Deep transfer learning based on dynamic domain adaptation for remaining useful life prediction under different working conditions 요약
Abstract
RUL 예측은 기계적인 breakdown을 효과적으로 aviod 하고 신뢰성을 높인다. 하지만, 다른 working condition의 distribution의 불일치 때문에 문제가 생긴다. 본 논문에서는 전이 학습을 통해 DDA(Dynamic Domain Adaptation) 개념을 도입하였다. 2개의 Dynamic Domain adaptation 네트워크가 학습되어 domain invariant 한 degradation feature를 extract 하고 RUL을 예측한다.
1. Dynamic Distribution adaptation networks
2. Dynamic adversarial adaptation networks
Fuzzy set theory는 conditional discrepancy loss를 계산하기 위해 제시되었다.
결과적으로, Run-to-failure bearing dataset에서 효과적임을 보였다.
다른 방법들과 비교하여 DDA-based 기반은 예측 효과가 더 좋으며, negative transfer 나 distribution weight functuation 의 영향을 줄인다.
Introduction
distribution shift의 문제를 해결하기 위해 최근 transfer learning 이 발전하고 있다. 여러 연구들로 인해 TL은 다른 워킹 컨디션에서의 prognostic 모델의 퍼포먼스를 효과적으로 높였다. 그러나, TL에서 해결해야 할 문제는 다음과 같이 있다.
1. 현재 연구들은 다른 도메인 간의 marginal(global) distribution 혹은 conditional(local) distribution 둘 중의 하나만의 분포를 다룬다. 이 둘을 고려한 degradation을 모델링 한 케이스가 없다.
2. marginal & conditional distribution 들이 domain invariant feature learning을 위해서는 같은 weight을 주었는데 이는 성능이 떨어지게 된다.
3. 부적절한 소스 샘플들은 transfered 된 모델의 퍼포먼스를 떨어트린다.
이러한 문제점들을 해결하기 위해, 본 연구는 DDA(Dynamic Domain Adaptation)를 RUL에 적용한다.
처음으로, reverse validation 기술을 통해 소스 도메인에서 타겟 도메인의 샘플과 비슷한 학습 샘플을 선별한다.
다음으로, 2가지의 다이나믹 도메인 adaptation 네트워크를 통해 (DDAN, DAAN) 자동적으로 domain invriant degradation features를 뽑아낸다.
마지막으로, dynamic adaptation network 가 marginal & conditional한 weight을 자동으로 조절한다.
결과적으로, 학습된 RUL 예측 모델들은 RUL 타겟 도메인의 추론에 활용된다.
본 연구의 컨트리뷰션은 다음과 같다.
- DDA 기반의 RUL 예측은 다른 working condition에서도 잘 될 수 있도록 한다.
- 다이나믹 도메인 어댑테이션 네트워크는 동시에 marginal 과 conditional distribution 차이를 줄인다.
- Reverse validation 기술은 적절한 샘플의 소스를 선택함으로써 RUL 예측 모델의 학습을 돕는다. 그러므로, 전이학습의 샘플 오염 문제를 줄인다.
Preliminaries
problem definition

Deep transfer learning
DNN, DL 기술을 TL에 접목되어왔다.
Non-adversarial approaches :
marginal distributions discrepancy across domains
maximun mean (MMD)
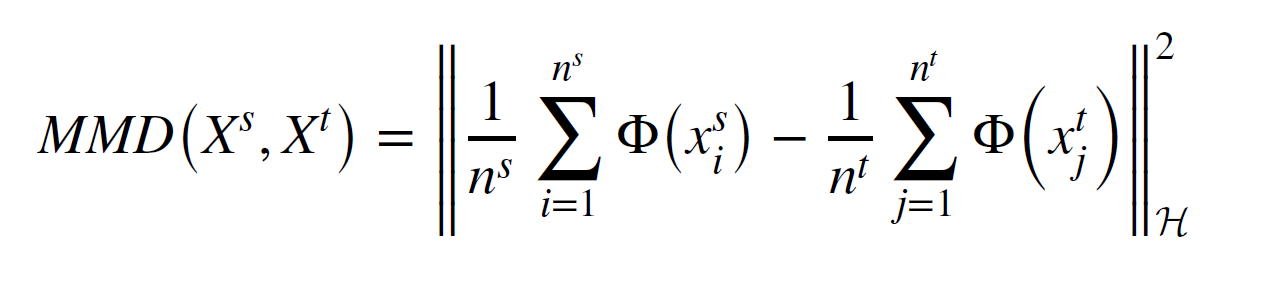
function은 feature mapping function임
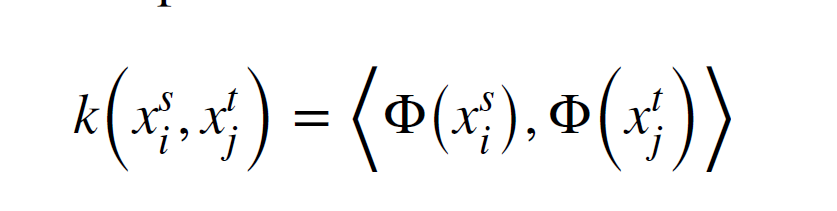
multiple-kernel maximum mean discrepancies (MK-MMD)
function은 MK-MMD에서 조정되어 다음과 같이 로 나타남
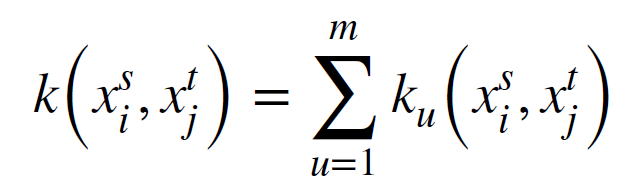
MMD는 더 발전되어 커널 함수를 사용하여 CMMD로 발전함
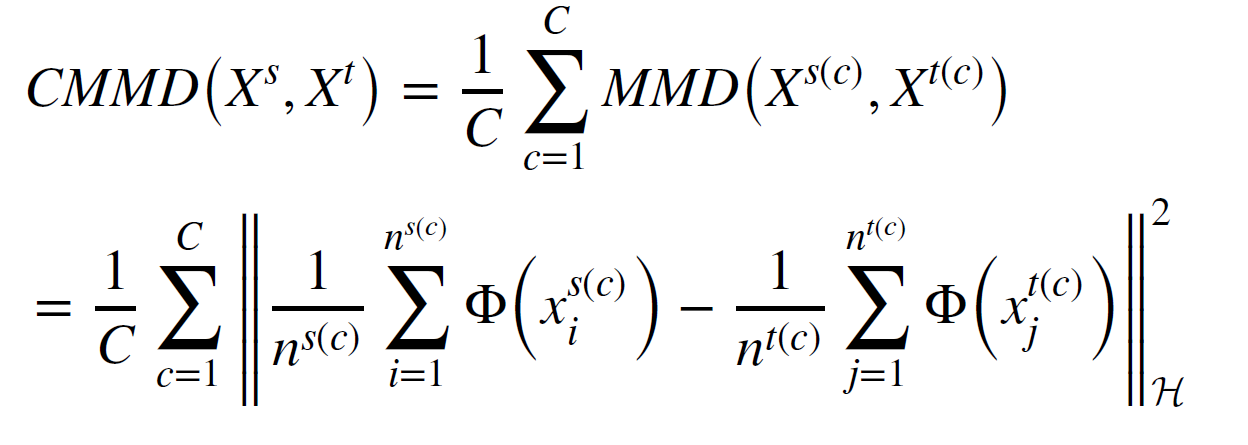
Adversarial approaches :
marginal distribution adaptation 은 도메인 classification loss maximization을 통해 수행된다. 이 operation은 extracted feature들을 만들고 있으며 도메인 discriminator에 의해 classified 된다.
토탈 로스 식은 다음과 같다.
