Research on Time Series Anomaly Detection: Based on Deep Learning Methods 요약
Abstract
시계열의 anomaly detection은 주로 통계 기법과 머신러닝 방법이 주를 이루었다. Deep neural network를 통한 anomaly detection이 연구되면서 기존의 연구보다 퍼포먼스가 좋아졌다. 트랜스포머와 GNN의 사용이 시계열 anomaly detection에 주로 사용되면서 최근 딥러닝 방법들 간의 심층적인 비교는 부족하였다. 따라서 본 논문에서는 시계열 anomaly detection에 적용될 수 있는 여러 DNN 방법들을 3가지 카테고리로 나누어 비교한다. 공개 데이터셋을 통해 평가하며 각 모델의 퍼포먼스를 비교한다. 그리고 당면한 문제와 anomaly detection의 발전 방향에 대해 소개한다. long-time series prediction에서 anomaly detection을 하는 것은 트랜스포머가 가장 성능이 좋았고, graph structure를 스터디 하는 것이 미래에 anomaly detection을 수행하는데 있어서 가장 효과적일 것이라 생각된다.
1. Introduction
타임시리즈 분석에는 두가지 메인 챌린지가 있다. 시계열 예측과 anomaly detection 이다. 본 연구는 시계열 anomaly detection에 초점을 맞추지만, time series prediction 또한 anomaly detection으로 사용될 수 있기 때문에 같이 다룬다.
시계열 anomaly detection을 산업 현장에서 빅데이터 분석을 통해 매우 중요하게 다뤄진다. 정보학의 발전으로 인해 데이터의 양은 엄청나게 증가하였는데, 시계열의 anomaly detection의 중요도가 더 커졌다. 이 분야에서 딥러닝의 중요도가 컸는데, DNN을 활용한 여러 방법론들이 나타나게 되었다.
그러므로, 본 연구에서는 DNN의 시계열 anomaly detection 대해 포커스 한다. CNN과 LSTM 뿐만 아니라 트랜스포머와 GNN까지 다룬다. 본 연구의 contribution은 다양한 연구들의 단점을 및 장점을 종합하고 팔로업 리서치에 레퍼런스가 되는 것이다.
2. Models
2.1 Supervised learning method
시계열의 anomalies는 다음과 같은 유형이 있다.
1. Innovative outlier (IO) : 시점 T에서의 anomalies를 나타냄과 동시에 그 이후 시퀀스에 대해서도 anomalies를 나나냄
2. Additive outlier (AO) : 시점 T에서만 anomalies를 나타냄
3. Level shift (LS) : T 시점에서 나타난 뒤, 이후에 시퀀스에 그 변위 만큼 영향을 나타냄
4. Temporary change (TC) : 시점 T에서 나타난 뒤 exponentialy 하게 영향이 줄어듦
Tailai Wen et al. 은 CNN 모델을 사용하여 time series segmentation 을 진행함. large-scale synthetic univariate time series data set을 통해 학습을 진행한 뒤, 전이학습을 통해 univariate or multivariable data set 에 적용하였음.
2.2 Unsupervised learning method
본 연구에서는 LSTM, 트랜스포머, GNN과 같은 실용적인 모델의 활용에 대해 집중함.
2.2.1 LSTM
recurrent neural network가 시계열의 complex한 dependency를 잘 반영할 수 있음.
