Efficient Deep Reinforcement Learning With Imitative Expert Priors for Autonomous Driving
abstract
DRL은 자율주행영역에서 많은 달성을 이루었지만, DRL을 위한 reward 함수 설정의 어려움과 낮은 샘플 효율로 인해서 실제 활용이 힘들었다. 이러한 문제점에 착안하여서, 본 연구에서는 사람의 prior 지식과 DRL을 결합한 독창적인 프레임워크를 제안하여 샘플효율을 증가하고 복잡한 보상함수의 디자인 노력을 개선한다. 우리의 프레임워크는 3가지로 구성된다.
1. expert demonstaration : 인간 전문가가 태스크의 실행을 설명하고, state-action 페어에 행동이 저장된다.
2. politcy derivation : 전문가의 정책을 모방하는것이 behavioral cloning과 uncertainty estimation을 통해서 수행된다.
3. RL : 모방 전문가 정책이 DRL agent를 학습하는것을 이끄는데, 이는 DRL agent의 정책과 imitative expert 정책의 KL divergence를 제한하면서 이루어진다.
제안한 방법론의 효과를 자율주행 영역에서 검증하기 위해서 2개의 시뮬레이션을 수행하였고, 베이스라인 알고리즘에 비해 많은 햧ㅇ상을 나타내었고, agent가 가장 높은 성공률을 나타내고 인간 전문가와 가장 유사하였다.
이를 통해, 제안 방법론은 DRL을 통해 agent를 학습하여 사람과 같이 자율주행을 실제 활용을 할 수 있는 가능성을 보였다.
Introduction
RL에는 2가지의 문제가 있다. 첫 번째는 데이터 효율이 너무 낮다는 것이다. RL agent가 정책을 학습하기 위해서는 아주 많은 interation을 수행해야 하기 때문이다. 이는 자율주행과 같은 다양한 문제가 있는 환경에서 특히 더 어려워진다. 다른 문제는 리워드 함수를 디자인하는 것으로써 이것이 잘 구성되지 못한다면 agent가 잘못된행동을 하게끔 이끌게 된다. 따라서 정확한 함수를 디자인하는 것은 아주 많은 시간과 비용을 야기한다. 기존의 연구에서는 보상 함수가 inverse RL과 같은 사람이 만들어낸 운전 데이터를 통해 보상함수를 만들 수 있었지만, 이는 몇몇 가정이 필요하고 실제 환경에서는 적합하지 않다는 문제점이 있다.
이러한 두가지 문제점을 해결하기 위해서 본 연구에서는 RL 프레임워크클 통해 인간 전문가의 지식을 RL agent에게 야간의 demonstaration을 통해서 주입한다. 이를 통해 샘플 효율성을 높이고 동시에 복잡한 보상 함수 디자인 과정을 극복할 수 있다. 첫 번째로 인간 전문가의 지식을 증류하기 위해서 본 연구에서는 imitation leatning 방법을 사용하고, uncertainty estimation을 활용한다. RL agent의 학습 과정에서 전문가의 policy와 가까워지도록 정책을 제한하여 imitative가 되게 한다. sparse reward function일때 인간과 유사한 운전 행동을 달성할 수 있다.
이러한 두가지 문제점을 해결하기 위해서 본 연구에서는 RL 프레임워크클 통해 인간 전문가의 지식을 RL agent에게 야간의 demonstaration을 통해서 주입한다. 이를 통해 샘플 효율성을 높이고 동시에 복잡한 보상 함수 디자인 과정을 극복할 수 있다. 첫 번째로 인간 전문가의 지식을 증류하기 위해서 본 연구에서는 imitation leatning 방법을 사용하고, uncertainty estimation을 활용한다. RL agent의 학습 과정에서 전문가의 policy와 가까워지도록 정책을 제한하여 imitative가 되게 한다. sparse reward function일때 인간과 유사한 운전 행동을 달성할 수 있다.
따라서 본 연구의 메인 contribution은 다음과 같다.
1. imitative 전문가로부터 demonstration을 받는 RL 프레임워크를 제안한다. IL을 uncertainty quantification 방법론을 통해서 학습이 수행되며 RL agent의 행동이 regularize 괴어서 exploration 능력이 향상된다.
2. 2개의 다른 방법론인 value penalty와 policy constraint을 제안하여 actor - critic 알고리즘의 프레임워크에 imitative expert policy를 결합한다. 이를 통해 샘플 효율을 증가하고, 기존의 RL 알고리즘에 비해 제안 방법론의 성능을 향상시킨다.
3. 제안 방법론이 운전 시나리오에 대해 검증이 되어 환경으로부터 실제 sparse reward 피드백을 받더라도 인간과 같은 운전 시나리오에 대응이 가능하다.
RELATED WORK
A. Imitation Learning and Reinforcement Learning
IL과 RL은 자율주행해서 많은 발전과 응용을 이루고 있다. IL은 자율주행에서 사람을 모방하는 방법론으로 정책을 학습시킬 수 있다는 장점이 있다. 하지만 IL의 단점은 distribution shift 문제이다. 이는 학습과 추론 단계에서의 데이터 분포 불일치로 인해서 많은 오류가 발생하게 된다. 따라서 RL은 이러한 문제점을 해결할 수 있다. 이것은 환경의 온라인 interatction에만 의존하기 대문이다. 하지만, RL을 학습하는 방법은 매우 비효율적이다. 이는 시뮬레이션된 환경에서도 마찬가지이다. 또한 리워크 함수를 결정하고 이를 튜닝하는 것은 매우 시간적으로 비효율적이다.