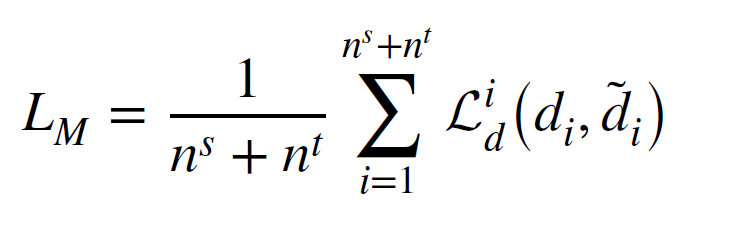
서브클래스 도메인 discriminator가 사용되어 conditional ditribution adaptation을 위한 conditional distribution의 adaptation을 진행한다. 그러므로, 총 로스 식은 다음과 같다.
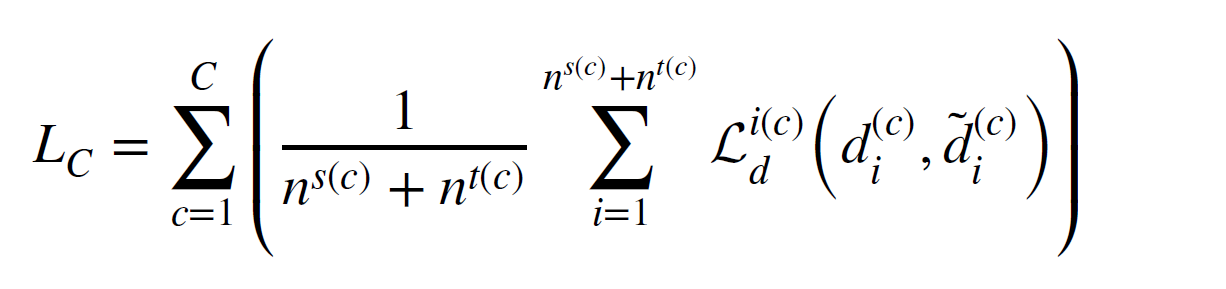
따라서, adversarial 및 non-adversarial 접근론은 성공적으로 domain adaptation을 할 수 있었다. 그러나 RUL 예측은 regression 문제이기 떄문에 DTL-기반의 RUL 예측 방법을 통해 다른 condtion으로 인한 도메인 shift를 연구해야 한다.
3. Proposed method
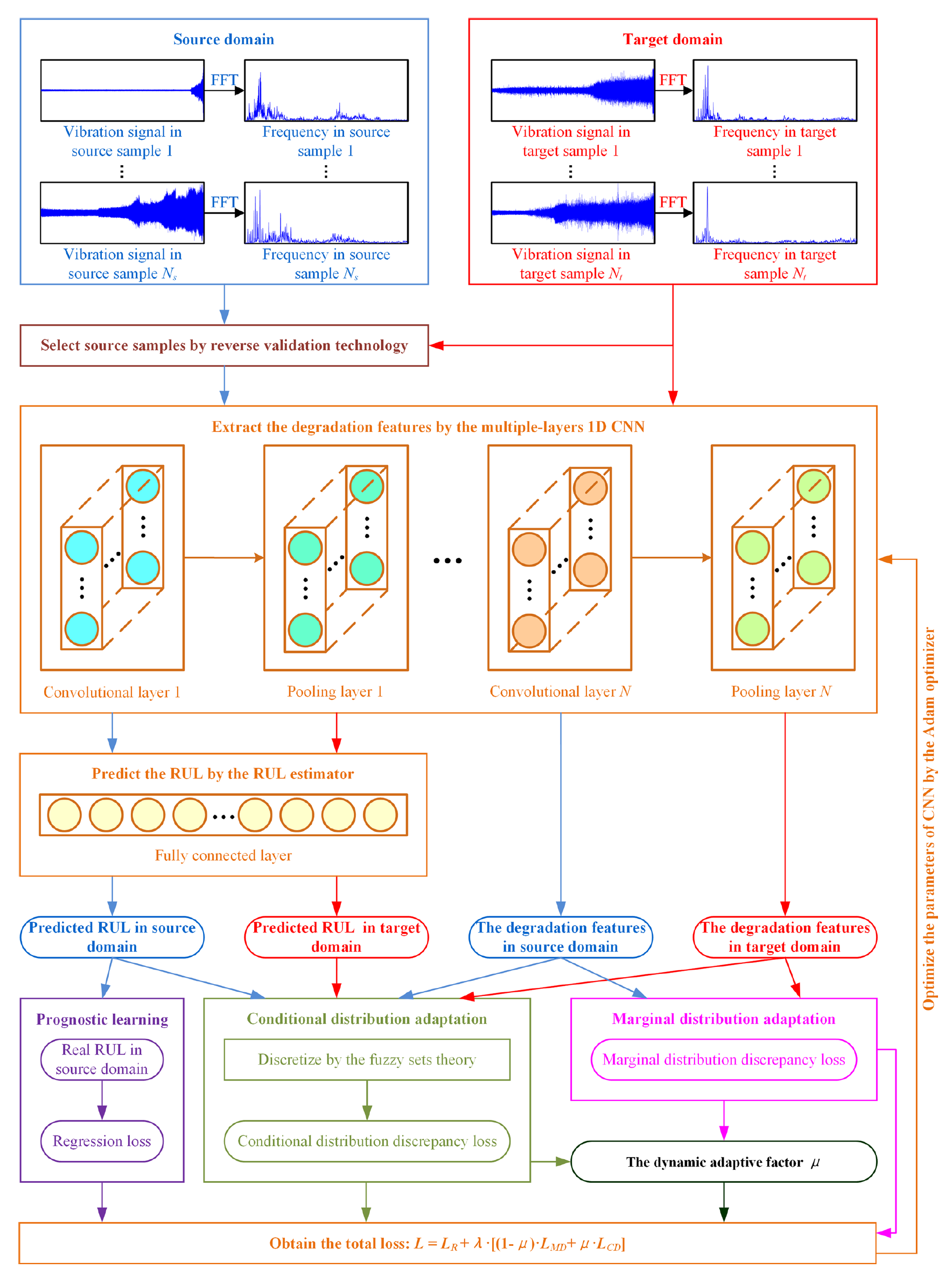
진동 데이터는 소스 도메인과 타겟 도메인으로 수집된다. RUL 라벨은 [0,1] 사이로 노말라이즈 되고, 소스 도메인에서만 활용된다.
Reverse validation 기수을 통해 소스 샘플을 선택한다.
1D CNN 과 3가지의 모듈들은 도메인 invariant degradation feature를 뽑아내고 RUL을 예측한다.
또한, fuzzy set 이론은 RUL을 구분하는데 활용하고, conditional distribution discrepancy loss를 계산하는데 도움을 준다. marginal과 conditional loss는 다이나믹 adaptive factor로 인해 조정된다.
마지막으로, Dynamic domain adaptation network-based 모델이 타겟 도메인 RUL을 잘 예측할 수 있도록 한다. 이를 통해 generalziation 성능이 향상된다.
