DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
Abstract.
컨티뉴얼 러닝은 하나의 모델로 태스크의 시퀀스를 catastrophic forgetting 없이 학습하기 위한 방법론이다. 이러한 방법은 리허설 버퍼를 두어서 이전 예시를 저장하고, exerience replay를 통해서 수행되는데, 프라이버시 문제와 메모리 한계때문에 이러한 방법은 문제가 된다. 따라서 본 연구에서는 심플하지만 효과적인 프레임워크인 DualPrompt를 제안한다. 이는 파라미터의 작은 set인 prompt가 적절하게 사전학습된 모델을 인스트럭트하여서 태스크를 학습하고 이전 examples의 버퍼링없어도 태스크가 순차적으로 도착하는 상황에서도 효과적으로 모델이 학습되도록 한다. 듀얼 프롬프트는 사전학습된 백본의 프롬프트를 보완하는 프롬프트를 붙이는 것인데, 이를 통해서 태스크 invariant하고 태스크-specific 한 instructions를 제공하기 위한 것이다. 검증 실험을 위해서 DualPrompt 는 지속적으로 SOTA 퍼포먼스를 class incremental 세팅에서 효과적임을 보인다. 특징적으로 DualPrompt는 큰 리플레이 버퍼를 가지고있는 최근의 컨티뉴얼 러닝방법론보다 좋은 성능을 보였다. 또한 더 챌링징한 벤치마크를 제안하는데 Split ImageNet_R이다. 이는 리허설프리한 컨티뉴얼 러닝 연구에 활용될 것이다.
1. Introduction
CL은 하나의 모델로 catastrophic forgetting을 막는것이다. 기존의 방법론들은 task-incremental learning을 고려할때 대부분 과도하게 단순화를 하여서 task identity가 클리어하지 못한 실제 상황을 반영하지 못한다. 우리의 연구는 더 어려운 class incremental setting을 unknown test-time task identity를 가진다.
리허설 기반의 CL 방법론은 데이터를 이전의 테스크로 부터 리허설 버퍼에 저장하게 된다. 이 방법론들은 SOTA 방법론이지만 이러한 버퍼에 의존하는것은 버퍼 사이즈에 민감하며, 상대적으로 큰 버퍼로 모델을 학습하는것이 공통적인 문제이다. 이러한 방법론들은 privacy 문제가 있으며 또한 메모리 비용이 증가하게 된다. 따라서 리허설 프리 컨티뉴얼 러닝 방법론이 고차원 데이터에서 비슷한 성능을 내는것이 바람직하다.
최근 방법론으로는 Learning to Prompt (L2P) 방법론이 새로운 관점으로 제시되었다. 러너블 프롬프트 파라미터를 활용하여 지식을 효과적으로 인코딩하기 때문에 버퍼가 더이상 필요가 없어지게 된다. 프롬프트 기술은 NLP의 task adaption을 위해서 설계가 되었다. 이것은 고정되거나 학습가능한 instructions를 사전학습된 큰 모델에 부착함으로써 작동된다. 이 과정을 통해서 새로운 데이터로 representation을 학습하는것 보다는 학습된 representations를 효과적으로 재사용한다. L2P는 리허설 프리 컨티뉴얼 러닝의 획기적인 방법론이지만, 아직까진 리허설 기반의 모델보다는 좋은 성능을 보이지 않는다.
L2P에서 하나의 단일 프롬프트 풀이 설계되어 각 작업 간의 공통 기능과 각 작업 별로 고유한 기능을 구별하지 않고 지식을 전달하게 된다. 이러한 설계는 complementary learning system(CLS)관점에서 sub-optimal이다. CLS는 2개의 learning system의 시너지를 통해 제안하는데, 인간의 학습 시스템 이론을 따른다. 뇌의 해면체는 특정 경험에서 패턴 분리 표현을 학습하는데 초점을 두고 있으며, Neocortex는 대뇌피질로 과거 경험 순서에서 일반적인 전이가능한 표현으로 학습하는데 초점을 두고 있다. 따라서 인간은 작업별 지식을 간섭 없이 별도로 학습하면서 작업불변 지식을 활용하여 미래 작업을 더 잘 학습할 수 있다. 이전의 CLS 기반의 방법론들은 두 종류의 지식을 배우기 위해 백본 매개변수를 분리하거나 확장한다. 따라서 이전에는 리플레이 버퍼를 반복적으로 구성하여서 catastrophic forgetting을 방지하였다.
