A Closer Look at Rehearsal-Free Continual Learning
Abstract
컨티뉴얼 러닝은 지속적으로 변이하는 학습 데이터에 머신러닝 모델이 잘 학습할 수 있도록 세팅하는 것이다. 동시에 이전에 보았던 class 정보를 학습 데이터에서 없어져도, 잃지 않아야 한다. 현재의 컨티뉴얼 러닝의 접근 방법론은 이전에 본 데이터에서 확장적인 리허설을 통해 지식의 degradation을 막았다. 하지만, 리허설은 메모리 코스트를 요구하고 이것은 데이터 프라이버시를 침범할 문제도 존재하게 된다.
따라서 본 연구에서는 지식 증류와 파라미터 정규화를 융합하는 과정을 통해서 스트롱 컨티뉴얼 러닝을 리허설 없이 수행하는 방법론을 제안한다. 기존의 컨티뉴얼 러닝 기술 특성인 예측 증류, 특질 증류, L2 파라미터 정규화, EWC 파라미터 정규화 등이 있는데, 이러한 것들의 가정이 리허설프리한 컨티뉴얼 러닝에 맞지 않음을 증명한다. 다음으로, 프리트레인된 지식을 리허설프리 모델에 활용 방법을 찾고 L2 파라미터 정규화가 EWC 파라미터 정규화와 특질 증류보다 효과적임을 보인다. 마지막으로 L2 파라미터 정규화는 VIP 트랜스포머의 셀프 어텐션 블록으로 현재 컨티뉴얼 러닝 방법론보다 효과적임을 보인다.
1. Introduction
훈련 데이터에 지속적인 시프트는 퍼포먼스 degradation을 유도하기 때문에 모델이 지속적으로 교체되어야 한다. 기존의 교체 방법론은 새로운 훈련 데이터를 기존의 훈련 데이터와 혼합시키고 재삭습을 시키는 것이다. 이것은 높은 퍼포먼스를 보일 수는 있지만, 모델이 학습하는데 많은 시간을 요구한다. 또한 새로운 데이터에 대해서 학습을 하게 되면 catastrophic forgetting을 야기한다.
따라서 이러한 문제를 대응하기 위해서 컨티뉴얼 러닝 세팅이 연구되었는데 이 태스크의 데이터에서는 covariate distribution shift 보다는 semantic distribution shifts를 보인다. 즉, 백그라운드 컨디션의 변화보다는 새로운 오브젝트의 클래스를 직면하는 경우를 말하는것이다.
본 연구에서는 컨티뉴얼 러닝 태스크 중에서 single, expanding classification head에 집중한다. 이는 멀티태스크의 컨티뉴얼 러닝 세팅과는 다르다. 이는 task incremental continual learning 이라고 불리우며, 각 태스크에 따라 classification heads를 분류한다. 하지만 SOTA 방법론은 태스크에 라벨이 없이 컨티뉴얼 러닝을 수행할 때, 학습 데이터의 서브셋을 저장하거나 믹스를 통해 생성해낸다. 이를 리허설이라고 불리고, 이는 private user data의 경우 오랜 기간 저장할 수 없다는 단점이 있다.
따라서 본 연구에서는 리허설 프리한 전략을 통해서 컨티뉴얼 러닝을 어떠한 학습 데이터의 저장 없이 수행한다. 새로운 방법론을 제안하기 보다는 기존의 전략을 새롭게 구축하는 시각을 제안한다. 즉, 어떤 타입의 정규화가 리허설 프리한 컨티뉴얼 러닝에 적합한가? 라는 질문을 통해 파라미터 정규화는 멀티클래스 시그모이드를 소프트맥스를 활용하는것보다 효과적임을 보인다.
하지만 본 연구에서는 아직 리허설 프리한 모델이 갭이 있음을 극복하지는 못했다. 따라서 이러한 갭을 줄이기 위해서 어떤 타입의 정규화가 프리트레인된 모델을 활용하는 리허설 프리 방뻐론에 효과적일까? 질문에 L2 정규화가 놀랍게도 프리트레닝 세팅에서는 가장 적합함을 보인다.
본 연구의 컨트리뷰션은 다음과 같다.
