Remaining useful life prediction of bearings using multi-source adversarial online regression under online unknown conditions
ABSTRACT
대부분의 전이학습 기반의 방법론은 충분한 데이터를 학습에 필요로 하지만, 타겟 데이터가 항상 available 한 것은 아니다. 즉, unknown condition에 대한 target data에 대해서 온라인 few-shot 시나리오가 이슈이지만, 효과적으로 다뤄지지는 않았다. 또한 single source domian의 제한된 지식은 degradation feature를 추출하는데 적합하지 않기도 하다.
따라서, MAOR(multi source adversarial online regression)을 제안하는데, 수도 도메인 확장을 고려하여 unknown condition에 대한 RUL예측을 수행하는 것이다. 이 방법을 통해서 타겟 도메인의 스트림 데이터를 각 라운드에 대해서 획득하고 온라인 학습 task를 수행한다.
수도 도메인을 생성할 때 도메인 레벨의 적응이 수도 도메인간의 이질적인 분포를 고려하며, 또한 수도 도메인과 소스 도메인간의 manifold 유사도를 고려한다. 또한 특질 레벨의 적응또한 임베딩 되어 있어서 멀티 소스의 adversarial 적응 아키텍처가 더 로버스트한 도메인 invariant한 특질을 학습하고 오프라인 모델을 빌드한다. 온라인 모델 예측 프레이뭐크는 온라인 타겟 데이터 streams를 예측하며, 온라인 모델을 adaptive weighting 을 통해 업데이트한다. MAOR은 다른 온라인 태스크들에 비해 좋은 성능을 나타내었다.
1. Introduction
최근 연구에서 DA와 DG방법론이 RUL을 예측하고, unknown condition에서 RUL을 예측하는데 많이 사용되었다(Liao, Huang, Li, Chen, & Li, 2020). 하지만 예측 모델은 작동 예시의 학습 instances가 충분한 상태에서 빌드가 가능하다. Zhuang et al. (2021)은 대조학습 및 MMD를 통해서 cross-dmain RUL 예측을 수행하였다. metric function에 대해서 수동으로 설정하며 타겟 데이터가 충분한 상황에서는 이러한 방법이 유효하다. Zhu et al. (2020) 은 transfer module을 MLP로 임베딩하였고, 전이가능한 RUL 예측을 다른 작동 환경에서 수행하였다. 그러나, 기존의 DA 기반의 RUL 예측 방법론은 fine-grained 정보를 domain을 align하면서 정보를 잃게 된다는 문제점이 있었다(Ding, Jia, & Cao, 2021). Liu et al.(2022) 은 같은 클래스의 서브도메인들의 discrepancies를 줄이는 방향으로 영향을 줄였다. 이 때 타겟 도메인의 모든 학습 instances들은 available 하다는 가정이 들어가게 된다(Han et al., 2022). 따라서 DA는 소스 도메인의 라벨된 지식과 타겟 도메인의 라벨되지 않은 지식을 통해 이루어지게 된다.
만약 타겟 도메인이 unknown 이며 온라인으로 instance by instance로 얻어지게 된다면, 이러한 방법들은 사용이 불가능해진다. 온라인 데이터 시퀀스를 이용해 학습하고 처리하는 방법은 간단하게 배치를 새로운 데이터를 받는 와중에 모델을 업데이트하는것이다. 하지만 이것은 높은 학습 코스트를 요구하며 복잡한 시스템에서는 바로 실시간으로 모델이 학습하기 어렵게 만든다. 따라서 본 연구는 온라인 타겟 데이터에 대해서 RUL 예측을 수행하는 것을 목표로 한다.
현재 온라인 학습은 머신러닝에서 많은 주목을 얻고 있다. (Xu, Liu, Jiang, Shen, & Huang, 2020). Zhou et al. (2022) 는 오프라인으로 모델을 만들고 온라인으로 adpative하게 모델의 파라미터를 업데이트 하는 방식으로 모델을 설계하였다. Wang et al. (2023) 은 베어링 failure 타입에 대해서 시뮬레이션과 머신러닝 모델을 혼합하여 효과적으로 RUL을 온라인 시나리오에서 예측하였다. 또한, 온라인 조기 이상 탐지를 위한 논문도 존재하였다. (Mao, Chen, Zhang, & Liang, 2023). 대부분의 온라인 전이학습은 결합 진단에 초점이 맞춰져 있으며, 몇몇의 연구들이 RUL 예측을 하고 있다. 따라서 본 연구는 온라인 전이 학습 기반의 RUL 예측 프레임워크를 통해 실시간으로 RUL을 예측한다.
대부분의 RUL 예측 방법론은 많은 run-to-fail 데이터셋을 요구한다(Kong & Li, 2022). 학습을 위한 라벨된 데이터의 학습은 시간을 많이 필요로 한다. 느린 degradation 프로세스 때문에, 각 작동 환경에서 전체 cycle 데이터를 활용하는것도 적절치 않다(Yang, Mei, Jiang, Tao, Sun, & Zhao, 2022). 적은 데이터는 data-driven method의 진단 정확도를 줄인다(Li, Xu, & Lee, 2023). 따라서, 많은 연구들이 few-shot 상황을 고려하여 수행되었다. Ding and Jia (2022) 는 meta-learning 프레임워크를 통해서 few-shot 샘플 예측을 라벨되지 않은 데이터를 통해서 구축하였다. Pan et al. (2022)은 적은 타겟 데이터를 파인튜닝하여서 타겟 도메인의 베스트 모델을 획득하였다.
그러나, 적은 타겟 데이터는 문제가 되므로, 적대 학습기반의 생성 프레임워크를 통해서 latnet domian을 만들고, unseen target domain으로 확장할 수 있다. (Zhuang, Jia, & Zhao, 2022). 이렇게 구축된 모델은 너무 복잡하다는 단점이 있다. 또한 이러한 방식은 샘플 수를 확장한다는 장점은 있지만, 이러한 방법론이 샘플의 이질적인 분포를 고려하여 만들지 않기 때문에 새로운 샘플의 다양성을 고려하지 못한다. 이러한 도메인들을 하나의 소스 도메ㅐ인으로부터 어떻게 확장하는지가 문제이다. 따라서 본 연구에서는 adaptive하게 data augmentation을 수행하면서 충분한 수도 도메인 데이터를 생성하는 시도를 한다.