B. Learning With Human Prior Knowledge
RL의 학습 과정에서 샘플의 효율을 높이기 위해서 RL 기반의 정책에 인간 전문가 지식을 주입시키기 위한 노력이 있어왔다. 특히 인간의 guidance를 활용하는 것은 solutuion space를 줄이고 RL agent의 exploration 을 줄일 수 있다. 이는 학습 과정에서의 불필요한 interation을 줄이게 된다. 그리고 이러한 방법론은 온라인의 인간 guidane에 아주 많이 의존하게 된다. 오프라인에서의 인간 전문가 지식이 활용되는 것이 매우 중요하다. 이는 RL agent와 human expert가 항상 온라인으로 상호작용하기 어렵기 때문이다.
C. Reinforcement Learning With Demonstrations
인간의 demonstration을 RL에서 효과적으로 활용하기 위해서 정책을 기존에 가지고 있는 지식을 통해서 적절한 수준으로 초기화 시키는 것이 중요하다. 그리고 RL을 좋은 reward 함수를 통해서 정책을 업데이트 해야 한다. 그러나 이 방법론은 RL의 맥시멈 엔트로피에서 정책의 randomness를 극대화 하고 정책의 explore를 초기에 최대화 시키기 때문에 이 방법이 잘 작동하지 않기도 한다. 대체 방법론으로는 RL 알고리즘에 리플레이 버퍼에 전문가 지식을 추가하여서 expert demonstration과 agent의 interatction으로 정책을 업데이트한다. 그러나 이러한 방법론은 각 state - action 페어에 대해서 annotating reward가 필요하고, expert reward 가 inaccessibile 한 경우도 존재한다.
따라서 본 연구에서는 최근 오프라인 RL의 발전 방향인 정책이 behavior 정책과 가깝게 학습되도록 유도하는 방법론을 사용한다. 온라인 RL 세팅에서 행동 정책이 전문가 demonstrations를 통해 학습이 되고, RL 에이전트의 행동과 exploration을 제안하는 가이드를 만든다. RL agent의 exploration capability를 유지하기 위해 uncertainty estimation을 활용한다. 이를 통해 agent는 uncertainty가 더 많다면, imitative expert 정책이 신뢰가능하지 않게 된다. 또한, reward 함수 디자인이 아주 간단하게 된다. 이는 에이전트의 행동이 expert policy에 의해 제한되기 때문에 sparse reward 가 이루어지게 된다. 이는 복잡한 환경에서도 똑같이 발생된다.
BACKGROUND
A. Reinforcement Learning
RL은 다이나믹 시스템에서 MDP로 정의된다. 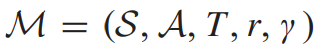
RL의 타겟은 long-term discounted cumulative reward를 얻은 정책을 학습하는 것이다.
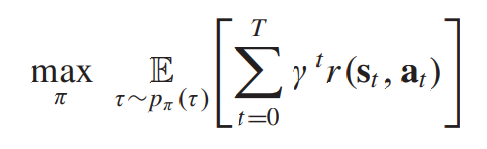
state value function(V-function)과 state action value function(Q-function)은 recursice하게 정의된다.
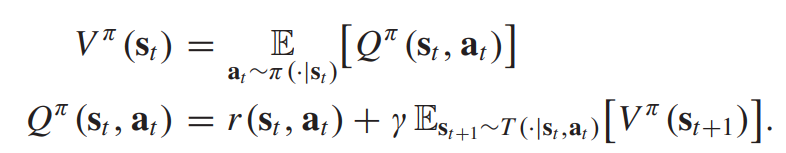
cumulative discounted 보상을 최대화하기위해 soft actor-critic (SAC) 은 통계적 정책을 사용하고 엔트로피 term을 통해서 exploration을 조정한다.
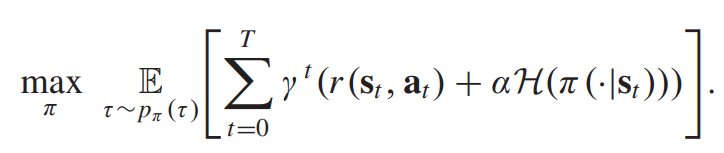
B. Behavioral Cloning
expert policy는 직접적으로 access 할 수 없기 때문에 많이 사용되는 방법론이 IL의 expert demonstration을 통해서 접근하는 것이다. 이전에는 expert demonstration dataset이 있다고 하면, 각각의 trajectory가 state-action pair로 존재하게 ㅗ디고, imitative exepert policy는 log-likeily 를 최대화하면서 이루어진다.
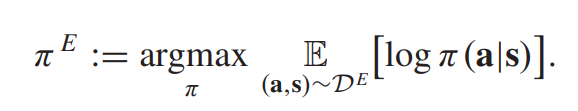
behavioral cloning (BC) 셋업에서 expert policy는 neural network 파리미터화가 되며, 스테이트 인풋 벡터와 싱글 deterministic 아웃풋을 만든다. policy 네트워크는 mean squared error를 최소화하면서 이루어지게 되는데, 이는 다음과 같다.
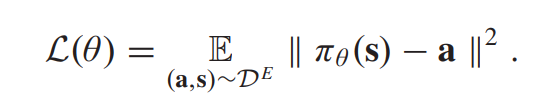
하지만 이러한 방법론은 deterministric 정책을 학습할수밖에 없다. 이것은 액션의 분포 학스벵는 적합하지 않다.
C. Policy Uncertainty
stochastic expert policy를 얻기 위해서는 인간의 전문가에게서의 uncertainty를 고려해야 한다. 이는 같은 state에서도 다른 action을 수행하는 인간의 상황을 모방해야 한다는 것이다. 따라서, 이러한 불확실성을 고려하기 위해서는 액션이 가우시안 분포를 가진다고 가정하는 것이다. 이는 다음과 같은 목적식으로 구성된다.
