A predictive sliding local outlier correction method with adaptive state change rate determining for bearing remaining useful life estimation
2023 하계 논문세미나
Abstract
RUL의 정확한 예측을 위해 본 연구에서는 predictive sliding local outlier correction (PSLOC) method를 제안함. 또한 adaptive state change rate (SCR) 또한 베어링 RUL을 위해 제안한다. 제시한 방법들은 현재 존재하는 베어링의 health prognsis methods에 키 이슈를 다루기 위한 것이다. PSLOC는 degradaation process에서 생기는 랜덤 fluctuations를 제거하는 것이다. 시계열 데이터에서 FPT를 탐지하는데 있어서 중요한 역할을 하며, RUL 예측 정확도를 높인다. SCR 알고리즘은 정확한 FPT determination을 위해 degradation process의 변화를 감지한다. PRONOSTIA 데이터셋으로 case study를 진행하여 제시한 방법론이 효과적임을 보인다.
Introduction
RUL 예측은 PHM의 메인 태스크 중 하나이다. future degradation trend를 모니터링 signal 및 historical data로 예측하는 것이다. RUL 예측을 함으로써 설비가 긴 uptime을 가지며 낮은 유지보수비용을 가지고 신뢰도를 높일 수 있다.
베어링의 degradation은 물리적은 프로세스로 지속적으로 변화한다. 긴 시간동안의 모니터링동안 랜덤한 fluctuations가 sensor의 loose 혹은 환경의 transient, degradation damage로 인해 이루어지게 된다. 게다가 노이즈와 진동은 abnormal fluctuations를 야기한다. 그러므로 fluctuations가 다루어지지 않는다면 false alarm을 야기하며 FPT를 결정하는데 있어서 정확도에 영향을 주게 된다. 랜덤한 anomalies 나 fluctuations가 HI에 영향을 주기 때문에 HI를 스무딩하여 RUL을 예측한다. modified Weibull distribution algorithm 을 통해 signal fluctuations를 제거하기도 하였다. 또한 inertial relative root mean square을 사용한 연구도 있다. 이러한 방법들은 정보를 포함하고 있는 fluctuations 또한 제거하는 방식이다. break-in phase라는 중요한 정보를 담고 있기도 한데, degradation stage에 중요한 정보이며, 위의 fitting process에서는 무시되는 것이다.
모델 기반의 RUL 예측은 degradation process의 물리적, 통계적 기초에 의한 것이다. 특히 random variation에 좀 더 robust 하며, 환경적인 방해 요소에도 RUL 예측을 잘 한다. 마코브 모델, wiener process 모델, inverse 가우시안 모델들이 RUL 예측에 사용된다. 베어링 degradation process는 healthy stage와 rapid dagradation stage로 나뉜다. 따라서 모든 모델 기반의 연구에서는 exponential 모델을 많이 사용한다. Gradient descent 모델을 사용하여 exponential 모델을 최적화 하기도 하고, particle filtering 알고리즘을 통해 improve하기도 한다. RUL 예측을 위해 bayesian 업데이팅을 expectation maximum 알고리즘과 혼합하기도 하였다. RMS는 exponentially degrade 하긴 하지만, randomness는 RUL 예측 정확도를 낮추게 된다.
모델 기반의 RUL 예측 방법론에서 중요한 것은 FPT를 잘 탐지하는 것이다. 베어링 degradation의 stage는 실제로는 아주 복잡하게 나누어지지만, 러프하게 healthy stage와 rapid degradation stage로 나뉘게 된다. FPT는 이 둘을 나누는 아주 중요한 것이다. Degradation process에서 failure features는 약하게 나타나고 detect하기 어렵다. 많은 케이스에서, FPT는 주관적으로 선택된다. 몇몇 접근 방법론이 3시그마와 같은 가이드라인을 선택하였지만 이는 degradation 전체를 반영하는 통계량이 아닌 일부만을 반영하는 통계 데이터를 보고 선택하는 것이기 때문에 FPT 결정에 대한 연구들이 지속되어왔다.
요약하자면, 비정상 spurious fluctuations를 제거하고, FPT 포인트를 정확하게 탐지해야지 정확한 RUL을 예측할 수 있다. 본 연구에서는 predictive sliding local outlier correction (PSLOC) method with an adaptive state change rate (SCR) 방법을 제안하여 베어링 RUL 예측을 한다. 본 연구의 메인 contribution은 다음과 같다.
1. PSLOC 방법은 anomalous fluctiations를 탐지하고 제거하며, degradation 트렌드에 맞추는 replace를 한다.
2. SCR 방법은 FPT를 탐지하기 위해 제안한 알고리즘이다. 이는 슬라이딩 위도우와 같은 컨셉으로 각 윈도우의 state를 탐지한다. 그러므로, 알고리즘으로 degradation process의 탐지를 할 수 있고, 적적한 조정이 가능하여 FPT를 정확하게 판별한다.
3. Exponential prediction 모델이 simulated annealing 알고리즘으로 성능이 향상되었다. 지속적으로 adaptive global obtimization 서치를 통해 degradation process에서 랜덤 에러를 줄인다.
Definition and analysis of the PSLOC method
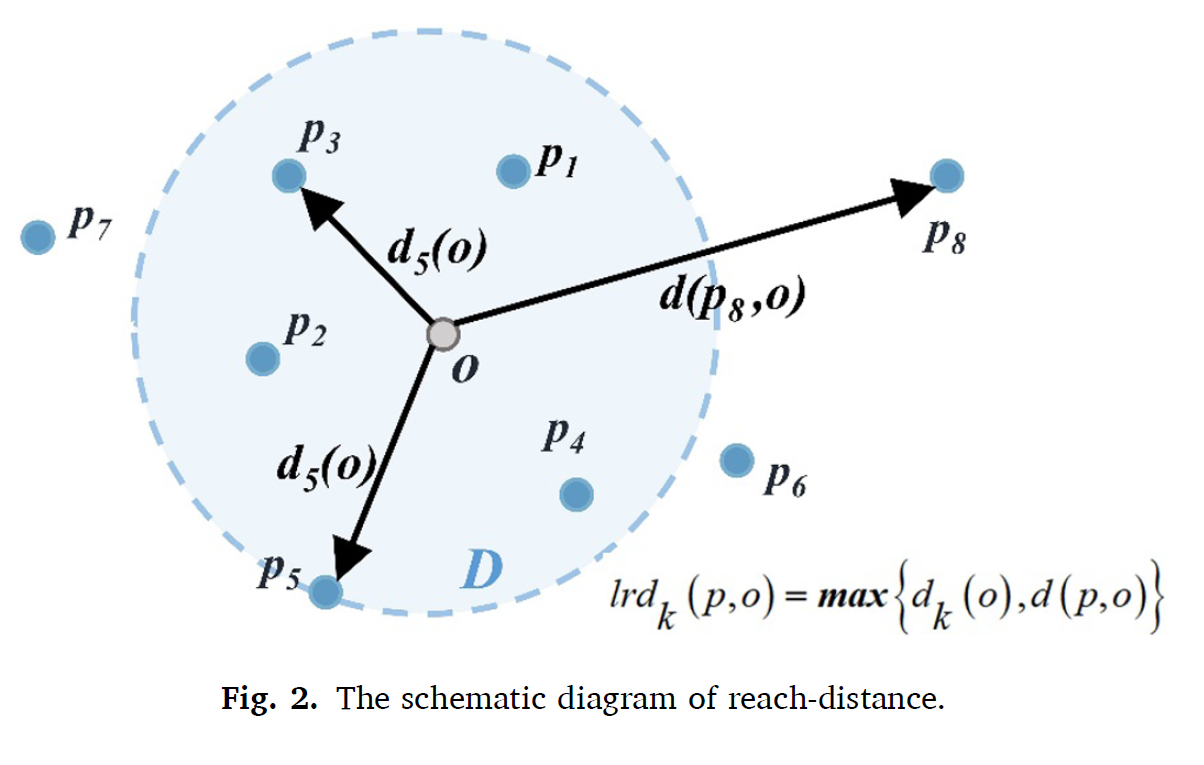
LOF algorithm
Run to Fail data에서 surrounding과 다른 데이터들이 있다면 abnormal이라고 판별하고 제거하거나 수정되어야 한다. 이는 LOF 알고리즘으로 anomaly를 detection 하는 알고리즘으로 수행한다. 이웃 데이터의 밀도에 따라 정상인지 비정상인지를 판별한다. LOF 값이 1에 가까울 수록 normal에 가까워진다.
