
Unsupervised Learning 과 Self-supervised Learning 의 차이점
Self-supervised Learning 는 자기 문장 안에서 학습하는것
Unsupervised 는 센터를 지정해줘서, 선터에 있는 데이터와 가까운 데이터들을 원으로 묶어준다. 이것을 바로 clustering, 이것이 Unsupervised
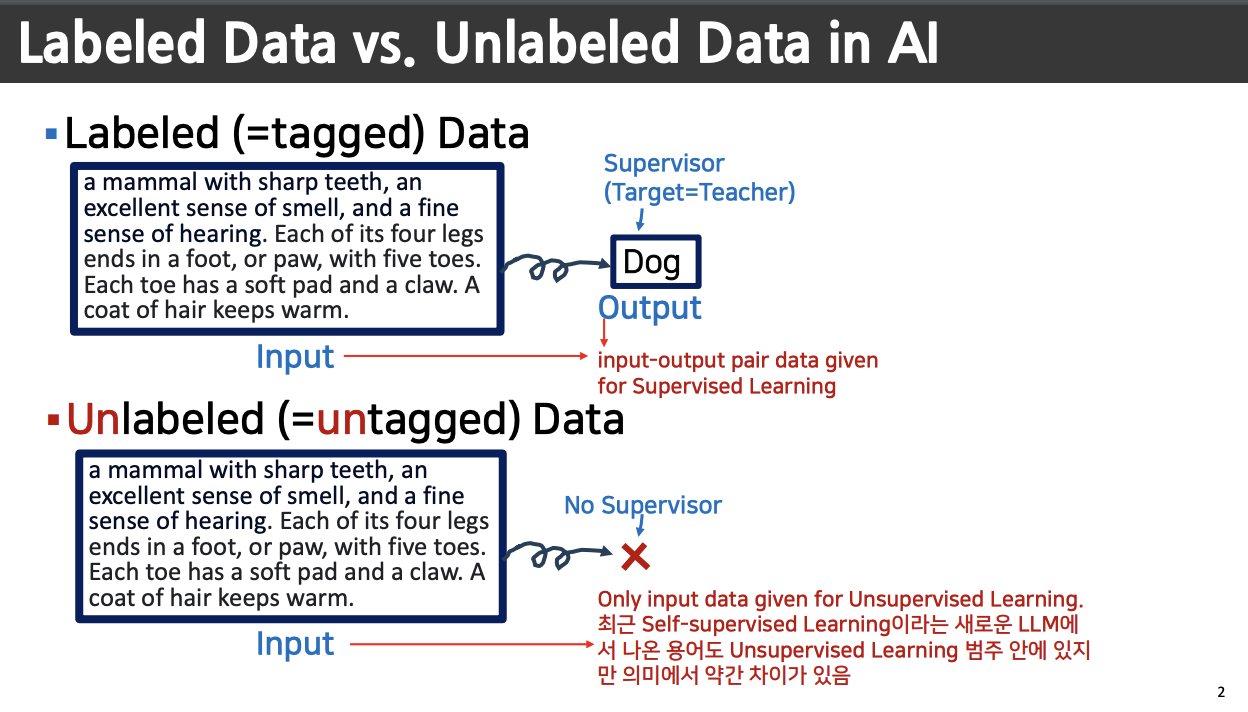
고양이와 개를 분류하는 문제, label 은 정답지 dog
Error Backpropagation
위 그림은 Deep Learning 에서 Supervised Learning 이라고 한다.
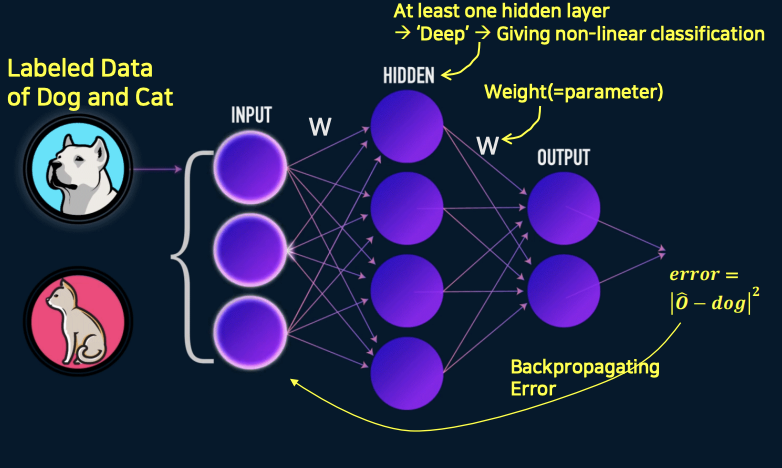
Fine-tuning 이란?
- pre-training 에서는 무작위로 untagged data 를 가지고 계속해서 학습했다. 그렇게 하다보면 나의 문제(task) 에 대해서는 LLM 이 정확한 결과를 주지 못함, 따라서 fine-tuning 을 하는 것
- 구체적인 task(일) 또는 domain(영역) 에 대하여 LLM 모델을 더 학습시키는 과정
- 이것은 LLM 을 시작점으로 사용한 다음 특정 작업 또는 도메인에 대한 레이블이 지정된 데이터의 데이터셋을 대해 training 함으로서 수행되어짐.
- fine-tuning 은 데이터에 더 잘 맞도록 모델의 가중치(파라미터)를 조정함으로써 특정 작업 또는 도메인에 대한 (Pre-trained)LLM의 성능을 향상시킬 수 있습니다
HOW? (Basic Methods)
-
Supervised Fine-Tuning (SFT)
- SFT는 레이블이 지정된 데이터를 사용하여 LLM을 훈련하는 미세 조정 유형입니다.
- 입력 및 출력(= target) 데이터 쌍(labeled(= tagged) 데이터)으로 구성되어 있으며, SFT는 LLM을 Fine-tuning 하는 비교적 간단하고 효율적인 방법입니다.
-
Reinforcement Learning from Human Feedback (RLHF)
- RLHF는 LLM을 훈련하기 위해 인간의 피드백을 사용하는 Fine-tuning 의 한 종류입니다.
- 사람의 피드백은 설문조사(suvey), 인터뷰, 사용자 연구 등 다양한 방법으로 수집할 수 있습니다.
- RLHF는 LLM을 미세 조정하는 더 복잡하고 시간이 많이 걸리는 방법이지만, SFT보다 더 효과적일 수 있습니다.
Chat GPT 답변뒤에 나오는 평가하기가 바로 강화학습이다.
-
Which Method Should You Use?
- 레이블이 지정된 데이터가 있는 경우 SFT를 사용하는 것이 좋습니다.
