Informer: Beyond Efficient Transformer for Log Sequence Time-Series Forecasting
Abstract
최근 트랜스포머의 포텐셜이 LSTF(Long-Sequence time-series forecasting)에 좋음을 보였다. 그러나 time-complexity가 제곱승에 비례한다는 것이 LSTF 예측에 있어 방해가 됨. 따라서 우리는 Informer를 제안하는데, 3가지의 특성이 있다.
1. ProbSparse self-attention mechanism : 의 메모리 사용량을 가짐.
2. Self-attention은 dominating 한 attention만을 halving cascading layer input을 활용하여 효과적으로 긴 인풋 시퀀스 alignment 능력을 향상
3. Generative style decoder는 심플하지만 one forward operation으로 극적으로 long-sequence 추론 속도를 높임
4개의 큰 데이터셋으로 인포머가 기존의 방법보다 LSTF에서 좋은 효과를 보임을 증명함
Transformer의 Sparsity
문장이 길어짐에 따라 리니어하게, 혹은 리니어에 가깝게 하는 것이 목표
Qurey - Key Pair를 설정
시계열 예측의 관점에서는, 더 긴 sequence를 인풋으로 받아도 정확도가 떨어지지 않는다.
바닐라 Transformer의 한계
quadratic computation of self-attention
memory bottleneck in stacking layers for long sequence
The speed plunge in predicting long output
-> 추론 단계에서 step-by-step decoding을 수행하기 때문에 RNN 기반의 모델만큼 느린 추론 속도를 보이게 된다.
Dynamic decoding
Informer 논문에서 사용하는 용어로, RNN과 같은 autoregressive 한 step-by-step decoding 방식을 의미
인퍼런스 수행 과정에서 첫번째 스텝에서 첫번쨰 토큰을 예측하고, 다음 토큰의 예측에서는 첫 번째 토큰의 아웃풋을 받아서 예측하는 방식임.
즉, 10개의 토큰을 예측해야 한다고 하면 과정이 10step으로 이루어지게 된다는 것을 의미함.
선행연구
- 휴리스틱한 방법론을 바탕으로, self-attention mechanism의 복잡도를 줄임
