RNNs
-
RNNs 은 순환 신경망(Recurrent Nerual Network)이다.
-
RNN 은 시퀀스 데이터(Sequence data) 를 모델링하는 데 사용되는 인공 신경망의 한 종류이다.
-
시퀀스 데이터는 순서에 따라 나열된 데이터로 예를 들어 문장, 음성, 시계열 데이터 등이 있다.
-
RNN은 다른 유형의 신경망과 달리 이전 단계의 출력을 현재 단계의 입력으로 사용하여 내부 상태를 유지한다. 이는 RNN이 이전 단계에서의 정보를 현재 단계에서 활용할 수 있게 해주는 장점을 제공한다. 이를 통해 RNN은 시퀀스 데이터의 의미와 구조를 파악하고, 문맥을 이해하는데 도움이 된다.
-
RNN은 시간에 따라 연속적으로 펼쳐진 구조를 가지고 있다. 각 시간 단계(time step)마다 입력을 받고 출력을 생성한다. 이때 입력과 출력은 벡터 또는 행렬로 표현된다. 또한 RNN 은 가중치를 공유하여 시간 단계마다 동일한 모델 파라미터를 사용한다.
-
RNN은 다양한 응용 분야에서 사용된다. 주요 예시로는 기계 번역, 자연서 처리, 음성 인식, 시계열 예측 등. RNN 의 기본형태인 단순한 순환 신경망 외에도, LSTM(Long Shor-Term Memory) 과 GRU(Gated Recurrent Unit) 과 같은 변종이 개발되었다. 이러한 변종들은 RNN 이 가지고 있는 장기 의존성문제(Long-term dependency problem) 를 해결하기 위해 고안되었다.
연속적인 데이터 예제
- 연속작이고 가변길이 데이터
- 다른 모델 적용해야하지 않을까 라는 접근

Notation
- Harry Potter and Hermione Granger invented a new spell.
- 고유명사 1, 고유명사 아닌 것 0
- 입력 단어 -> 출력 binary

Representing words
- 과거 : 사전에 10000개의 단어 각각 레이블 부여 -> One hot code (1개의 필드만 1 -> 차원 10000 개)
- 영어는 띄어쓰기 마다 의미 단위로 나누어질 수 있기 때문에 비교적 쉽다.
- 글자, 단어, 문장 단위로 자를 수 있으나 보통은 단어로 자른다
- 한글의 경우 -> 형태소로 자르기

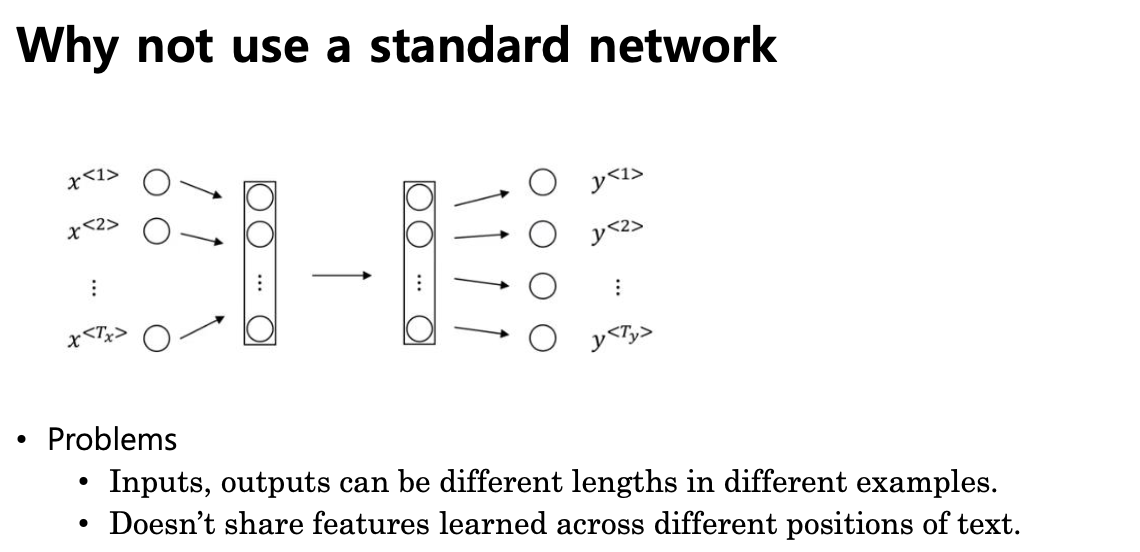
Why nor use a standard network
- 시각정보에서 컨볼루션 뉴럴 네트워크로 잘 동작하는
- but 자연어 처리에서 long term dependency는 어렵다?
- 문제 :
- 입력 을 넣으면 이라는 상태가 나온다.