1. 리허설 프리 컨티뉴얼 러닝을 통해서 later layer에 forgetting이 더 많이 일어남을 보인다. 프리트레이닝이 없을 때에는 mitigation 의 가장 효과적인 방법론은 final prediciton의 정규화임을 보인다.
2. 프리트레이닝이 존재하는 경웬느 예측을 정규화하는것 보다는 파라미터를 정규화하는 것이 효과가 좋음을 보인다.
3. 리허설 프리 방법론중에서는 SOTA 성능을 달성하였다.
2. Background and Related Work
Online Rehearsal-Free Continual Learning : 프리트레인된 모델을 통해서 스트리밍 관점의 학습을 수행하는 방법론이 존재한다. 이러한 연구는 고정된 특질 공간상에서 온라인 러닝에 집중하는데, 본 연구에서는 이와는 세팅이 완전히 다르다. 고정되지 않은 모델에 집중하면서 동시에 태스크 데이터에 대해서 수렴하도록 유도하기 때문에 오프라인 컨티뉴얼 러닝과 흡사하다.
Prototype-Based Approaches for Continual Learning : 스토롱 데이터 없이도 castastrophic forgetting 을 막을 수 있게끔 프로토타입을 활용할 수 있다. 최근의 방법론들은 프로토타입의 특질 공간을 학습하는데, 임베딩 네트워크를 학습하거나 혹은 자가지도학습을 스토롱 어그멘테이션을 활용하는 방법론이 있다. 크로스 엔트로피 classification 에 비해서 임베딩 네터워크의 프로토타입을 학습하는 것이 더 효과적이다. 하지만 이러한 방법론은 하드 챌린지가 될 위험이 있다. 데이터를 증강하고자 강한 자가지도학습을 수행하는 방법론은 SOTA 퍼포먼스를 리허설 프리 컨티뉴얼 학습으로 사용할 수 있다. 하지만 이것은 포겟팅을 방지하는 것으로 더 좋은 성능을 얻는것인지, 혹은 데이터의 증가만으로 더 좋은 특질을 추출하는것인지 구분이 불가하다. 또한 이러한 접근 방법론은 첫번째로 strong initial freature space를 학습해야 하는데 이것들은 처음부터 존재하지 않는 경우도 많다.
Rehearsal-Free Continual Learning: 최근 연구는 고정된 프리트레인된 트랜스포머 모델을 통해서 컨티뉴얼 러닝을 수행한다. 이 과정은 데이터의 시퀀스가 프리트레인된 인코더에서 separated 될 수 있다는 가정을 한다. 다른 연구에서는 리허설을 위한 이미지 제공을 deep-model inversion을 통해 수행한다. 하지만 이러한 방법론들은 generative 한 방법론들과 비슷한 리스크가 존재한다. 모델 inversion은 느린 프로세스로 높은 계산 코스트를 필요로 하고, 학습된 모델로부터 이미지를 inverting 하는 것은 데이터 프라이버시 문제를 야기한다. 따라서 본 연구에서는 전체 리허설이 포함하는 저장되고 학습되고 인버티드된 학습 데이터를 제거하고자 한다.
3. Preliminaries
Continual Learning: 컨티뉴얼 러닝에서는 라벨된 데이터는 M개의 시멘틱 오브젝트 클래스로 클래스의 겹치지 않는 서브셋들에 대한 N 개의 태스크로 이루어져 있다. 이 term은 task n 에 대해서 클래스 셋을 의미한다. 각 클래스는 하나의 single task에 대해서만 나타나며, 이전에 학습된 클래스를 분류하는 성능을 계속 유지하면서 새로운 오브젝트 클래스를 분류하는 모델을 만드는 것이다.
이 term은 task n 에 대해서 클래스 셋을 의미한다. 각 클래스는 하나의 single task에 대해서만 나타나며, 이전에 학습된 클래스를 분류하는 성능을 계속 유지하면서 새로운 오브젝트 클래스를 분류하는 모델을 만드는 것이다.
본 연구에서는 class-incremental continual 러닝 세팅을 수행하였다. 이는 learner 가 모든 n task 까지 본 class들에 대해서 모두 다 분류를 할 수 있어야 하기 때문에 매우 챌린징한 이슈이다.
