DNN :: 심층 신경망
-
DNN 은 은닉층이 여러개인 것을 의미
-
표기법
-
: 네트워크 층의 개수
-
: 층에서의 activation function 의 결과 즉 활성값
-
: 입력 값 X
-
: 맨 마지막 계층의 결과값, 예측된 출력값
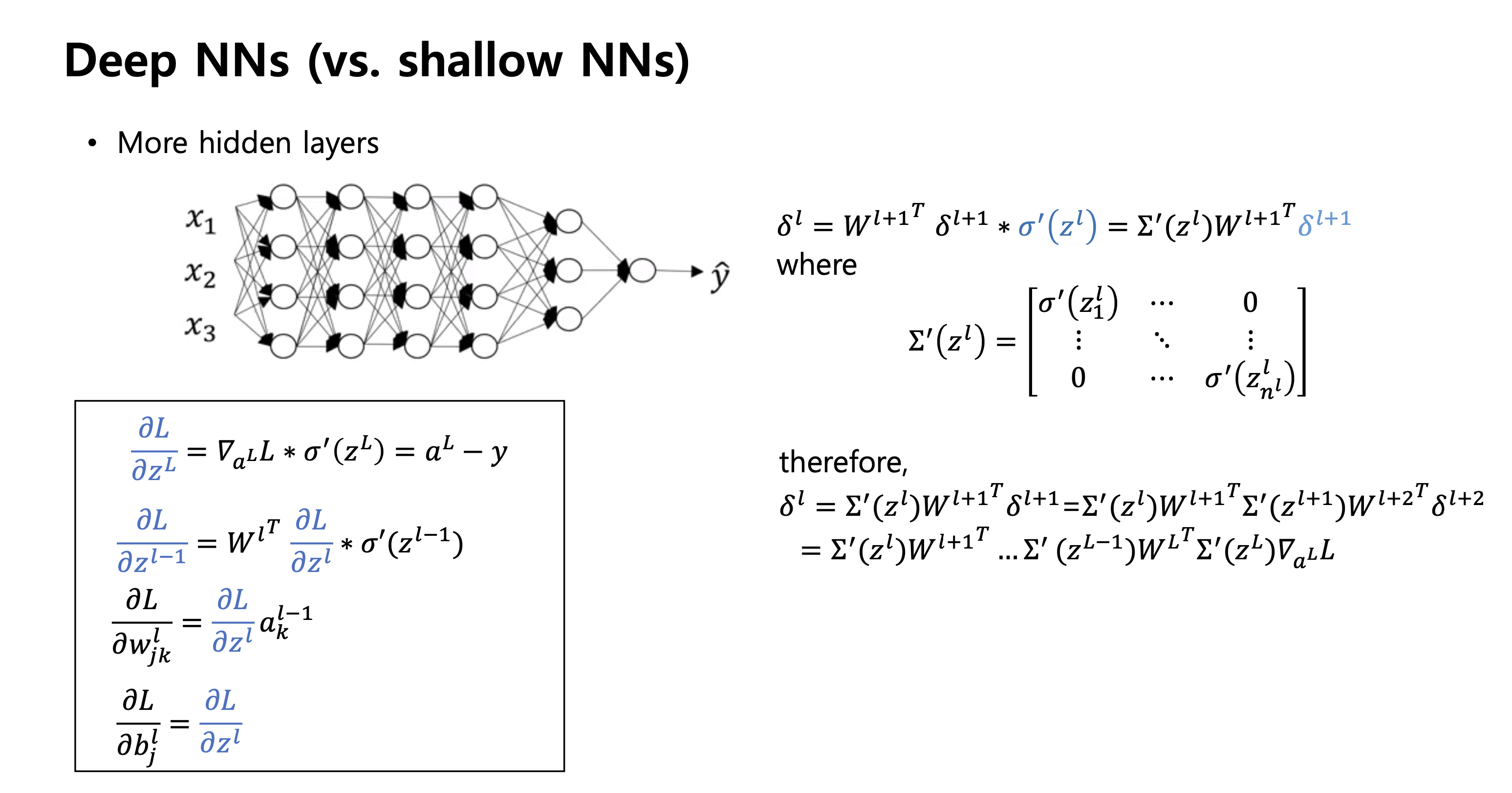
-
l-1 층에서의 미분과 l 층에서의 미분을 비교하는 점화식
-
vectorized 한 backpropagation 이 쉽다. (공식 암기x)
-
심층 신경망 네트워크 구성하기
-
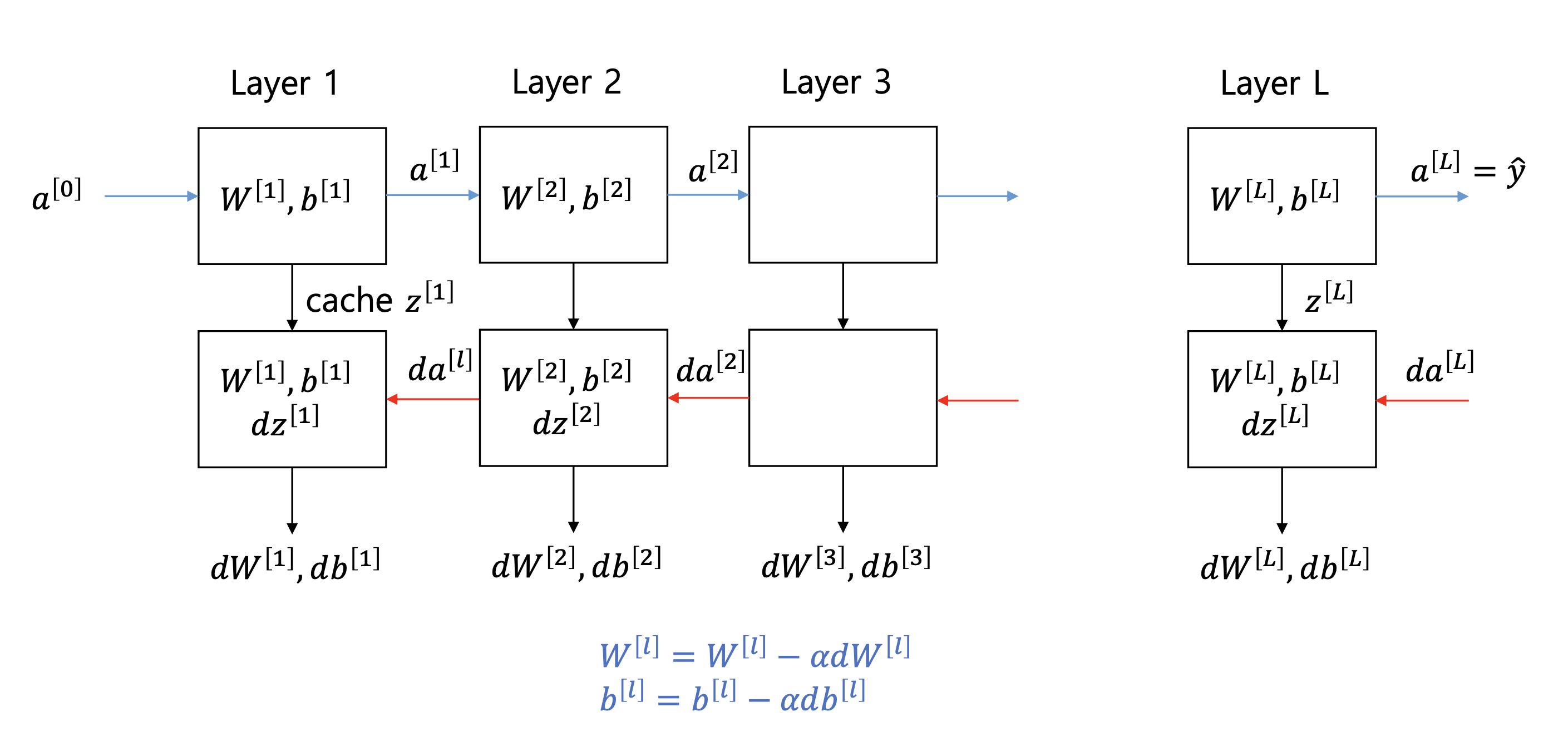
정방향전파와 역방향전파
- 번째 층에서 forward propagation 은 이전 층의 activation function 의 결과값인 을 입력으로 받아 다음 층으로 값을 출력으로 나오게 한다.
- 이때 linear combination 값인 과 변수 , 값도 cache 에 저장.
