You Only Live Once: Single-Life Reinforcement Learning
Abstract
강화 학습 알고리즘은 정책을 학습하여 태스크를 완수할 수 있게 디자인되었다. 하지만 실제 세상의 태스크에서는 한번의 시도로도 새로운 태스크를 성공적으로 이끌 수 있어야 한다. 예를 들어, 무너진 빌딩에서 물건을 꺼내오는 로봇을 상상해보면, 인간으로부터 직접적인 훈련을 할수는 없다. 한번의 테스트 타임의 시도로부터 물체를 꺼내와야하며 이 중에는 알지 못하는 장애물에 대해서도 인식할 수 있어야 한다. 이러한 문제를 해결하기 위해서 본 연구에서는 single life 강화 학습(SLRL)로 에이전트가 태스크를 한 번의 에피소드를 어떠한 간섭 없이도 이전의 지식을 활용하여 해결할 수 있게끔 제안한다. SLRL 은 낮선 상황에 대해서도 자동적으로 학습할 수 있도록 자연적인 세팅을 제공한다. 이러한 알고리즘은 out-of-distribution state인 세팅에 대해서도 잘 대응하여 강화학습이 수행될 수 있도록 한다. 이러한 observation에 모티베이션을 얻어서, Q-weighted adversarial learning (QWALE) 을 제안하는데, 분포 매칭 전략을 활용하고, 이는 에이전트의 이전 지식을 새로운 낮선 상황에 대해서 어떻게 활용할 것인지를 가이드해준다. 본 연구에서는 몇몇 싱글라이프의 연속적인 컨트롤 상황에 대해서 실험을 하였고, 20~60%의 성공률 향상이 있었다. 이는 낮선 state에 대해서도 빠르게 recover 한다는 장점이 있기 때문이다.
Introduction
실제 세계에서 작동하는 agent는 이전 경험과 다른 새로운 상황에 직면하게 된다. 테스트 시간에 직면하게 되는 광대한 범위의 경험은 훈련 중에 예상할 수 없다. 따라서 새로운 상황에 더 잘 대처할 수 있도록 강화학습이 적용되어왔다. 하지만, RL의 방향은 주어진 작업을 반복적으로 해결할 수 있는 최적의 정책을 학습하는데에 초점을 맞추고 있었다. 바로 즉석 적응을 통한 에이전트는 인간의 개입이나 감독 없이 작업을 한번 완료하는것이 요구된다. 본 연구에서는 이 태스크를 single-life reinforcement learning(SLRL)로 정의한다.
하지만 이 태스크는 어떠한 개입 없이 낮선 상황에 적응해야 하기 때문에 리워드 정보가 공유되지 않고 마지막 end of life에 한번 주어지게 된다. 에피소딕 RL에서는 에이전트가 낮선 state에 있다면 리셋을 통해서 다시 원래 상태로 돌아가게 된다. 반면에 SLRL에서는 이전 지식을 활용하여서 좋은 state 분포를 찾아야 한다. 결과적으로 이전의 프리트레인된 value 함수를 가지고 온라인 RL을 수행하여 파인튜닝을 하는것이 필요하다.
SLRL 설정을 잘 처리하기 위해서는 적응 과정을 유도하기 위해서 즉각적으로 shaped 된 보상을 제공해야 한다. 이는 reward shaping 이라고 하는데, agent의 분포를 이전 경험으로부터 사용하는 것이다. Adversarial imitation learning (AIL)의 GAIL과 같은 방법론은 reward shaping을 제공할 수 있다. 하지만 이러한 방법론은 두가지의 문제점이 있는데, expert demonstaration 이 prior 데이터로 제공되는데 SLRL에서는 suboptimal offline prior 데이터로써 제공된다. 두번째로 AIL 방법론은 에이전트를 prior 데이터의 전체 분포를 학습하도록 하는데, 이것이 optimal 정책이라고 가정하지만 이것이 우리의 세팅에서는 맞지 않는다. 이러한 문제점을 해결하기 위해서 QWAL을 제안하는데, prior data의 다른 state에 대해서 예측된 Q 값에 따라 다른 가중치를 가지고 있는 것이다. 이는 에이전트에게 prior data를 더 높은 값으로 유도하고 이를 통해 태스크 완료에 다다르게 된다.