위의 문제점들을 극복하기 위해서 멀티 소스 적대 온라인 리그레션 (MAOR) 방법론을 통해서 수도 도메인 확장을 고려하며 unknown 컨디션의 베어링 RUL 예측을 수행하는 모델을 제안한다. 구체적으로, 독창적인 수도 레이블 정보로 유도된 수도 도메인 확장을 인코더-디코더 방식을 통해 수행한다. 수도 레이블은 적응적인 웨이트를 통해서 다른 수도 도멩네서 생성을 한다. 도메인 레벨의 적응은 수도 도메인들 간의 이질적인 분포를 정렬하고, 수도 도메인과 타겟 도메인간의 maifold 유사도를 제한한다. 또한 소스와 수도 도메인의 퇴화 특질의 마지널 발산을 막기 위해 특질 metric이 특질 레벨의 적응을 통해 가까워진다. 그리고, 도메인에 invatiant한 멀티 소스 적대 로스를 통한 특질 추출이 사용되어서 학습된 오프라인 모델이 온라인 RUL을 예측할 수 있도록 한다. 반면에 온라인 전이 학습이 dynamic adaptive weighting을 통해 온라인 모델을 업데이트한다. 따라서 메인 컨트리뷰션은 다음과 같다.
1. 멀티 소스 적대 온라인 회귀 방법론을 통해서 베어링 RUL을 online unknown conditions에 대해서 수행한다. prediction scheme은 오프라인과 온라인 모델을 혼합하고, 효과적으로 온라인 태스크를 수행하여 adaptive weighting 과 온라인 updating을 한다.
2. 독창적인 수도 레이블 정보로 유도된 수도 도메인 확장 scheme이 제안된다. 도메인 레벨의 adaptation이 제안되어서 수도 도메인들간의 이질적인 분포를 학습하고, 소스와 수도 도메인들간의 manifold 유사도를 제한한다. 따라서 새로운 샘플의 다양성을 증대시킨다.
3. 멀티 소스 적대 적응 프레임워크를 통해서 보통의 특질 추출기를 도메인 특질 추출기와 혼합하여 파라미터를 줄인다. 또한 도메인 invariant 특질을 추출할 때 degradation 특질들간의 발산을 특질 레벨의 적응을 통해 제한한다.
2. Preliminaries
2.1. Adversarial domain adaptation for RUL
Adversarial domain adaptation (ADA) 는 GAN을 활용하여 소스와 타겟의 implicit한 정보를 학습하는 고ㅓㅏ정이다. 이를 통해 도메인들간의 discrepancy를 줄일 수 있다.
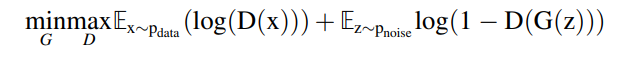
최근에 ADA 기반의 RUL 예측 방법론들이 많이 연구되었다. Ye and Yu (2022) 는 adversarial adaptation network를 통해서 데이터의 분포를 정렬하고, selective weight을 업데이트했다. 또한 간단히 타겟 특질을 소스와 비슷하게 추출되도록 강제하는것은 mutual information을 제거하는 효과가 있기 때문에 generalization을 방해한다는 논문또한 있었다. (Ragab, Chen, Wu, Foo, Kwoh, Yan, & Li, 2021). 따라서 Zhuang, Jia, and Zhao (2022)은 mutual 정보를 위한 지도 positive 대조 모듈을 통해서 domain invariant feature를 추출하였다. 그러나 RUL의 온라인 예측을 수행하기 위해서는 기존의 방법론은 적용이 불가하였다. 따라서 Mao et al. (2022)은 multilevel adaptation을 온라인 데이터 배치에 적용하여서 RUL을 예측하였다. Jiang et al. (2022) 은 cross-domain RUL 예측 과정에서 marginal과 conditional 분포를 ADA를 통해서 generalization error를 줄였다. Li et al. (2020)은 ADA를 제안하여서 데이터 alignment를 수행하였다. 이러한 방법론들은 글로벌하게 강건한 도메인 invarinat 특질을 ADA를 통해 획득할 수 있지만, marginal 특질의 분산은 잘 다뤄지지 않았다. degradation feature의 글로벌 extraction은 local fine-grained 정보를 잃게 되며 모델이 local한 a어노말리의 분포에 대해서 더 집중하는 결과를 보인다 (Ding & Jia, 2022).
따라서 본 연구에서는, 멀티 도메인 적대 도메인 적응 프레임워크를 통해서 오프라인 모델을 target 데이터 없이 수행한다. 반면에 소스와 수도 특질들이 특질 레벨의 적응에서 제한되어 특질 발산을 막고, 수도 레이블의 예측 에러를 막는다.
source feature 소스 도메인의 원래 데이터에서 추출된 특질이고,
pseudo feature 타겟 도메인의 데이터에서 추출된 수도 레이블을 기반으로 한 특질
이 두 특질 간의 차이가 feature divergence 임. 이 차이를 줄이는 것이 도메인 적응의 주요 목표
2.2. Multi-source domain adaptation for RUL
MDA라고 하는 이 분야는 개의 도메인으로 이루어져 있을 때, , ..... 개가 있다. multi-source transfer task는 mapping을 학습하는 것인데, = {,...........,} => f(x) 로 맵핑하는 것이다. 소스와 타겟의 개의 pair에 대해서 이 조합이 가능하다. MDA에서는 로스가 각 소스와 타겟 도메인 페어에 대해서 {,} common domain invariant representation을 학습하기 위해서 loss를 줄인다.
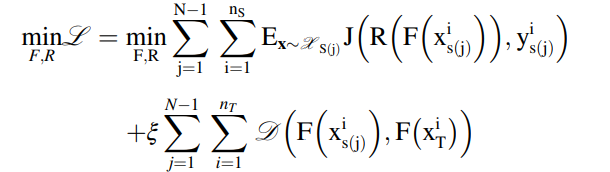
: 예측 loss
: distance loss
: feature extractor
: regressor
MDA 기반의 방법론은 결함 진단에 널리 사용되었다(Yang, Xu, Lei, Lee, Stewart, & Roberts, 2022). 그러나, RUL 예측 태스크에는 많이 사용되지 않았다. 싱글 소스 도메인 적응은 소스 도메인내에서의 domian shift를 고려하지 않았고, 멀티 소스 지식을 활용하지 못한다. (Ding, Ding, Zhao, Cao, & Jia, 2022). 따라서, . Zou et al. (2022) 은 추출된 degradation 특질의 discrepancies를 줄였다. MDA에서는 충분한 데이터가 각 소스와 타겟 도메인 사이에서 discrepancies를 줄이는데, 적절한 소스 데이터가 실제 industry에서는 이용불가능하다.
MDA는 는 멀티플 도메인들에 대해서 전이 학습을 수행할 수 있지만, implicit metric function이 미리 세팅 되어있어야 한다. 대조적으로 DA는 metric function에 대한 문제를 개선할 수 있다.
