WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Abstract
Visual anomaly classification과 segmentation은 산업에서 품질 검사 자동화에 매우 중요하다. 기존의 연구들은 각 품질 검사 작업에 맞춘 맞춤형 모델을 훈련하고, 작업별 이미지와 annotation이 필요하다. 하지만 본 연구에서는 이러한 문제를 해결하고자 제로샷 및 few-noramal 샷을 통해서 이상을 분류하고 segmentation 태스크를 수행한다.
최근 CLIP는, 비전 언어 모델로 제로/퓨 샷 퍼포먼스를 full-supervision 방법론에 비교해서도 경잴력 있게 하였다. 하지만 CLIP는 anomaly classification 태스크 에서는 실패하였다. 그러므로 우리는 윈도우 기반의 CLIP(winCLIP)를 통해 1) 단어에 compositional ensemble과 prompt templates에 대한 구체적인 앙상블을 제안하며, 2) 윈도우/패치/이미지 레벨의 특질을 text와 정렬하여 효과적인 extraction과 aggregation 방법론을 제안한다. 또한 정상 이미지의 보완 정보를 사용하여 few-normal-shot의 extension을 제안한다. MVTec-AD데이터에서 튜닝없이, WinClIP은 91.8/85.1%의 AU-ROC를 제로샷 이상 분류와 segmentation을 보였으며, WINCLIP+는 93.1%/95.2%을 보여 SOTA 방법론을 능가하였다.
1. Introduction
Visual anomaly classification (AC) 와 segmentation (AS) 분야는 산업 제조에서 이미지를 정상 또는 이상으로 예측한다. 그러나 두 가지 문제가 있다.
1) 결함이 드물고, 변동 범위가 넓어 훈련 데이터에 이상 샘플이 부족
2) 이전 연구들은 각 태스크에 맞게 맞춤형 모델을 훈련하고, 롱 테일 작업 전반에 걸쳐 확장이 힘들다.
비전-언어 모델은 제로샷 분류 작업에서 가능성을 보여주었다. 이는 광범위한 표현을 학습하면서, 텍스트 프롬프트를 활용하여 다운스트림 태스크로 제로/퓨 샷을 위한 특질을 추출할 수 있었다. CLIP는 몇 안되는 오픈 소스 비전-언어 모델이며 일반화 능력을 바탕으로 low-shot 퍼포먼스를 full supervision에 비해 경쟁력있게 확보할 수 있다.
본 연구에서는 제로샷/few-normal-샷에 중점을 두었다. 우리는 언어가 제로샷/few-normal-샷 anomaly classification/segmentation에 중요할 것이라 가정한다. 이는 여러 관찰에서 나왔는데 정상과 이상은 객체의 상황에 따라 달라지며, 언어는 이러한 상태를 명확히 하는데 도움이 된다. 예를 들어서 천에 구멍이 생긴 것이 일반 패션인지 의도된 스타일인지에 따라 정상과 이상 상태가 결정된다. 언어는 이러한 맥락과 구체성을 넓은 장상과 이상 상태에 가져올 수 있다. 또한 언어는 정상 상태에서 허용 가능한 정보를 추가로 제공할 수 있다.

