
Text vs Context
A : He got bit by a Python.
B : Python is a programing language.
- 컴퓨터는 Pythons 이라는 단어를 같은 의미로 이해한다 (text)
- 그러나, 인간은 주어진 단어간 contextual information 에 따라서 문장 B에서는 프로그래밍 언어(context)로서의 Python을 말하는 반면, 문장 A에서의 Python은 뱀을 말한다는 것을 이해할 수 있다.
- LLM 은 인간처럼 Pythons 을 다르게 이해할 수 있다.
- Q: Is Word2Vec embedding text or context method?
Pre-training 이 무엇인가?
- Pre-training 은 언어 모델이 데이터의 통계 패턴과 언어 구조를 학습하기 위해 많은 텍스트 말뭉치(corpus)에 대해 학습되는 초기 단계를 말합니다
- 텍스트로 적혀있는 언어를 가지고 단어간 context 를 이해하고 그것을 학습한다.
- The corpus : 책, 기사, 웹사이트 및 기타 인터넷 또는 기타 출처의 작성 내용 등 다양한 text sources
❶ 모델의 목적은 context에 기초하여 "sleeping" 이 될 수 있는 빈칸의 단어를 예측하는 것이다.Example : "The cat is _______." //다음에 올것이 무엇이냐를 학습 (통계적인 어떤 패턴이 있다)
❷ 방대한 양의 텍스트 데이터(corpus) 를 학습하여, 모델은 패턴, 문법, 맥락 관계을 학습한다.
- The corpus : 책, 기사, 웹사이트 및 기타 인터넷 또는 기타 출처의 작성 내용 등 다양한 text sources
Fine-tuning
- Fine-tuning 은 Pre-trained model을 더 작은 data set으로 더 특정한 작업에 대해 학습시켜 모델을 특정 작업에 대해 더 전문화하고 정확하게 만드는 것을 포함합니다
- ❶ : 기본 모델은 단순히 구글 검색이나 숙제와 같은 일련의 질문들을 나열함으로써 텍스트를 완성하려고 노력하는 것에 주목하세요,
- 구글 검색 처럼 많은 도움이 되지 않는 답변을 주지 않기도 하지만,
- ❷ : 반면, fine-tuned model 은 더 유용한 반응을 제공합니다.
- 파인 튜닝 된 것은 좀 더 도움이 되는 답변을 주었다.

- 파인 튜닝 된 것은 좀 더 도움이 되는 답변을 주었다.
- ❶ : 기본 모델은 단순히 구글 검색이나 숙제와 같은 일련의 질문들을 나열함으로써 텍스트를 완성하려고 노력하는 것에 주목하세요,
Why Fine-tuning and How?
- Fine-tuning 통해 기본 모델의 성능을 향상시킬 수 있을 뿐만 아니라, 작은 모델(미세 조정된 모델)이 훈련된 작업에서 종종 더 큰 모델(더 비싼 모델)을 능가할 수 있습니다
- 3 Way of Fine-Tuning:
- 1) Self-Supervised Learning :
- 같은 문장의 맥락에서, 다음 문장의 예측을 학습하고, 문장의 untagged (no labeled) data 를 가지고 다음 단어(토큰)을 예측한다.
- 주로 pre training 에서 사용 됨
- 2) Supervised Learning:
- 여기에는 특정 작업에 대한 입력-출력(질문-정답(대상)) 쌍에 대한 모델 교육이 포함됩니다. 예를 들어, 질문에 응답하거나 사용자 프롬프트에 응답하는 데 있어 모델 성능을 향상시키는 것을 목표로 하는 명령어 튜닝(instruction tuning)이 있습니다
- tagged data (= labeled data): 인풋과 아웃풋이 한 pair 로 되어서 그것을 가지고 학습을 한다.
- 즉, 인풋을 입력하면 인풋에 맞는 정답이 output 마지막에 기다리고 있다는 것과 비교를 해서 차이나는 것만큼 backpropagation 으로 error 를 뒤로 보내줘 weight 을 업데이트 해주는 것을 supervised learning 이라고 한다.
- 여기에는 특정 작업에 대한 입력-출력(질문-정답(대상)) 쌍에 대한 모델 교육이 포함됩니다. 예를 들어, 질문에 응답하거나 사용자 프롬프트에 응답하는 데 있어 모델 성능을 향상시키는 것을 목표로 하는 명령어 튜닝(instruction tuning)이 있습니다
- 3) Reinforcement Learning:
- reward 를 주면서 베이스 모델(pre trained model) 을 학습하는 데 있어서 도움을 주는 것
- 1) Self-Supervised Learning :
cf. Unsupervised Learning: untagged data (input-output(정답=target) pair 데이터(=label) 없이 | 데이터를 유사한 것 끼리 clustering. 반면에 Self-Supervised Learning은 tagged data 없이 자기 자신의 문장의 앞에 오는 단어들을 학습한 후에 다음에 올 단어나 문장을 예측)
- Self-Supervised Learning vs Unsupervised Learning 공통점 : 레이블이 없는 문장을 가지고 학습을 한다. (Untagged data)
- Untagged data () : 인풋만 가지고 학습을 한다는 것 (아웃풋이 없음)
왜 LLM 에서 Self-Supervised Learning 을 하는가?
- Self-supervised learning 은 Tagged data (Supervised learning) 확보의 어려움 때문에 생김
- 인풋과 정답지가 포함된 데이터를 확보하는게 많이 어렵다, 따라서 대량으로 tag 없이 teacher 없이 target 없이 무조건 학습을 시키자 (문장 내에서 어텐션을 가지고 학습 등등..)
- 일반적으로 Deep learning 모델은 모델 사이즈 (parameter 수)가 증가함에 따라 정확도가 향상되는데, 큰 사이즈의 모델을 적절하게 학습하기 위해서는 대량의 데이터가 필요
- Tagged data 가 적어도 되는 Self-supervised learning 은 학습 데이터 확보가 쉽고 따라서 모델 Size 증가가 가능하며 모델의 정확도가 더 늘어난다는 장점이 있음
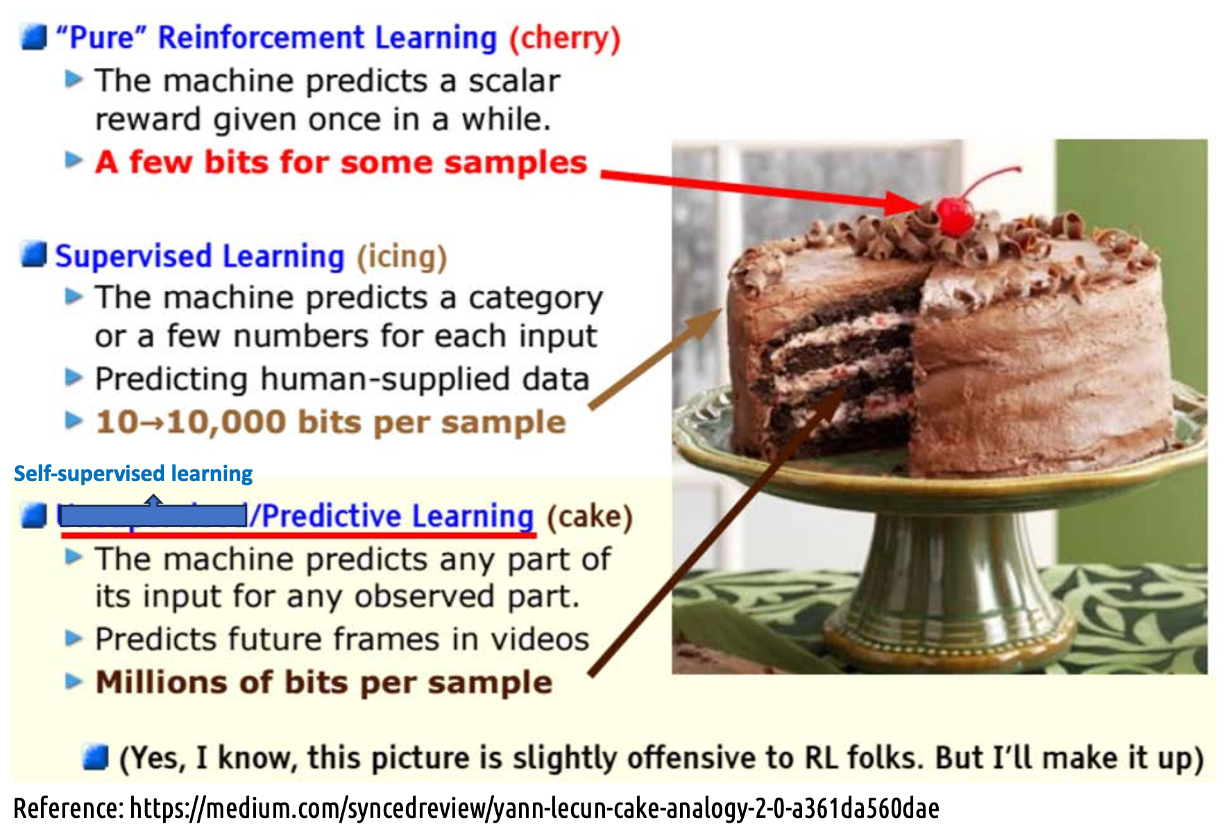
Reinforcement Learning vs. Self-supervised vs. Supervised Learning
강화학습은 체리 장식, 지도학습은 icing, 자기 지도 학습은 케이크
- Fine-tuning 에 사용
- ❶ Supervised learning 의 단점
- "레이블" 데이터가 많아야 함
- 학습되지 않은 데이터가 튀어나오면 예측 불가능
- ❷ Reinforcement learning 의 단점
- 실패해도 다시 시도하면 되는 게임에서 가능(다음에 성공해서 Reward를 받을 수 있으니까)
- 현실 세계에서는 실패 자체가 치명적일 수 있어서 적용하기 힘듦
- ❶ Supervised learning 의 단점
- Pre-training 에 사용
- ❸ Self-supervised learning 의 필요성
- 주변 상황과 조건을 고려해 예측 해야 함
- 실패하기 전에 사고가 난다는 것을 예측해야 함
- ❸ Self-supervised learning 의 필요성
Natural language processing (NLP)
- 자연어 처리 업무
- Sentiment Analysis
- Restaurant reviews (food is good (positive) and food is bad (negative))
- Text Classification
- Whole bunch of news we need to classify whether its political news, sports news, whether cinema news based on what they convey
- Next Word Prediction
- (This is a beautiful _). -> Flower
- Question Answering System
- Chatbots (ChatGPT)
BERT vs. GPT
- BERT (Bidirectional Encoder Representations from Transformer)
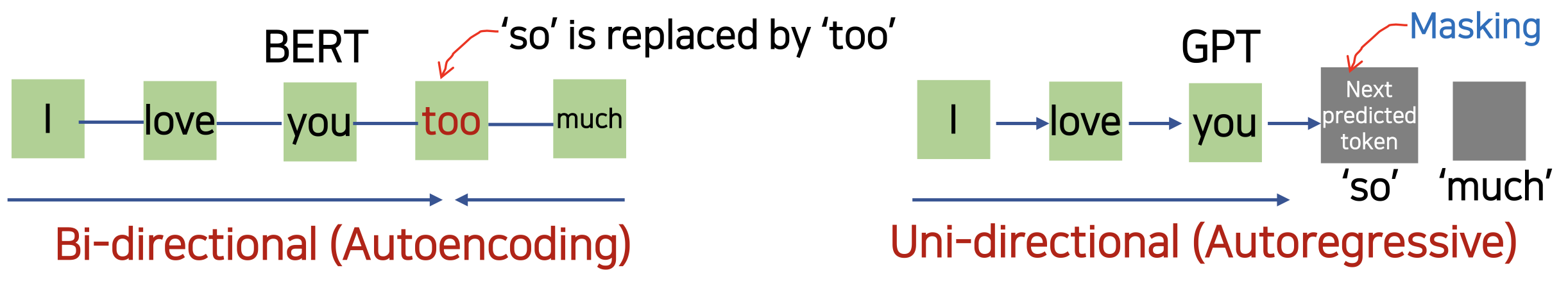
- BERT 는 Transformer 의 Encoder 를 기반으로 한 Language model 이다.
