Comparative analysis of machine learning models for anomaly detection in manufacturing 요약
Abstract
본 연구에서는 anomaly detection을 위한 10가지의 머신러닝 방법론을 평가함. Conventional한 머신러닝 방법론과 딥러닝 방법론 또한 포함함. 머신러닝 모델은 실제 공정 스케쥴 상에서 anomaly를 detect 하고, 다양한 feature를 학습함. 머신러닝 모델의 평가는 ground truth 를 위해 제작된 데이터를 활용하였음. 결과는 conventional 한 KNN 알고리즘이 가장 우수한 성능을 보였으며, 타 방법들은 데이터의 형태에 따라 한계를 보였음
1. Introduction
인더스트리 4.0은 스케쥴링, 컨트롤링, 제조 모니터링 등 제조업의 다양한 분야에서 혁신을 일으켰음. 수집된 데이터를 활용하여 지식을 extract 하는 데이터 프로세싱이 최근 중요해짐. 이는 practical 관점에서 매우 challenging 함. 제조업에서 시스템 효율을 최적화 할 수 있고, 퀄리티 보증에도 활용이 된다. anomaly를 detect 하는 것은 root cause analysis 를 구축하기 위한 첫 번째 단계이다. 그러므로, 시스템적으로 anomaly에 대한 추적이 이어져야지 시스템의 변화를 추적할 수 있다.
본 연구에서는 anomaly detection을 위해 머신러닝 방법론을 적용한 케이스를 조사한다. 수집된 historical data를 제조업 현장에서 anomaly를 detect 한 경우를 조사한다.
2. Theoretical background on the selected algorithms
본 연구에서는 Unsupervised 기반의 연구 방법론에 집중한다.
1. Local Outlier Factor (LOF) algorithm
밀도 기반 알고리즘으로, 데이터 포인트의 대부분이 노말이라고 생각하고 각 점들간의 proximity를 평가. 어느 한 점이 멀리 떨어져 있다면 anomaly라고 detect함.
데아터 포인트에서 가장 가까운 이웃과 얼마나 멀리 떨어져 있는지, 그리고 다른 이웃들이 얼마나 가까이 있는지를 통해 anomaly score를 계산함
-
Clustering-Based Local Outlier Factor (CBLOF)
클러스터링 기반의 알고리즘으로 클러스터의 center와의 거리를 기반으로 anomaly score를 계산함 -
K-Nearest Neighbors (KNN)
LOF와 비슷하지만, anomaly score를 계산하는 방법이 다르다. local density를 측정하는 것이 아닌, k개의 근접한 데이터 포인트간의 거리로 스코어를 계산한다.
공정의 데이터들은 다차원을 가지고 있다. 다차원의 noisy 성분들은 머신러닝 방법론의 퍼포먼스를 낮추기 떄문에 이러한 점이 challenging 하다.
4. Feature Bagging (FB)
앙상블의 개념으로, 멀티플의 머신러닝 방법론을 이용해 각 모델들은 feature의 서브셋만을 보고 학습해 anomaly score를 계산함. 마지막 아웃풋은 average 혹은 maximum으로 함.
-
Isolation Forest (IF)
이전 알고리즘이 클러스터링이나 classification을 위해 만들어진 모델임과는 다르게 IF 는 anomaly detection을 위해 직접적으로 만들어진 모델임. decision tree 기반의 접근론을 통해 이 트리들의 앙상블을 만듦. feature bagging과 비슷하게 IF또한 피쳐의 서브셋을 학습한 트리들이 만들어지면 decision이 이루어진다. 이는 특정 점이 anomaly라고 하면, 데이터 정점에 대해 travese 한 횟수가 적고 이를 통해 데이터가 isolation 되어 있다고 한다. -
Fast Minimum Covariance Determinant (FAST-MCD)
밀도 기반 알고리즘으로, 노말 데이터 분포는 투영하였을 때 가우시안을 가정하고 ellipse 에 포함됨. 따라서 이 밖에 있으면 outlier 라고 함. -
Copula-Based Outlier Detection (COPOD)
이 방법론은 잘 알려진 것은 아닌데, 위에 방법과는 다르게 어떤 파라미터의 세팅이 필요가 없다는 것이 장점이다. 확률론적인 결정으로 인해 copulas 컨셉을 이용함. -
Deep Neural Networks (DNN)
DNN 은 normal인, non-anomalous data를 학습한다. 히든 레이어에서 프로세싱하여 reconstruction이 잘 되는지에 따라 anomaly score를 계산한다.
3. Adopted methodology used for anomaly detection
3.1. Adopted methodology: CRISP-DM
Cross-industry standard process for data mining 의 약자로, ML의 데이터와 모델 적용 과정을 의마함.