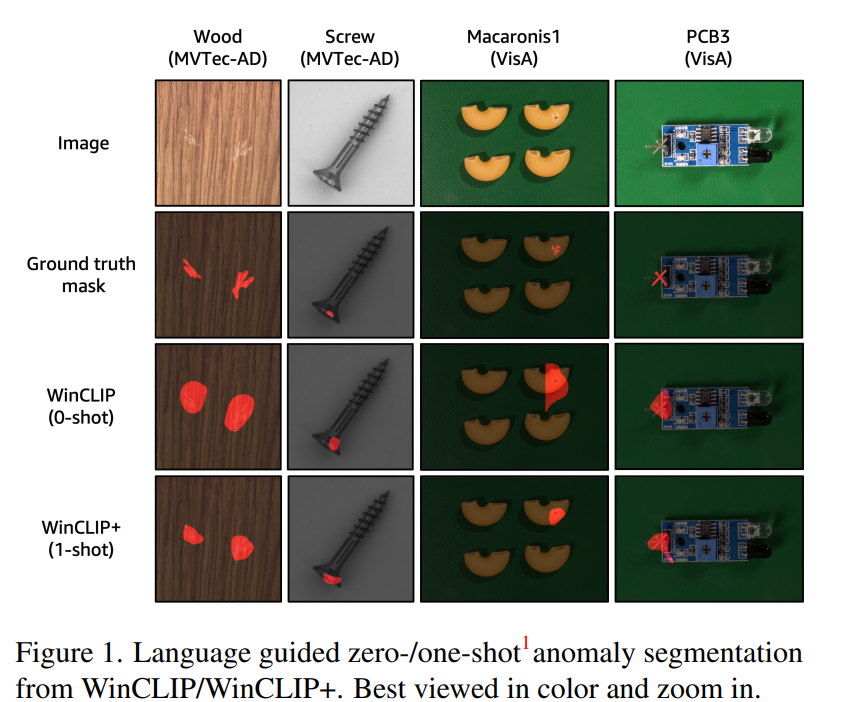
(a)에서 언어는 납땜 결함에 대한 정보를 제공하고, 배경의 작은 긁힘과 얼룩은 허용한다. 하지만 이상 분류 및 분할을 위해 비전 - 언어 모델을 활용한 연구는 없다. 따라서 본 연구에서는 사전 훈련된 CLIP를 통해 언어가 제로/few-normal-shot 에서 이상 분류/segmentation에 도움이 된다는 가설을 검증한다. 그러나 단순한 프롬프트는 효과적이지 않다. 정상 및 이상 상태를 더 잘 설명하기 위해 상태 수준 단어 앙상블로 단순한 기준선을 개선한다. 또한 CLIP가 이미지와 텍스트의 글로벌 임베딩에만 교차 모달 정렬을 적용하도록 훈련된다는 것이 문제가 된다. 이상 분할을 위해 픽셀 수준의 분류를 해야 하는데, 제로샷 이상 분할을 위해 언어와 정렬된 밀집 시각적 특징을 추출하는것은 간단하지 않다. 따라서 비전-언어 정렬을 보장하면서 다중 스케일 특징을 추출하고 집계하는 새로운 윈도우 기반 WINCLIP을 제안한다. 여러 스케일은 2b에 나와있다. 언어 기반 WinCLIP과 정상 참조 이미지의 시각적 단서를 결합한 WINCLIP+ 를 도입한다. 이는 2c로 보여진다. 제로샷 모델이 개별 사례에 대한 튜닝이 필요하지 않으며, 소수 정상만 있는 환경에서는 분할 주석을 사용하지 않아 광범위한 시각적 검사 작업에 적용 가능함을 보인다. Fig 1은 WinCLIP과 WinCLIP+의 결과를 나타낸다.
따라서 본 연구의 contribution은 다음과 같다.
1. 단순한 CLIP 기반 제로샷 분류보다 제로샷 이상 분류를 개선하는 프롬프트 앙상블을 제안한다.
2. 이미지 기반 소수샷 이상 분할을 위해 다중 스케일 특징 맵에 적용되는 간단한 참조 연관 방법을 제안한다.
3. WinCLIP+ 는 소수 정상 샷 이상 인식을 위해 언어 기반 및 비전 전용 방법을 결합한다.
4. MVTec-AD 와 VisA 벤치마크 데이터셋을 통해 우리의 WinCLIP/WinCLIP+의 성능을 검증하고 SOTA를 달성하였다.
2. Related work
Vision-language modeling
대형 pre-trained 비전-언어 모델 (VLM) 의 최근 성공으로, CLIP는 웹 스케일의 이미지-텍스트 데이터에 대해서 프리트레이닝을 수행하여 전례없는 일반화 성능을 보였다. 제로샷 추론의 강건성을 증가시키며, 더 나은 정렬을 보인다. VLM 연구들은 넓은 스케일의 pre-training 을 다른 aspects로 나타나는데, 데이터의 스케일링업이나, 효과적인 디자인, 멀티태스크 등등이 있다. 다른 도메인들에 대한 라지스케일의 VLM 활용을 촉진하기 위해서 LAION-5B 데이터에 대해서 오픈소스로 공개화가 되어 있다. 이 CLIP를 언어로 가이드된 탐지와 segmentation을 위해 활용하는 것은 좋은 퍼포먼스를 보인다.