BERT Fine-tuning
1) Single Text Classification
2) Tagging for Single Text
3) Text Pair CLassification (Regression)
4) Question Answer (Text Generation Chabot, Content Generation)
1. Fine-tuning (Single Text Classification)
pre-trained 된 12 개의 layer 를 가진 모델 BERT Encoder 를 사용하고, Fine-tuning 을 위해 분류를 해줄 FFNN layer 를 하나 더 붙여준다.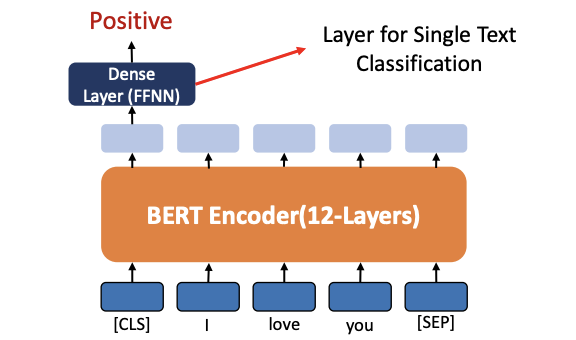
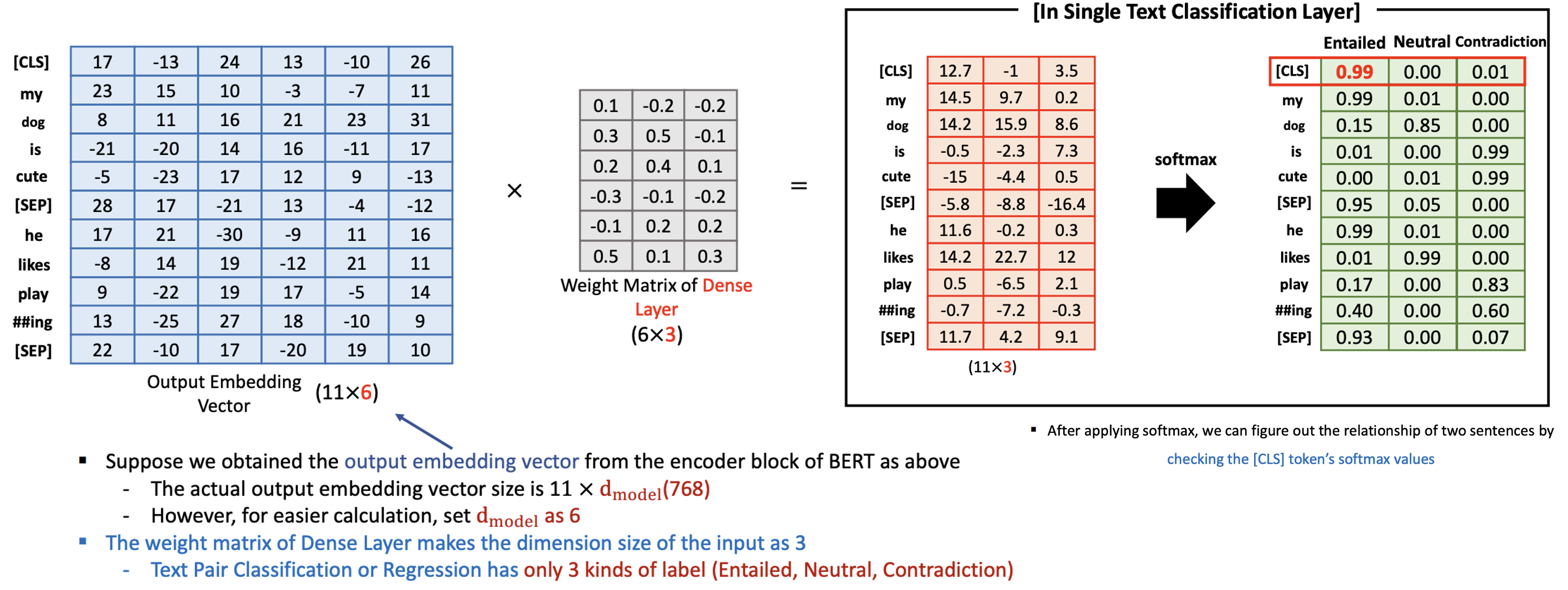
Numerical Example - Fine-tuning (Single Text Classification)
-
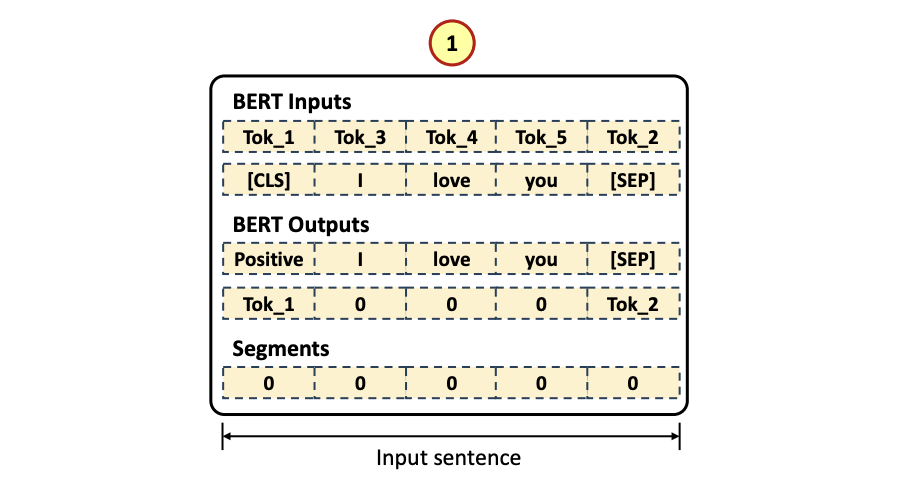
Input Tokenized Data
- [CLS] Token 이 첫번쨰 (1), Input data token (2) 그리고 [SEP] Token (3) 으로 채워짐

- [CLS] Token 이 첫번쨰 (1), Input data token (2) 그리고 [SEP] Token (3) 으로 채워짐
-
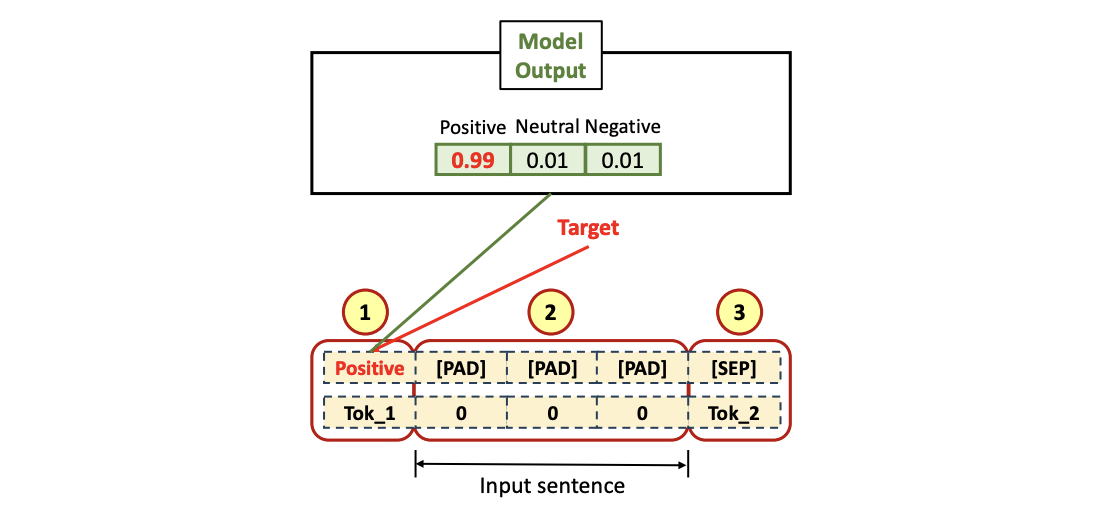
Output Tokenized Data (Labled(Tagged) Target)
- [CLS] Token 에 대한 label 이 첫번째 (1), 나머지 부분을 [PAD] 토큰들 (2)로 처리 후,[SEP] Token (3) 으로 채워짐
I love you라는 문장은 Positive 한 문장이기 떄문에 [CLS] 토큰에 대한 target data 로Positive- Softmax 의 결과로 나올