3.1.1. Business understanding
historical 로그에는 머신의 고장을 나타내는 이벤트가 있음. 이를 탐지하는 것은 root-cause analysis를 하기 위해 매우 중요함. 따라서 machine availability 문제와 연관되어 있는 anomaly behavior를 detection 함
본 연구에서는 4개의 stage의 생산 시스템에서 planning 과 스케쥴링 문제 데이터를 활용함.
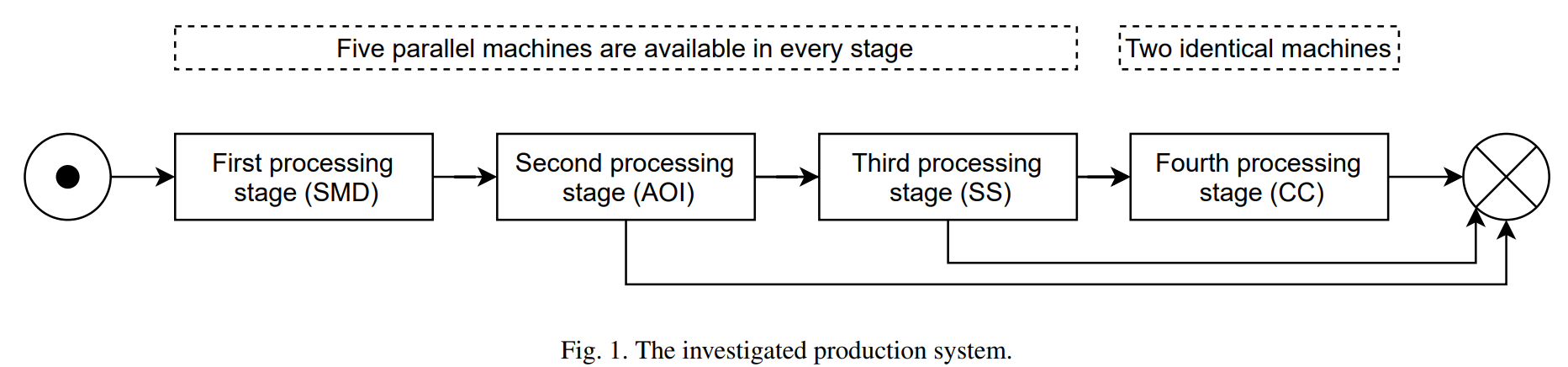
1~3 stage에서는 5개의 parallel한 machine이 다른 스피드로 작업을 진행. 4번째 stage에서는 2개의 parallel 머신이 작업을 진행.
이전의 최적화 알고리즘은 e Non-Dominated Sorting Genetic
Algorithm III (NSGA III) 사용.
3.1.2. Data understanding
최적화를 위해 우리는 확률적으로 머신 브레이크 다운을 만듦. 그리고 다시 최적화 알고리즘을 통해 스케쥴을 재 지정함. 시뮬레이션 중 counter를 통해 브레이크다운을 표시했는데, 이를 통해 ground truth를 만듦. 이를 통해 머신러닝 알고리즘의ㅏ anomaly detection 성능을 평가할 수 있음.
Feature selection 도 동시에 진행됨. 키 퍼포먼스 인디케이터가 피쳐로 활용되어 다음과 같이 나타남. 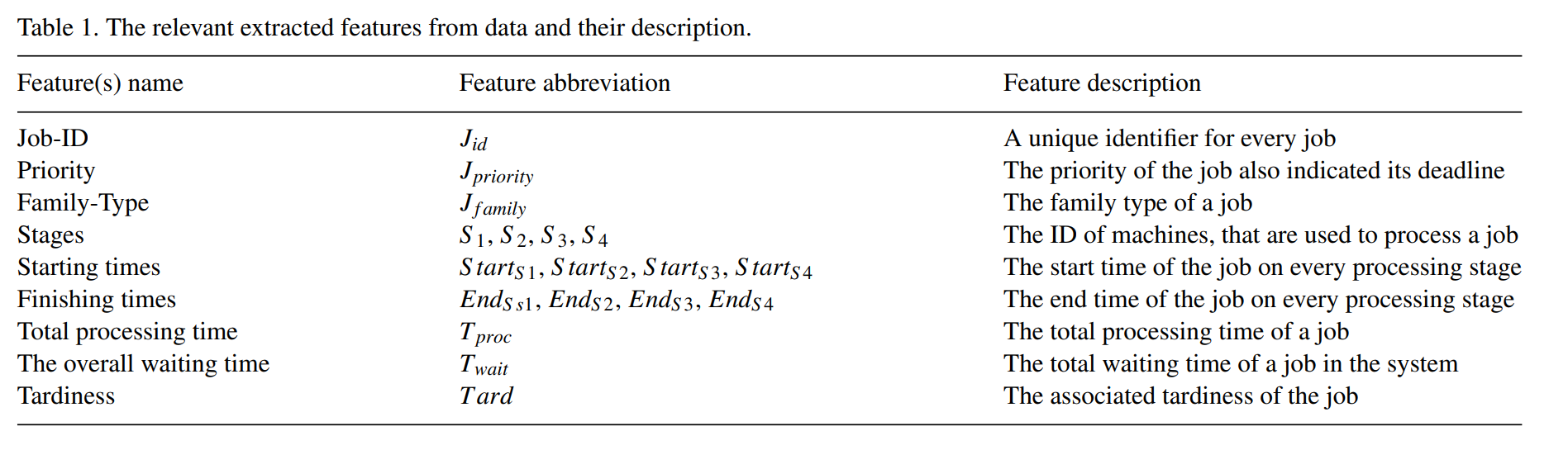
3.1.3. Data preparation
