ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING FOR ZERO-SHOT ANOMALY DETECTION
ABSTRACT
제로샷 이상 탐지 (ZSAD) 는 타겟 데이터셋의 샘플 없이 이상을 탐지하는 태스크이다. 데이터 프라이버시 등의 문제로 훈련 데이터에 접근할 수 없을 때 중요하지만, 모델이 이상을 다른 도메인에 대해서 일반화해야하기 때문에 도전적이다. 이러한 도메인에서는 제품이나 장기의 이상, 종양과 같은 객체, 비정상 영역, 배경의 특징 외형 등이 다를 수 있다. 최근 CLIP과 같은 대규모 사전 훈련 비전-언어 모델 (VLM) 은 이상 탐지를 포함한 다양한 비전 작업에서 강력한 제로샷 인식 능력을 보였다. 그러나 VLM은 이미지의 비정상성/정상성 보다는 객체의 클래스 의미를 모델링 하는데 초점이 맞춰져 있기 때문에 ZSAD 성능이 약하다.
따라서 본 연구에서는 다양한 도메인에서 ZSAD를 위해 CLIP을 적응시키는 새로운 방법론인 AnomalyCLIP을 제안한다. 이는 객체와 무관하게 이미지에서 일반적인 정상성과 비정상성을 포착하는 객체 비의존적 텍스트 프롬프트를 학습하는 ㄷ것이다. 이를 통해 모델은 객체의 의미보다는 비정상적인 이미지 영역에 집중할 수 있으며 다양한 유형의 객체에서 일반화된 정상성과 비정상성을 인식할 수 있다. AnomalyCLIP은 다양한 결함 검사 및 의료 영상 도메인 데이터셋에서 매우 다양한 클래스 이상을 탐지하고 분할하는 데 있어서 우수한 제로샷 성능을 보인다.
1 INTRODUCTION
이상 탐지 태스크는 산업 결함 검사나 의료 영상 분석에서 널리 적용되고 있다. 기존의 AD 접근법은 탐지 모델을 학습하기 위해 목표 도메인에서 훈련 예제를 활용하지만, 이러한 가정은 데이터 프라이버시위반 혹은 제조현장에서 관련된 데이터가 없는 경우와 같은 상황에서는 맞지 않는다. 제로샷 이상 탐지는 이러한 상황에서 어떤 훈련 샘플도 없이 이상을 탐지하며 다양한 시나리오에서 응용이 가능하다. 하지만 이상은 너무 다양하게 나타나기 때문에 이를 제로샷으로 탐지하기 위해서는 이상에 대한 변화를 강력하게 일반화하며 탐지할 수 있는 모델이 필요하다.
최근 VLM 모델은 이상 탐지를 포함한 다양한 비전 작업에서 강력한 제로샷 인식 능력을 보여주었다. 강력한 일반화 능력으로 다양한 다운스트림 작업을 강화하는 데 적용되었다. CLIP의 일반화 능력을 활용하기 위해 다수의 인공 텍스트 프롬프트를 설계했다. 그러나 VLM은 주로 이미지의 비정상성/정상성 보다는 객체의 클래스 의미론에 맞춰 학습되었기 때문에 시각적 비정상성/정상성을 이해하는 데 있어서 일반화 능력이 제한되고 ZSAD 성능이 약하다. 전역 특성을 효과적으로 객체 의미론 정렬에 맞추는 프롬프트 임베딩을 생성하는 경우도 많아 종종 미세한 지역 특성으로 나타나는 비정상성을 포착하지 못한다.(1d, 1e)

본 논문에서는 AnomalyCLIP이라는 새로운 접근법을 소개하여 CLIP을다양한 도메인에서 정확한 ZSAD를 위해 적용한다. ANomalyCLIP은 이미지에서 일반적인 정상성과 비정상성을 포착하는 객체 비의존적 텍스트 프롬프트를 학습하는 것을 목표로 한다. 먼저, 두 개의 일반 클래스 (정상/비정상) 을 간단한 프롬프트 템플릿을 고안하고, 그 다음에 이미지 레벨과 픽셀 레벨의 손실 함수를 활용한다. 이를 통해 모델이 객체 의미론보다는 비정상적인 이미지 영역에 집중할 수 있도록 하고 보조 데이터와 유사한 비정상 패턴을 가진 비정상을 인식하는 뛰어난 제로샷 능력을 제공한다. 보조 데이터와 목표 데이터의 객체 의미론은 완전히 다를 수 있지만, 비정상 패턴은 유사하게 유지된다. CLIP의 텍스트 프롬프트 임베딩은 다양한 도메인 간의 일반화에는 실패하지만, AnomalyCLIP이 학습한 객체 비의존적 프롬프트 임베딩은 Fig1f에서 다양한 도메인 이미지에서 비정상성을 효과적으로 인식함을 보인다.