따라서 본 논문의 컨트리뷰션은 다음과 같다.
1. SLRL 문제 세팅을 정의하고 자연적인 세팅을 통해서 즉각적인 adaptation을 수행하여 낮선 상황에서의 강화학습태스크를 연구한다.
2. reward shaping 을 분포 매칭을 통해 SLRL 태스크를 해결한다.
3. Q-weighted 적대 학습은 이전 데이터의 품질에 대한 민감도가 낮고, 에이전트에게 원하는 작업을 단 한 번 완료하기 위한 shaped 보상을 제공한다.
QWAL이 기존의 분포 매칭 접근 방식과 RL fine-tuning 에 비해 작업의 향상이 있었다. QWALE 은 온라인에서 새로운 변화에 더 잘 적응하고 OOD 환경에서도 잘 회복하는 알고리즘을 개발하기 위한 기준을 제시한다.
Related Work
Autonomous RL : deep RL 에서 에이전트들은 정책이 작업을 여러 번 반복해서 수행할 수 있는 효과적인 정책을 학습하는데 초점이 맞춰져 있다.
Continual RL : 에피소드 재설정 없이 무한한 시간에 걸쳐 평균 보상을 극대화하는 전략이다.
Leveraging offline data in online RL : 기존의 연구되던 태스크들은 작업을 효율적으로 해결하기 위한 정책을 이전 지식을 통해 학습하는 것이다.
Transfer and adaptation in RL : 훈련과 테스트 간의 설정 변화에 적응하는 문제를 연구하였다. SLRL 설정은 에이전트가 고정된 이전 경험 데이터 세트에 엑세스 할 수 있기 때문에 알고리즘적으로 온라인 탐색과 적응에 초점을 둔다. 다른 전이 학습 접근 방식은 정책의 가중치를 새로운 환경이나 작업에 적응시킨다. 하지만 본 연구에서는 단일 에피소드 내 적응에 초점을 맞추고, 에이전트가 실수로부터 자율적으로 복구해야 하기 때문에 챌린지한 설정을 가지고 있다.
Preliminaries
MDP를 통해 강화학습을 수행한다. 본 연구에서 제시한 방법론은 리워드 기반의 RL 알고리즘이긴 하지만, imitation learning 의 컨셉을 활용하여 sparse rewards를 극복한다. 이는 suboptimal한 prior data를 활용함에도 가능하다. AIL을 prior 데이터를 활용하여 전문가의 정책을 복원한다.
GAIL 과 같은 방버론에서는 다음과 같이 stationary distribution과 전문가의 데이터 간의 jensen-shannon divergence를 최소화한다. 이는 다음과 같다.
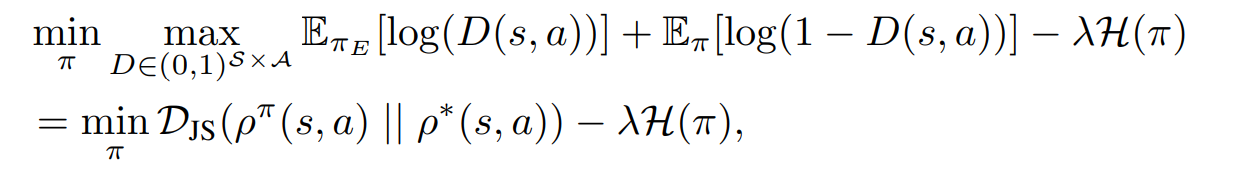
이는 SLRL 문제 세팅에서 demonstration data 없이 수행된다.
Single-Life Reinforcement Learning
SLRL 의 특성은 에이전트가 원하는 작업을 완료하기 위해서 단일 생명이 주어진다는 것이다. 작업이 완료되면 시도가 종료되며 에이전트는 어떠한 인간의 개입 또는 reset이 불가능하다. 완전히 자율적으로 작업을 완료해야 한다.
하지만 이러한 상황은 유용하게 shaped 된 보상을 얻는것이 어렵다. 단일 라이프는 작업이 완료된 후에만 한 번 보상을 받을 수 있다. 그러기 때문에 에이전트가 단일 라이프 동안 pretrained 된 오프라인 prior 데이터에 엑세스 할 수 있게 가정한다. 따라서 에이전트에 대해 관련 환경에서의 prior 데이터를 제공하고 분포 변화가 있는 도메인에서의 단일 라이프를 시뮬레이션한다. 이 과정은 다음과 같은 식을 최대화 하는 것이다.