- GPT 와 달리, BERT 는 Bi-directional (Autoencoding) model 이다.
- 한 번에(양방향) 전체 입력 시퀀스의 컨텍스트를 이해하므로 앞/뒤 컨텍스트를 동시에 고려할 수 있다/
- 문장에서 단어의 의미를 잘 이해한다.
- ex) 앞단의 'I love you' 와 'much' 를 동시에(Simultaneously) context 를 파악하여 'too' 라는 단어의 예측을 학습
- 다음 토큰을 예측하는 작업(sequence generation tasks)에서 Uni-directional 모델(GPT)이 잘 작동할 수 있음
- Uni-directional (Autoregressive : 한쪽 방향만으로 가 I, love 를 가지고 you 에측)
- 하지만, sentence-level task 에 있어서, uni-directional model 은 문제를 야기할 수 있다.
- 앞 뒤 전 후의 context 를 분석해서 토큰을 예측한다거나, 다음 문장을 예측하는 데에는 약하다.
- 만약 중요한 정보가 문장의 끝에 있다면, GPT 와 같은 uni-directional model 은 그 끝에 오는 토큰들의 정보를 제대로 활용하지 못한다.
- (앞쪽에서부터 파악되면 나중에 해석이나 예측에 많이 활용 되지만 맨 마지막 부분에 토큰이 있으면 딱 한 번 예측해서 파악한 후 끝나버리기 때문에 기여도가 미미)
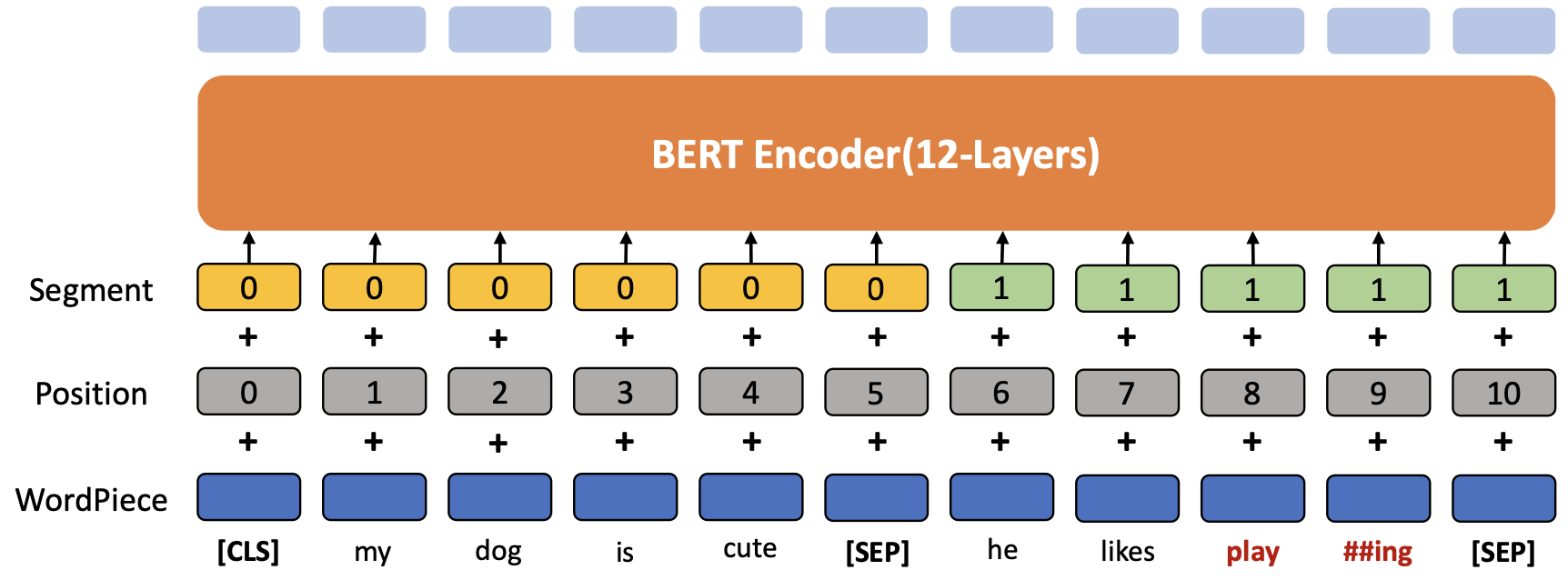
BERT 아키텍처
인코더는 정답지 타켓도 없는데 어떻게 학습이 될까
인풋에서는 인코더의 아키텍처의 충실하기 위해서 인풋만 들어감
트랜스포머의 경우 enoder-decoder multi-attention 에서 attention(Q, K, V) 에서 Q, K 의 결과만 사용했었다.
그런데 BERT에서 학습 해야 하는데 output 이 나왔을떄, 즉 teacher 가 되어줄게 없음.
그래서 BERT 는 output 에 정답이 되는 것을 하나가 딱 기다리고 있음
인코더만 사용해서 성공했다고 하는 편법이자 스마트한 발상의 전환
하나 주목할 것은
트랜스포머는 레이어를 6번 반복했지만, BERT 에서는 12번 반복
처음 시작할 것은 CLS 을 사용
새로운 문장(다른 문장)을 추가로 더 할 경우 SEP 토큰을 가운데 넣어줌
마지막을 가리키기 위해서 또한 SEP 을 넣어줌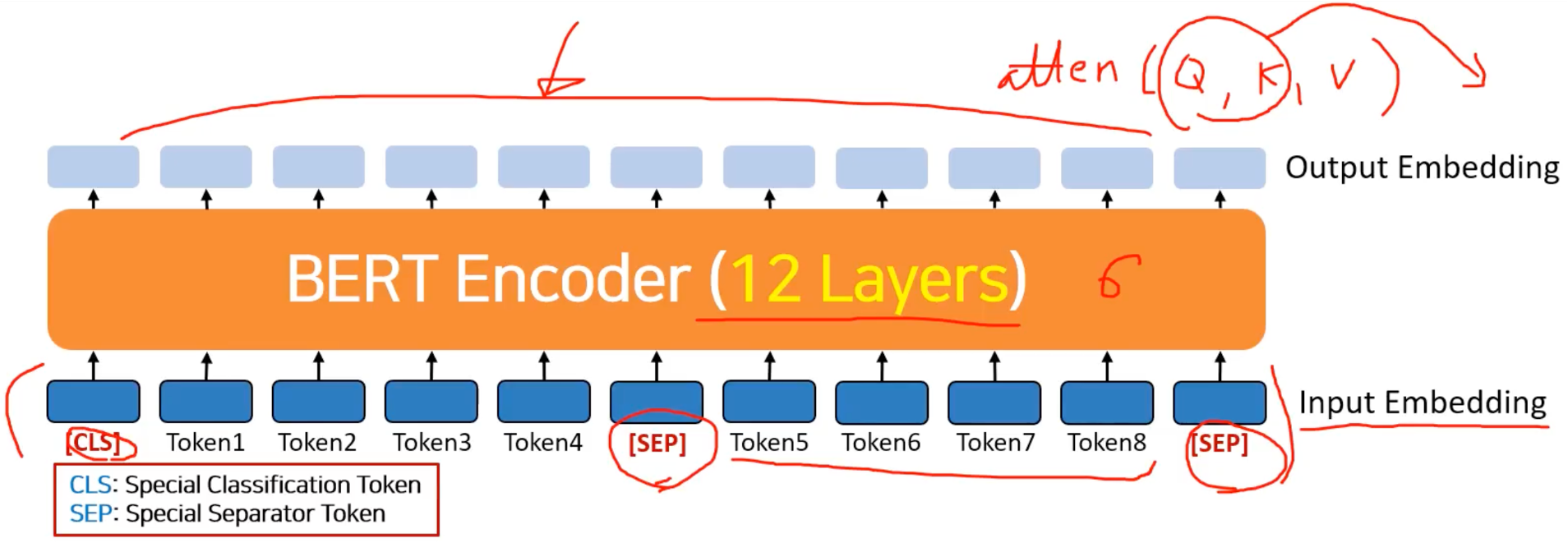
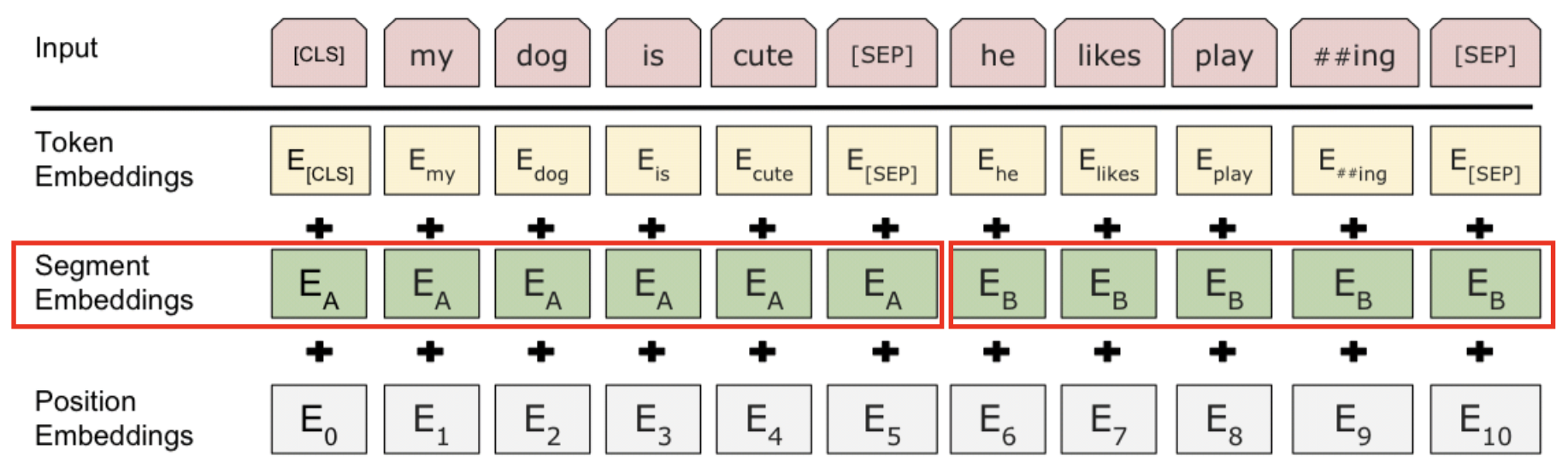
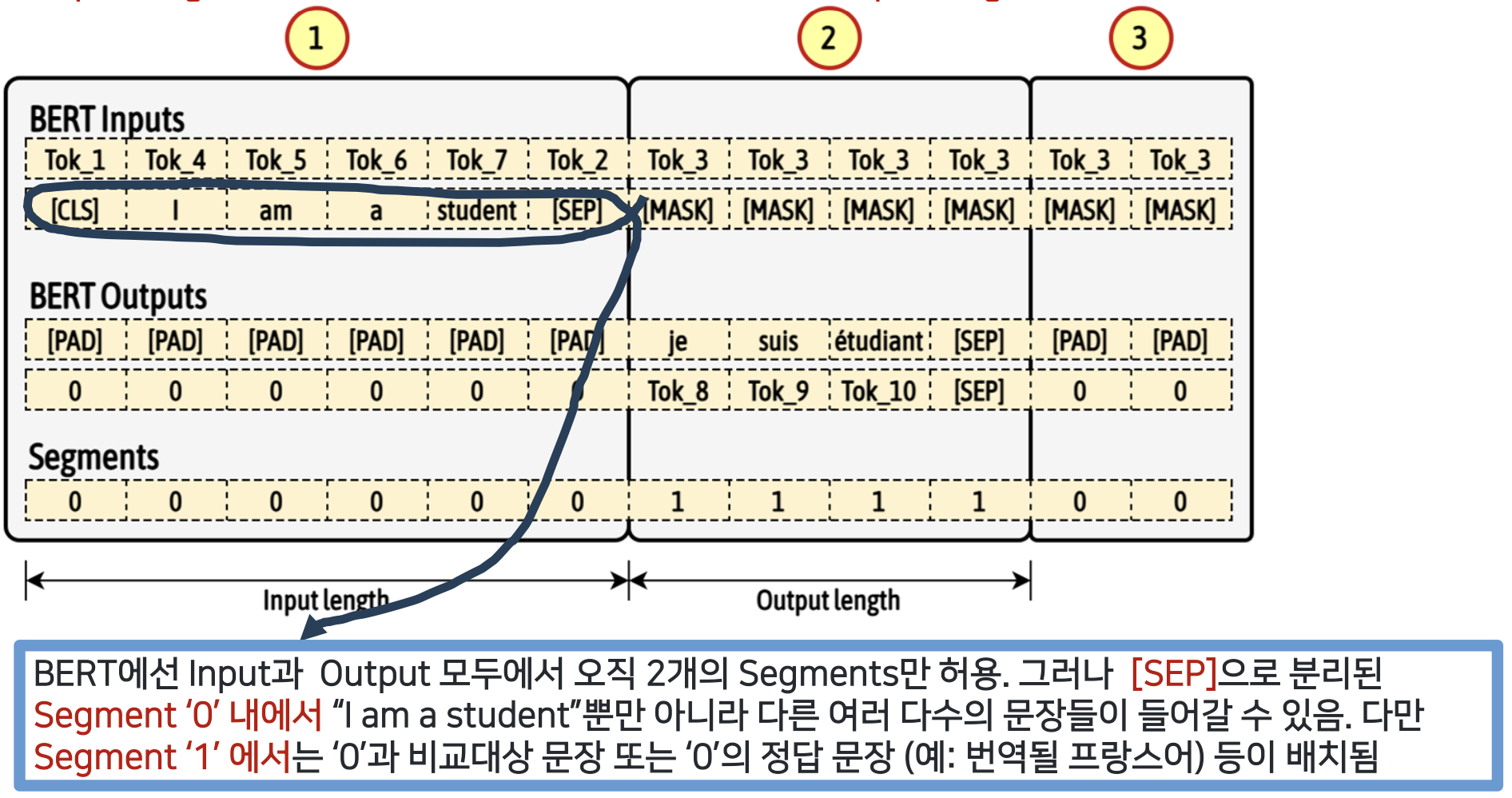
BERT 의 Input Embedding
기본적인 원리는 transformer 의 인풋 임베딩과 같지만 차이점도 있다.
BERT 에서 Input 세그먼트를 두 개를 사용할 수 있음
세그먼트가 무엇이냐?
my 에 대한 토큰 임베딩은 트랜스포머처럼 다른 dictionary 가 있음
거기에서 인덱싱 해서 디지털로 변환하는 것은 같다.
WordPiece Embedding 의 원칙에 의해서 playing 을 play 와 ##ing 로 나눠진다.
