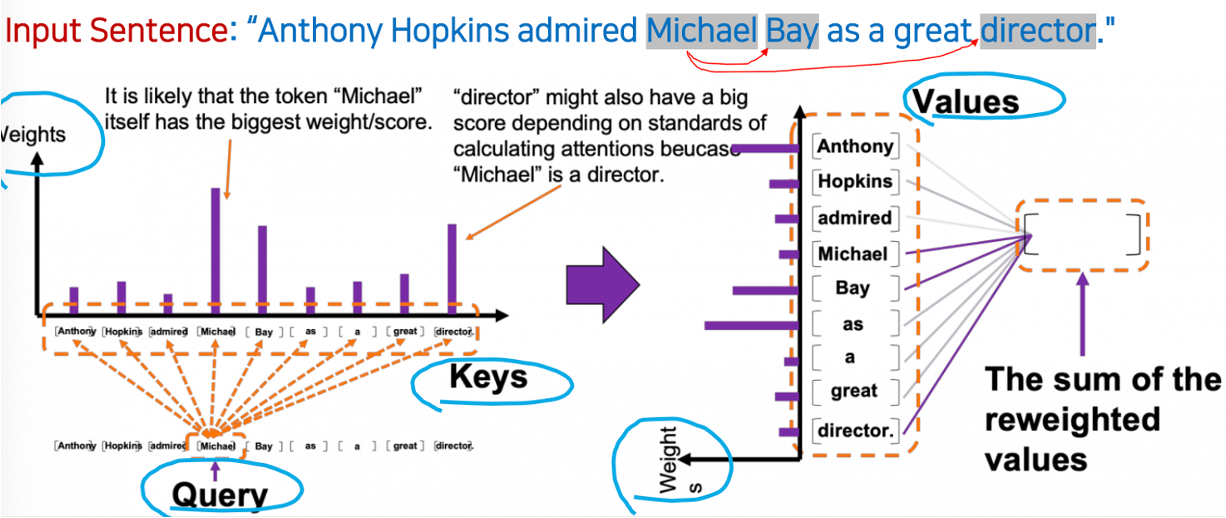
DBMS 와의 차이
- DBMS 에서는 쿼리를 적용하게 되면 key 를 1개를 찾지만, 트랜스포머의 어텐션에서는 매칭되는 것은 모조리 찾아줌 (1개가 아님 - 연관성이 있는지 없는지 모두 찾아줌.)
Query 와 Keys
- 위 문장이 Tokenization 을 통해 단어로 쪼개지고, 이 단어 하나하나가 Query 이다.
- 쿼리 토큰을 모든 키 토큰과 비교한 후 가중치에 따라 값이 결정된다(attention=relation)
- Multi-head Self-Attention 이기 때문에 Query 와 Key 가 같고, 하나의 쿼리 토큰에 대해서 9개의 키 토큰과의 similarity 를 계산하므로, 따라서 총 9 x 9 = 81 개의 쿼리가 생성됨.
- 쿼리 토큰이 'Michael'일 때, 'Michael', 'Director', 'Bay' 키 토큰은 쿼리 토큰 'Michael'과 밀접한 관련이 있기 때문에 비중(점수)이 클 가능성이 높다.
Keys 와 Value
-
value 라는것은 찾고자 하는 단어나 값을 리턴해주는 것인데 셀프 어텐션이니까 value 도 쿼리와 key 와 같이 같은 문장을 사용하고, 그 사이에 설정된 weight 값들을 그대로 사용한다.
-
쿼리와 key 의 관계처럼 values 또한 similarity 를 구하는 과정 -> 한번 더 해준다 reweighting
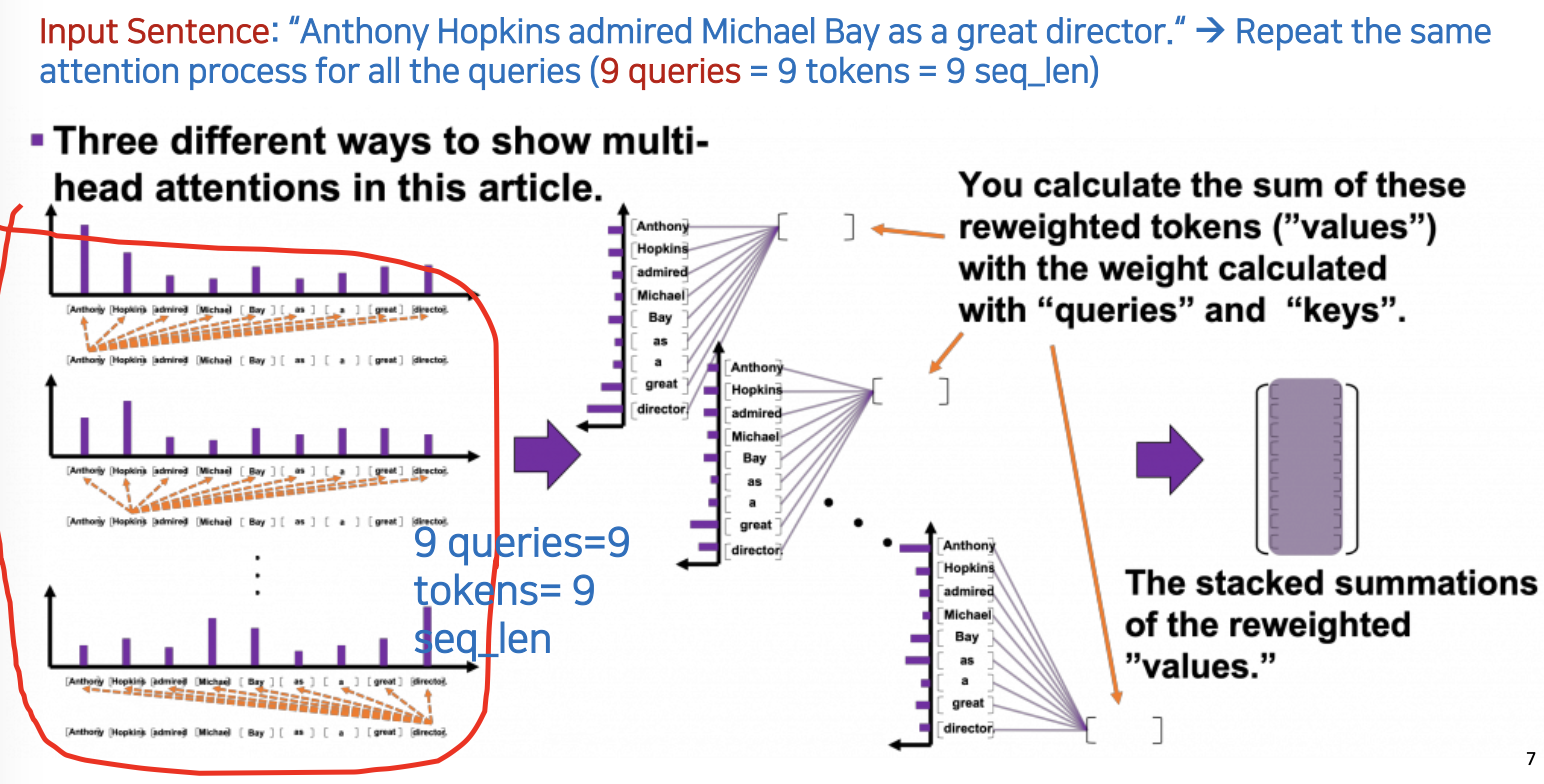
- 앞에서는 'Michael' 이라는 토큰 하나만 가지고 했었는데, 이 과정을 모든 9개의 토큰을 대상으로 반복해야함 (9개의 멀티 헤드인셈)
정리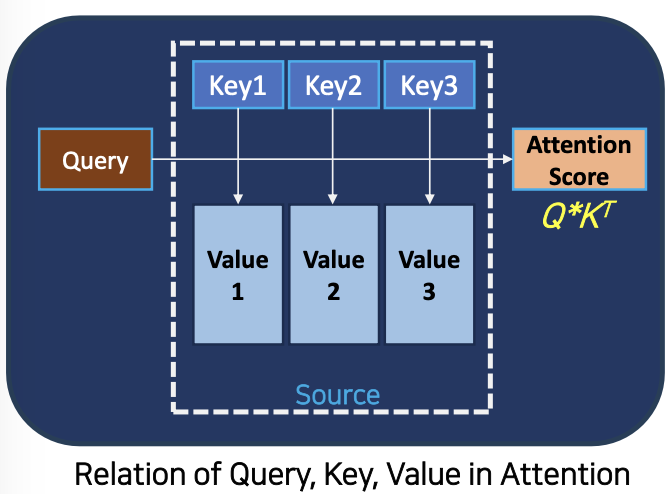
- 값은 어떻게 계산되는지
- Attention Function 은 주어진 쿼리와 모든 키 사이의 각 유사성을 계산합니다
- 그러면 Attention은 유사성을 가중치로써 모든 키에 매핑된 값에 할당하고 모든 가중치를 합산/반환합니다
- 리뷰: DBMS 에서 쿼리, 키, 값:
- 쿼리: 중간고사 성적이 어떻게 되나요?
- DBMS 는 쿼리에 대해 하나의 key 값에 해당하는 value 를 찾는 것.
- Query, key, value
- Q= query : Source Token (찾고자 하는 정보. 찾는 정보)
- K=Key : Target Tokens (Query 와 비교되는 Tokens. Query와 비교한 Target Tokens, key가 가중치를 받는 경우)
- V=Value : 유사도 점수(가중치를 반영한 유사도 점수
- Attention 에서 모델은 키와 쿼리를 비교한 후 유사성 점수를 가진 모든 키를 반환하지만 DBMS는 일치하는 쿼리-키 쌍(튜플) 하나만 반환합니다
쿼리(Query)와 키(Key) 행렬을 내적(dot product)하면 어텐션 스코어(attention scores = )가 생성됩니다. 이 스코어는 각 쿼리와 각 키 간의 관계를 나타내며, 어떤 키에 더 집중해야 하는지를 결정하는 데 사용됩니다.
어텐션 스코어를 소프트맥스(softmax) 함수를 사용하여 확률 분포로 변환합니다. 이렇게 하면 각 키에 대한 가중치(어텐션 가중치)가 생성됩니다.
어텐션 가중치를 사용하여 값(Value) 행렬과 가중합을 계산합니다. 이것이 어텐션된 값(Attention-weighted values)을 나타내며, 쿼리와 키 간의 관련성을 기반으로 값을 조정한 결과입니다.
따라서, 쿼리와 키를 내적하여 얻은 가중치를 사용하여 값을 가중합하여 어텐션된 값을 계산합니다. 이 어텐션된 값을 보통 "reweighted values" 또는 "어텐션 값(Attention values)"이라고 합니다.
이러한 각 밸류의 토큰(reweighted values)을 다 더해준다.
Positional Encoding (Sinusoid Positional Embedding) in Transformer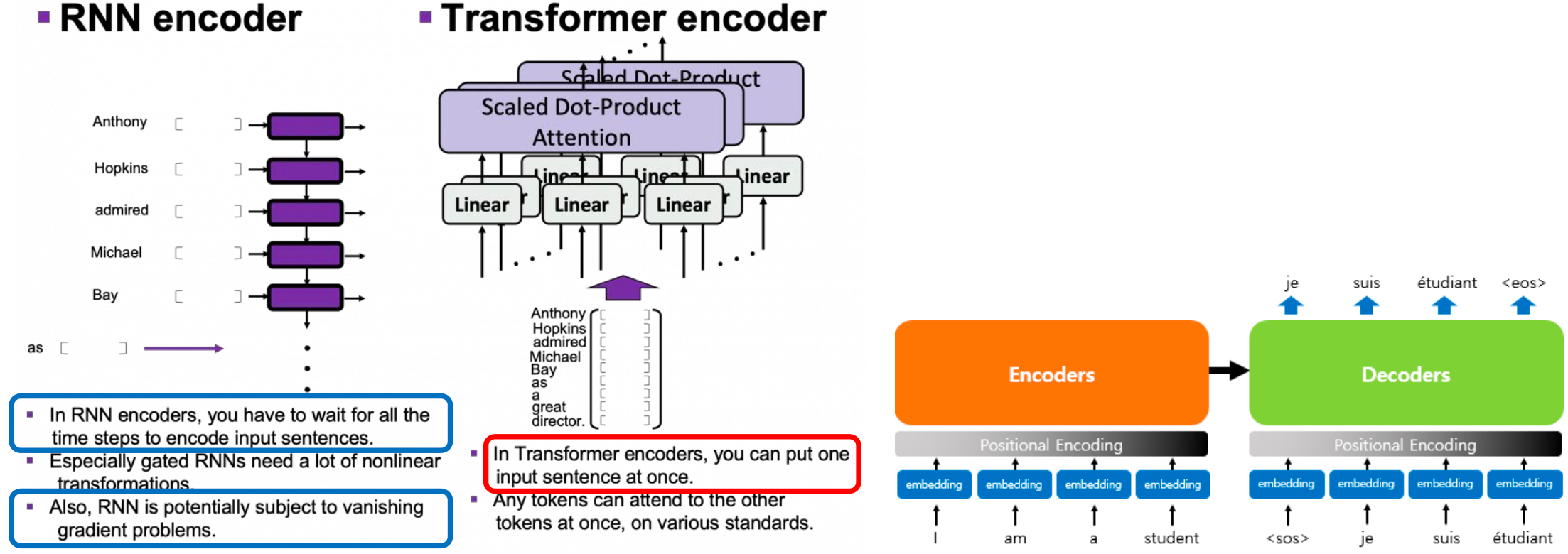
RNN 기반의 인코더와 트랜스포머의 인코더 비교
- RNN 기반 Seq2Seq 에서는 토큰(단어)이 순차적 으로 입력되므로 모델이 토큰 위치 정보(Advantage)를 유지할 수 있습니다
- 하지만 활성함수를 반복적으로 사용하면서 gradient vanishing 문제가 있어 학습이 잘 되지 않는다는 단점이 존재.
- 그러나 Transformer에서 토큰(word)은 병렬적 으로 동시에 입력되므로 모델이 토큰들의 순서를 지킬 필요가 없지만, 모델이 토큰 위치 정보를 기억할 수 없다(단점)
- 멀티헤드를 사용할 수 있는 장점은 있다.
어떻게 그 단점을 극복할 수 있을지
- 각 토큰의 위치를 기억해주기 위해 추가적인 매트릭스 사용하는 positional encdoing 이 있다.
- 임베딩 : I 라는 단어를 숫자로 변환
- 임베딩 된 것을 포지셔널 인코딩 해줘야 각 토큰들의 위치 정보를 포함시킬 수 있다.
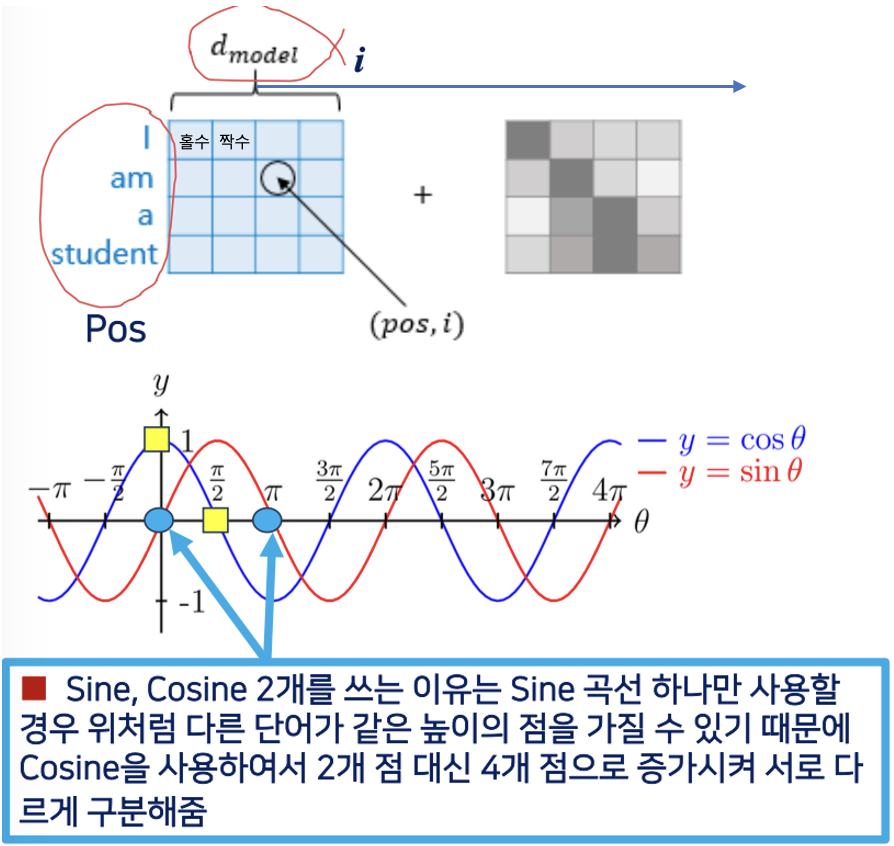
- In Sinusoid Positional Embedding 에서는 사인과 코사인의 두 가지 함수를 사용합니다
- Pos : 입력 문장에서 임베딩 벡터의 위치, 즉 단어의 위치
- : 차원이 크기
- ex) i 라는 단어는 512 라는 크기의 칼럼을 가졌다 (0111011 .. 식으로 테이블에 약속된 값)
- : 임베딩 벡터에서의 차원의 인덱스
- ex) "am" 의 경우 (2,i)
- 위치에 따라서 홀, 짝으로 입력하되 위의 수식을 이용
- Sine, Cosine 2개를 쓰는 이유
- 사인 커브 하나만 가지고 입력을 취해서 위치를 정할 수 있지 않을까 생각해볼 수 있지만
- 사인 함수 하나만을 사용한다면, sin에서 y값이 같아지는 경우(다른 단어가 같은 높이의 점을 가질 수 있음)가 발생!
- 따라서 cosine 을 추가로 사용
- 왜 10000 제곱을 해줄까?
- 위치 정보를 주기적인 사인 및 코사인 패턴으로 인코딩하기 위한 하이퍼파라미터로 사용
- 을 나눠줄까? 왜 포지션을 나눠준것을 사인 코사인에 대입할까?
- 홀수 부분에서는 코사인을 사용하고, 짝수 부분에서는 사인을 사용하는 이유는 무엇일까?
는 하이퍼파라미터인데 트랜스포머에서는 이 크기를 512 개를 사용한다.
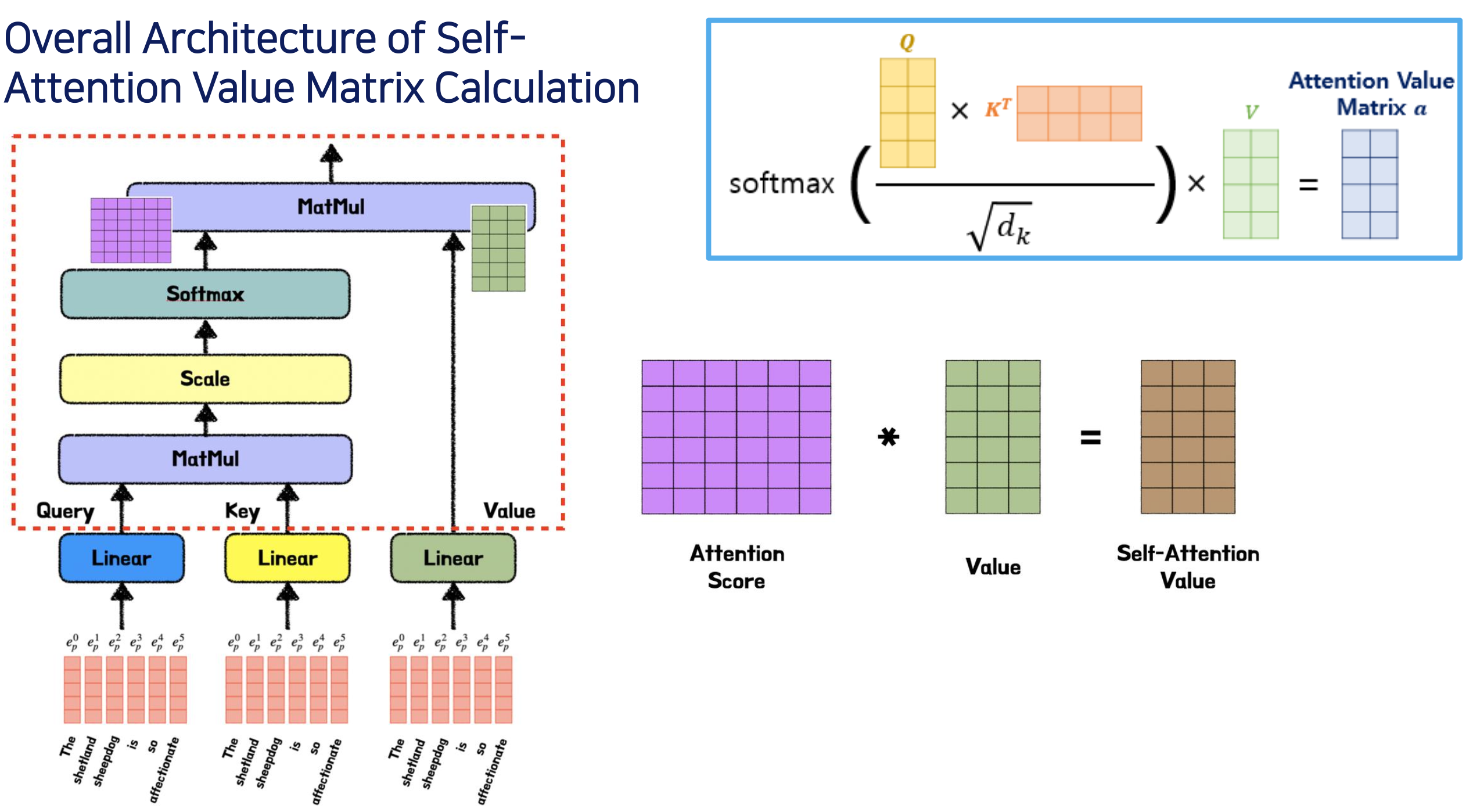
Self-Attention Value Matrix Calculation (Scale-dot Product Attention)(가장핵심)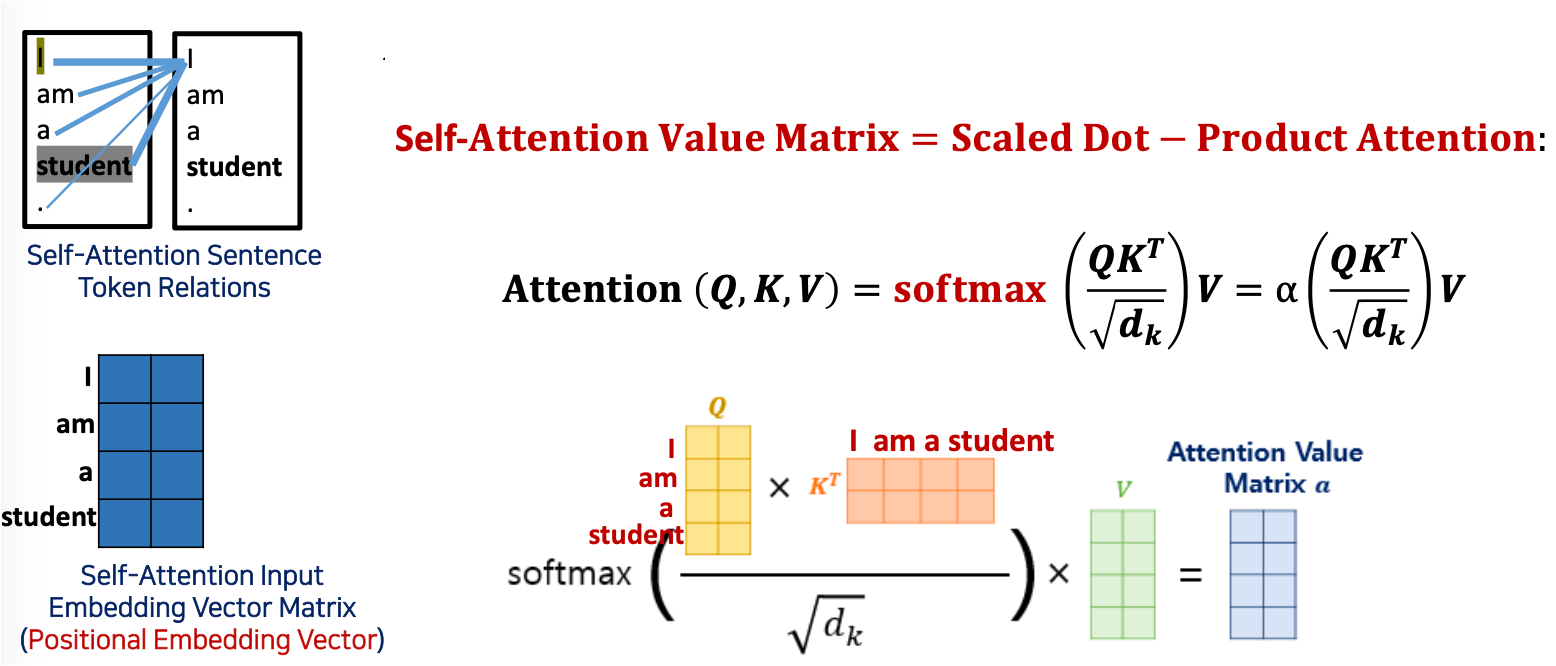

- 토큰 하나에 대하여 공식에 적용해 어텐션 값을 구한다. 그렇게 계산된 최종 결과값을 attention value matrix 라고 부른다.
- Query-Key Product () = Attention Score
- 모든 Query와 모든 Keys (Tokens)간 Attention (Similarity=Relation)을 얻기 위해선 Product를 해 준다(큰 값이 High Relation)
셀프 어텐션이기 떄문에 와 는 같고 둘을 내적. 와 는 포지셔널 인베딩을 거쳐 converting 을 해놓은 상태인것.
- 스케일 다운
- Attention Score의 값들이 너무 크면 학습이 잘 되지 않음 (수렴이 잘 되지않기 때문에). 따라서 ( = dimension of )를 나누어서 값을 줄여 줌 (Scaled-down)
- multi-head attention value matrix 의 차원
- : 는 모델의 칼럼 부분인, 벡터의 매트릭스의 크기인데, 멀티 헤드의 경우는 칼럼의 크기 을 헤드의 개수만큼 나눠줘야함 -> 그러면 가 나오는데, 이것을 라고 한다.
- 그냥 쉽게 말해서 K 가 V와 크기가 같기 떄문에 를 그냥 k의 dimension 이다 라고 이해
- 헤드의 개수로 나눠주는 이유?
- 예를 들어, "i" 라는 단어의 이 64개의 컬럼이라면, 남은 모든 헤더 ("am", "a", 'student")에 대해서 총 64 + 64 + 64 + 64 = 512 개가 되기 때문에, 헤더 숫자만큼 1/4 로 나눠야 한다.
- 루트를 씌워주는 이유?
: Q와 K^T 를 곱해주다보니, 너무 큰 matrix 가 탄생해버림. 따라서 너무 크면은 학습이 잘 안된다. 따라서 루트로 나눠줌(스케일을 다운시켰다고 함) 따라서 scale dot product 인것
- Softmax 적용
- softmax 에 대입해 각 토큰을 확률로 바꿔준다.
- Value 곱
- 그런 다음 아래와 같은 그림의 Value 매트릭스를 한번 더 곱해는 것을 reweight value matrix 라고 부른다.
최초의 value matrix (학습 초기) 는 Q 와 K 와 똑같은 것이다. (훈련전에 똑같은 값으로 출발한다.)
Self-Attention 또는 Scaled Dot-Product Attention의 경우, 일반적으로 Q, K, V를 모두 동일한 가중치 행렬로 초기화합니다. 이것은 트랜스포머 모델의 주요 특징 중 하나이며, 초기에 이러한 가중치 행렬을 무작위로 설정
(정정) dimension 을 줄이기 위해서 sqrt 를 씌워주는이유: 차원을 출여주는 것인지, 아니면 그 각각의 컬럼의 숫자를 줄여주는지? ...(토론방 질문)
왜 루트를 씌우는지? 다른 수식으로 숫자로 줄일 순 없는지?
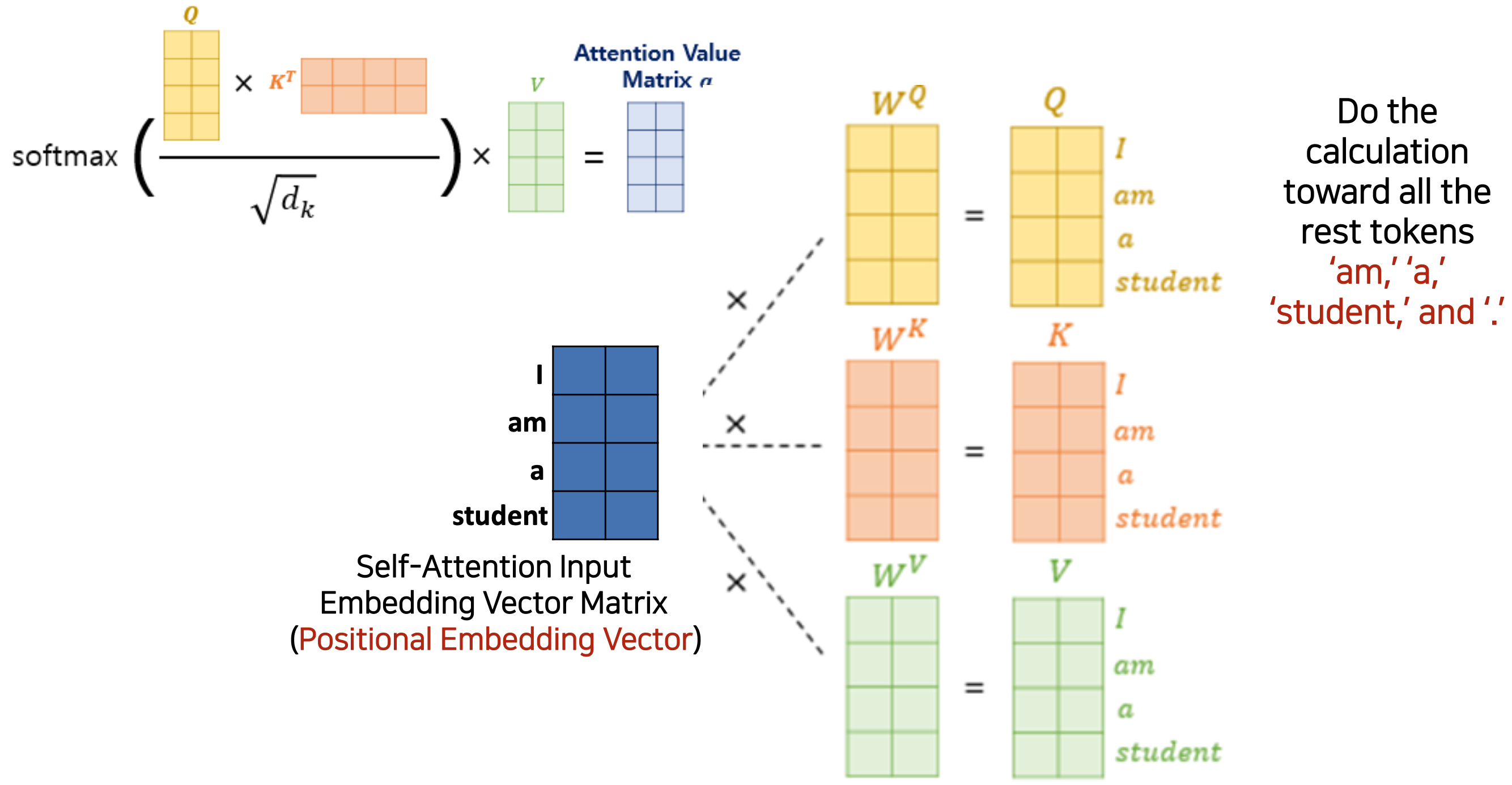
Positional Encoding and Weight Matrix
- attention score () 계산 전에 positional encoding vector input 에 가중치 행렬을 곱해야 한다.
- 가중치 행렬은 임의의 값으로 시작하여 training 을 통해 업데이트된다.
- weight Matrix () 가 변하는 것이고 그런 다음, 그러한 weight 이 곱해지면서, am 에 대한 각 어텐션들이 변경 되는 것이다.
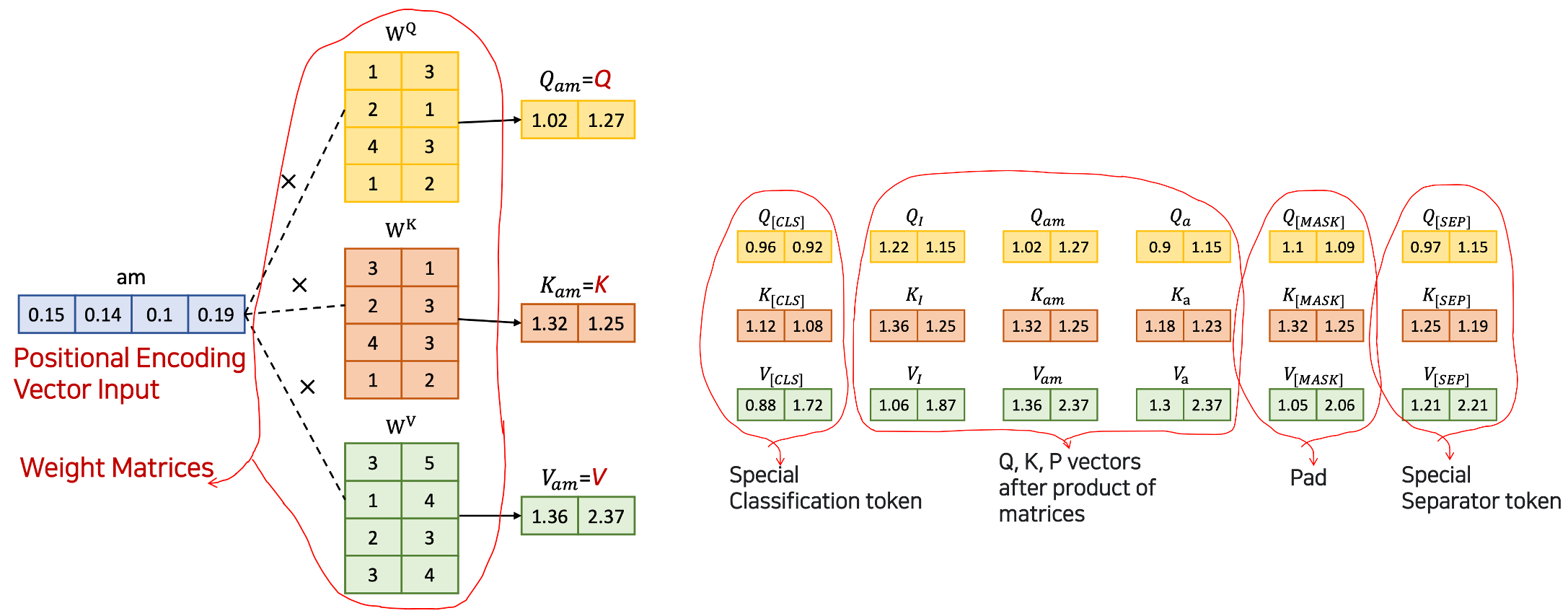
아래의 그림에서 input 이 업데이트 되는 것이 아니라, Weight Matrix 가 업데이트 되는 것.
이 부분 중요

Query-Key Product ()=Attention Score = Weight
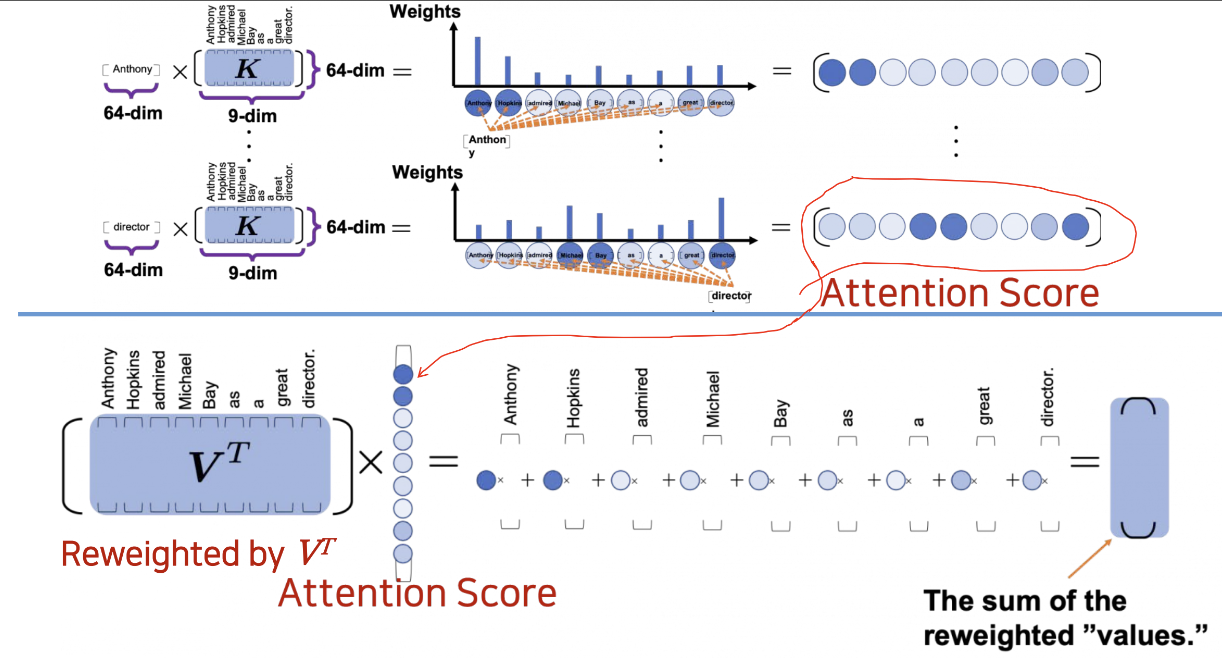
Anthony Hopkins admired Michael Bay as a great director- 1) 첫 번째 토큰 Anthony
- Anthony 라는 토큰의 64개의 컬럼에 대해 Self Attention 이므로 나머지 9개의 토큰과의 attention 계산해야함 (Anthony 라는 단어가 각 단어와의 어텐션이 얼마인가)
- 따라서, key의 차원은 를 사용
attention score's dim =
- 2) ~ 9)
그렇게 이런 과정을 각 토큰 마다 해준다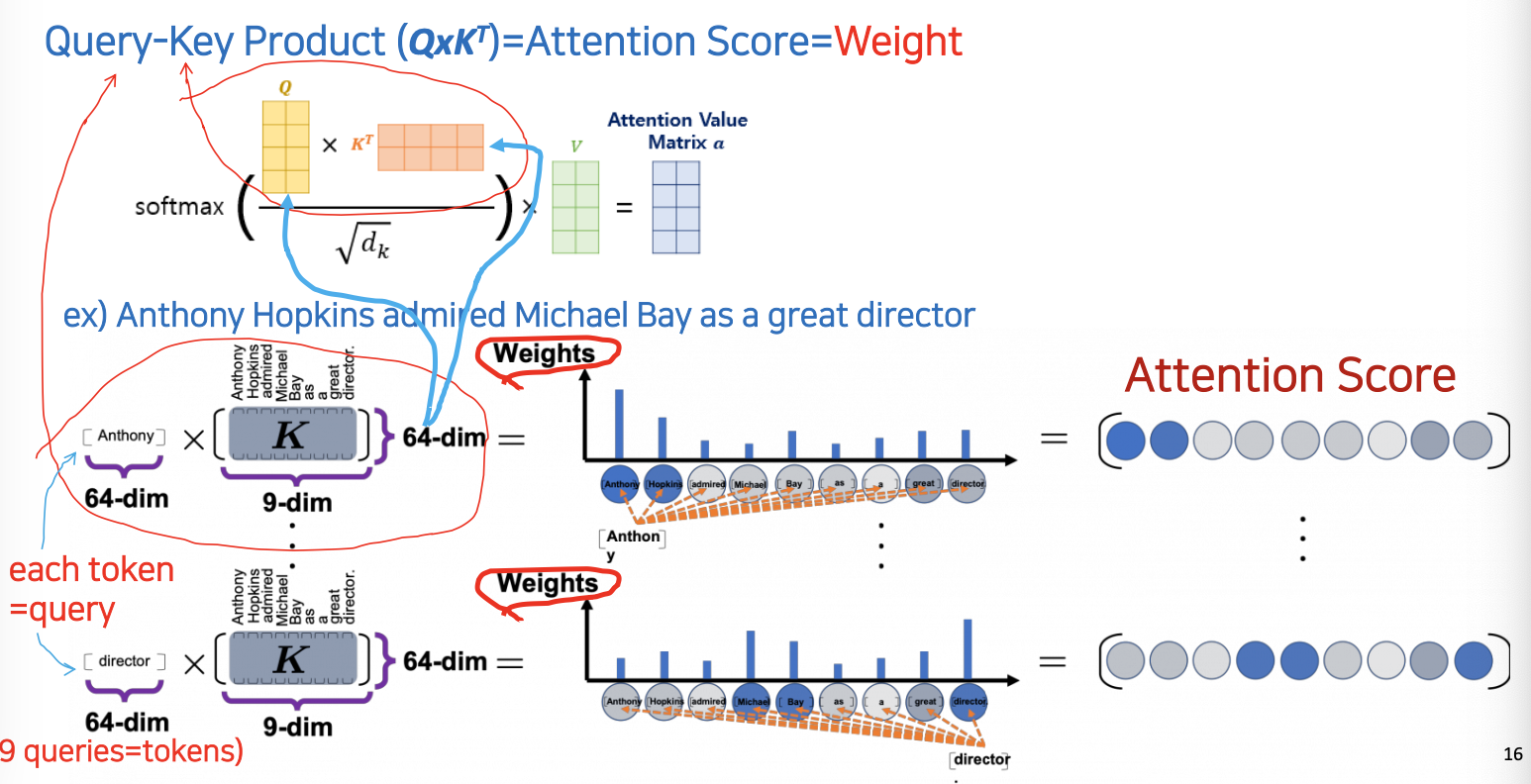
Sum of the Reweighted Attention Values
i am a student라는 문장으로 해도 똑같다.- 첫 번째 Query Token :
i - 모든 Key Token :
i,am,a,student
i라는 Query 토큰과 똑같은 차원의 Key 토큰들을 Transpose 해준 것 을 곱하면(self 이기떄문에 같은것) 128, 스케일 다운시켜서 16- 그 모든 결과들을 소프트맥스에 적용 그 결과들이 하나의 확률 분포(Attention Distribution)를 이룸
- 그 다음에 reweight 를 한번 해주면 마지막으로 attention value 가 나온다.
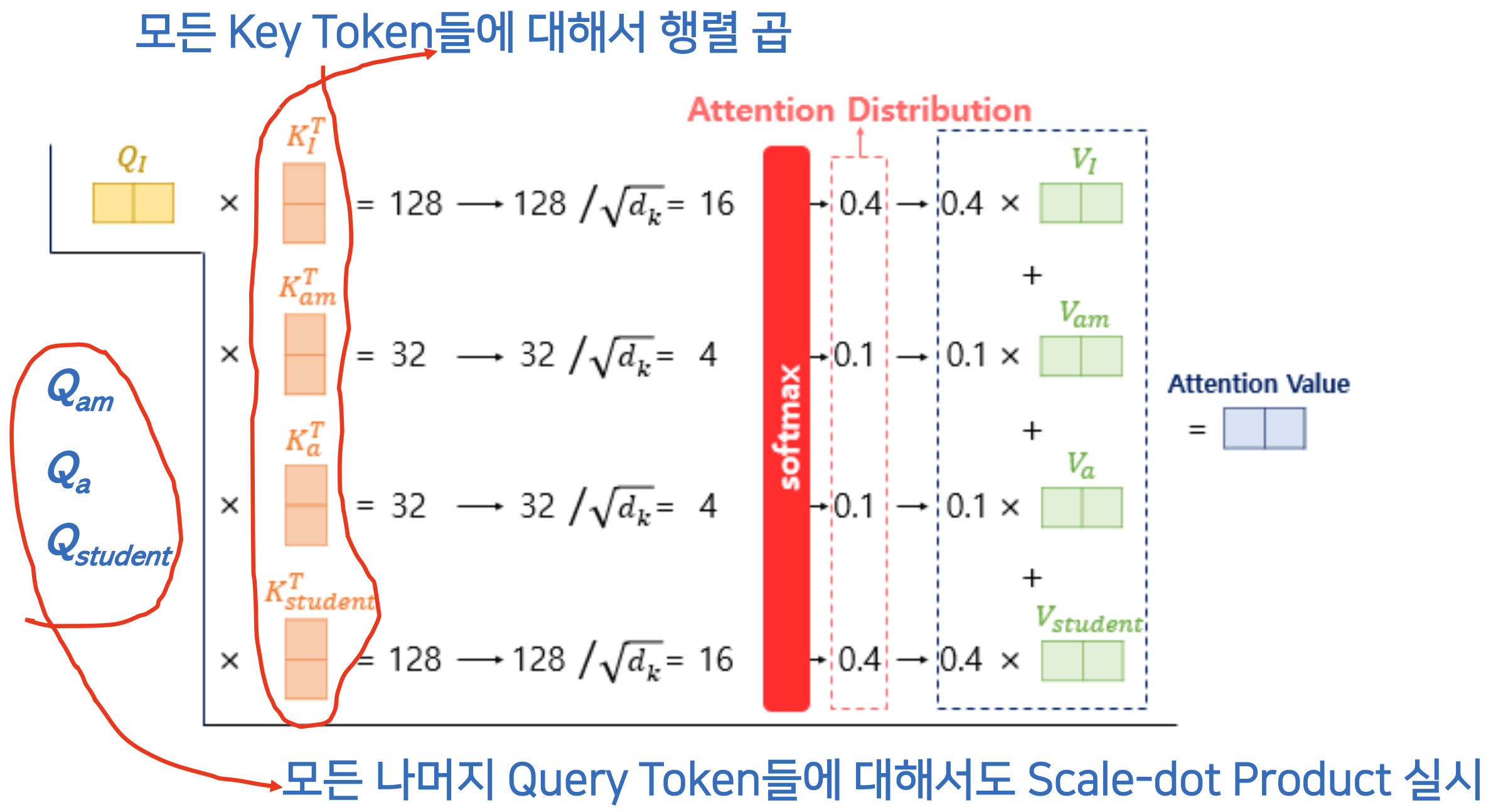
- 첫 번째 Query Token :
- 이제
i만이 아니라,am,a,student도 모두 다 위와같은 과정(Scaled-dot product) 실시- Attention Value for
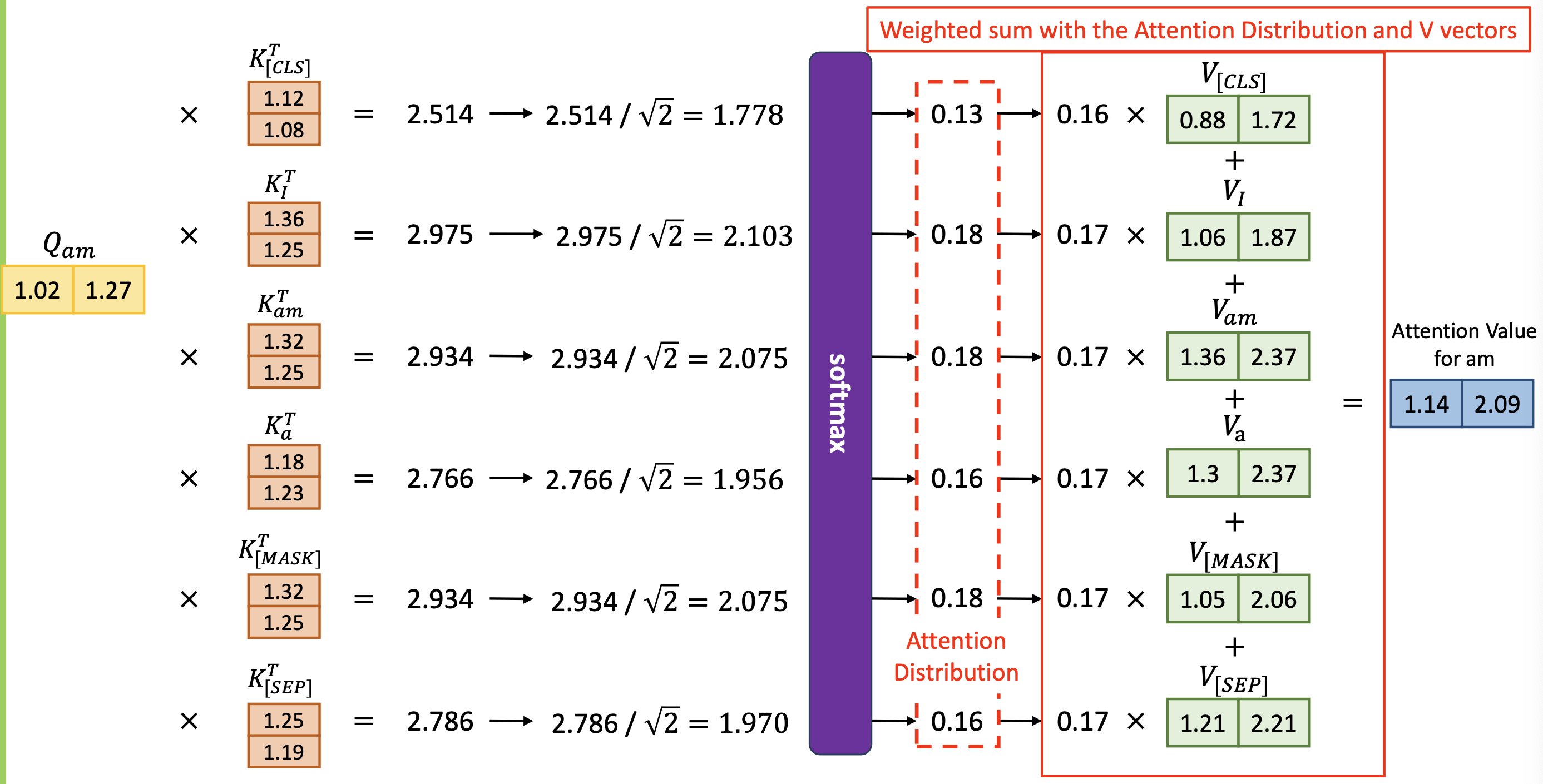
- 마지막으로 attention score 가 나오면. 그 attention score 에 Value 와 곱해주어 reweighted value 그 다음 다 합해줌
- Attention Value for
Attention Score
- Q와 K를 곱하는 이유?
- 위의 식을 빌려서 적용시킨 것이다 다만 를 나눠준것이 추가된다.
- 위 식에서 ||A|| ||B|| 대신 를 사용했다는 것.
- 이론적인 배경은 위와 같고
- 어떤 문헌에서는 softmax 를 적용해주는 것을 알파 표시를 하기도 한다.
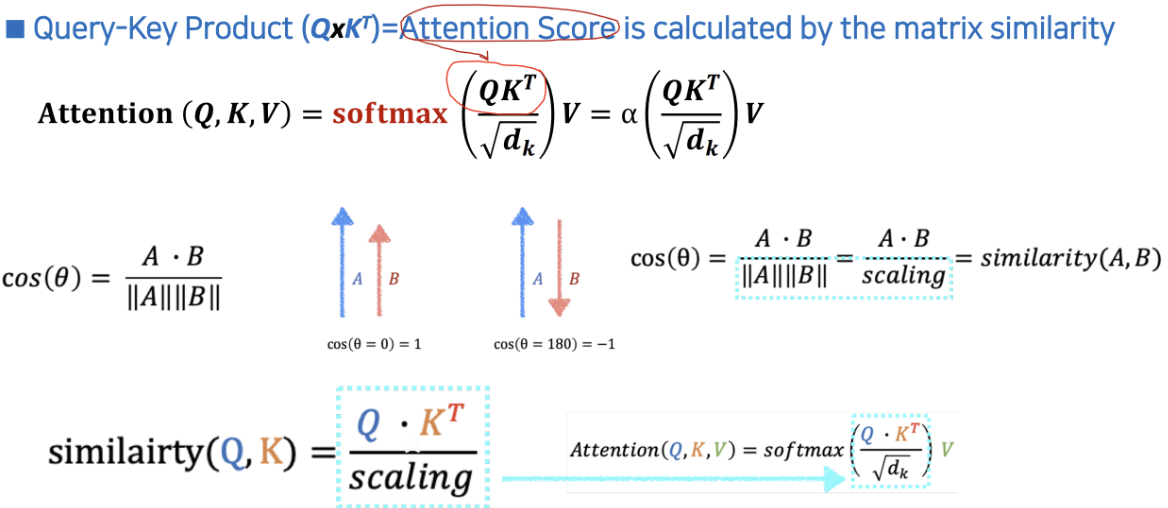
- 어텐션 스코어의 과정 자세히
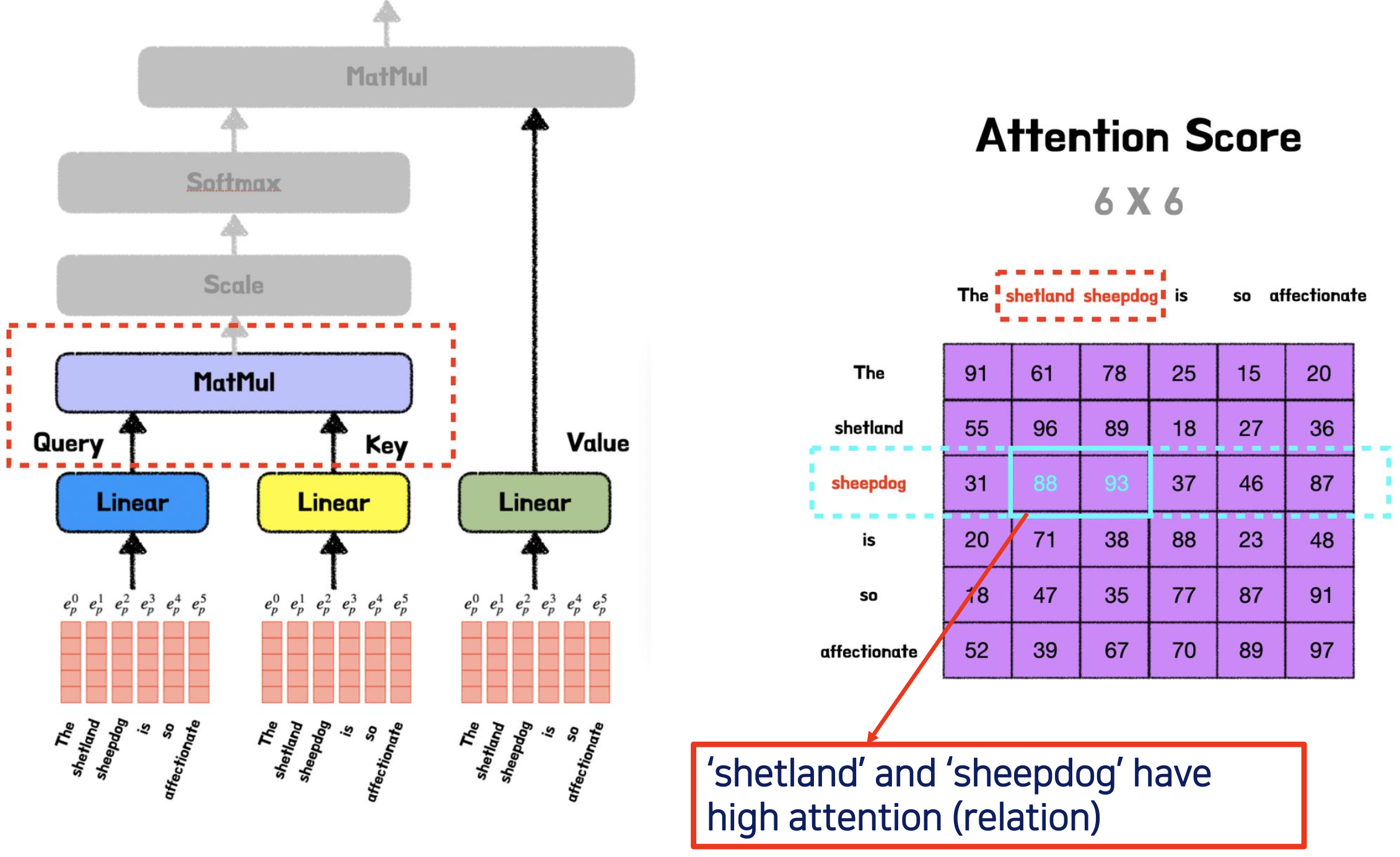
Self-Attention Value Matrix Calculation
i에 대한 Input Embedding Vector가 이라고 가정 (실제는 이것보다 훨씬 큼) 트랜스포머는 512개가 각각 다른 숫자로 되어 있는 테이블이 있다.- Self Attention 이기 떄문에, 최초 학습을 시작할 단계에서는 모두가 같은 것을 사용한다.
- 하지만, 각각 자신들의 trained weights () 에 의해서 는 다르게 업데이트 될 것이다.
- 아래 그림을 보면, 시작단계에서는 들이 같을 값을 가지는데, Weight 값들이 학습, 업데이트가 되면서, 값들이 (Attention Scores) 다음과 같이 바뀌었다.
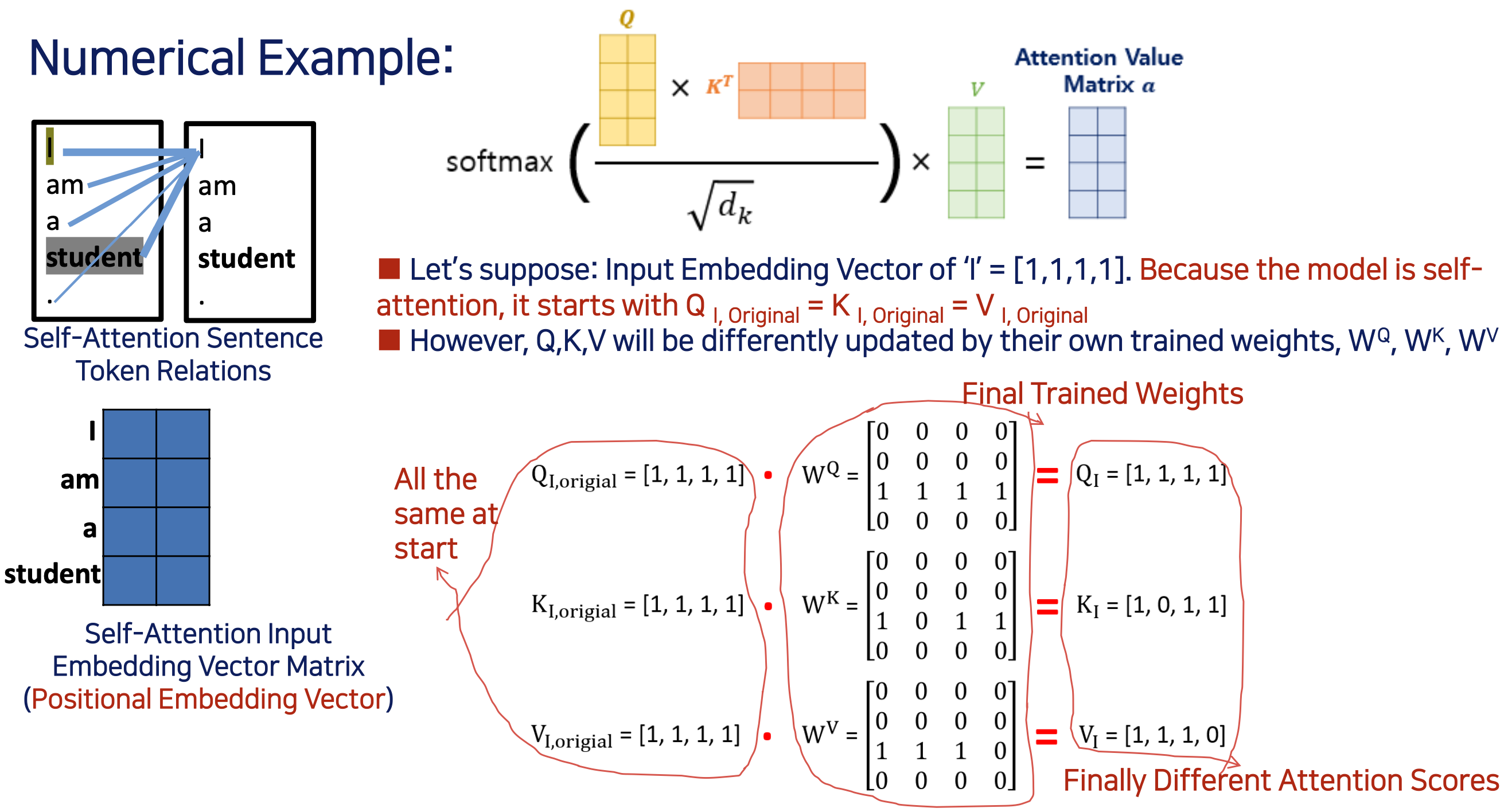
- 아래 그림을 보면, 시작단계에서는 들이 같을 값을 가지는데, Weight 값들이 학습, 업데이트가 되면서, 값들이 (Attention Scores) 다음과 같이 바뀌었다.
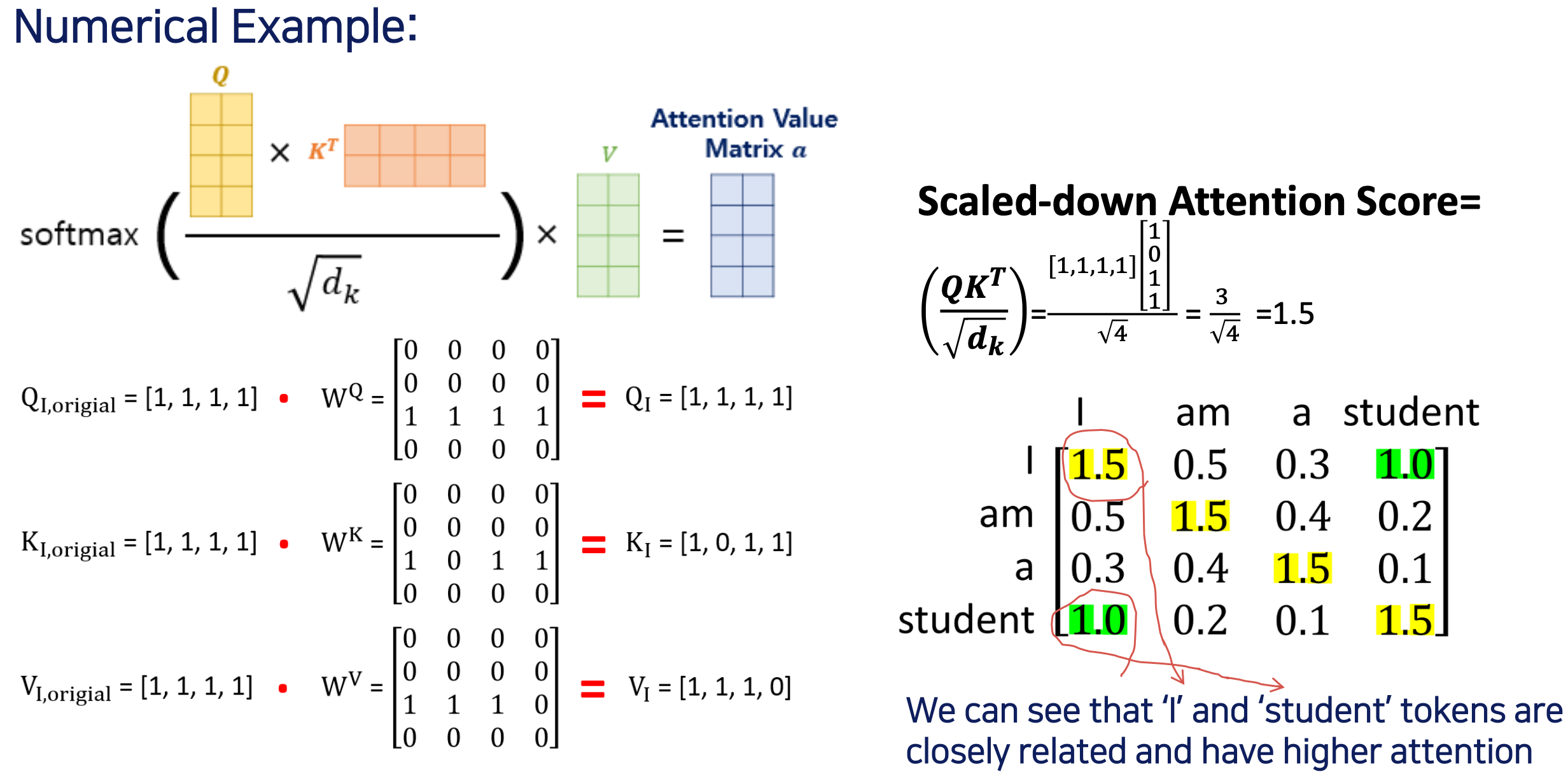
- 구체적으로 숫자를 넣어서 계산
- 처음 Key 의 크기가 4 이니까 루트 4로 나눠준것
- 최종적으로 업데이트 된 것은 I 토큰에 대한 쿼리 매트릭스가 [1,1,1,1] 로 업데이트
- 그다음에 각각 K, V 들도 업데이트 됨.
- 자기 자신에 대한 것은 모두 1.5 가 나옴
- 모두 이런식으로 i 와 student 는 많은 관계가 있으므로 attention 이 1.0 으로 높은 편 이런식으로 weight 값들이 업데이트 된다.
- 그런다음, 모든 엘리먼트들을 소프트맥스 활성함수에 적용시키면 확률값이 나온다.
- value 도 reweighting 해준다, 마지막으로 어텐션 밸류 메트릭스가 나온다.
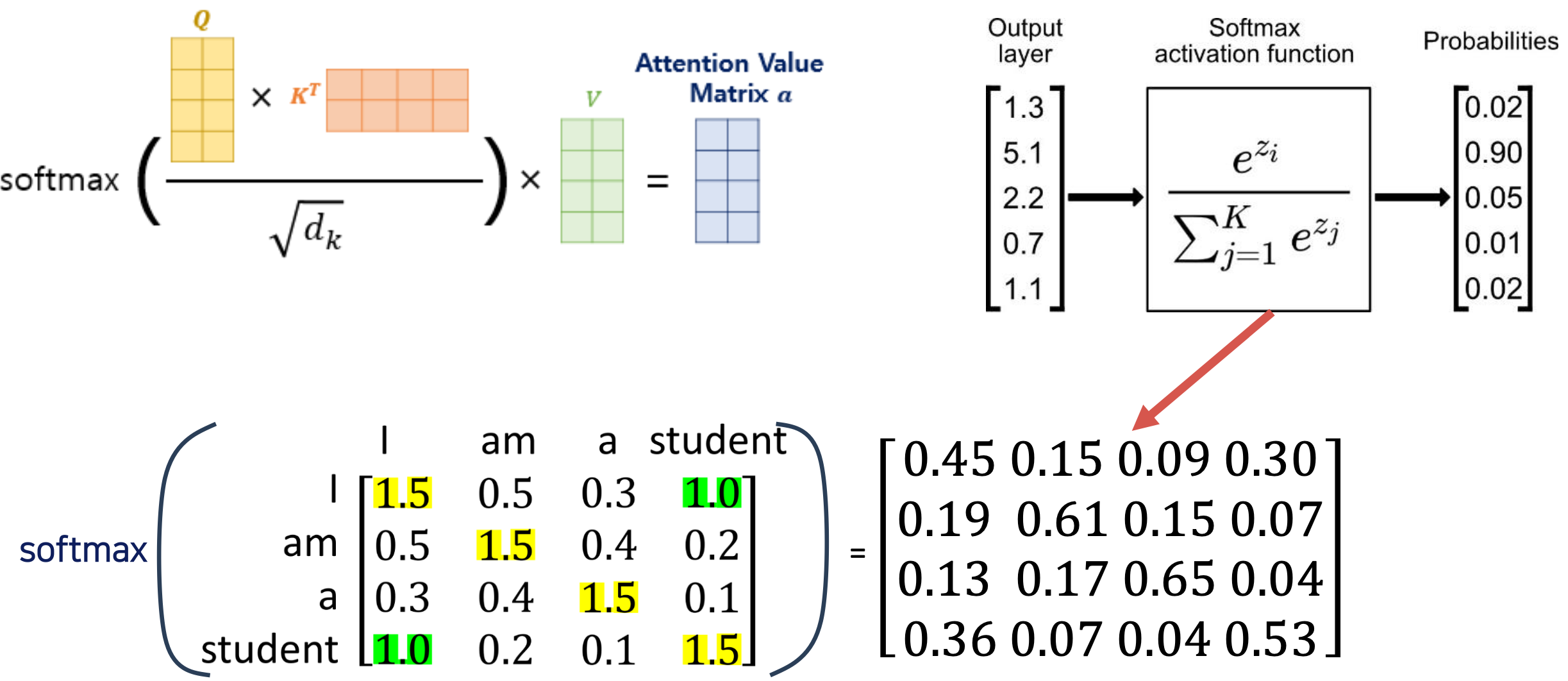
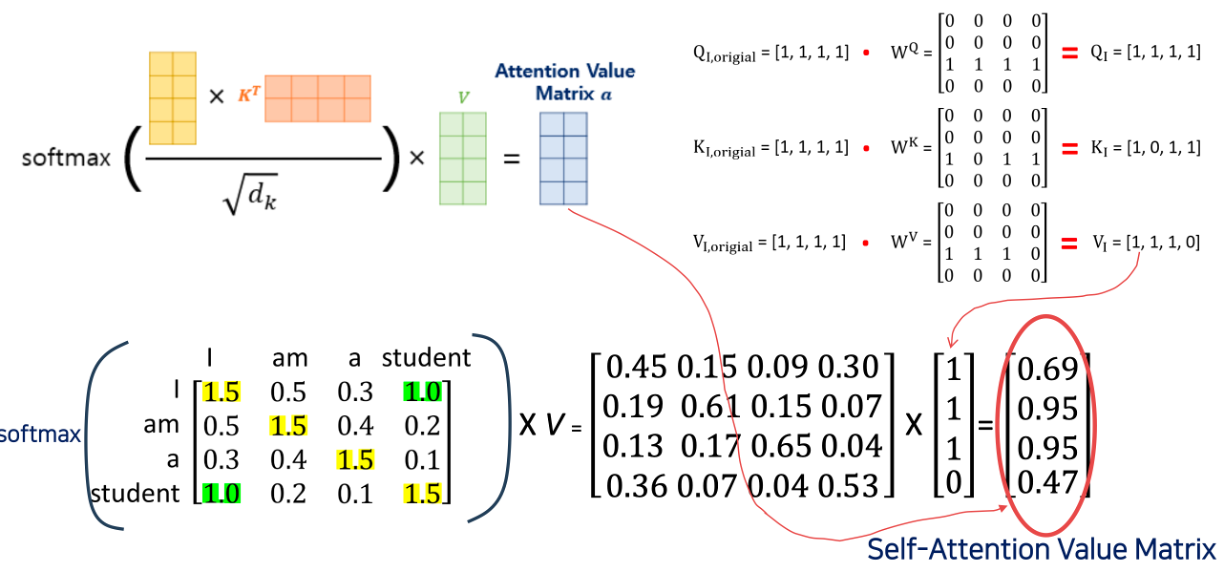
Self-Attention Value Matrix Calculation 의 전반적인 아키텍쳐
- am a student and 에 대해서도 각각 해야된다는 것
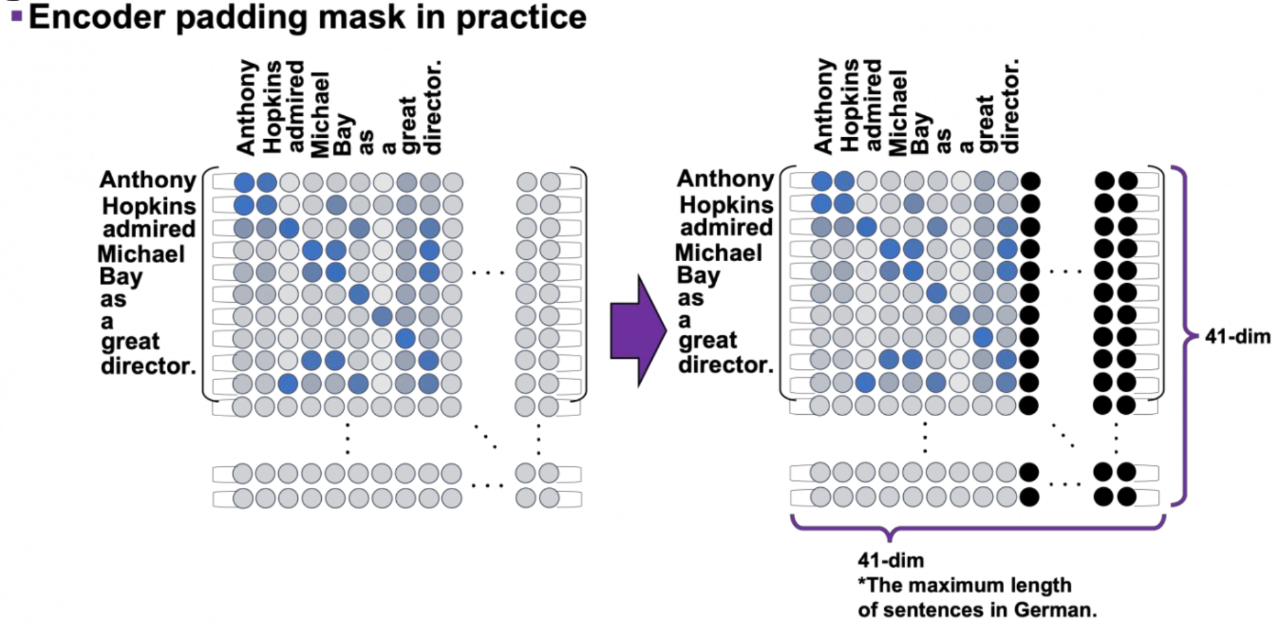
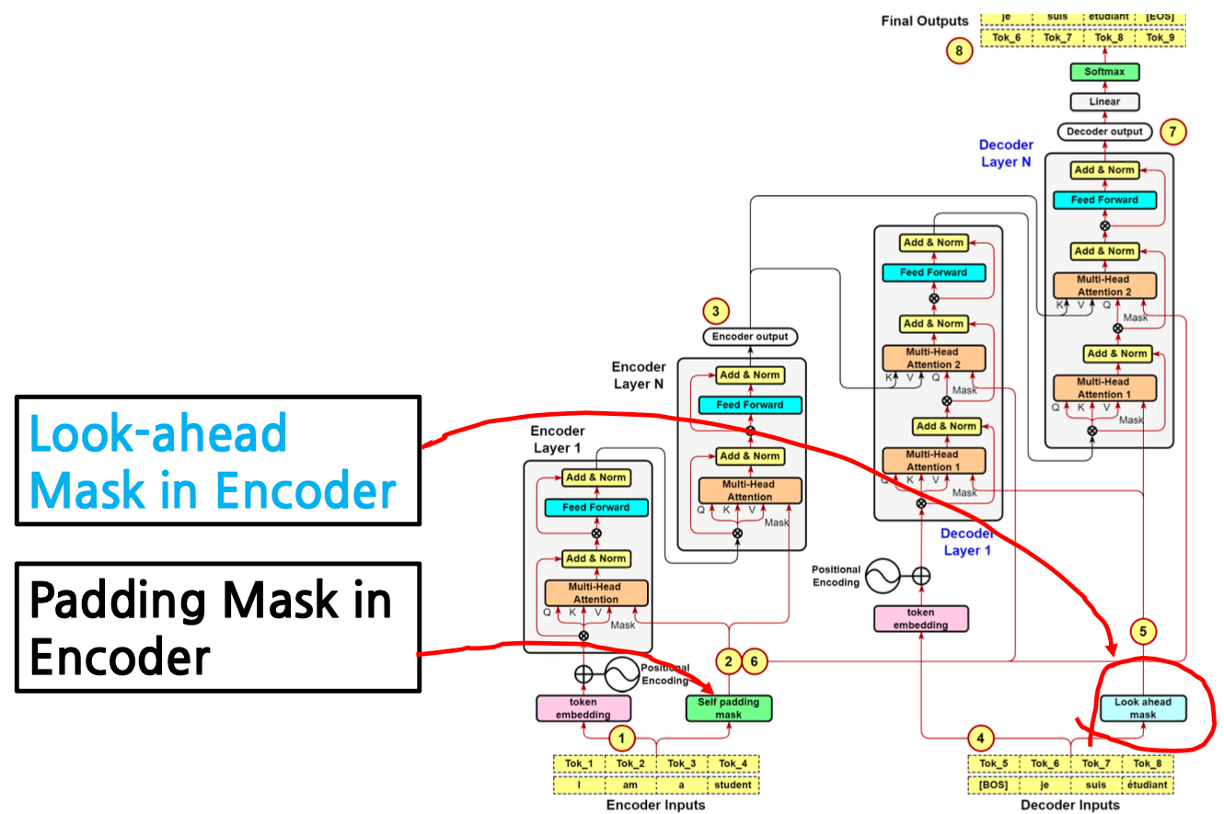
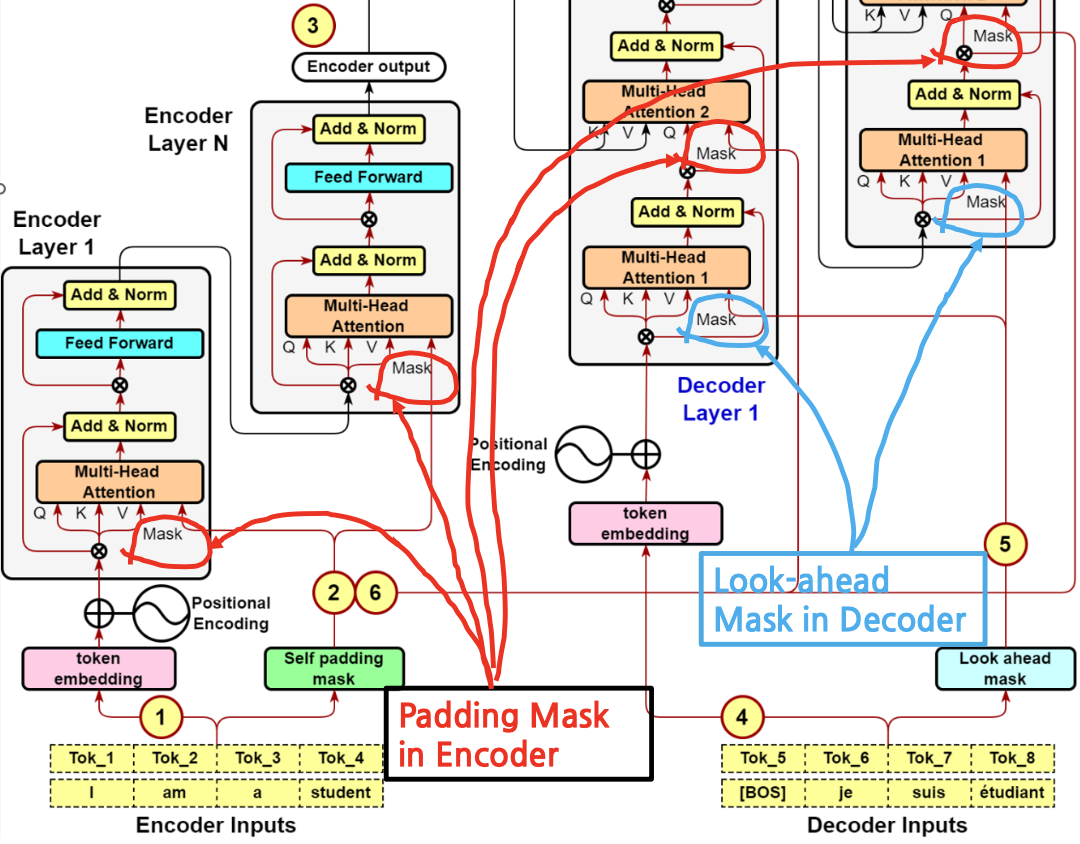
Padding Mask vs. Look-Ahead Mask
Padding Mask in Encoder and Decoder
- Encoder 또는 Decoder 의 input sentence 의 최대 크기가 41 Tokens 라고 가정하자.