Source sample selection
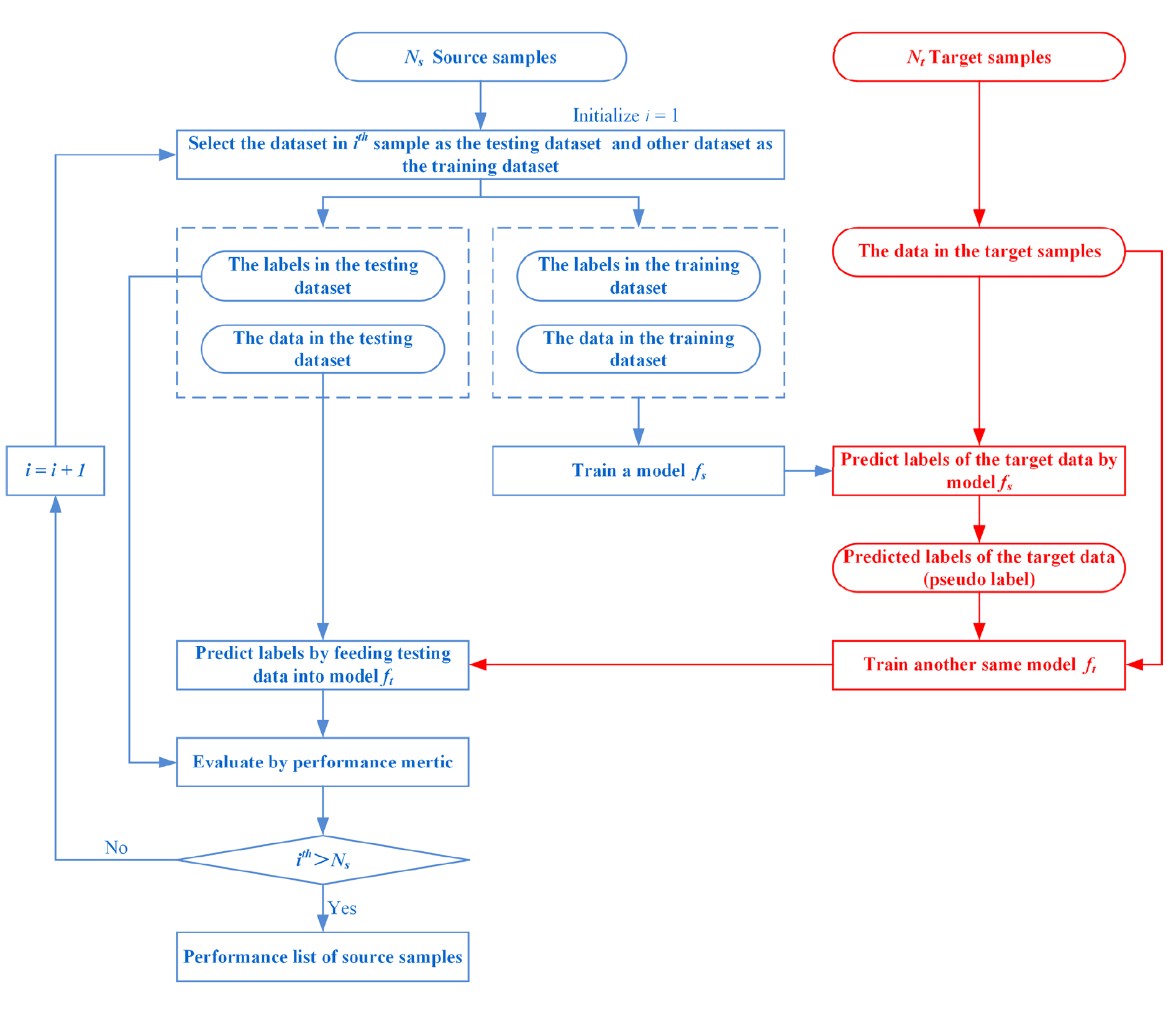
소스 샘플의 i번째 샘플을 선택하여, 테스트 데이터로 사용하고 나머지를 통해 모델을 학습한다. 그리고 학습된 모델로 타겟 도메인에 대한 추론을 진행하고 모든 샘플에 대한 결과 MAE값을 평균을 취한다. 평균 이하의 값들로 구성된 샘플을 select 하여 학습 데이터로 사용한다.
Dynamic domain adaptation network
다른 working condition에서의 domain shift 문제를 해결하기 위해 dynamic adaptation network를 본 논문에서 제시한다.
Dynamic domain adaptation network는 mariginal 및 conditional 분포 차이를 줄일 수 있을 뿐만 아니라, 다이나믹 도메인 어댑테이션 기술을 통해 분포 가중치를 동적으로 조정하며 RUL 예측 성능을 높인다.
DDAN에서 멀티-레이어 CNN이 feature extractor로 사용되어 고차원의 degradation feature를 추출하는데 사용된다.
다음으로, FC 레이어를 통해 RUL 예측 하였다. margninal & conditional 분포 차이는 동시에 고려되어야 하므로, DDAN를 학습하는 것의 목표는 3가지의 모듈을 가지고 있는데 prognostic learning, marginal distribution adaptation, conditional distribution adaptation 이다.
prognostic learning module 에서는, DDAN의 degradation feature와 RUL 값의 차이를 로스식을 통해 학습한다.
marginal distribution adaptation module 에서는 다른 도메인들 간에 marginal distributions를 aligning 하여 도메인 invarient 한 features를 추출할 수 있게 한다. 다른 도메인간의 차이를 측정하는 것이 marginal distribution adaptation의 핵심이다. MK-MMD 를 사용하여 도메인간의 difference in the marginal distributions을 측정한다. 그러므로, 로스 식은 다음과 같다.
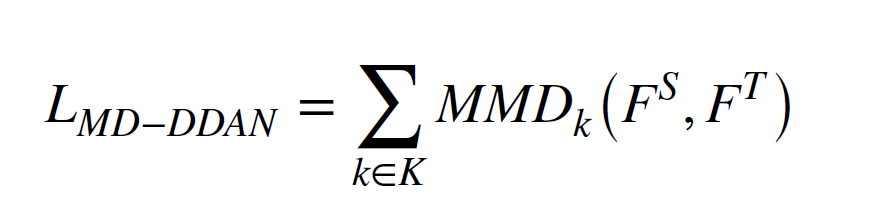
conditional distribution adaptation module 에서는 더 많은 fine-grained domain adaptation이 conditional distributions을 할 수 있게 한다. 이는 다른 도메인들 간에 conditional distributions을 조정하면서 가능해진다.
하지만, 현재 존재하는 conditional probability distribution adaptation 기술은 regression에 적합하지 않는데, 그 이유는 명확한 regression indicator가 없기 때문이다. 그러므로, regression 라벨들은 discretized 되어야 한다. RUL의 정의에 의해 RUL 라벨들은 3가지 카테고리로 나뉘는데, early, mid, late로 나타난다. 이는 Fuzzy set theory를 통해 RUL stage를 나눈다. 이는 conditional distribution discrepancy loss를 구하는 과정이 된다.
이를 통해 RUL estimator의 아웃풋이 나오게 된다.
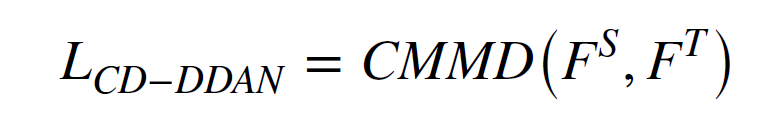
따라서, DDAN의 총 Loss 식은 다음과 같다.