segment Embedding : 문장의 성질이 다른 것은 segment 로 나눠줌
segment 는 두개(A 와 B)밖에 못나눠줌
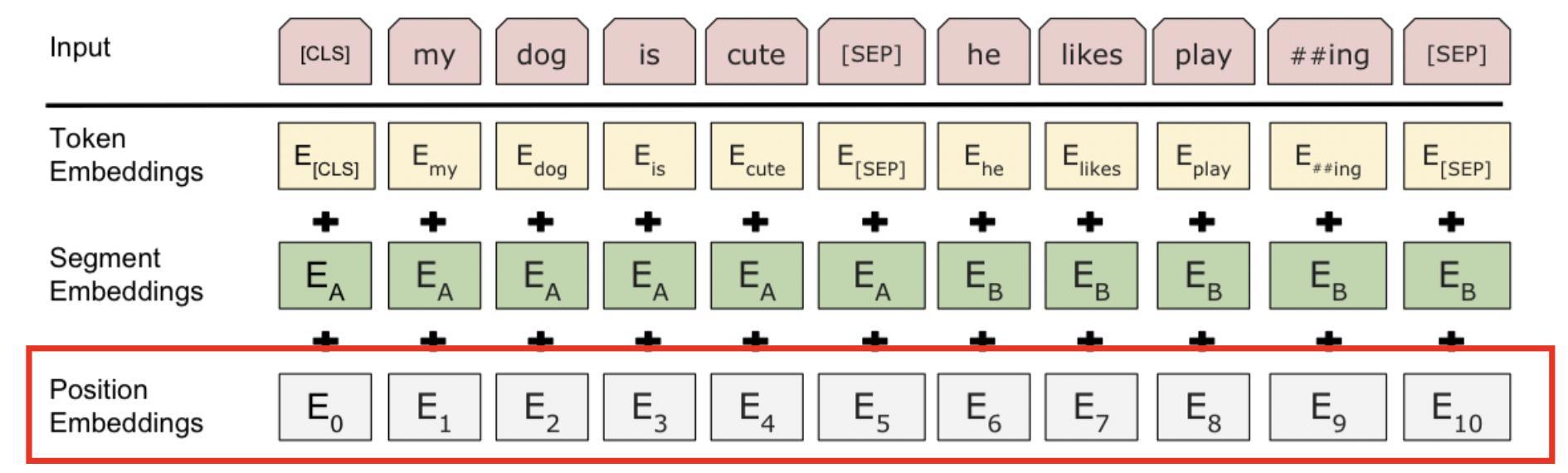
Positional Embedding : 트랜스포머에서는 사인 코사인을 사용해서 포지셔널 임베딩을 해줬는데, 여기서는 간단함. 그냥 순서대로 순서를 적어줌 (E_0, E_1 ...)
최종 BERT Input
- CLS 토큰에 대해서 한번
- Token Embedding + Segment Embeddings + Positional Embedding
- my 토큰에 대해서 한번
- Token Embedding + Segment Embeddings + Positional Embedding
- ...
- 다 합한 것이 input
Token Embedding by WordPiece in BERT
Original sentence "My dog is cute, he likes playing"- WordPiece 는 BERT 만의 특징
- Vocabulary Set Size : 30522 토큰, playing 과 같은 동명사들은 set 안에 없음
- Subword tokenization that splits into smaller units than a word
- ❶ : 원본 문장을 단어들로 쪼갠다
- ❷ : 만약 한 단어가 vocabulary set 에 존재한다면, 단어를 쪼개지 않는다
- ❸ : 만약 한 단어가 vocabulary set 에 존재하지 않는다면, 2개의 subwords 로 쪼갠다.
(단어의 첫 번째 subword 를 제외하고, 다른 subword 는 ## 을 앞에 붙인 단어이다)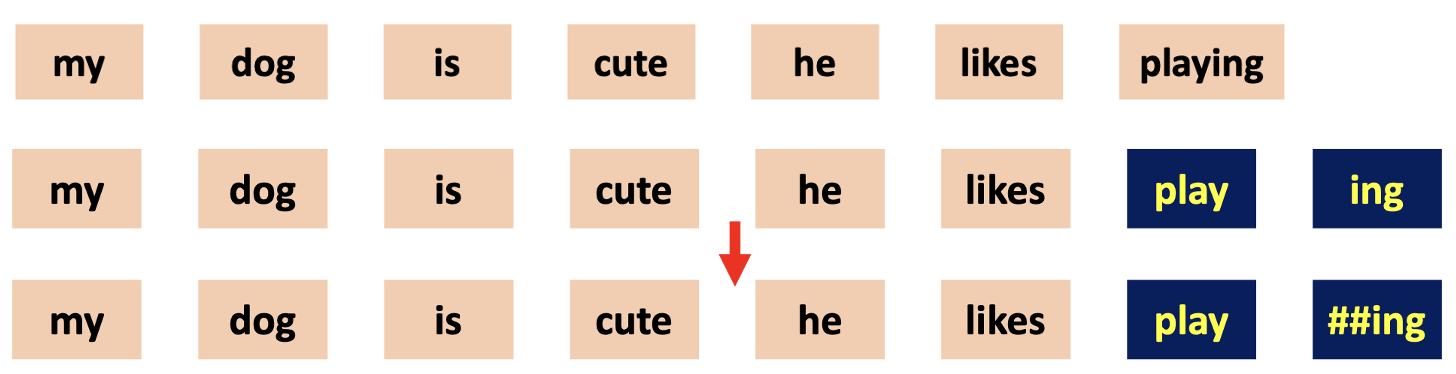
Segment Embedding
- 문장 분리를 위해 BERT는 세그먼트 임베딩을 사용합니다
- 첫 번째 문장에 문장 A 임베딩을 추가하고 두 번째 문장에 문장 B 임베딩을 추가합니다
- 세그먼트 임베딩 벡터는 두 개만 사용됩니다
- 모델이 한 문장만 받으면 입력에 문장 A 임베딩만 추가합니다

Position Embedding
- 심플하게 까지 임베딩
- attention mechanism은 각 토큰의 위치를 고려하지 않기 때문에, BERT는 Transformer와 같이 Position Embedding 을 사용합니다
- 각 토큰에 Position Embedding 을 추가하기만 하면 됩니다 (단, BERT는 Synosoid Positional Embedding을 사용하지 않습니다)
BERT 의 Input Embedding 요약
- BERT는 input을 위해 3개의 embedding layer 를 사용
- 1) WordPiece Embedding
- WordPiece Embedding Vectors 는 30,522 vocabularies set 을 가짐
- 2) Position Embedding (input sequence size)
- Position Embedding Vectors 는 최대 문장의 길이인 512 이다.