- 이후 다음스텝에서는 와 를 이용해서 만듦
- 중간에 loop : 상태를 표시
- leng term dependency 를 다룰 수 있다고 말하는 이유는 라고 해서 과거의 정보를 포함하고 있을 것이라는 생각에서 나온다.
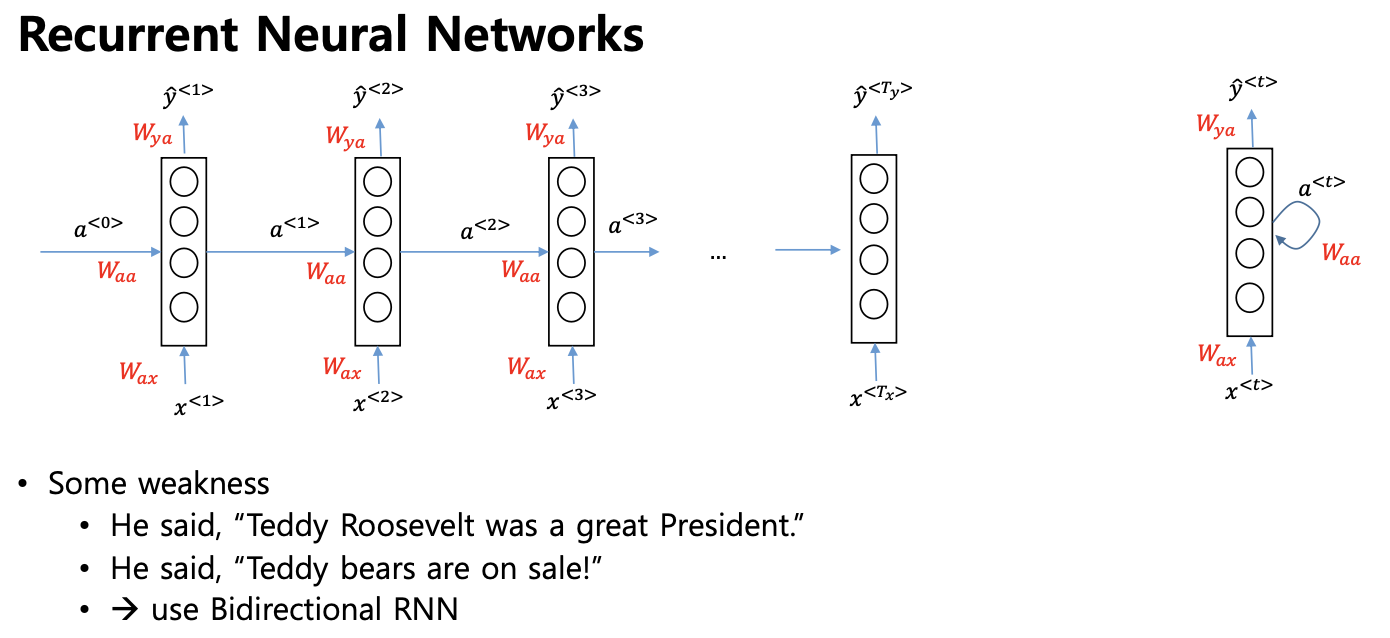
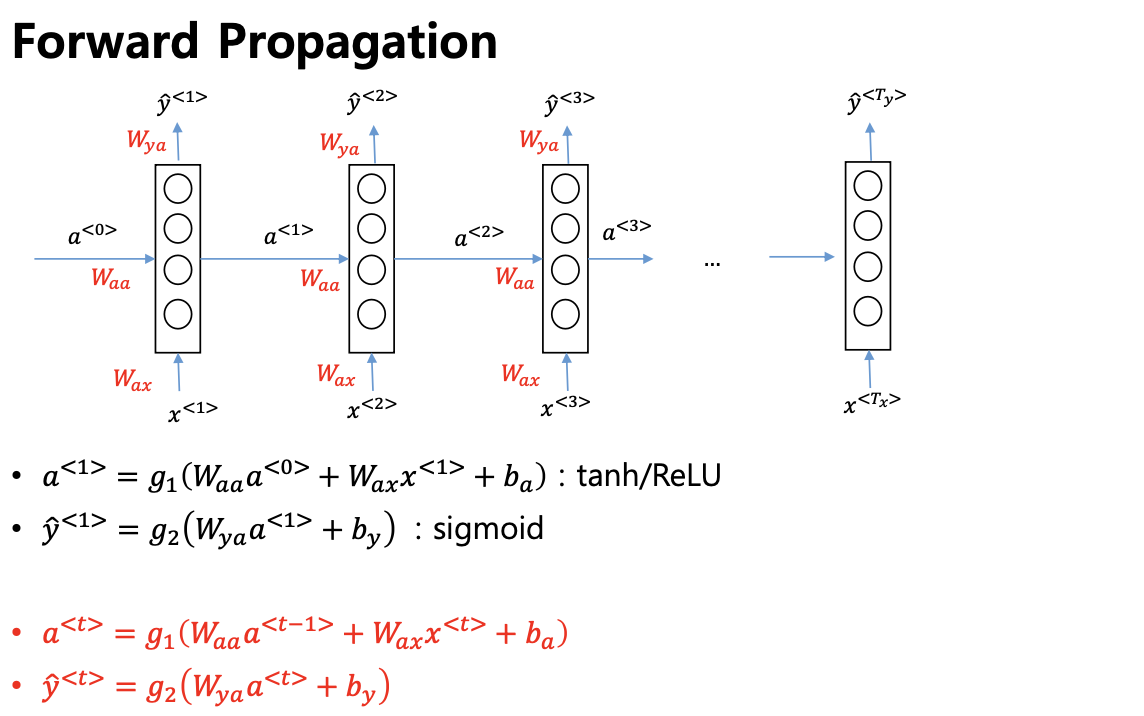

