Transfer Learning
- 여태 몇가지 모델을 배웠다. fully connected layer 를 사용한 Shallow Neural Network, 살짝 깊은 Deep Neural Network, Convolution layer 를 사용한 LeNet, ResNet 을 배웠다.
- 우리가 봤던 것들이 굉장히 작은 네트워크부터 큰 네트워크까지 있었다.
- ResNet 은 굉장히 깊은 것도 있었다. 예를 들어 VGG
- 이런것처럼 모델이 굉장히 커지다 보니까 파라미터수도 많아지고, 그 파라미터를 트레이닝 시키는 것 자체가 굉장히 힘들다.
- 모델의 파라미터가 많아지는것도 문제지만, training data 가 큰 것도 문제이다.
- 모델 training data 에 대해서 mini-batch 를 구성하고, 그 mini-batch 를 가지고 모델을 training 해야하니까
- 모델도 커지고 data 도 커져서 어떤 모델을 training 하는 것이 점점 힘들어진다.
- 주요한 전이 학습 시나리오
- CNNs as fixed feature extractor
- Fine-tuning the CNN
그래서 어떤 방법론이 나오느냐?
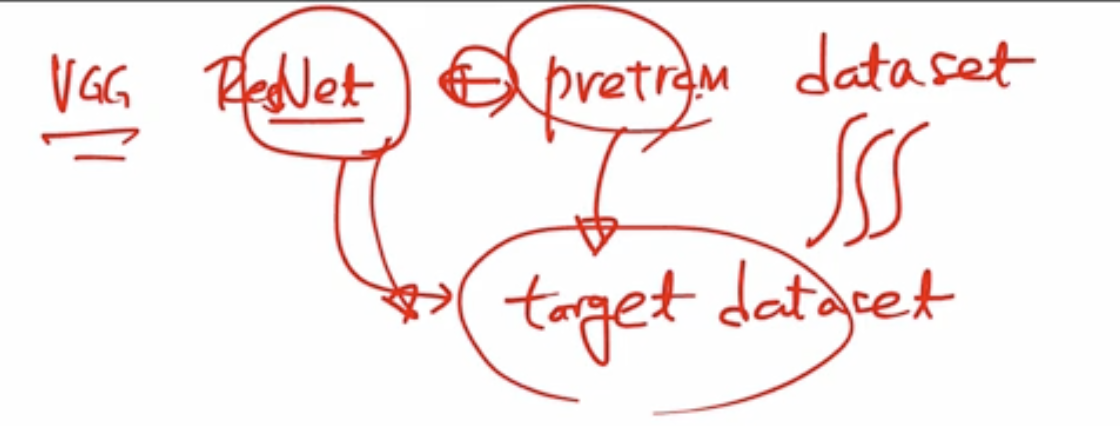
- 기존의 Convolutional Nerual Network (CNN) 을 누군가가 training 을 해놓았다면(pretrain), 우리가 그것을 다시 training 할 필요 없이 가져다 사용하면 되는것이다.
- VGG, ResNet 을 이미 training 시켰다고 가정, pretrain 된 이런 모델들을 가져다가 원하는 Task 에 쓰는것이 가능
- 전제 : VGG, ReNet 을 pretrain 한 data set 과, pretrain 된 data set을 가지고 target data set에 적용을 시키는데, 이 둘이 아주 유사해야지만이 이 전력이 맞아 떨어짐.
- 이 둘이 다르면 아무 소용이 없음
- 따라서 이 둘이 얼마나 같은가가 문제가 된다.
- pretrain dataset 을 target dataset 에 적용시키는 것이 Transfer Learning
- 테니스 치던 사람이 배드민턴을 배우면 비교적 배우기 쉽다는 예시랑 비슷하다.