- 번째 층에서 backpropagation 은 를 입력으로 받고 를 출력한다. 이때 업데이트를 위한 와 도 함께 출력한다. 이들을 계산하기 위해서 forward propagation 에서 저장해두었던 캐시를 쓰게 된다.
-
왜 심층 신경망이 더 많은 특징을 잡아낼 수 있는지
-
직관1 : 네트워크가 더 깊어 질수록, 더 많은 특징을 잡아낼 수가 있다. 낮은 층에서는 간단한 특징을 찾아내고, 깊은 층에서는 탐지된 간단한 것들을 함께 모아 복잡한 특징을 찾아낼 수 있다.
- 노드를 무한히 증가시킨다면 세상의 모든 함수에 근사할 수 있다
- Network 가 deep 하게 hidden layer 를 쌓으면, hidden layer 의 노드를 무한히 쌓지 않아도 된지만 어렵다.
-
직관2 : 순환 이론에서 따르면, 상대적으로 은닉층의 개수가 작지만 깊은 심층 신경망에서 계산할 수 있는 함수가 있다. 그러나 얕은 네트워크로 같은 함수를 계산하려고 하면, 즉 충분한 은닉층이 없다면 기하급수적으로 많은 은닉 유닛이 계산에 필요하게 될 것이다.
-
순환 이론 : 로직 게이트의 서로 다른 게이트에서 어떤 종류의 함수를 계산할 수 있을지에 관한 것.