이렇게 나타난 feature value 들은 numeric representation 으로 전환됨. one-hot-encoding을 통해 진행. 차원을 높이는 문제가 있지만, integer representation으로 바꾸는 것 보다 더 모델의 퍼포먼스가 좋았음.
또한 feature composition을 다양하게 함.
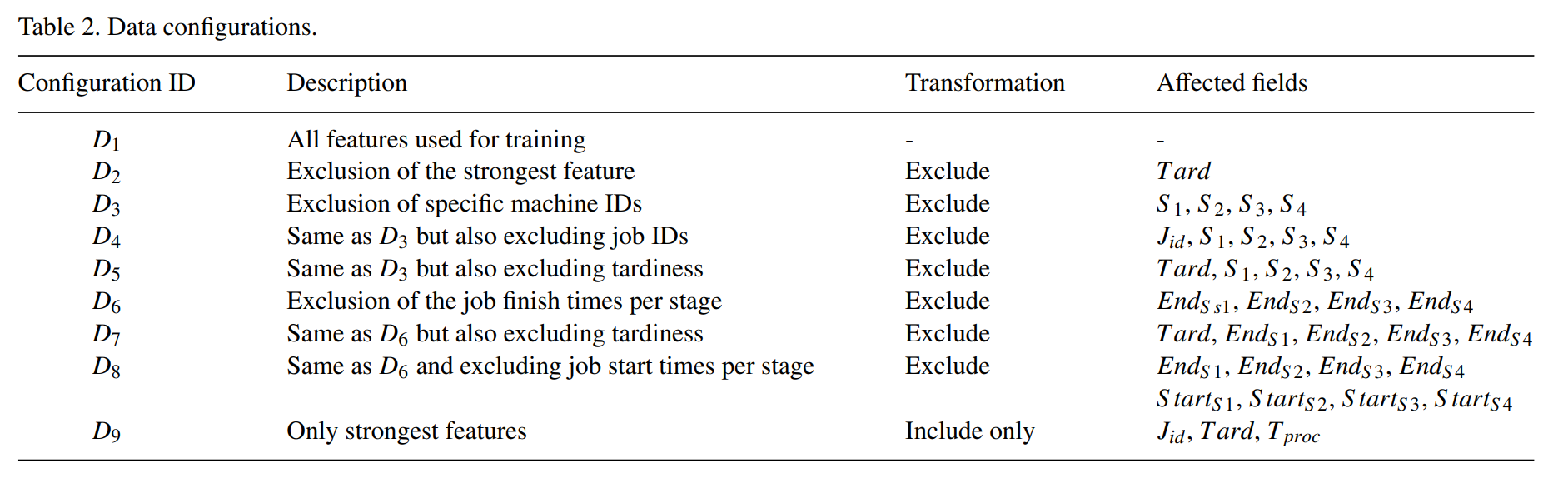
3.1.4. Modelling
모델의 구성을 다음과 같음

3.1.5. Evaluation
F1 score를 평가에 사용함. F1 = 1 이면 모델이 모든 anomalies 를 잡아내고 false positive가 없다는 것을 의미함. 100가지의 로그를 10개의 모델과 9개의 feature set을 통해 평가함
4. Computational results
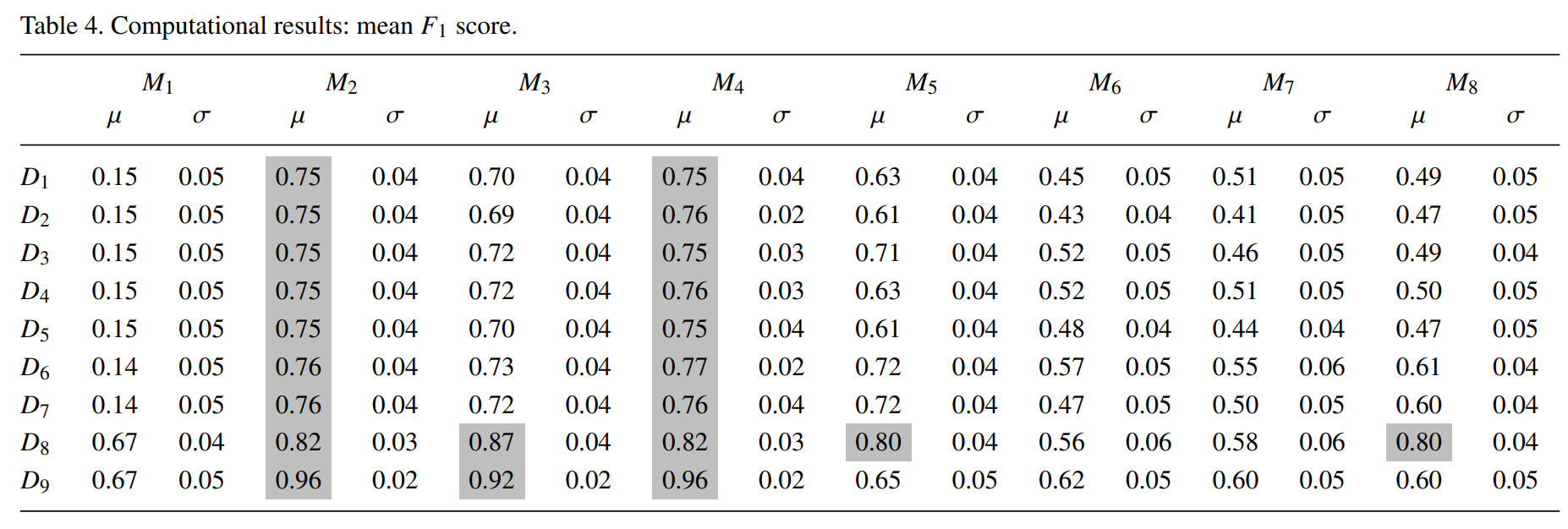
FAST-MCD and Local Outlier Factor 은 정확한 결과를 나타내지 못해 제외함
K-Nearest Neighbors (KNN) : M2
and KNN-based Feature Bagging algorithms : M4
가 가장 우수한 성능을 보임
LOF-based Feature Bagging, algorithm : M3
가 다음으로 우수하였음
D8에서는 KNN 보다도 성능이 우수하였는데, 이는 simple LOF는 성능이 아얘 안나온 것과는 대조적임.
Clustering-Based Local Outlier Factor (CBLOF) : M1은 좋지 못한 성능을 보임.
Evaluated Isolation Forest (IF) variants : M6, M7
은 퍼포먼스가 좋지는 못함