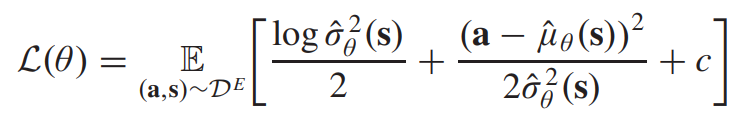
D. Model Uncertainty
expert의 확률적 policy를 고려하였다면 정책에 대한 mean과 variance에 대해서는 아직 certain 하거나 reliable하지 않다. 이는 학습 데이터셋에 고려되지 않았을때 그렇다. 모델의 불확실성은 학습 데이터의 부족함 때문에 일어나게 된다. 따라서 모델의 불확실성을 예측하는것은 imitative expert policy를 제안 방법론에서 핵심이 되고, RL 에이전트가 demonstration 데이터셋에 대해서 포함이 되어 있지 않은 상황을 자주 마주칠때 고려된다. 따라서 이를 통해 out-of-distribution 상황에서 신뢰도를 획득할 수 있게 된다.
본 연구에서는 이러한 상황에 대비하기 위해서 deep ensemble 방법론을 사용하게 된다. 이는 간단하고 효율적인 방법론이다. 이는 각기 다른 random 초기화된 M 네트워크에 대해서 앙상블을 활용하고 다른 데이터를 활용한다. 모든 네트워크를 취해서 결과를 가우시안 mixture 분포에 근사시키고, 이들의 평균과 분산은 다음과 같이 계산된다.
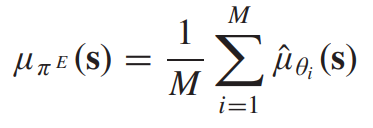
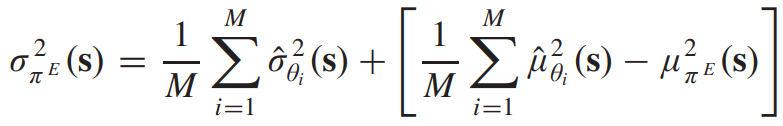
DEEP REINFORCEMENT LEARNING WITH IMITATIVE EXPERT PRIORS
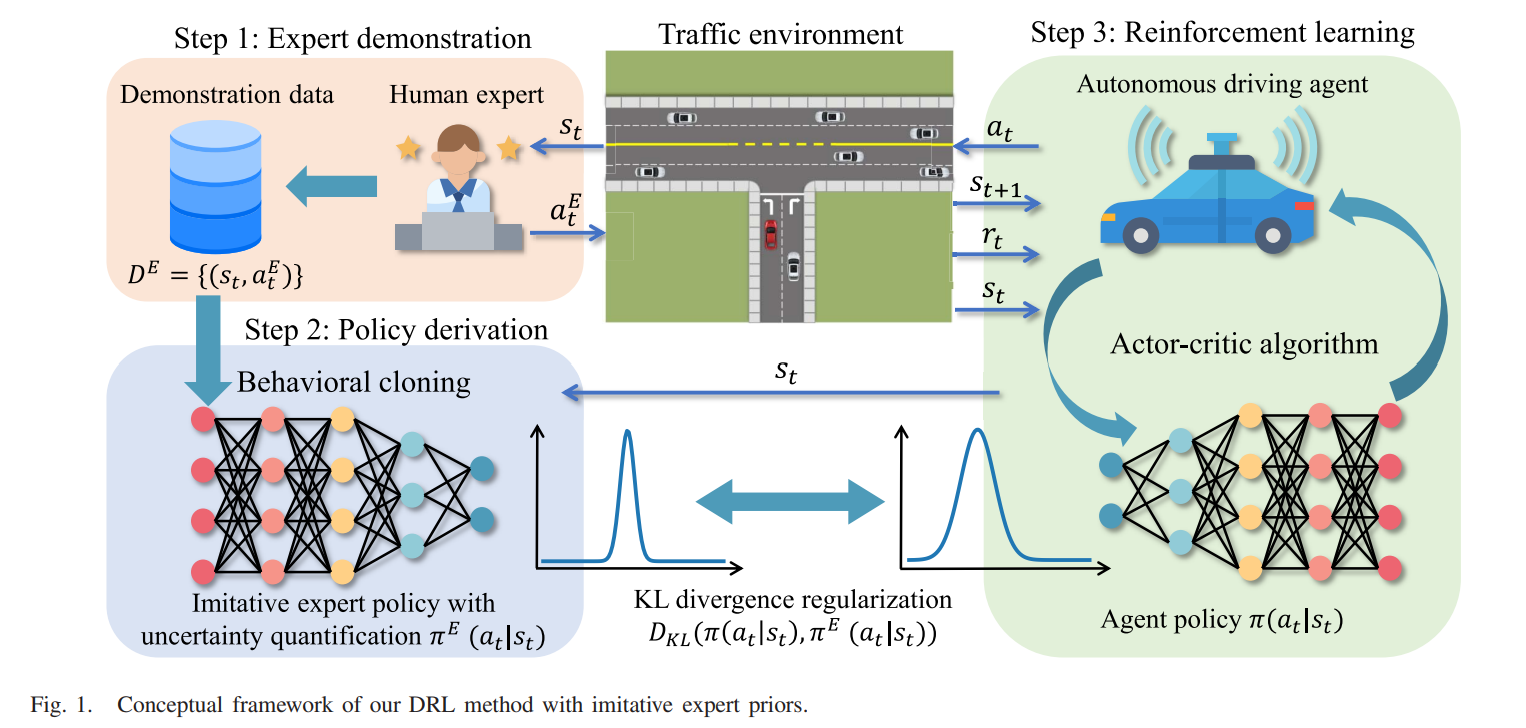
A. Framework
3 가지의 스텝을 가지고 있다.
1. expert demonstration : 태스크에 대한 실행과 함께 그들의 행동이 state-action pair에 인코딩 되어있다.
2. policy derivation : imitative expert 정책이 demonstration data를 기반으로 수행된다.