-
XOR 구현 방법 2가지
-
XOR 게이트를 binary tree 로 구현 -> n
-
XOR form : and 게이트와 or 게이트 사용 ->
-
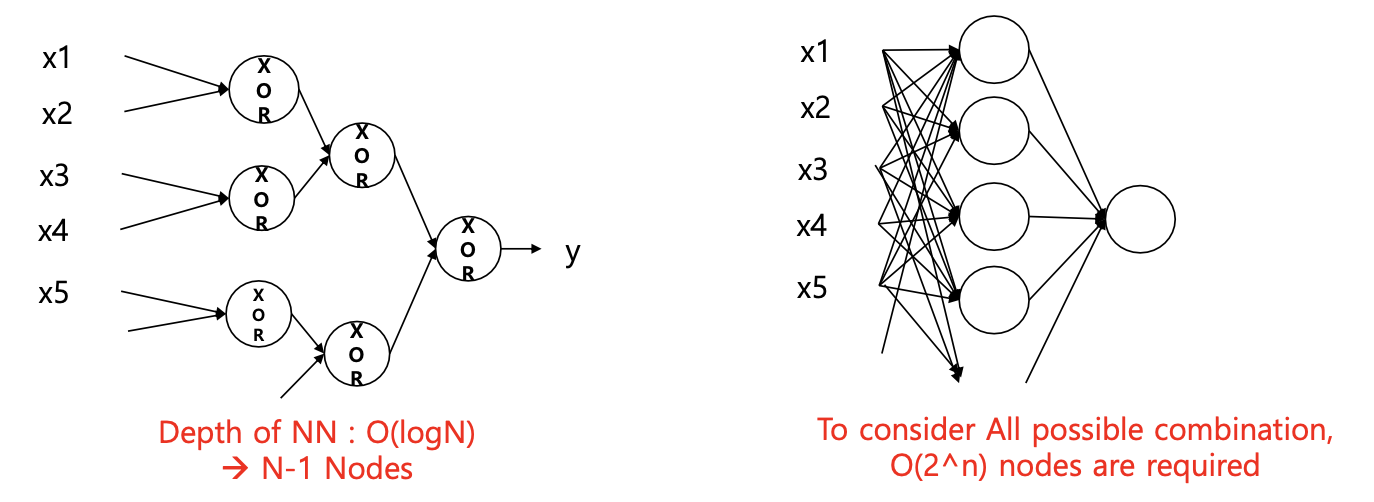
-
-
Hyperparameters
- 변수 : 학습 가능한
- 하이퍼파라미터 :
- 학습률(learning rate) :
- 반복횟수
- hidden layer 의 개수 L
- hidden layer 의 units 의 개수 : , , ..
- 활성화 함수의 선택
- Momentum, minibatch size, regularizations, ...
- 매개변수인 하이퍼파라미터를 결정하므로서 최종 모델의 변수를 통제할 수 있다.
Training/validation/test 세트
-
Training set (훈련 세트) : 훈련을 위해 사용되는 데이터
-
Validation set (개발 세트) : 다양한 모델 중 어떤 모델이 좋은 성능을 나타내는지 확인
-
Test set (테스트 세트) : 모델이 얼마나 잘 작동항는지 확인
- 데이터가 커짐에 따라 비율이 98/1/1 로 변하였다.
개발 세트와 테스트 세트가 같은 분포로 오도록 보장해야한다.
- 데이터가 커짐에 따라 비율이 98/1/1 로 변하였다.
편향(bias) 와 분산(Variance)
-
편향 : 한쪽으로 치우친 성질
-
분산 : 기댓값으로부터 얼마나 떨어진 곳에 있는지
-
편향-분산은 서로 트레이드 오프 관계
-
이전에는 bias 를 줄이거나 분산을 줄이지는 도구가 없었다.
-
현대 딥러닝에서, 더 큰 네트워크를 가지는것은 우리의 분산에 해를 가하지 않고 bias 를 줄인다.
의미 문제점 해결 높은 편향(high bias) 예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 말한다. 과소적합(underfitting) - 더 큰 네트워크
- 더 오래된 훈련
- 네트워크 아키텍쳐 조정알맞음(just right) - - 높은 분산(high variance) 예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)이 높다고 말합니다. 과대적합(overfitting) - 더 많은 데이터 구하기
- Regularization : 정규화
정규화 (Regularization)
- 과대적합(overfitting : high-variance)을 방지(분산을 줄이는)하는 방법으로는 데이터를 더 구하는 방법이 있다 하지만 이는 힘들기 떄문에 그대신 정규화(Regularization)을 해줄 수 있다.
- L1 보다 L2 정규화를 많이 사용
- 정규화는 훈련 속도를 빠르게 하고 모델에 어떠한 해도 가하지 않기 때문에 웬만하면 하는게 좋다.
Regularization for logistic regreesion
-
목적 : 인 를 찾기
-
Logistice regreesion
- cost 함수 : (추가된 term -> 얘도 최소화 해야함 : 0으로 밀어붙이기)
- logistic regression 에서의 L2 정규화 : ( 제곱)
- : 정규화 파라미터
- 거의 모든 마라미터는 w 에 속해있기 떄문에 가 빠진것이다.
Regularization for NNs
-
목적 : 인 를 찾기
-
cost 함수 : (추가된 term -> 얘도 최소화 해야함 : 0으로 밀어붙이기)
-
Frebenius 노름이라고도 불린다 :
-
back propagation :
- (역전파에서 온 값들)
- 업데이트 :
-
L2 정규화가 weight decay 라고 불리는 이유
- (역전파에서 온 것들) (역전파에서 온 값들)
- 위의 식을 보면 weight 에 1보다 작은 값인 가 곱해지기 떄문이다
- 1에서 를 뺀값에 를 곱한다면 를 계속 작아진다.