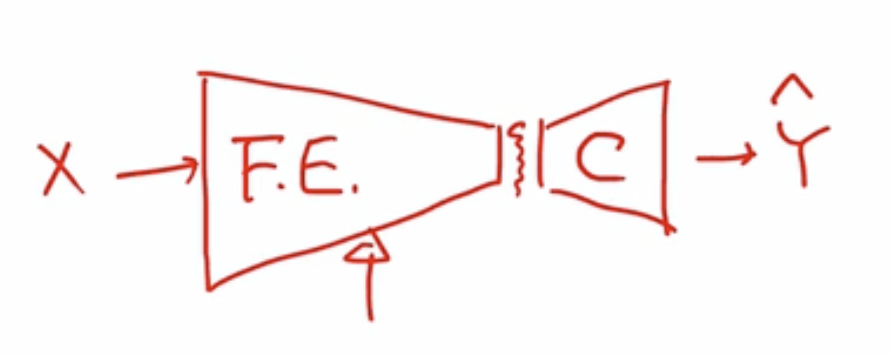
전체 딥러닝의 보통의 구성
- VGG, ResNet 은 보통 다음의 구성을 따른다
- 입력 x 로 부터, CNN, max pooling 으로 이루어진 layer 들이 있고, 오른쪽 끝 어느 부분에서 flattening (3차원으로 되어있는 feature vector 를 1차원 vector 로 펼치는 과정)을 한다
- 그 뒤로는 fully connected layer 를 몇개 연결을 하고, softmax 를 통해서 결과를 만들어낸다
- x로 부터 결과를 만들어 내므로써 분류라는 목적을 달성하기 위해
- 앞단 : feature 를 뽑아내는 F.E (feature extractor)
- 뒷단 : 뽑아진 feature 를 가지고 분류하는 Classifier
만약, training data 와 target data 가 유사하지 않다면?
-
우리의 training data set 를 통해서 이 전체 Net 을 pretrain 하였다.
-
target data set 이 있는데 training data set 이 굉장히 유사하여, 이 전체 Network 를 t.d 로 training 시키고, target 에 적용하면 됨.
-
만약, 이 둘이 유사하지 않다면?
- 예를 들어서 t.d 로 어떤 이미지이고, target 은 이미지들의 야간사진이다 등의 이런 약간의 차이가 있는