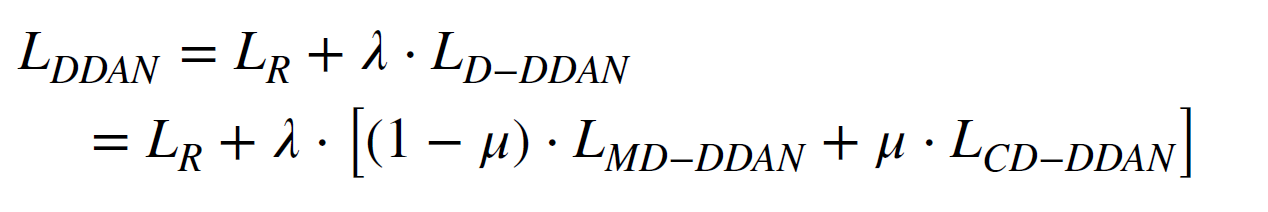
Dynamic adversarial adaptation network
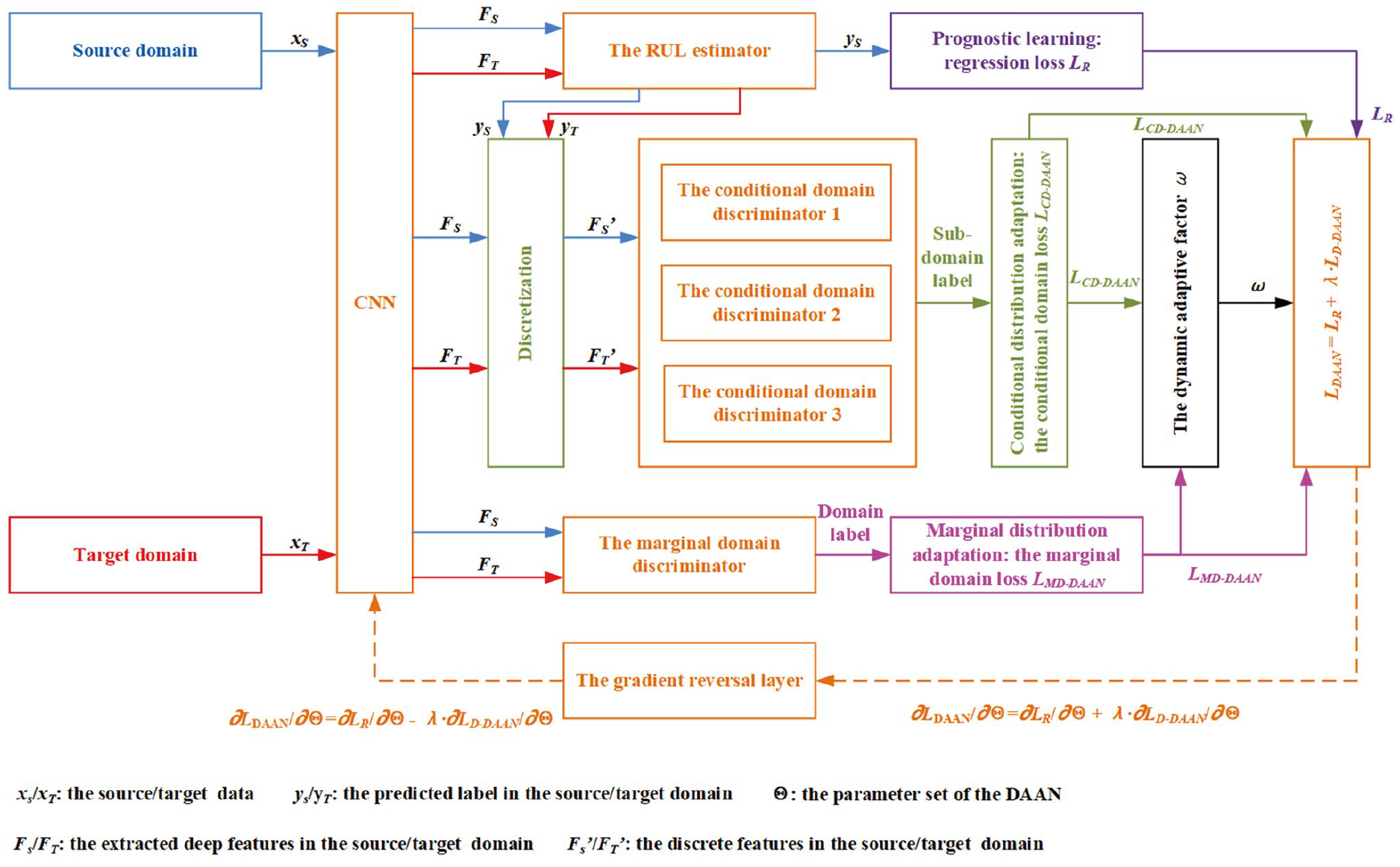
DAAN 네트워크 아키텍쳐는 다음과 같다. marginal distribution adaptation
module 과 conditional distribution adaptation module은 DDAN과 다르게 구성된다.
marginal domain discriminator 는 소스도메인 instance들과 타겟 도메인 instance들을 구분하도록 디자인되었다. 그러므로, binary classification이 진행되어 도메인 discriminator가 동작한다.
conditional domain adaptation module은 다른 도메인들 간의 multi-subclass distribution을 정렬한다. DDAN과 비슷하게 RUL 라벨이 fuzzy class를 통해 분리가 되고, conditional 한 분포를 학습하여 멀티플 컨디셔널 discriminator가 동작한다.
이를 다 합치면 다음과 같은 식이 나오게 된다.
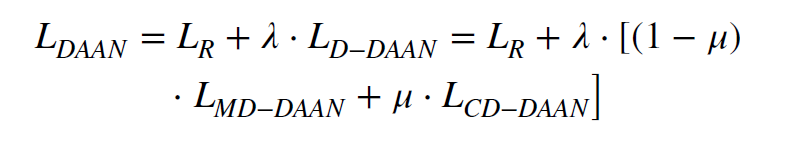
Dynamic domain adaptation
DTL(Deep Transfer Learning) 에서 adaptive factor가 marginal distribution
과 the conditional distribution의 상대적인 중요도를 반영하는데 매우 중요한 요소이다. 적절한 factor를 찾아 반영하는 것이 실제 문제에서는 매우 중요하다.
Wang et al.,2020d; Wang & Zhao, 2020는 이 다이나믹 adaptive factor를 다음과 같이 예측하였다.
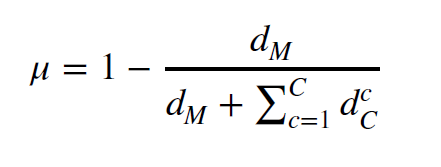
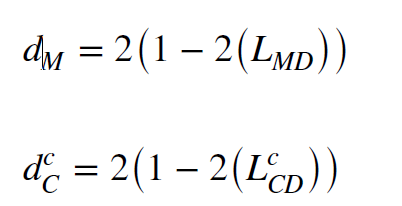
이는 학습 도중에 뮤가 학습이 되어 업데이트가 되는 구조이다. 따라서 distribution의 변화를 학습할 수 있고, weight을 조정하여 토탈로스에 반영된다.
Experimental results and discussion
Case study 1
Data description
XJTU-SY
11kN loading 힘과 2250 rpm 이 소스 도메인,
12kN loading 힘과 2100 rpm 이 타겟 도메인이다.
Approaches implementation
FFT 수행 및 reverse validation 진행하여 적절한 샘플을 sorting하였다.
이는 학습 타겟 샘플의 데이터셋이 사용되어서 소스 샘플을 골라내는 것이다.
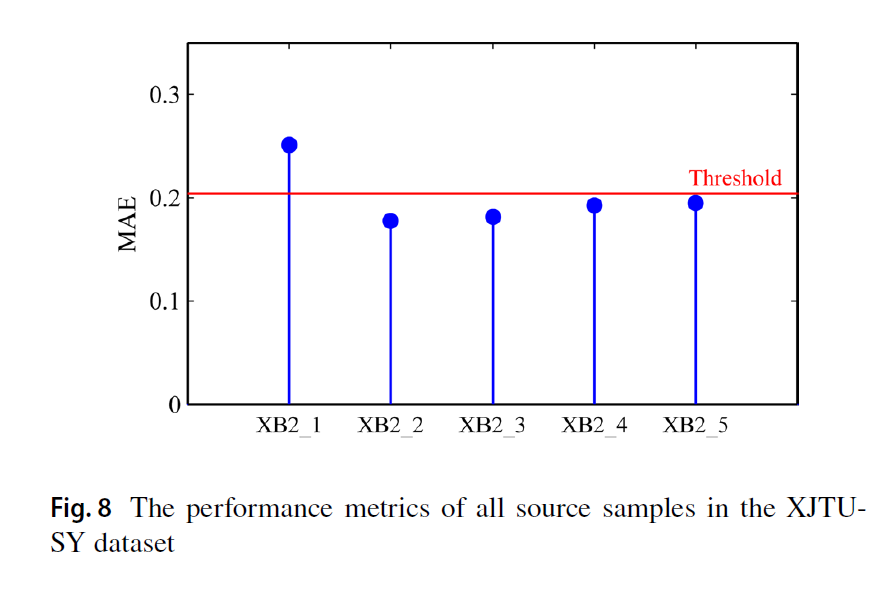
소스 샘플의 퍼포먼스 평균이 threshold로 사용되었다. 이때, threshold를 넘지 못하는 소스 샘플들은 마지막 소스 학습 데이터셋으로 사용된다.