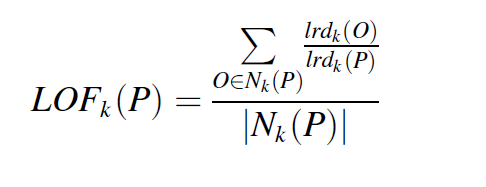
LS-SVM algorithm
least squares support vector machines (LS-SVM) 알고리즘으로, 진단과 예측 문제에 많이 사용된다. LS-SVM알고리즘은 inequality 문제를 equality constraints로 바꾼다. linear equation은 다음과 같다.
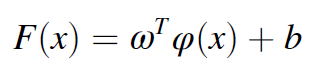
그리고 optimization problem은 다음과 같다.
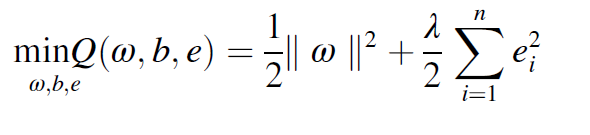
라그랑지안 승수법에 의해 다음과 같이 식이 정리된다.
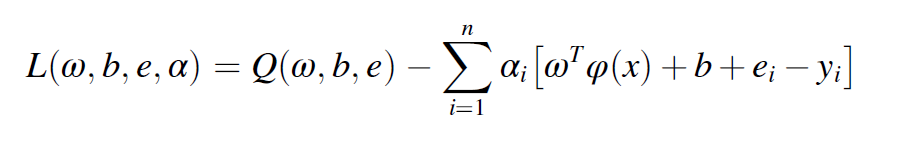
이 공식을 간단히하면 최종 regression function은 다음과 같이 정리된다.
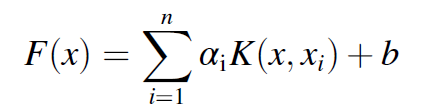
Detection and updating of abnormal fluctuations using the PSLOC method
Abnormal data는 HI의 큰 fluctuations를 야기한다.
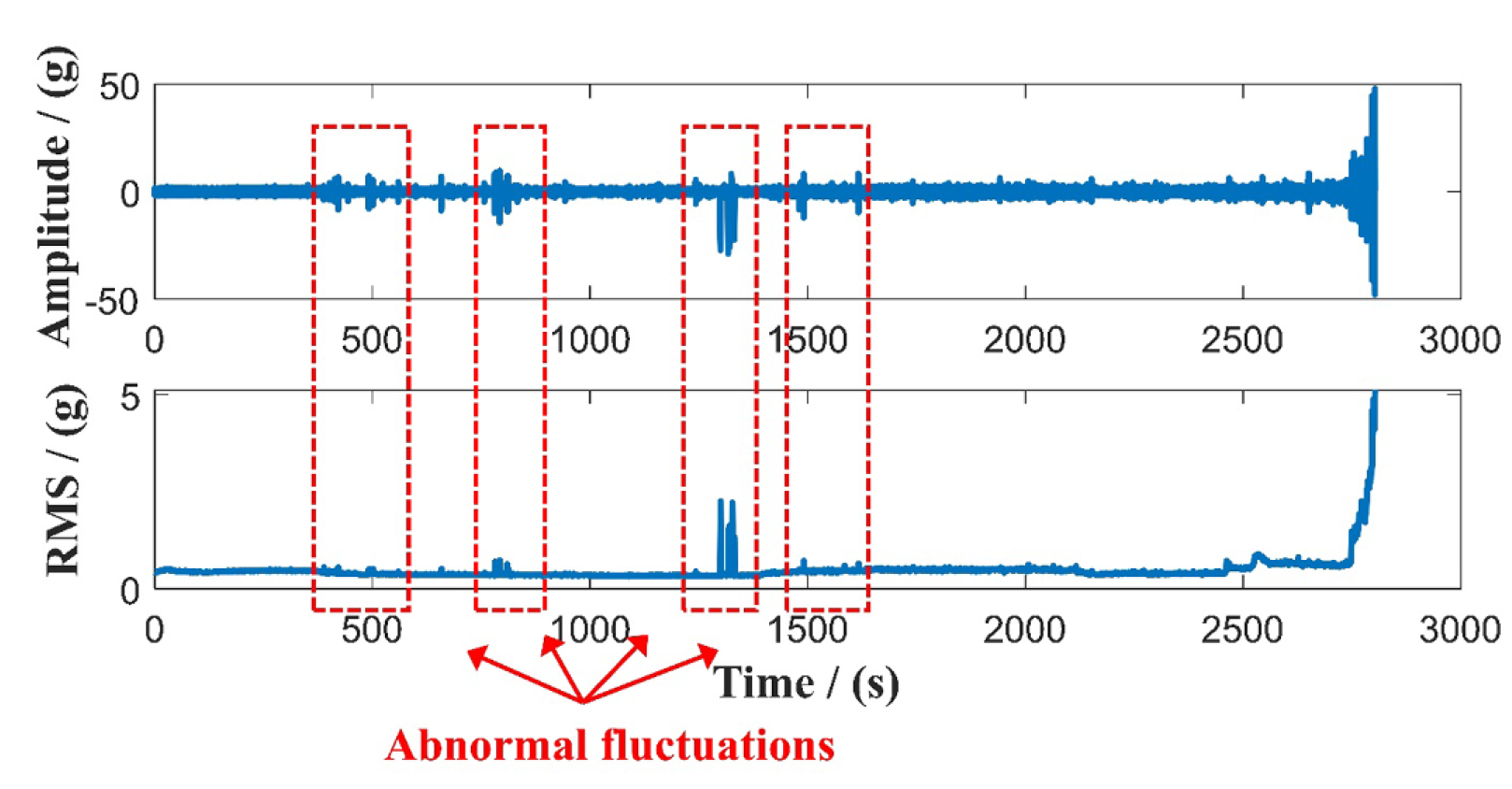
다음 그림과 같이 degradation trend에 영향을 준다. 그러므로, anomaly detection 알고리즘을 사용함으로써 이러한 지점의 영향을 줄이는 것이 타당하다. 시계열 데이터는 모니터링 중 한 포인트씩 입력이 된다. 기존의 outlier detection은 data update process를 고려하지 않는다. 따라서 LOF 알고리즘을 지속적으로 업데이트하게 해야한다.
본 연구에서는 PSLOC 방법을 사용하여 이러한 문제점을 해결한다. 이것은 sliding shift window 방법으로 LS-SVM의 이점을 이용하는것이다. 이 방법을 통해 abnormal fluctuations를 탐지할 수 있을 뿐 아니라, HI를 스무쓰하여 detection 정확도를 높이게 된다.
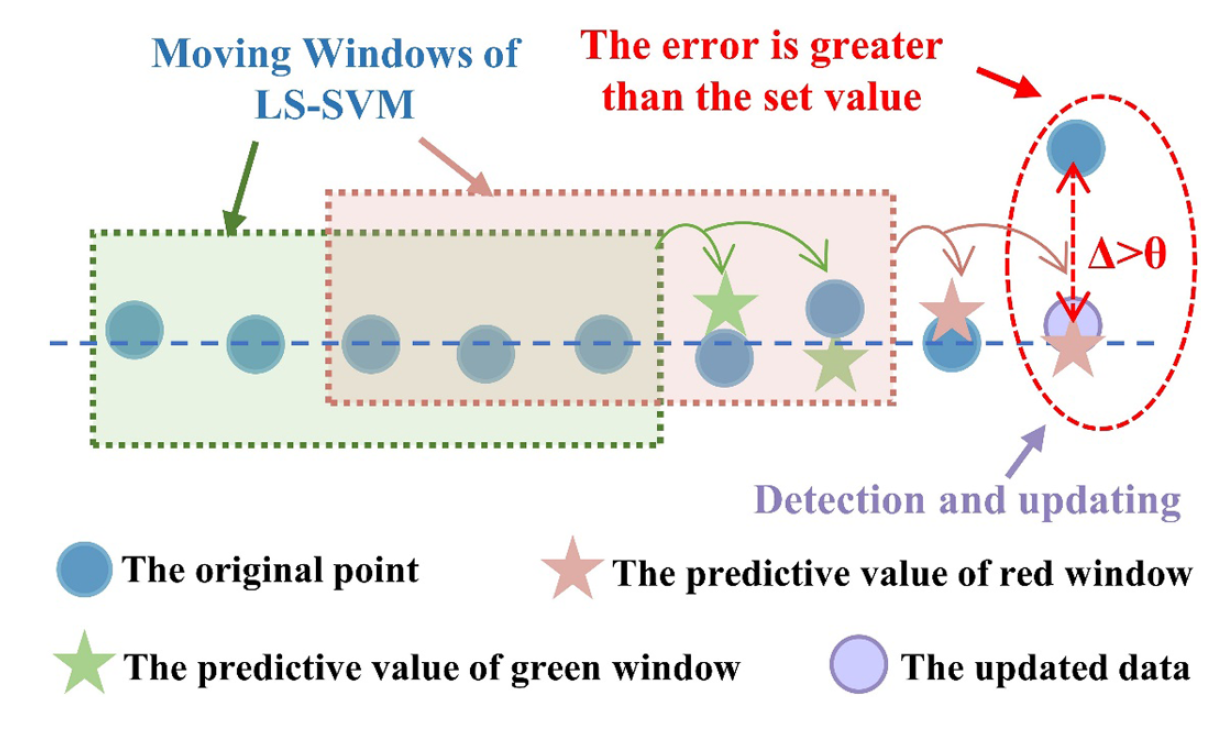
Step 1: Dividing the sliding window
Sliding window 사이즈는 적절한 사이즈로 설정된다. 윈도우가 특정 스텝으로 shift된다. 예측 퍼포먼스와 anomaly detection accuracy는 윈도우 사이즈에 의해 결저된다. 윈도우 사이즈가 너무 작게되면 degradation 정보다 적게 담기기 때문에 너무 작으면 안된다. 윈도우 사이즈는 또한 너무 커서도 안되는데, 예측과 탐지에 너무 큰 intervals를 가지기 떄문에 temporal detection에서 신뢰도를 잃게 된다.