3. RL : RL agent의 학습 과정에서 imitative expert policy가 적용된다.
B. Actor-Critic Algorithm
agent 학습 과정에서 수정된 actor - critic RL 알고리즘을 제안한다. agent policy를 imitative expert policy 로 제한하기 위해서 2가지 방법론을 사용한다.
알고리즘은 4가지의 네트워크를 학습한다. Q함수 네트워크 2개와, value 함수 네트워크와 stochastic 정책 네트워크이다.
Q함수 네트워크는 하나의 shared target으로 학습이 되며 다음과 같은 목적식을 갖는다.
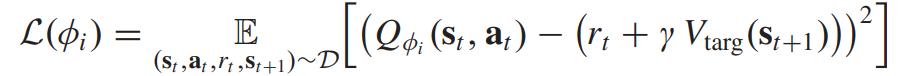
Value 함수 네트워크는 다음과 같은 로스식을 통해 업데이트 된다.
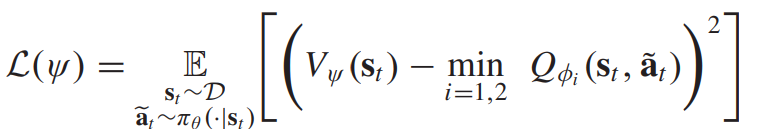
정책 네트워크의 로스식은 다음과 같다.
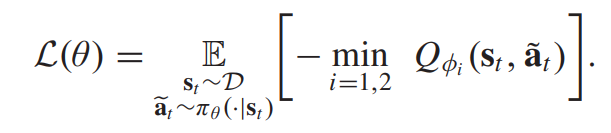
Q-learning과 정책 학습 프로세스를 거쳐서 2가지의 접근 방법론인 imitative expert priors와 actor-critic 알고리즘을 통합한다. 이는 divergence panelty를 value function에 추가하는 것과 agent policy와 expert policy간 divergence 자체를 제한하는 것이다.
C. Expert Priors as Value Penalty
학습된 policy가 expert policy와 비슷하게 학습이 이루어지도록, 다음과 같은 보상함수에 패널티 텀을 추가한다.
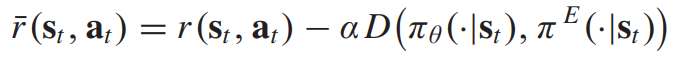
이는 패널티 텀을 value 함수에 직접적으로 추가하는것과 동일하다. 그러므로, 다으모가 같이 로스식을 업데이트하게 된다.
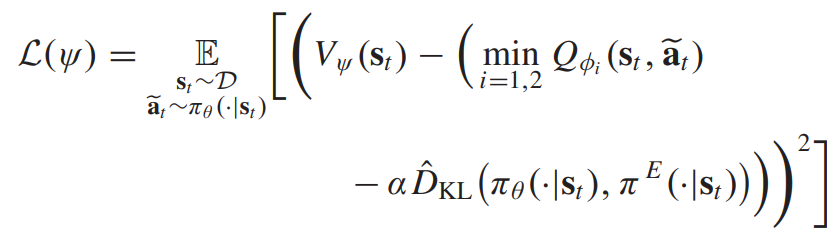
결과적으로, 정책은 각 state에서 패널티가 추가된 value function을 최적화해야하고 그러므로, 각 정책 네트워크의 policy는 다음과 같다.
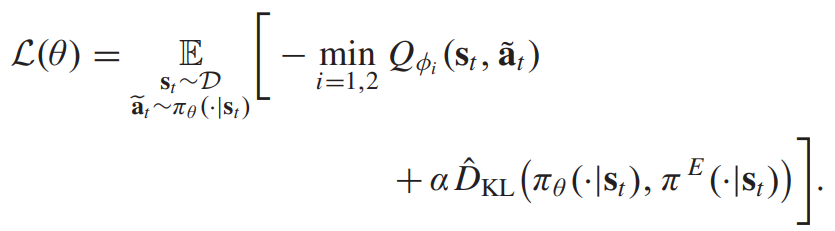
D. Expert Priors as Policy Constraint
value function에 패널티항을 추가하는 것이 아니라 학습 policy와 expert policy와의 divergence 자체를 제한하는 방법이 있다. 이는 다음과 같이 나타난다.
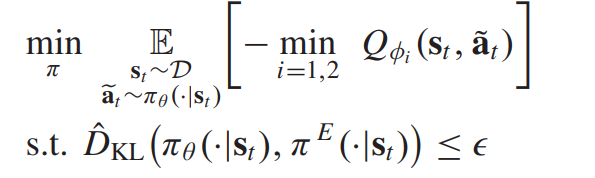
이 최적화 문제는 라그랑지안 듀얼 문제로 풀수 있다.
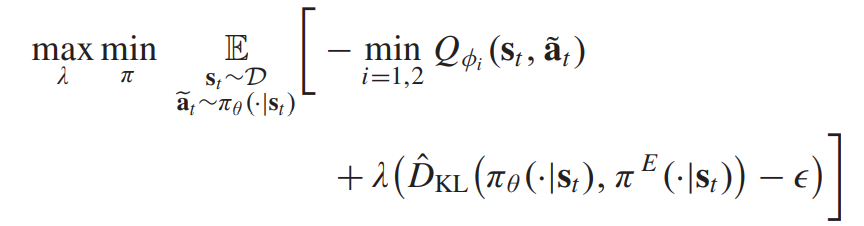
EXPERIMENTAL SETUP
A. Driving Scenarios
SMARTS 시뮬레이션 플랫폼을 활용하여 수행하였다.