DAAN과 DDAN은 성공적으로 RUL을 예측하였음
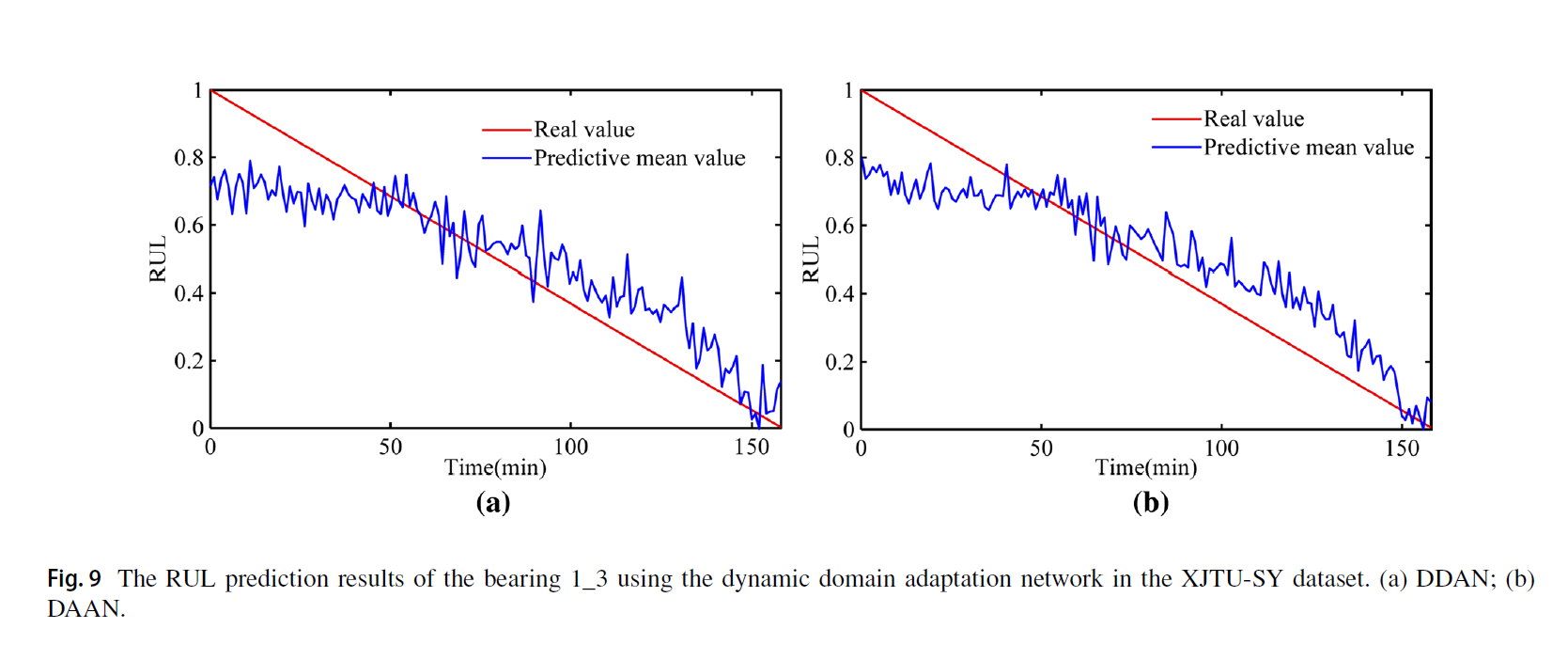
또한 소스 데이터셋을 selection 한 것이 더 성능이 좋았음
Results analysis and discussion
- Analysis of the hyperparameters of the dynamic domain adaptation network
도메인 adaptation 네트워크는 하이퍼 파라미터로 tradeoff, learning rate, batch size 가 있다. 여러 비교 실험을 통해서, DAAN이 DDAN보다 이러한 tradeoff 차이에 영향을 많이 받음을 알 수 있었다. 하지만, 이러한 tradeoff 가 합리적인 구간에 존재한다면, 퍼포먼스가 stable 함을 보였다. 따라서 learing rate 은 0.001, 0.0001, 0.00001 과 batch 사이즈는 64, 128, 256으로 두었다. 실험 결과, 0.0001, 128로 둔 값이 퍼포먼스가 좋았다. - Comparison with the prognostic method without source
sample selection
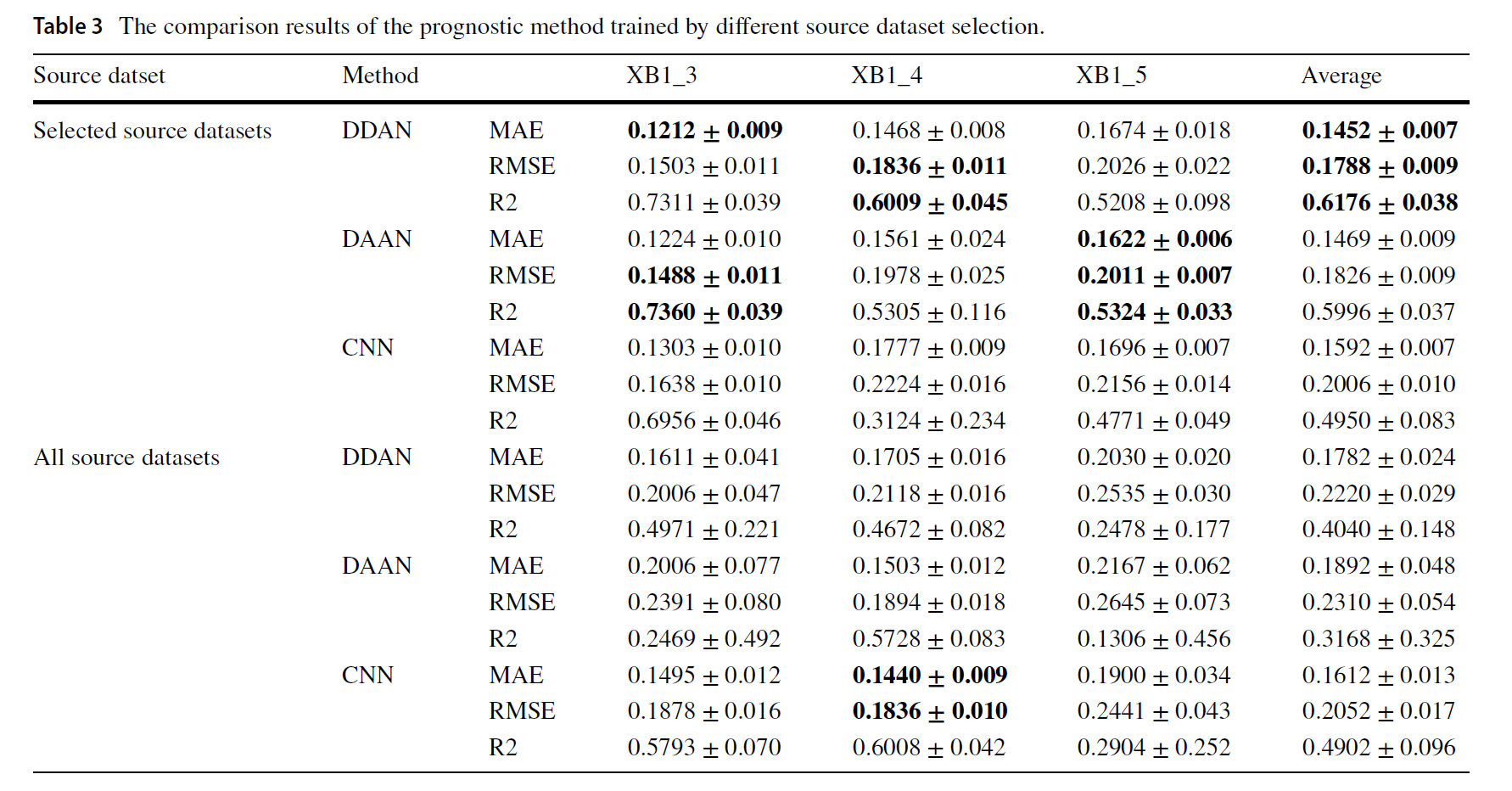
RUL 예측 모델을 DDAN과 DAAN 각각 학습한 결과, 다음과 같이 sample을 selection 한 결과가 더 좋았다.