따라서 본 연구에서는 MDA와 ADA에 영감을 얻어 multi-source adversarial adaptation 프레임워크를 데이터 증강을 통해서 구축하고, multiple independent 및 related 도메인을 만들고 이를 통해 domain invariant feature를 얻게 된다.
2.3. Online transfer learning
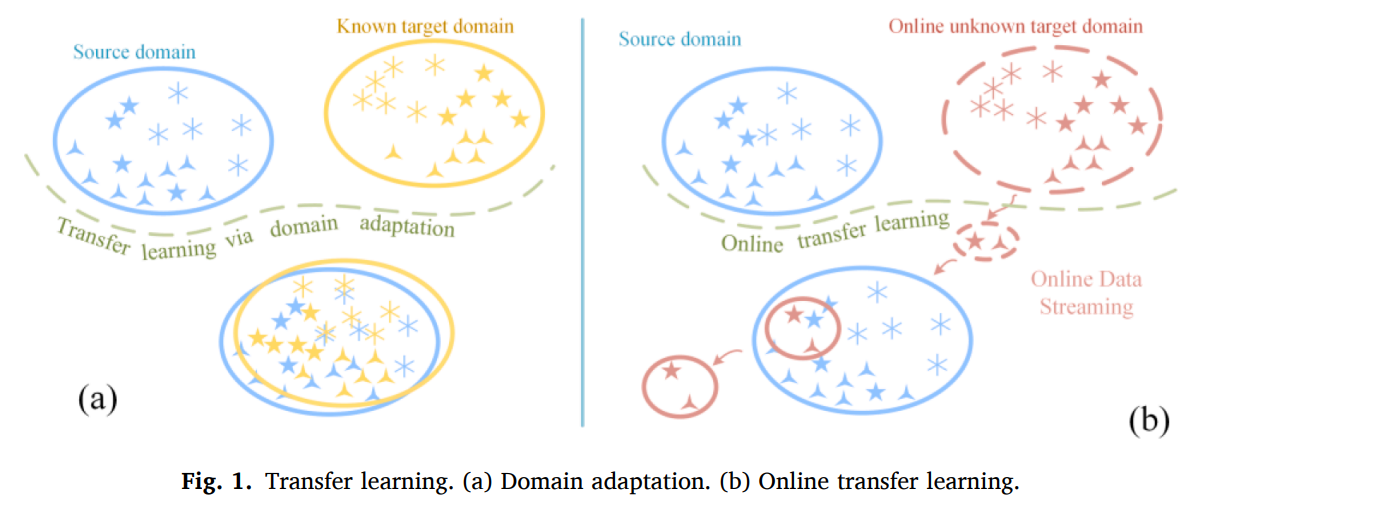
실제 시나리오에서는 타겟 데이터는 online processing에서 도착하기 시작하기 때문에 unknown 이라고 할 수 있다. 타겟 데이터가 미리 획득되기 때문에 모델이 target data stream에 대해서 적응이 되어야 한다(Zhao, Hoi, Wang, & Li, 2014). 온라인 전이 학습 기반의 모델은 준지도학습을 통해 오프라인으로 모델을 구축하고, 라벨되지 않은 타겟 데이터를 통해서 파라미터를 파인튜닝해서 온라인 모델을 업데이트한다. Maoet al. (2022)은 조기 failure 데이터를 활용하여 온라인 RUL 수도 값을 오프라인 데이터의 degradation 정보를 가지고 만들었다. 현재 존재하는 batch learning 기반의 RUL 예측 연구들은 타겟 데이터가 available 하다는 가정을 하는데, RUL 예측은 unknown target data를 통한 online RUL 예측이 필요하다. 따라서 MAOR을 통해서 오프라인 모델을 학습하고, 예측단계에서 온라인 모델이 동적으로 weighting update strategy와 타겟 데이터 스트림을 통해 업데이트된다. 오프라인 전이학습과는 다르게 온라인 전이학습에 대한 연구는 많이 존재하지 않는다.
3. Methodology
3.1. Overview
MAOR 프레임워크는 다음과 같다.
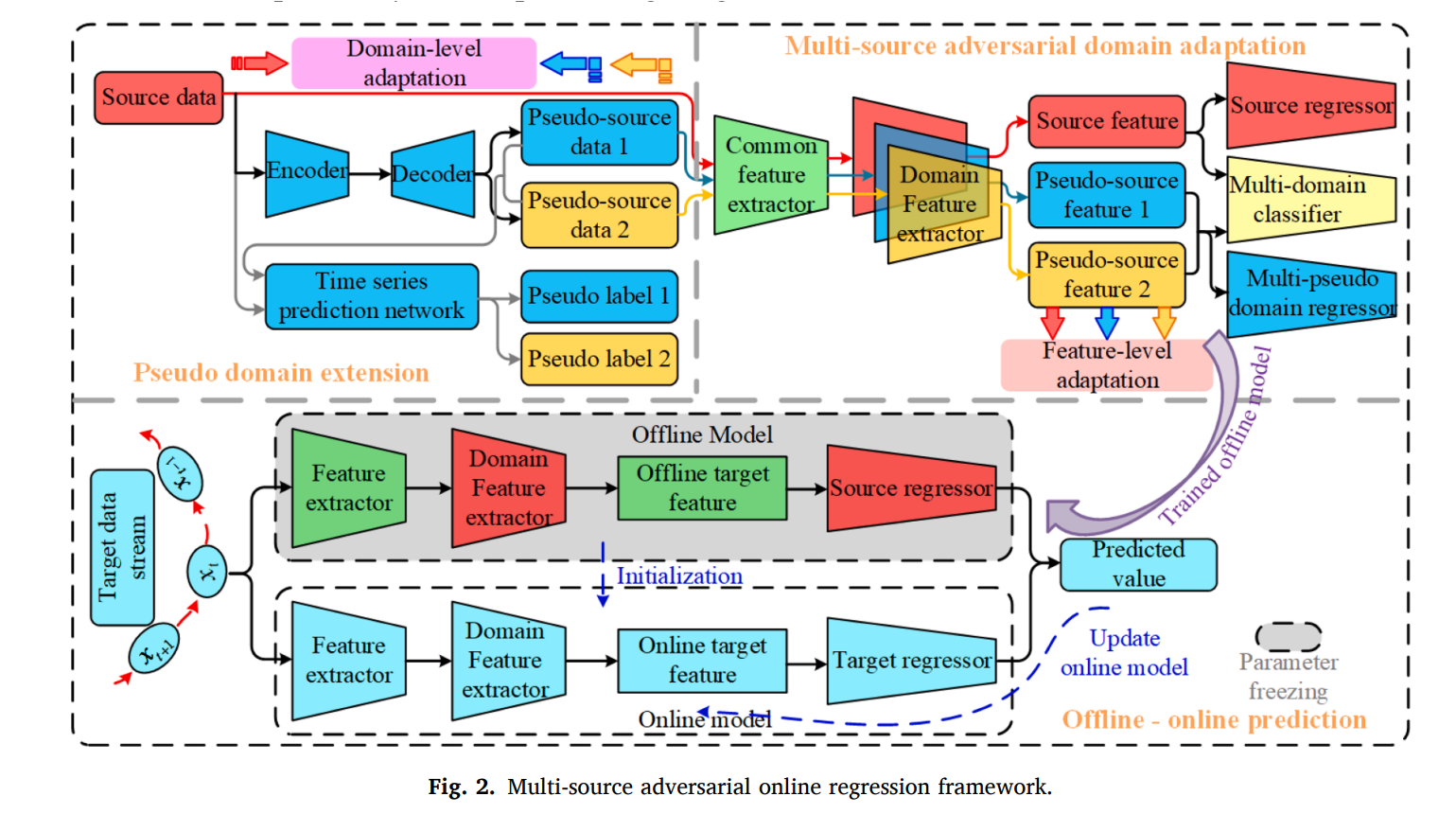
메인 스텝은 다음과 같다.
