
요약
01 파일 정보 수집 : wc
02 파일 정렬 : sort
03 파일 분할 : split
실습 11-1 파일 내용 정렬하고 분할하기
04 중복 삭제 : uniq
05 필드 잘라내기 : cut
06 두 파일 연결하기 : paste
실습 11-2 파일에서 필드 추출하고 파일 합치기
실습 11-3 유닉스 시스템 사용자 목록 만들기
07 파일 덤프 : dd
요약
연습문제
01. 파일 정보 수집 - wc
wc [옵션] 파일명- 텍스트 파일에서 라인수, 단어수, 문자수를 리턴
사용 예
# 옵션
wc -c /etc/services # 바이트 수
wc -m /etc/services # 문자수
wc -C /etc/services # -m 과 동일
wc -l /etc/services # 라인 수
wc -w /etc/services # 화이트 스페이스나 새로운 행으로 구분된 단어수
# 실습
wc /etc/passwd # /etc/passwd 파일의 정보를 확인
wc /etc/hosts # /etc/hosts 파일의 정보 확인
wc -l /etc/services # /etc/services 파일의 라인 수 확인
cat /etc/hosts | wc -l # /etc/hosts 파일의 라인 수 확인하는 다른 방법
ls -l /usr/bin | wc -l # /usr/bin 디렉토리 파일의 라인수가 의미하는 것은 무엇인가?
# 현재 디렉토리에 파일이 몇개 있는지 알려면어떻게 해야 하는가?
ls -l > test_wc # test_wc 파일로 저장
wc -c test_wc # 총 문자 캐릭터 바이트수
02. 파일 정렬 - sort
sort [옵션] 파일명- 텍스트 파일의 내용을 지정한 방법 으로 정렬 하여 화면에 출력
- 정렬 기준
- 1) 환경변수 LC_COLLATE (설정된 경우가 거의 드물다)
- 2) 환경변수 LANG (LC_COLLATE가 없으면)
- LANG 이 유니코드 로 되어있다면
: 공백 특수문자 숫자 영문자 (로 정렬해줌) - 아스키코드
: 공백 숫자 영소문자 영대문자, 특수문자는 사이사이
- LANG 이 유니코드 로 되어있다면
옵션 및 사용 예
# 옵션
sort test_sort1 # 아스키 코드 기준 기본 정렬
sort test_sort1 -d # 사전순 정렬(공백은 포함, 특수문자는 제외하고 정렬)
sort test_sort1 -r # 역순으로 정렬
# 필드 정렬하기 : +번호 또는 -k
sort +1 test_sort2 # 두번째 필드 기준
sort -k 2 test_sort2 # 두번째 필드 기준
# 정렬하고 자하는 필드를 지정, pos1 열부터 pos2 열까지 정렬
sort +1 -2 test_sort2 # 1열부터 2열까지 정렬
# 숫자를 산술값으로 환산 : -n
sort -k 4 test_sort2 # ->
sort -n -k 4 test_sort2 # 네번째 필드를 숫자로 생각을 해서 정렬