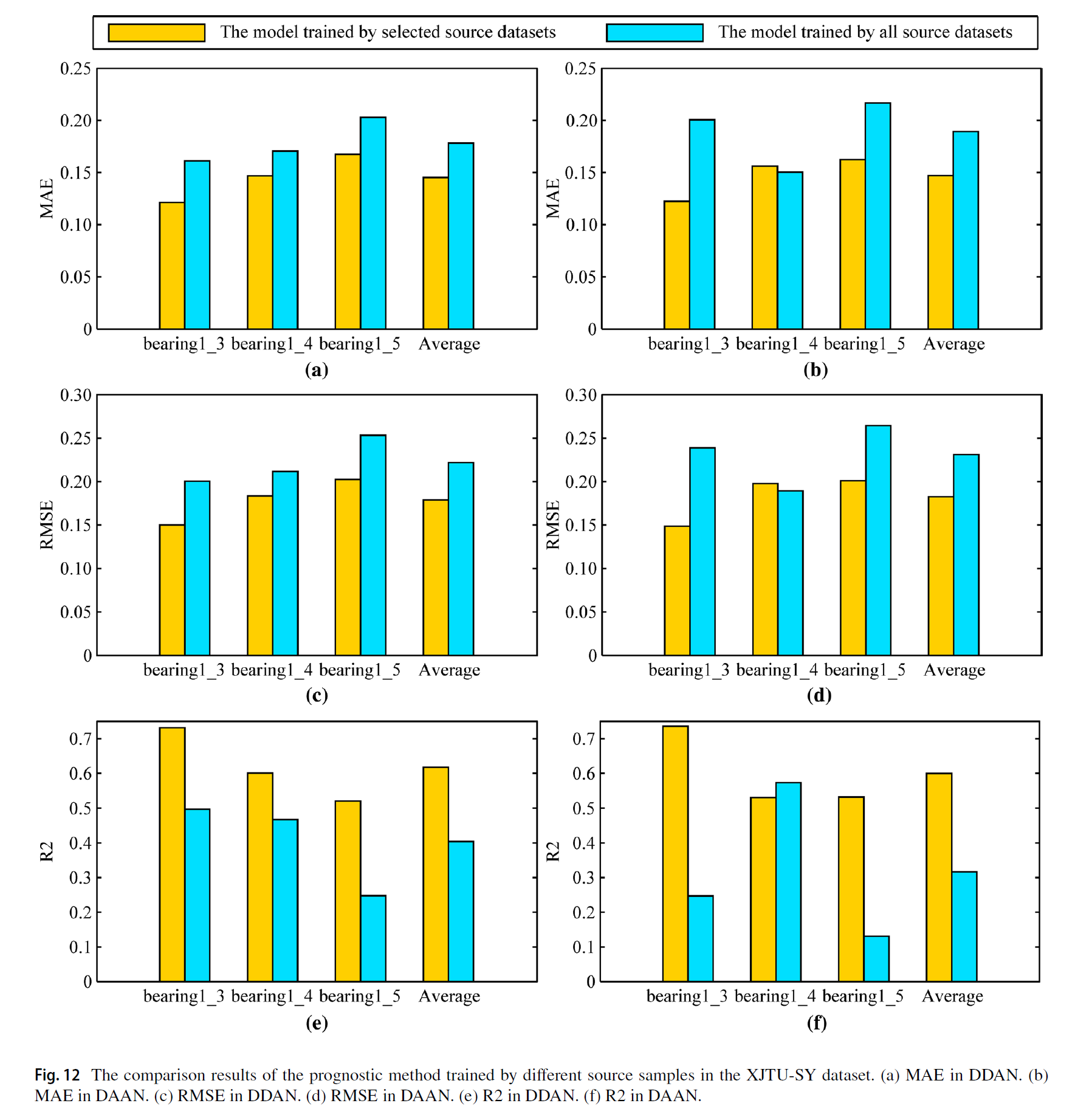
이는 negative transfer를 수행하는 dataset을 제거하는데, 이는 bearing 1_2을 추가하여 RUL을 예측하였을 때 CNN 혹은 DDA와 같은 기본적인 모델에서도 성능이 떨어지는 것으로 보아, 네트워크에 학습하면 부적절한 샘플이라고 보았다. 이러한 결과를 통해 reverse validation 기술이 적절한 소스 샘플을 선택하여 학습 데이터를 취사선택하고, 이것으로 효과를 확실하게 검증함을 보였다. - Comparison with the other prognostic method
ML 모델, DL 모델, 그리고 nonadversarial DTL 기반의 예측 모델 기반으로 수행하였을 때 본 모델의 성능이 좋았다.
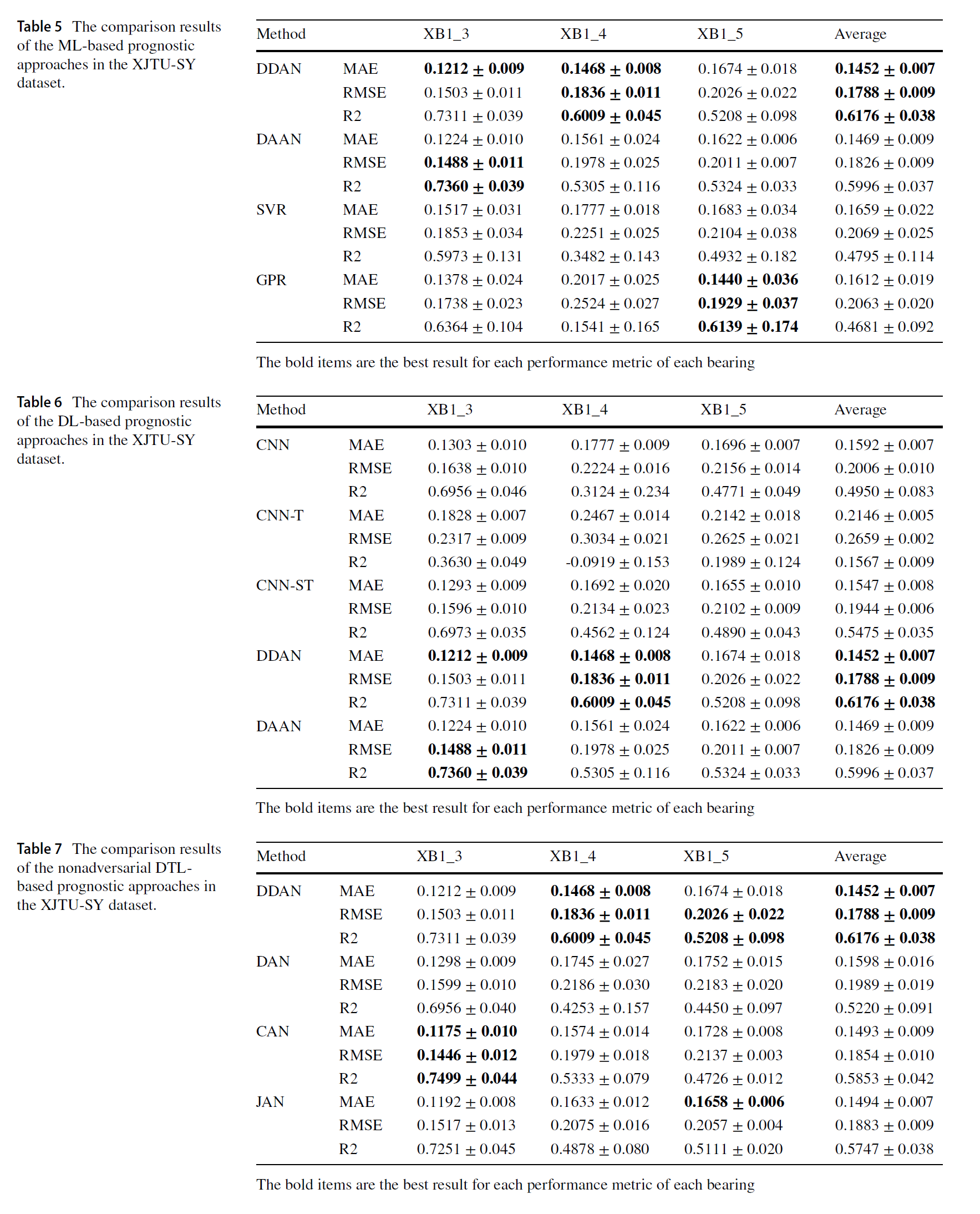
또한, dynamic adaptation factor의 영향을 보기 위하여 실험을 진행하였다. 뮤 값에 따라서 퍼포먼스의 변동이 심했는데, 이 값을 고정하는것이 아닌 본 연구와 같이 유동적으로 예측하여 뮤값을 설정하는것의 효과를 보였다.