- RNN 은 다음과 같이 동작
- linear
- not linear
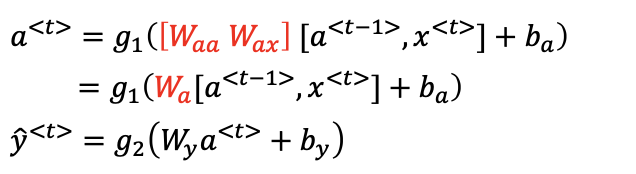
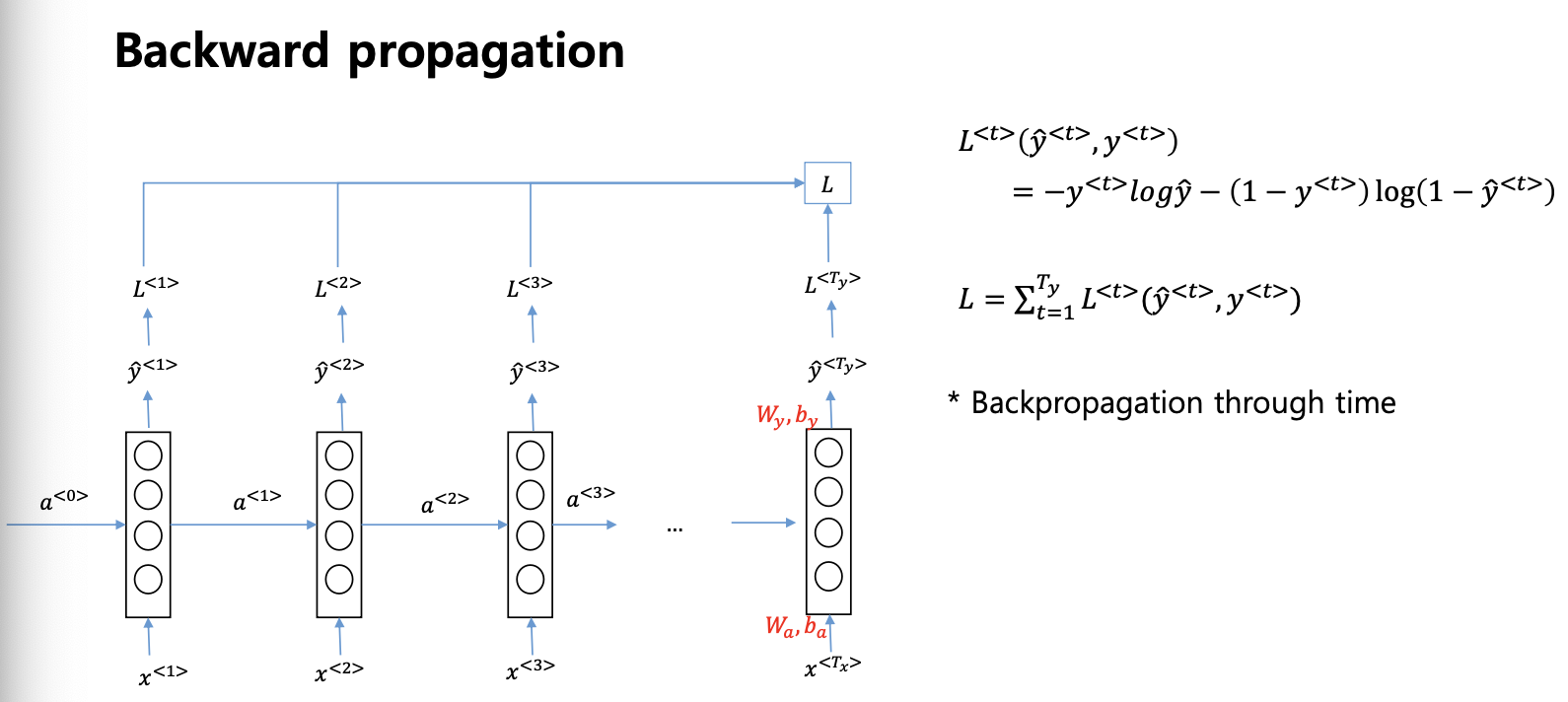
backprop
-
따로 다루진 않지만 RNN의 역전파 과정은 굉장히 복잡하다
-