- 면에서는 똑같은 클래스르 가지고 있고, x 면에서는 무언가 성격이 좀 다른 경우
- 전략
- 위 네트워크를 그대로 갖다 쓰지는 못하고 F.E 부분을 그대로 갖다 쓰는데, C 부분은 target data 로 한번 training 을 다시 하고 싶다라는 전략을 세울 수도 있음.
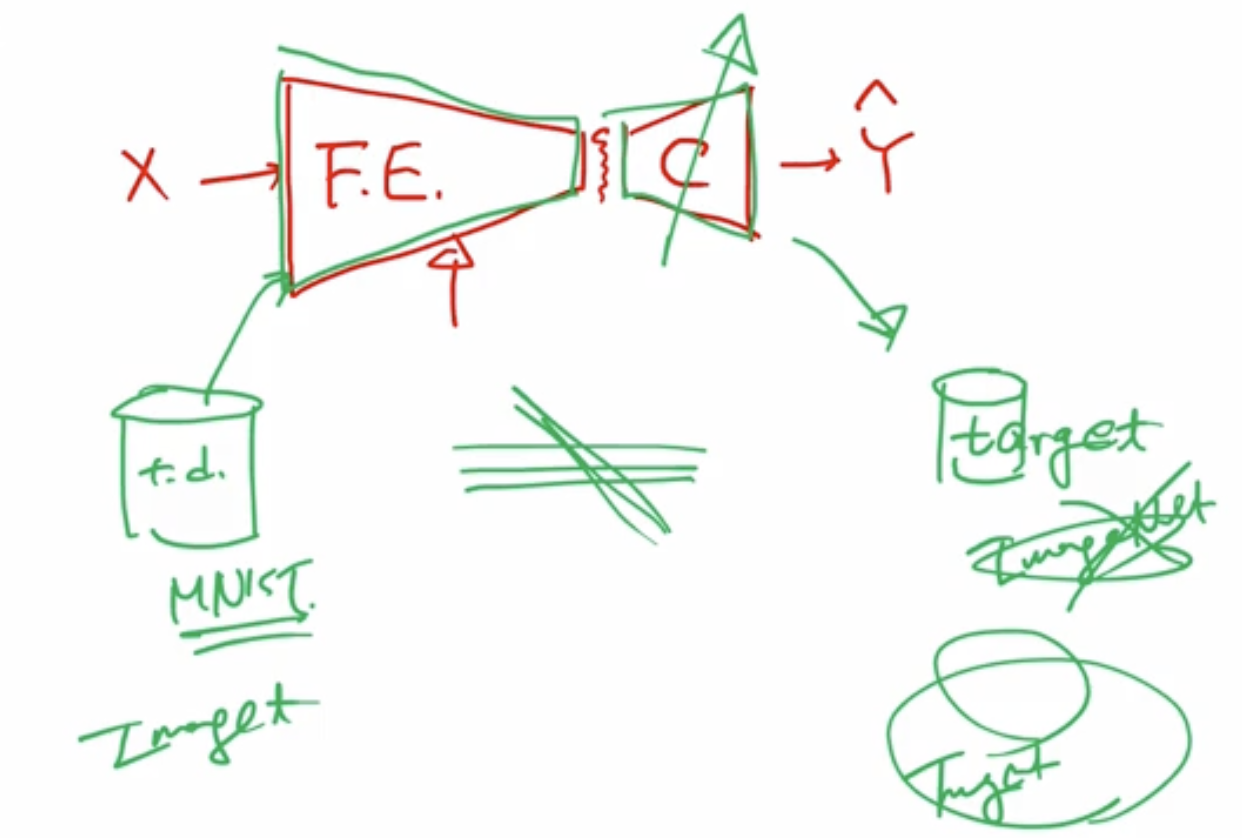
- 위 네트워크를 그대로 갖다 쓰지는 못하고 F.E 부분을 그대로 갖다 쓰는데, C 부분은 target data 로 한번 training 을 다시 하고 싶다라는 전략을 세울 수도 있음.
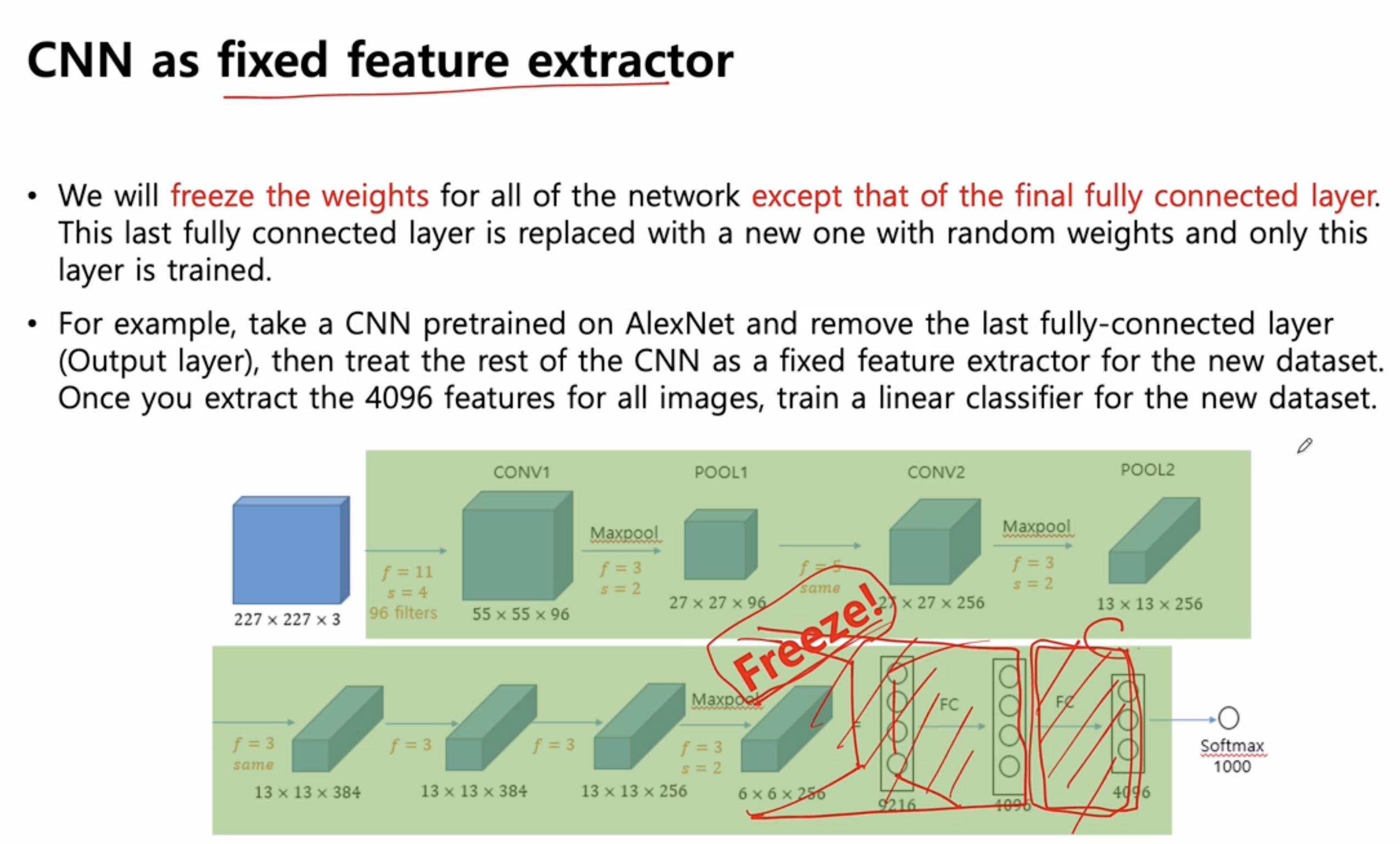
전략 1 : CNN 을 feature extractor 로 쓰고 싶다
- 전략 설명 : pretrain 된 AlexNet 을 그대로 가져오는 것이 아니라, 나머지는 Freeze! (고정) 시켜놓고 맨 마지막 fully connected layer 만 다시 새로운 target dataset 으로 trainig 을 해서 쓰겠다.
- 예시, feature extractor 를 맨 마지막 FC 직전까지 보고 freeze, 맨 마지막 부분(Classifier)만 새롭게 training 해서 쓰겠다.
전략 2 : Fine-tuning the CNN