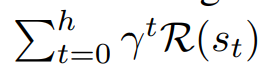
이것들은 마지막으로 성공 state에 다다를 때 까지 sink state들이 없다고 가정한다. 따라서, 자율적으로 어떠한 미스테이크에서도 회복할 수 있어야 한다. 이전의 비슷한 컨셉의 연구가 있었지만, RL exploration 이론에서 연구가 되었던 것이고 본 연구에서의 SLRL은 특정 스페셜 케이스에 대해서 더 제너럴한 regret minimization 프레임워크를 통해서 실제 real-word RL 에 맞는 세팅을 가져간다.
Q-weighted Adversarial Learning (QWALE)
5.1 Algorithm Description
2가지 측면을 고려해야 한다. 첫번째는 에이저트가 이전 데이터의 분포로 이끌려 가는 것이고, 에이전트가 OOD에 빠졌을 때 복구하는데 도움이 된다. 또 하나는 작업 완료로 이끄는 것이다.
GAIL은 전문가의 상태-행동 분포를 향상시키는 프레임워크를 제안한다. 전문가의 분포와 가까워지도록 한다. 하지만 SLRL에서는 이 가정을 완화한다. 품질이 낮은 오프라인 이전 데이터에만 접근할 수 있을 수도 있기 때문이다. 따라서 이전 데이터의 품질에 관계 없이 알고리즘을 수행할 수 있는 이전 데이터의 전체적인 상태-행동 분표를 균일하게 일치시키는 정책을 학습하는 방향이 아닌, 작업 완료로 이끄는 상태-행동 pair를 일치시키고자 한다.
이전 데이터의 상태-행동 분포를 일치시키는 문제는 확률적 최적 제어에서 연구되어 왔다. 이 문제는 RL 문제로 프레임되고 추가 제약 조건이 포함된다. 최적화 문제의 해결책은 원하는 목표 상태-행동 분포가 특정 형태를 가진다는 것이다. 이것을 바탕으로 적절한 정책을 유도할 수 있다.
QWAL는 DJS를 최소화하는 것으로, 목표 분포와 현재 정책의 분포를 가깝게 만들어주는 방법이다.
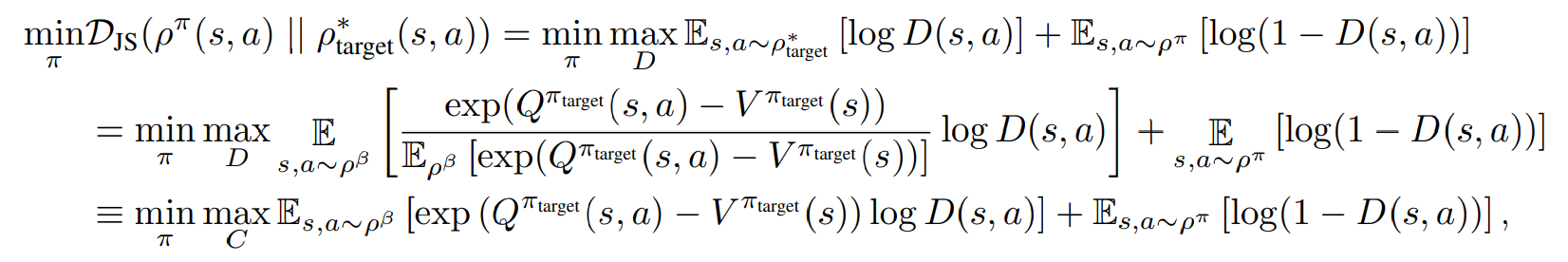
따라서 QWALE은 소스 MDP에서 Q 함수를 사용하여 discriminator를 훈련한다. Q 함수는 RL 사전 훈련을 통해 얻을 수 있고 학습에서는 이를 활용한다. 이러한 방식으로 QWALE은 AIL을 전체적인 설정에 적용하여 이전 데이터에도 적용이 가능하다.