PSLOC 방법의 윈도우 사이즈의 효과를 반영하기 위해 70과 170 time interval이 선택되었다.
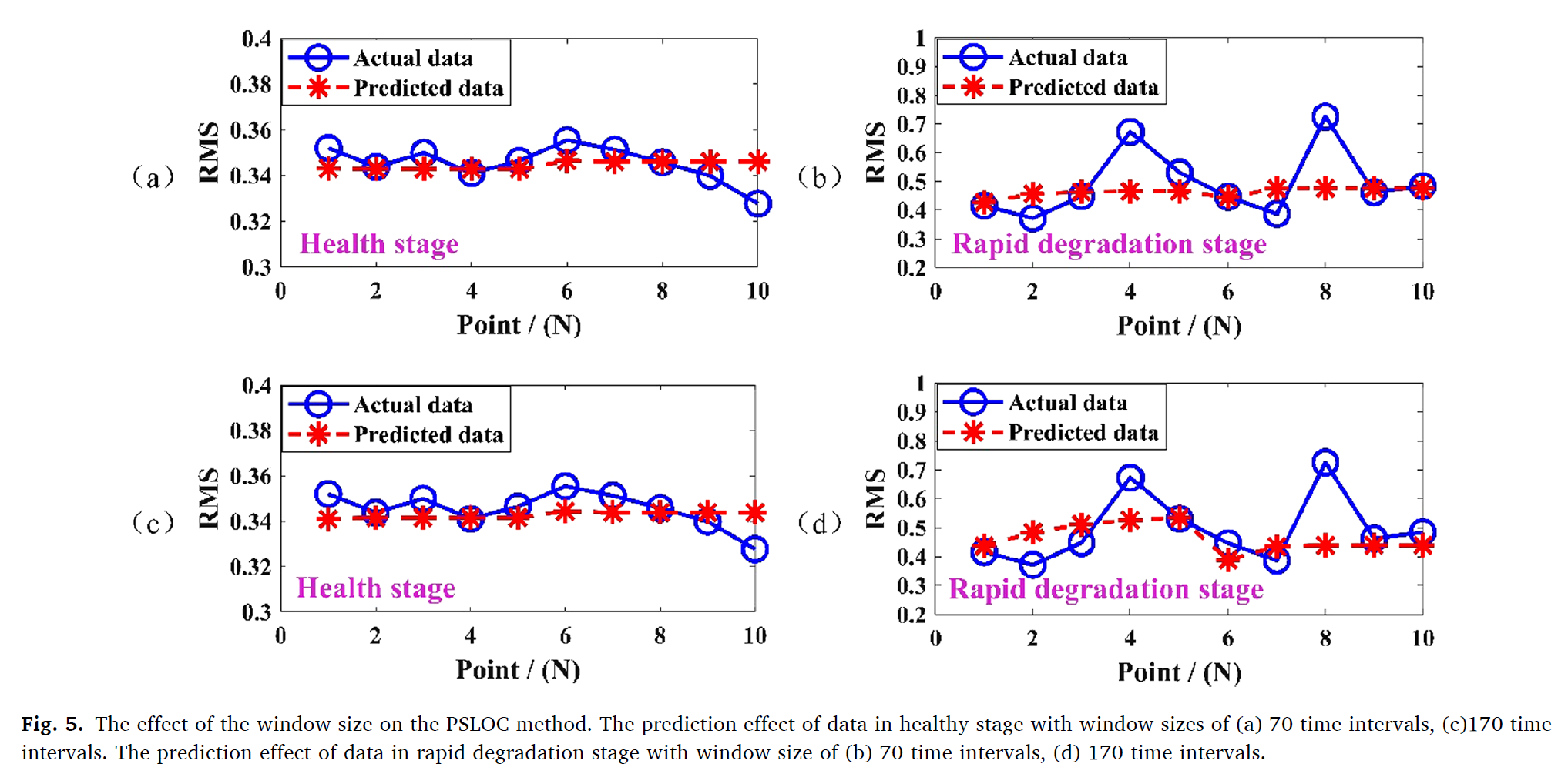
예측 결과는 170의 윈도우 사이즈가 70 사이즈보다 훨씬 더 좋은 성능을 보였다. 하지만 이는 베어링의 수명에 따라 윈도우 사이즈가 달라져야한다는 문제점을 가지게 되는데, 온라인으로 처음에 윈도우 사이즈를 설정하기가 어렵다. 그러므로, 테스트와 실험들을 통해서 총 수명의 3~8%의 길이를 가지는 윈도우를 설정하는 것이 성능에 제일 효과적이었다.
Step 2: Multi-step trend prediction for each sliding window
LS-SVM 알고리즘은 각 윈도우를 통해서 short-time tred prediction의 이점으로 multi-step prediction을 할 수 있다. 업데이트된 윈도우 데이터들은 각 예측을 위한 학습 데이터로 사용되며, 같은 사이즈의 각 데이터들은 동시에 data front-end에서 삭제된다. 이것은 알고리즘이 최근의 degenerate features를 학습하는데 도움을 줄 뿐만 아니라, 예측 정확도를 높이고 또한 계산 코스트를 증가시키는 것을 방지한다. 예측 step의 사이즈를 선택하는 것은 윈도우 사이즈와 연관이 되어 있고, 이것인 예측 효과에 영향을 미친다. 본 알고리즘은 많은 prediction point를 요구하지 않고 적절한 스텝 사이즈를 선택함으로써 정확도를 보증한다.
PSLOC 방법에서 예측 step size의 효과를 보기 위해 healthy state와 fast degradation state에서 2가지의 데이터가 선택되었다. 3가지 다른 예측 2, 6, 12 스텝이 선택되었다.
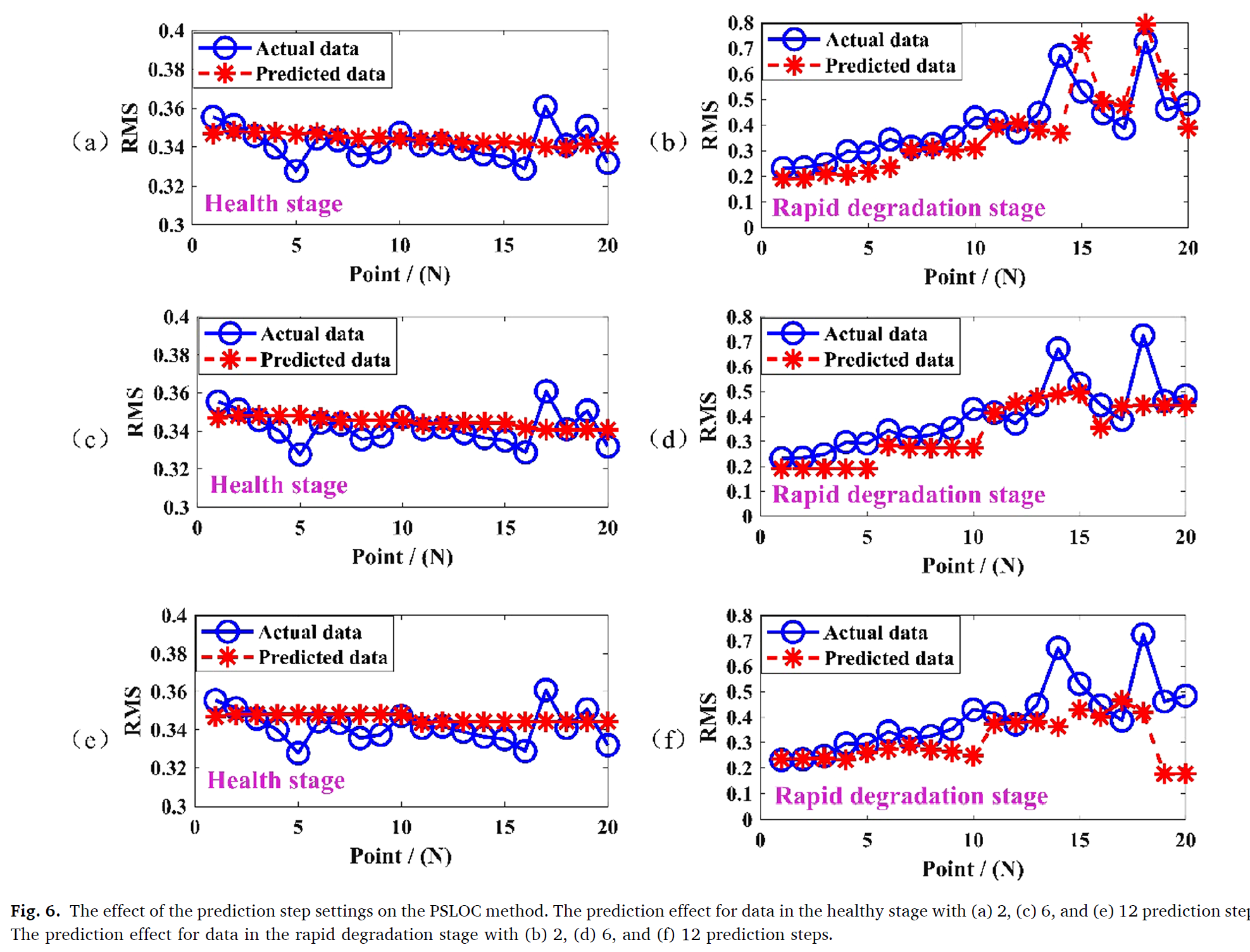
Prediction은 2 step 일때가 가장 mse값이 작았지만 이렇게 예측을 진행하면 효율성이 떨어지기 때문에 큰 mse의 차이가 없는 6 step을 선택한다. 예측 스텝 길이는 윈도우 사이즈의 2~5%를 선택하는 것이 좋다.
게다가, window sliding 스텝 사이즈와 예측 LS-SVM 스텝을 같은 숫자로 두었다. 만약 윈도우 슬라이딩 스텝이 예측 스텝보다 작다면, 계산 코스트가 중복된 계산으로 증가할 것이다. 윈도우 슬라이딩 스텝이 예측 스텝보다 크다면, 몇몇 포인트가 miss될 것이고, abnormal fluctuation detection과 업데이팅의 의미가 사라진다.
Step 3: Determining and updating anomalies
각 윈도우의 예측 데이터는 실제 모니터링 데이터와 비교된다. 만약 예측과 실제 값이 smoothing threshold 보다 크다면, anomaly로 탐지되며 윈도우가 outliers를 포함하고 있다는 것이 된다. 이 윈도우는 LOF를 통해 어떤 데이터 포인트가 아웃라이어인지를 본다. 특정 데이터 포인트가 아웃라이어로 결정이 되면 이것은 replaced 되는데, 수식은 다음과 같다.
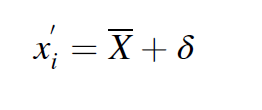
는 anomaly 10개 포인트의 평균을 의미하고, 는 와 실제 값의 차이의 평균을 의미한다.
다른 degradation stage에서 스무딩 threshold는 다른 값을 가지게 된다. 만약 healthy stage와 Rapid degradation stage의 threshold가 같은 값을 갖게 되면 PSLOC의 trends 예측의 문제가 된다. 그러므로, smoothing threshold가 degradation degree에 따라 달라져야 한다. Healthy state를 represent 하기 위해 설비 구동 초기 10개의 윈도우를 선택하여, 이 윈도우들의 HI의 average fluctuations의 주파수를 구하여, 초기 smoothing threshold를 이 주파수에서 1을 더한다. HI의 변화가 rapid degradation stage에서 바뀌기 때문에 모든 20 window마다 smoothing threshold를 업데이트한다.
Prediction framework for RUL
Introduction to the overall prediction framework
시계열 데이터를 예측할 때, 인풋 데이터는 순차적으로 들어오기 때문에 바로 anomaly인지를 판별하기가 까다롭다.
제시한 모델은 3가지의 스텝으로 나뉜다.
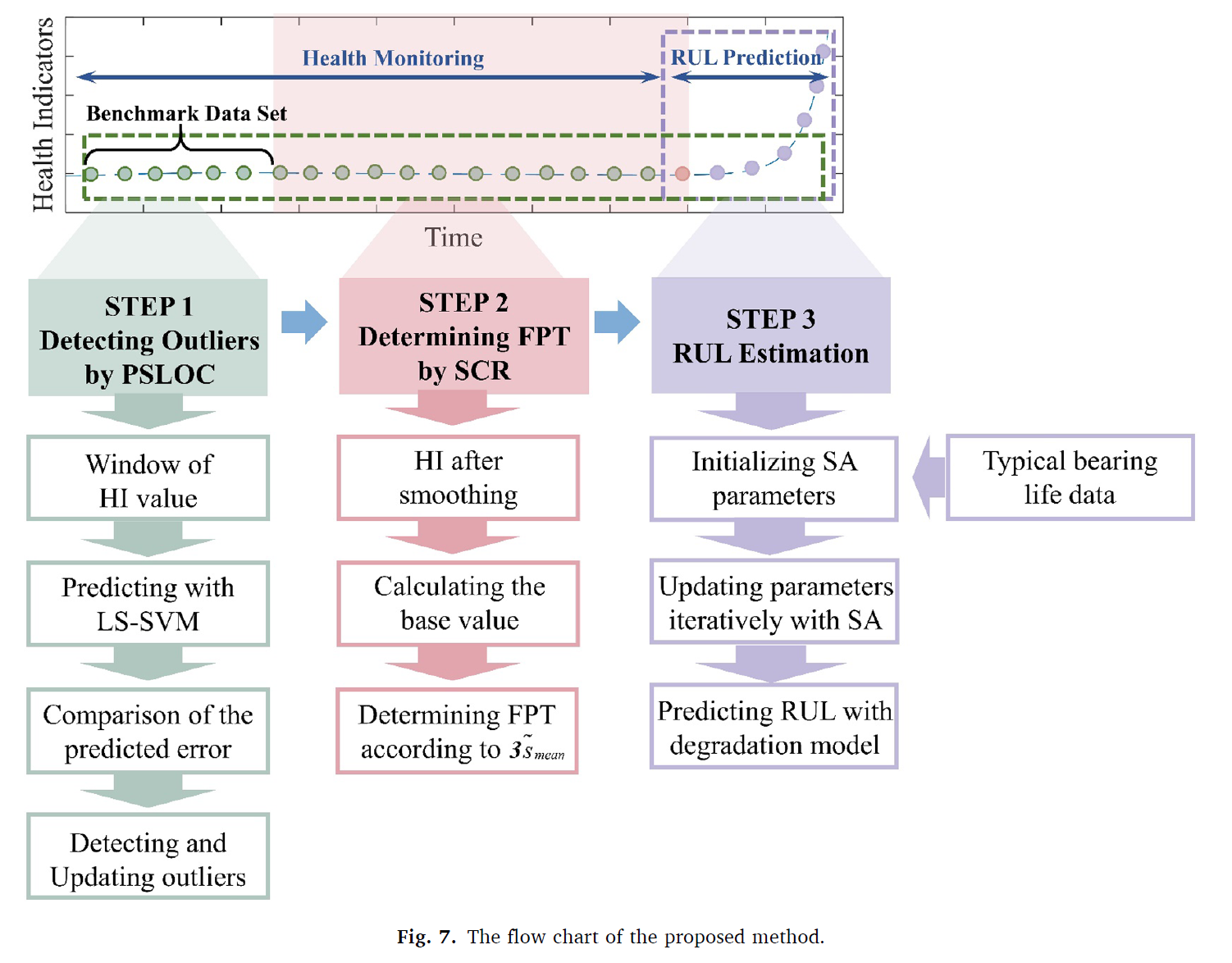
1. 모니터링 중에서 abnormal fluctuations를 PSLOC를 이용하여 탐지
2. FPT 시점을 SCR를 이용하여 탐지
3. FPT 도달 이후 RUL 예측
FPT detection
SCR방법은 prediction point에서 fault를 찾아 통해 FPT를 탐지한다. State evaluation unit 단위로 SCR을 계산하는데, 슬라이딩 윈도우 사이즈와 동일하다. 만약 윈도우의 SCR 값이 detection threshold를 넘는다면, 윈도우의 첫 번째 포인트가 FPT가 된다.
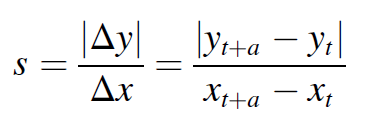
degradation의 SCR 은 다음과 같이 나타나며, a는 윈도우의 길이이다. 이것을 n step까지 계산하고, matrix화 한다.
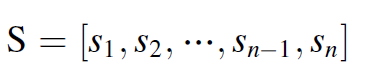
PSLOC detection이 완료된 100개 윈도우의 s의 평균은 SCR의 base 값이 된다. FPT의 threshold는 3가 된다. 이 때 윈도우의 last point가 FPT가 된다.
RUL prediction
Bayesian-based degradation model을 updating 하는 방식이 소개되었다. 본 모델은 state 모니터링 정보가 priori 지식으로 exponential 모델의 stochastic 파라미터를 업데이트하는 방식이다. 하지만 이 모델의 단점은 마라미터들이 degradation process에 따라 변하지 않는다는 점이다. Bayesian exponential 모델을 SA알고리즘을 사용하여 업데이트한다.
SA 알고리즘은 파라메트릭 서치를 위해 사용된다. SA는 globally optimal algorithm이지만, 약간의 expert knowldge를 필요로 한다.
전체적은 RUL 예측 방법론의 스텝은 다음과 같다.
1) 베어링의 run-to-fail 데이터를 선택하여, RMS 커브를 획득한다. PSLOC 방법으로 anomaly를 제거한다. exponential model에 인풋으로 넣고, 이 데이터에 적합한 degradation 파라미터를 SA를 통해 획득한다. 그리고 그들의 평균 값들을 초기 파라미터로 설정하고 그 값은 다음과 같다.
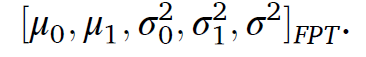
2) 실제 시계열 데이터를 최적화 하기 위해 SA알고리즘에 fitness 함수가 활용되어 실제값과 예측 값간의 MAD를 계산한다. FPT 이전의 5개의 윈도우를 테스트 데이터로 사용한다. 예측 모델이 SA와 함꼐 최적화 되며 지속적으로 average absolute error 를 줄인다. 현재 최적 RUL이 마지막으로 계산되며, 새로운 파라미터가 업데이트된다.
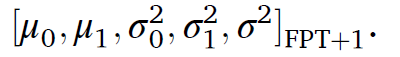
3) 현재 파라미터를 통해 RUL을 계산하며, 업데이트된 포인트를 테스트 데이터에 업데이트하며, 그 길이만큼 앞에서는 제거된다. 예측 모델은 지속적으로 SA와 함꼐 최적화되어 RUL을 계샇ㄴ하고, 새로운 degradation 파라미터를 획득한다.
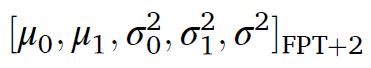
4) step3 가 failure threshold에 도달할때 까지 반복된다.
이 알고리즘은 다음과 같이 정리된다.

Results and analysis
Experimental platform
PHM Challenge 2012 데이터를 사용하였다.
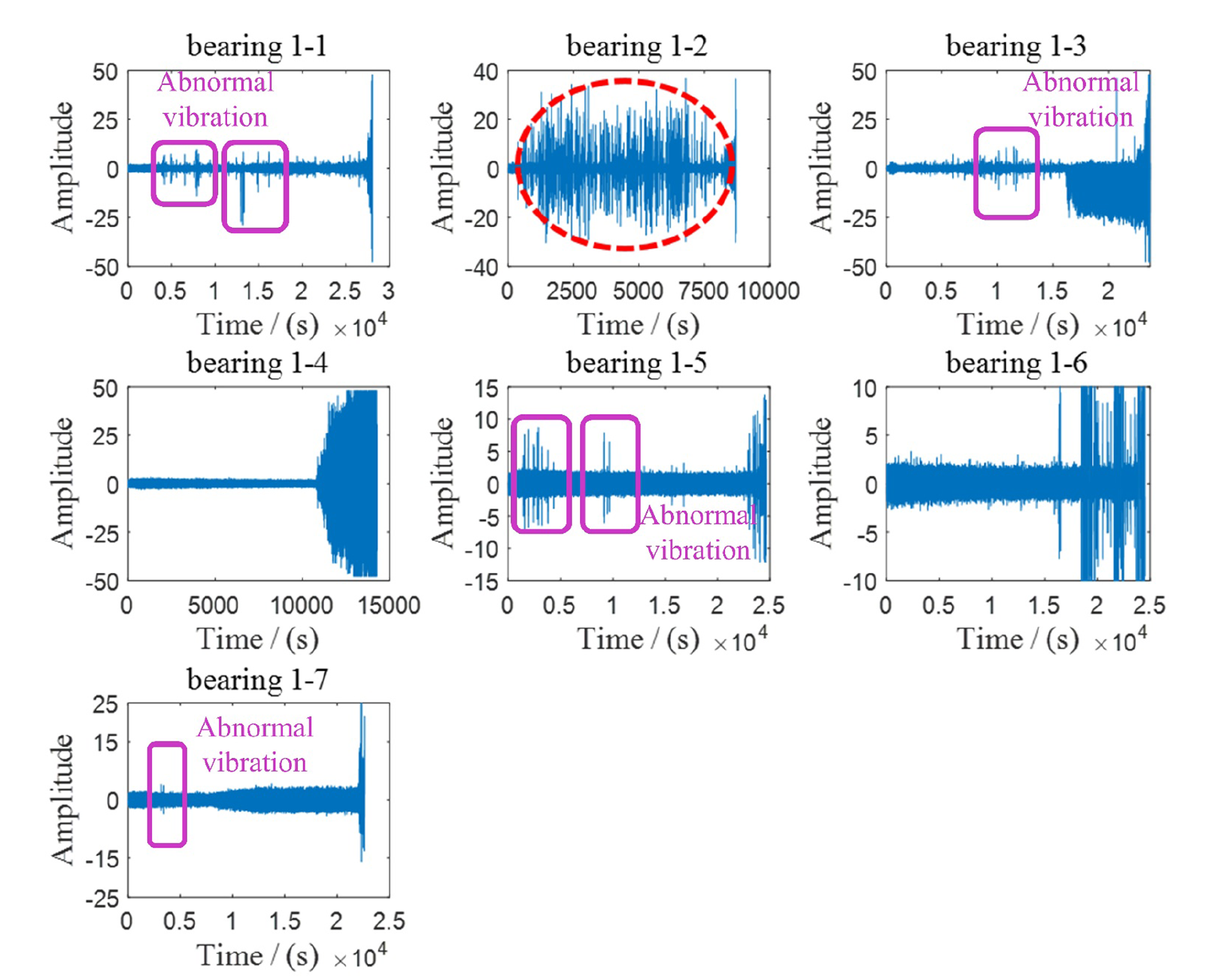
데이터의 원본을 plot하면 다음과같이 시각화된다.
Checking and updating of abnormal fluctuation data
베어링 1-2는 improper bearing installation으로 판단되어, 해당 방법론의 validation으로는 사용되지 않는다.
각 데이터에 존재하는 진동값의 이상한점들은 HI의 fluctations을 야기한다. FPT를 결정하는데 기존의 3 혹은 SCR 방법론을 노이즈를 제거하기 전후로 비교한다.
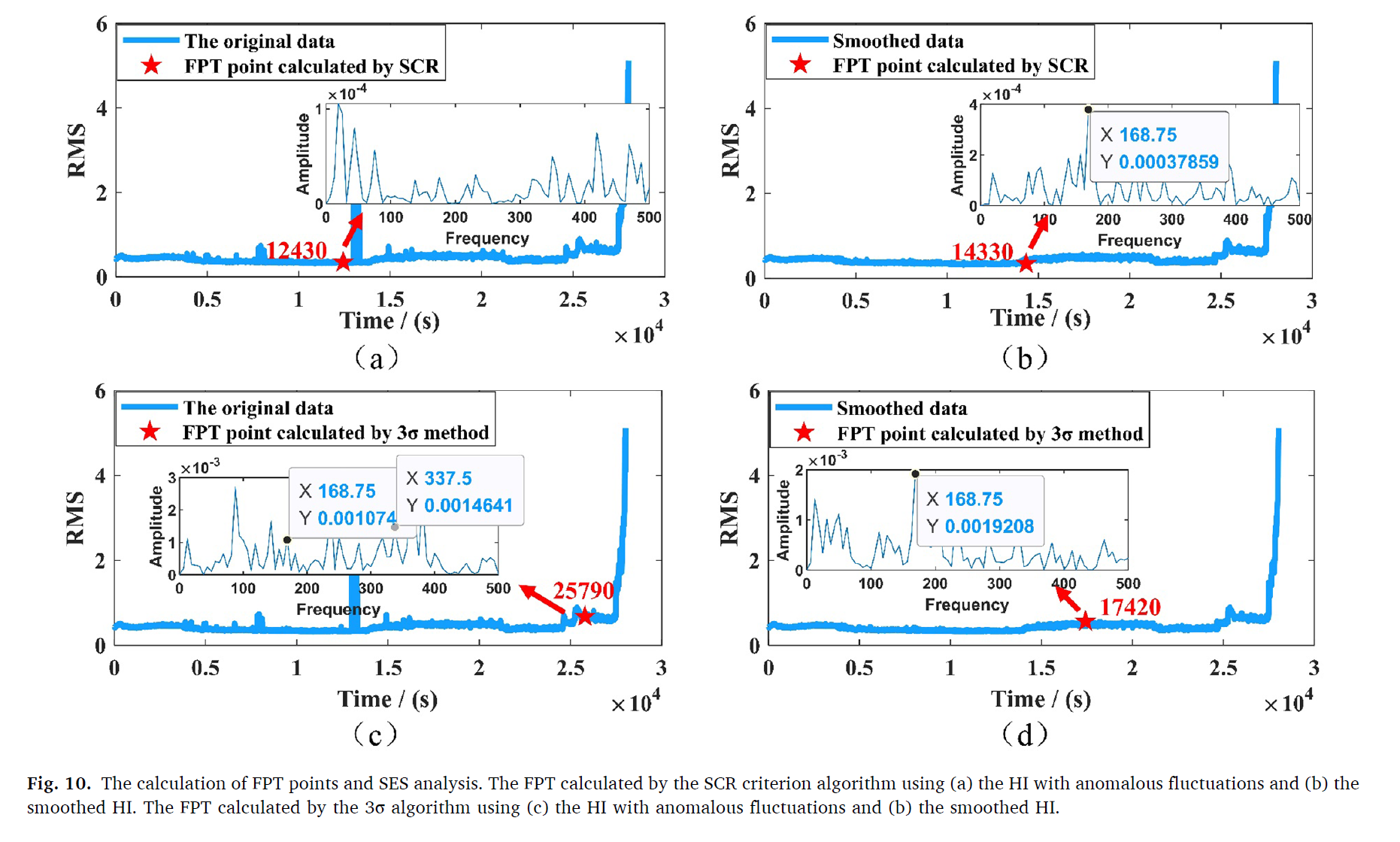
Squared envelop spectrum (SES) 는 fault diagnosis에 많이 활용되는데 베어링 FPT 시점에 health status를 fault diagnosis를 진행하였다.
결과를 보면, abnormal을 제거한 경우에 더 늦게 FPT를 탐지하게 되었다.
(c)에서는, FPT시점에서 SES의 고장 주파수를 탐지 할 수없었다. 하지만, (d)에서는 FPT에서 디텍트 할 수 있었다.
베어링 1-1에 대해서는 180의 윈도우 사이즈 및 8의 moving step을 제시하였다. PSLOC의 효과를 증명하기 위해, 다음과 같이 나타난다.
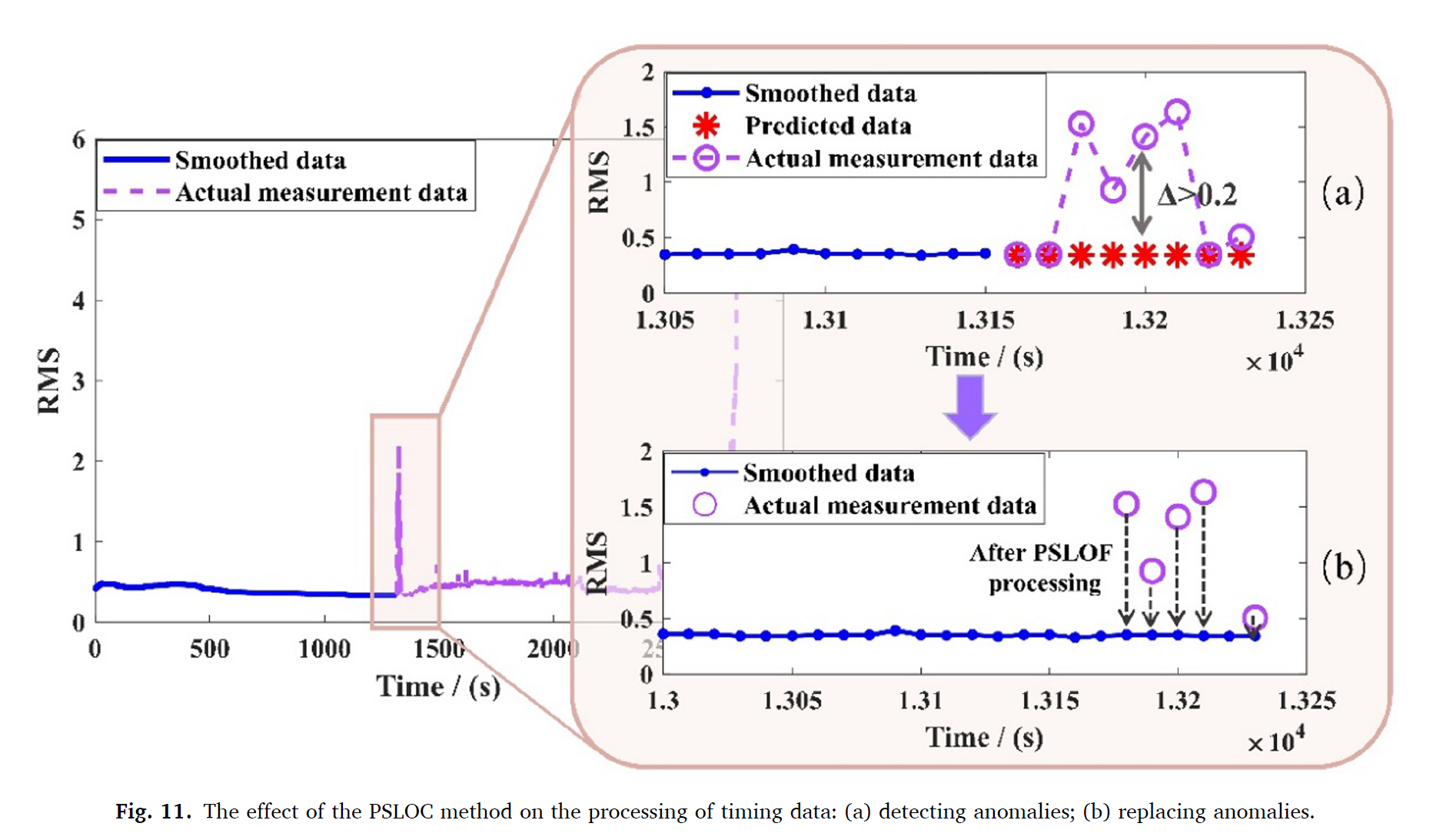
이를 통해 smooth가 잘 작동함을 알 수 있다. 그리고 temporal data에 대해 PSLOC의 효과를 보이기 위해 베어링 1-1에서의 일정 포션을 가지고 시퀀스 형태로 인풋을 집어넣었다. Fig.12에는 4개의 윈도우가 동시에 보여진다.
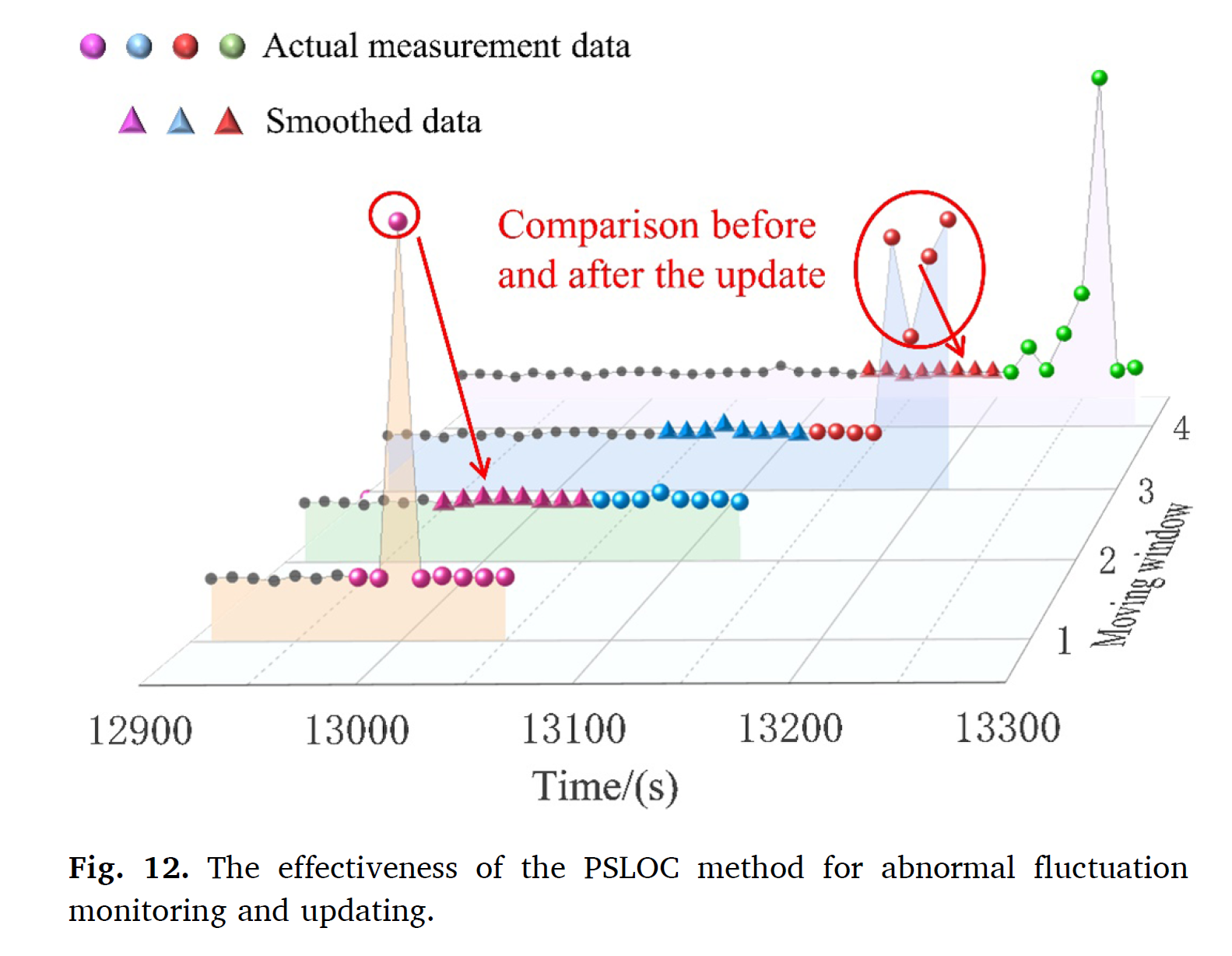
윈도우 1과 3에서 보여지는 실제 데이터는 큰 fluctuations를 보여준다. 스무딩이후 비정상 fluctuations는 업데이트되고 윈도우가 업데이트되어 2와 4와 같이 나타나게 된다. 이것은 제시한 PSLOC 알고리즘이 효과적임을 보인다.
PSLOC 방법론은 전체적인 데이터를 랜덤 그리고 spurious 한 local fluctations를 제거하는데 사용된다.
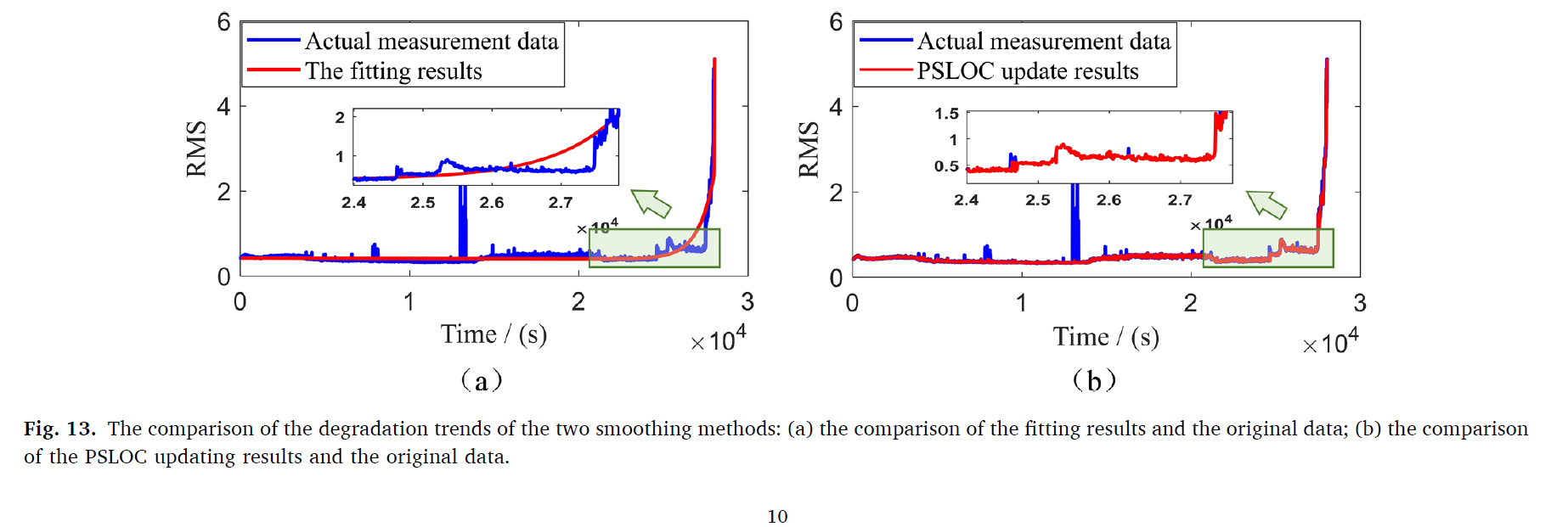
기존의 방법론과 비교하여 PSLOC는 degradation trend가 너무 스무쓰하여 break in phase degradation이 무시되었다. 이것은 상당한 degradation process 정보의 손실을 의미한다. b번에서는 이와 비교하여 단지 local의 fluctuation만 제거했음을 알 수 있다.
Determination of the FPT
동작시작 시점으로부터 100개 윈도우의 SCR 값평균으로 threshold 를 구했다. SCR이 threshold를 넘은 윈도우의 마지막 시점이 FPT로 선정되었다. RUL 예측은 이 시점부터 시작된다.
제시한 방법론이 다른 방법론 대비 더 정확하게 potential trend of HI를 잡아내며, FPT를 더 빠르게 잡아내었다.
RUL prediction and comparison
FPT가 reach 되었다면, RUL 예측이 시작되는데, PSLOC 로 스무드된 데이터가 업데이트 되는 과정에서인풋으로 들어간다. 1-6과 1-7은 typical한 데이터이므로, 초기 degradation 파라미터들을 획득하여 평균값을 다른 베어링 예측의 prediction framework의 초기값으로 사용한다.
예측값의 정확도를 평가하기 위해 relatuve accuracy(RA)가 제시되었다. 이 metric은 relative error를 실제 RUL과 예측 RUL간의 차이를 보는 것이다. RA가 1에 가까우면 예측된 RUL값이 실제 RUL값과 비슷하다는 것이다.
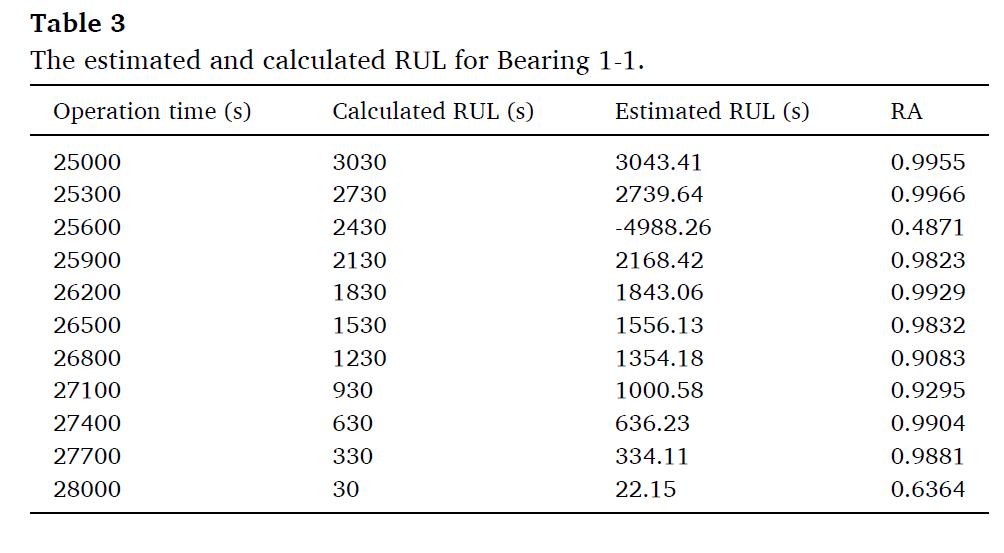
베어링 1-1에 대해서 특정 point에 대한 RA값은 다음과 같다.