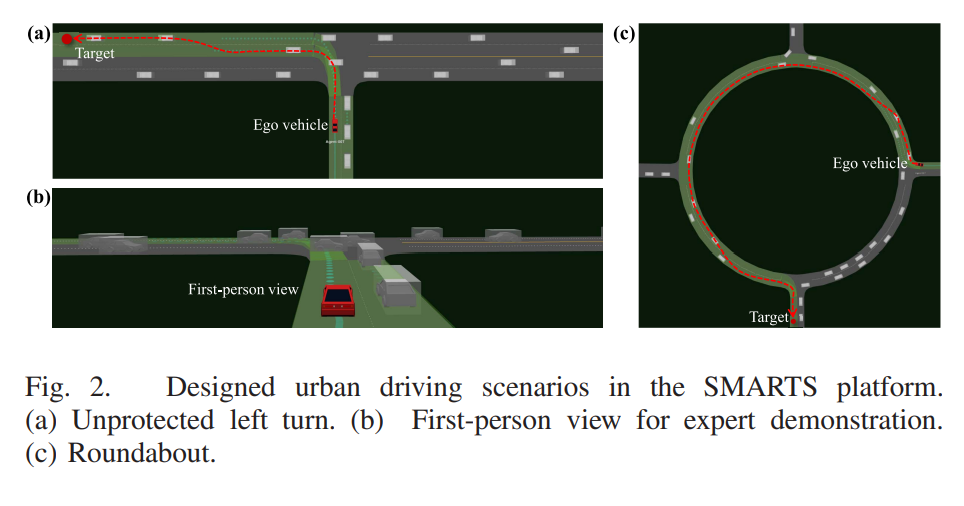
자율주행 agent는 비보호 좌회전 태스크를 복잡한 상황에서 수행하게 된다. 또한 회전교차로에서의 자율주행 시나리오도 존재한다. 이러한 두가지 시너라오를 통해 제안한 방법론의 효과를 검증하게 된다. 좌회전은 복잡하지만 태스크자체는 빨리 끝나게 된다. 회전교차로의 경우에는 반대로 태스크 자체는 간단하지만 오래 걸리는 문제이다. 본 연구에서는 실제 상황을 시뮬레이션하기 위해서 driving behavior 모델의 파라미터를 랜덤하게 선택하였다. 20개의 서로다른 traffic flows를 학습하게 된다. 테스트 단계에서는 또다른 50개의 traffic flows를 만들어서 generalization capability를 만들게 된다.
B. MDP Formulation
1) State Space: 조감도 이미지를 활용하였다. 이를 통해 enviroment 정보를 임베딩한다. 이것은 ego vehicle이 센터에 있게 된다. 조감도 이미지는 다음과 같이 나타난다.
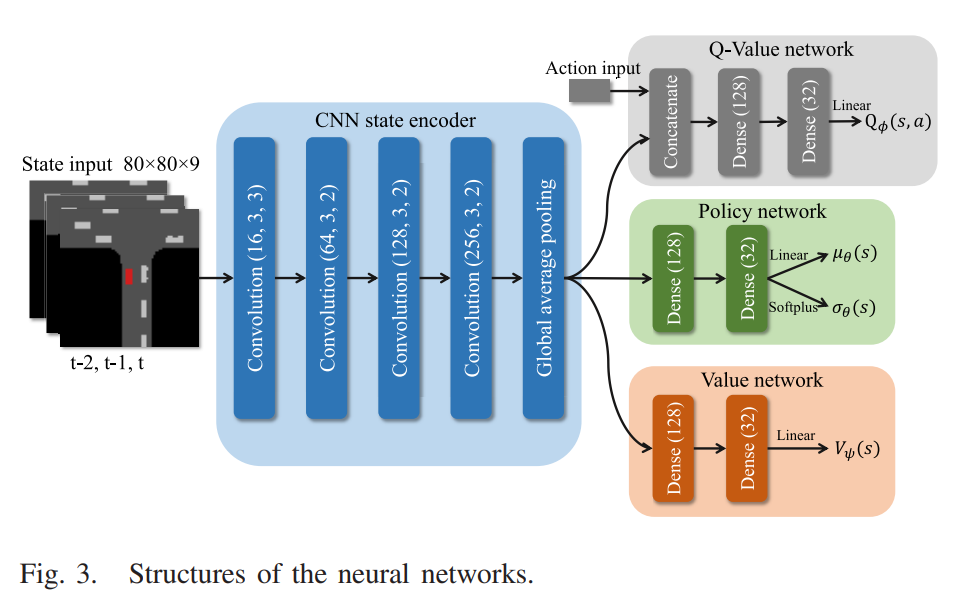
조감도 사이즈는 80x80x3 이며, 3개의 이미지를 stack 하여서 state 인풋으로 한다.\
2) Action Space: lane following controller를 통해서 컨트롤을 한다. 이는 타겟스피드, 레인 체인지로 이루어진다. 이는 steering이나 sccelerator와는 다르게 직접적으로 컨트롤하지 않고 하이레벨에서 이루어진다. 이러한 컨트롤 세팅을 가져가는 이유는 이러한 longitudinal 모션은 더 정제된 액션을 필요로 하는 반면에, discrete lane fllowing 혹은 lane change 와 같은 액션은 대부분에서 비슷한 값을 가지면 되기 때문이다.
3) Reward Function : 의미있는 값을 학습 에피소드 마지막에만 아웃풋으로 내보내는 sparse reward function을 활용한다. 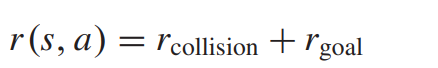
하지만 sparse reward는 베이스라인 RL 알고리즘이 적절한 퍼포먼스를 획득하기 어렵게 만든다. 그러므로 reward shaping 테크닉을 활용하여 다음과 같이 나타낸다.
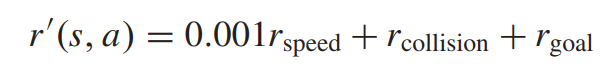
이러한 shaped reward 함수를 통해서 reward-shaping term으로부터의 disturbance를 방지한다.