Positive,Neutral,Negative라는 3개의 tag의 칼럼을 Weight Matrix 형태를 갖춤
-
Segments
- Input length 만큼 '0'(1) 으로 채운다
- Input length 만큼 '0'(1) 으로 채운다
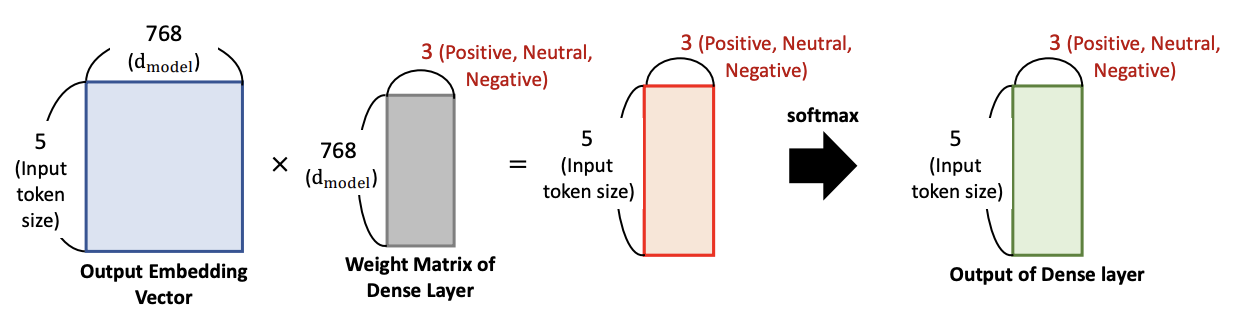
12개의 head, 한 헤드당 value 64 -> d_model = 768
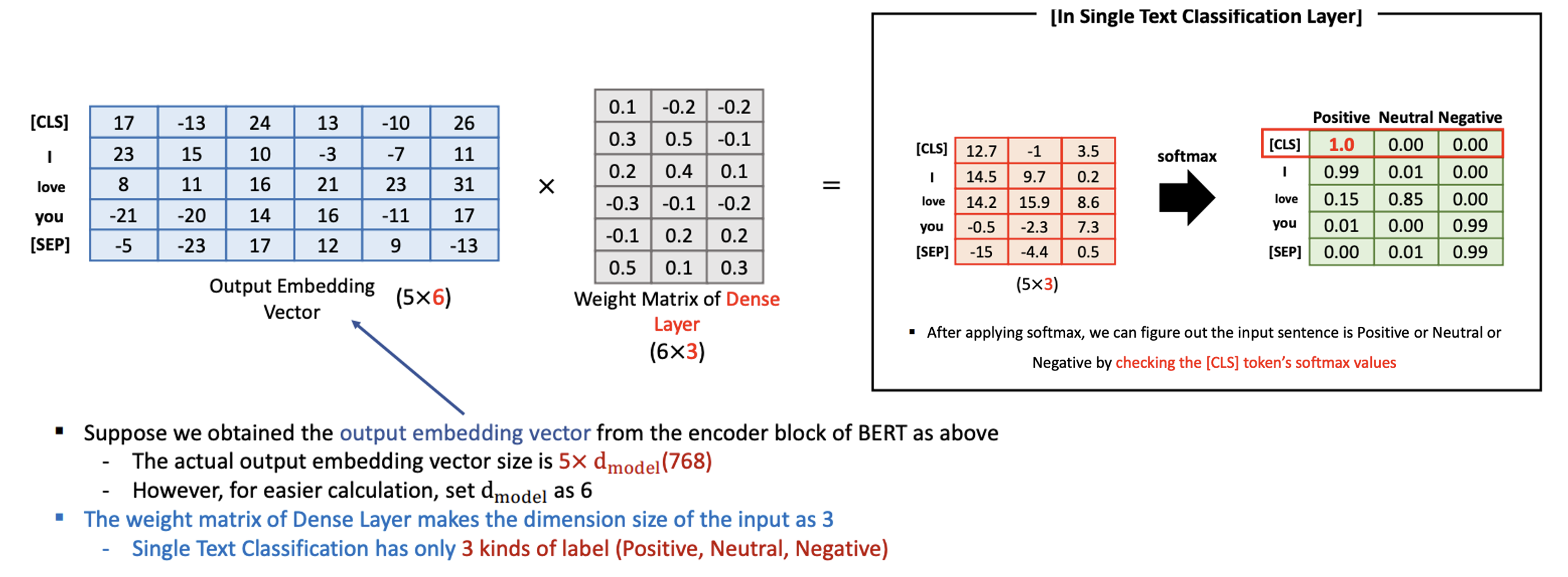
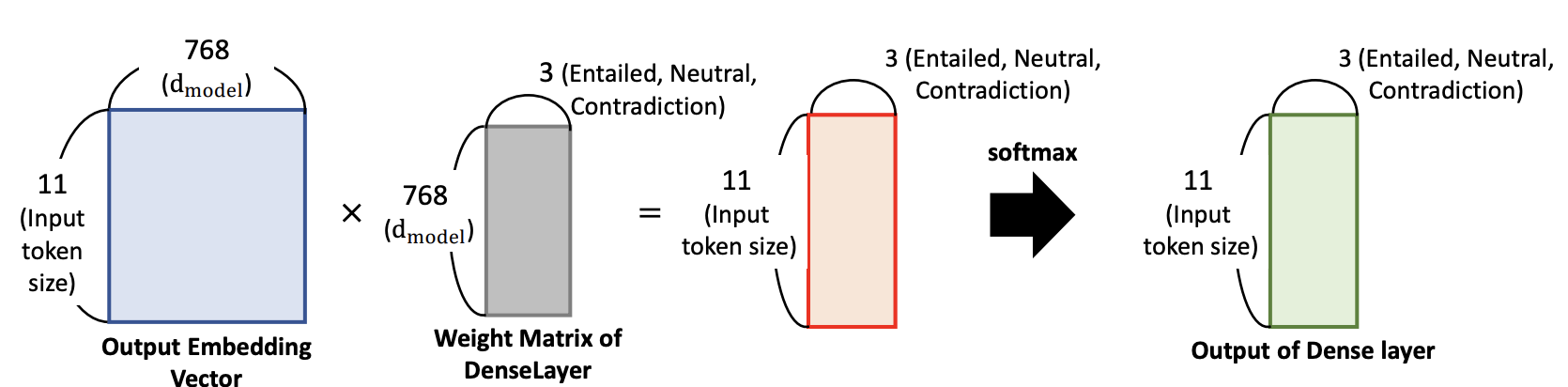
학습된 흔적인 Weight matrix 는 3개로 분류 (Positive, Neutral, Negative)
그러면 5 x 3 이 나옴, 그런다음 그림에서는 보여주지 않았지만 FFNN 을 수행하고, Weight 들 업데이트
Sofmax 로 확률을 구하게 되면 3개의 칼럼에 대한 확률값들이 나오고, 가장 높은 확률이 만약 Negative 라면 주어진 sentence 는 Negative
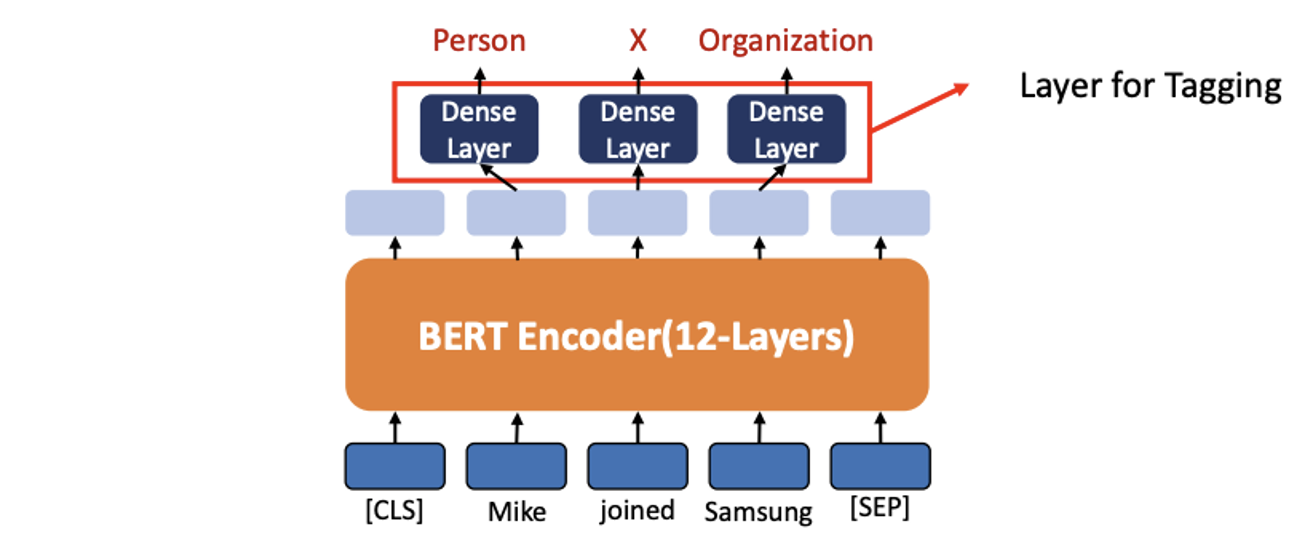
2. Fine-tuning (Tagging for Single Text)
- 명사에 대해서 (동사는 해당 x)
- Single Text 에 대한 Tagging은 각 단어 또는 엔티티에 태그를 지정하는 작업입니다
- ex) Object name recognition task
- 예를 들어서
Mike -> Person,Samsung -> Organization이렇게 tagging
- 출력 레이어는 입력 텍스트의 각 토큰 위치에 밀집된 레이어를 사용하여 분류에 대한 예측을 수행합니다
꼭 기억해야 할 것 : Fine-tuning 은 Supervised Learning 과정이고, 더 정확하게 말하면 Self Supervised Learning 이다!