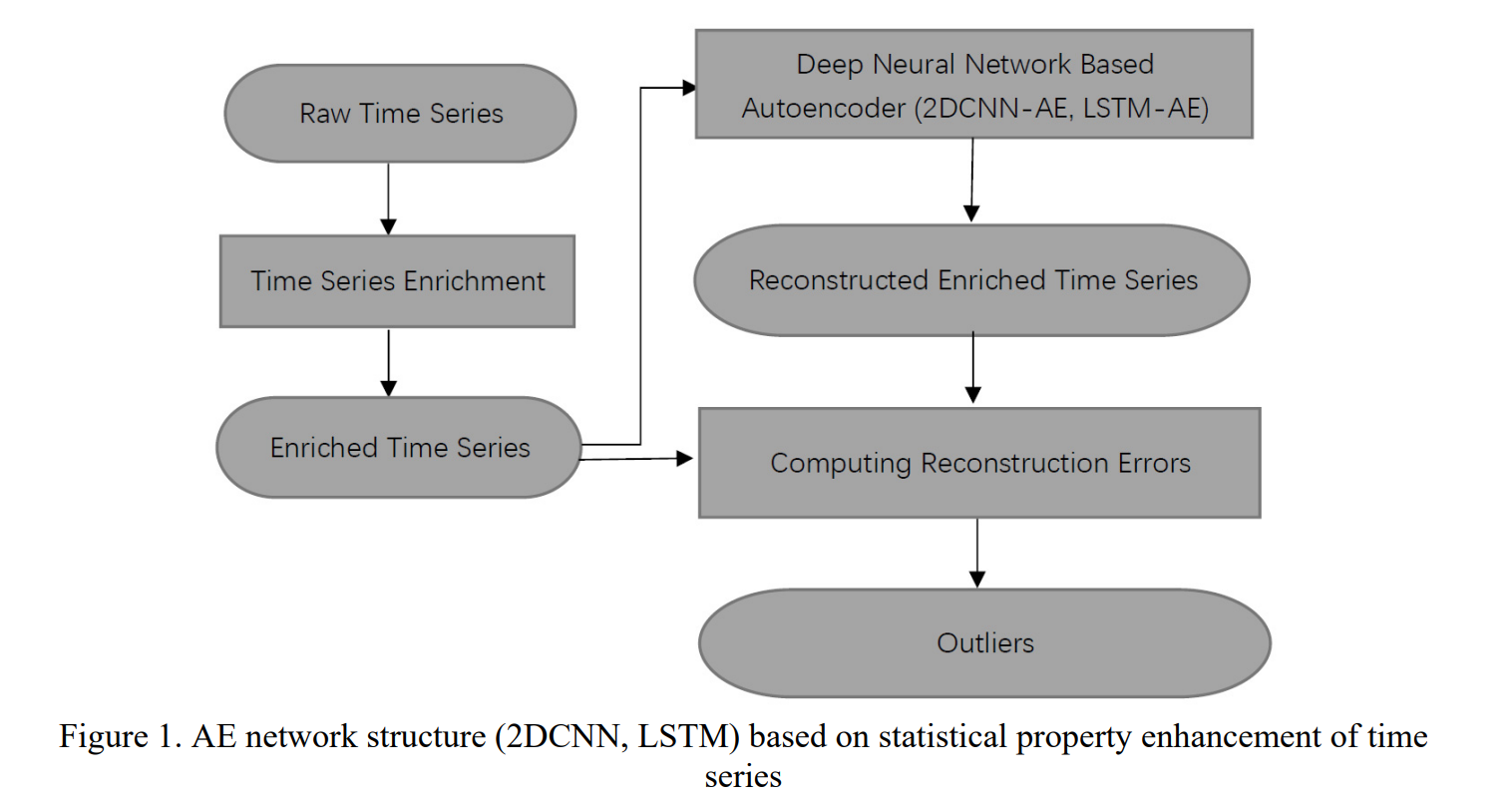
Tung Kieu et al. 은 오토인코더 프레임워크를 2D CNN과 LSTM model을 통해 제안함. 본 방법은 시계열 원본에서 statistical features 를 추출하고, 오토인코더를 통해 차원을 줄였음. 시계열을 AE를 통해 복원하는 과정에서 어떤 것이 anomalies인지 판별이 가능함. 정상 데이터가 대다수인 상태로 학습하기 때문에 anomaly가 복원 성능이 떨어지게 되는 원리임.
Daehyung Park et al. 은 LSTM-based Variational Autoencoder (LSTM-VAE) 디텍터를 제안함. 시계열 anomaly detection에 이용 가능한 모델이다. 이는 데이터의 분포를 학습하는 것이 목표인 모델인데, 실제 데이터의 분포가 라고 한다면, 를 실제와 근사하는 것이다. 하지만 를 바로 구할수는 없고, 히든 레이어 변수인 z를 통해 수식을 정의할 수 있다. 즉 이는 다음과 같이 나타난다.
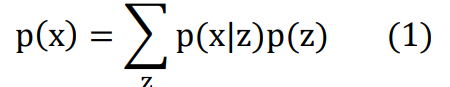
이를 통해 VAE는 AE와 같은 기능을 나타낸다. 즉, implicit variables를 얻기 위해 sequence를 넣고 implicit variable을 통해 원본 인풋을 복원하는 과정이다. VAE가 다른 점은 hidden variables의 분포를 학습하기 때문에 regularization이 가능하며 오버피팅을 방지한다.