-> weight decay 라 불림( 가 0까지 계속 깎여 나가는것 -> 위에서 직관적으로 설명했던 으로 밀어붙인다는 말과 동일한 부분)
⏹ 어떻게 정규화가 과대적합을 줄일 수 있는지?
- 값을 크게 만들어서 가중치 행렬 를 0 에 가깝게 설정할 수 있다.
- 그 결과로 간단하고 작은 신경망이 되기에 과대 적합이 덜 일어난다.
- 활성화 함수를 사용했을 경우 값이 커지면 비용함수에 의해 는 작아지게 되고, 이떄 이므로 도 작아지게 된다.
- 아래 그림을 보면 가 작을떄 는 선형 함수가 되고, 전체 네트워크도 선형이 되기에 과대적합과 같이 복잡한 결정을 내릴 수 없다.
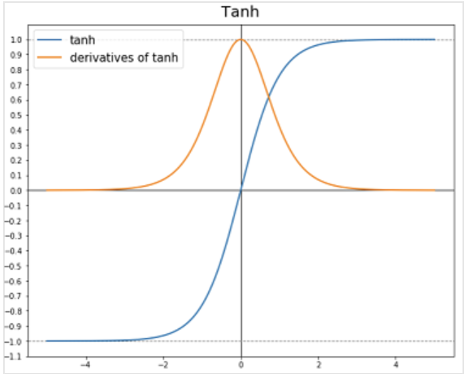
Dropout 정규화
구현
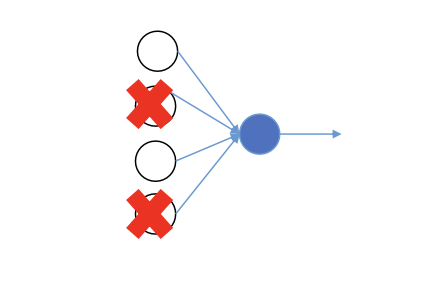
- 드롭아웃 방식 역시 overfitting 을 줄이는 방법 중 하나이다.
- 드롭아웃 방식은 신경망의 각각의 층에 대해 노드를 삭제하는 확률을 설정하는 것이다. 삭제할 노드를 랜덤으로 선정 후 삭제된 노드의 들어가는 링크와 나가는 링크를 모두 삭제한다.
- 그럼 더 작고 간소화된 네트워크가 만들어지고 이때 이 작아진 네트워크로 훈련(forward prop,loss 계산, back prop, gradient ..)을 진행한다.
z3 = np.dot(W1, X) + b1 # 선형 함수 a3 = relu(Z3) # 활성화 함수
- a3(3번쨰 layer에서의 activation function 의 output)라는 활성화값 행렬을 입력으로 받아 np.random.rand()을 사용해 입력 레이어(a3)와 동일한 크기의 d3 행렬을 생성
keep_prob는 드롭아웃 기법에서 유지할 뉴런의 비율을 나타내는 값입니다. 예를 들어, keep_prob 값이 0.8이면, 각 학습 단계에서 무작위로 선택된 뉴런 중 80%만 유지하고, 나머지 20%는 제거합니다.- 확률값
keep_prob(0.8) 보다 작은 값에 대해서만 True값으로 구성된 d3 행렬을 생성합니다- 이렇게 생성된 d3 행렬은 a3 행렬과 원소별 곱 연산(multiply)을 수행하여 일부 뉴런들을 무작위로 제거합니다.
- 마지막으로, a3 행렬의 모든 원소를 keep_prob(0.8)으로 나누어 줌으로써, 드롭아웃으로 제거된 뉴런들에 대한 보정을 해줍니다.
- 이를 통해 제거된 뉴런들이 더 이상 활성화되지 않더라도, 전체 층의 활성화값의 크기가 일정하게 유지됩니다.
- 보정된 활성화값을 사용하여 층의 가중치와 편향을 곱해줌으로써, 다음 층에서의 입력값을 계산합니다.
- 드롭아웃으로 인해 제거된 뉴런들에 대한 보정이 제대로 이루어지지 않으면, 모델이 학습 데이터에 과적합되는 경향이 커지게 됩니다.
- 따라서 드롭아웃에서는 보정 과정이 매우 중요한데, 이를 효율적으로 수행하기 위해 inverted dropout이라는 기법을 사용합니다. 이 기법은 학습 단계에서 드롭아웃을 적용할 때와 테스트 단계에서 드롭아웃을 적용하지 않을 때의 계산 방식을 동일하게 유지함으로써, 모델의 성능을 일정하게 유지할 수 있습니다.