4. Rehearsal-Free Regularization
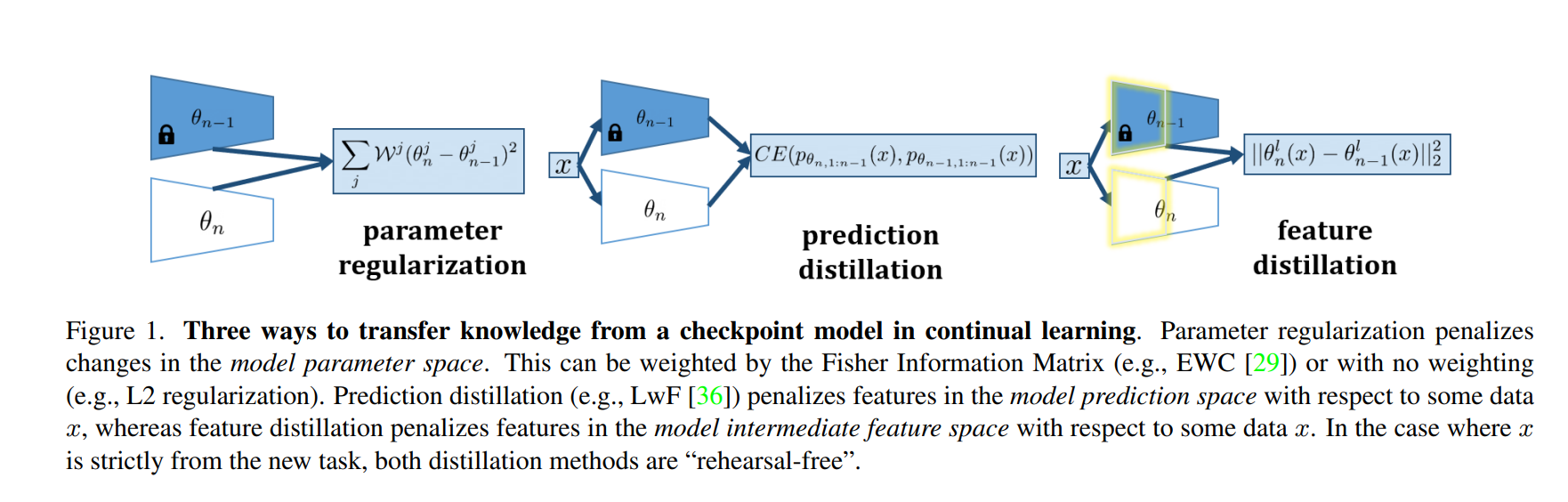
새로운 태스크에 대해서 체크포인트 모델에서 지식을 전이시키기 위해서 3가지의 클래식한 리허설 프리 모델을 비교한다. 이러한 방법론들중 예측 증류 방법론이 모델의 calssifier의 정보를 전이하는데 중요하다. 다른 두가지 방법론들은 파라미터 regularization과 특질 증류 방법론으로, 모델의 feature 인코더의 지식 전이가 더 중요하다.
4.1. Parameter Space Regularization
EWC와 같은 방법론이 사용하는 방법론으로 모델의 파라미터 공간에서 정규화를 수행하는 방법론이다. 이는 다음과 같은 식으로 나타난다.
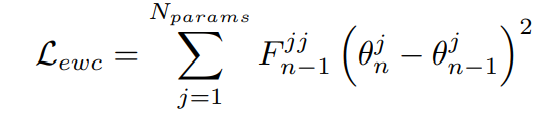
F가 항등행렬이라면, 간단히 L2 정규화 문제로 변환된다.
4.2. Feature Space Regularization
prediction spaec 상에서의 지식 증류는 PredKD 라고 하며, 다음과 같은 로스식을 통해 수행하게 된다.

특질 공간상에서의 지식 증류는 FeatureKD 라고 하며, 다음과 같은 로스식을 통해 수행하게 된다.