이는 quadratic한 한계점만 다루고 있음(LogSparse Transformer) - Reformer의 경우 긴 인풋의 stacking layer에 대한 복잡도를 고려하였는데, 극단적으로 긴 sequence 에만 최적화 되어 있다는 단점이 있음.
- Linformer 라는 것은 선형적 복잡도를 가지는 attention 기법을 제안하였는데, 현실 세계의 long-sequence에 대해 확장성을 가지지 못함
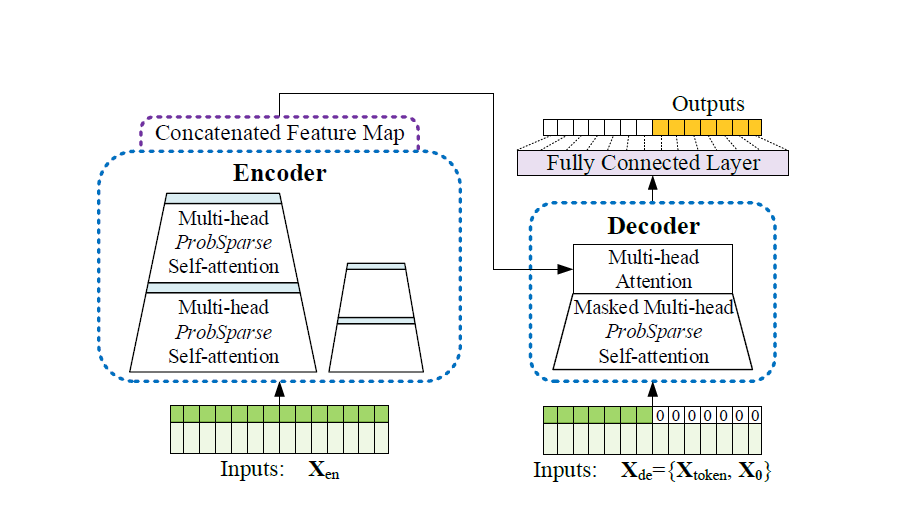
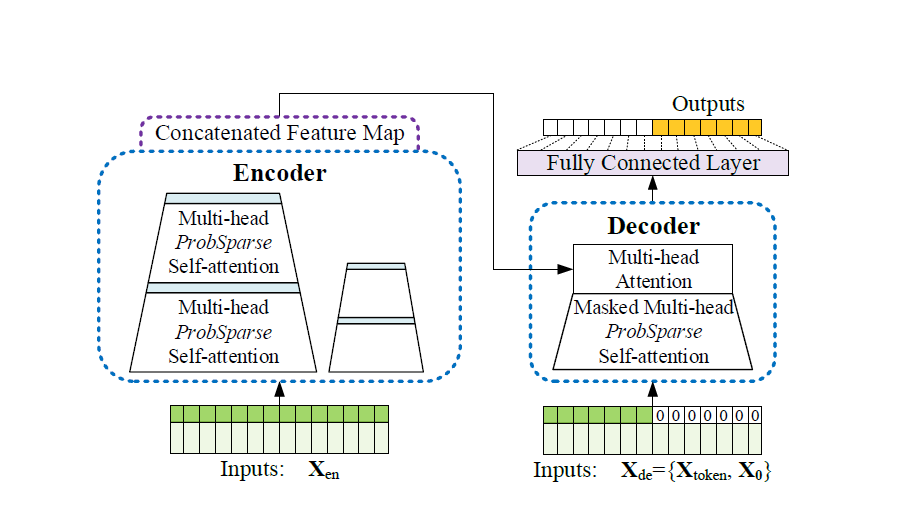
모델 architecture
인풋 구조
Scalar라 하는 Input이 있고, 이는 D차원으로 Projection 시킨 것
Local time stamp라는 것은 고정 위치 값을 사용한 것
Global time stamp특정 일에 대한 정보를 담고 있는데, 데이터셋을 구축할 때 time feature를 구축함
인코더 인풋 : 시퀀스 길이만큼의 scalar와 sequence embedding 값이 들어오게 됨.
디코더 인풋 : 스타트 토큰의 일정 길이의 인풋, 예측 길이만큼은 0으로 padding
(인코더의 인풋에 일정 길이만큼을 떼서 디코더 인풋으로 넣음)
ProbSparse Attention
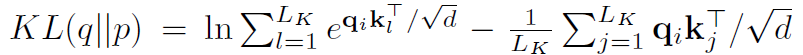
Kernel Smoother : 쿼리와 키의 내적을 근사하는 하나의 함수임
이전 휴리스틱 방법론들은 selective가 어떤 윈도우나 랜덤화된 알고리즘을 활용하였는데, 인포머는 새로은 selective 전략을 세움.
Dominant dot-product pair 의 분포는 유니폼분포와 상이하다는 것을 활용
우리가 관측한 쿼리에 대한 키의 확률 분포가 uniform 분포에 근사된다면, 불필요한 set으로 간주한다.
따라서, p 분포와 q 분포의 유사도를 KL-divergence로 계산
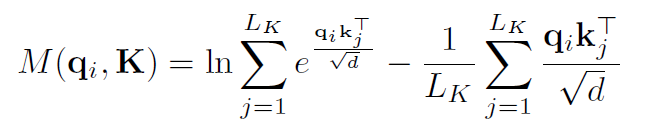
이를 통해 측정 지표를 만들어냄
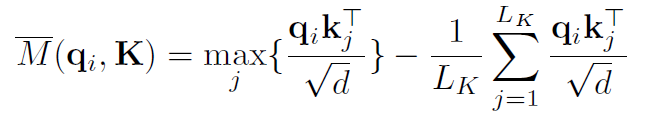
여기서 유의미한 쿼리 상위 u개만 선택하여 계산
그러나 이 방식으로는 모든 쿼리와 키의 연산이 필요함
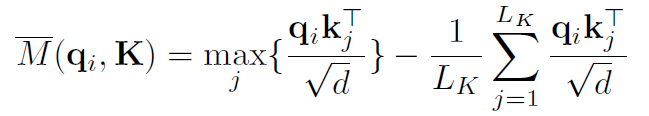
의 근사식을 통해 모든 쿼리키 페어가 아닌, 키를 샘플링함
샘플링 키의 갯수는 하이퍼파라미터로 설정.
최종 내적은 쿼리 중 중요도가 u와 모든 키를 함
그렇다면, 일정하게 key를 샘플링하는 것이 괜찮은 것인가?