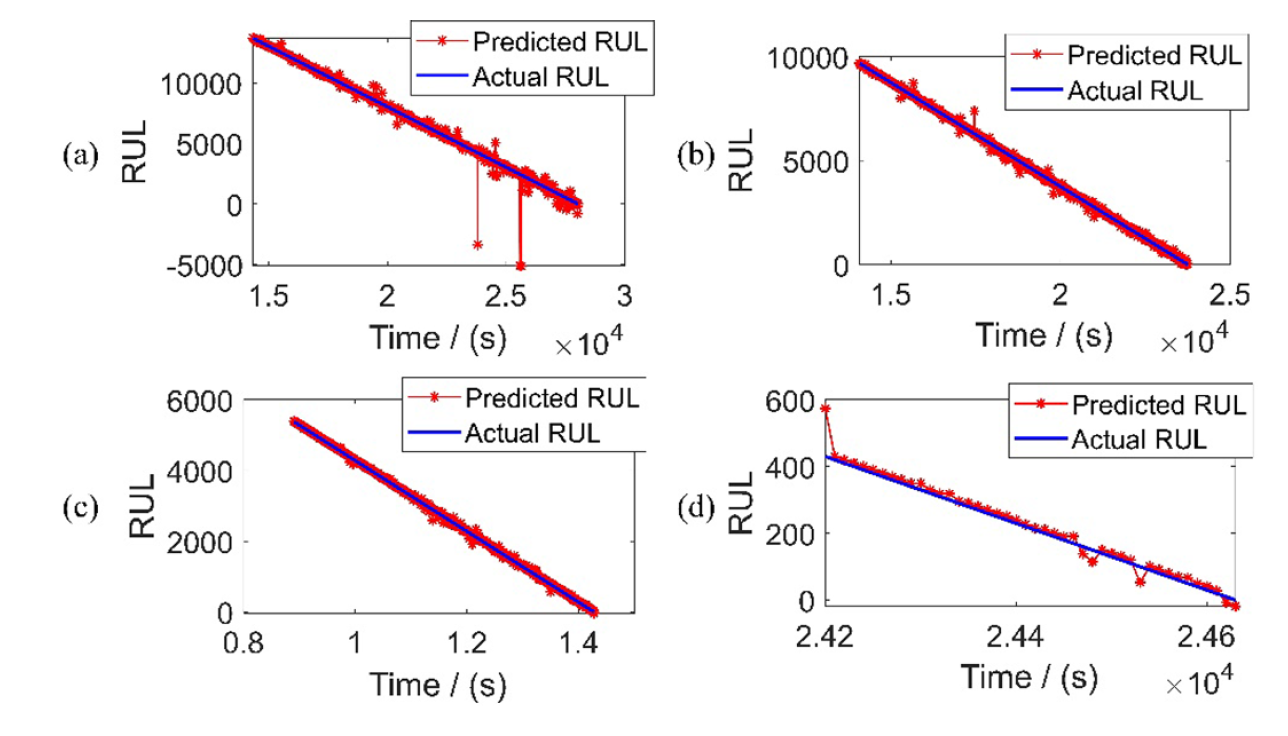
이를 통해 RUL 예측 성능이 acceptable함을 알 수 있다. 하지만, 특정 시점에서 예측값과 실제 값의 차이가 존재함은 분명하다. 이 문제는 이전 윈도우에서 획득한 예측모델의 파라미터와 실제 파라미터의 간극이 큰 시점이다. 25600시점에서 RA값이 매우 작은 것도 그런 의미에서 나타난것이다.
이 모델의 성능을 평가하기 위해 4개의 모델과 비교를 하였다.
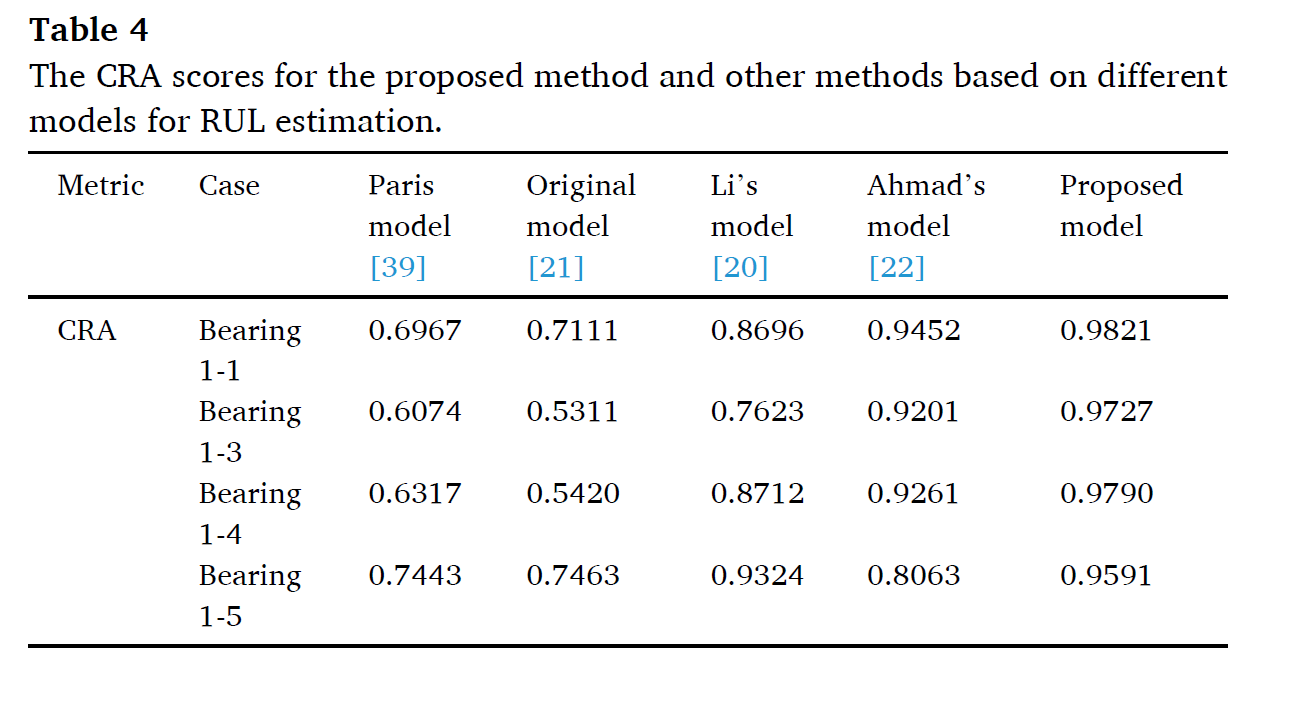
original 모델은 bayesian 파라미터를 업데이트를 진행하는 exponential 모델이다.
Li et al. 은 bayesian exponential 모델을 particle filterling 통한 향상 버전이다.
Ahama's model은 particle filter기반의 bayesian RUL 예측 모델이다.
Paris 모델은 regression 모델에 particle filitering 을 접목한 것이다.
CRA는 특정 period간 RUL예측값의 variation을 나타냄
Conclusions
PSLOC 방법은 anomalies 를 탐지하고 스무스함으로써 베어링 degradation 의 trend를 잘 반영하고 동시에 trend 정보를 보존한다.
이를 통해 정확한 FPT를 탐지할 수 있게 하며, RUL 예측의 정확도를 높인다.
exponential 모델이 또한 향상되는데 SA가 사용되어 예측 정확도를 높인다. 벤치마크 데이터셋이 validation이 활용된다. 제시한 방법론이 좋은 퍼포먼스를 보임을 확인하였다.
향후 HI가 bearing degradation에 더 sensitive하게 발전할 수 있게끔 연구가 필요하다. 또한 물리적인 프로세스이므로, 메카니즘을 접목하여 정밀한 state의 segmentation이 수행될 수 있는 연구가 필요하다.