# 2차 정렬
sort +2 -3 +1 -2 test_sort2 # 3번 필드만을 기준으로 정렬
# 3열이 같으면 그다음에 2열을 기준으로 정렬
# 정렬 결과 저장
sort -n +3 -4 -o sort.out test_sort2
# (중요)필드 구분자 지정하기 : -t
# 디포르로 스페이나, 탭으로 필드를 구분
sort -t: /etc/passwd # : 를 기준으로 정렬실습하기
# 1)
mkdir Linux/ch11
# 2)
cd Linux/ch11
# 3) 실습 데이터 파일을 현재 디렉토리로 복사
cp /tmp/s.dat
# 4) 기본 파일 내용을 확인
cat s.dat
# 5) 기본 정렬
sort s.dat
# 6) 대소문자 구분없이 정렬
sort -f s.dat
# 7) 역순으로 정렬
sort -r s.dat
# 8) 3번째 열을 기준으로 정렬
sort +2 s.dat
# 9) 정렬 결과를 파일로 저장
sort -o sor.out s.dat
# 10) 결과 파일을 확인
cat sort.out
# 11) 3.4 번쨰 열을 기준으로 정렬
sort +2 +3 s.dat
# 12) 기본 파일과 정렬 파일을 합병
sort +m s.dat sort.out사용예
-
아스키코드 기준으로 정렬
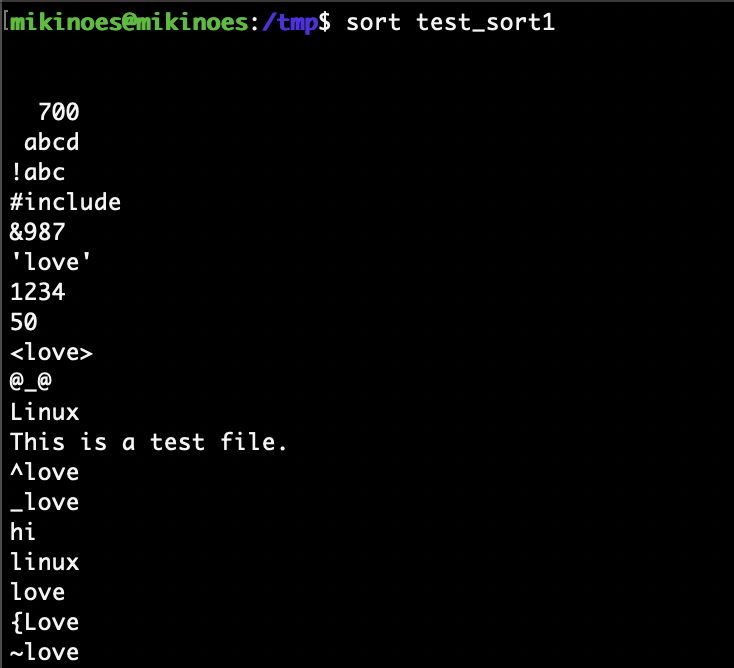
-
사전식 정렬 : -d
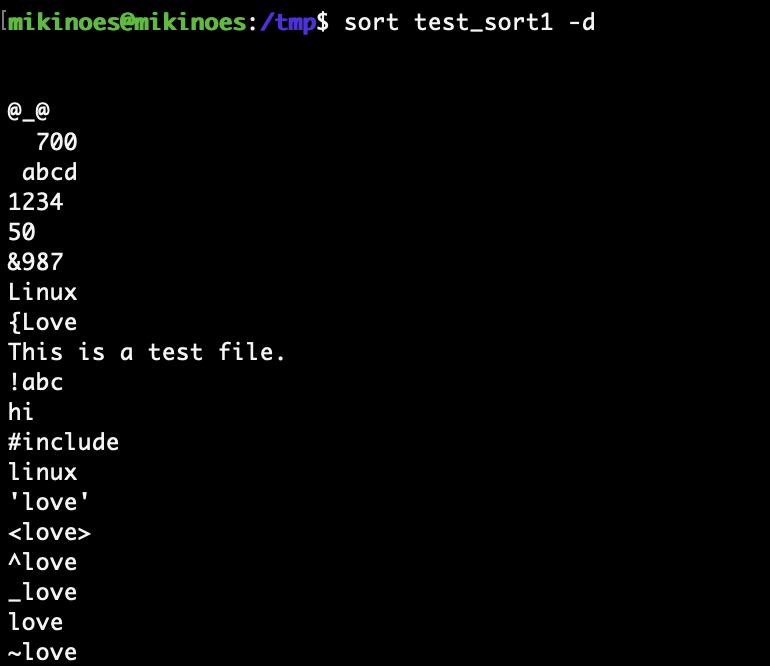
-
역순으로 정렬 : -r
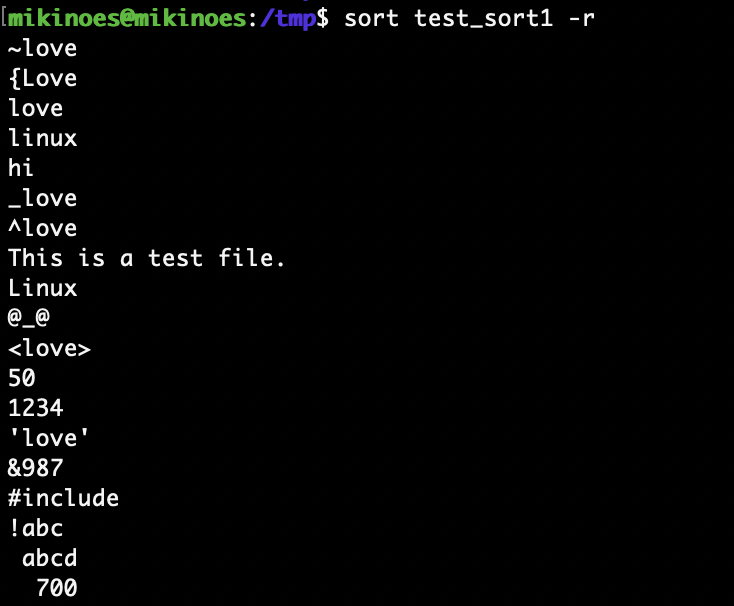
03. 파일 분할 - splite
split [옵션] [파일명]- 큰 파일을 일정한 크기의 여러 개 작은 파일로 분할
- 분알된 파일 이름은 xaa. xab, ... 순으로 생성
- 옵션
-b n: 크기가 n바이트인 파일로 분할 - 바이트 단위-l n: n 줄씩 분할 (= -n) - 줄단위- 옵션을 지정하지 않으면 1000 줄씩 분할
- 파일을 지정하지 않으면 표준 입력 내용을 분할 저장
사용 예
# 기본 데이터
cp /etc/services test_split
wc -l test_split # 결과 : 134 test_split -> 134 줄로 이루어진 파일
# 행을 기준으로 파일 분할
split -l 30 test_split # 30줄 단위로 구분하여
ls # 결과 : test_split xaa xab xac xad xae
# 바이트 기준으로 파일 분할
wc -c test_split # 4545 test_split
split -b 512 test_split # 512 바이트(char) 단위로 구분
ls # test_split xaa xab xac xad xae xaf
wc -c x* # x 로 시작하는 파일의 바이트 수 출력04.중복삭제 - unique
uniq [옵션] [입력파일 [출력파일]]- 파일 또는 표준입력으로 입력된 내용중 중복된 내용의 줄 이 연속으로 있으면 하나만 남기고 삭제
- 파일을 지정하지 않으면 표준입력 내용을 처리