Anomaly classification and segmentation
anomalies의 희귀성으로 인해 주된 포커스는 정상 이미지에 대해서 집중되고 있었다. MVTec-AD 벤치마크 데이터는 이전 연구들에서 사용되었지만, 구체적인 적용은 full-normal-shot 에서만 가능했다. 최근 연구는 few-shot 으로 더 좋은 정상성을 모델링하는데 집중하고 있다. RegAD는 모델을 재사용하여서 unseen object에 대해 few-shot 으로도 일반화 성능이 좋다. 반면에 academic 데이터와 산업 데이터의 gap 으로 인하여, VisA가 MVTec-AD보다 더 현실성있게 제안되었다. ViT는 특히 시각 inspection에 더 포텐셜이 있다.
State classification
Anomaly classification 이 state classification으로 볼 수 있는게, normal 과 anomalous 를 구분하게 되는 것이다. CV는 object, scene, material recognition 에 초점을 맞췄다면, state classification은 오브젝트의 물리적 특성이나 속성에대해서 구분하는 것이다.
3. Background
Anomaly classification and segmentation.
AC는 x-> {-,+} 로 맵핑하는 이진분류 문제이다. +는 이미지 레벨에서의 anomaly를 말한다. AS는 픽셀 레벨에서의 anomalies의 location 아웃풋으로 x-> {-,+}^hxw 이다. Threshold 보다 스코어가 넘으면 binary classification이 수행된다.
anomalous의 샘플 부족으로 one-class scenario로 정상 데이터만 이용가능하다는 가정하에 연구가 많이 진행되고 있다. 본 연구에서는 one-class의 프로토콜을 따라가지만, 특정하게 few-shot (K=1~4) 까지, 그리고 zero-shot만 가정한다.
Zero-shot classification with CLIP
CLIP는 million scale로 이미지-텍스트 페어가 있기 때문에 CLIP는 이미지 인코더 f와 텍스트 인코더 g를 대조 학습을 통해 f(xt) 와 g(st)의 상관을 코사인 유사도로 최대화한다. CLIP는 zero-shot 분류를 k-way 카테고리 분포를 통해 수행한다.
CLIP는 언어 인터페이스를 통해 시각적 지식을 재조면 하며, 본 연구에서는 이렇게 활용하는 지식을 anomaly recognition에 더 적합하게 만들고자 한다.
4. WinCLIP and WinCLIP+
4.1. Language-driven zero-shot AC
Two-class design
CLIP-AC 를 binary zero-shot anomaly classification 프레임워크를 제안한다. 2개의 클래스의 프롬르프트가 존재하는데, "normal [o]", "anomalous [o]" 이다. [o] 는 오브젝트 레벨의 레이블이다. 또한 one-class 디자인을 normal 프롬프트만을 가지고 디자인하기도 하였다. 실험 결과 CLIP은 simple한 two-class의 디자인이 one-class보다 월등히 성능이 좋으며, 좋은 퍼포먼스를 위해서는 투클래스 디자인이 필수임을 보인다. 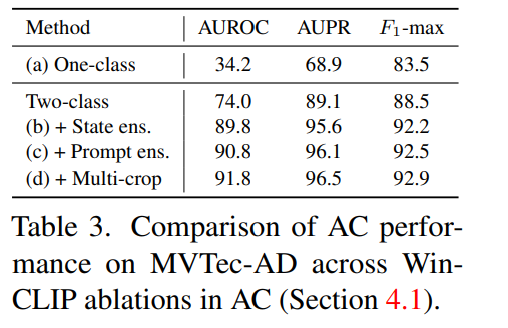
Compositional prompt ensemble (CPE)
오브젝트 레벨의 분류기와는 다르게, CLIP-AC는 object가 주어졌을 때 2개의 state를 구분한다. normal과 abnormalous 를 구분하는 과정은 태스크에 따라 다양한 정의가 내려질 수 있다. 따라서 물체의 추상적인 정상과 비정상을 더 정확히 정의하기 위해서 a Compositional Prompt Ensemble 을 제안하여 모든 state words들의 레이블에서과 text templates 의 모든 조합을 생성한다. 상태 단어는 대부분의 객체가 공유하는 일반화된 상태를 나타낸다. 또한, 특정 결함에 대해서 사전 지식을 바탕으로 특정 상태 이상 단어를 추가할 수 있다.

이 그림의 왼쪽 상단과 같이 상태와 템플릿의 모든 조합을 얻은 뒤, 레이블당 텍스트 임베딩의 평균을 계산하여 정상 및 이상 클래스들을 나타낸다.