- 3) Segment Embedding
- Segment Embedding Vectors 는 독립적인 단락의 최대 수인 2이다.
- 1) WordPiece Embedding
BERT 아키텍처
인풋이 다 채워지지 않았을떄는 역시 패딩으로 맟춰주는 작업이 필요함
마지막에 헤드 개수 만큼 나누줘서 아웃풋을 보내줌 (멀티 헤드 어텐션)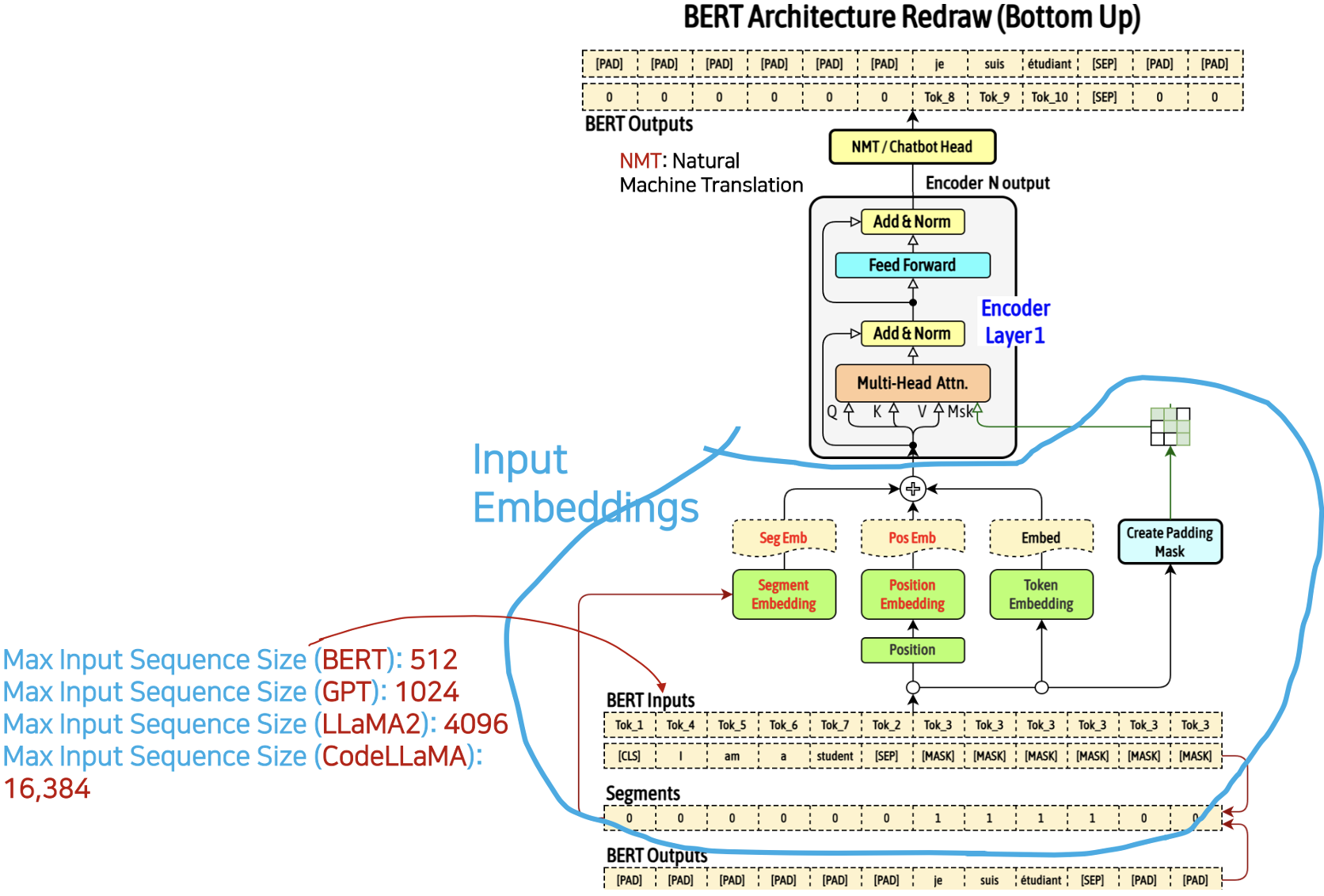
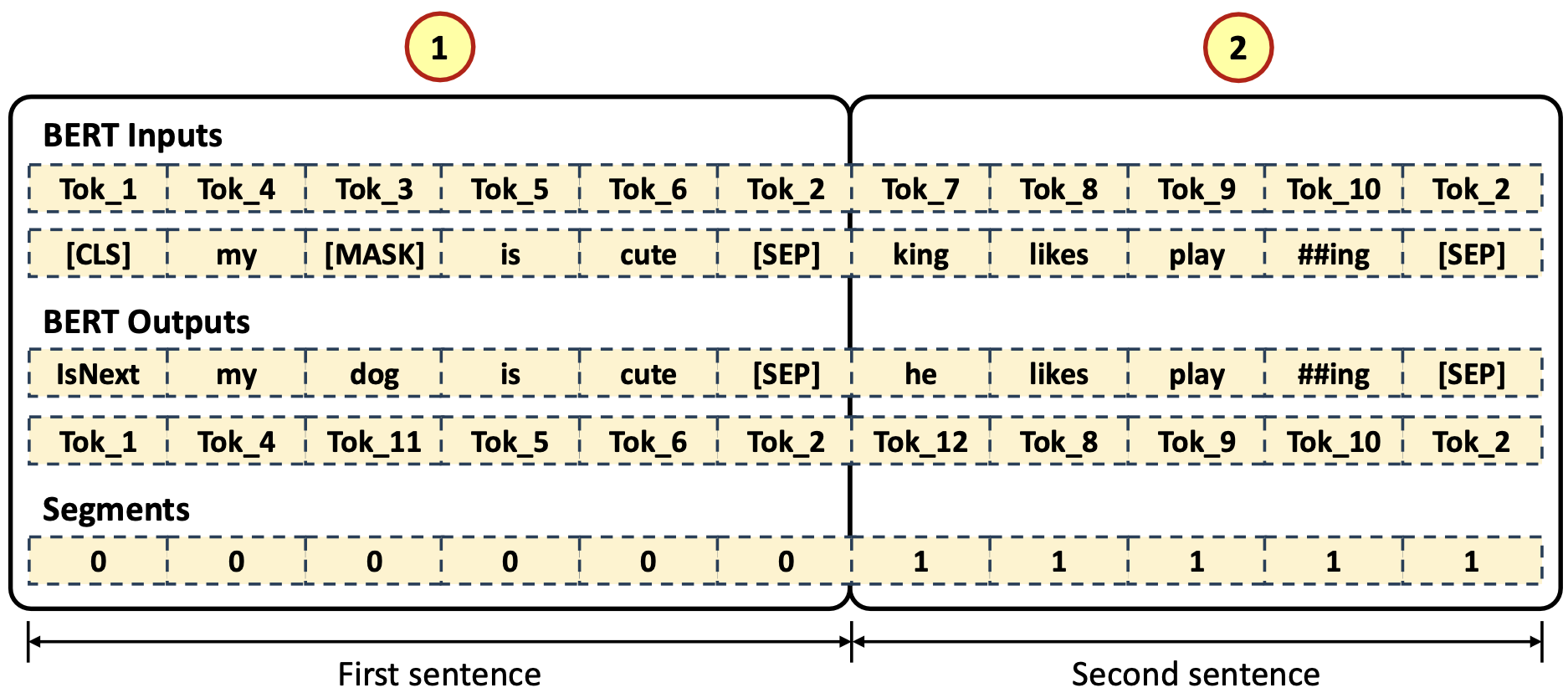
Building BERT Inputs, Outputs, Segments
- Input Tokenized Data (NMT, Natural Machine Translation with MASK)
- [CLS] token 이 첫 번째, input data token(❷) 그리고 [SEP] token, 나머지는 output 과 매칭을 하기 위해서 [PAD] token 들로 채워짐
- Output Tokenized Data
- Output 의 Input 부분을 의미없게 Input length 만큼 [PAD] 토큰들로 먼저 채운다. 그 다음에 output tokenizaed data(❷) 가 오고 [SEP] token 을 채운 다음 나머지 부분은 [PAD] 로 처리
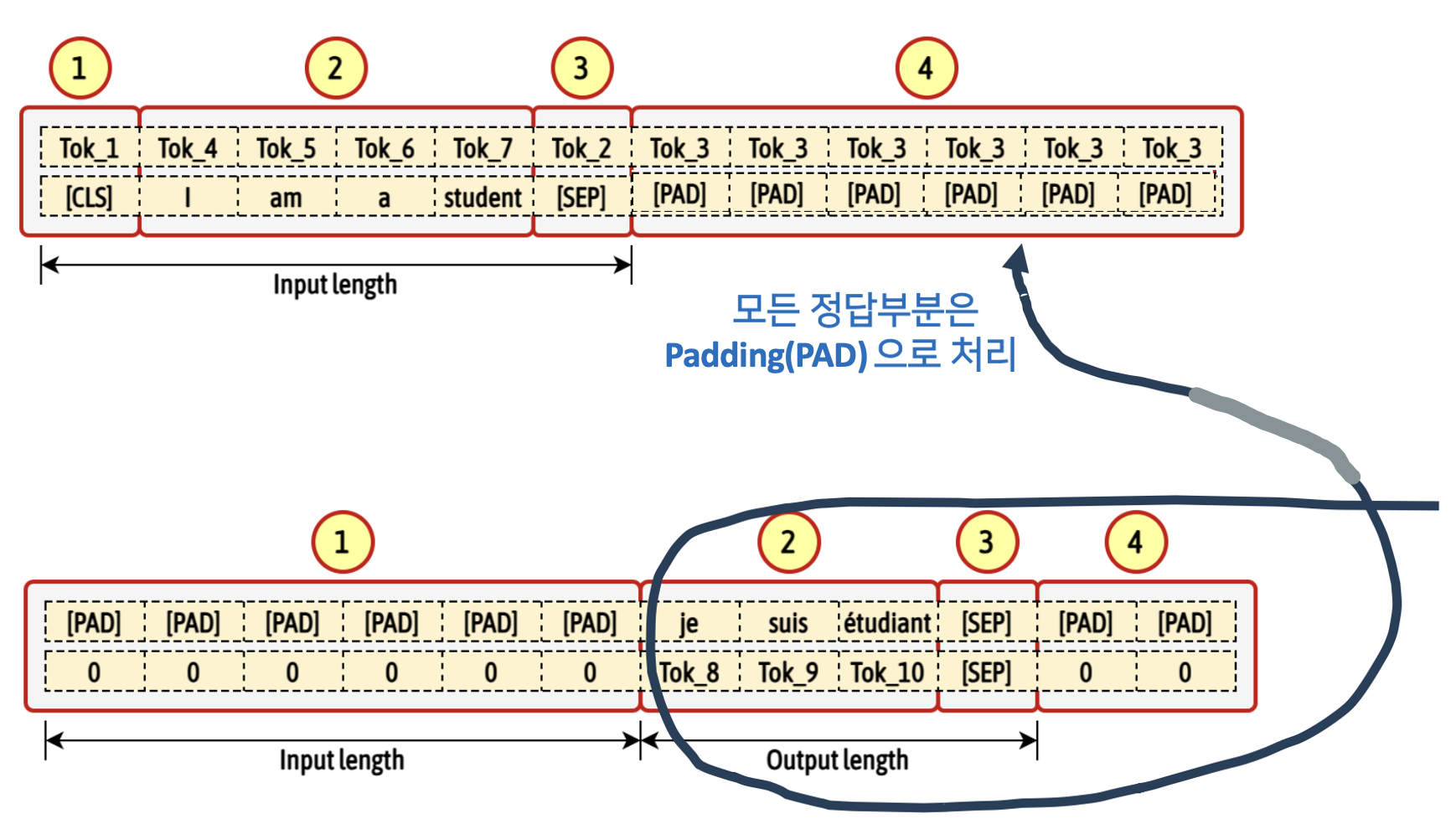
- Output 의 Input 부분을 의미없게 Input length 만큼 [PAD] 토큰들로 먼저 채운다. 그 다음에 output tokenizaed data(❷) 가 오고 [SEP] token 을 채운 다음 나머지 부분은 [PAD] 로 처리
- Segments