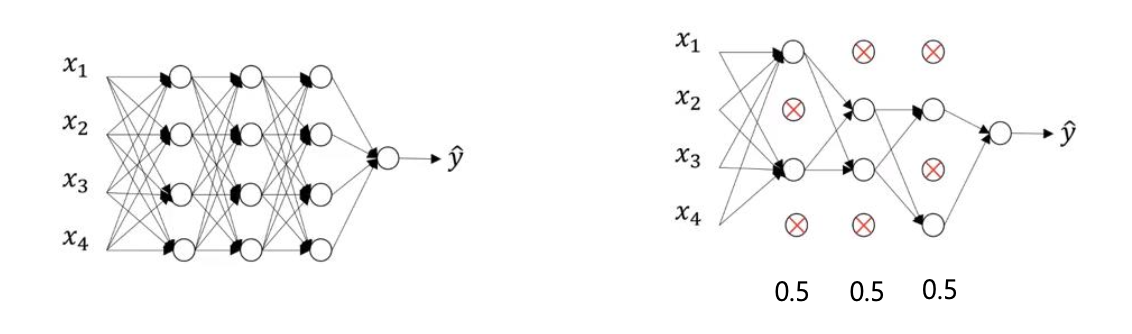

⏹ Dropout 의 이해
- 직관 : 드롭아웃은 랜덤으로 노드를 삭제 시키기 때문에, 하나의 특성에 의존하지 못하게 만듦으로서 가중치를 다른곳으로 분산 시키는 효과가 있다.
- 드롭아웃의 keep.prop 확률은 층마다 다르게 설정할 수 있다.
- 예를 들어 이 높은 차원을 가진다. 따라서 더 낮은 keep_prob 을 layer 2 가 받을 수 있다.
- 모든 반복에서 잘 정의된 비용함수가 하강하는지 확인하는게 어려워진다. 따라서 우선 드롭아웃을 사용하지 않고 비용함수가 단조감소인지 확인 후에 사용
교재 other tips
• 만약 overfitting 문제가 발생하지 않는다면, dropout을 사용할 필요는 없습니다.
• 예를 들어, 컴퓨터 비전 분야에서는 보통 충분한 양의 데이터가 없고, 거의 항상 overfitting 문제가 발생합니다. 그래서 dropout을 자주 사용하게 됩니다.
• Drop out의 큰 단점 중 하나는 비용 함수 J가 더 이상 명확하게 정의되지 않는다는 것입니다. 매 반복마다, 일부 노드가 무작위로 제거되기 때문에 비용 함수 J가 명확하게 정의되지 않아서, 매 반복마다 J를 단조적으로 감소시키기가 어려울 수 있습니다.
• 디버깅할 때, keep_prob를 1로 설정하여 dropout을 끄고 코드를 실행하고, J가 단조적으로 감소하는지 확인한 후 dropout을 켜는 것이 좋습니다.
⏹ 다른 정규화 방법들
-
data augmentation (데이터 증식)
- 이미지의 경우 더 많은 훈련 데이터를 사용하므로서 과대적합을 해결할 수 있다.
- 보통 이미지를 대칭, 확대, 왜곡 혹은 회전 시켜서 새로운 훈련 데이터를 만든다.
- 이런 추가적인 가짜 이미지들은 완전히 새로운 독립적인 샘플을 얻는 것보다 더 많은 정보를 추가해주지는 않지만, 컴퓨터적인 비용이 들지 않고 할 수 있다는 장점이 있다.
-
Early stopping (조기종료)
-
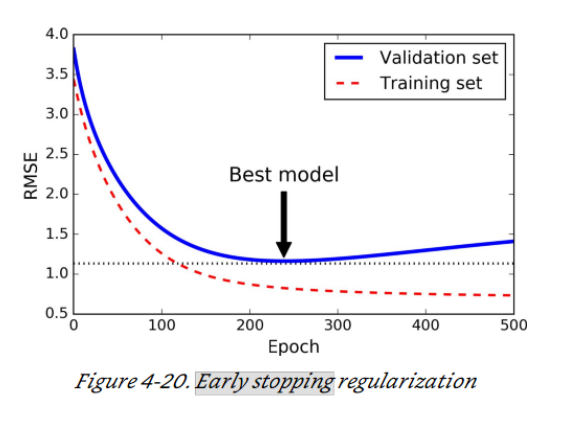
-
훈련 세트의 오차는 단조적인 하강함수로 그려질 것이다.
-
조기종료에서는 개발 세트(validation set)의 오차도 그려준다.
-
만약에 개발 세트의 오차가 어느 순간 부터 하락 하지 않고 증가하기 시작하는 것이라면 과대적화가 되는 시점이다.
-
따라서, 조기 종료는 신경망이 개발 세트의 오차 지점 부근, 즉 가장 잘 작동하는 점일때 훈련을 멈추는 것이다.
-
단점 : 훈련시 훈련 목적인 비용함수를 최적화 시키는 작업과 과대적합하지 않게 만드는 작업이 있다. 두 작업은 별개의 일이라서 두 개의 다른 방법으로 접근해야 한다. 그러나 조기 종료 두 가지를 섞어 버린다. 따라서 최적의 조건을 찾지 못할 수도 있다.
-
⏹ training set(입력값) 의 정규화
-
정규화 방법 라고 가정
- 평균을 0으로 만들기
- 분산을 1로 만들기
- 또는
- 테스트 세트를 정규화 할때 훈련 데이터에 사용한 와 을 사용해야한다.
- 정규화를 통해 비용함수의 모양은 더 둥글고 최적화하기 쉬운 모습이 된다. 그로 인해 학습 알고리즘이 빨리 실행된다.