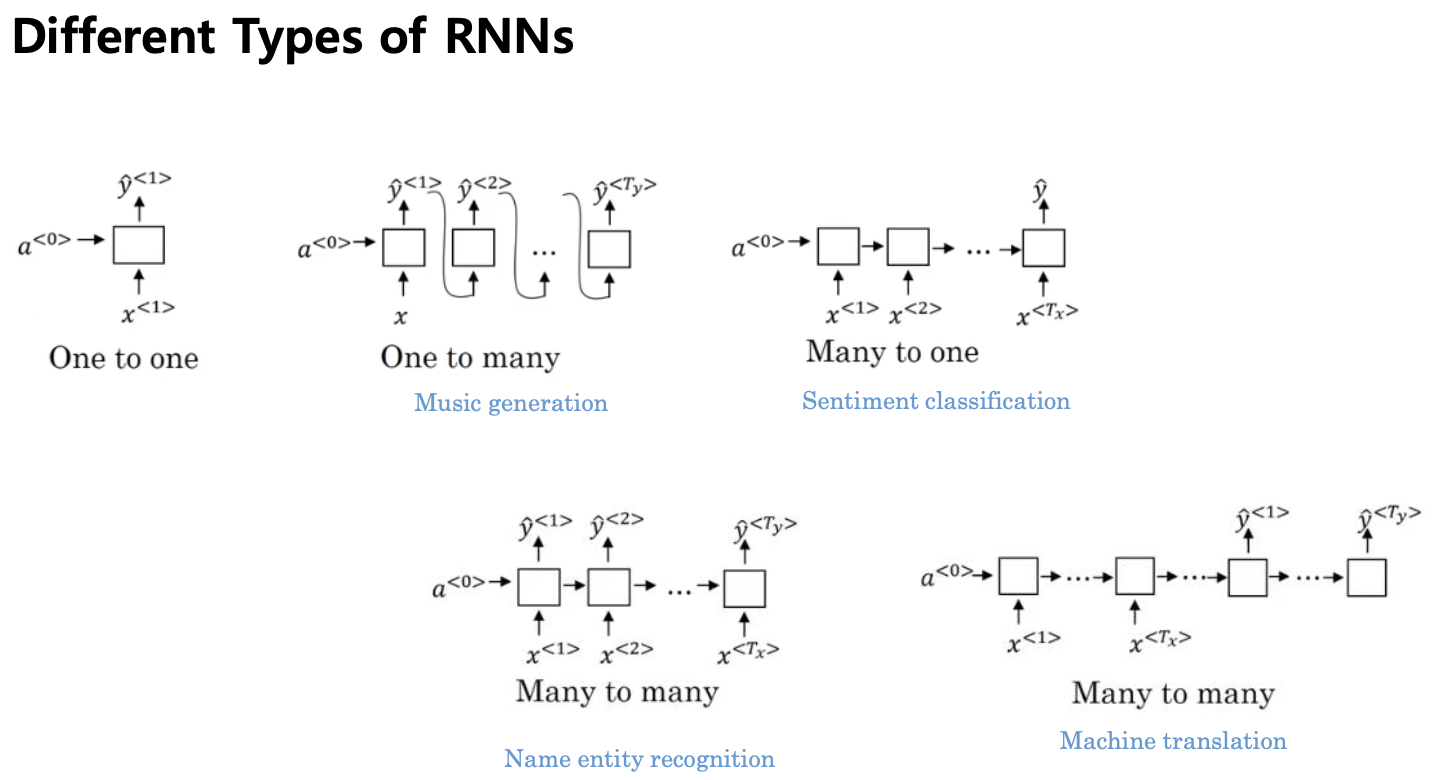
Sppeech recognition : 입력이 들어갔을 떄
-
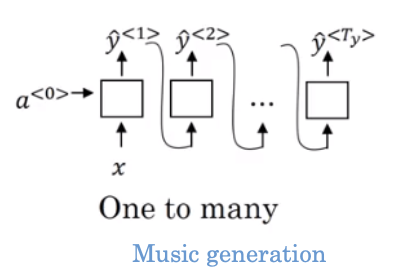
Music generation :
-
Sentiment classification : 전체 글이 들어가서 거기에 대한 아웃풋이 하나가 나온다
-
따라서 똑같은 Task 가 아니다.