- 입출력 파일 이름은 달라야 함
- 옵션
-u: 중복되지 않은 줄만 출력-d: 중복된 줄 중 1줄만 출력-c: 각 행의 처음에 중복횟수 출력
사용 예
# 연속으로 중복된것중 하나를 제외한 나머지 제거
uniq test_uniq1
# 연속된 것은 아니지만 중복을 제거하고 싶다면
# 정렬과 중복 제거를 동시에 수행한다.
sort test_uniq1
sort test_uniq1 | uniq
# 중복 없는 행 보기
uniq -u test_uniq1
# 중복 행과 중복 횟수 보기
uniq -d test_uniq1
uniq -c test_uniq1 05. 필드 잘라내기 - cut
cut [옵션] [파일명]- 파일의 각 행에서 선택된 필드를 잘라냄
- 옵션
-c 리스트: 각 줄에서 잘라낼 문자 위치 지정-f 필드수: 지정한 필드 잘라냄.ㅌ$-d 문자: 필드 구분자
(기억 : 스페이가 아니라 탭을 디폴트 필드 구분자로 생각을 한다)
사용 예
기본 데이터 : 스페이스로 띄어져 있는 데이터 test_cut
cut -c5-8 test_cut # 문자 추출 : -c
cut -f 2,3 test_cut # 필드 추출 : -f
# 필드 구분자 지정하기 : -d
cut -d: -f 1 /etc/passwd | more
cut -d' ' -f 2 test_sort2
### 실습하기
# 1) /etc/passwd 파일을 현재 디렉토리로 복사
cp /etc/passwd
# 2) passwd 파일 중 필드 구분자로 : 로 지정하여 7번쨰 필드를 추출하여
# shell.out 파일로 저장
cut -d: -f 7 passwd > shell.out
# 3) 지정한 파일 내용 확인
more shell.out
# 4) shell.out 파일 내용을 정렬한 후 중복 제거
sort shell.out | uniq
# => 위 작업의 결과로 알 수 있는 것은?06. 두 파일 연결하기 - paste
paste [옵션] [파일1 파일2 ...]- 지정한 파일의 내용을 붙임
- 사용자가 지정하 두 개 이상의 파일 내용 중 같은 줄을 붙이거나 한 파일의 끝에 다른 파일의 내용을 추가
- 옵션
-s: 파일의 끝에 추가 (split 로 나눈 파일을 원래대로 붙일 때)-d: 필드 구분자-: 파일 대신 표준 입력 사용
사용 예
# 파일 붙이기
paste test_paste2 test_paste1
# 두 파일의 행이 같지 않을 경우 -> 맞는 줄까지만 그냥 이어붙이기
paste test_paste2 test_paste3
# 필드 구분자 지정 : -d
paste -d: test_paste1 test_paste2
# 파일 수평 붙이기 : -s
paste -s test_paste1 test_paste2
# cut 과 paste 의 복합 사용
cut -d' ' -f 1 s.dat | paste - u.dat # 스페이스를 구분자로 하고 첫번쨰 필드(성) 만 추출하여 u.dat 에 과 붙여주겠다.