Numerical Example-Fine-tuning (Tagging for Single Text)
- Input Tokenized Data
- [CLS] token 이 첫번째 (1), Input data token (2) 그리고 [SEP] token (3) 으로 채워짐

- [CLS] token 이 첫번째 (1), Input data token (2) 그리고 [SEP] token (3) 으로 채워짐
- Output Tokenized Data (Labled(Tagged) Target)
- [CLS] token 이 첫번째 (1), Input tokens 에 대한 Label Tag Tokens (2) 그리고 [SEP] token (3) 으로 채워짐
- Mike 의 타겟 토큰으로 Person, Samsung 의 타켓 토큰으로 Organization 을 적어준다.
- 3만개의 vocab set 안에 있는 Person 이라는 토큰인 것, Organization 도 마찬가지. 즉 3만개의 vocab set 이 각 토큰마다 연결됨 (많은 Computing 시간 소요)
- 그래서 mike 는 Person, samsung 은 Organization 의 확률이 높게 나오도록 학습시켜 나간다.
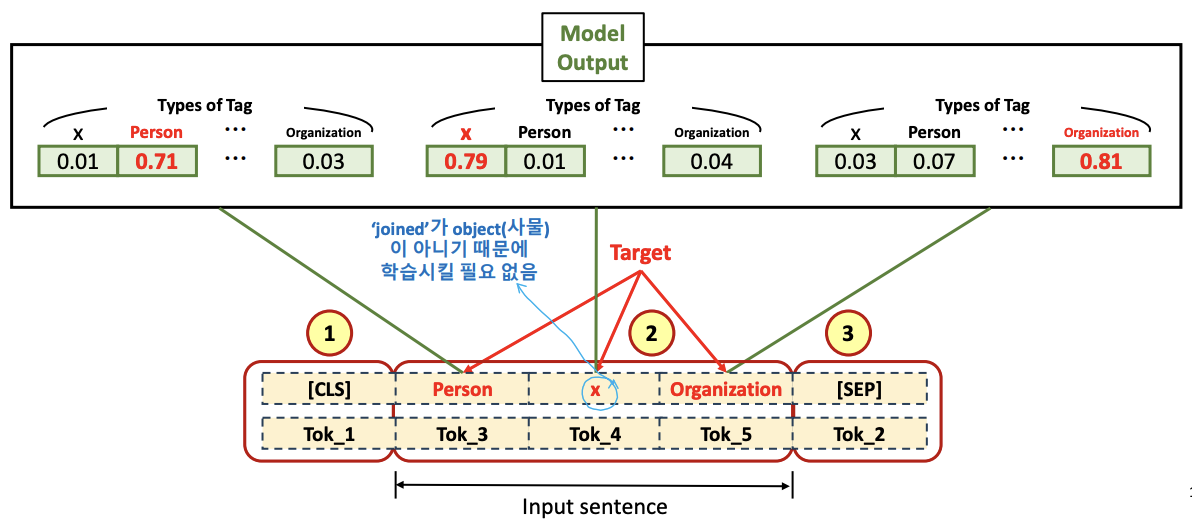
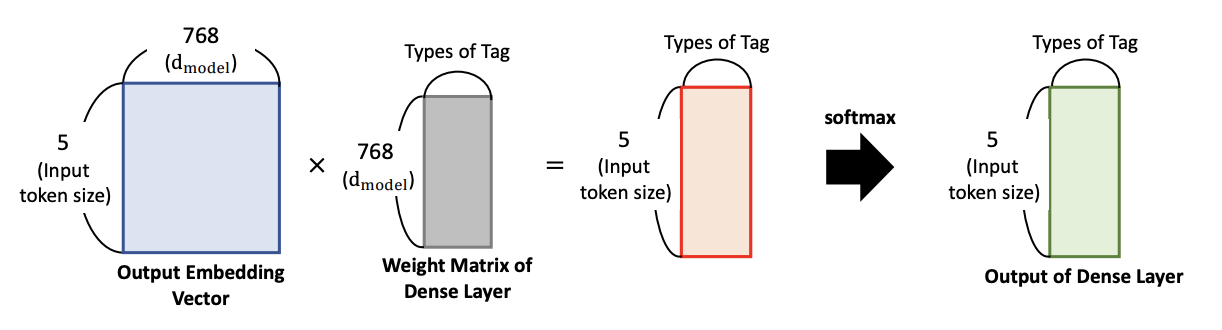
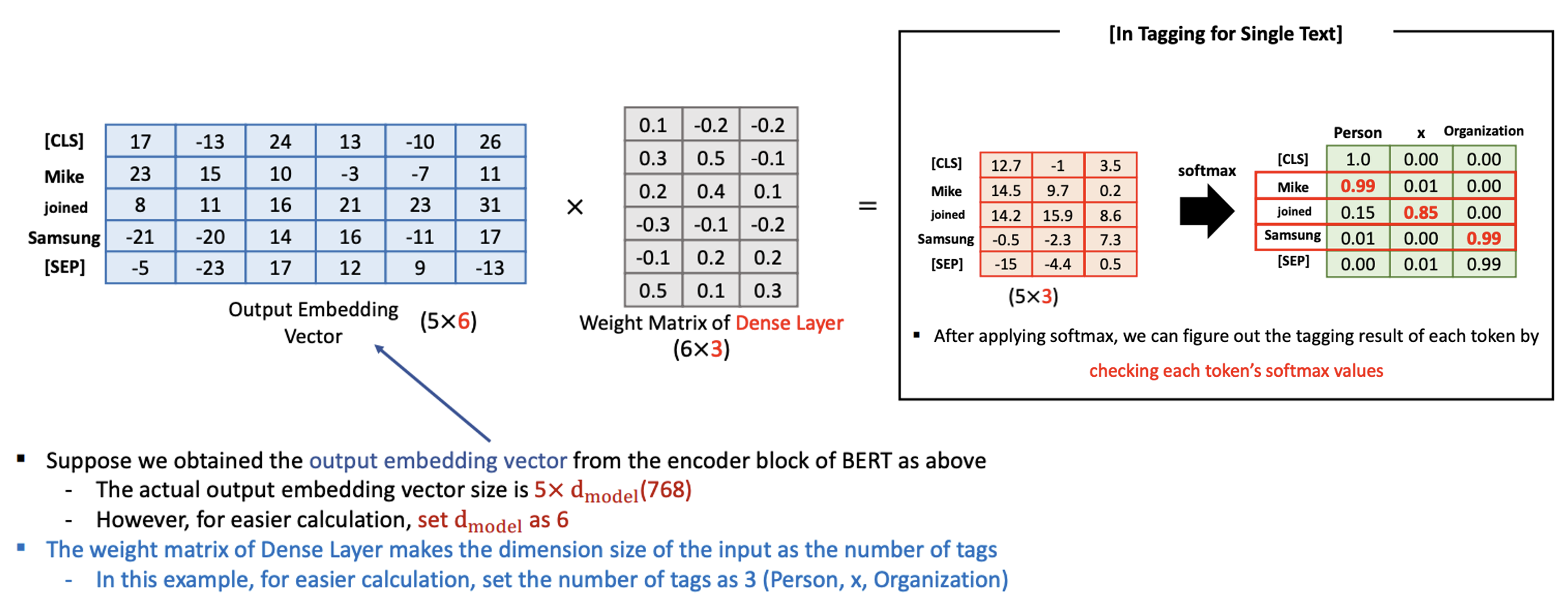
- 사실은 아래 그림에서 처럼 Weight matrix 에서 3이 아니라 3만개가 연결되어야 함.
- Epoch 를 계속 돌리다보면 Weight Matrix of Dense Layer 가 계속 업데이트되어감.
- 그 다음에 softmax 적용
- Mike 는 Person 이라는 vocab 에서 가장 높은 확률이 나와야 하고, samsung 도 마찬가지로 Organization 에 대한 확률이 높게 나와야 함.