Case study 2
PHM2012 데이터셋으로 진행하였다.
Prognostics results, comparison and discussion
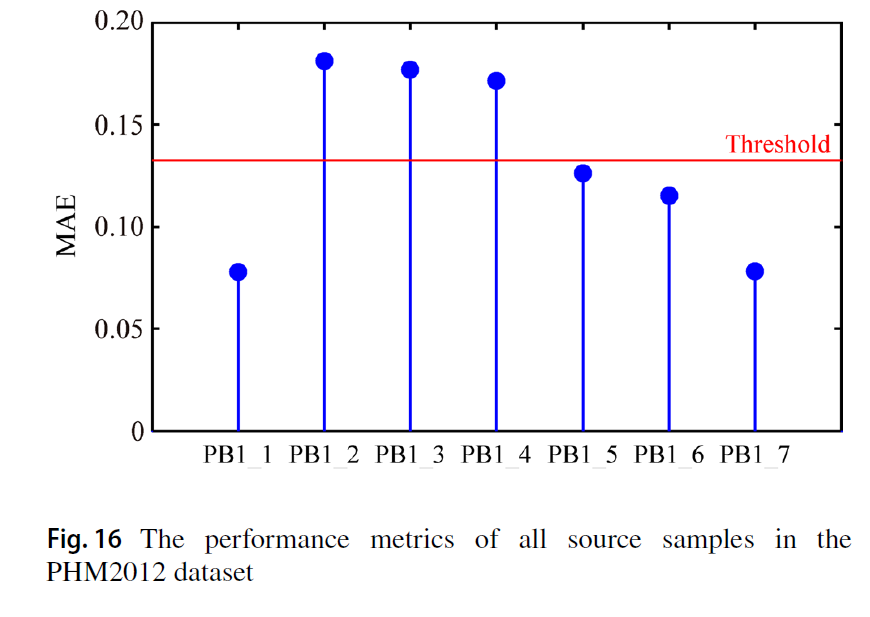
먼저, 데이터셋에 대해서 퍼포먼스를 측정한 결과 다음과 같았다. 따라서, threhold를 넘은 3개의 데이터만을 이용해서 학습을 수행하였다
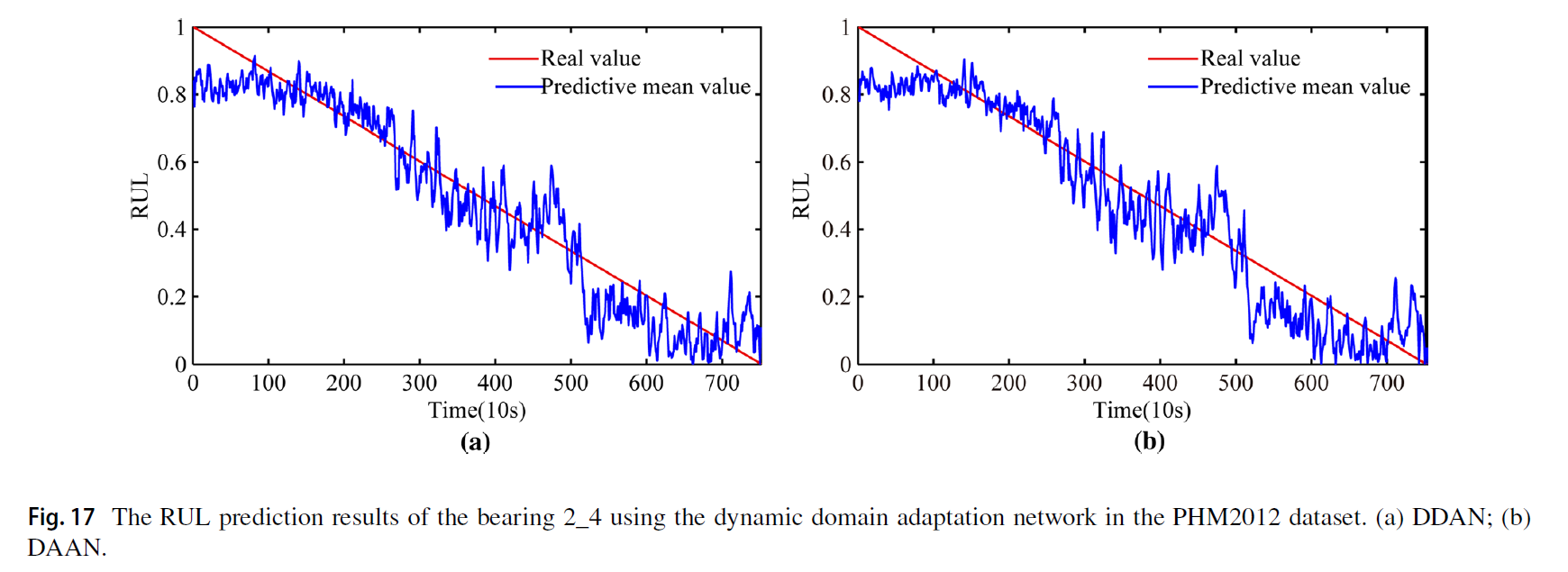
bearing 2_4에 대해서 regression을 수행한 결과 다음과 같이 DDAN, DAAN 모두 잘 예측을 수행하였다.