본 논문에서는 General-prompt와 expert-prompt 의 두 가지의 프롬프트를 제안한다. 이중 프롬프트는 고차원의 프롬프트 스페이스를 분리하는데 하위 수준의 잠재적 표현 공간에 중점을 두는 기존의 방법론보다 효과적이다. 그리고 또한 어떻게 두 종류의 프롬프트를 attach 할 지 탐색하는 것이 백본 모델을 학습알 때 forgetting을 줄이고 효과적인 지식 공유를 할 수 있게 하여 학습의 효과를 향상시키게 된다.
또한 Split imageNet-R 이라는 CL 벤치마크 데이터를 소개한다. 각 작업에서의 클래스 내 다양성이 크기 때문에 작은 버퍼는 지난 경험을 충분히 나타내기 어렵다. 심화된 방법조차도 잘 수행되기 위해서는 큰 버퍼가 필요하다. 듀얼 프롬프트는 replay buffer를 사용하지 않고도 우수한 성능을 보이게 된다. 따라서 본 연구는 다음과 같은 컨트리뷰션이 있다.
1. 단순하고 효과적인 리허설프리한 CL 방법론을 제안하여, G-프롬프트와 E-프롬프트를 통해서 태스크인베리언트, 태스크스페시픽한 지식을 전이하게 된다. 이 방법론은 간단하여서 어떤 데이터나 메모리의 access 없이도 실제 상황의 CL 시나리오에 적합하다.
2. 듀얼 프롬프트는 다양한 디자인 초이스를 탐색하게 되는데 2가지의 프롬프트를 사전 학습 모델에 통합하게 된다. 처음으로 emprically 하게 적절하게 백본 모델에 프롬프트를 attaching 하는 것이 CL에 큰 효과를 나타냄을 보였다.
3. 새로은 CL 벤치마크를 제안한다. Split ImageNet-R으로, 이러한 방법을 validate 하는데 도움이 된다. DualPrompt는 새로운 SOTA 방법론으로, 상대적으로 큰 버퍼 사이즈를 갖는 리허설 기반의 방법론보다 퍼포먼스가 조핟.
2 Related work
Continual learning
Regularization-based methods : catastrophic forgetting을 중요한 파라미터를 정규화 함으로써 새로운 태스크 학습시에 제한하게 된다. 아직은 class-incremental 상황이나, 더 challenging 데이터셋에 대해서는 만족스럽지 않다.
Architecture-based methods : 이 방법론은 isolated된 파라미터를 할당한다. 이러한 방법론은 모델 확장, 모델 분리로 나뉘게 된다. 이러한 방법론들은 대부분 task-incremental setting에는 대응이 어렵다. 그러나 DualPrompt는 pre-trained된 트랜스포머 기반의 모델에 집중한다. 또한 아키텍처 기반의 방법론은 대부분 상당한 추가 파라미터를 model seperation을 위해 필요하게 된다. 반면에, DualPrompt는 추가적인 파라미터가 무시될만하다.
Rehearsal-based methods : 학습된 데이터를 리허설 버퍼에 저장하여서 현재 태스크를 학습하는것이다. 이러한 방법론이 꽤 간단한 아이디어 같지만, class-incremental setting에서는 매우 효과적이다. 몇몇 리허설 기반의 방법론들이 SOTA 퍼포먼스를 보였다. 그러나 리허설 기반의 방법론들은 버퍼 사이즈에 많이 의존하게 되며 데이터 프라이버시 문제에서 자유롭지 못하다. 본 연구의 DualPrompt 는 이러한 기존의 문제를 리허설 프리 관점으로 해결하고, 프리트레인 모델을 효과적으로 활용한다.
Prompt-based learning
NLP 분야에서 최근에 뜨고 있는 전이학습 방법론으로 Prompt based learning이 있다. 이는 모델의 컨디션을 주가위한 고정된 함수가 존재하며, 자연어 모델이 추가적인 정보를 통해서 다운스트림 태스크를 수행할 수 있게 된다. 하지만, 이러한 프롬프팅 함수는 아주 다루기 어렵고 휴리스틱하다. 따라서 최근의 연구는 프롬프트를 러너블 파라미터로 두어서 최근의 전이학습에서 우수한 성능을 보였다. 프롬프트는 태스크 specific 지식을 적은 파라미터로 획득이 가능하다. 그러나 DualPrompt는 CLS에서 영감을 받아 사전 훈련된 백본에 보완 프롬프트를 첨부하여 태스크별 지식사이의 보완적프롬프트를 학습하는 다른 접근 방식을 제안한다. DualPromptsms L2P보다 우수한 성능을 보인다.