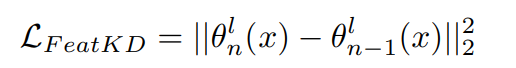
4.3. Task-Bias
태스크 바이어스는 최근 태스크의 데이터에 대해서 추론이 편향되어 있는 경우를 말한다. 기존에는 리허설 데이터를 통해 이러한 문제를 해결해 왔지만, 본 연구에서는 sigmoid binary cross-entropy classification loss 를 활용하여서 해결한다. 소프트맥스의 경우에는 이전에 본 클래스에 대한 bias를 리허설이 없다면 심하게 갖게 되는데, 이유는 이 손실을 최소화한다는 것은 이전 클래스의 output이 없어지기 때문이다. 본 연구에서는 BCE 클래시파이어를 통해 이전의 태스크 라벨이 없는 상황에서의 성능 저하를 없앨 수 있다.
5. Experiments
EWC, L2, PredKD, FeatKD의 리허설 프리 컨티뉴얼 러닝 세팅에서의 성능을 확인한다. 로스의 성능또한 비교한다.
i) naive model trained with classification loss only (referred to as naive)
ii) upper bound model trained with the joint training data from all tasks (referred to as upper-bound).
CIFAR 100 데이터셋을 활용한다.
Evaluation Metrics: final accuracy를 비교하며, 모든 N개의 태스크 종료 후 모든 과거의 classes의 분류 정확도를 비교한다.
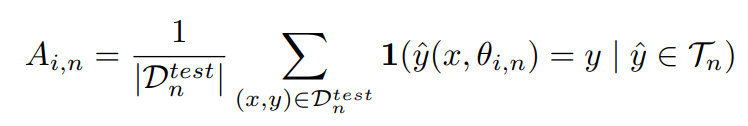
final task accuracy 결과로써, 이 얻어진다. 또한 태스크 라벨이 주어지지 않았을 때, 글로벌 태스크에 대한 성능 평균 감소 측정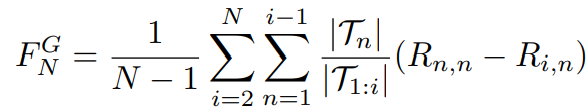
local forgetting을 측정한다.

5.1. Rehearsal-Free Continual Learning
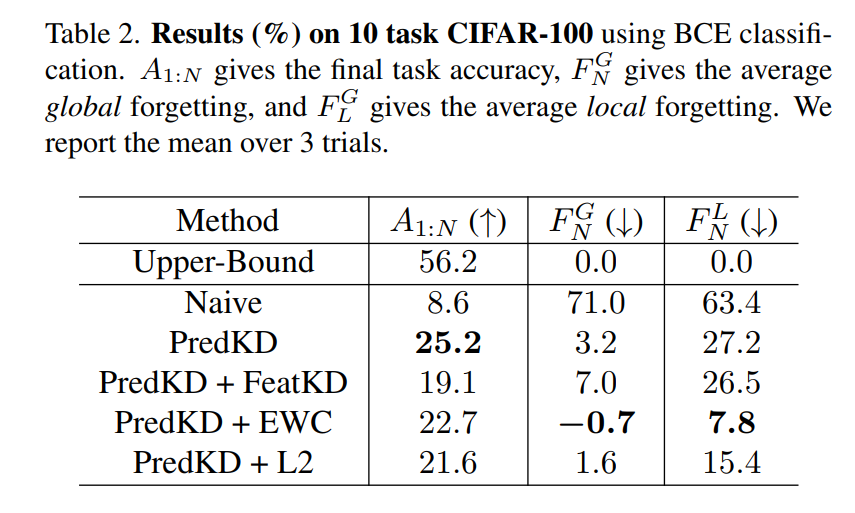
CIFAR-100의 데이터셋에서, 10개의 클래스를 10개의 task로 구성하였다. Table 1b를 보면, EWC 와 FeatKD 모두 소프트맥스와 featKD가 추가가 되었을 때 feature drift를 완화할수 있음을 보였다. BCE와 PredKD를 결합할 때가 가장 성능이 좋았다.

파라미터의 정규화 및 특징 충소가 catastrophic forgetting 에 미치는 영향을 더 살펴보기 위해서 다음과 같은 접근법을 보게 된다.
i) PredKD4, ii) PredKD + FeatFK, iii) PredKD + EWC iv) PredKD + L2
어디에서 잊혀지는지 이해하고자 시간에따른 CKA 유사성을 살표본다. 유사성이 높은 경우가 성능이 좋은 것이다.