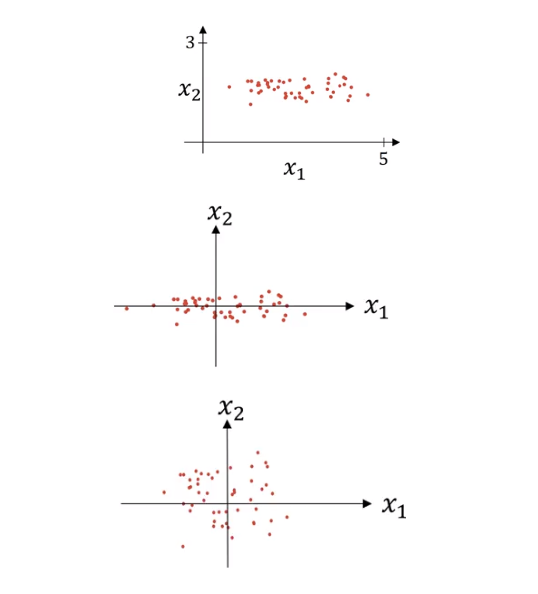
- 평균을 0으로 만들기
입력값을 정규화 하는 이유?
- 만약 과 가 매우 값의 다른 범위를 가진다면, 상응하는 과 도 값의 다른 범위를 가진다.
- 정규화되지 않은 입력의 곡선에 대한 학습 속도는 작도록 제한될 수 있습니다
: normalize 하지 않고 데이터를 사용한다면, 어떤 특정 데이터의 w 가 더 커져 loss 모양이 불안정적으ㅗㄹ 나온다.
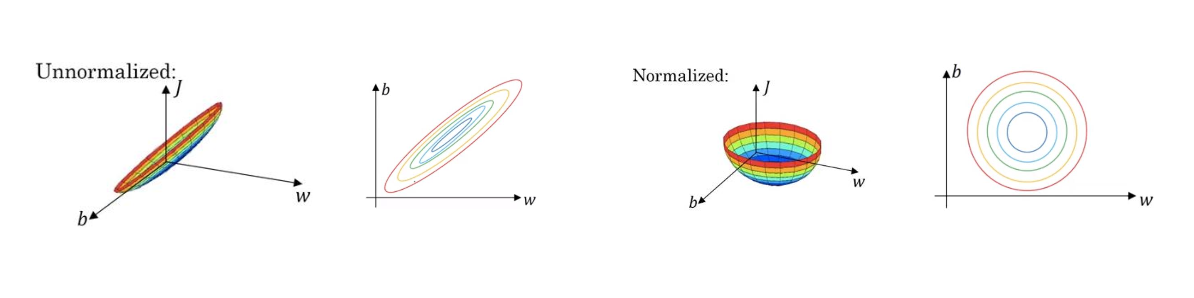
⏹ 경사소실(Vanishing gradients) / 경사폭발(exploding gradients) unstable gradient problem
-
우리는 대략 벡터 의 길이로 학습 속도를 측정합니다
-
매우 deep 한 신경망을 훈련시킬때 나타나는 문제점은 경사소실과 폭발이다.
-
예를 들어 각 layer에 대해 2개의 노드가 있는 deep 네트워크가 있다고 가정합니다
- 그리고 이라고 가정했을 때
- 그럼 ... 이다.
- 이때, 모든 가중치 행렬 = (단위 행렬) 이다. 즉, 가 된다.
- 더 깊은 신경망일수록 이 클수록 의 값은 기하급수적으로 커진다(폭발).
- 이를 토대로 생각하면 경사 하강법에서 의 값이 단위행렬보다 큰 값이라면 경사 폭발
- 반대로 의 값이 단위 행렬보다 적은 값 이라면 경사의 소실 문제점이 생긴다.

-
경사의 소실과 폭발로 인해 학습 시키는데 많은 시간이 걸리기에 가중치 초기화 값을 신중하게 해야한다.
w 를 1보다 조금만 커도 즉, 조금만 흔들어도 폭발하는 문제
즉, 네트워크를 deep 하게 쌓으면 표현력은 좋아지지만 w 가 불안해진다(네트워크가 불안해진다)
⏹ 심층신경망의 가중치 초기화
- 경사 소실 및 폭발을 막기 위해 가중치 초기화를 하고 이는 가중치를 1보다 너무 큰 수나 너무 작은 수를 하지 않도록 해주어 폭발이나 소실을 막아주는 것임
- activation function 을 이것을 사용하지 않고 ReLU 사용
⏹ deep NN 에 대한 가중치 초기화 : single neuron 예시
- 와 가 normal distribution 를 따라 으로 초기화되었다고 가정한다.
- + ... 라고 하고 그래프를 그려본 결과
- input 의 개수가 적다면 분산이 작게 나오고
- input 의 개수가 만약 500 이라면 w즉 , 500개의 가 있는 경우는 분산이 크게 나온다.