3 Prerequisites
3.1 Continual learning problem setting
태스크 바운더리가 클리어하고, 태스크 스위치가 학습 시간에 갑자기 일어난다고 가정한다. class-incremental learning을 가정한다. 태스크의 identity가 테스트 시간에 각각 알려지지 않는다고 가정한다. 또한 이전 연구 세팅에 따라 ViT로 ImageNet을 학습한 사전학습모델이 이용가능하다. 이저느이 리허설 기반의 방법론들과는 다르게, 어떠헌 리허설 버퍼를 요구하지 않는다.
3.2 Prompt-based learning
프롬프팅 기반 학습은 전이 학습을 위해서 자연어 처리에서 처음 제안되었다. 프롬프팅의 주요 아이디어는 사전 훈련된 모델에 대한 추가 지시를 추가하여서 다운스트림 태스크를 컨디션으로 수행하는 것이다. 최근 등증한 기술로 프롬프팅 튜닝은 언어 모델에 대한 프롬프트 매개변수 세트를 추가하여서 다운스트림 NLP 작업을 수행하기 위해 언어 모델을 활용한다. 일반적으로는 모델의 예측을 지시하기 위해서 입력 시퀀스 앞부분에 추가된다.
비전분야에서 ViT 기반의 시퀀스 모델을 사용한 프롬프트 튜닝은 다음과 같다.
인풋 임베딩 레이어는 인풋 이미지를 시퀀스와 같은 아웃풋 특질를 추출한다. L은 시퀀스 길이이며, D는 임베딩 차원이다. 다운스트림 태스크를 수행할 떄, 사전학습된 백본은 계속 프론하며 이를 general feature extractor라고 한다. 그리고 프롬프트 파라미터들은 p라고 하며 마지막으로 extended feature는 classification task를 수행한다. 프롬프트는 고차원의 instruction을 인코딩하는 라이트웨이트 모듈이라고 생각하면 되고, 이것을 통해서 백본을 사용하여서 사전훈련된 representation에서 다운스트림 태스크를 수행하게 한다.
4 DualPrompt
제안된 모델은 DualPrompt로 다음과 같이 요약된다.
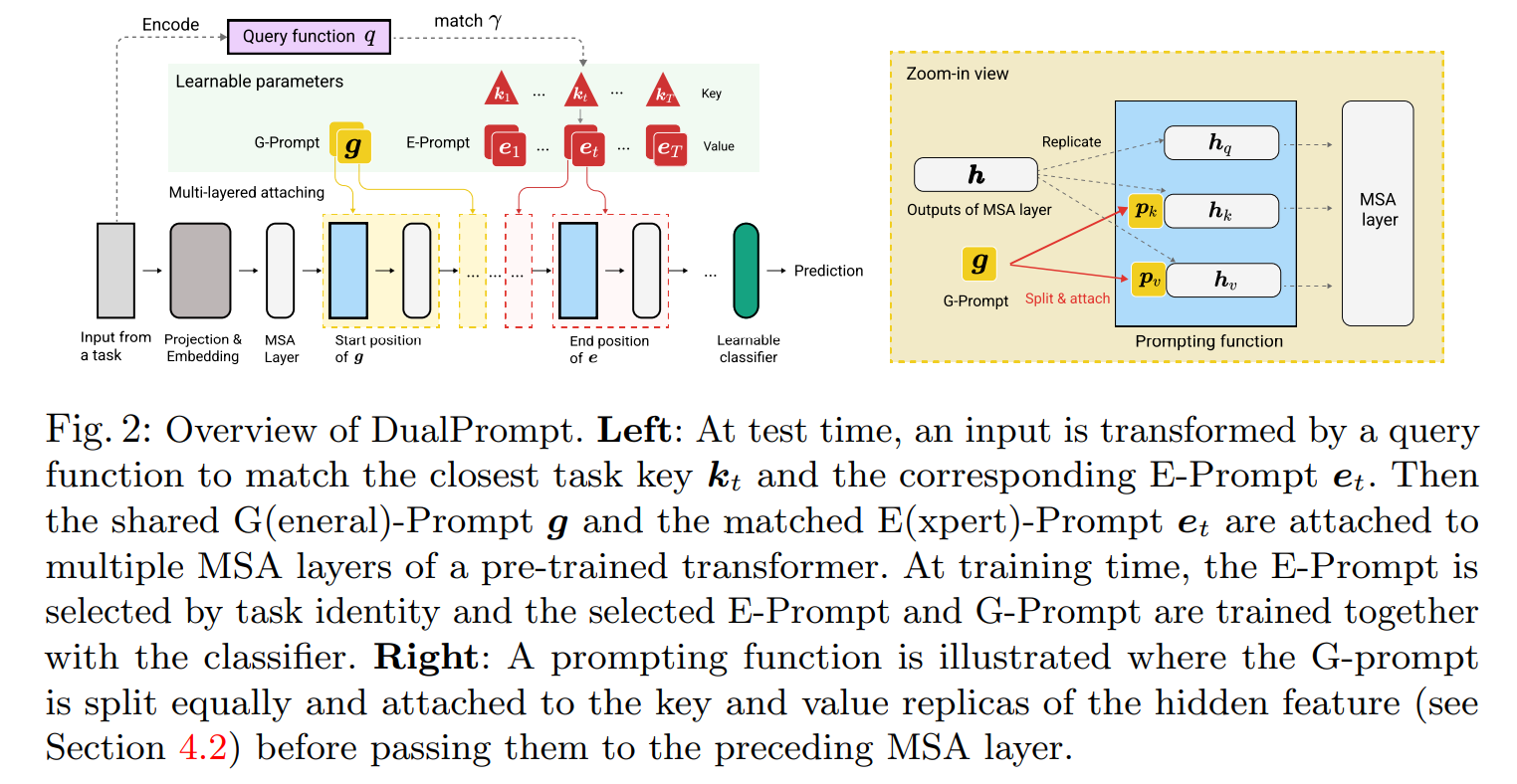
4.1 Complementary G-Prompt and E-Prompt
사전학습된 ViT 를 개의 MSA 레이어로 주어졌을 때, 다음과 같이 두개의 프롬프트로 정의가 가능하다.
G-Prompt : i번째 MSA 레이어에 G-Prompt를 attach 하려고 하므로, 다음과 같이 나타난다.
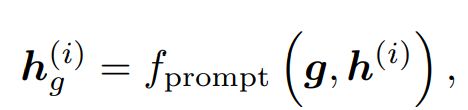