가중 discriminator의 훈련 과정의 목표는 에이전트를 현재 상태보다 더 나은 결과를 이끌 것으로 기대되는 상태로 discriminator를 변화시키는 것이다. Q 함수는 특정 상태가 높은 보상으로 이어질 것이기 때문에 시간에 따라 얼마나 바람직한 상태인지를 추정하는데 자연스러운 선택이다. 판변라에서 예제를 가중화하는데 Q값의 사용은 판별자가 목표에 더 가까운 상태를 선호하게 만든다. 최적 정책을 단순히 모방하는 것과는 다른 동작이다. 최적 경로를 따라 모든 전환에 동등한 가중치를 부여할 것으로 예상되는 동작과는 다르다.
5.2 Practical Implementation
SAC 알고리즘을 통해서 maximum entropy off-policy RL를 통해 우리의 목적식을 최적화하였다. 이는 다음과 같은 weighted 된 loss식을 사용하였다.
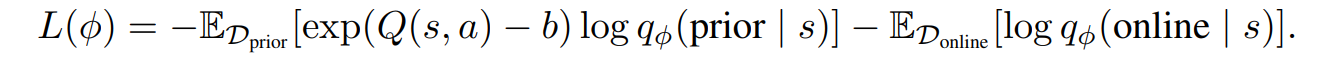
discriminator는 보상을 수정하는데 사용되며 off-policy를 업데이트 하는 과정에서 사용된다. 하나의 trail test time 에 대해서 액터와 크리틱은 pretreained weight 을 통해서 초기화가 되며, 리플레이 버퍼가 오프라인 데이터를 통해서 초기화된다. 그리고 다음과 같은 알고리즘을 통해서 실험이 진행되었다.

Experiments
6.1 Experimental Setup
Environments :
대상 환경은 시작 위치가 이전 데이터에서 본 적이 없는 새로운 위치이다.
pointmass 설정은 에이전트가 2D에서 시작 위치인 원점(0,0) 에서 점(100,0) 으로 이동하는 것을 목표로 한다. 강한 바람이 있기 때문에 y값을 위로 올리는 동적 변화가 있다.
장애물이 포함되어 있다.
franka-kitchen 환경에서 평가를 진행한다.
Comparisons :
QWALE를 세 가지 대안적 방법과 비교한다. a) SAC 세부 튜닝은 소스 설정에서 정책과 가치 함수를 사전 훈련한다. b) SAC-RND 에서는 단일 라이프 세부 튜닝중에 추가로 RND explorer 보너스를 포함한다. c) GAIL-S 는 discriminator가 현재 상태 s에만 작동한는 생성적 적댇적 모사 학습을 실행한다. 본 연구에서는 discriminator가 현재 상태만 살펴보도록 선택하여 소스 데이터와 대상 환경 사이의 동적 변화에 덜 민감하도록 한다.
Prior datasets :
우리는 소스 MDP 에서 표준 에이포소드 RL 설정에서 SAC를 실행하고 마지막 50000개의 전환을 이전 데이터로 취급한다. SLRL에는 소스 MDP의 이전 데이터만 있다면 에피소드 RL을 실행하지 않아도 된다.
Evaluation Metrics :
방법 평가를 위해서 10개의 시드를 기반으로 작업 완료 전에 걸린 평균 및 중앙값 단계와 표준 오차, 성공률을 본다. 단일 라이프 RL 동안 모든 환경에서 에이전트에게는 작업을 완료하기 위해 200,000 단계가 주어딘다. 20만 단계 후에도 작업을 완료하지 못한다면 실행이 실패로 기록된다.
6.2 Results using mixed data as prior data
QWALE이 네 가지 도메인 모두에서 가장 낮은 평균 및 중앙값 단계 수, 가장 높은 성공률을 나타냈다.