- Input length 만큼 '0'(❶) 으로 채운다. 그 다음 부분은 Output length 만큼 '1' (❷)로 채운다. 나머지는 '0'(❸) 으로 채움
- Input length 만큼 '0'(❶) 으로 채운다. 그 다음 부분은 Output length 만큼 '1' (❷)로 채운다. 나머지는 '0'(❸) 으로 채움
How BERT Pre-training (= Scratch) works
(Self-Attention Case)
- Input 과 Output : 같은 문장 'I love you'
- 각 Output 토큰이 12개의 Encoder layer를 통과할 때마다, self-attention은 출력 계층에서 모든 토큰의 contextual information 을 업데이트할 것이다.
- self attention -> 트랜스포머와 별 차이가 없음
- 하나의 워드 벡터가 모든 워드 벡터를 지칭하는 연산은 BERT의 모든 12개의 인코더 레이어에서 발생하고 있습니다
- 각 레이어의 출력 임베딩 벡터는 다음 레이어의 입력 임베딩 벡터가 됩니다
- 12층 후에 출력 임베딩 벡터를 얻을 수 있습니다
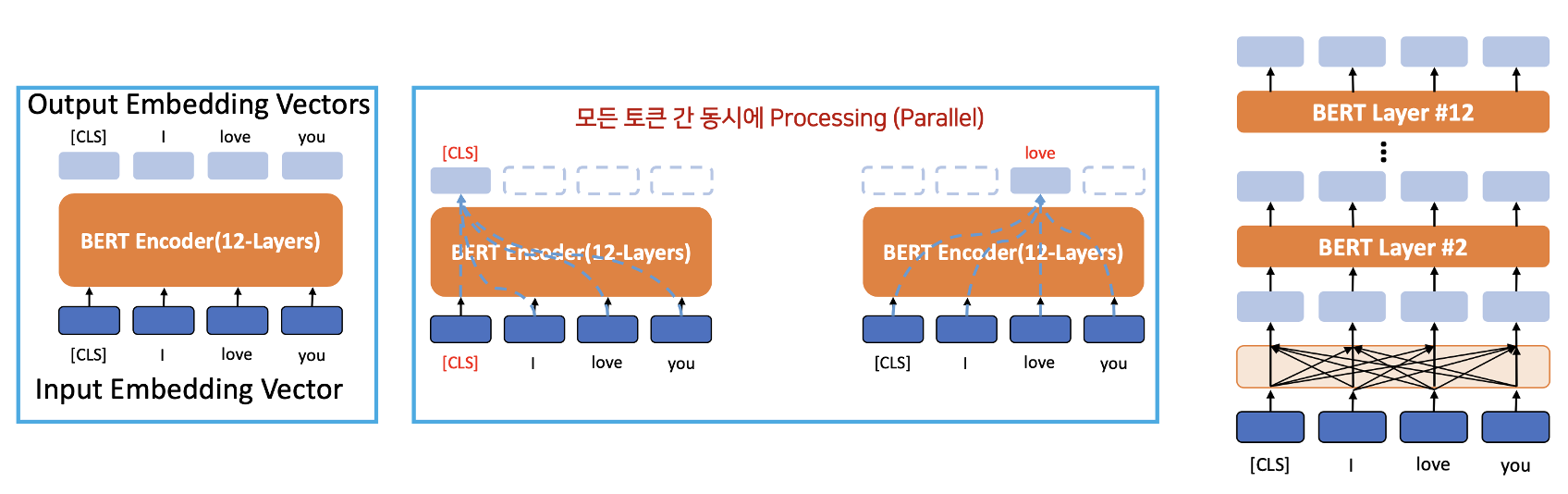
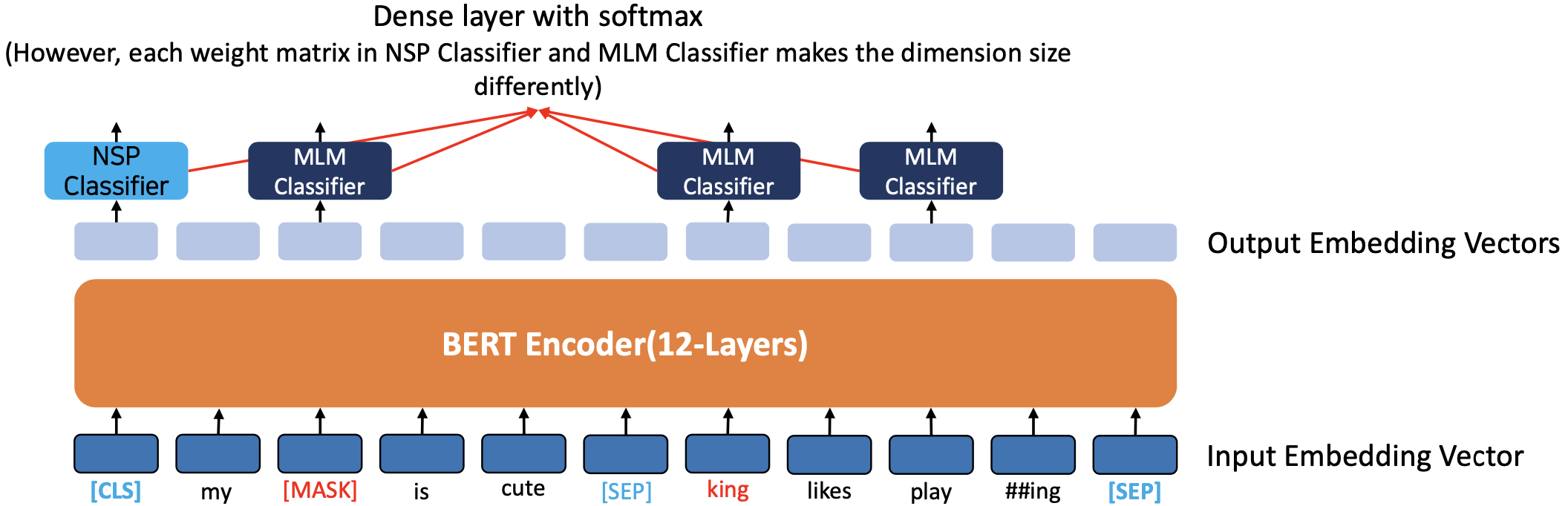
BERT Pre-Training (Scratch)
pre-training 의 두가지 타입
❶ Masked Language Model (MLM) - 트랜스포머에는 없었던 것
- 입력 텍스트의 15%가 무작위로 마스킹됨
- market 이 랜덤하게 선택이 되어 마스킹 됨
- 그 다음 fruits 도 선정되어 마스킹 됨
- 그렇게 마스크된 단어들(market, fruits)을 예측하도록 모델을 학습시킨다.