따라서 본 연구의 contribution은 다음과 같다.
1. 정상/비정상을 구분하기 위한 객체 비의존적 텍스트 프롬프트를 학습하는 것이 ZSAD에서 효과적이면서 간단하다는 것을 증명함.
2. AnomalyCLIP을 통해서 객체 비의존적 프롬프트 탬플릿과 a glocal abnormality 로스 식을 활용하여 일반적인 비정상/정상 프롬프트를 학습한다. 이를 통해 AnomalyCLIP은 프롬프트 디자인을 크게 단순화하고 두 개의 프롬프트를 변경할 필요 없이 다양한 도메인에 대해 효과적으로 대응할 수 있다. 이는 수백 개의 수동 정의된 프롬프트에 대한 광범위한 엔지니어링에 크게 의존하는 기존 방법에 대조된다.
17개의 산업 및 의료 도메인 데이터셋에 대한 종합적인 실험을 통해 AnomalyCLIP이 결함 검사와 의료 이미지 도메인에서 매우 다양한 클래스 의미론을 가진 데이터셋에서 이상을 탐지하고 세분화하는 데 있어 우수하였다.
2 PRELIMINARY
CLIP은 T(·) : 텍스트 인코더, F(·) : 비주얼 인코더 로 구성된다. 두 인코더는 메인스트림 다층 네트워크로 구성된다. 텍스트 프롬프트를 사용하는 것은 제로샷 인식을 위한 다양한 클래스의 임베딩을 얻는 방법이다. 클래스 이름 c를 포함한 텍스트 프롬프트 템플릿 G를 T(.) 을 통해 전달하여 해당 텍스트 임베딩을 얻는다. CLIP에서 일반적으로 사용되는 텍스트 프롬프트 템플릿은 [cls] 이며, 이는 클래스 이름을 의미한다. F(.)는 이미지를 인코딩하여 시각적 표현을 도출한다. 클래스 토큰은 글로벌 시각적 임베딩으로 취급되며, 패치 토큰은 로컬 시각적 임베딩으로 취급된다. CLIP은 텍스트와 시각적 임베딩 사이의 유사성을 측정하여 제로샷 인식을 수행한다. 대상 클래스 세트 C와 이미지 xi가 주어지면, CLIP은 xi 가 c에 속할 확률을 다음과 같이 예측한다.
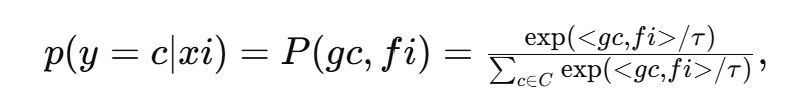
객체 이름을 [cls] 로 사용하는 많은 비전 작업과 달리, CLIP을 사용하여 ZSAD 작업을 수행할 때 객체 비의존적으로 수행해야 하기 때문에 2가지 클래스의 텍스트 프롬프트를 설계하고 이 두 클래스의 가능성을 계산하도록 제안한다. 비정상일 확률 p를 이상 점수로 하며, 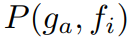
로컬 시각적 임베딩으로 확장되어 각각의 엔트리의 분할 맵에 대응하는 이상점수는 다음과 같다.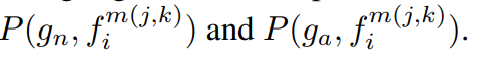
3 ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING
3.1 APPROACH OVERVIEW
본 논문에서는 객체 비의존적 프롬프트 학습을 통해 CLOP을 ZSAD에 적응시키는 AnomalyCLIP을 제안한다. AnomalyCLIP은 객체 비의존적 텍스트 프롬프트 템플릿을 다음과 같이 도입한다. 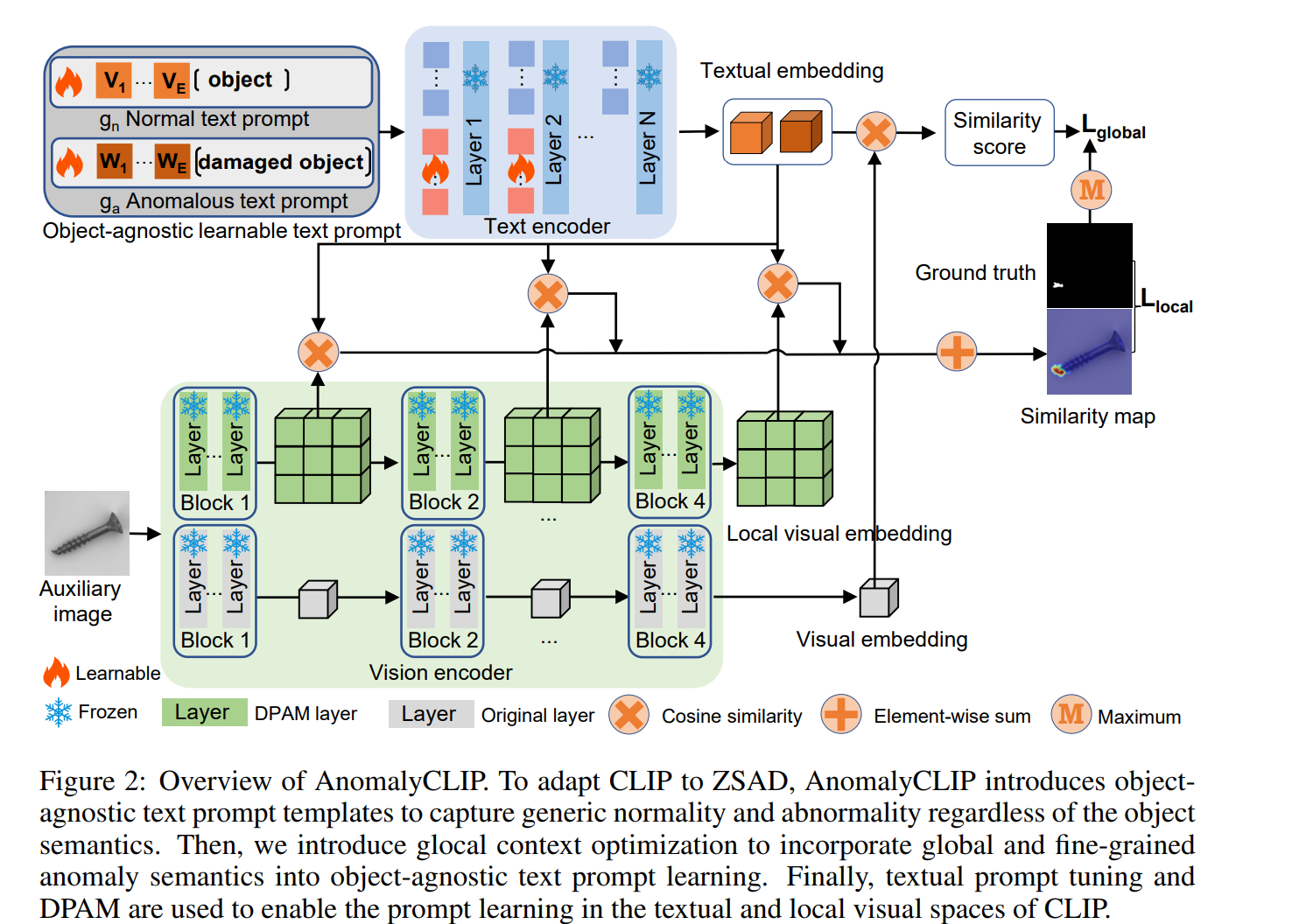
일반화된 임베딩을 학습하기 위해 정상성 클래스와 비정상성 클래스에 각각 해당하는 두 가지 객체 비의존적 테스트 프롬프트 템플릿인 gn 과 ga를 설계한다. 골로벌 및 로컬 이상 의미를 객체 비의존적 텍스트 임베딩 학습에 통합하기 위해 글로벌 및 로컬 context 최적화를 도입한다. 추가적으로, DPAM은 CLIP의 텍스트와 로컬 시각적 공간에서 학습을 지원하기 위해 사용된다. 마지막으로, 더 많은 로컬 시각적 세부 정보를 제공하기 위해 여러 중간 레이어를 통합한다. 추론 시에는 텍스트와 글로벌/로컬 시각적 임베딩의 불일치를 정량화하여 각각 이상 점수와 이상 점시 맵을 얻는다.
3.2 OBJECT-AGNOSTIC TEXT PROMPT DESIGN
일반적으로 CLIP에서 사용되는 텍스트 플홈프트 템플릿은 객체의 의미에 초점을 맞추기 때문에 시각적 임베딩을 쿼리하기 위한 이상 및 정상 의미를 포착하기 힘들다. 가장 간단한 해결책은 특정 이상 유형을 포함하는 템플릿을 설계하는 것이다. 그러나 이상 패턴은 다양하고 알려저 있지 않다면 이렇게 나열하는것은 어렵다. 따라서 일반적인 이상 의미를 포함하는 프롬프트 템플릿을 정의하는 것이 중요하다. 이를 위해 damaged [cls] 와 같은 텍스트를 채택하여 긁힘이나 구멍과 같은 다양한 결함을 감지할 수 있는 포괄적인 이상 의미를 커버할 수 있다. 그러나, 텍스트 프롬프트 템플릿을 사용하는 것은 일반적인 이상을 구별하는 텍스트 임베딩을 생성하는 데 어렵다. 이는 CLIP의 원래 사전 학습이 이미지 내의 이상과 정상 대신 객체의 의미에 맞춰져 있기 때문이다.
이를 해결하기 위해서 학습 가능한 텍스트 프롬프트 템플릿을 도입하고 AD 관련 데이터를 사용하여 조정한다. 파인튜닝 과정에서 이러한 과정은 광범위하고 세부적인 이상 의미를 모두 통합하고, 이를 잘 구별할 수 있는 텍스트 임베딩을 만들어낸다. 이는 수동으로 정의된 텍스트 프롬프트 템플릿의 필요성을 피할 수 있게 해준다. 이러한 텍스트 프롬프트는 객체 인식 텍스트 프롬프트 템플릿이라고 불리며 다음과 같이 정의된다.
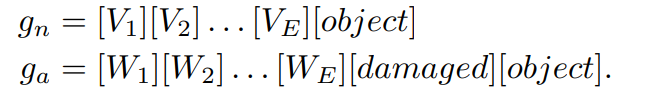
이는 다양한 이상들의 공통된 패턴을 학습할 수 있게 한다. 생성된 텍스트 임베딩은 더욱 일반적이고 다양한 객체와 다양한 도메인에서 이상을 식별할 수 있는 능력을 갖추게 된다. 이는 대상 데이터셋에서 객체 이름이나 이상 유형에 대한 지식이 필요 없음을 의미한다.
3.3 LEARNING GENERIC ABNORMALITY AND NORMALITY PROMPTS
Glocal context optimization
글로벌 및 로컬 관점에서 정상 비정상 프롬프트를 학습하는 방법은 global and local context optimization 이라고 한다. 다양한 객체의 이미지에 대한 글로벌 시각적 임베딩과 객체 비의존적 텍스트 임베딩을 일치시킨다. 이를 통해 글로벌 특징 관점에서 정상/이상 의미를 효과적으로 포착한다. M을 중간 레이어의 집합이라고 하면, 텍스트 프롬프트는 다음과 같은 전역적 손실 함수를 최소화하여 학습된다.
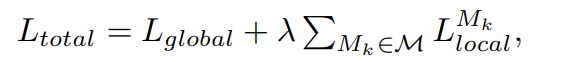
L_global은 보조 데이터의 정상/이상 이미지에 대한 객체 비의존적 텍스트 임베딩과 시작적 임베딩 사이의 코사인 유사성을 정렬한다. S는 그라운트트루쓰 분할 마스크이며, S=1 이라면 해당 픽셀은 비정상 인 것이고, 0 이면 정상이다. 따라서 다음과 같이 볼 수 있다.
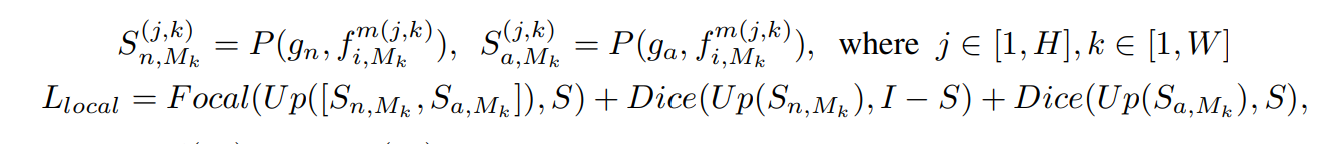
여기서 Focal과 Dice는 focal loss, Dice loss이다. 이상 영역은 일반적으로 정상 영역보다 작기 때문에 불균형 문제를 해결하기 위해 Focal 로스를 사용한다. 또한 모델이 decision boundary를 정확히 설정할 수 있게 Dice 손실을 사용한다.
Refinement of the textual space
텍스트 공간을 정확히 학습하기 위해 텍스트 프롬프트 튜닝을 도입하였다. CLIP의 텍스트 공간을 튜닝하는데, 이를 위해 추가적으로 학습 가능한 토큰 임베딩을 텍스트 인코더에 추가한다. 임의로 초기화된 토큰 임베딩t'm을 동결된 CLIP 텍스트 인코더의 m번째 레이어 Tm 에 붙인다. 그리고, t'm과 토큰 임베딩 tm을 채널 차원에 연결하고 Tm에 전달하여 해당하는 새로운 학습 가능한 토큰 임베딩 t'm+1 을 얻는다. 이는 self-attentionm 학습 매커니즘을 통해 업데이트된 그래디언트가 t'm을 최적화하기 위해 업데이트되고 지정된 레이어에 도달할 때 까지 반복한다.
Refinement of the local visual space
CLIP의 시각 인코더는 전역 객체 의미론과 정렬되도록 사전 학습된다. self-attention 학습을 통해 이러한 토큰들은 전역 객체 인식에 기여할 수 있지만, 객체에 상관없는 텍스트 프롬프트에서 세밀한 이상 탐지 학습을 직접적으로 저해한다. 훈련 중에 시각 인코더를 동결 상태로 유지하면서 국부적인 시각 공간을 정제하기 위해 DPAM(Diagonally Prominent Attention Map)을 제안한다.
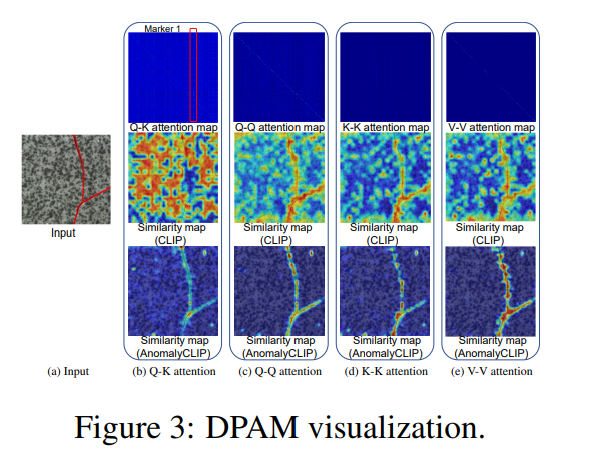
이는 시각 인코더의 Q-K attention을 대각 prominent attention으로 대체하는데, Q-Q, K-K, V-V 가 있다. c, d, e는 각각의 결과를 나타낸 것이다. 이 맵들은 대각선으로 두드러지기 때문에 원래 CLIP에 비해서 AnomalyCLIP이 개선된 분할 맵을 생성하게 된다. 이는 더 세밀하며, 이상/정상 텍스트 프롬프트 임베딩과 시각 임베딩의 정렬을 정확하게 한다. AnomalyCLIP은 V-V 자가self-atteion 학습을 수행한다.
4 EXPERIMENTS
4.1 EXPERIMENT SETUP
17개의 공개 데이터셋을 실험하였다.
SOTA 방법론으로는 CLIP, CLIP-AC, WinCLIP, VAND, CoOP 가 포함된다.
Implementation details
백본으로 CLIP 모델을 활용한다. 모델의 파라미터는 모두 frozen 된다. 학습가능한 워드 임베딩 E 는 12의 길이를 갖는다. 학습하능한 토큰 임베딩들은 첫 9레이어에 부착되며, 그들의 길이는 4이다. AnomalyCLIP을 파인튜닝한다.
4.2 MAIN RESULTS
ZSAD performance on diverse industrial inspection domains
ANomalyCLIP과 다섯 가지 방법론과 비교해 보았을 때, 대부분의 데이터셋에서 다른 다섯 가지 방법보다 우수하였다. 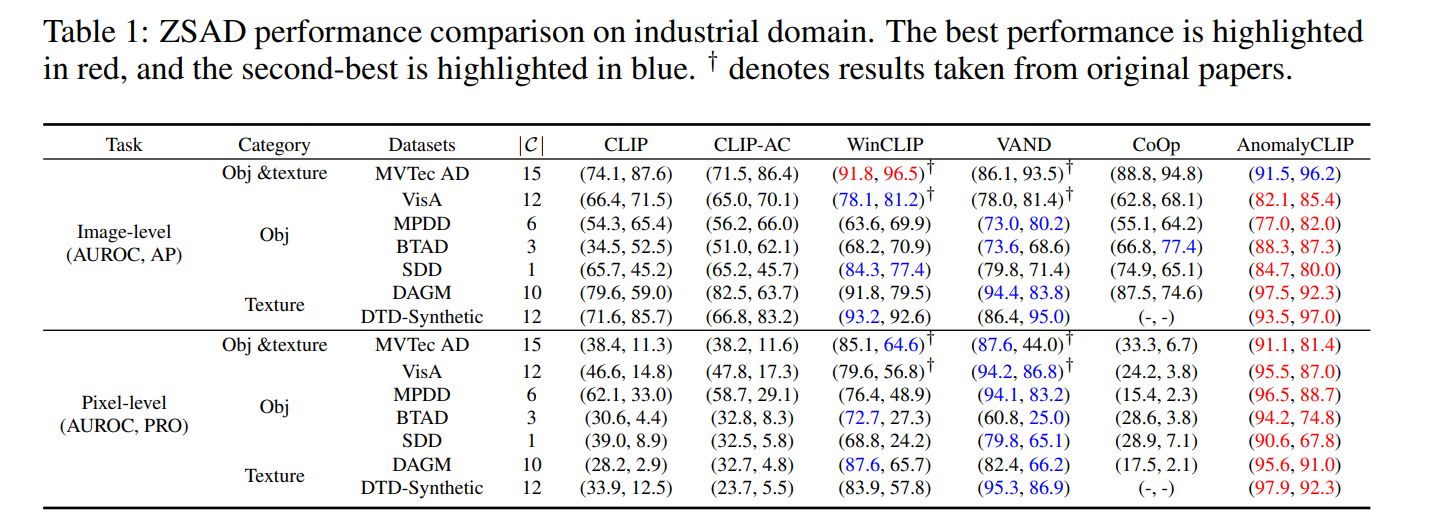
CLIP과 CLIP-AC는 객체 의미에 초점을 맞추기 때문에 낮다. 수동으로 정의된 텍스트 프롬프트를 사용하는 WinCLIP과 VAND는 더 낫다. 반면에 CooP는 학습 가능한 프롬프트를 사용하여 전역 이상 의미를 학습하기는 하지만, 이러한 프롬프트는 전역 특징에 초점을 맞추고 지역적 특성을 무시하기 때문에 성능이 좋지 못하다.
AnomalyCLIP은 CLIP을 ZSAD에 맞춰 다양한 도메인의 데이터셋에 대해 일반화가 가능했다. 이는 다음과 같이 시각화된다.
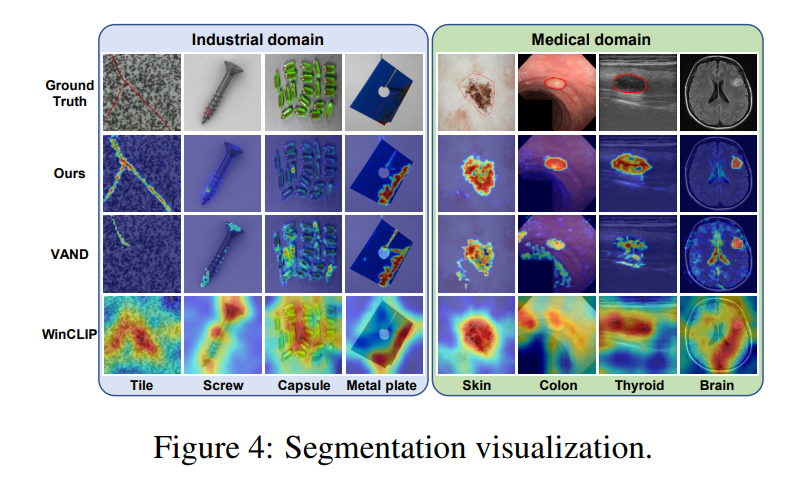
Generalization from defect datasets to diverse medical domain datasets
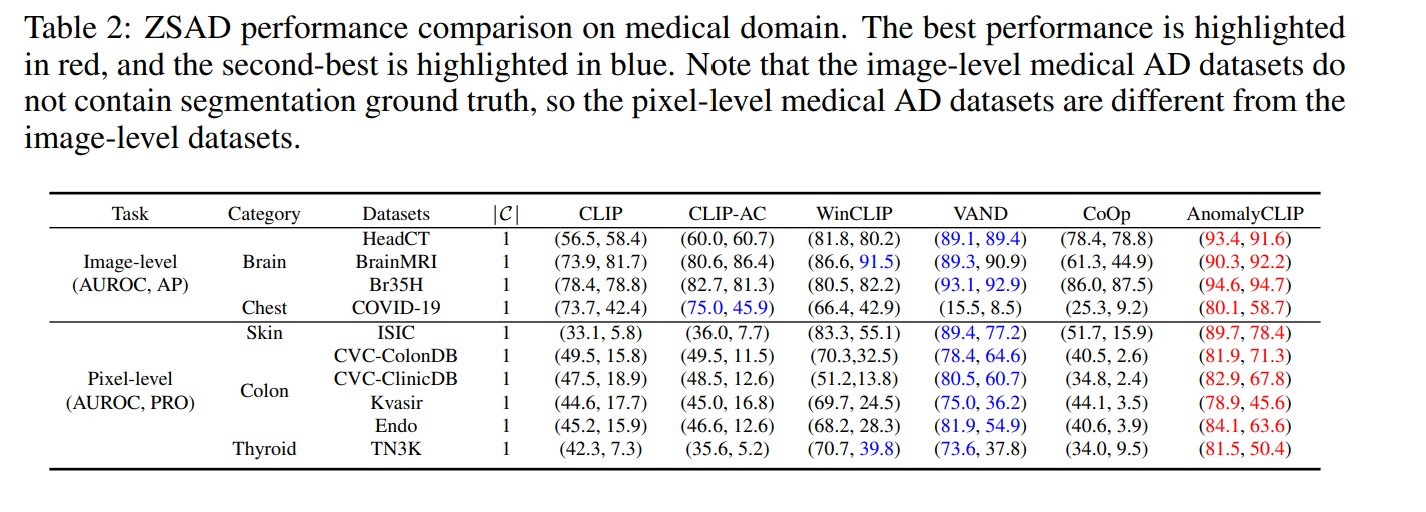
일반화 능력을 평가하기 위해 10개 의료 이미지 데이터셋에서 추가로 조사하였다. 이는 의료 영상 도메인에서 매우 다양한 객체 의미를 가진 데이터셋에서 AnomalyCLIP의 ZSAD 성능을 보여준다.
Can we obtain better ZSAD performance if fine-tuned using medical image data?
산업 데이터셋에서의 성능과 비교해보면, AnomalyCLIP은 의료 데이터셋에서 상대적으로 낮은 성능을 보인다. 부분적으로 프롬프트 학습에 사용된 보조 데이터의 영향 때문이다. 문제는 이미지 레벨 및 픽셀 레벨의 레이블이 된 대규모 2D 의료 데이터셋은 훈련에 사용이 불가하다. 따라서, ColonDB를 통해 데이터셋을 생성하고 다른 모델과 비교하였다.
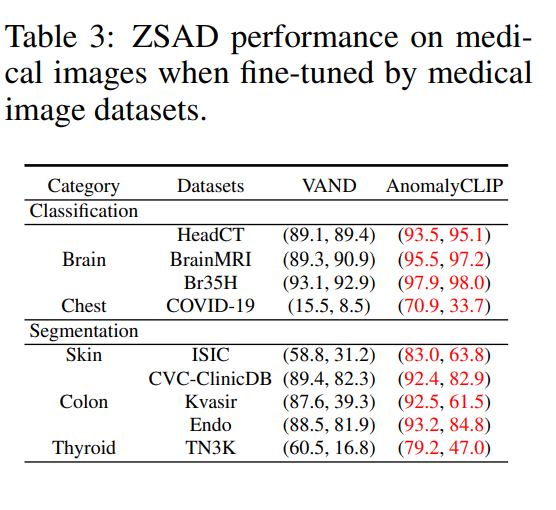
전체적으로 AnomalyCLIP과 VAND는 성능을 비교해본결과 AnomalyCLIP이 더 좋은 성능을 분류와 분할 모두에서 보였다.
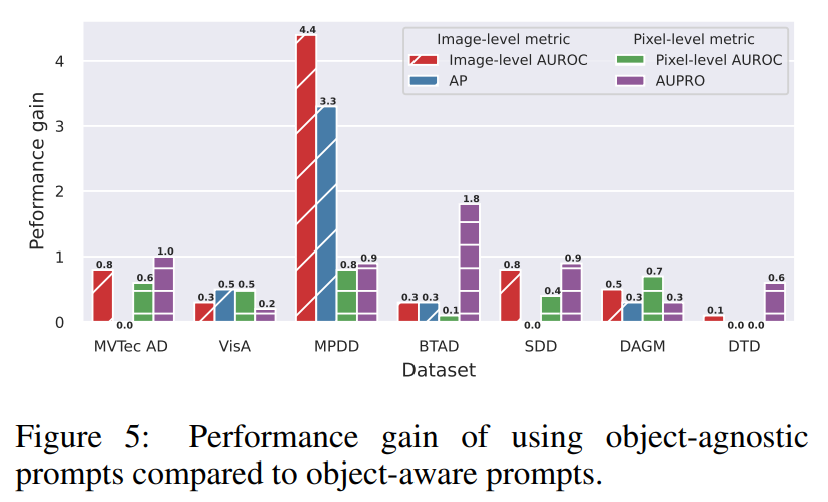
Object-agnostic vs. object-aware prompt learning
AnomalyCLIP에서 객체 비종속 프롬프트 학습의 효과를 연구하기 위해서 객체 인지 프롬프트 템플릿을 사용하는 변형과 AnomalyCLIP을 비교하였다. 결과는 AnomalyCLIP의 객체 비종속 프롬프트 학습이 이미지 레벨과 픽셀 레벨의 이상탐지에서 훨씬 우수하다는 것이다.