E-Prompt: E=는 태스크 dependent한 파라미터의 셋이므로, 시퀀스 길이에 대해서 같은 임베딩 차원 D를 갖고, 토탈 넘버 T개를 갖는다. t-th task 인풋 예시를 들면, E-prompt를 j-th MSA 레이어에 attach 하기 위해서 비슷하게 수행이 된다.
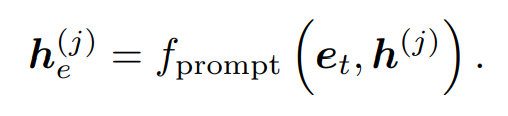
또한 입력 인스턴스의 특성과 일치하도록 로스식으로 매칭하여 해당 키를 업데이트하낟. 가 따라서 t번째 태스크를 다른 키보다 더 가깝게 되도록 한다. 테스트 타임에서는 시험 샘플에 대해서 쿼리 함수 q를 채택하여서 작업 키에서 최적의 일치 항목을 검색하고 해당 E-Prompt를 선택하여 사용한다. 추가 구성 요소를 도입하여 다양한 일치 및 쿼리 전략을 설계하는것은 CL에서의 parsimony의 원칙을 위반하는 것이다. 사전 훈련된 전체 모델을 쿼리함수로 활용하게 된다. 따라서 토큰에 해당하는 특성 벡터를 코사인유사도를 통해 얻게 된다.
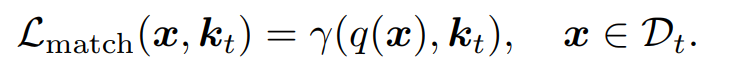
테스트 예제 x가 있다고 하면, 간단하게 최고로 매치되는 태스크 키 인덱스를 찾는다. 매칭 로스와 상응하는 쿼리 매커니즘을 통해서 벤치마크데이터셋에 대해서 작동하는것을 보였다.
4.2 Prompt attaching: where and how?
G 및 E 프롬프트는 훈련 중에 백본과 함꼐 각각 instruments를 인코딩하고 추론 시 모델에서 예측이 지시하게 된다. 우리는 그것을 어떻게 단일 MSA레 이어에 첨부하는지 4.1에서 다루었ㄱ다. 그러나 대부분의 기존 프롬프트 관련 작업은 단순히 첫 번째 MSA에만 프롬프트를 배치하거나, 모든 MSA 레이어에 대치하게 된다. 따라서 어디에 어떻게 프롬프트를 attach 할지가 매우 중요하다.
Where: Decoupled prompt positions. 직관적으로 백본의 다른 레이어는 다른수준의 특성 추상화를 갖기 때문에 순차적으로 작업을 학습할 때 일부 표현 레이어는 다른 표현 레이어에 비해 작업별 지식에 더 높은 반응을 보이게 된다. 작업 불변 지식에 대한 반응이 반대로 높을 수 있다. 두 종류의 프롬프트는 이를 가장 적절한 위치에 분리된 방식으로 첨부할 수 있도록 해야 한다. 따라서 서로 다른 instruments를 통해 해당 표현과 효과적으로 상호작용이 가능하다.