C. Expert Demonstration
인간 전문가는 드라이빙 태스크에서 사람의 시각으로 본 데이터에서 액션을 제공하게 된다. 4가지의 discrete actions는 키보드를 통해 나타낼 수 있다. 스피드업, 스피드 다운 / 그리고 차선 왼쪽변경, 오른쪽 변경 이렇게 총 4가지로 이루어진다. 이러한 액션은 모든 timestep 에서 제공되지는 않는다. 또한 전문가에게 이야기해서 공격적으로 행동하는것과 같은 다양한 태스크의 액션을 획득하였다. 비보호좌회전과 회전교차로의 경우에서 각각 40개의 trajectories 를 획득할 수 있었다.
D. Comparison Baselines
1. SAC 2. Proximal Policy Optimization (PPO) 3. Generative Adversarial IL (GAIL) 4. Behavioral Cloning (BC)
E. Implementation Details
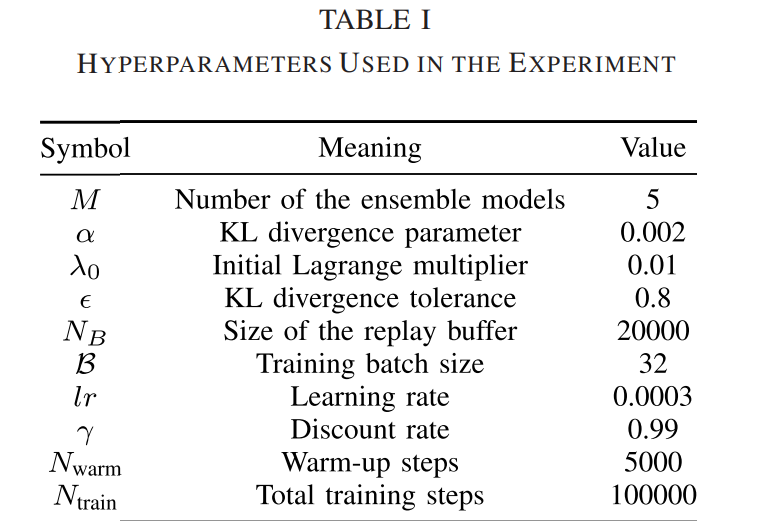
NVIDIA RTX 2080 Super GPU, AMD 라이젠 3900X 를 학습에 활용하였음
RESULTS AND DISCUSSIONS
A. Training Results
비보호 좌회전 시나리오에서 인간 전문가는 보수적, 공격적 두 가지 운전 스타일로 학습을 수행하였다. imitatiave 전문가 정책은 모델 불확실성을 사용하여 유도되며, 10회의 시도가 수행되어 해당 방법의 평균 훈련 성능을 반영하게 된다. 제안된 방법론과 baseling 방법론의 보상 함수가 다르기 때문에 평균 성공률을 활용하게 된다. 이는 마지막 20개의 에피소드에서 성공적으로 완료한 에피소드 수를 20으로 나눈 것을 의미한다. 이는 제한된 시간 내에 목표 지점에 도달할 때만 계산된다. 실패 조건에는 다른 차량과 충돌, 운전 가능한 도로를 벗어나거나, 허용 시간을 초과하는 경우이다.
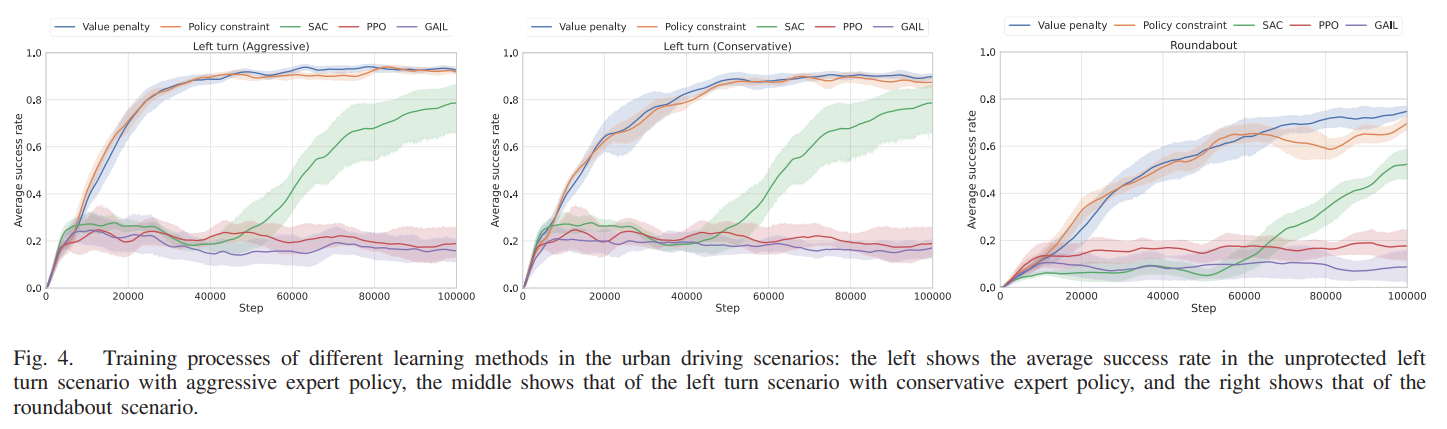
이는 다양한 방법의 훈련 결과를 보여주는데 학습 프로세스는 평균값의 실선과 95%의 신뢰 구간으로 표시된다.
비보호좌회전 시나리오에서, 제안 방법의 퍼포먼스가 제일 좋았다.