1. 수도 도메인 확장, 2. 멀티 소스 적대 도메인 적응 (MADA), 3. 오프라인-온라인 예측
- 수도 레이블 정보로 유도된 인코더 디코더가 다른 수도 도메인들을 만들기 위해 구축된다. 도메인 레벨의 적응이 수행되어서 수도 도메인 생성단계에서의 제한으로 작용된다.
- 2단계의 MADA를 통해 공통 특질 추출기와 도메인 추출기를 통해서 공통 특질과 퇴화 특질을 추출한다.
- 오프라인-온라인 예측 프레임워크는 학습된 오프라인 모델을 RUL값의 adaptive weighting 업데이트를 통해 온라인 모델을 구축한다.
3.2. Pseudo domain extension
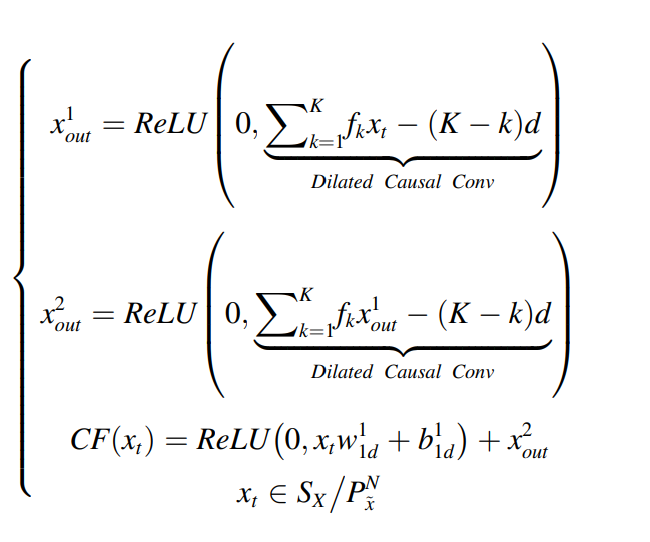
소스 도메인과 비슷한 분포로 생성된 수도 도메인은 더 많은 지식을 얻을 수 있다. 인코더-디코더가 N개의 수도 도메인을 만들 수 있게 하며, 이는 다음과 같다.
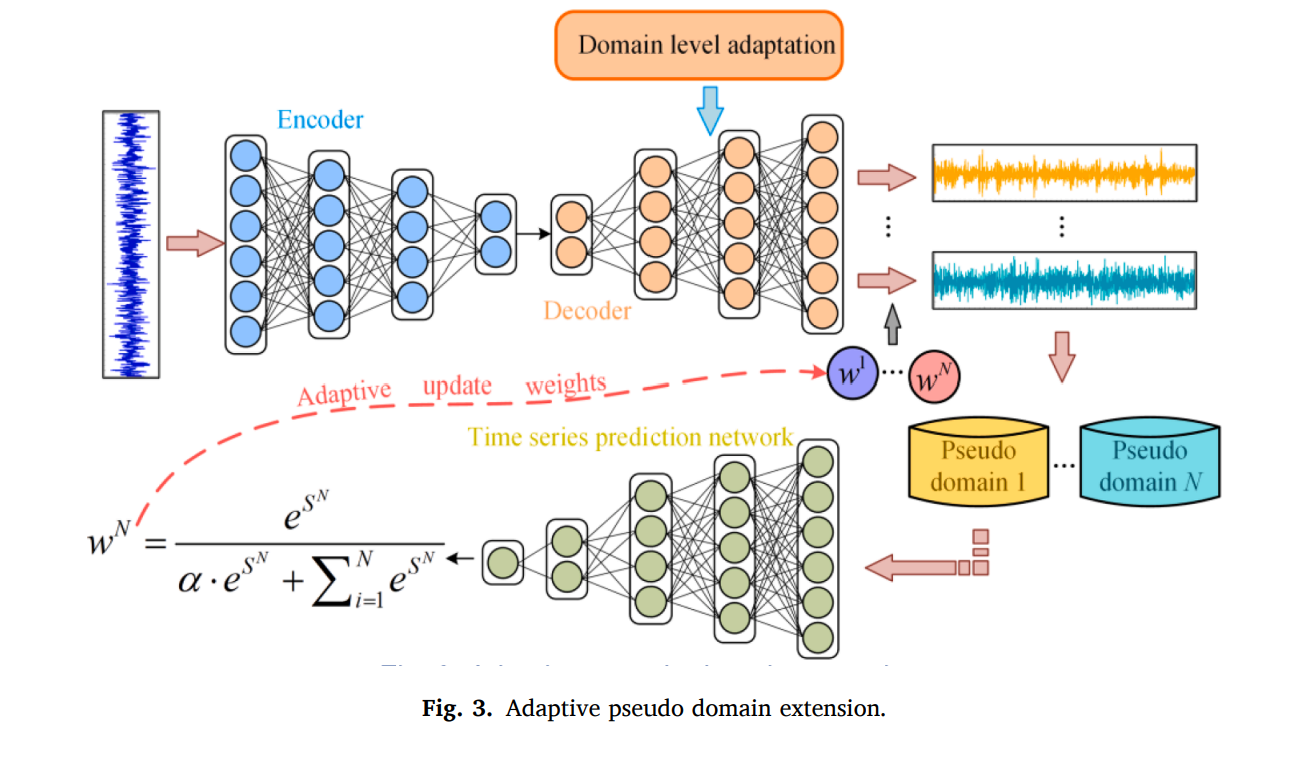
소스 샘플들
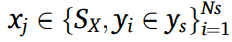
은 인코더에서 특질 인코딩을 거쳐서 다운 샘플링되고, 백그라운드 백터 로 변환된다. 이는 다시 수도 샘플들 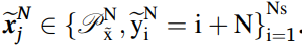
을 생성하게 된다. 수도 도메인을 다르게 만들기 위해서 adaptive weight w 가 업샘플링 과정에서 더해지게 된다. 이에 대한 수식은 다음과 같다.