2.2.2 Transformer
트랜스포머는 시계열 예측에 주로 사용된다.
Haoyi Zhou et al. 은 long sequence time-series forecasting을 위해 트랜스포머를 적용하였다. computing time complexity 문제와 spatial complexity 문제, 그리고 long-time series input 과 output간의 관계 학습에서의 챌린지가 있었다. 또한 멀티 레이어를 쌓기 때문에 긴 시퀀스에 대해서는 메모리 보틀넥이 생겼다. 또한 step by step으로 decoding 하는 과정에서 추론 스피드가 느리다는 단점도 있었다.
ProbSparse self-attention는 self-attention distilling and generative style decoder 를 통해 위에서 언급한 문제들을 해결하였다. 이를 통해 time series anomaly detection task에 효과적으로 사용가능했는데, Zekai Chen et al는 이를 활용해 GTA방식을 제시하였다.
2.2.3 GNN
multivariable time series에서 k개의 변수와 n개의 moment로 간주하고 다음과 같은 행렬로 표현할 수 있다. 와 같은 수식으로 표현이 된다.
기존의 시계열 anomaly detecion 방법론은 fig 1. 과 같이 normal 데이터로 학습을 하고 test 데이터를 인풋으로 넣어 anomaly score를 계산하고 쓰레시홀드를 넙는다면 anomaly로 진단한다.
Zhao et al. 은 2차원의 행렬을 GNN과 결합하였다. 하나는 단변량의 시계열 데이터를 그래프의 노드로 대응시켰다. 또 하나는 같은 시점의 다변량을 그래프의 노드로 대응시켰다.
GDN은 다변량 시계열 데이터 간의 관계를 추출하는데, 각 시계열을 그래프의 노드로 간주하고 fully connected 되었다는 가정을 버리고 노드 사이의 connection을 학습하였다.
두 논문 모두 feature extraction을 위해 graph attention을 사용하였다.
2.2.4 Other models
Deep SVDD 는 normal sample일수록 class의 center로 모이게 된다. test 과정에서 샘플이 class의 중심에서 너무 멀다면 anoamly 라고 판정한다.