똑같은 RNN 을 사용하더라도 연결방식의 차이는 존재
- 이전 step 의 출력을 다음 스텝의 입력으로 -> music generation, 이전 노래를 알아야 다음 노래 에측 가능
- 입력이 다 들어올떄까지 출력이 없다 -> sentiment classif
- 입력길이와 출력길이가 같다 -> Name entity recognition
- 문장 다 들어보고 거기에 해당하는 -> 입력길이와 출력길이가 다를 수 있다(마침표 나올떄까지) -> Machine translation
언어 모델
- 가장 그럴싸한 문장을 추정하는 것이 언어 모델
- 언어 모델 장점 : 트레이닝 시킬 때 사람이 별도로 labeling 할 필요 없다
- 다음은 언어 모델
- 다음은 언어 모델

- 실질적으로 one hot 코드를 사용하진 않는다
- 고차원 공간에 하나의 벡터로 단어를 다 매핑시킨 방법 사용 -> 단어 벡터의 장점 :
- king - man + woman = queen 이 가능함
- sementic 한 의미를 담고 있기 떄문에 이를 사용하여 자연어 처리의 성능을 높혔음

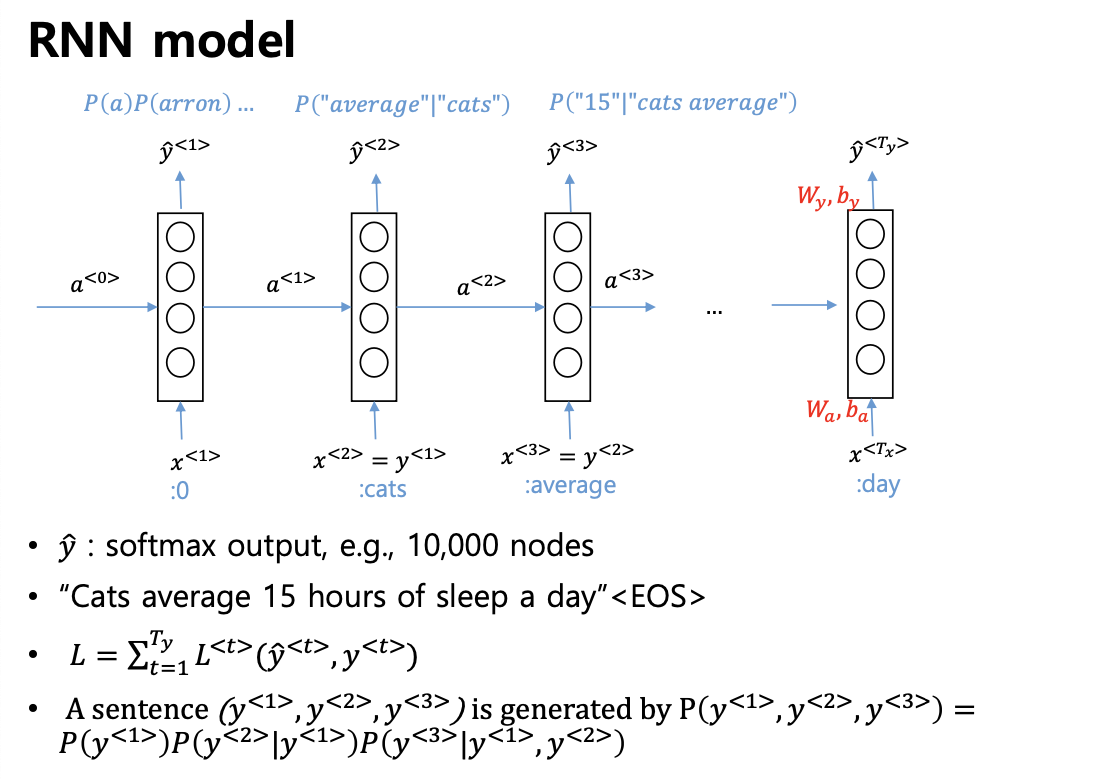
RNN 모델
- 언어모델은 다음 그림과 같이 동작한다
- 가장 확률이 높은 단어를 추천하는 형태로
challenge
-
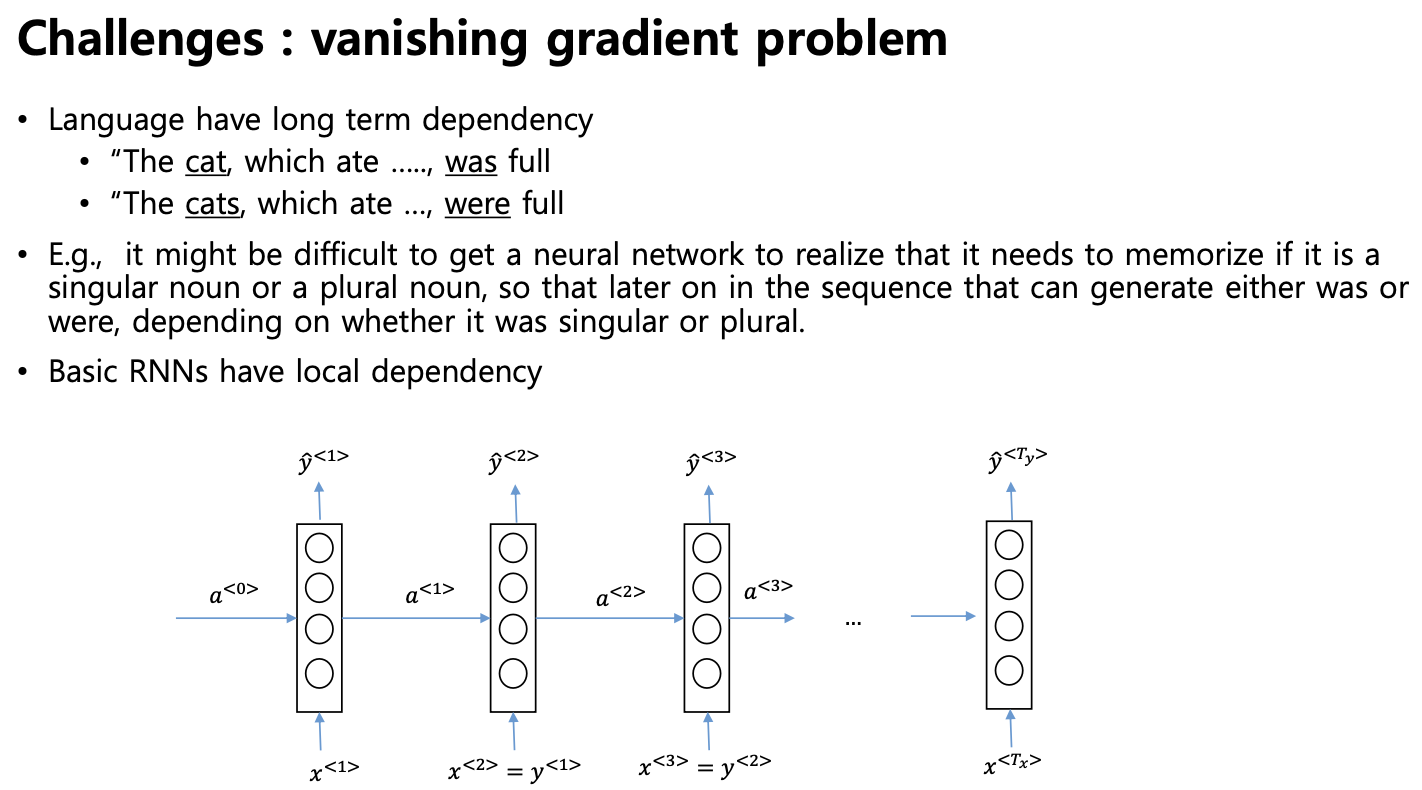
하지만, vanishing gradient 문제가 있음
-
이를 해결하기 위해 RNN 중 GRU
-
수식
- state a 가 c 라는 것 -> 다음 스텝으로 넘어가
- 2) c 틸다를 만들어냄 : 계산해서 다음 스텝으로 넘길 state 를 만들어야하는데, c 틸다를 만들어놓고 (candidate : 후보)
- 3) 감마 만들기 : 그전 스텝에서 들어왔던 c 와 어째 계산(감마 : 1이면 열리고 0이면 닫힘)
- 노브라고 불름 (감마같이 생긴것)
- 노브라는 것은 벡터 (0과1 사이의 값)
- 노브를 사용하는 이유?,,
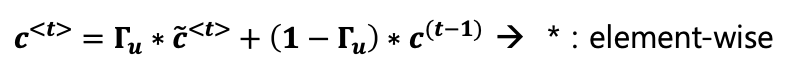