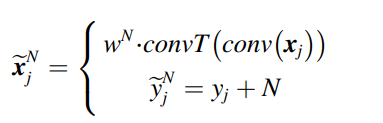
또한 소스 도메인으로부터 학습된 예측 네트워크를 통해서 수도 데이터의 수도 레이블을 만들게 된다. 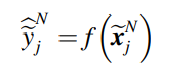
수도 도메인의 SCORE metric은 다음과 같다. 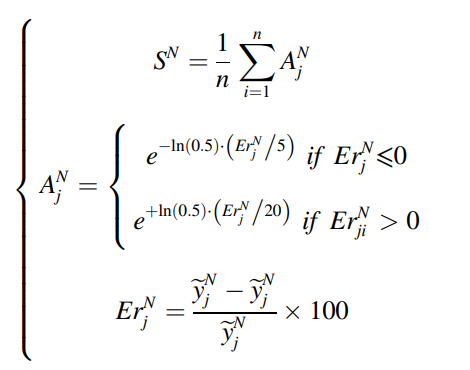
여기서 주의해야 할 점은, w가 초기의 다른 수도 도메인들을 만들 때 직접적으로 영향을 미친다는 점이다. 그러므로, adaptive weight updating scheme을 제안하며 수도 레이블의 S 값을 기반으로 하는 상대적인 weightdmf 다음과 같이 할당한다.
여기서 주의해야 할 점은, w가 초기의 다른 수도 도메인들을 만들 때 직접적으로 영향을 미친다는 점이다. 그러므로, adaptive weight updating scheme을 제안하며 수도 레이블의 S 값을 기반으로 하는 상대적인 weightdmf 다음과 같이 할당한다.
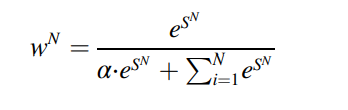
여기서 알파는 weighting factor로써, 수도 도메인이 S값이 크게 된다면 더 큰 weight 을 주게 되고, 수도 도메인을 기존보다 더 다르게 만들게 된다.
j : 소스 도메인 index
T : Target 도메인
N : 소스 + 타겟 도메인 수
N-1 : 소스 도메인 수
: 시계열 총 길이
i : 시계열 index
몰라 일단은
2) Domain-level adaptation.
많은 도메인들이 만들어지지만, 의미없는 샘플들일 가능성이 높다. 죽, 수도 도메인은 semantically consistent 해야 하고, 소스와 연관되어있어야 한다. 하지만 수도 도메인은 다른 분포를 가져야 도메인의 다양성이 증가하게 된다. 도메인 레벨의 adatptation scheme은 이러한 특성을 제한하기 위해서 제안된다. N개의 수도 도메인이 존재한다면,
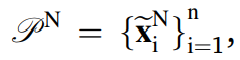
여기서 추정하건데, n은 시계열의 샘플 갯수가 맞고, i는 시계열 인덱스가 맞다. N은 수도 도메인의 총 갯수이며, x틸다는 수도 도메인 데이터를 의미한다.
수도 도메인들간의 distance는 다음과 같이 측정된다.
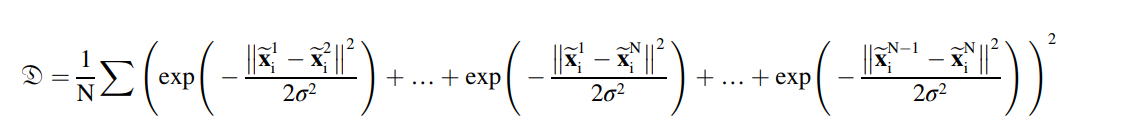
알파는 가우시간 커널의 넓이이다. 도메인 레벨의 적응은 D를 최대화 하는 것인데, 수도 도메인들간의 거리를 넓히는 것이다. 게다가, 수집된 데이터셋의 특정 manifold에서 분포되어 있기 떄문에 수도 도메인에서도 유지가 되어야 한다. 라플라스 norm은 로컬 구조의 invariance를 보장하기 위해서 디코더에 제안된다.
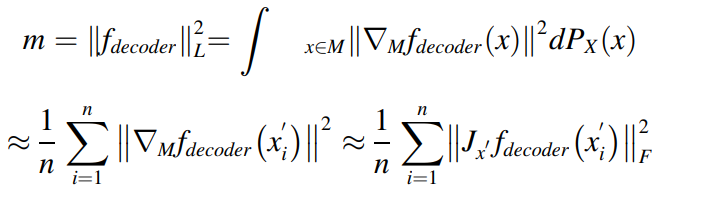
자코비안 matric의 복잡성을 줄이기 위해서 랜던 유한 차이가 이를 근사하기 위해 제안되었다. 따라서 식은 다음과 같이 변형된다.
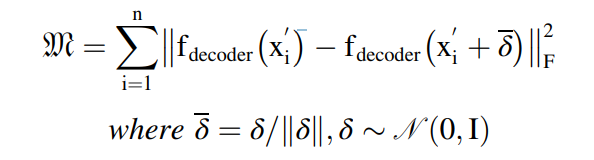
따라서, 도메인 레벨의 adaptation loss는 2개의 아이템으로 이루어져 있고, 수도 도메인과 소스 도메인의 관계가 다음과 같이 정의가 되었기 때문에 토탈 로스식은 다음과 같이 이루어진다.
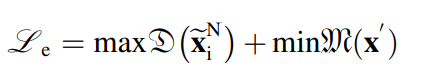
3.3. Multi-source adversarial domain adaptation
1) Two-stage multi-source adversarial regression.