MAD-GAN은 시계열 anomaly detection에서 generative adversarial networks (GAN) 을 활용한 것이다. LSTM을 통해 시계열 간의 관계를 학습하였고, GAN 의 프레임워크에 embedded 하였다.
USAD는 adversarial training framework 에 코덱을 제시하였는데, AE 및 adversarial training의 이점을 활용하면서 두 방법론의 단점을 보완하였다.
2.2.5 DAGMM
DAGMM은 비지도 학습 기반이지만, 다른 방법과는 다른 점이 있다.
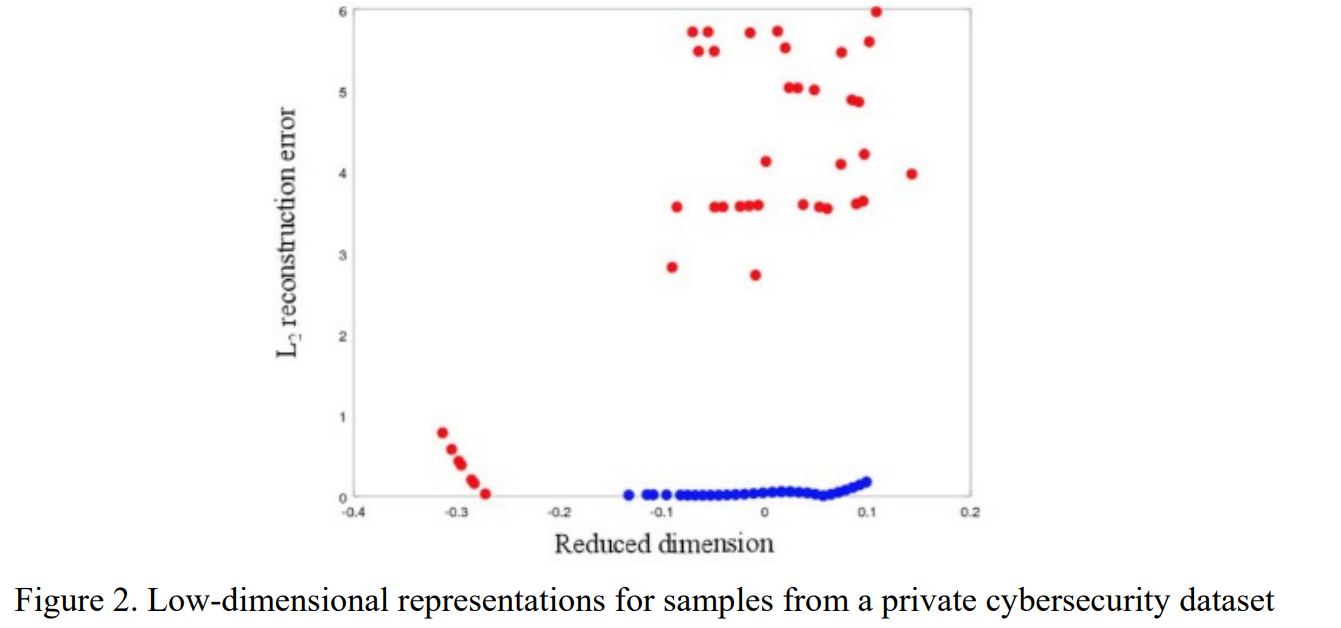
Fig2. 에서 X축은 오토인코더를 통한 1-d 공간상의 좌표이며, y축은 재구성 오차 값이다. 파란색이 정상, 빨간색이 비정상 데이터이다. 그림과 같이 비정상과 정상을 잘 구분함을 알 수 있다.
DAGMM은 GMM을 AE 모델에 결합한 것으로 GMM의 확률 값을 샘플이 정상인지 비정상인지 판별하기 위해 사용한다.
3. Findings
3.1 Supervised model
리서치를 조사하면서 CNN 모델이 supervised 방법에서 퍼포먼스가 좋음을 확인하였다. anomaly detection에서는 몇몇 문제가 있었다. 시계열의 anomalies 에 의한 영향은 짧은 시간동안 지속되기 때문에 long-time series에서 이를 판별하기 어렵다. 또한 정확도가 지도학습에서는 학습 데이터 퀄리티에 좌우한다는 문제도 있다.
3.2 Unsupervised model
3.2.1 Model comparison
Secure Water
Treatment (SWaT),Water Distribution (WADI) Mars Science Laboratory Rover (MSL) 의 public datasets 사용
SWAT 은 low dimensional large dataset
WADI 는 high dimensional large dataset
MSL 은 low dimensional small dataset
evaluation은 precision (P) recall (R) and F1 score (F1) 사용

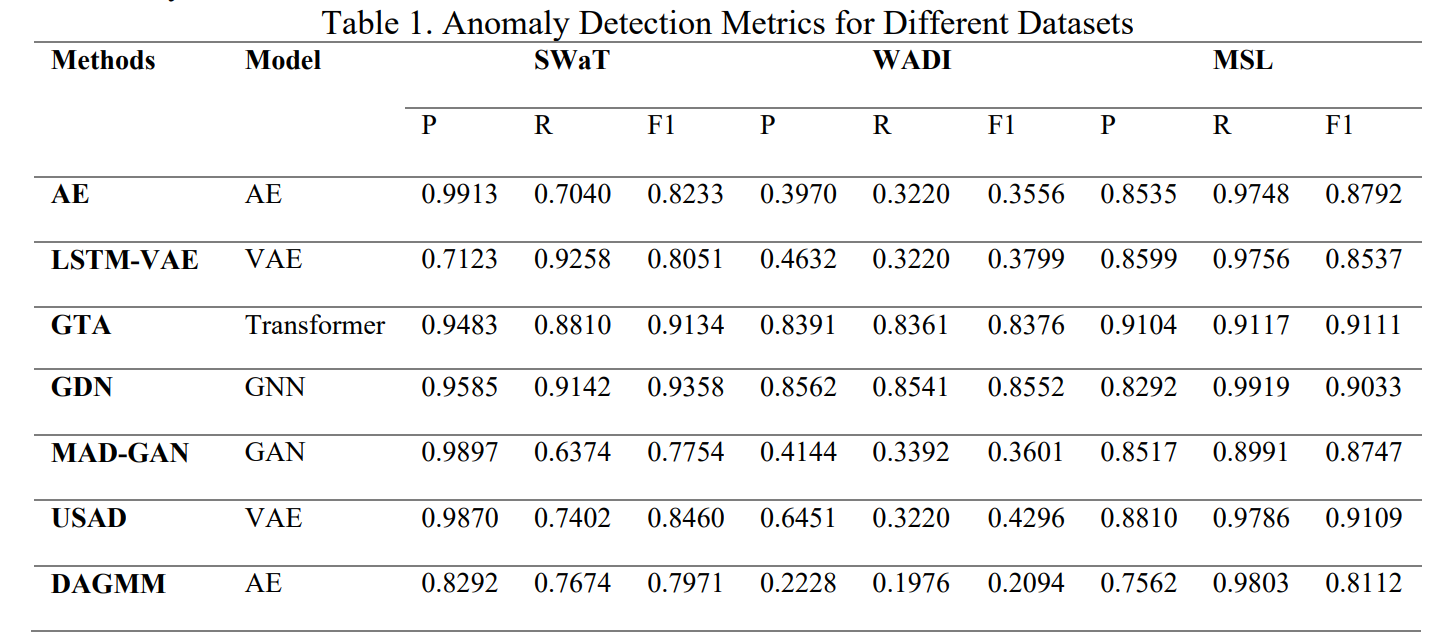
GNN and transformer는 고차원과 and large amount of data에서 성능이 좋았음. 특히 graph structure의 성능이 눈에 띄며, time-series anomaly detection에서 GNN이 좋은 효과를 보임을 알 수 있었음.