- 다양한 종류의 단어들을 처리하고싶다면 3만갸의 vocab set 를 사용하지만, 3만개가 아니라 더 적게 사용해도 됨
3. Fine-tuning (Text Pair Classification or Regression)
- 즉, 두개의 문장을 연결해서 두 문장이 어떤 관계인가 (Positive, Neutral, Negative 관계인가?) 를 파악하는 것
- 앞서 배운 Text Classification 이랑 과정이 똑같다.
- 두 문장이 어떤 관계인지를 계산하기 위해서 토큰 하나만 필요함
- BERT는 텍스트 쌍을 입력으로 받는 작업을 해결할 수 있습니다
- ex) 자연어 추론(NLI)
*NLI: 두 문장이 주어졌을 때, 한 문장이 다른 문장과 논리적으로 어떻게 연관되는지 분류합니다
- ex) 자연어 추론(NLI)
- 모델은 특수 토큰 [CLS]를 사용하고 출력 레이어에 밀집 레이어를 추가하여 텍스트 쌍 분류 또는 회귀 작업을 해결할 수 있습니다
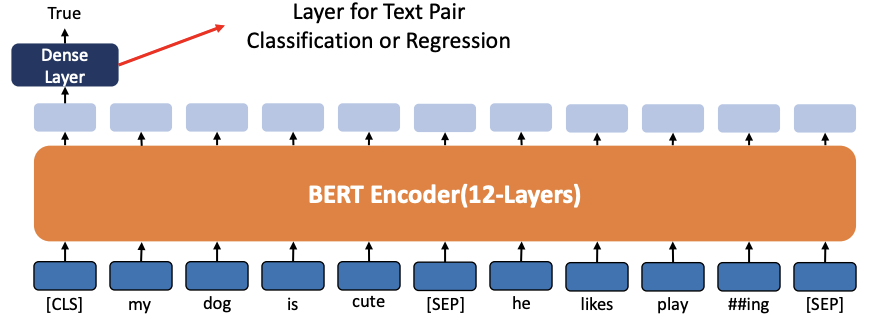
Numerical Example-Fine-tuning(Text Pair Classification or Regression)
- Input Tokenized Data
- [CLS] token 이 첫번째 (1), first sentence input data token (2), 그리고 [SEP] token (3), 나머지는 second sentence input data tokne 들과 [SEP] token (4) 으로 채워짐

- [CLS] token 이 첫번째 (1), first sentence input data token (2), 그리고 [SEP] token (3), 나머지는 second sentence input data tokne 들과 [SEP] token (4) 으로 채워짐
- Output Tokenized Data (Labled(Tagged) Target)
- [CLS] token 에 대한 label 이 첫 번째 (1), input length 만큼 [PAD] 토큰들로 채우고, [SEP] token 을 채운다 (2), 그 후, output length 만큼 [PAD] 토큰들로 채우고 [SEP] token 을 채운다 (3)
Entailed: Positive 하다, 관계가 깊다는 의미Contradiction: 정반대의 관계이다
- Fine-tuning 에서는 모든 두개의 문장들 가지고 전부 처리를 해줘야 함
- 따라서, Pre-training 처럼 Untagged data로 무작위의 많은 데이터량을 가지고 할수가 없음.
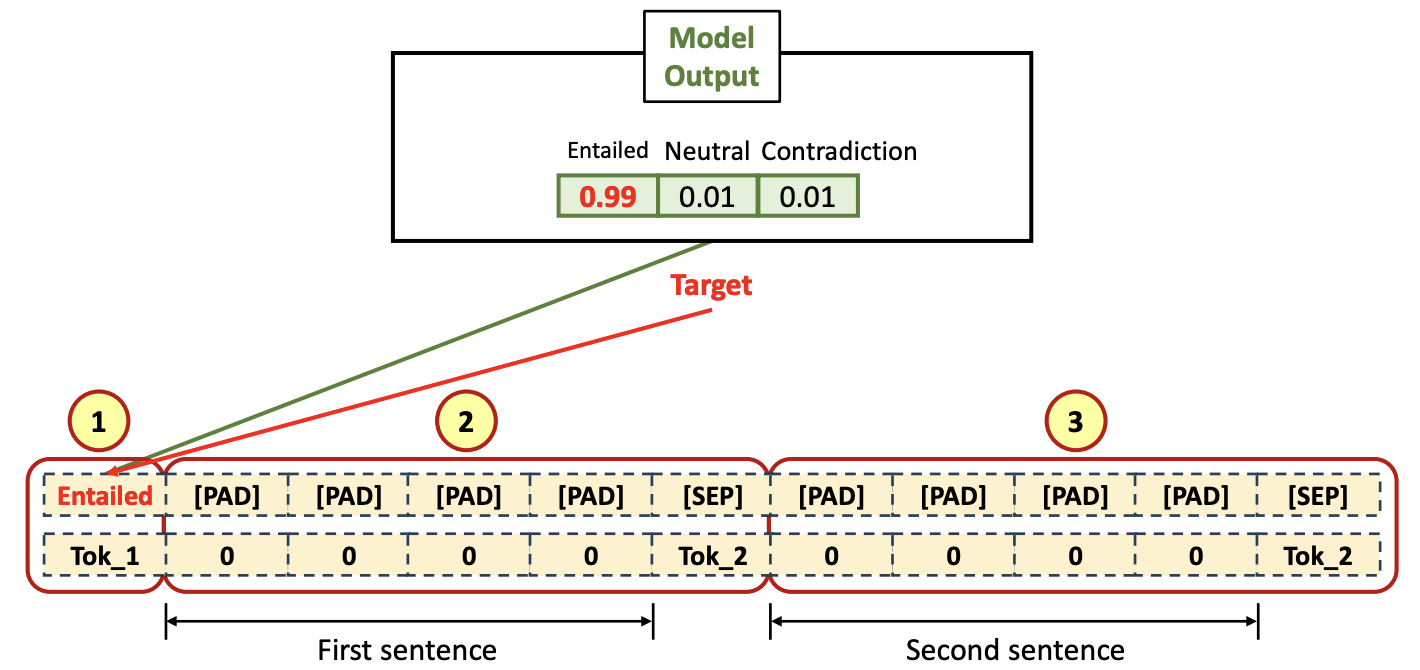
- 따라서, Pre-training 처럼 Untagged data로 무작위의 많은 데이터량을 가지고 할수가 없음.
- [CLS] token 에 대한 label 이 첫 번째 (1), input length 만큼 [PAD] 토큰들로 채우고, [SEP] token 을 채운다 (2), 그 후, output length 만큼 [PAD] 토큰들로 채우고 [SEP] token 을 채운다 (3)
- Segment
- First sentence length 만큼 '0'(1) 으로 채운다. 그 다음 부분은 Second sentence input length 만큼 '1'(2) 로 채운다.