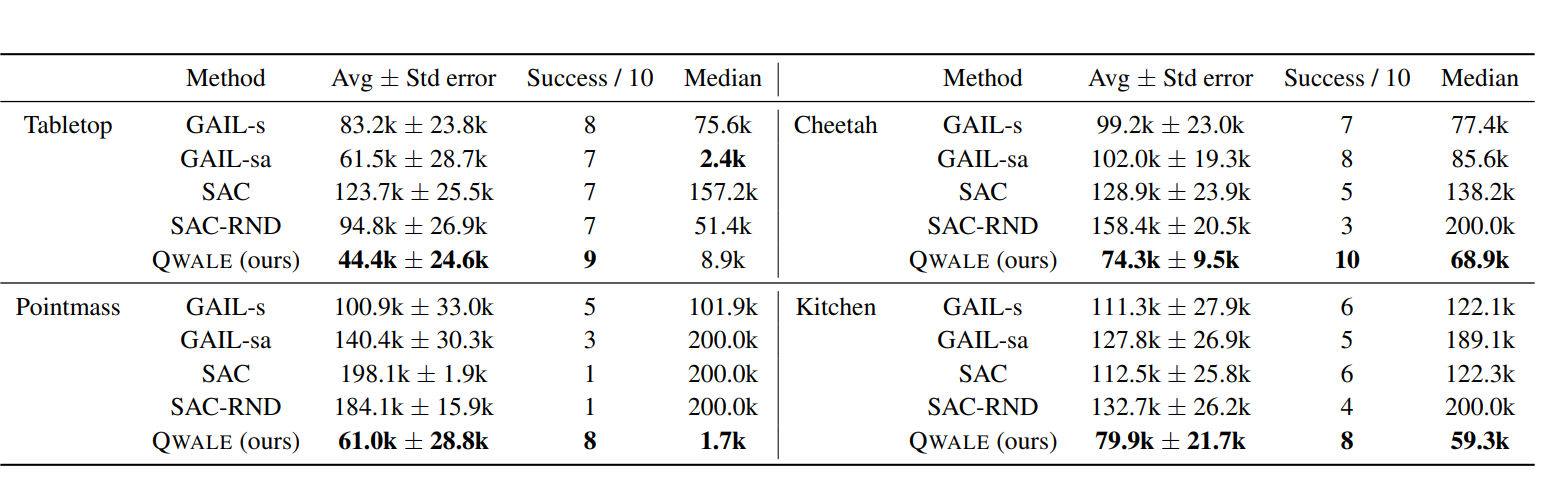
특히 2번째로 높은 방법론보다도 20~40%의 성능 향상이 있었다. RND는 일부 도메인의 성능을 향상시킬 수는 있지만, QWALE 만큼 잘 적응시킬 수 없고, 탐사를 증가시키는것만으로는 충분하지 않다. 이러한 결과는 판별자를 훈련할 때 이전 데이터를 Q 값을 가중화하는 추가적인 형태가 목표로의 안내를 크게 개선함을 보인다.
6.3 Recovering from novel situations in SLRL
SLRL의 주요 도전 과제는 에이전트가 분포에서 벗어나면 재설정을 할 수 없다는 것이다. 소스 및 타겟 도메인 간에 차이가 있기 때문에 에이전트는 이전 데이터에서 분포 밖인 상태에 처하게 된다. 소스 데이터에서 사전 훈련된 가치 함수는 상태를 평가하고 에이전트를 좋은 상태로 안내하게 된다. 하지만 이전 데이터를 벗어난 경우에는 정확하지 않다. 따라서 온라인 RL을 통해서 사전 훈련된 가치 함수를 세부 조정하는 것은 에이전트가 다시 돌아가도록 유도하지는 않는다. 특히 sparse 한 보상 함수인 상황에서 더 그렇다. 따라서 분포 일치 방법인 QWALE는 분포에 따라 보상을 높여 다음과 같이 시각화하였다.