이 실험에서는, PredKD가 가장 높은 정확도로 수렴함을 알 수 있다. PredKD+EWC는 가장 낮은 forgetting을 보였다. 이는 다음과 같이 해석이 가능하다.
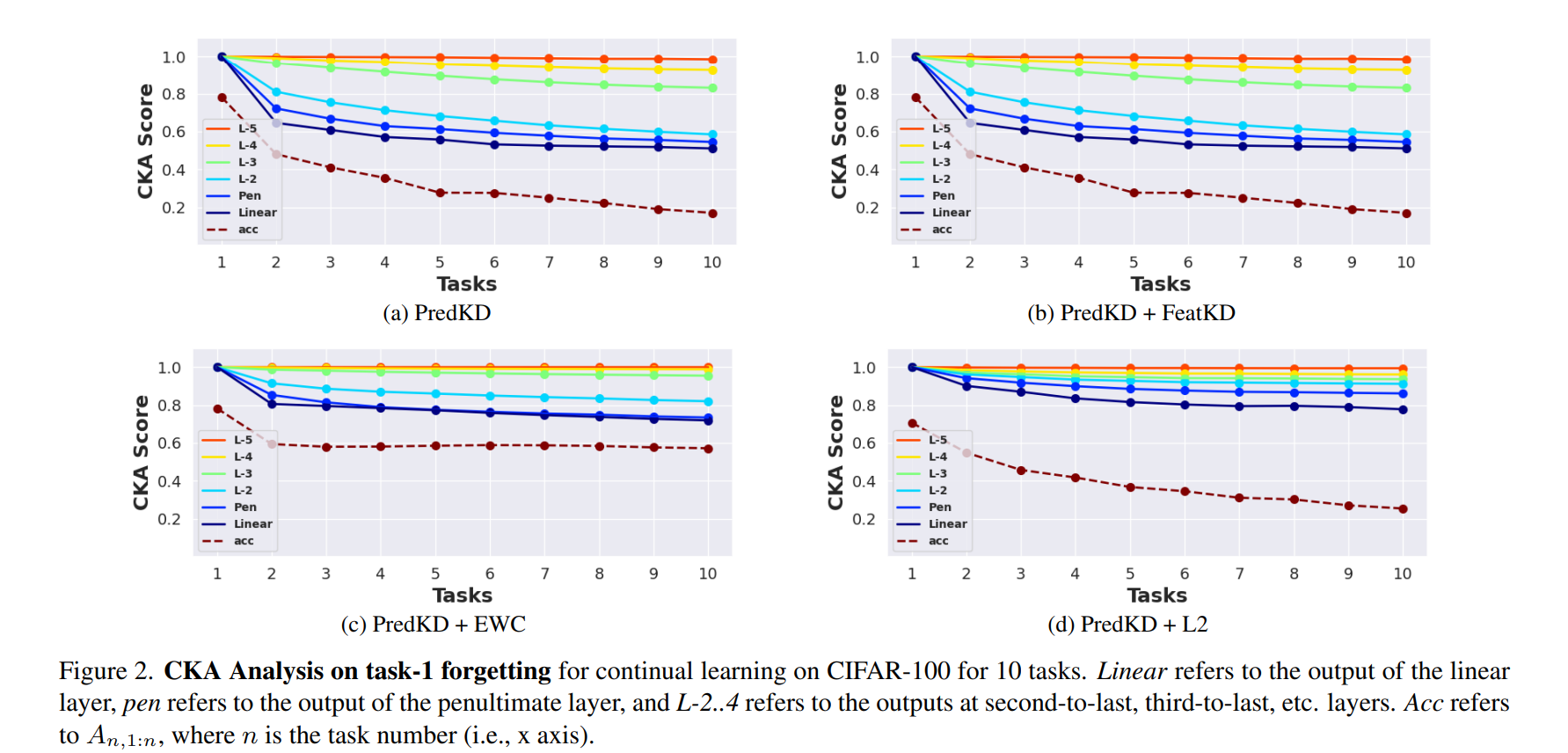 Fig2. 에서는 모든 레이어에서 task 1과 유사성을 유지하는 것과 최종 정확도 간의 트레이드오프를 볼 수 있다. 낮은 forgetting은 새로운 task를 배우는 능력이 저하된다는 의미이다. 따라서 결과는 다음과 같이 정리된다.