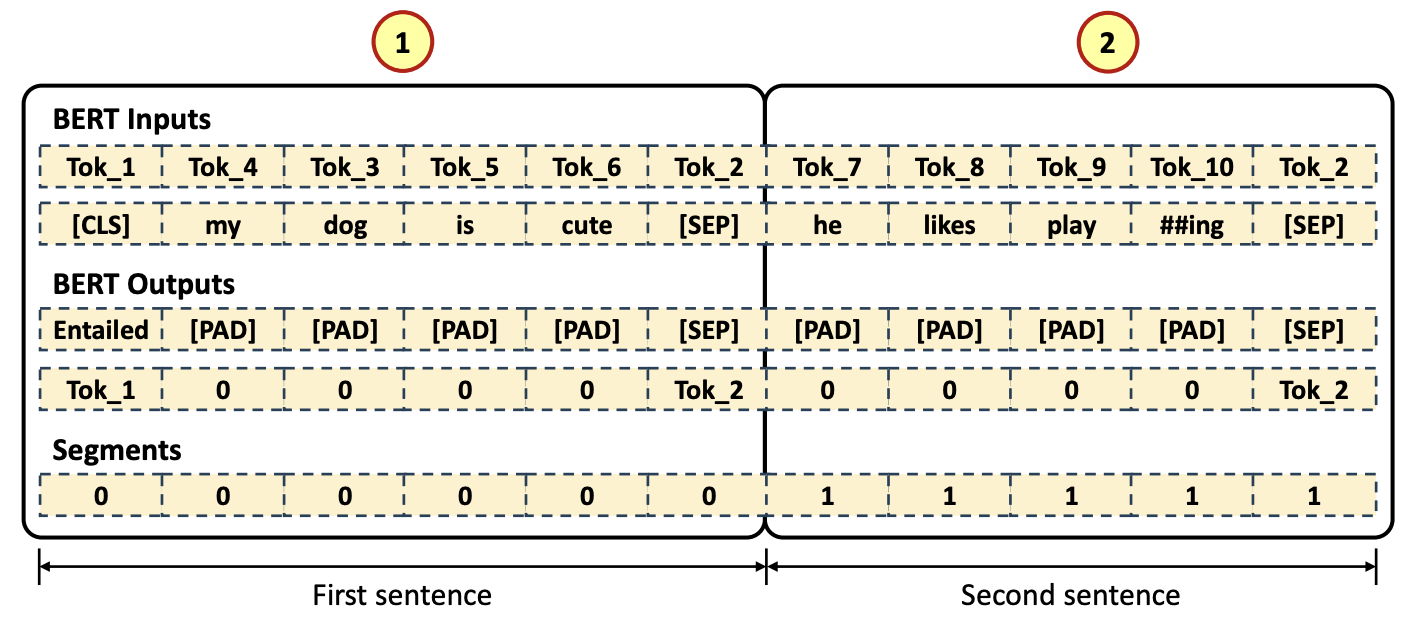
- First sentence length 만큼 '0'(1) 으로 채운다. 그 다음 부분은 Second sentence input length 만큼 '1'(2) 로 채운다.
4. Fine-tuning(Question & Answer with User’s Context)
사용자가 실마리가 될 수 있는 컨텍스트를 힌트로 제공해서 내가 Answer 를 구하겠다는 것
- BERT는 Question & Answer 과제를 해결할 수 있습니다
- 모델이 질문과 주요 텍스트를 입력으로 받으면 모델은 Main Text의 일부를 추출하고 Question에 Answer 합니다
- 주어진 텍스트 내에서 question 에 대한 answer을 포함하는 시작과 끝 index 찾기
- input 은 Question 과 우리가 힌트를 줄 Main Text given by User
- output 구성은 Main Text given by User 의 각 토큰들에 대해서 Dense Layer (FFNN) 를 붙여줌
- Fine-tuning 에서는 이미 pre-training 으로 학습된 모델에 다음과 같이 layer 를 붙여주는 것이다
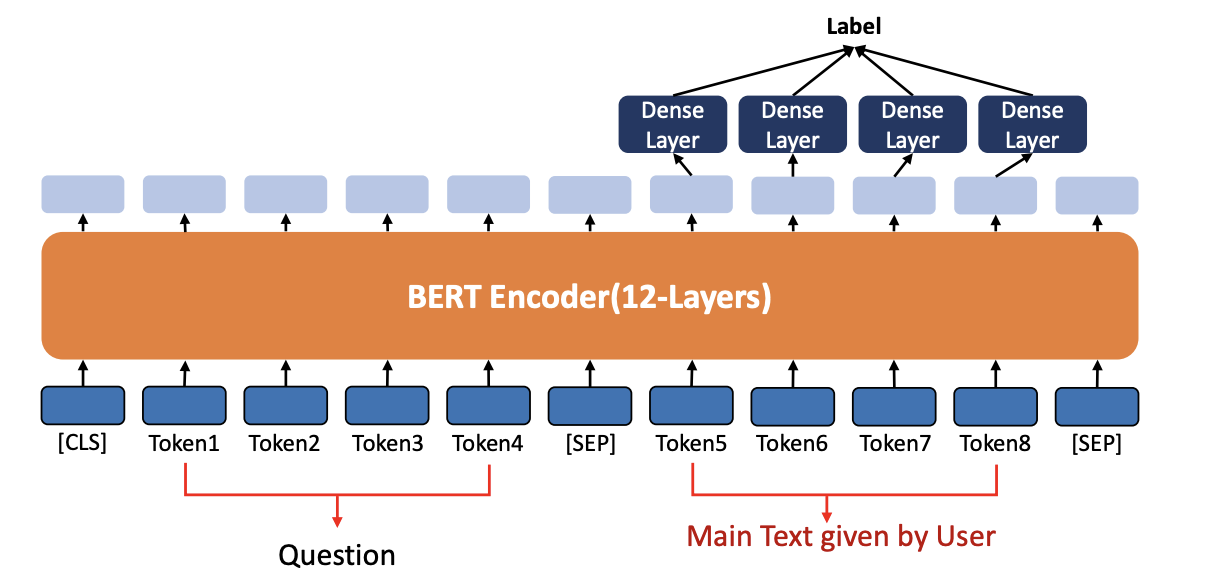
- Fine-tuning 에서는 이미 pre-training 으로 학습된 모델에 다음과 같이 layer 를 붙여주는 것이다
- 앞부분은 Question 이고 뒷부분은 우리가 입력한 Context 인데, Context 전체가 답이 될수가 없음
- 그 중에 어떤 part 에 정답이 숨어있는가를 알아보기 위해서
start와end태그를 붙임start태그 부터end태그 까지 내가 원하는 답이 여기 있다! (이 2개의 태그를 알려주면서 학습)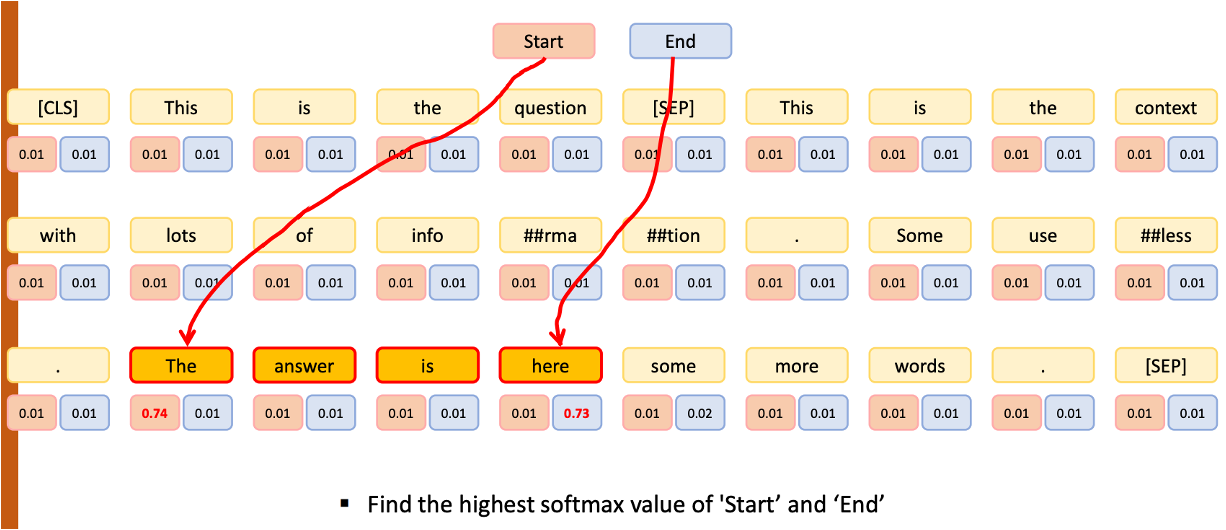
- Input Tokenized Data
- [CLS] token이 첫번째 (①), Question tokens (②) 그리고 [SEP] token (③), 나머지는 Main text token들과 [SEP] token (④)으로 채워짐
- Q :
When was BERT released - Main Context :
BERT is a large language model. BERT was released in 2018. it ...