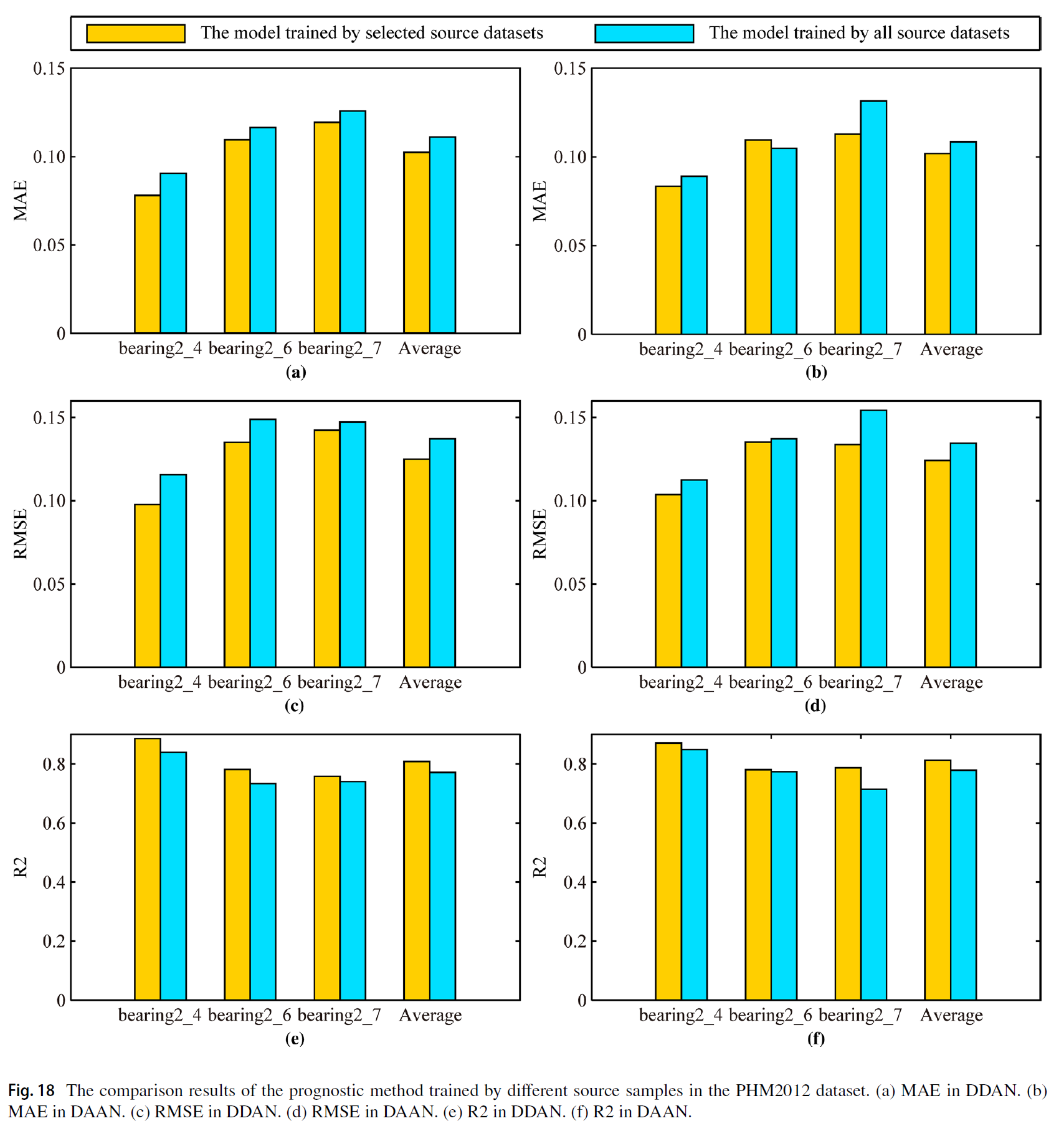
마찬가지로, 모든 데이터를 학습하지 않고 revese validation sample selection 방법으로 학습을 수행하였을 때 성능이 좋았다.
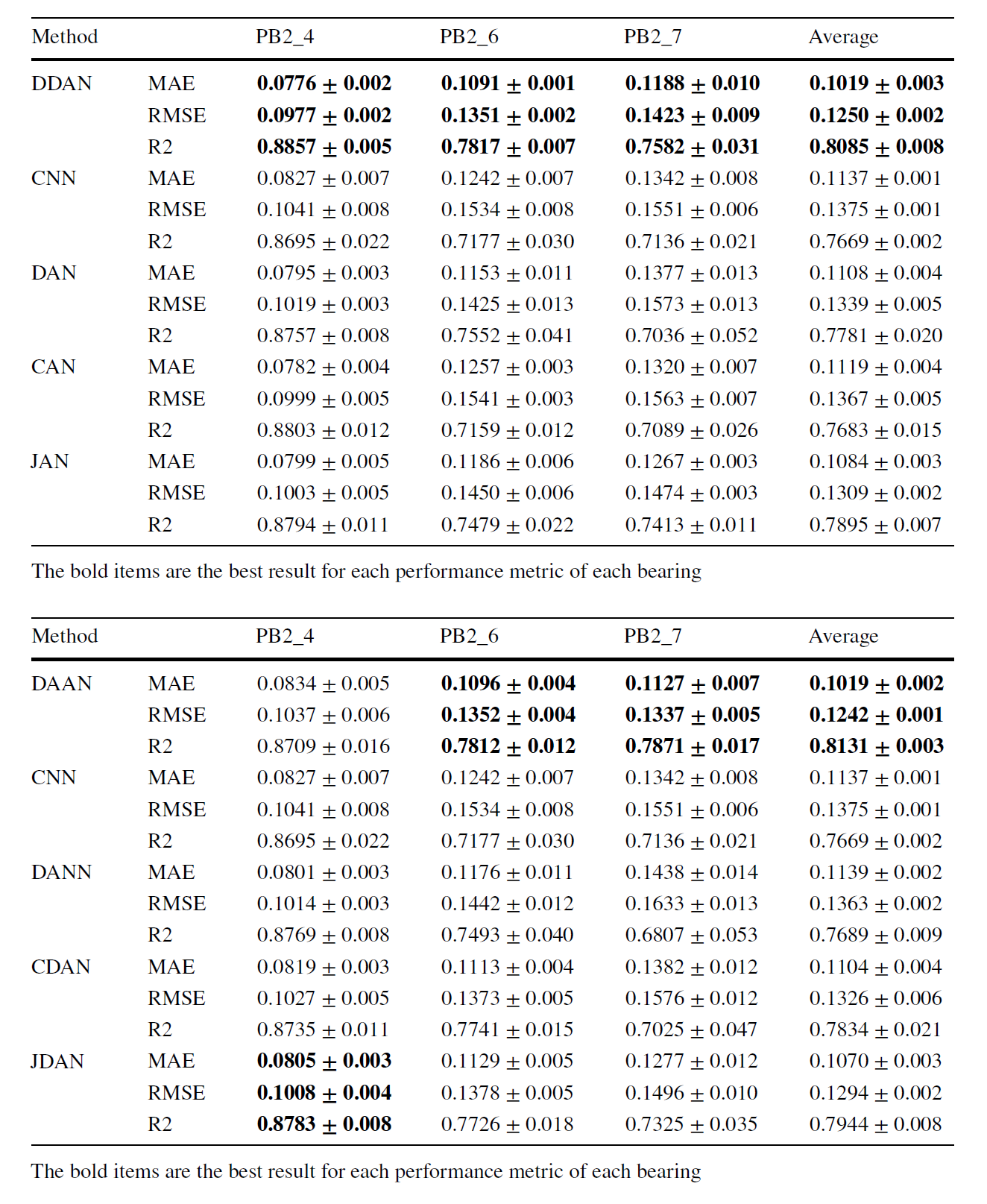
또한 다른 방법론과의 비교 실험에서도 제안한 방법론이 마찬가지로 좋은 성능을 보였다.
Conclusions
본 논문에서는, dynamic domain adaptation 네트워크 기반 RUL 예측 방법론을 제안하였다. 처음으로, revese validation 기술을 통해 적절한 RUL 예측 모델을 구성할 수 있는 샘플들을 선택하였다. 그리고, 2가지의 dynamic domain adaptation network인 DDAN과 DAAN을 domain invariant한 feture를 추출하고 RUL을 예측하였다. 또한 dynamic adaptive factor가 학습 과정에서 marginal과 conditional distribution 을 통해 적응적으로 조정되기 때문에 모델의 퍼포먼스를 향상시켰다. 추후 연구로는, 멀티 센서 정보를 퓨전하는 하이브리드 방법론을 통해서 RUL을 예측해 보고자 한다.