2가지의 value function panelty 와 policy constraint 방법론 둘 다 비슷한 성능을 보였다. SA와 비교하여 본 연구는 30%의 샘플만으로도 비슷한 성능을 획득하였다. SAC는 무작위로 exploration을 하는 반면에, 본 연구에서 사용한 전문가 imitative 방법론을 통해서 샘플 효율이 증가함을 알 수 있다. 또한 SAC의 훈련 과정은 다양한 시도 간에 불안정한 모습을 띄는데 반해, 본 연구에서 제안한 방법론은 비교적 일관된다. 또한 PPO와 GAIL은 성능이 그리 좋지 않음을 알 수 있다. 다양한 운전 행동에서학습의 차이에 대해서는 보수적인 행동을 학습하는 것이 공격적인 행동을 하는 것보다 어려웠는데, 이에 대해서는 보수적인 경우에는 중간에 멈추어야하는 경우가 생기기 때문이다. 또한 ego 차량은 enviroment 차량이 안전 사항을 위반하더라도 ego 차량에 양보해야 하는 의도로 설계되어있기 때문에 이 기능을 이용해서 공격적인 시나리오에서 더 잘 학습이 되었다.
또한 원형 교차로의 경우에도 비슷한 결과로 다른 비교 모델 대비 좋은 성능을 보였다. 단지 본 연구에서는 value function에 패널티 항을 추가하는 것이 정책을 제안하는것보다 더 좋은 성능을 보였다. 이는 환경으로부터의 보상 피드백이 희박하고 보상에 추가적인 피드백을 추가하는것이 행동과 상태의 가치를 더 잘 추정할 수 있기 때문이다.
B. Testing Results
학습이 완료되었다면 50개의 또다른 교통 흐름을 생성한 다음 최고의 훈련 성능을 보이는 주행 정책을 활용하여 시작점부터 도착점까지 탐색하게 된다. 테스트에서는 확률 정책의 평균값만 출력 동작으로 수행하게 된다. 테스트 성공률은 50개의 모든 시나리오에 대해서 성공했을 때를 기준으로 평가된다.
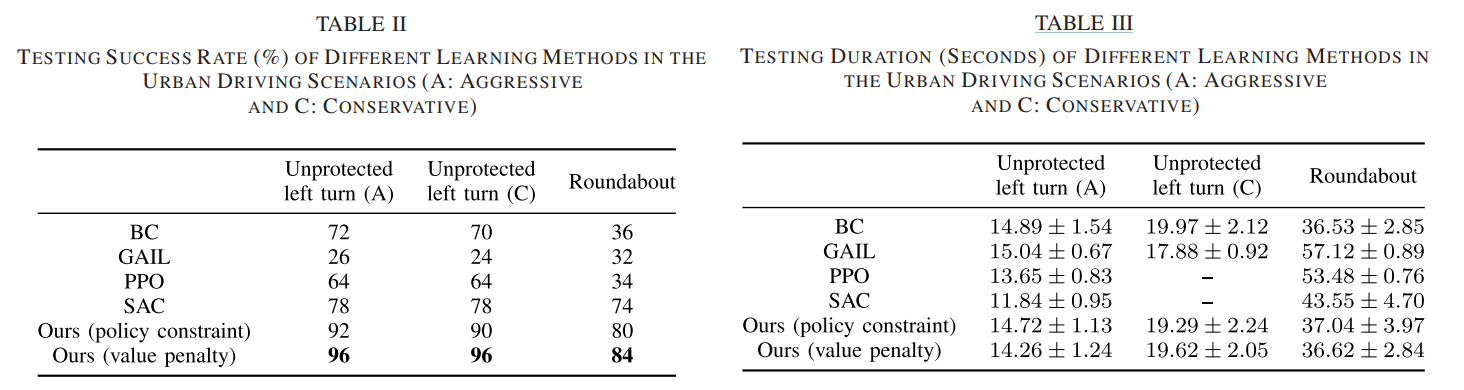
Table 2에 따르면 본 연구에서 제안한 방법론이 제일 좋은 성공률을 보였다. 특이사항으로 SAC의 경우 비보호좌회전 테스트 시간이 매우 짧다. 이는 더 높은 속도로 가능한 한 빨리 목표 지점에 도달하도록 유도되었기 때문이다. 이는 SAC가 매우 공격적으로 학습이 되었음을 알 수 있다. 하지만 본 연구에서 제안하는 방법론은 인간 지식을 기반으로 학습을 수행했기 때문에 주행 스타일에서 안정적이다.
또한 원형 교차로의 경우에는 반대로 더 SAC가 더 길게 되었는데 이는 주로 외부 차선에 붙어있고, 더 높은 속도를 얻기 위해 차선을 변경하지 않았다. 하지만 우리의 제안된 방법론은 인간 전문가의 모방을 통해 더 빠르게 수행할 수 있도록 학습되었다.
다양한 주행 정책의 차량 동적 상태를 일부 전형적인 경우에 분석한 결과가 나와 있습니다. Fig. 5(a)~(c)는 우리의 제안된 방법과 SAC의 보호되지 않은 좌회전 시나리오에서 차량의 속도, 가속도 및 곡률을 나타낸다. 따라서 이러한 경우를 잘 설명함을 알 수 있다.
C. Effects of Imitative Expert Policy
1) Uncertainty Estimation: 전문가 정책을 얻을 수 있도록 다양한 불확실성 추정의 효과를 통해 앙상블 모델을 구성한다.