Fig2. 에서는 모든 레이어에서 task 1과 유사성을 유지하는 것과 최종 정확도 간의 트레이드오프를 볼 수 있다. 낮은 forgetting은 새로운 task를 배우는 능력이 저하된다는 의미이다. 따라서 결과는 다음과 같이 정리된다.
1. PredKD와 BCE는 리허설 없는 지속적인 학습에 강력한 baseline을 제공한다.
2. 파라미터 정규화를 추가한다면 forgetting 이 감소하지만, plasiticity가 낮아지게 되어 최종 정확도가 낮아지게 된다.
5.2. How to Leverage Pre-Trained Models
리허설 프리 학습과 SOTA간의 GAP은 여전히 크기 때문에 사전 훈련된 모델 활용 방법을 탐구한다.
이에 대한 결과는 다음과 같다.
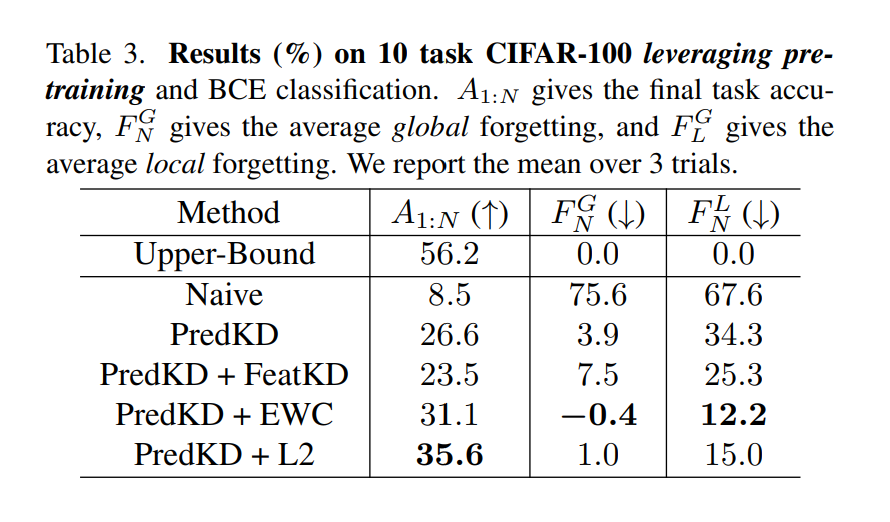
사전 훈련된 상태에서는 이미 새로운 작업이 임베딩된 모델이므로, 새로운 작업에 대한 학습 능력 향상이 크게 필요하지 않다. 따라서 사전 훈련이 없는 시나리오에서 새로운 작업의 성능 저하를 야기했던 방법이 효과적이지 않다. 따라서 PredKD + L2 방법론이 효과적임을 보인다. 즉, 프리트레이닝 방버론은 망각의 영향을 주지는 않지만, 새로운 작업을 학습하는 능력을 향상시키게 된다.
따라서 결과는 다음과 같이 정리된다.
1. 사전 훈련이 있는 경우에는 PredKD와 함께 L2가 가장 우수한 성능을 보이고 파라미터 정규화 없는것과는 더 좋은 성능을 보인다.
2. 파라미터 정규화 방법에서 프리트레인 방법론은 새로운 작업을 학습하는 능력을 향상시키지만, forgetting에는 큰 영향이 없다.
5.3. Context with Current Literature - ResNet
SOTA 방법론과 CIFAR-100 ResNet 백본을 통해서 비교를 수행하였다.

제안 방법론과 SOTA 방법론 모두 둘다 리허설을 위해서 이미지를 저장하지는 않지만, 후자는 이미지를 합성하게 된다. 따라서 결과는 다음과 같이 정리된다.
1. 프리 트레이닝은 SOTA 리허설 방법론인 이미지 합성보다 더 좋은 성능을 보인다.