따라서 attach 되는 레이어를 다음과 같이 표기하게 된다.
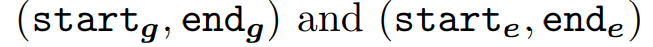
이들은 MSA 레어이가 간단히 연속된다는 가정을 한다. 또한 완전히 다르거나 겹칠수도 있다.
How: Configurable prompting function
프롬프트 함수는 프롬프트를 임베딩피처와 결합하는 방법을 제어한다. 고수준 지침이 저수준 표현과 상호 작용하는 방식에 직접적으로 영향을 준다. 우리는 잘 설계된 프롬프트 함수가 전체적인 CL 학습 성능에 영향을 주게 된다. 프롬프트 함수를 적용하는 것은 MSA 레이어의 입력을 수정하는것이다.
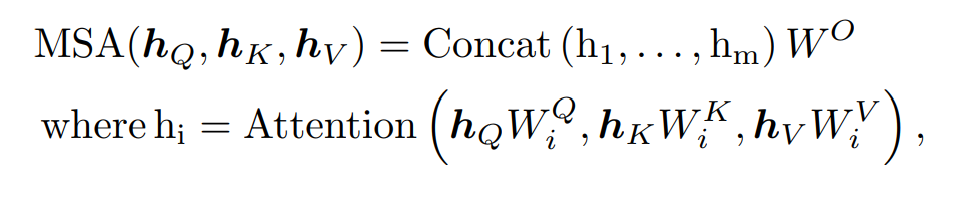
Prompt tuning은 프롬프트 입력 토큰에 선행하여 추가하는 것으로 동일한 프롬프트 매개변수 p를 hQ,hk,hV에 연결하는 것과 동일하다. 이는 출력 길이를 증가시키게 되는데 이 작업은 class가 첫 번째 MSA 레이어에 추가되는 방식과 동일하다.
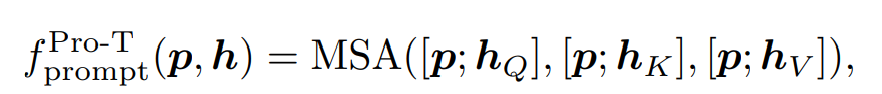
Prefix Tuning 은 프롬프트 p를 Pk,Pv로 분할하고, hK와 hV에 선행하여 추가하는 것으로 hQ는 그대로 유지한다. 이를 통해서 출력 시퀀스의 길이는 h와 동일하다. 이 두가지 버전을 통해서 실험적으로 연구하고 CL 관점에서의 성능 차이를 이후에 논의한다.
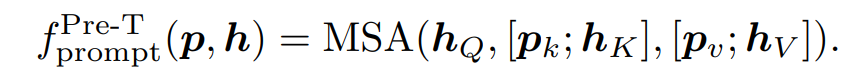
4.3 Overall objective for DualPrompt
프롬프트 를 attached 된 아키텍처를 제안한다. t번째 태스크에서의 인풋 x를 f함수를 통해 변환을 하게 된다. 그리고 classifcation head 에 보내 예측을 하게 된다. 마지막으로, 두가지 프롬프트, 태스크 키들, 그리고 새롭게 초기화된 classification head 에 대해서 엔드 투 앤드로 다음과 같이 나타낸다.
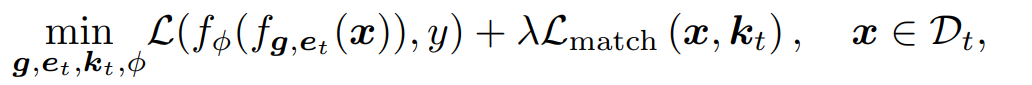
5 Experiments
5.1 Evaluation benchmarks
Split ImageNet-R. Split CIFAR-100. 두 가지를 활용한다.
5.2 Comparison with state-of-the-arts
Comparing methods.

DualPrompt를 regularization, rehearsal, promt-based 방법론과 비교하였다. 듀얼 프롬프트는 다른 방법론들에 비해서 항상 성능이 좋았다. 즉, DualPrompt는 어떠한 버퍼데이터 없이도 더 좋은 퍼포먼스를 보였다.
Architecture-based methods.
