Cross entropy
Cross EntropyMultinomial Classificationcross entropy loss functionentropymultinomial logistic regression
Clinic-Classification
목록 보기
5/5
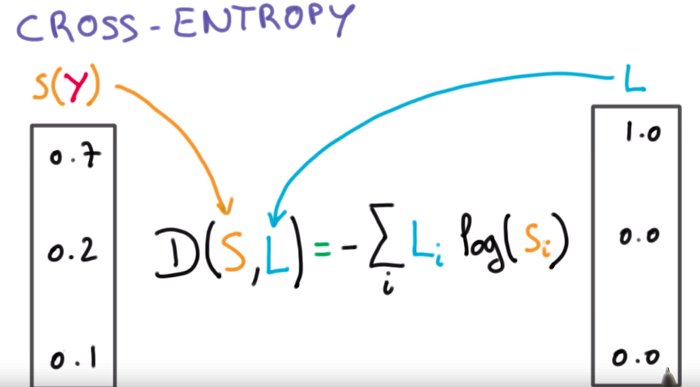
Classification Task에서 빼놓을 수 없는 것 중 하나는 바로 Cross entropy cost function입니다. 이것이 왜 분류 문제에서 중요한지, 어떤 역할을 하는지 서술해주세요.
cross entropy를 이해하기에 앞서 entropy란 무엇인지 이해하는게 좋습니다.
entropy는 불확실성을 나타내며, entropy가 높다는 것은 정보가 많고, 확률이 낮다는 것을 의미합니다.
(모든 사건이 같은 확률로 일어나는 것이 가장 불확실합니다)
cross entropy는 불확실성의 확률분포의 오차범위를 구하고 이를 줄이기 위해 사용됩니다.
분류 문제는 categorycal 합니다.
예를 들어 주머니에서 4가지의 색깔이 있는 공이 있고 이를 뽑는다고 가정했을때, yi값(target)이 [0.5, 0.125, 0.125, 0.25]이고, 학습한 활률(예측값)인 y^i값이 [0.25, 0.25, 0.25, 0.25]입니다.
위의 리스트로 보여지는 값이 entropy라고 볼 수 있으며, yi와 y^i의 값을 가지고 cross entropy하여 오차범위를 구합니다.
(이제 y^i를 학습할때 yi에 가까울수록 cross entropy값이 줄어들기 때문에 cross entropy값이 낮아지는것을 목표로 학습하는 것 입니다.)

ENTJ-A