2. 프리 트레이닝은 2000개의 데이터 코어셋으로 구성된 리허설보다 더 좋은 성능을 보인다.
5.4. Context with Current Literature - ViT
컨티뉴얼 러닝 방법론에서 파라미터 저육화가 프롬프팅보다 더 좋은 성능인지를 보아야 한다. 동일한 위치의 VIT 모델을 수정하는 것을 목표로하여서 실험을 설계한다. ImageNet-R 을 통해서 벤치마크를 수행한다. 이는 기존의 ImageNet과는 다른 문제이다. 따라서 ImageNet-1K 에서 사전 훈련된 VIT-B/16 백본을 사용할여서 파이토치에서 수행하였다. 대부분의 백본을 고정하고, VIT 모델의 셀프 어탠션 블록에서 QKV 프로젝션 행렬을 파인튜닝한다. 이때 컨티뉴얼 러닝 방법 중 정규화를 통해 미세 조정하는 방법과 비슷하게 프롬프팅 방법과 동일한 모듈을 수정하는 것이다.
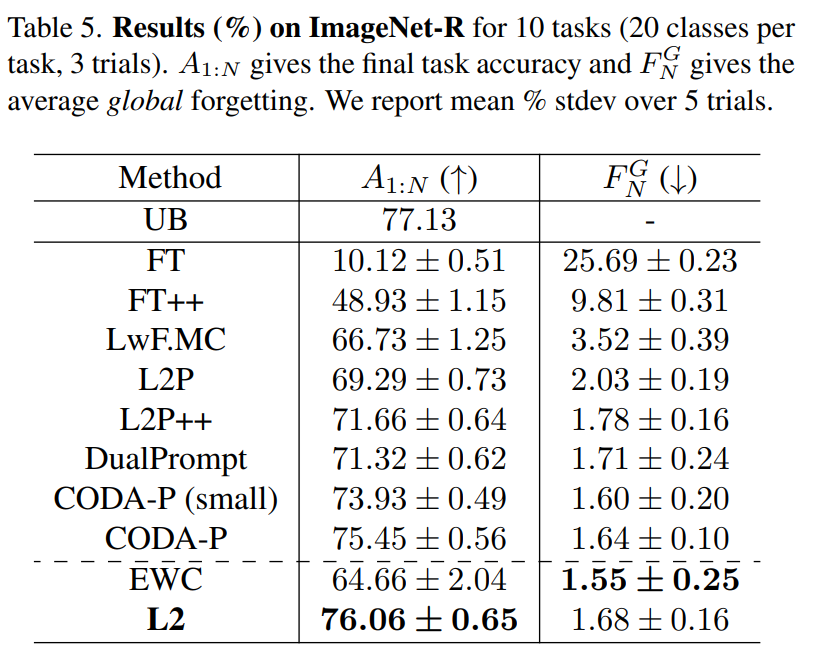
L2는 기존의 방법과 비교하였을 때 유의미한 성능 향상을 얻었으며, EWC는 좋은 성능을 보이지는 못했다. 이는 VIT 셀프 어탠션 블록의 QKV 프로젝션 행렬에 대한 L2 파라미터 정규화를 통한 컨티뉴얼 러닝 방법론이 기존의 프롬프팅을 능가하는 성능을 가졌음을 의미한다.
6. Conclusions
본 연구에서, 몇몇 유명한 컨티뉴얼 러닝 방법론이 리허설 프리 컨티뉴얼 세팅으로 연구되었다. 파라미터 정규화로 L2 혹은 EWC 방법론은 소프트맥스가 classification head 에서 제거된다면 리허설 프리 세팅에서 낮은 forgetting 을 보였다. 하지만 이는 low accuracy를 보였는데 이는 forgetting은 낮지만 새로운 데이터에 대한 학습 능력이 낮아졌기 때문이다. 따라서 프리트레인된 모델을 사용하게 된다면 높은 정확도를 유지하면서도 forgetting을 방지할 수 있음을 보였다. 또한 ViT 트랜스포머를 통해서 L2 파라미터 정규화가 최근 유명한 프롬프팅 방법에 비해 퍼포먼스가 좋음을 확인하였다