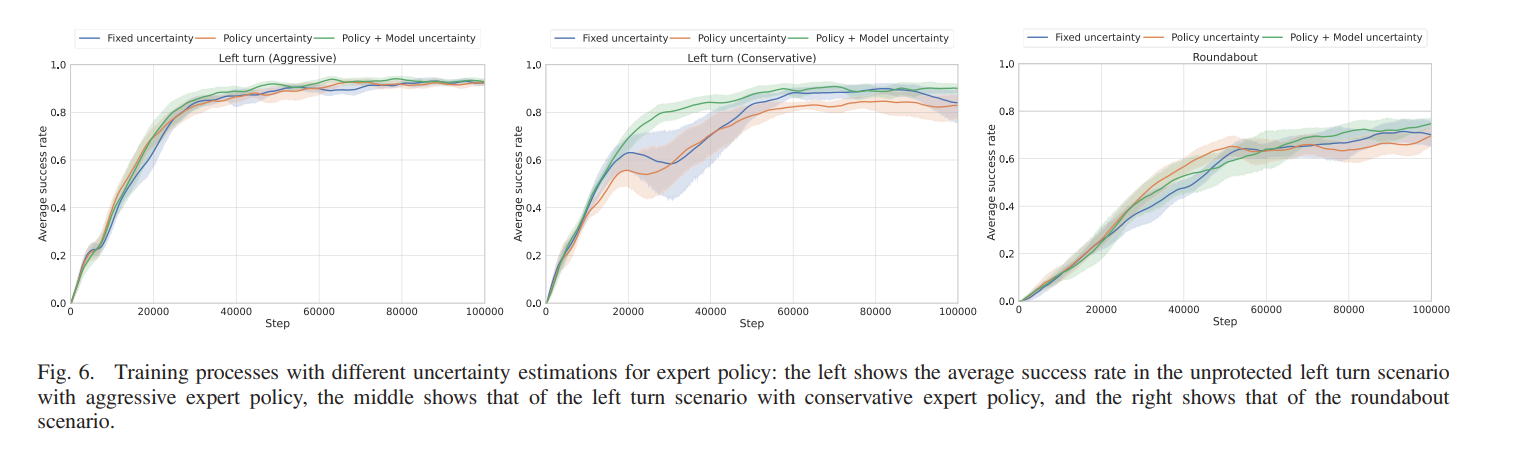
이 결과는 제안 방법이 앙상블을 통해서 정책 및 모델 불확실성을 추정항 수 있는 전문가 정책에서 효과적임을 보인다. 이는 태스크가 복잡해질수록 효과적이다. 비보호 좌회전에서 공격적인 행동에서는 큰 차이가 없다. 이는 단순하고 작업의 해결 공간이 제한되어 있기 때문이다. 하지만 보수적인 행동에서는 이야기가 달라지는 것이 복잡한 태스크에 따라서 불안정한 훈련 과정과 다양한 시도 간의 높은 분산이 필수적이게 된다. 이런 경우에 도메인 지식 imitative 학습 RL agent가 더 효과적으로 퍼포먼스를 보인다.
2) Training Sample Size: 샘플 사이즈가 10개, 20개, 40개일때를 비교한다.
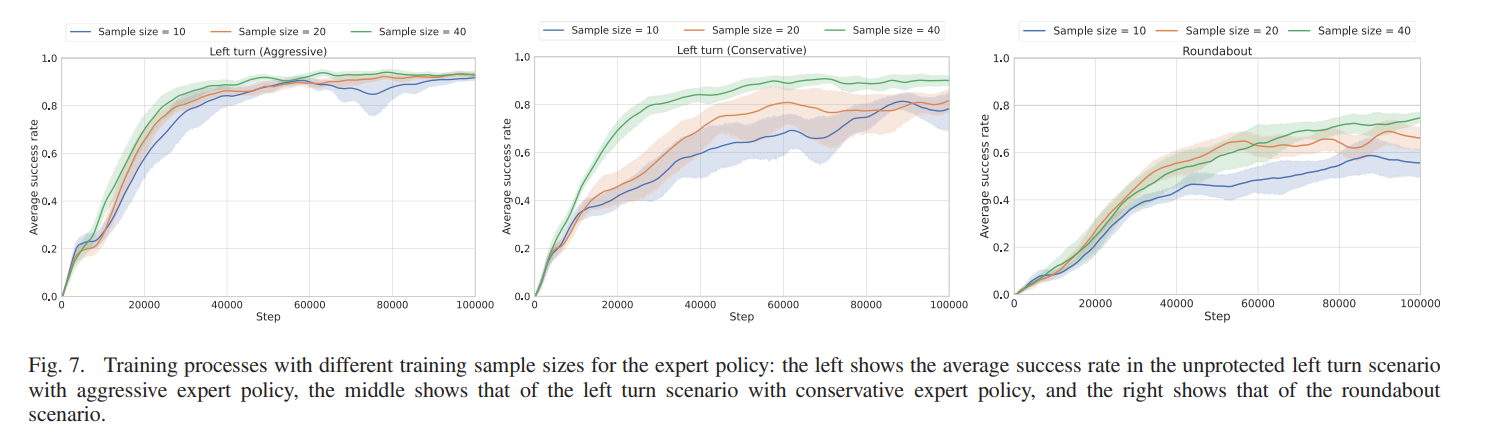
작업 복잡성이 증가함에 따라서 샘플 크기의 차이가 유의미해 진다. 비보호 좌회전 시나리오에서 공격적인 행동을 하는 것이 적은 양의 샘플을 필요로하였다. 그러나 보수적인 행동을 학습하는 경우에는 더 큰 훈련 샘플 크기가 학습 정확도를 높이게 됨을 알 수 있다.
D. Discussions
RL의 두 가지 주요 문제는 낮은 샘플 효율, 보상 함수를 명확히 지정하기 어렵다는 점이었다. 본 연구에서 제안한 방법은 인간의 사전 지식을 도입함으로써 이러한 문제에 대처하였다. 구체적으로, 우리는 주행 작업을 실행하는 인간의 데모를 인간 전문가 정책으로 요약하고, 이를 RL 에이전트의 훈련을 안내하는데 사용한다. 그러나, 제안된 방법의 약점으로는 특정 차선만 사용 가능하기 때문에 실제 시나리오에는 잘 맞지 않는다는 것이다. 또한 많은 하이퍼파라미터가 본 연구에서 제안되었는데 이것들을 실제로 활용하기 위해서 최적화 하기 위해 많은 시간이 필요하다는 점이 있다.