CPE는 CLIP의 프롬프트 앙상블과는 다르다. CLIP 프롬프트 앙상블은 객체 라벨을 설명하지 않고, 객체 분류를 위해 선택된 템플릿만을 나타내며, 이상 탐지 작업에는 적합하지 않은 템플릿을 포함하기도 한다. CPE의 텍스트는 CLIP의 임베딩에서 이상 탐지 작업에 적합한 것들을 추출ㄹ해 내고, 제로샷 스코어링 모델을 이미지 임베딩 f(x) 를 통해 나타낸다.
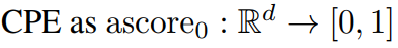
4.2. WinCLIP for zero-shot AS
CPE를 기반으로 winCLIP을 제안한다. 이는 언어를 통한 정렬과 로켈 디테일을 가진 밀집된 시각적 특징을 추출한 뒤, ascore0을 공간적으로 적용하여 이상 분할 맵을 생성한다.
1. 슬라이딩 윈도우 세트를 생성한다.
2. 활성 영역에 대해서 계산된 출력 임베딩을 다음과 같이 정의한다. 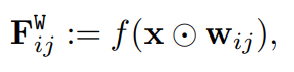
이는 ViT를 활용한 WinCLIP의 밀집 특징 추출을 의미한다.
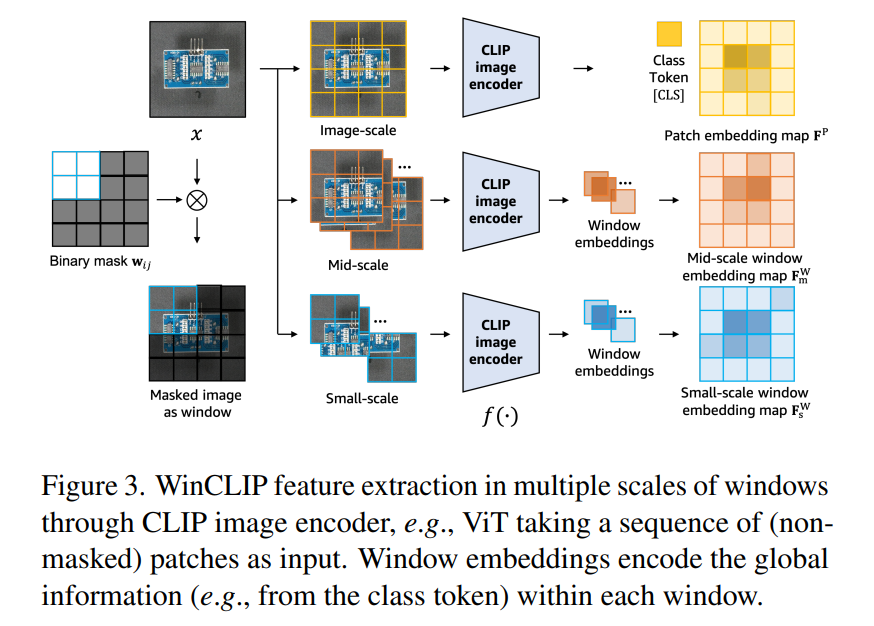
ViT기반 CLIP의 패치 임베딩 맵은 패치 수준의 특징들이 언어 공간과 정렬되지 않아 밀집된 예측에서 결과가 좋지는 못했다. 이는 CLIP에서 언어 신호가 로컬 디테일을 포착하는데 방해하기 때문이다. 우리는 WinCLIP의 밀집 특성이 언어와 더 잘 정렬됨을 알 수 있다. ViT 기반 CLIP의 경우에는 모든 특징이 CLIP의 사전 학습된 클래스 토콘이 텍스트와 직접 정렬되어 나타난다. WinCLIP은 특히 ViT 아키텍처와 함께 효율적으로 이를 계산하여 마스크된 모든 패치를 전달하기 전에 일바를 삭제하는 마스크드 AE와 비슷한 방식으로 작동하게 된다.
4.3. WinCLIP+ with few-normal-shots
포괄적인 이상 분류 및 분할을 위해서는 언어로 유도된 제로샷만으로는 충분하지 않다. 이는 특정 결함이 텍스트로만 정의될 수 없기 때문이다. 이상을 보다 정확하게 정의하고 인식하기 위해서 WinCLIP+를 제안한다. 이는 K개의 정상을 참조하여 언어로 유도된 방법과 시각적 접근법의 상보적 예측을 결합하여 더 나은 이상 분류 및 분할을 제공한다.