- 고정시키는 것은 좀 싫고, pretrain 된 무언가(이미 결정된 weight)를 가져와서 그것들을 가지고 initialize 를 하고 거기서 부터 다시 training 을 시작하여 새로운 target data set 으로 전체를 training 할 것이다.
- 전체를 다 training 할수도있고, 아니면 몇몇 layer freeze 하고 나머지를 training 할 수 도있다.
알아두면 좋은 이야기
- CNN 이 있을 떄 pretrain data set 을 불러오고 걔네들의 weight 를 initial 값으로 쓰거나 , 아니면 일부를 freeze 하고 쓰거나 한다.
- CNN 의 경우는 앞을 freezing 시킨다.
- 왜? CNN 은 layer 마다 뽑아내는 feature 가 다른 경향을 보인다.
- 앞쪽은 약간 납작하고 채널수가 짧은 그런 feature 를 뽑다가. 뒷단으로 가면 height, width 가 줄어들고 채널수가 많은 feature 를 뽑는 경향이 있다.
- 이것과 마찬가지로 앞단의 layer 별로도 뽑는 feature 들도 달라지는데
- 결론적으로 앞단으로 갈수록 generic 한 feature 들이 많이 뽑힘 (어떤 edge, pattern 을 발견한다거나 등의 과정이 앞단에서 이루어짐)
- 뒤쪽에서 일어나는 일 : target 하고 있는 Task (에를 들어 얼굴 인식, 객체 탐지 등..), 이것과 관련된 좀더 구체적인 feature 를 뽑아낸다.