4.3 ABLATION STUDY
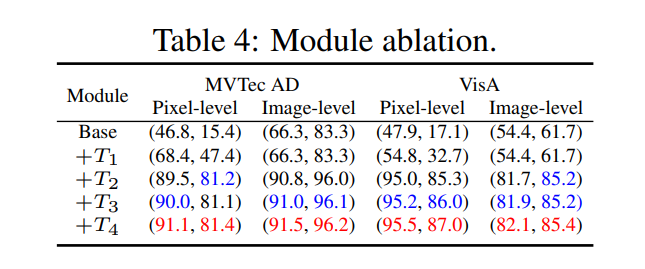
Module ablation
모듈 ablation 결과 다음과 같이 T1(DPAM), T2(객체 비종속 텍스트 프롬프트), T3(텍스트 인코더에 학습 가능한 토큰 추가), T4(다층 비주얼 인코더 특징) 을 포함하여 ablation 스터디가 수행되었다. 각 모듈은 AnoamlyCLIP에 성능에 기여함을 알 수 있다.
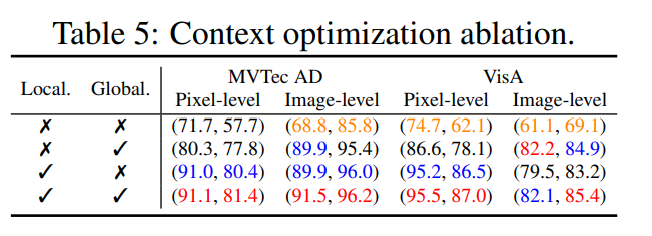
Context optimization
global-local 문맥 최적화를 없애는 경우에는 다음과 같이 나타난다. 따라서, 글로벌 문맥 최적화는 이미지 레벨의 탐지를 더욱 정확하게 만들며, 로컬 문맥 최적화는 로컬 이상 정보를 포함하여 픽셀 수준의 성능을 개선한다. 이 둘을 각자 사용하는것 보다 동시에 사용하는것이 일반적으로 성능이 좋았다.
DPAM strategy ablation
V-V를 기본적으로 사용하는데, 다른 Q-Q와 K-K self-attention을 수행한 결과는 다음과 같다.
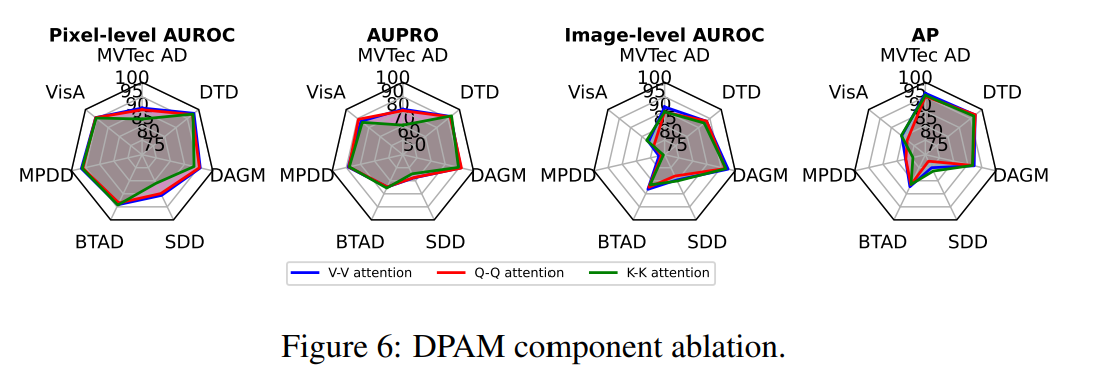
전체적으로 C-C가 AnomalyCLIP에서 성능 향상이 있었다.
6 CONCLUSION
본 논문에서는 훈련을 위한 타겟 데이터셋이 없는 이상 탐지의 ZSAD에 대해 다룬다. 이는 CLIP의 ZSAD에 대한 일반화 성능을 강화하기 위해 AnomalyCLIP을 제안하였다. 이는 일반화된 ZSAD를 위해 비정상/정상 객체 비종속 프롬프트 학습을 설계하였다. 또한 AnomalyCLIP에 글로벌 및 로컬 이상을 포함하기 위해서 객체 비종속 텍스트 프롬프트를 최적화하기 위한 글로벌 및 로컬 문맥 최적화 기법을 제안하였다. 실험 결과 AnomalyCLIP이 우수한 ZSAD 성능을 달성하였다.