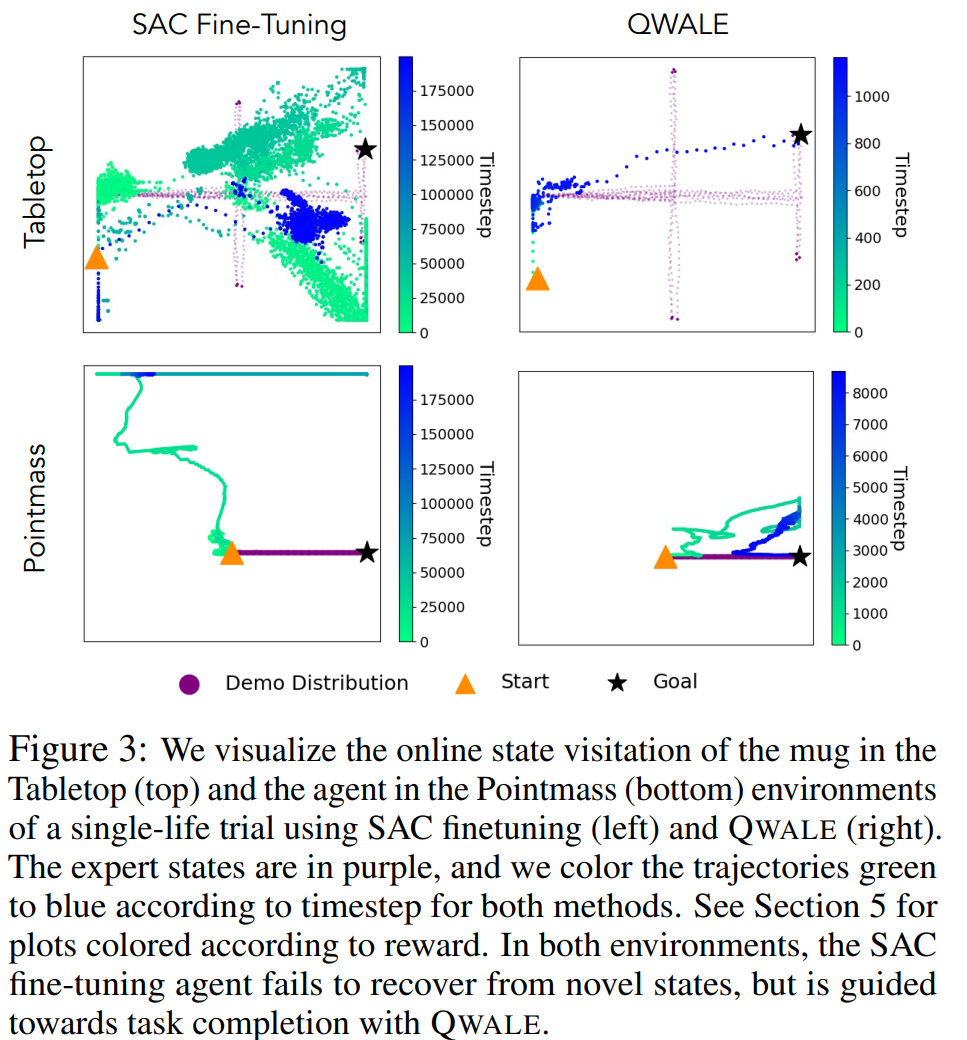
타임스텝에 따라 궤적을 나타내게 되면 보상과 매우 큰 상관관계를 보임을 알게 된다. 보상이 에이전트가 생소한 상태에서 회복하고 목표를 점진적으로 안내하는 방법을 알려준다. 에이전트가 OOD일때 에이전트는 이전 상태 분포로 더 가까이 이꿀어주는 상태를 탐색하도록 이끌어주며, 분포 내에 존재할 때에는 목표로 가까운 상태로 이동하도록 장려받아서 효율적인 작업 완료를 이룰 수 있도록 한다.
6.4 Using demos as prior data
SLRL 문제 설정에서 다양한 discriminator 기반의 접근 방식의 성능을 평가한다. 여기서는 데모 데이터가 이전 데이터로 사용 가능하다. 이전 데이터 수집 시 표준 RL을 사용하여 사전 훈련된 동일한 Q 함수에 대해서 액세스 할 수 있지만, 시험 시 사전 훈련된 정책 및 크리틱가중치로 어떤 알고리즘도 초기화시키지는 않는다.