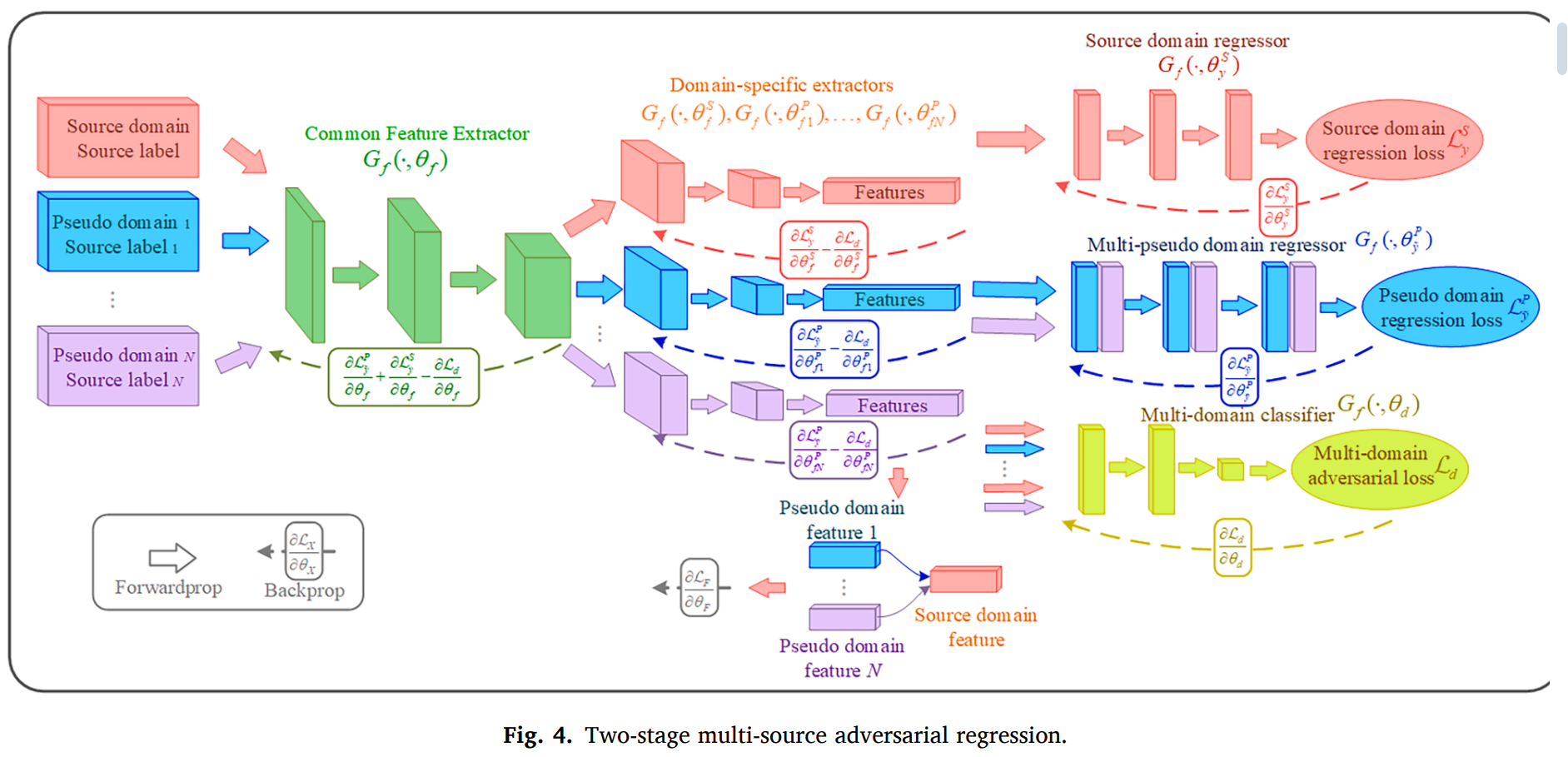
소스 도메인
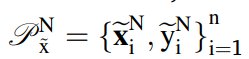
N개의 수도 도메인
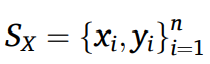
이 포함된다. 또한, 소스 도메인은 다음과 같이 X : 특질 공간, P(x) : 마지널분포 를 포함한다.
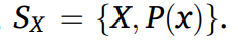
regression task 는 N개의 소스와 수도 도메인 pair에 대해서 더 generaliazable한 커먼 맵핑을 하기 위한 것인데 그 맵핑은 다음과 같다.
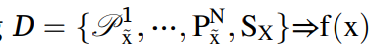
소스와 수도 도메인들간의 적대 로스는 줄어서 common invariant representation이 일어나도록 한다. description은 다음과 같다.
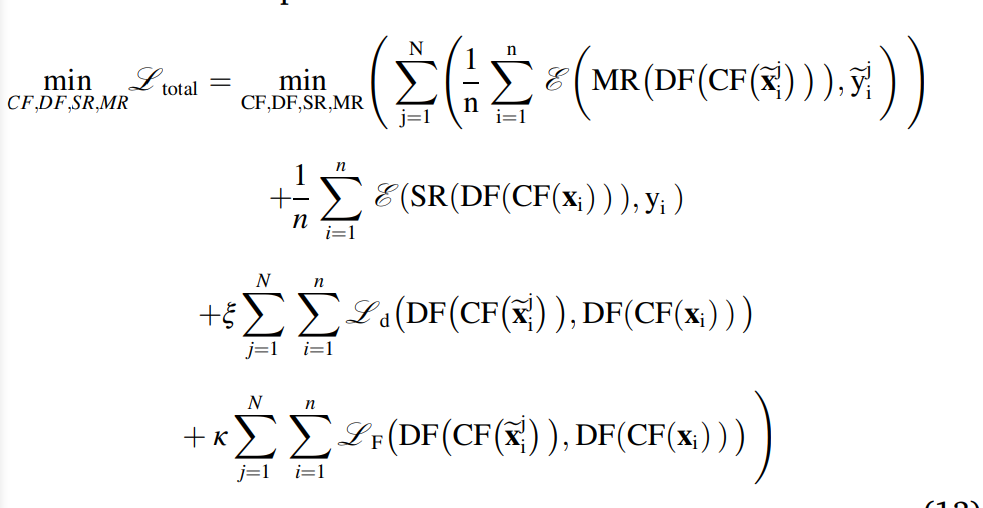
MR : 멀티 소스 리그레서
DF : 도메인 특질 추출기
CF : 공통 특질 추출기
SR : 소스 리그레서
: 멀티 소스 적대 로스
: 특질 레벨의 적응 로스
그리고 트레이드 오프 팩터가 있다.
첫 번째 스테이지에서는 모든 도메인들은 공통 특질 추출기를 거친다.
공통 특질 추출기의 파라미터는 공유된다.