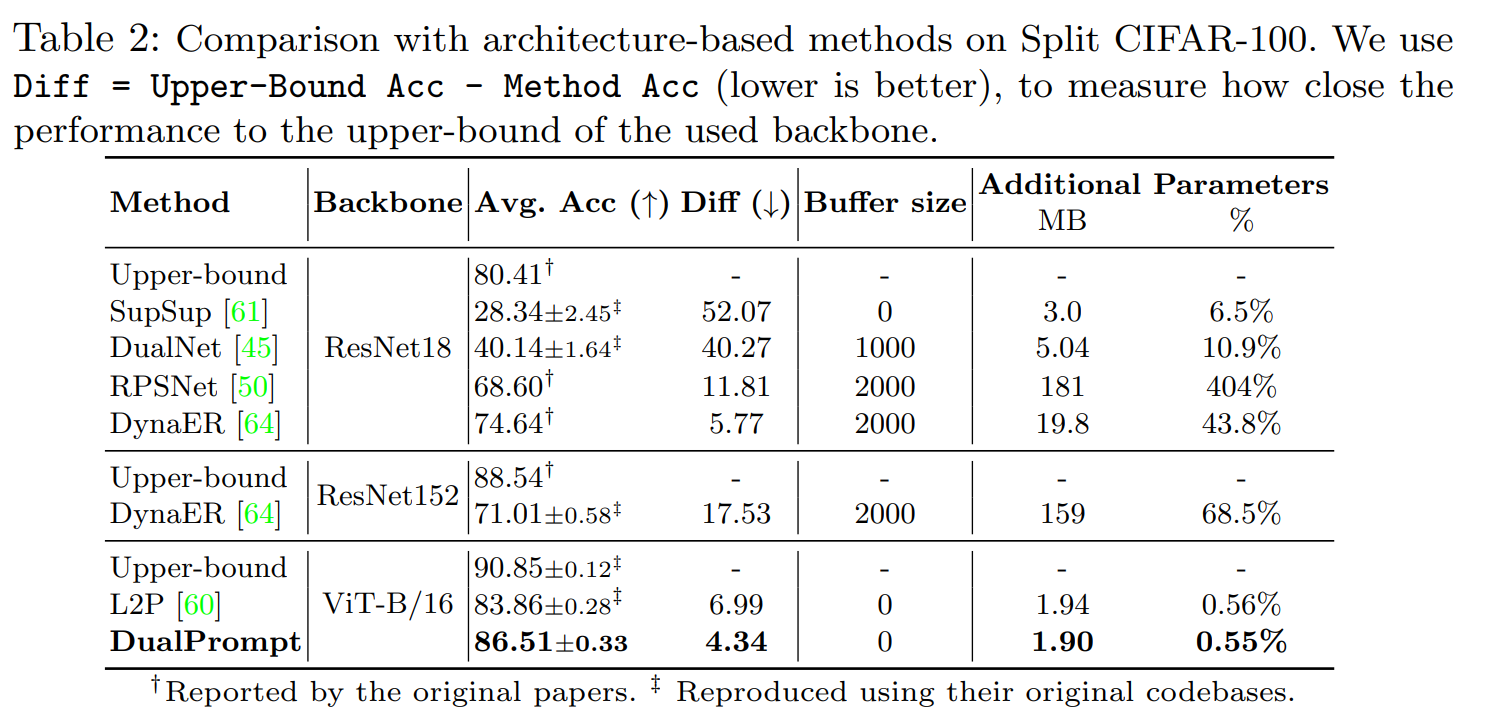
기존의 아키텍처 기반의 방법론들은 ConvNet 기반으로 트랜스포머기반의 모델보다 성능이 떨어진다. 게다가 추가적인 파라미터들을 추가해줘야 하는데, 이러한 모델들의 공정한 비교를 위해서 주어진 아키텍처의 iid 설정에서 어퍼바운드 성능과 어떤 방법의 성능이 가장 가까운지를 측정한다. 마찬가지로 DualPrompt가 최고의 정확도를 달성하였다.
5.3 Does stronger backbones naively improve CL?
본 연구에서 제안한 방법론보다 더 강력한 백본이 성능에 미치는 영향을 탐구해야 한다. 특히 사전 훈련된 ViT가 일반적인 ConvNet 에 비해서 강력하긴 하지만, 반드시 CL에서의 성능 향상으로 이어지지는 않는다. 적절하게 모델을 설계하여 catastrophic forgetting을 방지하지 않는다면, 사전 훈련된 모델은 의미가 없어지게 된다. 대규모 모델을 전통적인 아키텍처 기반 방법에 효과적으로 활용한다는 것은 아직 챌린징 이슈이다. 따라서 DualPrompt는 최첨단 비전 백본을 continual learning에서의 문제를 해결하는데 새로운 접근 방식을 제공하였다.