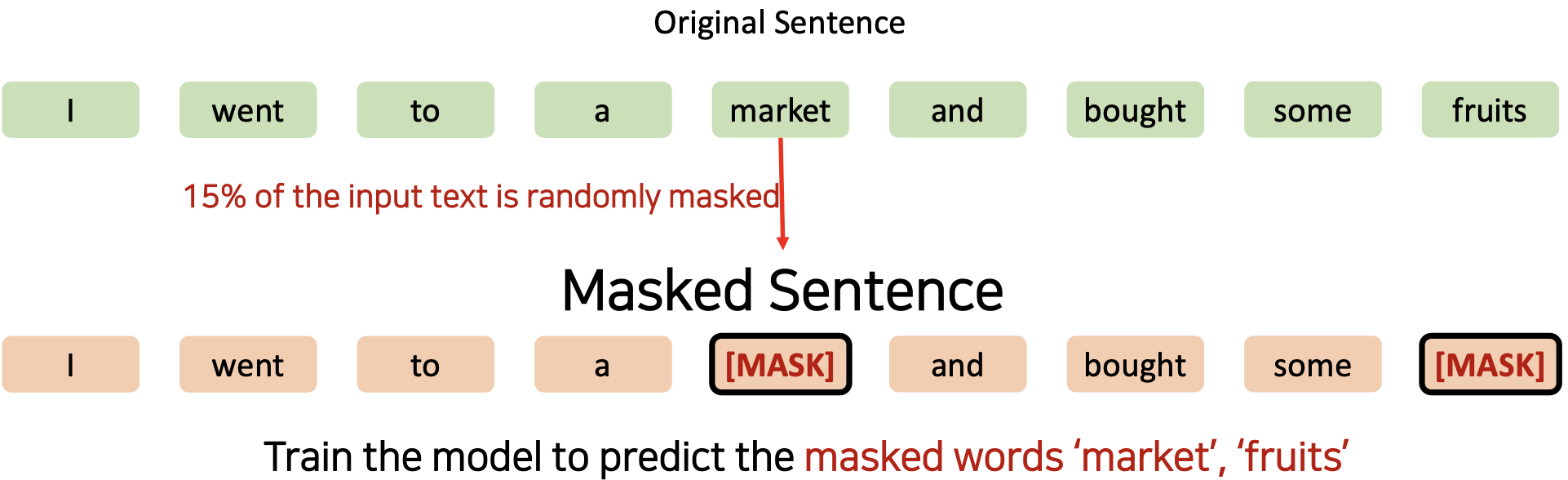
- 하지만, Fine-tuning 과정에서는 [MASK] 토큰을 사용하지 않습니다
- pre-training 과정과 Fine-tuning 과정이 일치하지 않는 문제점이 있다.
- 불일치 문제를 해결하기, 위해 임의로 선택한 15% 단어의 모든 토큰을 [MASK] 토큰으로 사용하지 않는다.
- 80% 단어만 [MASK] 마스킹 하고
- The man went to the store The man went to the [MASK]
- 10% 는 아무런 관계 없는 랜덤한 단어로 교체 (store dog 로 교체)
- The man went to the store The man went to the dog
- 혼란을 주기 위해서 나머지 10% 단어는 같은 것을 사용
- The man went to the store The man went to the store

- The man went to the store The man went to the store
- 80% 단어만 [MASK] 마스킹 하고
- 정리
- 전체 단어의 85%가 모델 훈련에 사용되지 않음
- 훈련에 사용되는 단어는 전체 단어의 15% 입니다
- 전체 단어의 12%를 [MASK] 토큰으로 변경하여 Original 단어를 예측합니다
- 전체 단어의 1.5%가 무작위로 변경되어 Original 단어를 예측합니다
- 전체 단어의 1.5%는 변하지 않지만 모델은 단어가 바뀌었는지 안 바뀌었는지 모릅니다 (또한 원래 단어를 예측합니다)

- MLM Pre-training
- 'dog' 토큰은 [MASK] 토큰으로 대체되고 모델은 마스크된 단어를 예측합니다
- Output layer 에서 다른 위치에 있는 벡터는 예측 및 학습에 사용되지 않고, Output layer 의 'dog' 의 벡터만 학습 및 예측에 사용됩니다
- 마스크된 단어를 예측하기 위해, Output 벡터는 MLM clssifier 를 통과 하고 Original 단어를 예측합니다
- 높은 확률 값을 가지는 'dog' 혹은 'cat', 'son' 등등이 와도 됨
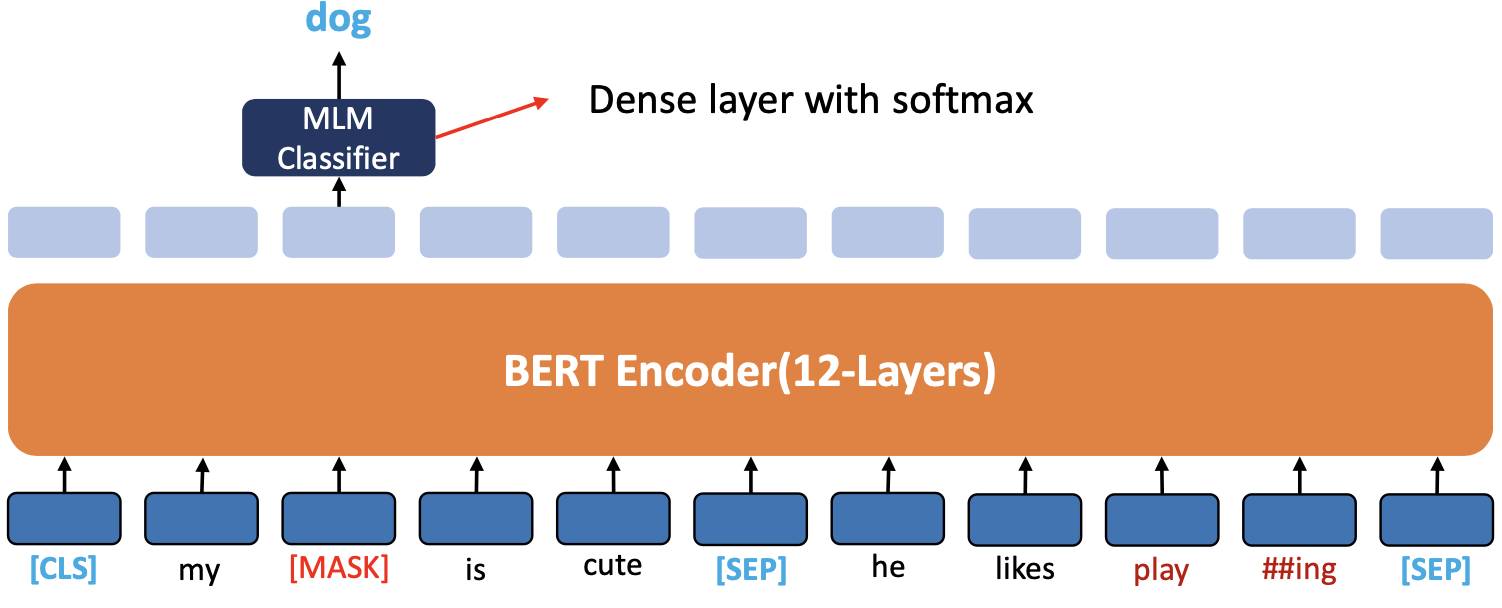
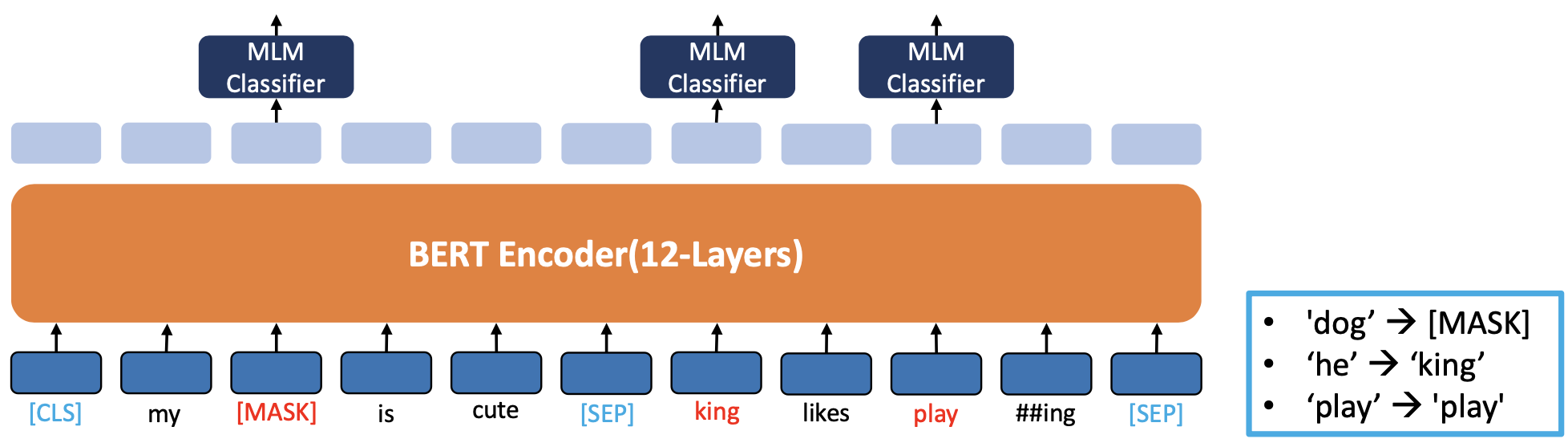
- (85%) [MASK]의 원래 단어 예측
- (15%) '왕'에 대한 원어 예측('그'에 대해 무작위로 선택)
- (15%) '놀이'의 원어 예측(원어 그대로 유지하도록 무작위로 선택)
- BERT는 'play'라는 단어가 대체되었는지 여부를 알지 못합니다
- 해설
- king 이라는 랜덤한 엉뚱한 단어로 교체하고 그것이 맞는지 틀린지 MLM clssifier 로 판단
- Output 이 3만개의 컬럼(vocabulary set)이 다 연결이 되어있고
- MLM Classifier 를 통해서 king 은 확률값이 가장 낮은 값이 나와야 함.
- play 도 마찬가지로 높은 확률값이 나오게 될것임
- play 가 아니더라도 practicing 단어와 같이 확률이 높은 토큰들이 올수도 있음
❷ Next Sentence Prediction (NSP)
- 주어진 두 문장이 연속적인 (연관된) 문장인지 아닌지를 추측하기 위해 모델을 학습시킨다
- 실제 연결된(연관된) 문장과 랜덤하게 연결된(연관되지 않은)문장의 비율은 50:50입니다
- 즉 I love you, I'd like to eat brunch. -> 서로 연관이 없는 두 문장
- 이처럼 50%는 연관이 있는 것, 50% 는 서로 연관되지 않은 것들을 임의로 넣어서 훈련시킨다.
- "이것은 연관된 것입니다." 하고 맞추도록 학습키시고, "이것은 연관되지 않은 것입니다" 하고 맞추도록 한다.
- 에)
- 두 문장이 서로 연관이 있는 경우
- IsNextSentence 의 확률이 높아진다.
- 두 문장이 서로 연관이 없는 경우
- NotNextSentence 의 확률이 높아진다.

- 두 문장이 서로 연관이 있는 경우
Simultaneout MLM ans NSP Pre-training
- BERT 에서 MLM과 NSP가 동시 에 학습됨
- 두 문장을 구분하기 위해 각 문장 끝에 [SEP] 토큰을 넣는다.
- [CLS] 토큰 위치의 출력 레이어에서 이진 분류 문제를 해결하여 두 문장의 연속 여부를 파악합니다
- NSP의 목적은 질의응답이나 자연어 추론(NLI)과 같은 두 문장 사이의 관계를 이해하기 위해 중요한 과제를 해결하는 것입니다
- 과정
- 제일 아웃풋에 가장 먼저 판정을 내려주는 것이 NSP
- 인풋 토큰은 두 sentence 로 이루어지니까 [SEP] 로 구분해주고
- 그 안에 sentence 들에서 Masking ([MASK]), Replacing (king), 그대로 (play) 해주고
- 그리고 나서 MLM Classifier 를 통해서 Masking 해준 것 예측하고, Replacing 한 것이 맞는지 틀린지 확률 값 구해주고, Original 토큰도 맞는지 틀린지 확률 값 구해준다.
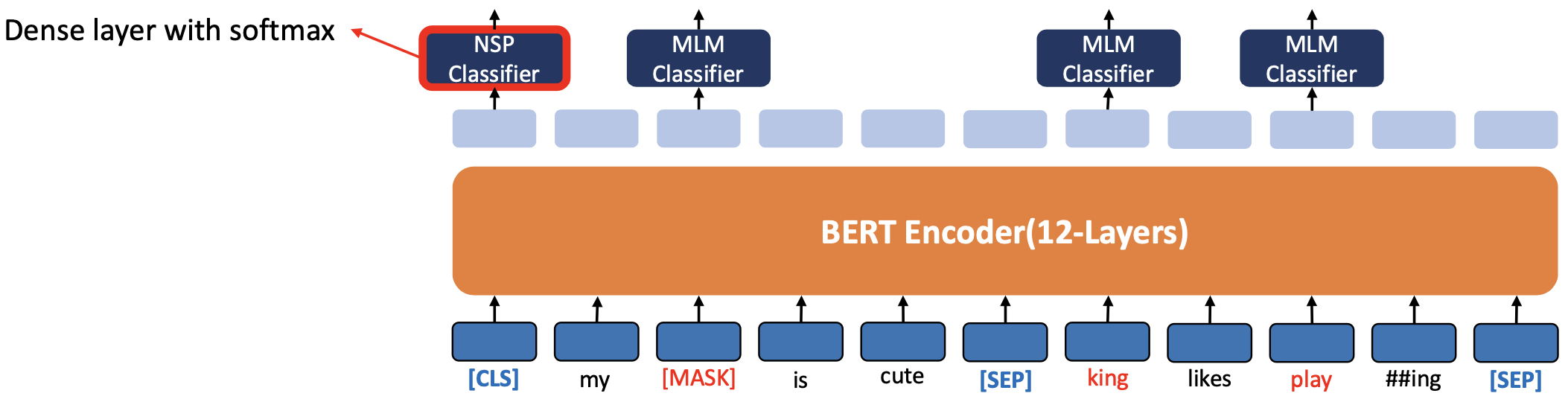
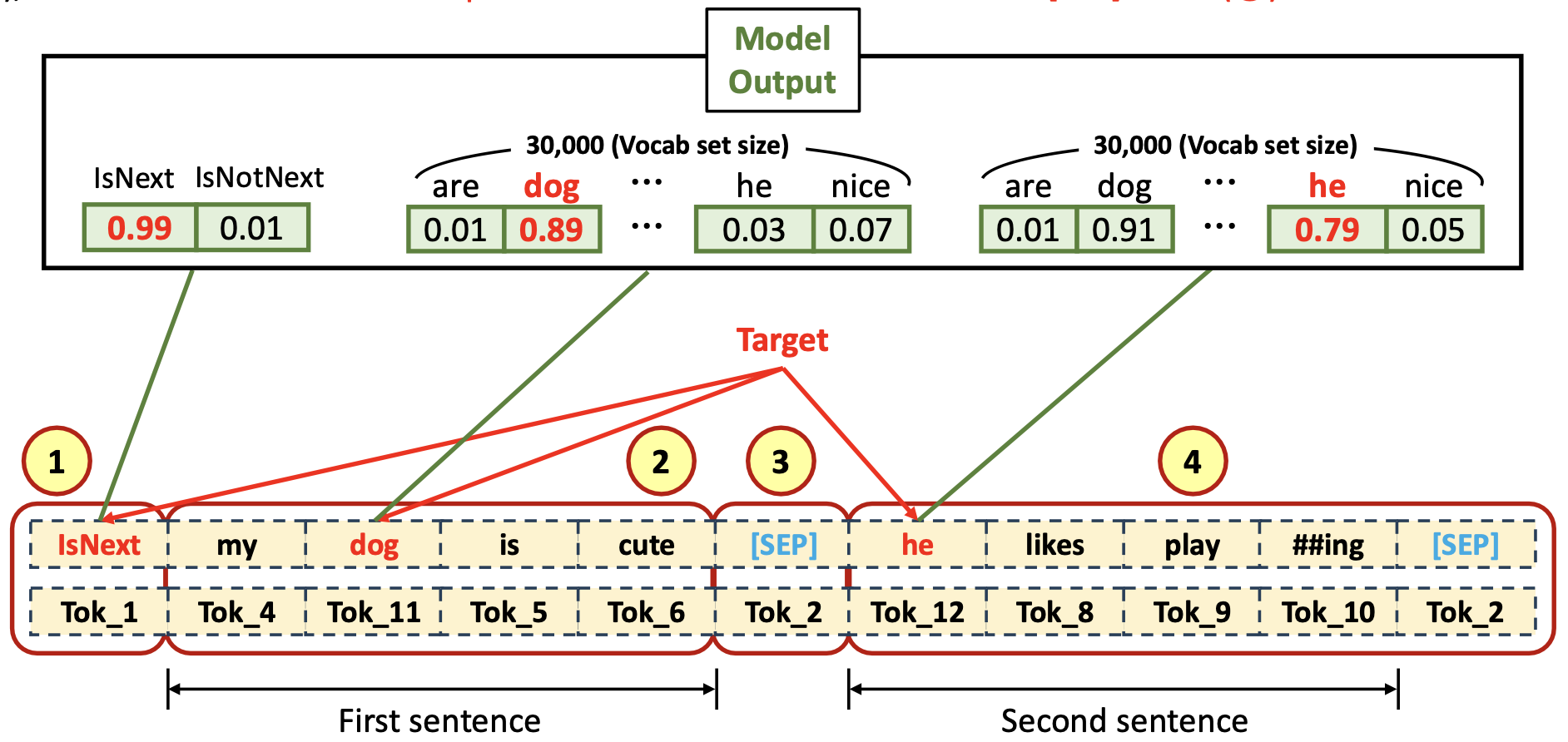
Pre-training (MLM & NSP)
- Input Tokenized Data
- [CLS] token 이 첫 번째 (❶), first sentence input data tokens (❷) 그리고 [SEP] token (❸), 나머지는 second sentence input data token 들과 [SEP] token (❹) 으로 채워짐
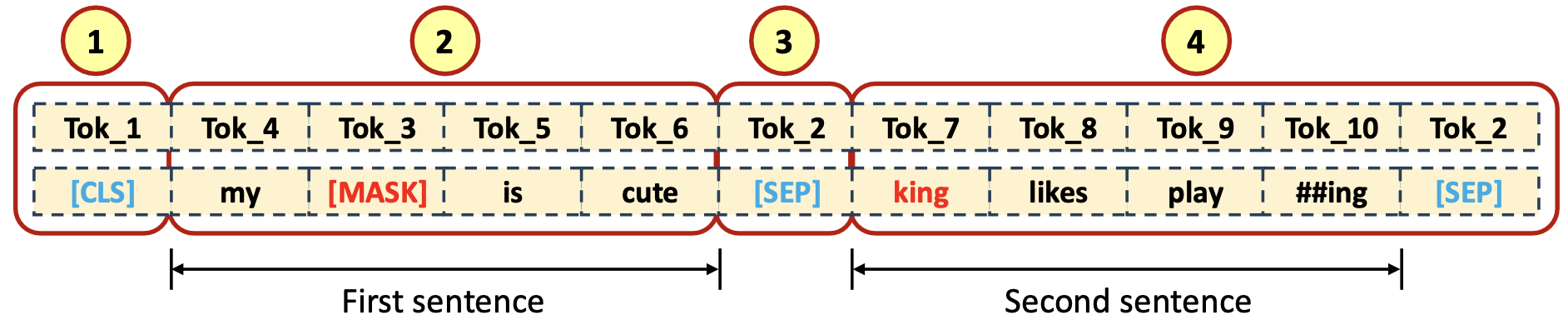
- [CLS] token 이 첫 번째 (❶), first sentence input data tokens (❷) 그리고 [SEP] token (❸), 나머지는 second sentence input data token 들과 [SEP] token (❹) 으로 채워짐
- Output Tokenized Data (Labled(Tagged) Target)
- [CLS] token 에 대한 label 이 첫 번째 (❶), first sentence input data tokens (❷) 에 대한 label tokens 그리고 [SEP] token (❸), 나머지는 second setence input data token 에 대한 label token 들과 [SEP] token (❹) 으로 채워짐
- Output 결과
- SEP로 구분된 두 문장이 서로 연관되어 있느냐 하면 IsNext, 연관 없으면 IsNotNext 부여
- 원래 마스크 된 것에 확률 값이 높은 dog, replacing 한 것중 확률이 높은 he가 아웃풋으로 결정될 수 있다
- 이때 vocabulary 3만개를 다 연결해줘야 한다 부족한 단어들은 WordPiece 로 해결
- 이런식으로 인코더 아웃풋이 디코더의 역할(target 정답지 제공) 을 한다고 볼 수 있다.
- Segment
- First sentence input length 만큼 '0'(❶) 으로 채운다. 그 다음 부분은
- Second sentence input length 만큼 '1'(❷) 로 채운다.
Numerical Example (NSP & MLM)
-
입력 개?
- BERT 모델의 차원이 8개의 head를 사용하고, 한 헤드당 64개의 value 를 사용함 (트랜스포머와 동일)
- 과 곱해줘야 하므로 NSP classifier 의 행 사이즈가 512 여야 함
-
input token size : 11개
-
NSP Classifier 는 두 종류의 label(IsNext, IsNotNext) 칼럼을 사용한다. -> weight matrix 의 사이즈가 2가 되고 그게 칼럼이 된다
- IsNext 또는 IsNotNest 에 대한 확률 값 구하기
-
MLM 들은 칼럼들이 3만개가 연결되어서 FFNN 와 Softmax 를 통해서 확률을 구한다.
- 3만개를 다 연결해줘서 각 11개의 토큰에 대한 확률 값 구하기
- 3만개를 다 연결해줘서 각 11개의 토큰에 대한 확률 값 구하기
-
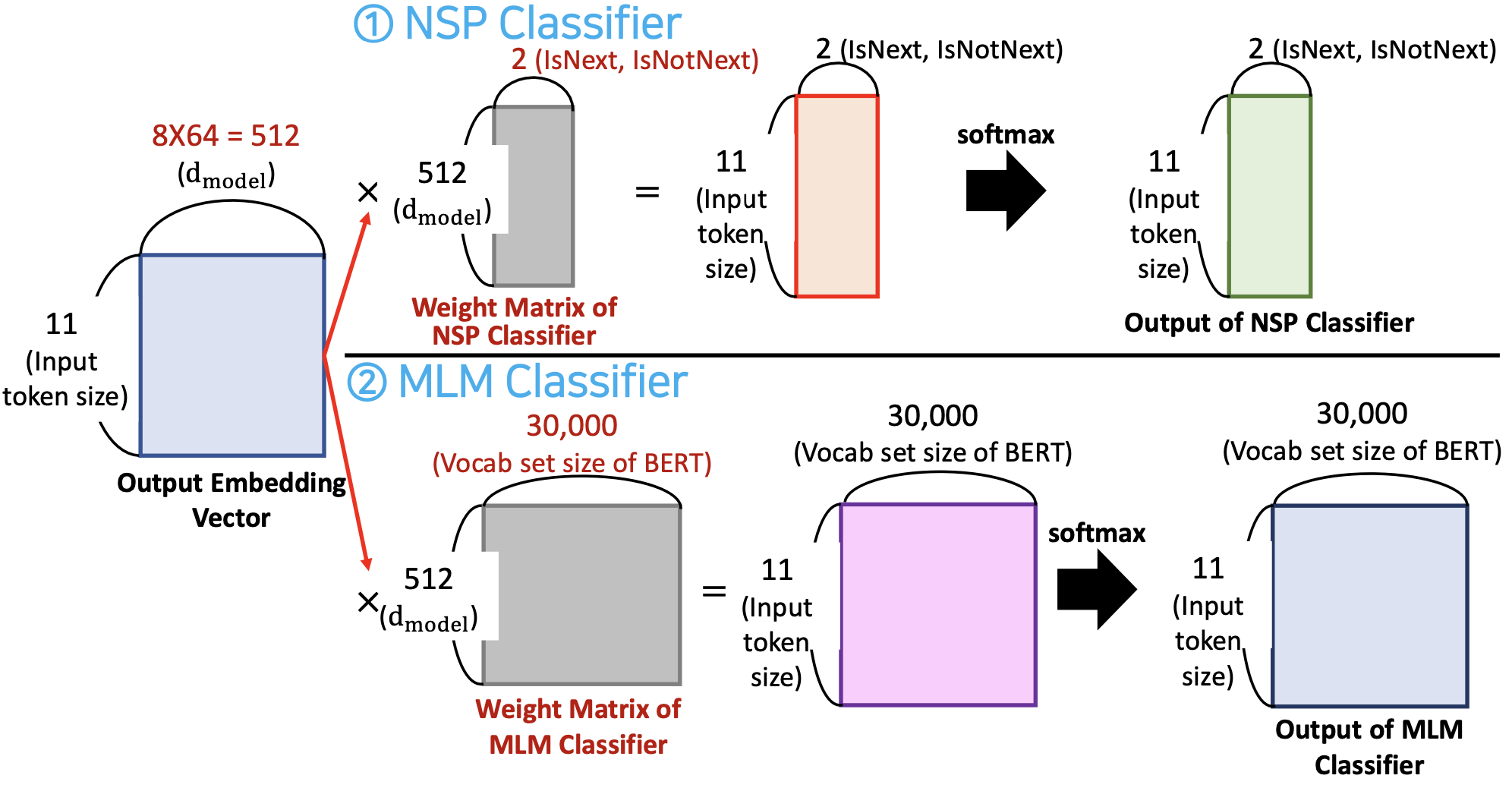
1) NSP Classifier
- 위와 같이 BERT 의 encoder block 으로부터 output embedding vector 를 얻었다고 가정해보자
- 실제 output embedding vector size =
- 그러나, 쉽게 계산하기 위해서 으로 설정
- NSP Classifier 의 weight matrix 는 input 의 dimension size 를 2로 만든다.
- NSP Classifier 는 오직 2 종류의 레이블만 가진다 (IsNext, IsNotNext)
- Softmax 를 적용한 후,[CLS] 토큰의 softmax value 를 확인하므로써 , 두 문장이 연속적인지(연관이 있는지) 아닌지를 알아낼 수 있다.
- "IsNext 의 확률이 높기 떄문에, 두 문장은 서로 연결된것이 맞습니다" 라고 학습 결과를 알려줌
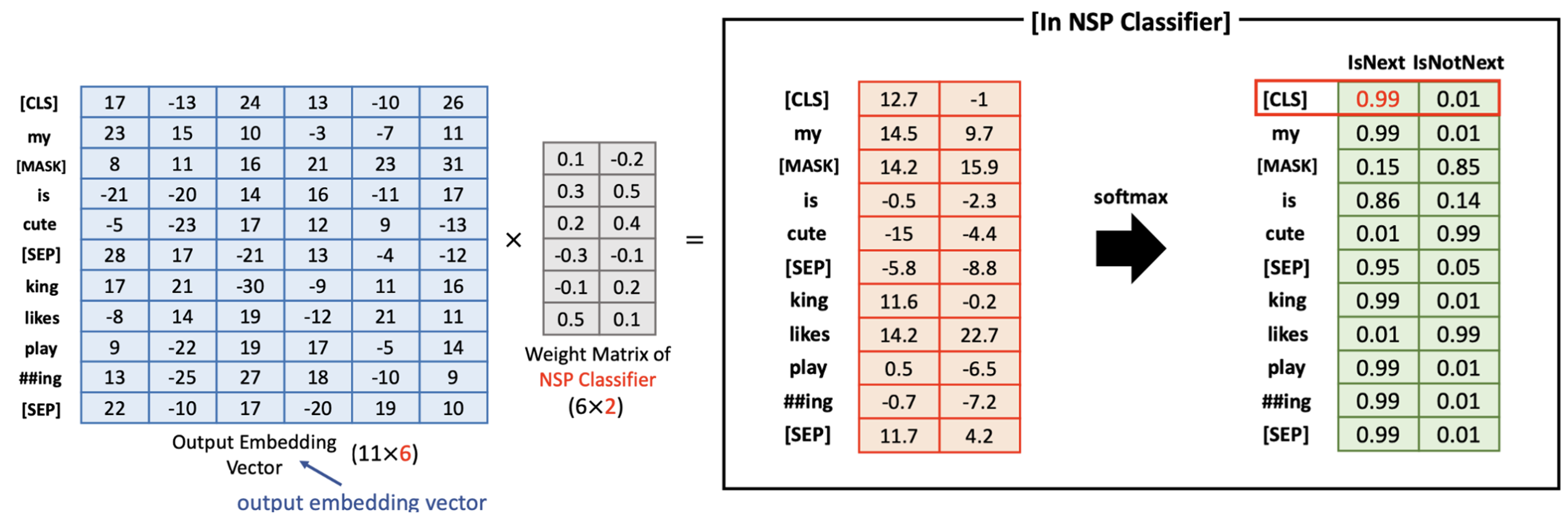
- "IsNext 의 확률이 높기 떄문에, 두 문장은 서로 연결된것이 맞습니다" 라고 학습 결과를 알려줌
- 위와 같이 BERT 의 encoder block 으로부터 output embedding vector 를 얻었다고 가정해보자
-
2) MLM Classifier
- 위와 같이 BERT 의 encoder block 으로부터 output embedding vector 를 얻었다고 가정해보자
- 실제 output embedding vector size = 그리고 실제 voacb set 사이즈는
- 그러나, 쉽게 계산하기 위해서 , vocab size = 7 로 설정
- MLM Classifier 의 weight matrix 는 input 의 dimension size 를 vocabulary set 사이즈인 7과 같게 만든다.
- Softmax 를 적용한 후, MLM Classifier 의 output 을 확인하므로써 masked token 과 randomly changed token 을 알아낼 수 있다.
- [MASK] 부분에는 dong 가 확률값이 가장 높고, king 이 아닌 he 가 확률값이 높기 떄문에 잘 못 왔구나 알 수 있음
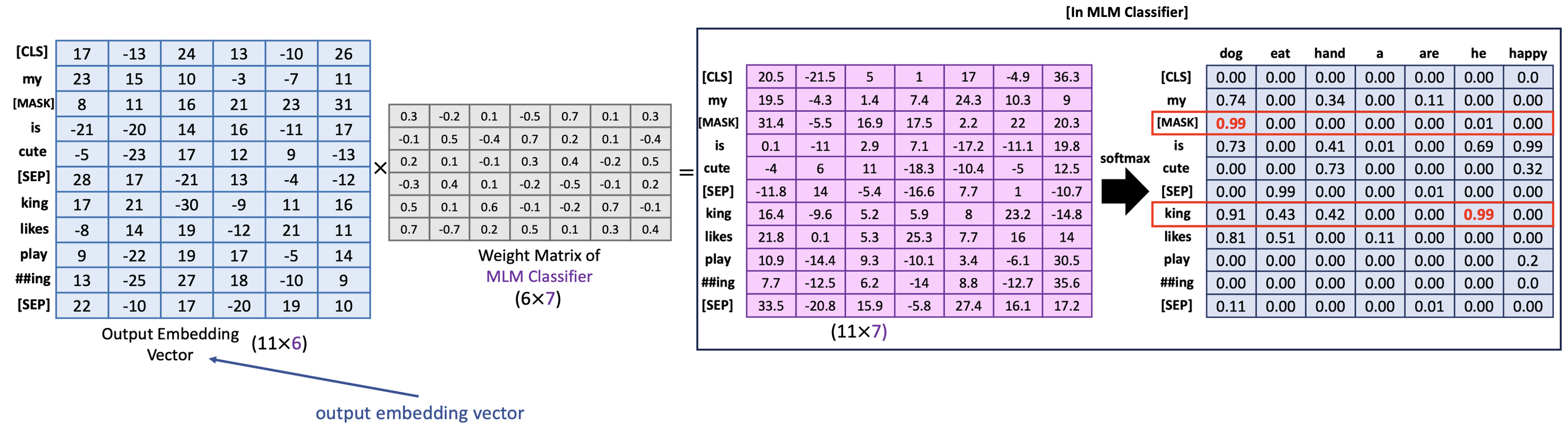
- [MASK] 부분에는 dong 가 확률값이 가장 높고, king 이 아닌 he 가 확률값이 높기 떄문에 잘 못 왔구나 알 수 있음
- 위와 같이 BERT 의 encoder block 으로부터 output embedding vector 를 얻었다고 가정해보자
마무리
- 토론주제
weight matrix 는 FFNN 을 사용한다. 그 다음에 weight matrix 는 backpropagation 을 통해 업데이트 된다.
weight matrix 는 share 한다고 했었음 (FFNN 에서)
input 에서부터 첫 번째 FFNN, 두 번째 FFNN 다 거친다음에 뒤로 역전파 해주면서 epoch 할때마다 error 를 최소화 하는 방향으로 weight matrix 업데이트를 한번씩 한다 -> 방법적으로 RNN 과 같다.
- 다음 강의 주제들
Fine-tuning of BERT