두 번째 스테이지에서는 추출된 특질 pair들
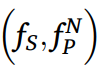
을 가지고, 멀티 소스 classifier에 넣는다. MMD adversarial 학습을 통해서 각 pair의 distribution discrepancies를 줄인다. 학습 프로세스는 다음과 같다. 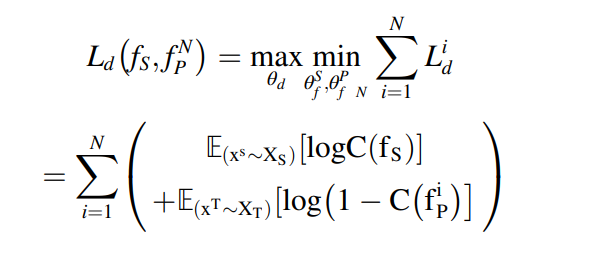
2) Feature-level adaptation.
MADA를 통해서 도메인에 invariant한 표현을 추출할 수 있었다면, 소스와 수도 도메인 특질들 사이에 마지널 분포의 차이가 존재한다면, 아주 discrepancy elimination에 악영향을 미치게 된다. 그러므로, 특질 레벨의 adaptation을 통해서 global adversarial adaptation을 수행하여 MADA에서 마지널 특질 인트로피의 안정성을 유지한다. 소스와 수도 도메인 특질들 간의 metric을 강제하는데, Shannon 엔트로피는 다음과 같이 정의된다.
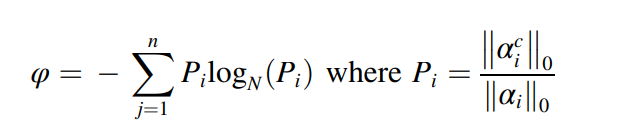
다양한 도메인에 대해서 다음과 같이 엔트로피가 정의된다.
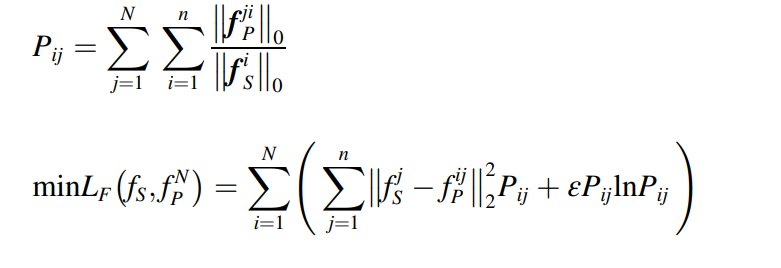
따라서 이 식을 만족하면서 특질 레벨의 적응이 이루어지게 된다.
3.4. Offline-online prediction framework
타겟 데이터의 스트림을 얻었다면, 오프라인-온라인 예측 프레임워크가 디자인되고 이는 다음과 같다.
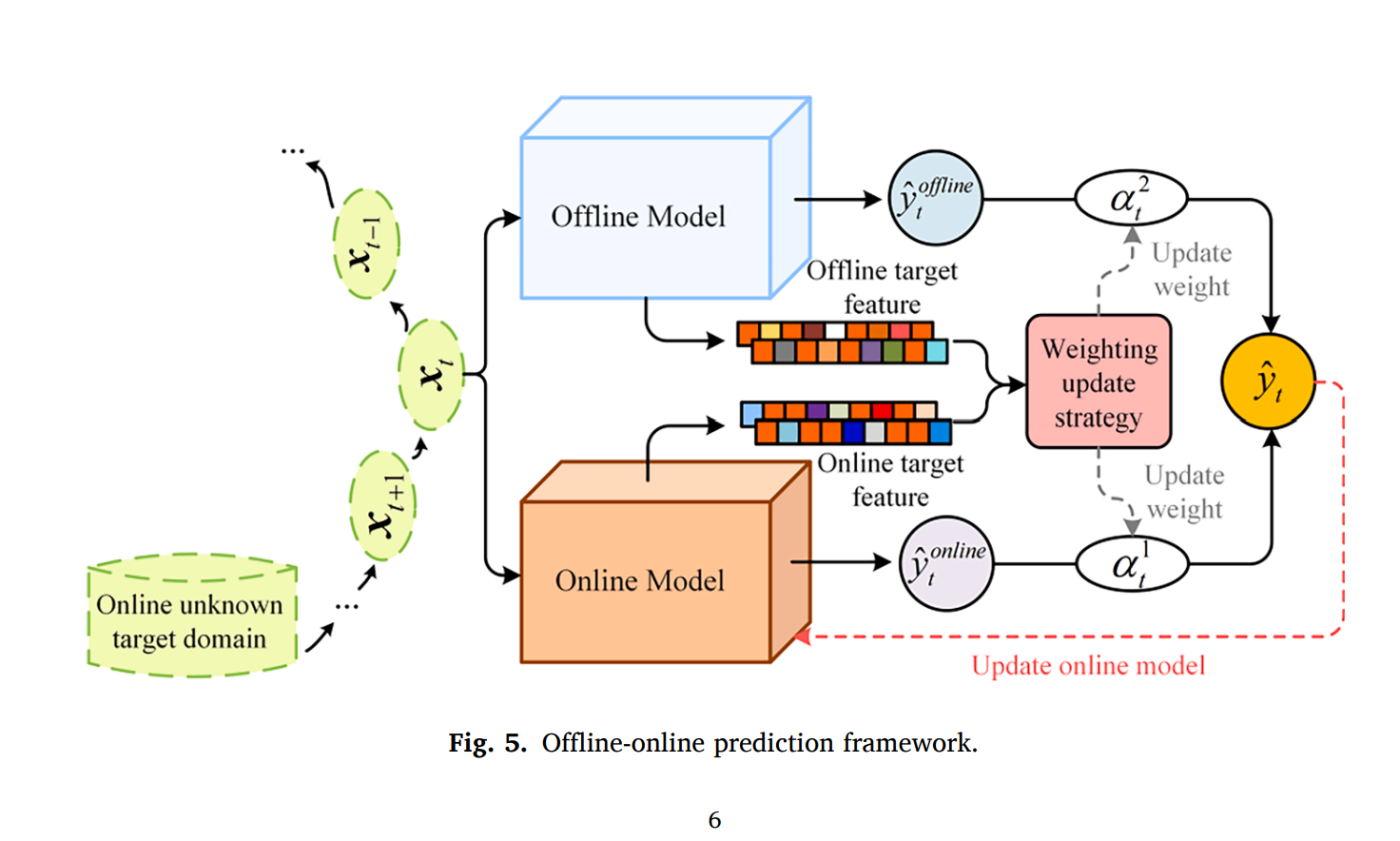
보통 토탈 목적 함수는 2개의 파트로 이루어져있는데, 하나는 수도 도메인 확장의 로스 식이다.