5.4 Exploration of where and how to attach prompts
5.2섹션에서의 성능은 Gprompt와 Eprompt의 영향을 강화하기 위해 적절한 위치를 선정한 뒤 나온 결과이다.
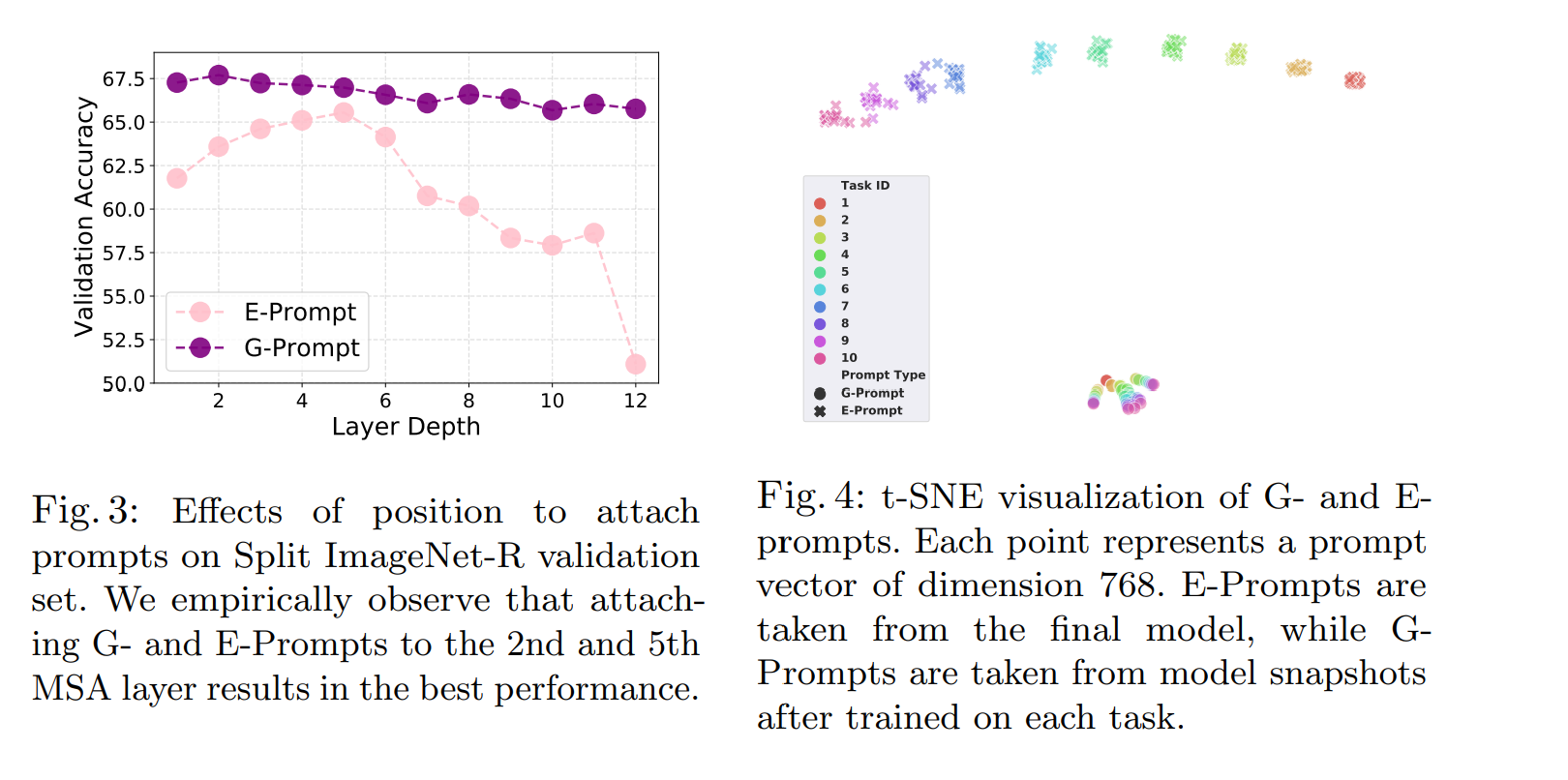
Position of prompts : 가장 적절한 위치를 선정하기 위해서는 휴리스틱 탐색 전략을 활용하였다. 단일 MSA 레이어에만 Eprompt를 삽입한 경우에 결과물은 fig 3에 나와있다. 이를 다중 레이어로 확장하고 검색실험을 수행하여서 startg=1, endg=2 가 최상의 선택임을 알게 되었다.