참조 이미지를 통합하는 주요 모듈로서 참조 연관을 제안한다. 코사인 유사도 기반으로 D의 메모리 특징을 저장하고 검색한다. 이러한 모듈과 쿼리 이미지에서 추출된 특징이 주어졌을 때 이상 분할을 위한 예측을 할 수 있다.
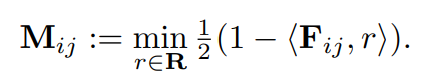
이어서 연관 모듈을 WinCLIP에서 얻은 다양한 크기의 특징 맵에 적용하낟. 소수의 샘플이 주어졌을 때 별도의 참조 메모리를 구성한다. a) 소규모의 WinCLIP 특징, b) 중간 규모의 WinCLIP특징, c) 전역 컨텍스트를 가진 마지막 특징
결과적으로 WinCLIP+ 는 세 가지 참조 메모리를 얻는다. 그런 다음, 주어진 쿼리에 대해 이상 분할을 위한 다중 스케일 예측을 평균화한다.
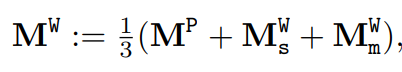
이상 분류를 수행하기 위해서, 이 값과 WinCLIP 제로샷 분류 점수를 결합한다. 이 값은 다음과 같다.
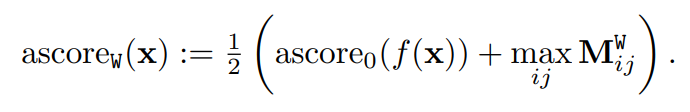
5. Experiments
Datasets.
MVTec-AD , VisA
Evaluation metrics.
분류
Area Under the Receiver Operating Characteristic (AUROC), Area Under the Precision-Recall curve (AUPR), F1-score at optimal threshold
분할
pixel-wise AUROC (pAUROC), Per-Region Overlap (PRO) scores , (pixel-wise) F1-max
5.1. Zero-/few-shot anomaly classification
few-normal-shot 셋업에서 2개의 prior works를 비교한다. 첫 번째는 원래의 CLIP 제로샷 분류 모델이고, 두 번쨰는 이미지넷을 위해 고안된 프롬프트 앙상블을 사용하는 CLIP-AC 이다. WinCLIP은 이 두가지에 비교하여 성능이 더 좋았다.
몇 개의 정상 샷이 주어진 경우에도 비슷한 경향이었다. MVTec-AD 에서는 제로샷 WinCLIP이 이전의 few-shot 버전보다 뛰어났다. 또한 WinCLIP+의 1/2/4 shot 성능이 제로샷보다 우수하였다.