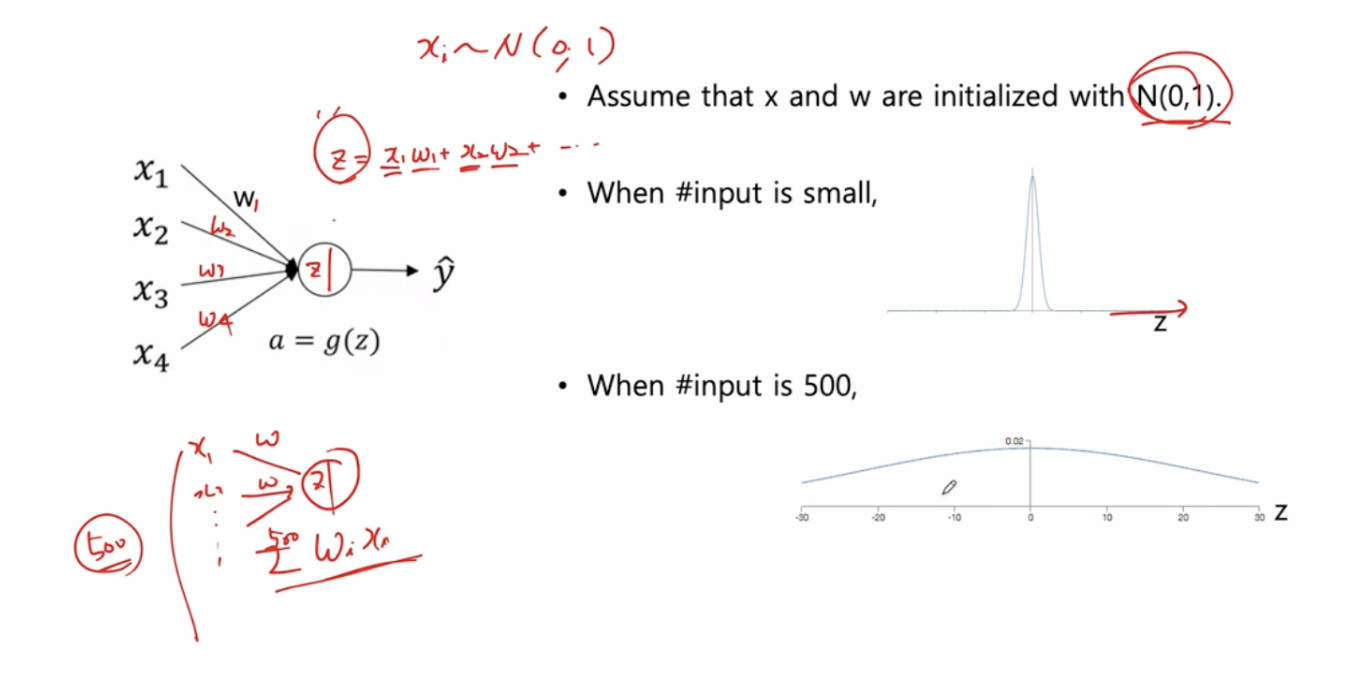
- 문제점
: 어떤 노드에 들어오는 input 의 수에 따라서 에 대한 초기화를 달리 해줘야 한다.
즉, input 수에 따라서 normalize 해주는 방식이 필요할 것 같다는것이 관찰할 사안
- 문제점
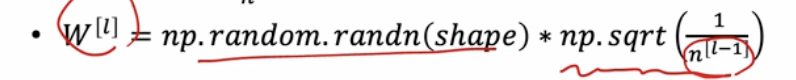
w 를 random 하게 noramalize 하는게 아니라 디른 noramlize term 을 가지고 있는것이다. 이것은 자기 노드에 들어오는 입력숫자
normalize term :
만약 노드로 들어오는 입력이 4개라면 에 4가 들어가는것이다.
n 이 커지면 커질 수록 w 는 작아진다. 이렇게 하므로써 z 의 분포를 비등비등하게 맞춰주는 것이다.
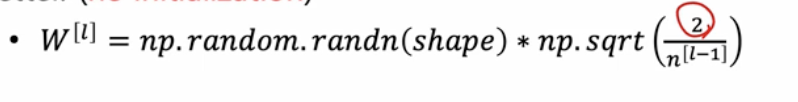
정리 : 자신의 노드로 들어오는 입력 숫자를 포함하고있는 noralize term 을 포함한 initialization 이다.
이런 initailization 을 통해서 Neural Net 이 좀더 수렴을 쉽게 할 수 있도록 사용할 것이다.