# 만약 - u.dat 가 아닌 u.dat - 라면 어떻되는지? (듣기로는 성이 나중에 붙여진다?)
### 실습하기
# 1) /etc/passwd 파일 구조 파악
more /etc/passwd
# 2) 첫 번째 필드인 로그인 ID 추출
cut -f 1 -d: /etc/passwd > login_list
# 3) 사용자 이름 추출 (5번째 필드)
cut -f 5 -d: /etc/passwd > name_list
# 4) 파일 합치기
paste -d: name_list login_list > user_list
# 5) 정렬
sort -o user_list user_list07. 파일 덤프 - dd
dd [옵션] [if=입력파일] [of=출력파일]- 지정항 입력 파일을 지정한 옵션에 따라 변환하여 출력파일로 저장
- 옵션
bs=n: 입출력 블록의 크기를 n 바이트로 지정 (기본 1블록 = 512바이트)conv=lcase: 알파벳을 소문자로 변환conv=ucase: 알파벳을 대문자로 변환
사용 예
# 대소문자 전환하기
dd conv=lcase if=test_cut of=test_dd1
# 파일 지우기
dd if=/dev/null of=test_dd2 # /dev/null 은 블랙홀
# 아무것도 안가져온것을 덮어쓰니까 파일이 지워짐
# 파일 생성
dd if=/dev/zero count=100 of=test_dd2 # 디폴트 512 바이트 씩 100번 읽어와서 test_dd2 를 만들기
# 51200 사이즈이 파일 생성
dd if=/dev/zero bs=1024 count=100 of=test_dd3 # 1024 바이트 씩 100번 읽어와서 test_dd2 를 만들기