Copula-Based Outlier Detection (COPOD) : M8
은 대부분의 케이스에서 IF보다는 성능이 살짝 우세하였음
5. Conclusions and outlook
10개의 ML 방법론을 anomaly detection에 적용하면서 성능 평가를 진행하였음. 결과는 FAST-MCD and Local Outlier Factor (LOF)는 아얘 본 데이터셋과 맞지 않다는 결론을 도출함. 7개의 남은 모델은 서로다른 정확도로 아웃라이어를 detect함.
이 중 KNN이 가장 높은 성능을 보였음. 또한 가장 낮은 feature의 수에서도 가장 높은 성능을 나타내었음. Local-outlier-factor-based Feature Bagging은 noisy feature를 제거했을 때 성능이 효과적이었음.
AutoEncoders and Copula-Based Outlier detection은 noisy feature만을 제거했을 때 가장 높은 성능을 보였음.
F1 스코어가 0.75 이상인 모델이 root-cause-analysis에 적합하다고 생각되며, 이는 Table 4. 에서 마크표시를 하였음.
본 연구에서 활용된 데이터를 확장시키고, 또한 그 수를 늘린다면 다른 결과가 나타날 것이라고 생각됨. 특별히 DNN 기반의 모델에서는 오토인코더가 데이터 학습 양에 따라 퍼포먼스가 달라지는 특성을 가지고 있음.
본 연구에서 획득한 결과는 historical production logs를 조사하는데 효과적임. 이를 통해 preventive maintenance mechanisms을 세울 수 있으며, machine
breakdown을 줄일 수 있음.