코드
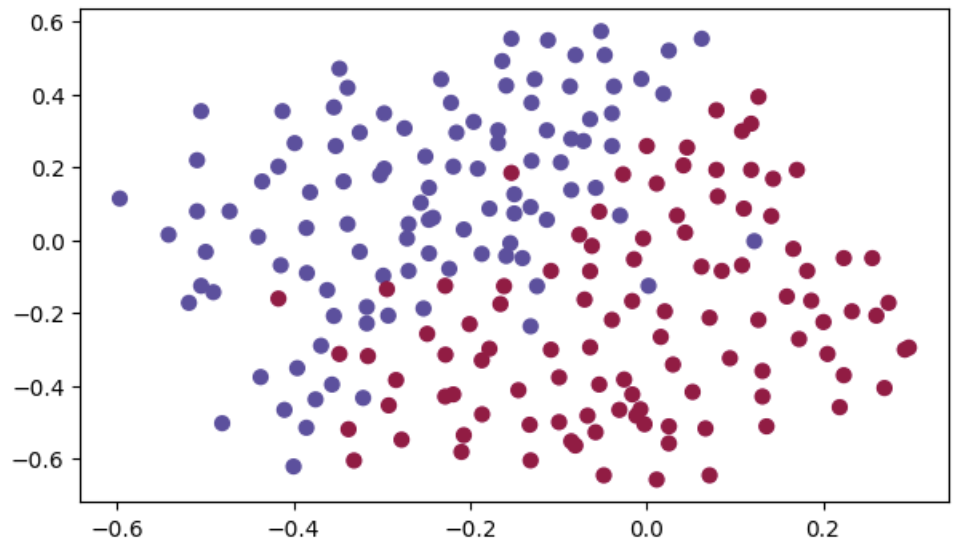
# 목표 : 딥러닝 모델을 사용하여 빨간(0) 파란(1) 분류
# 정규화 되지 않은 모델 먼저 사용해보자
# 그런다음 어떻게 정규화를 하고 이 문제를 풀기위해 어ㄷ느 모델을 결정해야하는지를 배운다.
# 비정규화 모델
# - 이미 위에 구현된 NN 을 따를것, 이 모델은 다음으로 사용되어질 수 있다.
# - 정규화 모드 : 0이 아닌 값으로 lambd 입력을 설정
# - 드롭아웃 모드 : 1보다 작은 값 keep_prob 설정
# 어떤 정규화 없이 그 모델을 먼저 시도할것이고 그런다음 다음을 구현할 것이다.
# - L2 정규화 함수 : compute_cost_with_regularization()" and "backward_propagation_with_regularization()"
# - Dropout 함수 : forward_propagation_with_dropout()" and "backward_propagation_with_dropout()"
# 순전파 진행 : LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
def model(X, Y, test_X=None, test_Y=None, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0, keep_prob = 1):
# 3층 신경망 구현: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
# Arguments:
# X -- 입력 데이터,
# Y -- 실제 label 벡터 (1 : 파란점 / 0 : 빨간점)
# learning_rate -- 학습률
# num_iterations -- 반복횟수
# print_cost -- 참이면 10000번의 반복마다 cost 출력
# lambd -- 정규화 파라미터, 스칼라값임
# keep_prob - 드랍아웃동안에 유지할 뉴런의 비율
# 딕셔너리 파라미터 초기화
# 루프(gradient descent)
# 순전파(Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.)
# Cost function
# 역전파 (L2 정규화와 드롭아웃 둘다 사용할 가능성이 있다, 그러나 여기서는 한번에 하나씩만 할 예정)
# 파라미터 업데이트
# Returns:
# parameters -- 그 모델에 의해서 학습된 파라미터, 그 파라미터들은 예측에 사용할수있다.
# L2 정규화 : 과적합을 에방할 수 있는 기본적인 방법,
def compute_cost_with_regularization(A3, Y, parameters, lambd):
# L2 정규화에 대한 Cost function 구현
# 인자 :
# A3 : 이전의 활성값, 순전파의 출력값
# Y : 정답 label 벡터
# parameters : 그 모델의 파라미터를 포함하고 있는 딕셔너리
# returns:
# Cost : 정규화된 Loss 함수의 값
L2_regularization_cost = (1/m) * (lambd/2) * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3)))
def backward_propagation_with_regularization(X, Y, cache, lambd):
# L2 정규화를 추가한 기준 모델의 역전파 구현
# 인자 :
# X, Y
# cache : 순전파의 캐시 출력값
# lambd : 정규화 파라미터
# returns : gradient
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache # 순전파 과정에서 계산된 값들 받기
dZ3 = A3 - Y
### START CODE HERE ### (approx. 1 line)
dW3 = A3 - Y #채운값
### END CODE HERE ###
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
### START CODE HERE ### (approx. 1 line)
# L2 정규화를 사용하기 위해 (lambd/m) * W2 부분 추가
dW2 = 1./m * np.dot(dZ2, A1.T) + (lambd/m) * W2 # 채운값
### END CODE HERE ###
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
### START CODE HERE ### (approx. 1 line)
dW1 = 1./m * np.dot(dZ1, X.T) + (lambd/m) * W1 # 차운값
### END CODE HERE ###
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients def forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):
...
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1) # 선형회귀, 활성화함수 대입
### START CODE HERE ### (approx. 4 lines)
D1 = np.random.rand(A1.shape[0],A1.shape[1]) # 행렬 D1 초기화
D1 = D1<keep_prob # D1 의 공간을 0과 1로 변환 (keep_prob 을 스레시홀드로 사용)
A1 = np.multiply(D1, A1) # A1 의 뉴런 닫기
A1 = A1/keep_prob # 폐쇄되지 않은 뉴런들의 값 확장
### END CODE HERE ###
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
### START CODE HERE ### (approx. 4 lines)
D2 = np.random.rand(A2.shape[0],A2.shape[1])
D2 = D2<keep_prob
A2 = np.multiply(D2, A2)
A2 = A2/keep_prob
### END CODE HERE ###
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T)
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
### START CODE HERE ### (≈ 2 lines of code)
dA2 = np.multiply(dA2, D2) # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation
dA2 = dA2/keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T)
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
### START CODE HERE ### (≈ 2 lines of code)
dA1 = np.multiply(dA1, D1) # Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation
dA1 = dA1/keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T)
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients