이 글은 테디노트님의 패스트캠퍼스 강의를 듣고 작성하는 포스트 입니다.
AI 입문자이므로 잘못된 내용이 있으면 댓글로 남겨주세요.
다양한 PDF Loader
RAG 구조에서 가장 먼저 수행할 단계는 문서를 로드하는 것이다.
나는 PDF 문서를 많이 로드할 예정이라 PDF를 먼저 살펴보았다.
- PyPDFLoader
- PyMuPDFLoader
- PDFPlumber
이 외에도 많은 PDF Loader가 있다.
다른건 모르겠고.. 일단 PDFPlumberLoader 성능이 나쁘지 않다고 해서 먼저 사용해 보았다.
from langchain_community.document_loaders import PDFPlumberLoader # PDF loader
loader = PDFPlumberLoader("data/2021 재무제표.pdf")
docs = loader.load()
# 로드한 페이지 수 확인
print(f"문서의 페이지수: {len(docs)}")data폴더를 만들고 그 안에 로드할 pdf를 넣었다.
그리고 위와 같이 코드를 써준 후에 실행하면 docs에 pdf 내용이 로드된다.
순탄치 않은 PDF Load
잘 load되었길래 신나서 이것저것 필요한 pdf를 넣었다.
그런데 LLM이 내 대답에 똑바로 대답을 안하고 자꾸 해당 내용을 찾을 수 없다길래 확인해보니...
넣은 PDF 중 일부는 빈 내용으로 load가 된 것이었다.
이게 대체...💩
내가 대체로 넣는 PDF들은 표가 많은데, 로드된 표는 텍스트 형식으로 PDF에 들어가있었으며
로드되지 않고 빈 페이지로 로드된 부분은 이미지 형식으로 PDF에 들어가져 있었다.
PDFPlumberLoader는 이미지를 인식하지 못하기 때문에 그냥 빈 페이지로 로드한 것이다...^^
이미지로된 표 Load하기 시도..
!pip install -qU rapidocr-onnxruntimefrom langchain_community.document_loaders import PyPDFLoader # PDF loader
# extract_images=True : 이미지추출 활성화
loader = PyPDFLoader("data/'PDF파일이름'", extract_images=True)
docs = loader.load()
print(f"문서의 페이지수: {len(docs)}")
이미지 추출을 할 수 있다고해서 PyPDFLoader를 사용했지만 page_content='' -> 대차게 실패한 모습이다💩
pytesseract 설치해서 시도해보기
이번엔 나의 친구 GPT의 도움을 받았다.
pytesseract 라이브러리를 설치해서 사용해보라고 권유한다.
참고로 Tesseract는 구글에서 개발한 오픈소스 OCR 엔진으로, 이미지를 분석하여 이미지 속의 텍스트를 추출하는 데 사용된다.
(pip install로 pdfplumber, pytesseract, pillow를 다운받았고, 따로 pytesseract 엔진을 git에서 다운받아 설치까지 했다)
import pdfplumber
import pytesseract
from langchain_core.documents import Document
def load_pdf_with_ocr(pdf_path):
loader = PDFPlumberLoader(pdf_path)
docs = loader.load()
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
page_text = docs[i].page_content # 기존 텍스트
metadata = docs[i].metadata
# 이미지가 있는 경우 OCR 수행
for image_obj in page.images:
x0, top, x1, bottom = image_obj["x0"], image_obj["top"], image_obj["x1"], image_obj["bottom"]
image = page.to_image()
cropped_image = image.crop((x0, top, x1, bottom)).convert("RGB")
# OCR로 이미지에서 텍스트 추출
ocr_text = pytesseract.image_to_string(cropped_image)
page_text += "\n" + ocr_text
# 문서화하여 저장
docs[i] = Document(page_content=page_text, metadata=metadata)
return docs파일 경로를 지정해서 PDF파일을 로드하면 일단 텍스트 추출을 하고, 이미지가 있는 경우 OCR로 이미지를 분석해 텍스트를 추출해주는 메서드다.
두근두근하며 실행해봤지만 또 실패다.
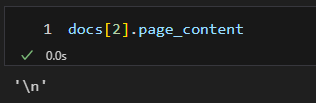
PDF에서 텍스트로 드래그 안되는 부분을 일단 이미지로 잘 인식하고 있는지를 확인하기 위해 중간에
if-else 구문을 넣었다.
열이 받는다.
PDF의 페이지 전체를 이미지로 변환 후 텍스트 추출하기
import pdfplumber
import pytesseract
from langchain_core.documents import Document
def load_pdf_with_ocr(pdf_path):
loader = PDFPlumberLoader(pdf_path)
docs = loader.load()
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
page_text = docs[i].page_content # 기존 텍스트
metadata = docs[i].metadata
# 페이지 전체를 이미지로 변환
page_image = page.to_image()
full_page_image = page_image.original.convert("RGB") # PIL 이미지로 변환
# OCR로 페이지 전체 텍스트 추출
ocr_text = pytesseract.image_to_string(full_page_image, lang="kor+eng")
# 문서화하여 저장
docs[i] = Document(page_content=ocr_text, metadata=metadata)
return docs
이미지를 인식못하니까 그냥 PDF 페이지를 한땀한땀 이미지로 만들고 그 이미지에서 텍스트를 긁어오는 코드로 바꿨다.
결과는...?
놀랍게도 무언가가 page_content에 들어갔다!
근데 그 무언가가 뭔지 모르는 외계어가.........😊💩
이미지에서 텍스트는 가져오되, 표 구조를 이해 못하고 아무글씨나 가져다 붙인 느낌이다.
(근데 표 어느부분에서 뭘 어떻게 가져온건지도 모르겠음;;;;)
절반만 성공했다... 이걸 성공했다고 해야할지.......ㅂㄷㅂㄷ
쓰레기같은 PDF...쓰레기같은 내 코딩실력......