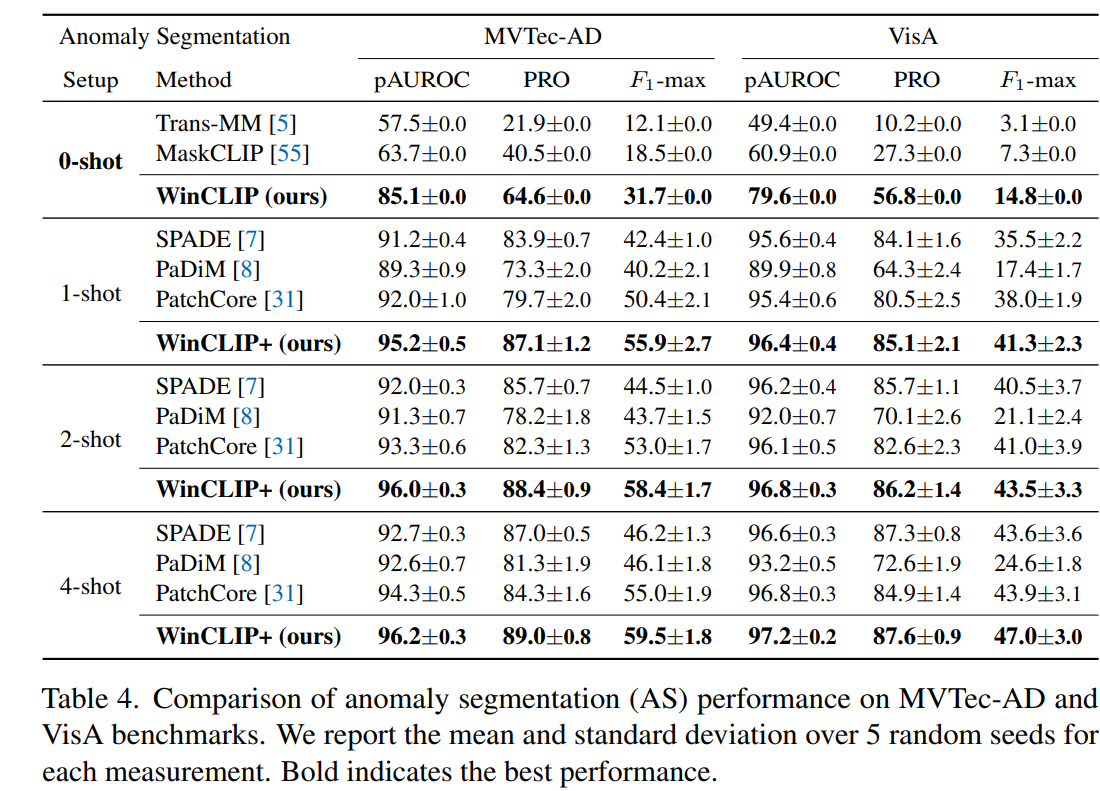
5.2. Zero-/few-shot anomaly segmentation
제로샷 이상 분할에 대한 이전 연구는 따로 존재하지는 않지만, 두 가지 방법을 변형하여 사용하면 다음과 같다. 1. Trans-MM은 트랜스포머 모델을 위한 최근 모델 해석 방법으로 픽셀 수준의 마스크를 제공한다. 2. MaskCLIP은 MVTec-AD와 VisA 데이터셋 모두에서 두 방법을 크게 능가 한다. 이는 CLIP의 일반적인 변형이 WinCLIP만큼 성능을 발휘하지 못하기 때문이다.
몇 개의 정상 샷을 사용하는 setup에서는 3가지 이전 작업들과 비교했다. WinCLIP+ 는 두 벤치마크에서 모든 지표에서 이전 방법들을 능가했다. 이는 언어 프롬프트가 제공하는 추가적인 가치를 보여주며, 여러 객체와 결함에 대한 질적 결과를 보여준다. 모든 경우에 있어서 1-shot WinCLIP+는 이전 작업들보다 정답에 더 집중된 마스크를 제공한다. 또한, 1/2/4-normal-shot WinCLIP+는 제로샷 WinCLIP보다 더 나은 성능을 보였다. 이는 언어 기반 예측과 참조 정상 이미지를 기반으로 한 시각적 모델의 상호 보완적인 이점을 입증한다.
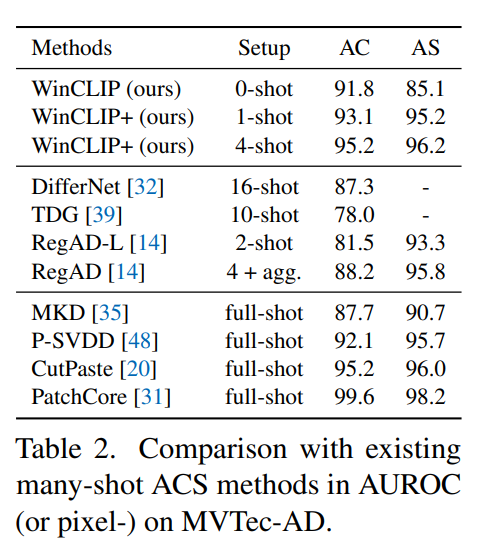
5.3. Comparison with many-shot methods
우리의 4-shot WinCLIP+는 모델 튜닝을 위해 풀샷 샘플을 사용하는 최근 방법과 경쟁할 수 있다. CutPaste 와 비교하여 경쟁력이 있으며, WinCLIP은 최근 몇 샷 학습 방법들인 DifferNet과 TDG를 능가한다. 이들의 10샷 이상보다 제안한 방법론의 성능이 좋았다.
5.4. Ablation study
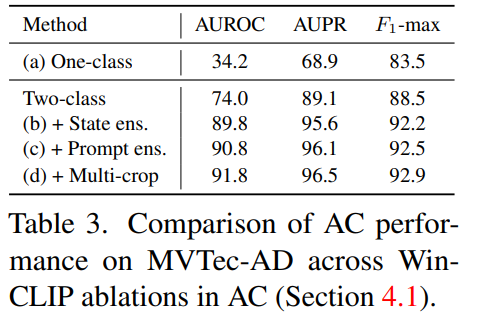
WinCLIP for AC: 제로샷 AC 모델을 구성할 때 a) anomalous 의 단어를 주었을 때 리즈너블한 퍼포먼스를 보였다. 이는 비정상성에 대한 CLIP 효과를 나타낸다. b) state-lebel, c) promt-level 에서의 텍스트를 비교한다면 다양성을 갖추는 것이 성능 향상의 주요 원천이다.