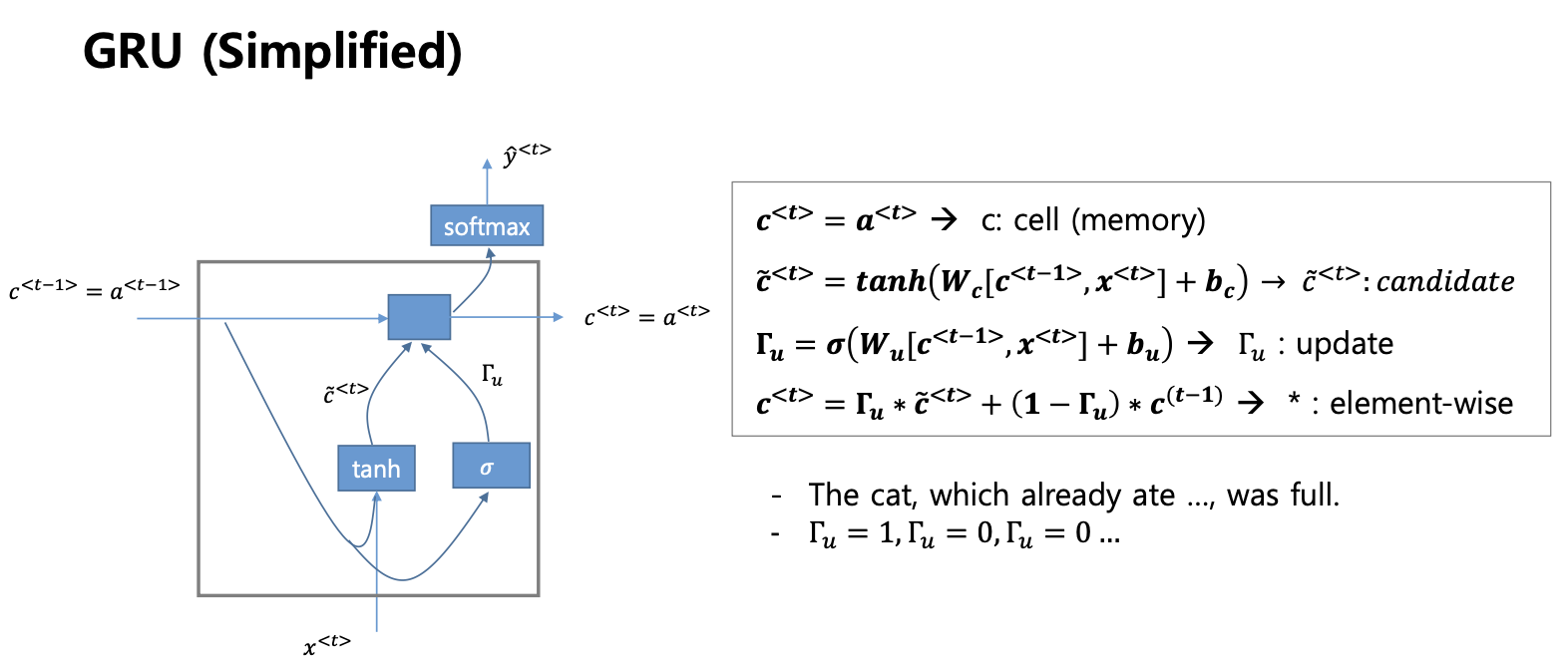
- GRU 버전중 노브가 하나 더 있는 것이 원조인데
- 노브를 하나 뺴서 쓰는 simplifiy 버전을사용해도 상관없다

- GRU 가 LSTM 의 간략화 버전이라고 할 수 있다.
- 구조 : LSTM 은 넘기는 state 는 2개이다 (이유는 잚 모르신다함)
- 후보를 만들고, 노브 3개만들기(감마u, 감마f, 감마o - update, forgiven, output 이라는 의미)
- c
<t>를 결정할 때 내가 후보를 써서 업데이트를 할지 그전에서 올라온 셀을 쓰고 잊어버릴지를 결정 - 그다음 a 를 만든다?

- 다음 강의자료는 그림 -> 복잡해서 pass
GRU vs LSTM
- GRU 권장
- GPU 를 사용하더라도 training 이 되게 오래걸림
- 이유
- 역전파를 통해서 업데이트를 하는데
- 아무리 GPU 를 사용하더라도 각 .. 를 기반으로 각각 조금 업데이트 하고 이런식이므로 되기 떄문에 느림
- 우리 수업시간에 다루지 않은것 : 이것을 해결하기 위한것이 attention 테크닉에서 유래된 transformer -> 2학기