# 102400 사이즈이 파일 생성
# /dev/zero : eof 가 나오지 않는 전부 0인 데이터추가 실습 1
dd 라는 명령어를 이용해서 복사도 가능하다
- count 내용이 없으면 그냥 bs 만큼 이 파일에서 eof 를 만날떄까지 계속 읽어서 test_dd2 를 만드기 때문에 사실상 복사가 된다
- 이후 diff 로 내용을 비교해보면 내용이 다르지 않다라는 결과가 나온다
- 그럼 /dev/zero 를 읽는다면 eof 가 없기 떄문에 계속 만들어짐.
환경변수 확인


추가 실습 2 (시험에 나올 수도 있는 내용, 강조하심)
-
1) /etc/services 를 현재 디렉토리에 복사

-
2) wc 명령어로 확인
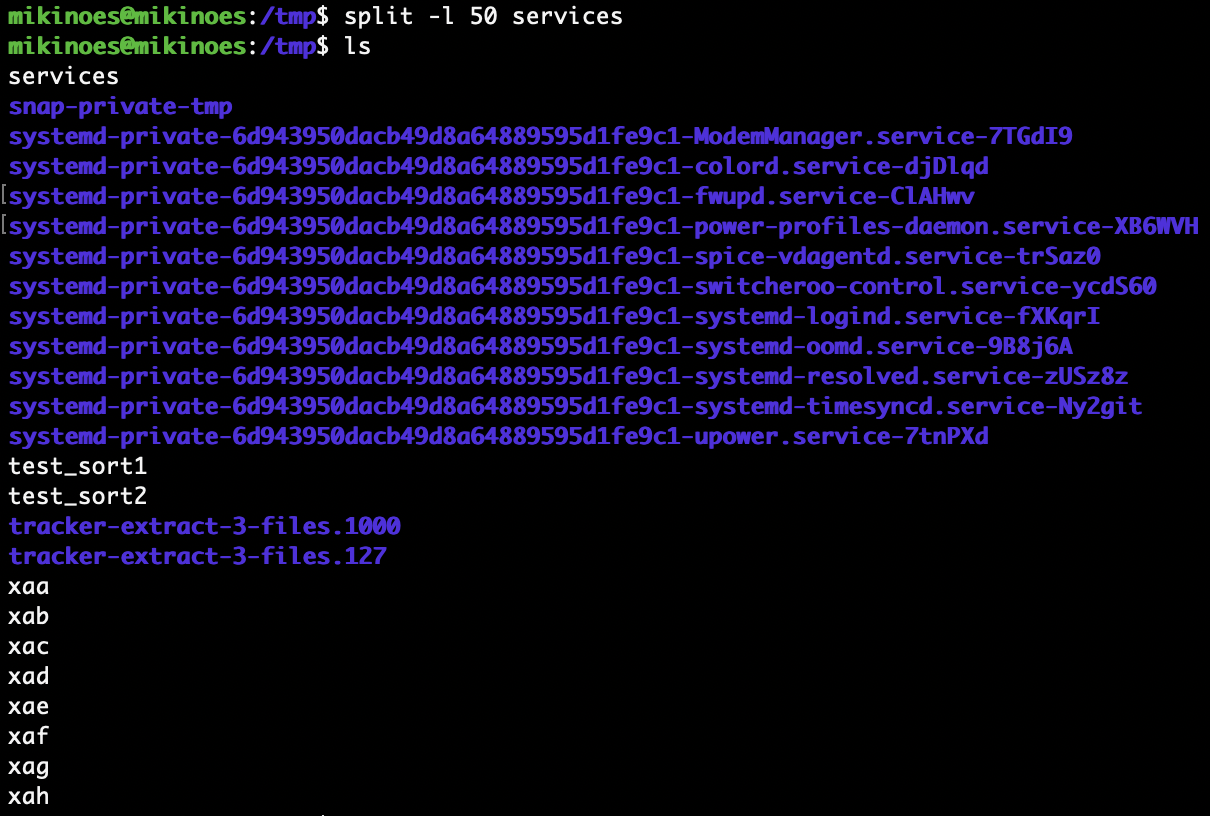
-
3) split 명령어의 -l 옵션을 사용하여 50 줄씩 분할
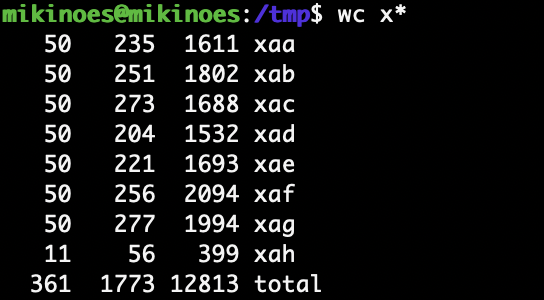
-
4)
paste -s x* > aa: 다음과 같이 시리얼(-s : 수평 붙이기) 하게 x 로 시작하는 분팔된 파일들을 붙이면- 공백문자 tab 에 의해서 잘못 원래 우리가 알던 /etc/services 파일 내용과는 다르게 출력됨.

- 공백문자 tab 에 의해서 잘못 원래 우리가 알던 /etc/services 파일 내용과는 다르게 출력됨.
추가실습 3
- a라는 파일을 하나 만들고 3줄씩 분할한 다음 paste 진행
- '\n' 가 탭 으로 만들어져서 붙여짐
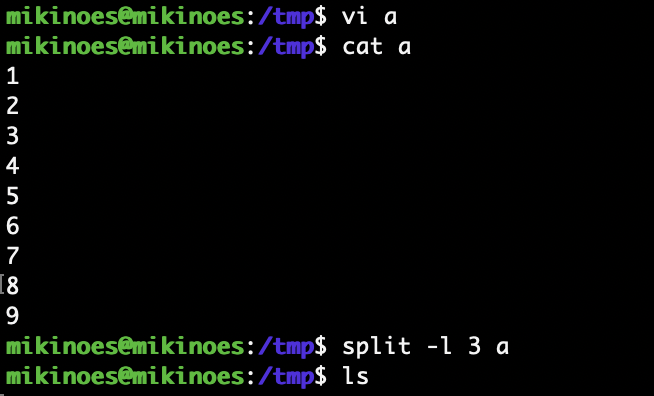
- 5) 따라서 수평(-s)으로 붙일때는, tab 으로 바뀌는 구분문자를 newline 지정해주고 붙이면 해결
paste xaa xab xac xad -s -d'\n' > aapaste x* -s -d'\n' > aa도 동일

공부한 것 기록용