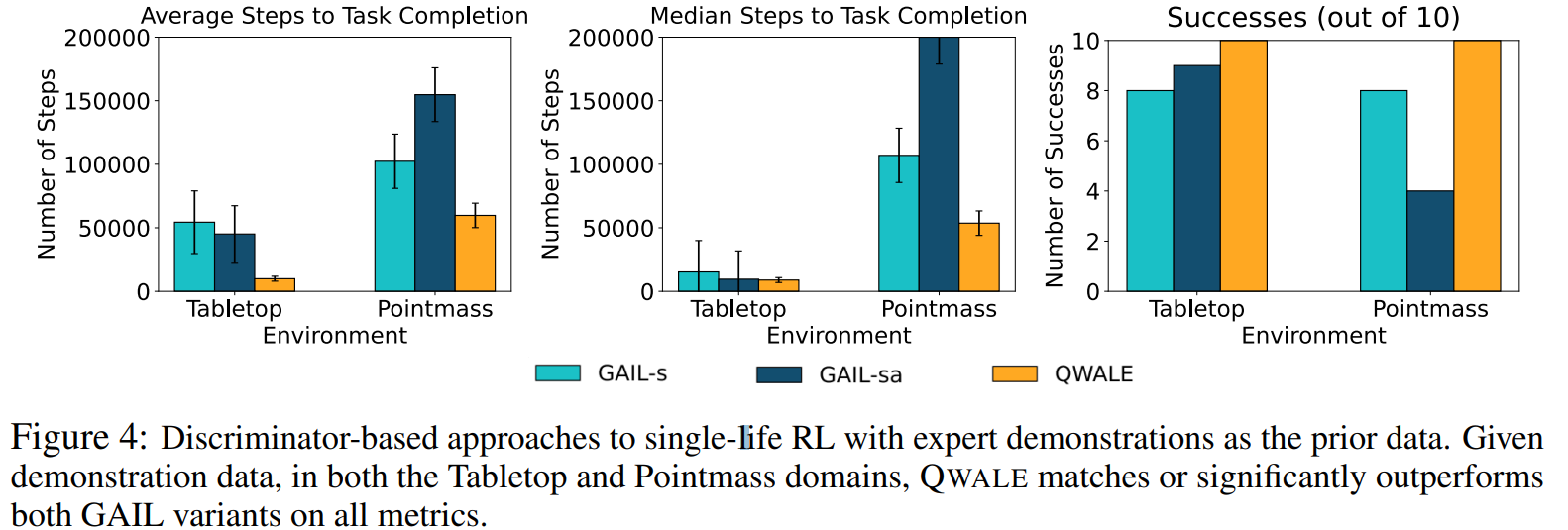
GAIL 변형은 모두 도메인에서 작업을 해결할 수 있지만, GAIL-SA의 경우에는 특히 성능이 좋지 못하다. 두가지 GAIL 변형과 비교하여서 AWALE는 두 도메인 모두에서 성능이 좋았다. 이러한 결과는 원하는 작업의 완료를 향한 보다 구체적인 보상 형성이 데모를 이전 데이터로 사용하는 경우에도 SLRL 설정이 도움이 될 수 있음을 보인다.
Conclusion
본 연구에서는 single-life 강화학습에서의 문제 세팅에 대해서 정의하고 연구하였다. 이는 한번의 시도로 자율적으로 태스크를 이전의 지식을 활용하여 완료할 수 있어야 한다. 기존의 RL의 파인튜닝을 수행하면 이러한 낮선 환경 문제에 대응이 어려웠다. 우리는 이러한 문제가 에피소딕 RL에서는 리셋을 통해서 다시 시작할 수 있지만, 우리의 태스크에서는 이러한 가정이 불가능하기 떄문임을 이야기하였다. 관련된 이전 데이터와의 분포를 정렬하는 것은 reward shaping 을 통해서 에이전트가 문제에 직면했을때 회복하는것을 돕는다. 우리는 이를 QWALE로 정의하여서, Q값을 통해서 가중치를 주어 분포 매칭 방법론에서 더 이전 데이터를 효과적으로 활용하여 sinlge-life RL 태스크에 활용하였다.
QWALE가 효과적으로 타겟의 태스크를 한번의 에피소드를 어떠한 간섭없이도 효과적으로 수행할 수 있었지만 중요한 한계점이 있다. QWALE를 포함하여 어떤 알고리즘이든 100%의 성공을 달성할 수는 없었다는 점이다. 이를 해결하기 위해서 향후 연구에서는 지속적으로 성공할 수 있는 정책을 학습해야 한다. 마지막으로 실험 도메인의 다양성을 늘려야 한다. 소스와 타겟 MDP 간의 reward 와 state space가 같았지만, 이것이 일치하지 않는 경우에도 수행이 성공적으로 이루어져야 한다.