마지막으로 d)로 multi-crop prediction을 통해서 마이너한 improvement를 보였다.
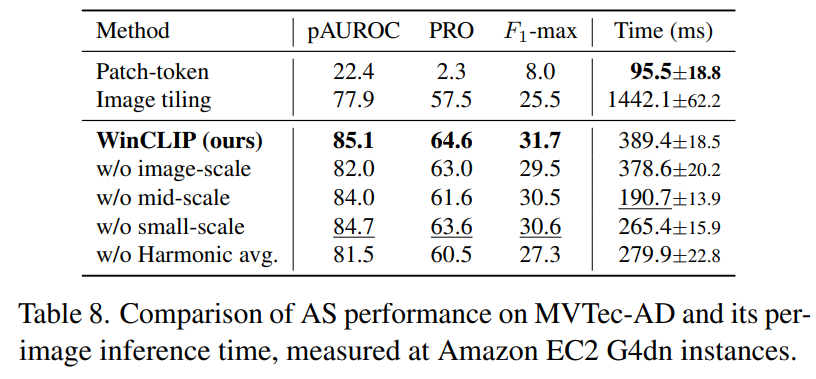
WinCLIP for AS: Table8. 을 통해서 WinCLIP이 제로샷 이상 분할을 위해 로컬 특징을 추출하는 효율 뿐 아니라, 결과를 향상시키기 위한 다중 스케일과 조화 평균의 효과를 검증한다. 패치 토큰은 빠른 추론 시간을 가지지만 언어와 정렬되지 않는다. 이미지 타일링은 로컬 특징을 활용할 수 있지만, 상당한 계산 오버헤드를 발생시킨다. WinCLIP은 로컬 특징을 윈도우 기반으로ㅓ 계산하여 더 나은 성능을 보이면서도 추론 속도를 가속화 한다. 이미지 수준의 특징과 중간/로컬 컨텍스트 모두에서 분할 성능이 향상된다.
WinCLIP with task-specific defects: 일반적인 경우를 다루는 것 외에도 특정 작업에 맞는 상태 단어도 지원한다. 특히 VisA 와 MVTec-AD는 특정 결함 유형을 제공한다. 특정 상태 단어가 VisA에서 제로샷 분류 성능을 평균 AUROC 기준으로 0.8% 개선하고, 특히 PCB2에서 5.3%의 성능 향상을 가져온다는 것을 보여준다. 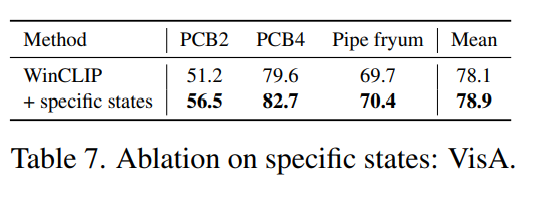
- Conclusion
정상과 비정상을 미세 텍스트 정의와 정상 레퍼런스 이미지를 통해 AC, AS 태스크를 수행하는 프레임워크를 제안하였다. 대규모 웹 데이터로 사전 훈련된 CLIP이 텍스트와 이미지 간의 우수한 정렬을 제공하여 이상 인식 작업에서 강력한 표현력을 발휘한다는 것을 보였다. 조합 프롬프트 앙상블은 텍스트로 정상성과 이상성을 정의하며, 사전 훈련된 CLIP으로부터 지식을 추출하여 더 나은 제로샷 이상 인식을 가능하게 한다. WinCLIP은 윈도우 및 이미지 수준에서 다중 스케일 특징을 통해 제로샷 segmentation을 수행한다. 몇 개의 정상 샘플이 주어진다면, 시각 기반의 레퍼런스 association은 언어 정의와 두 상태에 대한 보완적인 정보를 제공하여 few-shot WinCLIP+ 가 가능하게 한다. 최근 벤치마크 데이터를 통해 기존의 SOTA 방법론을 뛰어넘는 성능을 보였다.