- 즉 병렬화된 버전은 transformer

결론 : RNN 도 좋은 테크닉
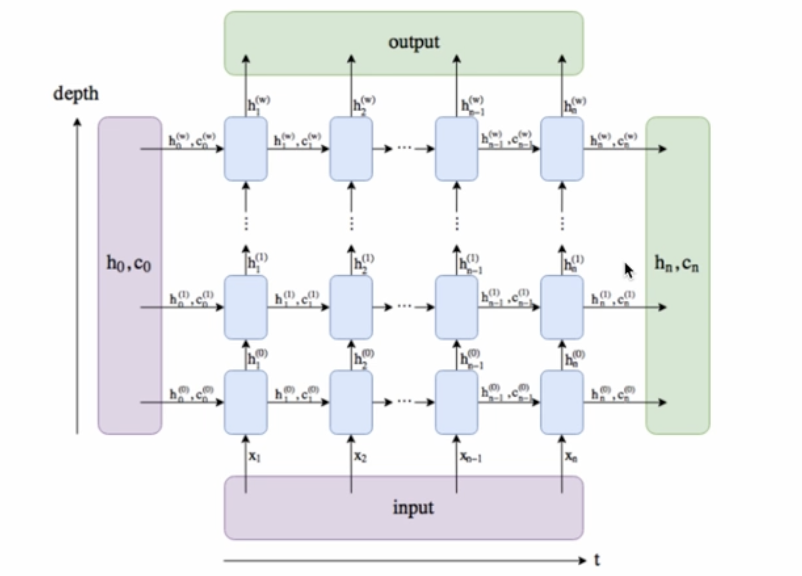
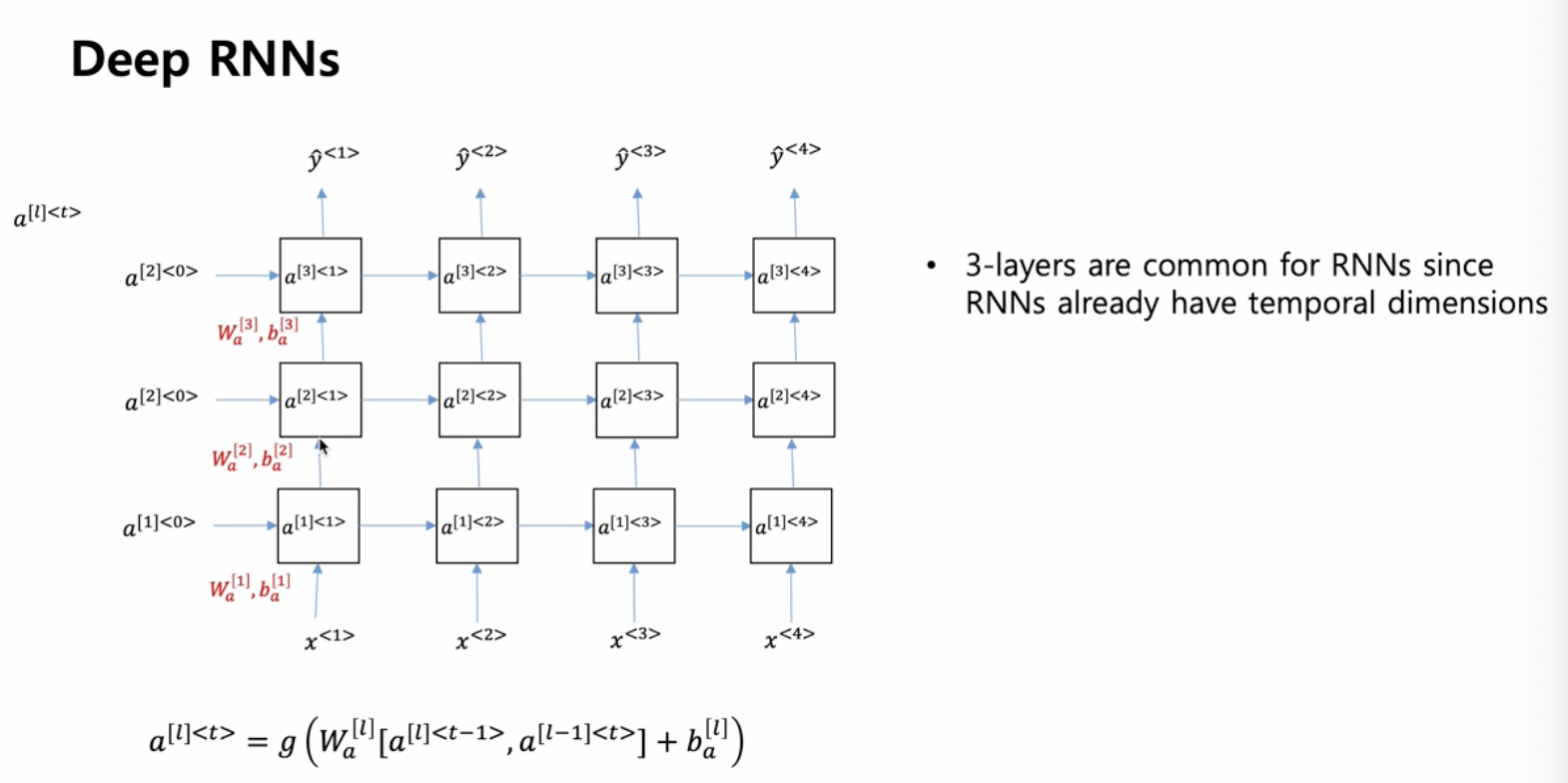
Deep RNNs
- RNN 을 딥하게 쌓을 수도 있다.
- 기본적인 구조는 입력 x 가 들어가면 출력 y 햇이 나오는 구조
(state 는 계속 전달되는 방식) - GRU 같은 경우에는 하나의 state 만 전달되고, LSTM 은 2개(a와 c)가 전달됨
- RNN 레이어 3개(위아래)인 그림 -> 입력 x 의 출력을 중간의 LSTM 에 들어가는 구조
RNN with PyTorch
- 사용될때 주의 점
- 입력을 차례대로 for 문을 통해서 넣는게 아닌, 입력을 시간축으로 쭉 펼쳐서 입력으로 넣는다.
- 실제로는 차례대로 들어가는 것 처럼 보인다.
- LSTM 같은 경우는 2가지의 state 가 필요(왼쪽 : ) -> 마지막 결과값이