만약 실제 input sentence 가 9 Tokens 라면, - 우리가 필요한 pad 는 41-9=31 Tokens 이다. (사용하지 않을 31개의 토큰을 패드로 처리)
- 선택되지 않게 굉장히 작은 음수값을 패드의 값으로 설정
- 오른쪽 위의 Look-ahead Mask 의 경우, 인풋에서 사용하는 Padding Mask 와 다른데,
- 정답을 가리 위해 마스크를 사용하는 것은 동알
- Look-ahead Mask 는 Decoder 에서만 사용
- 영어에서 프랑스어로 번역하는데 있어서 프랑스어를 알려줘야 하는 상황, 즉 디코더에서 사용
- ex) je 가 성공하면 그 다음은 가려서 하고, 그리고 suis 가 성공하면 그 다음은 가리고 이런식
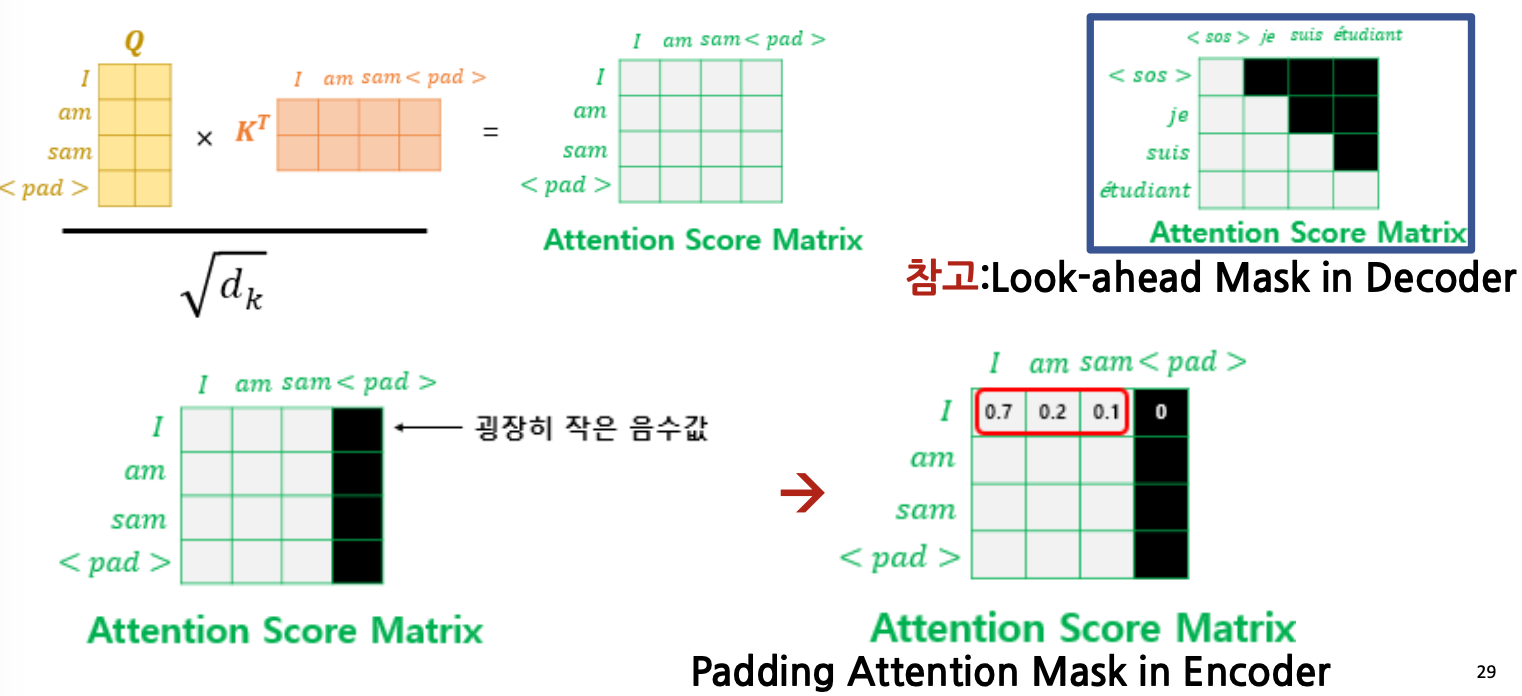
- self padding mask는 인코더의 인풋(영어문장)에서만 사용
- Padding Mask 는 인코더 디코더 모두 사용
- Look Ahead Mask는 디코더의 인풋(프랑스어)에서만 사용
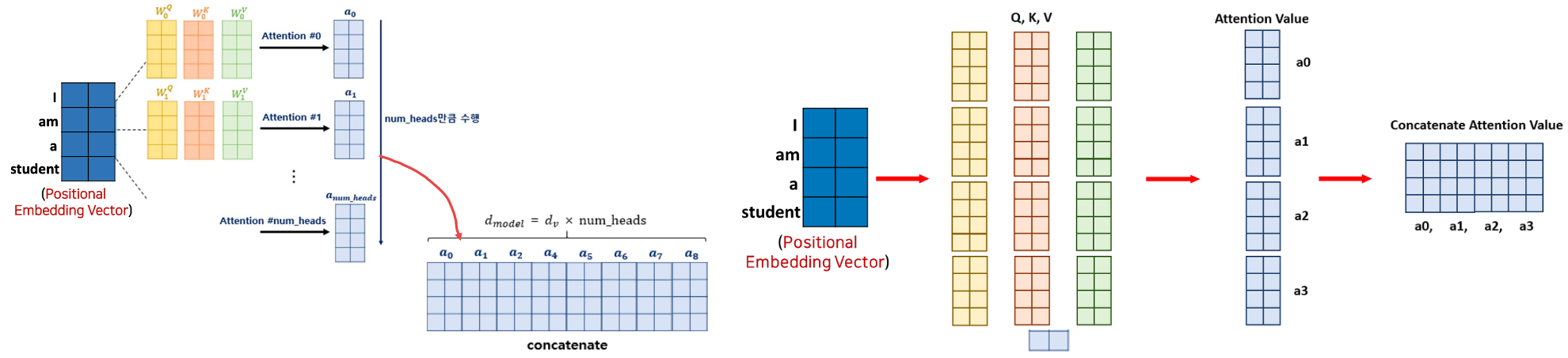
Multi-Head Attention Value Matrix Calculation
- 각 헤드에 대한 Matrix 들을 다 합해준 것이 concatenate$
Encoder-Decoder Attention Value Matrix Calculation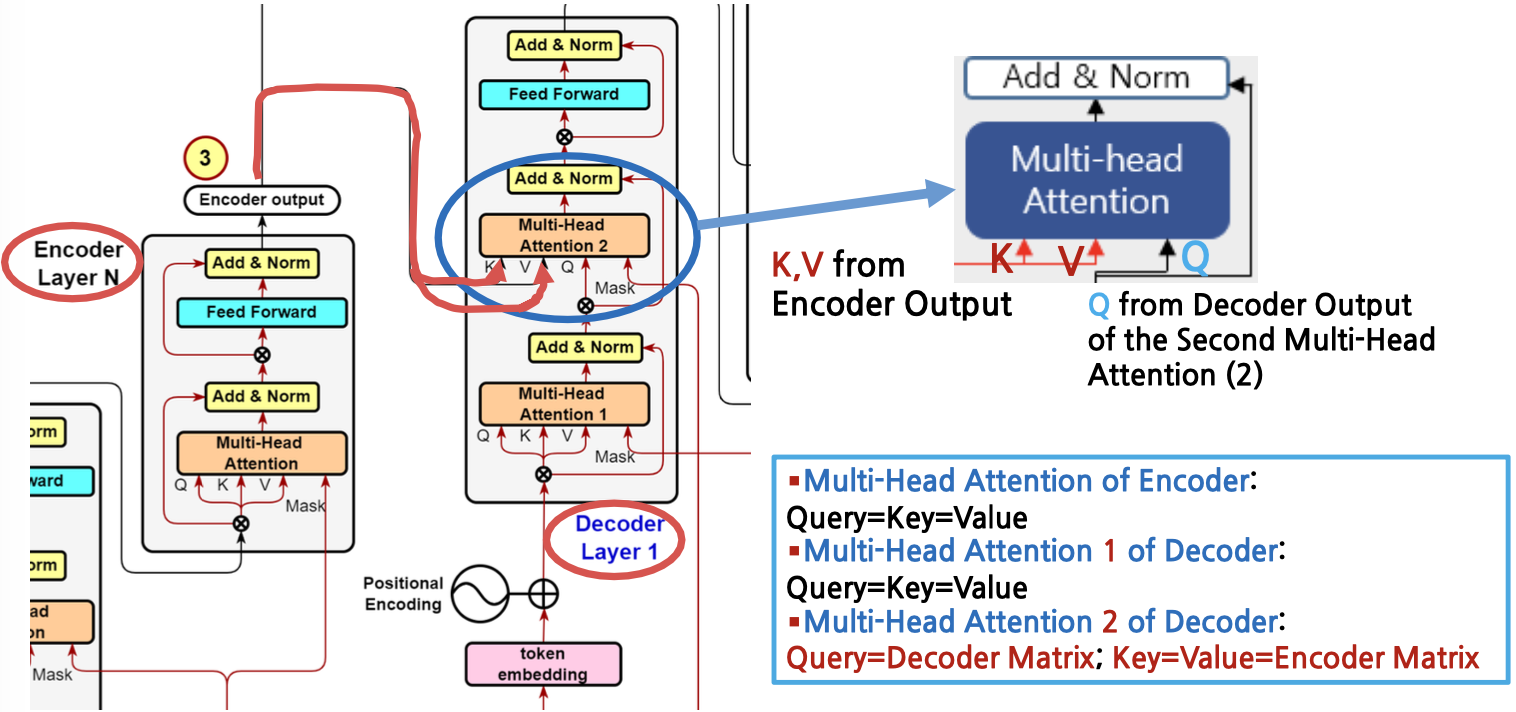
self attention value matrix 구하는 것은 했는데, Encoder-Decoder attention value(디코더에서 인코더가 만나는 부분)는 어떻게 구할것인가?
- Scaled Dot-Product Attention 과 같다. 하지만,
- Multi-head attention of Encoder, Multi-head attention 1 of Decoder
- 얘네들은 둘다 self attention 이기 때문에, 초기 training 시에는 (Query = Key = Value) 와 같이 값이 다 같다다.
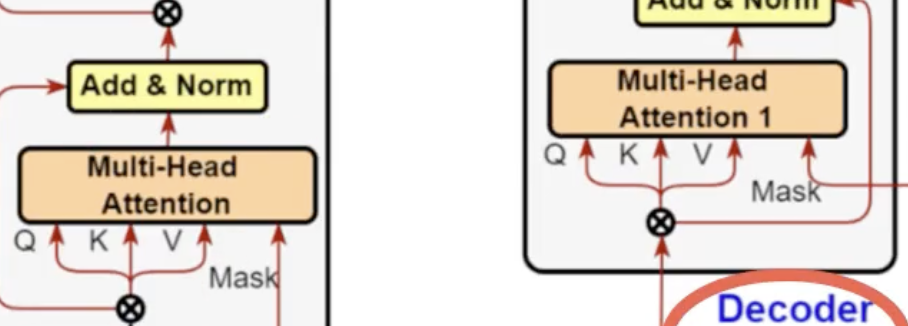
- 얘네들은 둘다 self attention 이기 때문에, 초기 training 시에는 (Query = Key = Value) 와 같이 값이 다 같다다.
- (매우중요) Multi-head Attention 2 of Decoder
- 위의 경우 인코더에서 학습이 완료된 것이 넘어와 입력되기 때문에 training 초기에 값이 다르다
- (Query=Decoder Matrix; Key=Value=Encoder Matrix)