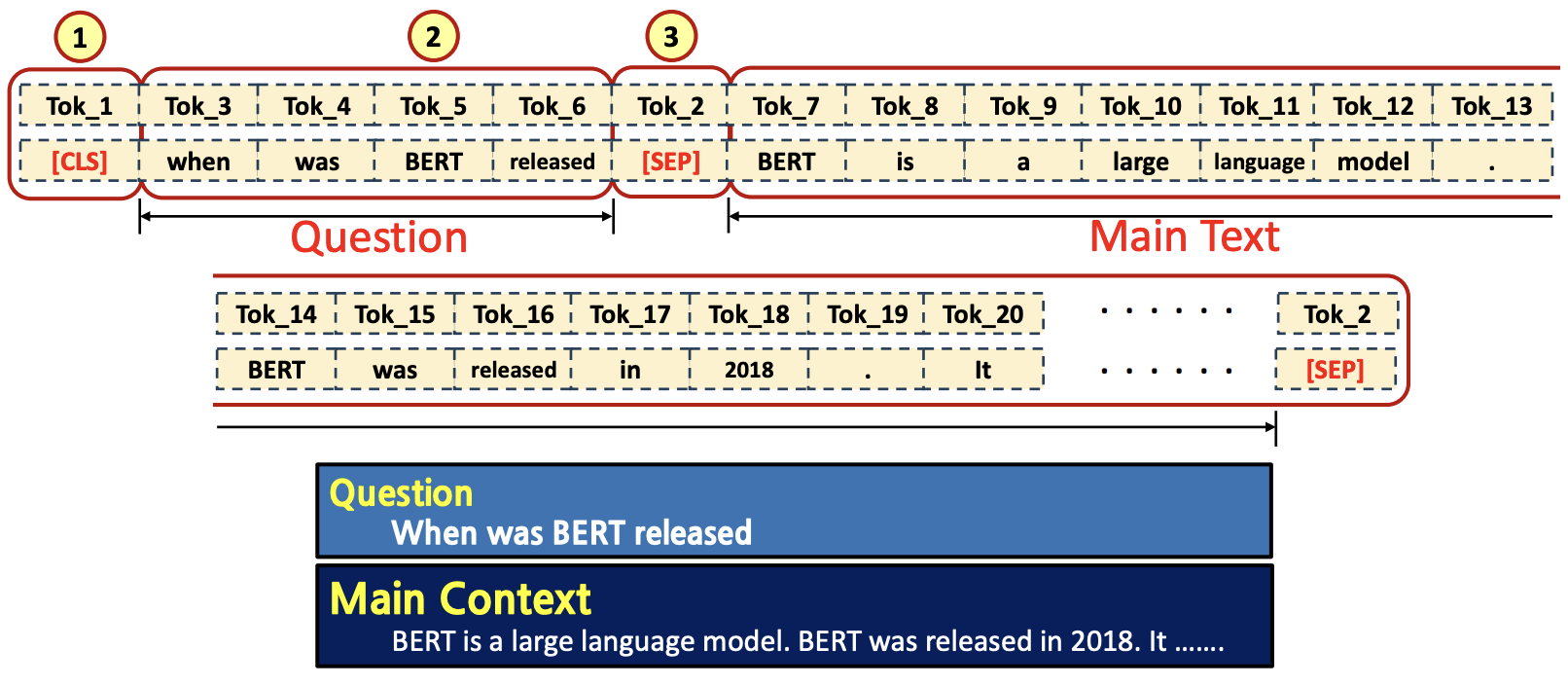
- Output Tokenized Data
- Question tokens만큼 [PAD] 토큰들 (①) 로 채우고, [SEP] token을 채운다 (②). 그 후, Main text에서 ‘Start와 ‘End’ 토큰에 대한 label을 제외한 토큰들은 [PAD] 토큰들로 채우고 [SEP] token을 채운다 (③)
- Fine-tuning 은 Supervised Learning 으로서, 우리는 어느 시점(start)부터 어느 시점(end)까지 정답이 숨어있는지를 알고있어야 한다.
- 나머지는 padding 처리
- 오직 start 와 end 가 있는 토큰만 찝어주는 것
- 2개의 칼럼만 필요, 또한 우리는 이미 target 데이터로서 어떤 토큰이 start 고, 어떤 토큰이 end 인지 알고있다.
- 그리고 FFNN 에서 처음에는 start 과 end 의 확률이 낮게 출발을 하겠지만 계속해서 학습을 해서 start 와 end 포인트의 확률이 높아질 것임.
- start 와 end 사이의 문장이 여러개여도 마찬가지
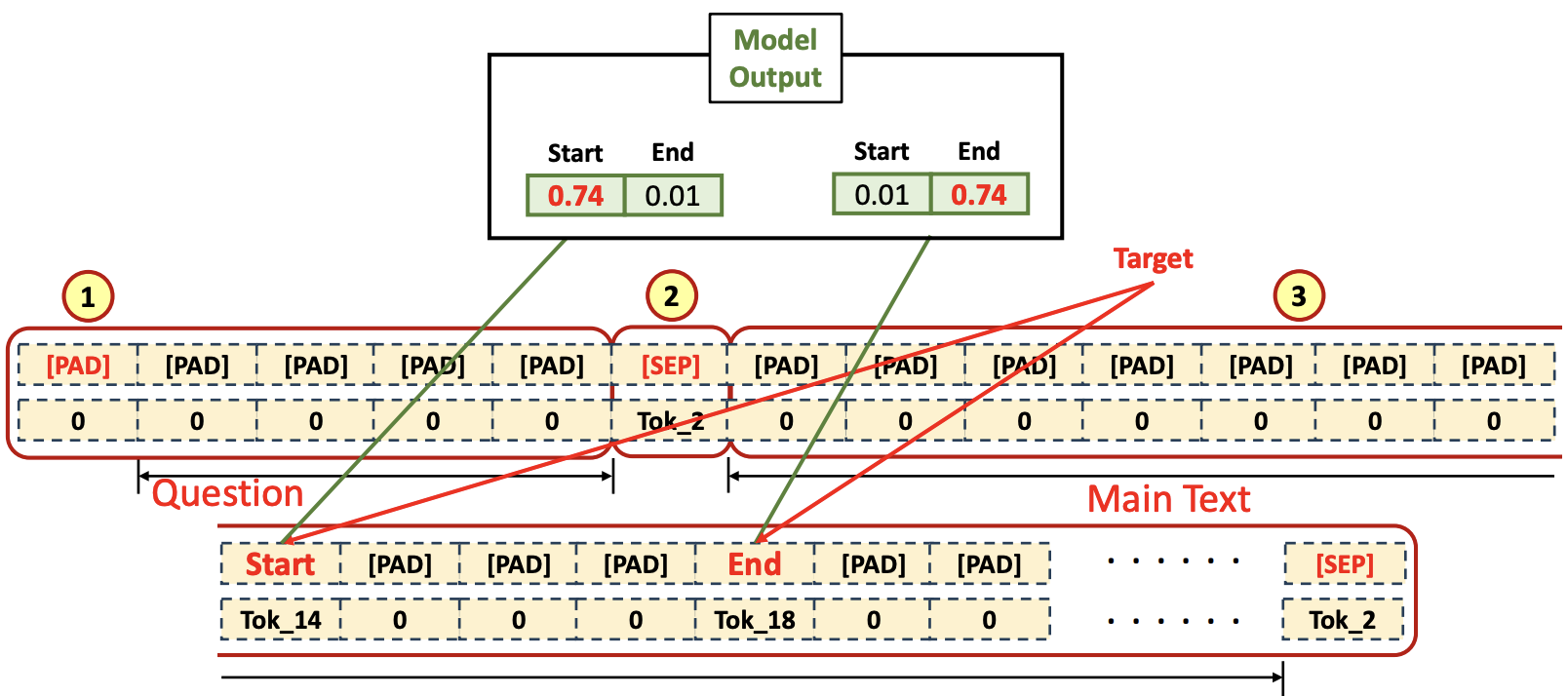
- Segment
- Question tokens length 만큼 ‘0’(①)으로 채운다. 그 다음 부분은 Main context length만큼 ‘1’(②)로 채운다.