Encoder
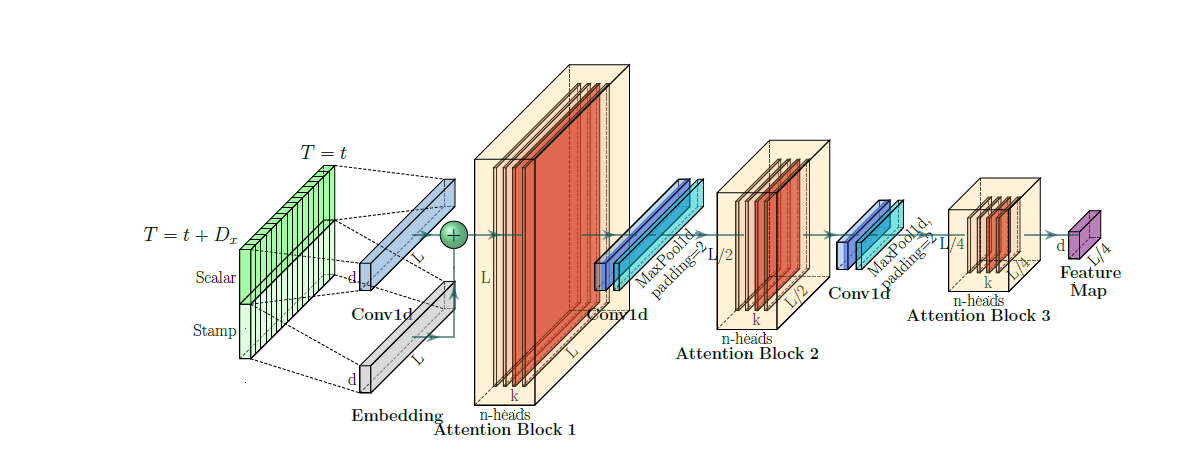
self-attention distiling
Distiling 이 핵심이다. 어탠션 아웃풋으로부터 중요한 정보를 추출하여 다음 레이어에 전달.
attention matrix가 probsparse attention으로부터 생성이 되면, value matrix와 곱한다. 코드에선 top-u 개의 index를 저장해 두었다가, 헤드별로 다양하게 뽑힌 쿼리 정보를 합침. concate 된 8개의 아웃풋은 1D convolution과 맥스풀링을 거쳐 distiling을 거침
매 레이어마다 반복을 하여 이전 레이어 인풋의 절반만큼 크기가 줄어들게 되어, 여러개를 stacking 하는데 등비수열 만큼 줄어들게 된다.
Decoder
기존과 동일하게 바닐라 어텐션을 활용
Experiments
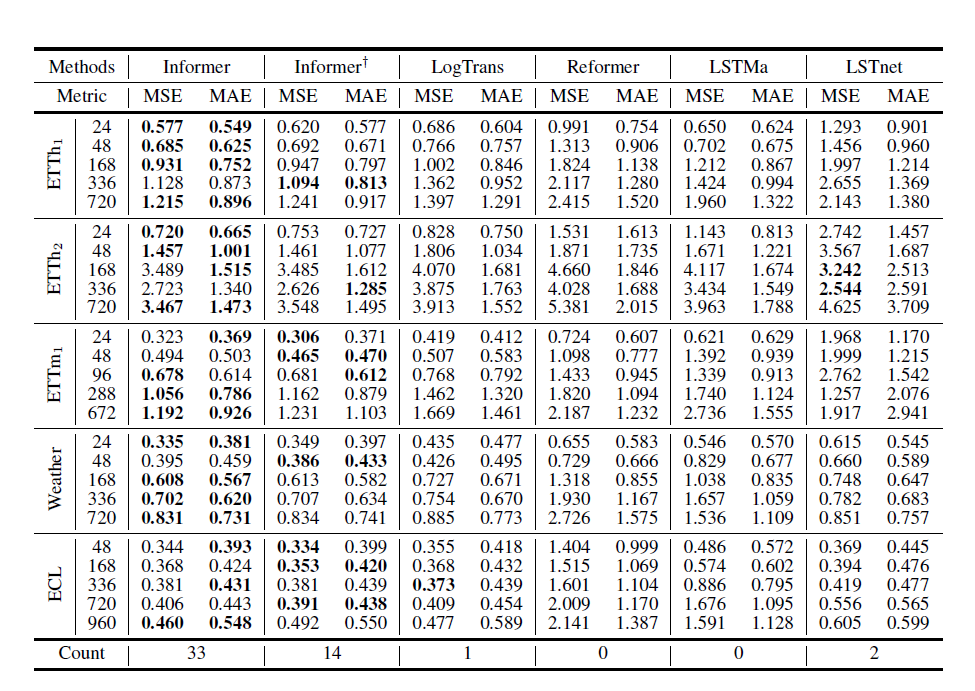
Informer가 가장 우수한 성능을 보임
특히, 단변량의 경우에서 더 좋은 성능을 보였는데 다변량에서는 큰 차이가 나지는 않았음. 이는 참조할 수 있는 변수량이 많아질수록 모델의 성능도 높아지기 때문이라고 생각함
Reference
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021, May). Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 12, pp. 11106-11115).
https://www.youtube.com/watch?v=Lb4E-RAaHTs
[Paper Review] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
[DSBA] Lab Seminar 2021