3.2.2 Performance summary of anomaly detection methods
(1) AE, DAGMM
AE는 정확도가 좋지 못했음.
DAGMM은 convergence 속도가 느렸고, tuning parameter 와 priori probability에 의해 낮은 generalization 퍼포먼스를 보였음.
결론적으로, 둘은 high dimensional 시계열 데이터에는 맞지 않았음.
(2) LSTM-VAE, MAD-GAN, USAD
LSTM-VAE 은 AE와 구조가 비슷하지만 오버피팅을 방지할 수 있는 장치가 있음.
MAD-GAN 은 파라미터가 너무 많아 generalization 성능이 낮았다.
USAD 는 VAE 기반의 적대학습을 진행했는데, 학습이 빠르다는 장점이 있었다.
하지만 (1) 과 비슷하게 high dimensional 시계열 데이터에는 맞지 않았음.
(3) GTA, GDN
graph structure 를 시계열에 적용한다는 특징이 있었음.
GTA는 그래프 구조를 학습하고 트랜스포머를 활용하여 시계열 예측을 진행함.
GDN은 다변량 간의 관계를 학습하고 각 시계열을 노드로 간주하여 노드간의 관계를 학습한다. 또한 graph network를 바로 feature extracion에 활용한다. 두 가지 모두 저차원 데이터셋에 활용이 잘 될 뿐만이 아니라, 고차원 데이터셋에도 정확도가 높았다.
그러나 GNN은 노드 수의 변화가 생기는 dynamic change를 반영하지 못한다.
3.2.3 Open problems
비지도 학습 기반 시계열 anomaly detection에서 풀어야 할 숙제는 다음과 같다.
실제 환경에서는 데이터가 지속적으로 생성되므로 전문가가 새롭게 라벨링한 것이 모델에 피드백 된다. 따라서 모델은 지속적으로 업데이트가 이루어져야 한다.
또한, 변수가 실시간으로 변화할 수 있기 때문에 모델이 이에 대응할 수 있어야 한다.
anomalies의 빈도는 매우 낮기 때문에 모델이 이를 탐지하기란 매우 어렵다. 몇몇 특별한 케이스를 detection 하는 정확도를 높여야 한다.
4. Conclusion
Time series anomaly detection은 다양한 필드에서 발전해 왔다. 그러나, time series anomaly detection model의 정확도는 지속적으로 증가해야 한다. deep neural network의 장점이 이 task에 적합하므로, 연구자들은 지속적으로 이 분야를 연구해야 한다.
본 연구에서는 10개의 anomaly detection에 사용되는 모델의 퍼포먼스를 비교분석하였다. 공개 데이터셋을 각 모델에 적용하여 각 모델이 어떤 데이터셋에 효과적인지를 보였다. 하지만 본 연구에서 사용한 다양한 모델들은 제안 목적이 서로 다르기 때문에 본 데이터셋에 적합하지 않을 수 있어 본 연구의 결과가 모델의 직접적인 퍼포먼스를 반영하지는 않는다.
데이터량의 증가로 인한 비지도학습의 중요도가 증가하면서 본 연구에서 저자는 비지도 학습에서 발전이 필요한 포인트를 제시하였다.