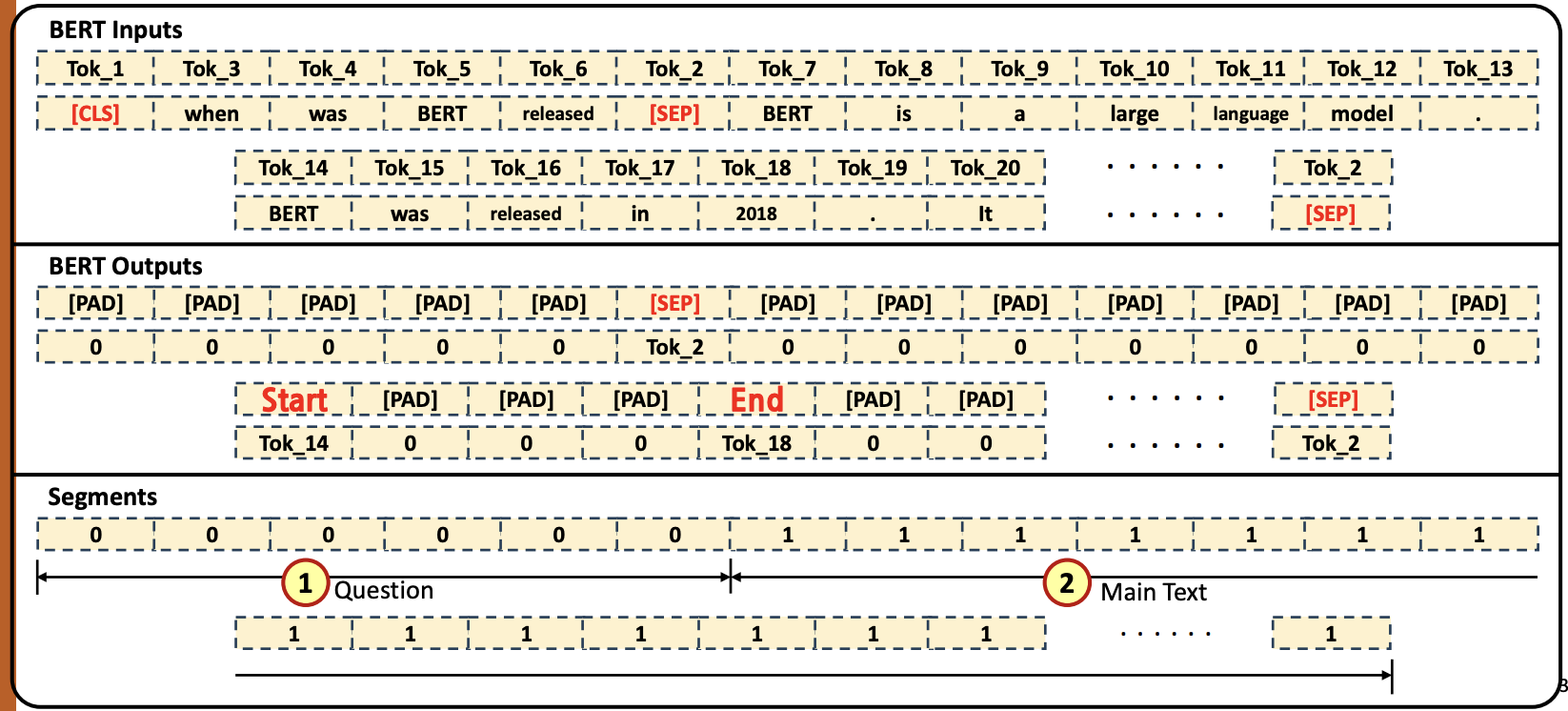
- Question tokens length 만큼 ‘0’(①)으로 채운다. 그 다음 부분은 Main context length만큼 ‘1’(②)로 채운다.
- 모든 Input 토큰을 대상으로 start 와 end 의 확률을 구해주는 것
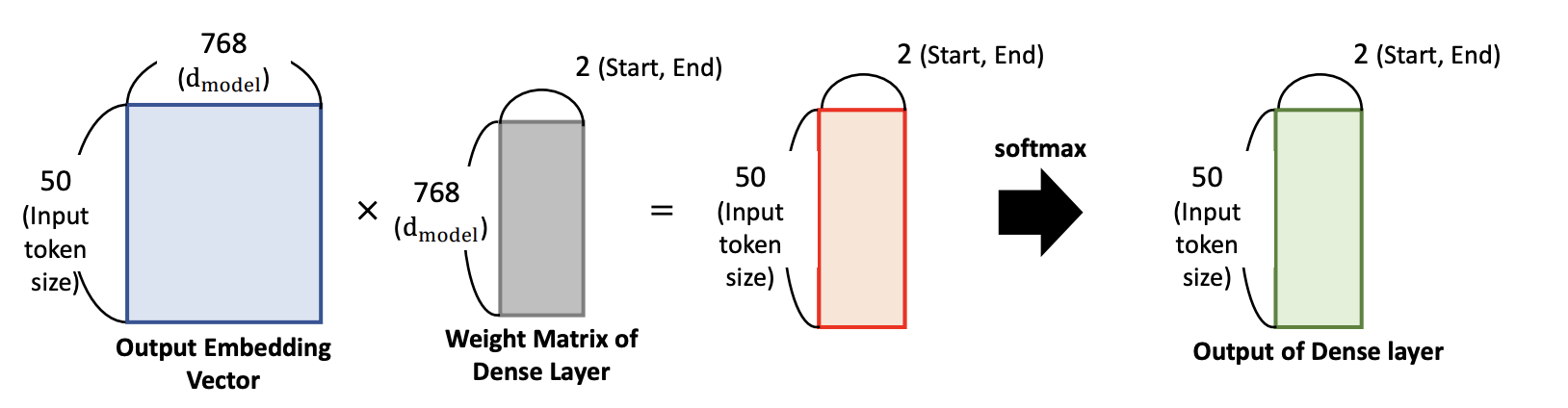
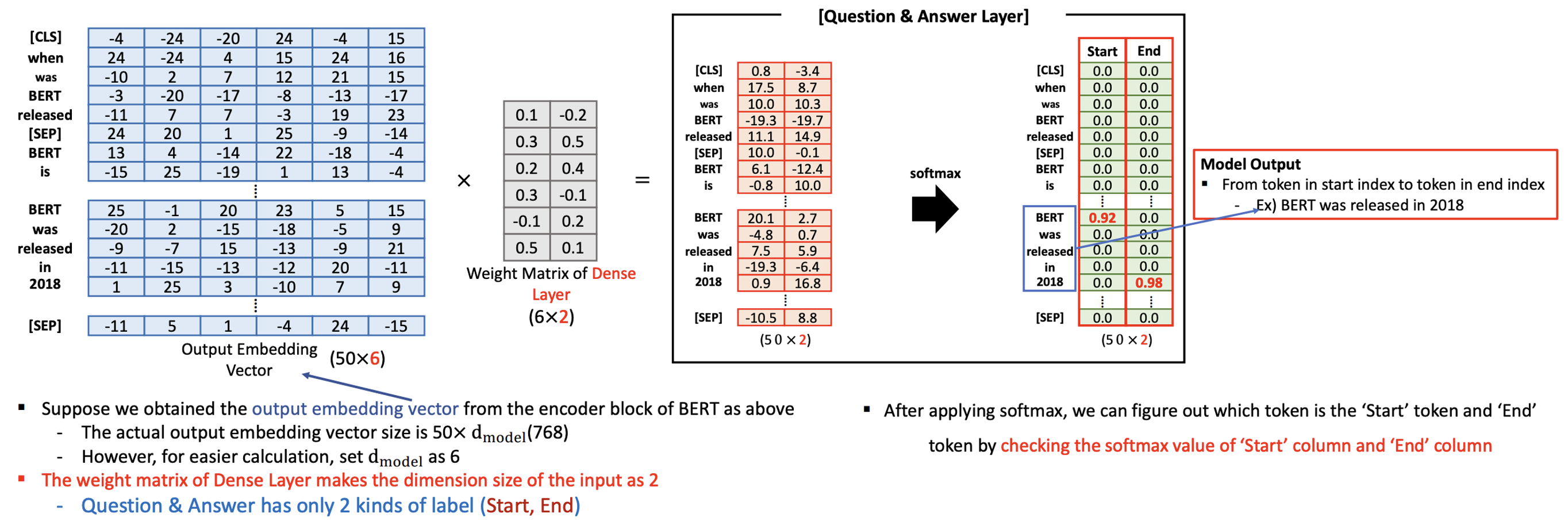
Question and Discussion:
① How can we fine-tune the BERT model
without user’s context?
② What will the input and output formats be?