- 만약에 이미 pretrain 된 모델을 갖다가 우리의 Task 에 새롭게 쓰려면 앞쪽에 일반적인 것들은 이미 pretrain 된 것들을 그대로 사용을 하고, 뒤쪽에 Task specific 한 것만 우리가 새롭게 training 시키겠다 라는 것은 현명한 전략이다.
- 그래서 앞단이 아닌 뒷단을 주로 새롭게 training 하는 부분을 많이 사용한다.
Whne and how to fine-tune?
- 새로운 dataset 이 주어졌을떄 우리가 어떤식으로 transfer learning 을 할지에 대한 고민할 떄 판단 기준(전략 1,2..)
- 1 - data size 가 얼마인지
- 2 - training data set(여기서는 original data set) 과 New dataset 이 얼마나 유사한지
- 위 두가지 축을 가지고 4가지 시나리오 구성
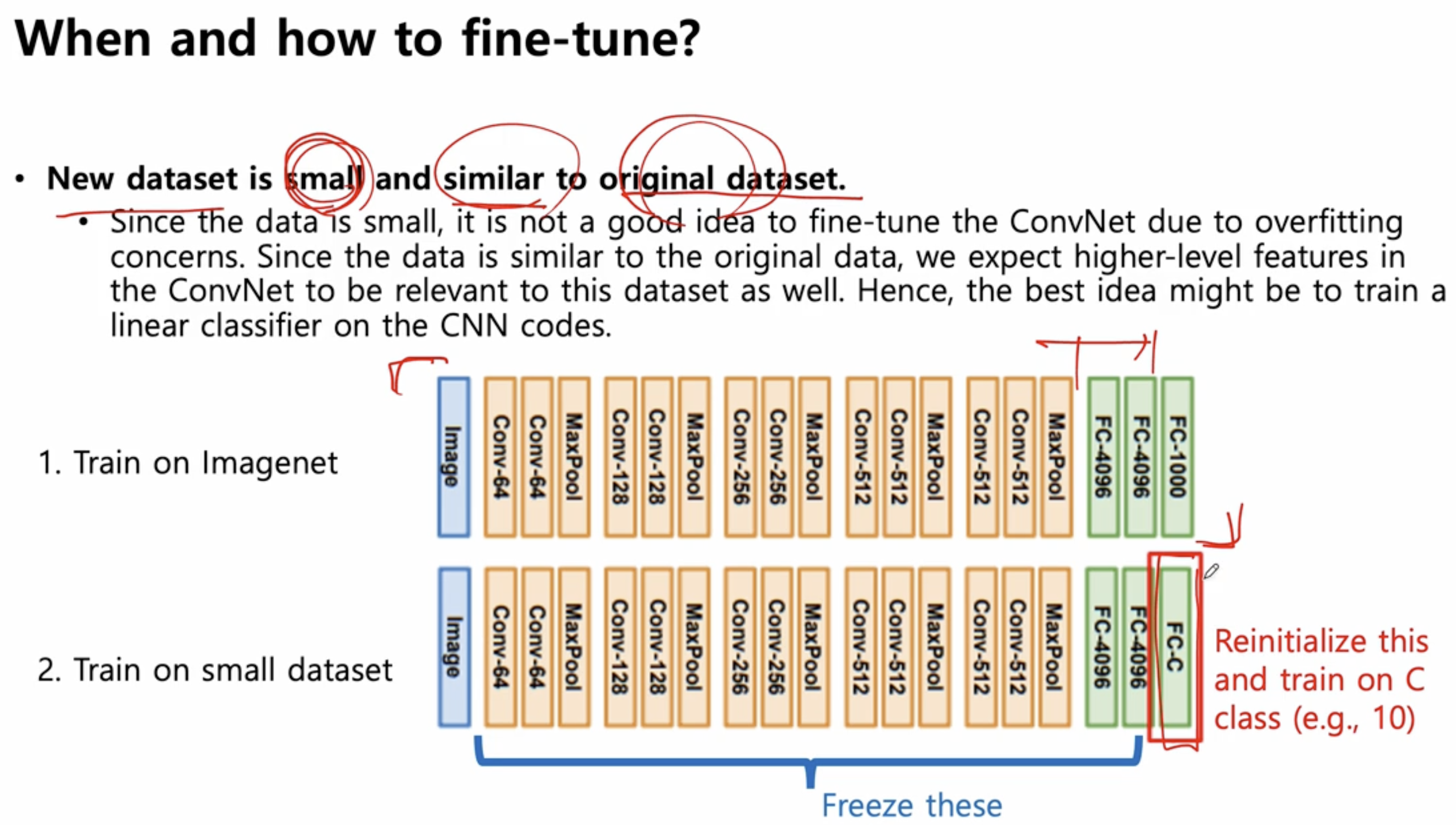
- 1) New data set 이 적고, original data set 과 분포가 유사할 떄
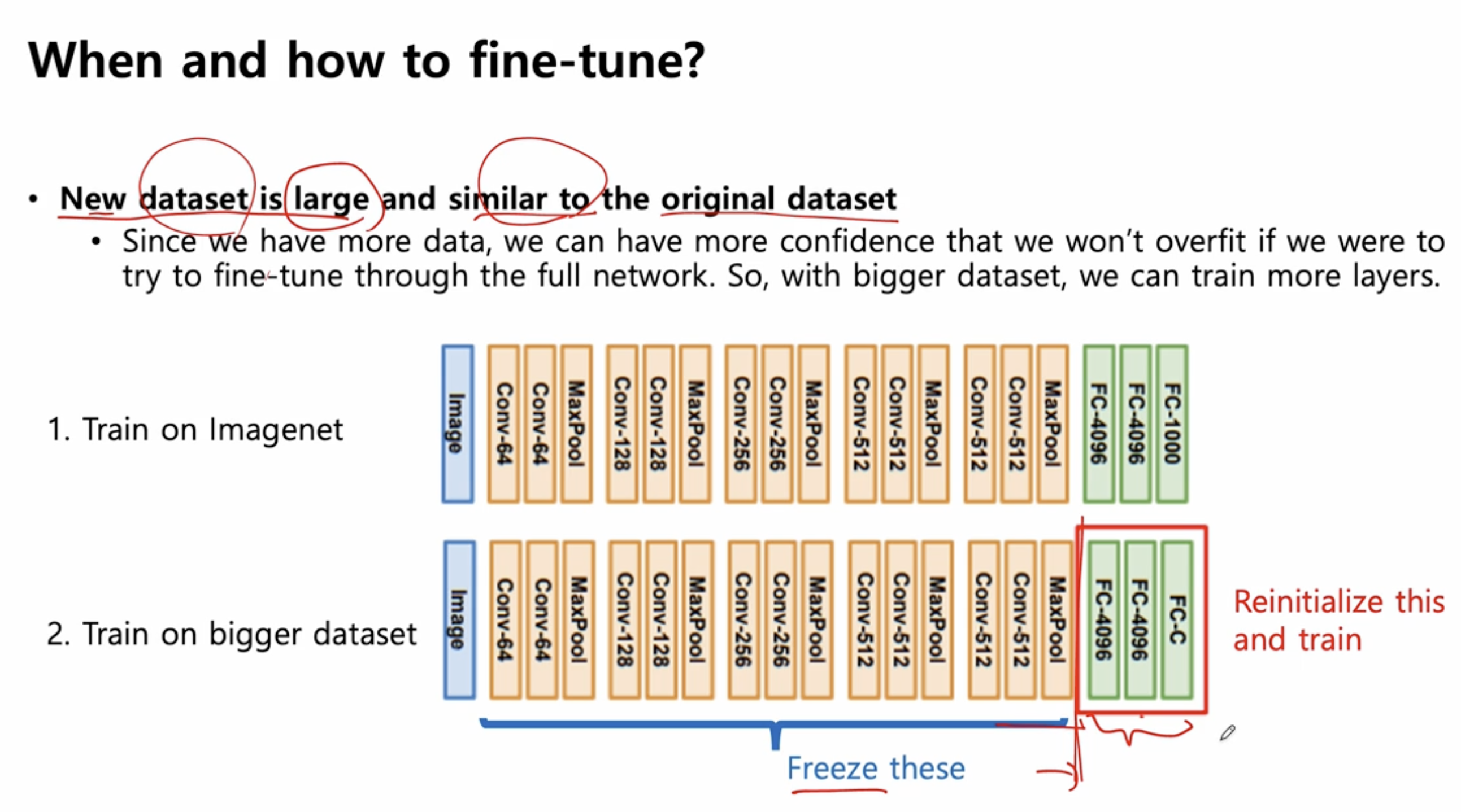
- 2) New data set 이 크고, original data set 과 분포가 유사할 때
- 3) New data set 이 작고, original data set 과 분포가 다를떄
- 4) New data set 이 크고, original data set 과 분포가 다를떄

1) New data set 이 적고, original data set 과 분포가 유사할 떄
- 새로운 data set 이 적기 떄문에, 얘를 갖고 트레이닝을 전체를 해버리면 overfitting 가능성 있다.
- overfitting 을 방지하기 위해서 최대한 많은 layer 를 freezing 하고 맨 마지막의 fully connected layer 의 weight 만 새로운 data set 을 가지고 fine-tuning
- 기존의 pretrain 이 잘 되어있다면, 굳이 weight 를 바꿀 이유는 없기 떄문에
- 즉, 이럴때의 전략은, 최소한의 layer 만 fine-tuning 하는 것이 옳바른 전략
2) New data set 이 크고, original data set 과 분포가 유사할 떄
- new data set 이 크기 떄문에 overfitting 에 대한 문제가 없어졌다
- 이러한 경우는 보다 자유롭게 할 수 있다.
- convolution layer 가 끝나는, flattening 되는 지점까지의 feature extractor 는 그냥 freeze 시켜놓고
- 나머지를 fully connected layer 들을 new data set 을 가지고 다시 training 하는 fine-tuning 하는 방법
3) New data set 이 작고, original data set 과 분포가 다를 때
- 두 분포가 다르다면, pretrain 된 Model 에서 freezing 하는 layer 가 적어야 된다 (새롭게 original data set 과는 다른 target data set 으로 최대로 많은 layer 를 새롭게 fine-tuning 하는 것이 필요하기 떄문)
- 그런데 그렇게 하자니, data set 이 너무 적다 -> overfitting 이 일어날 가능성이 크다.
- 이런 부분은 굉장히 어려운 문제
- 그러니 그렇게 하지말고, 그냥 앞부분은 freeze 해 놓고 data set 이 적으니 뒷 단의 Classifier 부분을 SVM 이라는 다른 Classifier 를 쓰자.
- 어쨋든 이런 케이스는 굉장히 딜레마이다.
4) New data set 이 크고, original data set 과 분포가 다를 때
- Original data set 과 다르기 떄문에 많은 부분을 fine-tuning 이 필요하겠지만, 다행히 data set 이 크기 떄문에 최소한의 부분만 freeze 하고 나머지는 다 크게 주어진 New data set 으로 training 한다는 전략
transfer learning 을 배운 이유
1) GPT 와 같은 잘 trainng 된 모델을 갖다 쓰고 필요할 경우의 fine-tuning 하는 경우
2) 어떤 task 를 하고 싶은데, 처음부터 우리가 모델을 만들고 새로운 데이터셋을 트레이닝 시킬 필요가 없다는 것
- 굉장히 잘 알려진 모델을 갖다서 쓰는것이 가능.


공부한 것 기록용