신기하게 Gprompt와 Eprompt를 attach 하는 MSA 레이너는 서로 겹치지 않는다. 또한 startg>starte이며 얕은 레이어에서 task-invariant한 정보를 Gprompt가 잘 캡처하는것을 의미하고, Epormpt가 깊은 레이어에서 task-specific한 정보를 더 잘 포착한다는 것을 의미한다. 깊은 레이어에 첨가된 경우에는 두개 다 성능에 좋은 영향을 미치지 못했다.
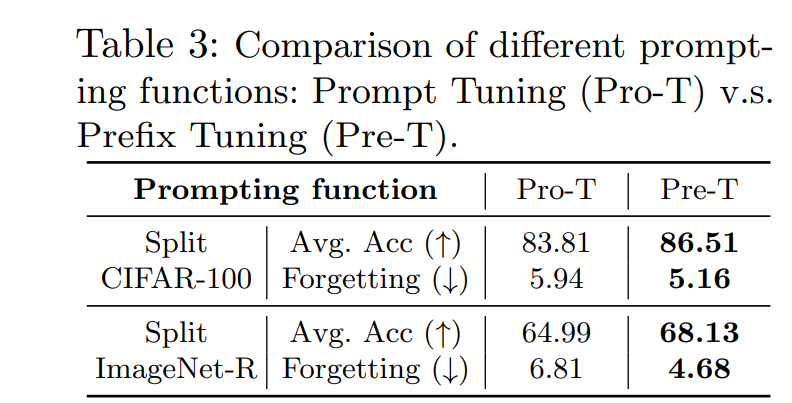
Prompting function: Prompt v.s. Prefix. : 다음과 같은 결과에서 Pre-T의 경우가 더 좋은 성능을 보임을 확인하였다.
5.5 Ablation study
이전 섹션에서 검색한 최적 매개변수를 기반으로 각 구성 요소의 중요성을 보여주기 위해서 DualPrompt의 어블레이션 스터디를 진행하였다.
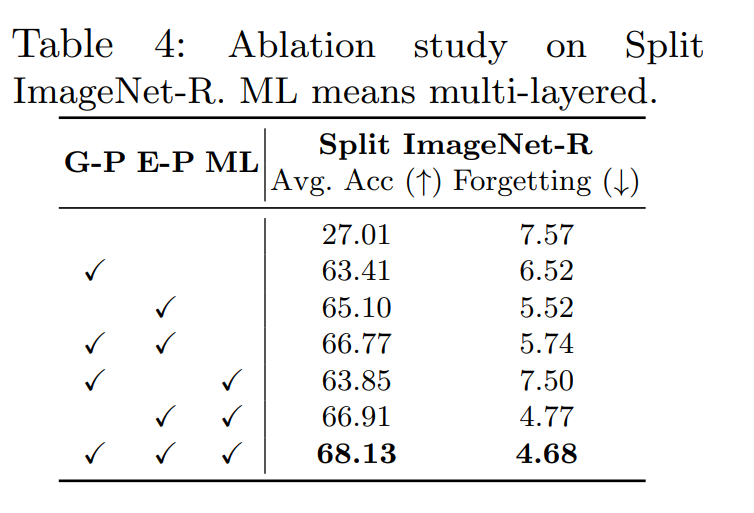
일반적으로는 모든 요소가 최종 성능 향상에 기여하지만, 단일 레이어의 Gprompt만 추가되어도 상당한 개선이 있게 된다. 이는 태스크 불변의 지식이 다양한 작업 간에 일반화되기 때문이다. 하지만 이것은 불가피하게 forgetting을 초래하기 때문에 작업별 지식을 제대로 분리하게 되는 Eprompt를 통해 최종적인 성능을 획득할 수있다. 또한 Eprompt만 적용하는 것은 미래 작업을 학습하는데 도움이 되는 작업 불변적인 지식을 무시하게 된다.
6 Conclusion
본 연구에서는 독창적인 방법으로 DualPrompt 를 제안하였는데, 리허설 프리 기반의 컨티뉴얼 러닝 방법론으로 class-incremental 세팅에서의 이슈를 다루고 있다. 이는 complementary 프롬프트를 사전학습된 모델에 attach 함으로써 지식을 분리하게 된다. 상호보완성을 검증하기 위해서 새로운 벤치마크 데이터셋인 Split ImageNet-R을 제안하였다. DualPrompt는 기존의 SOTA 퍼포먼스를 능가하면서로 추가적인 메모리 사용이 없이도 기존의 아키텍처 기반과 리허설 기반 방법론보다 성능이 좋았다. 따라서 DualPrompt를 통해서 실제 월드에서의 리허설프리의 CL 의 적용 시작점이 되기를 희망한다.