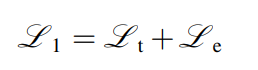
다른 하나는 MADA의 로스식이다.
따라서, 오프라인 모델과 온라인 모델의 예측 결과는 weighted 되어서 마지막 예측 레이블을 만들어내야 하는데, weight들은 adaptively, dynamically리 온라인 모델에 조정된다. T 의 시점이라고 가정해보면, online unknown target data 는 오프라인 및 온라인 모델에 각각 fed된다. 마지막 prediction은 온라인과 오프라인의 weight된 결과이다.
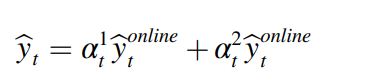
이러한 weight은 초기에는 random하게 초기화되며, 예측이 각 라운드에서 오프라인과 온라인 타겟 특질들을 통해 업데이트 된다. 이 수식은 다음과 같다.
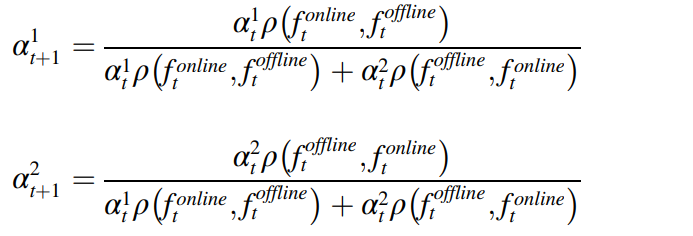
업데이트 인디케이팅 함수는 다음과 같다.
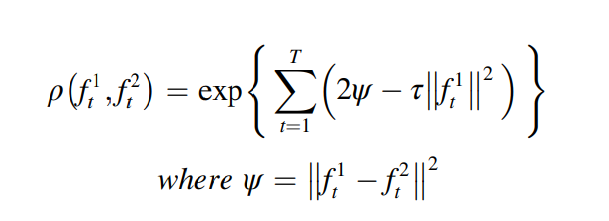
4. Case study
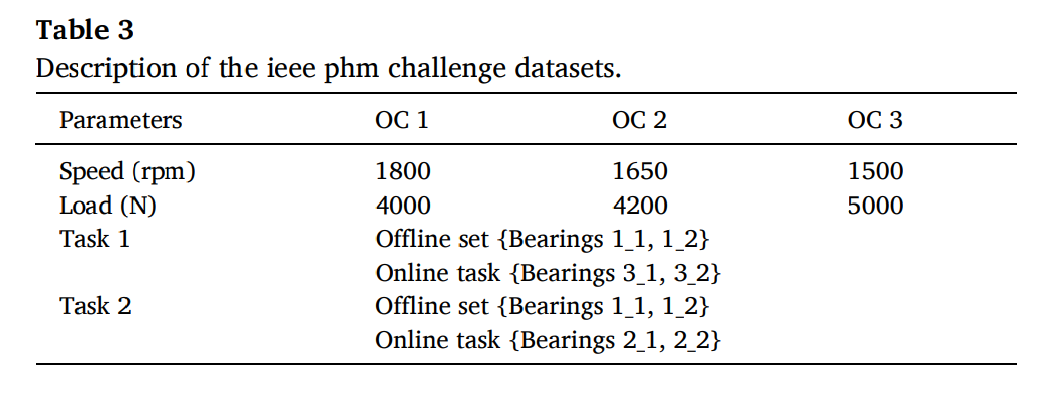
4.1. Dataset description
데이터셋은 IEEE PHM 2012 데이터셋을 활용하였다.
4.2. Ablation test
공통 특질 추출기가 없을때 스코어가 낮아지고, RMSE, MAE가 높아졌다.
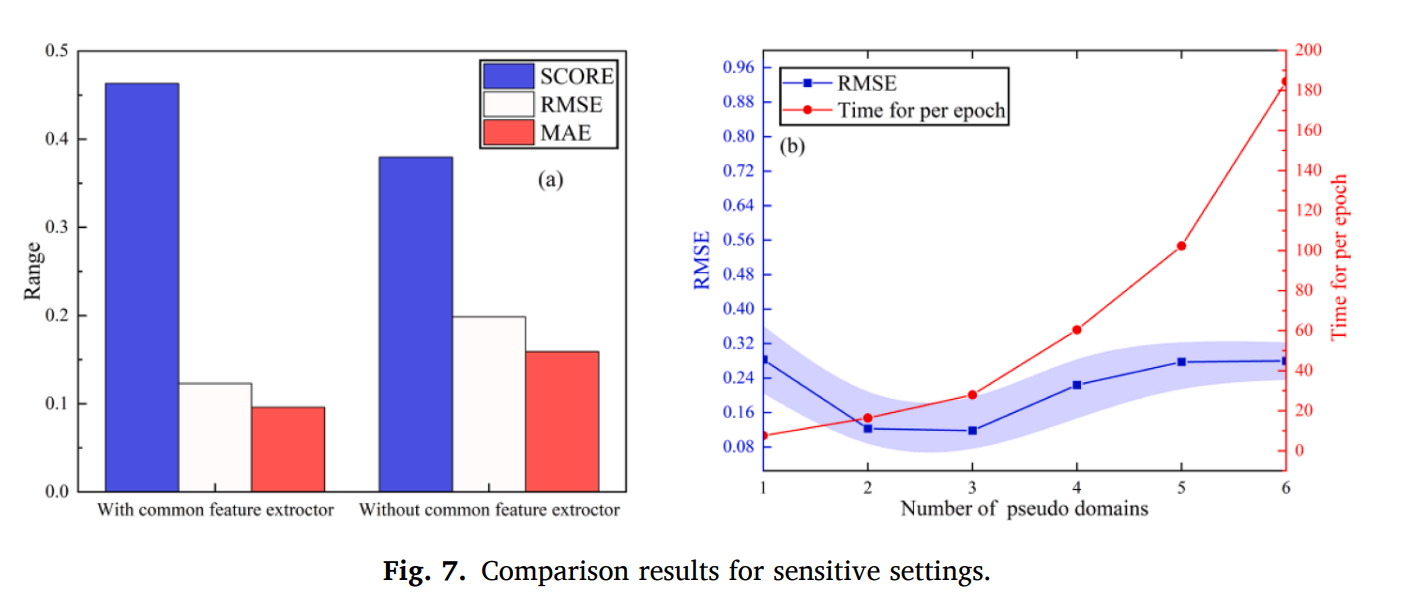
N=3일때 RMSE가 가장 낮다. 하지만 모델의 복잡도는 그만큼 많이 증가함으로, 수도 도메인의 수 N=2로 설정하였다.
4.3. RUL prediction
예측 결과는 다음과 같다.
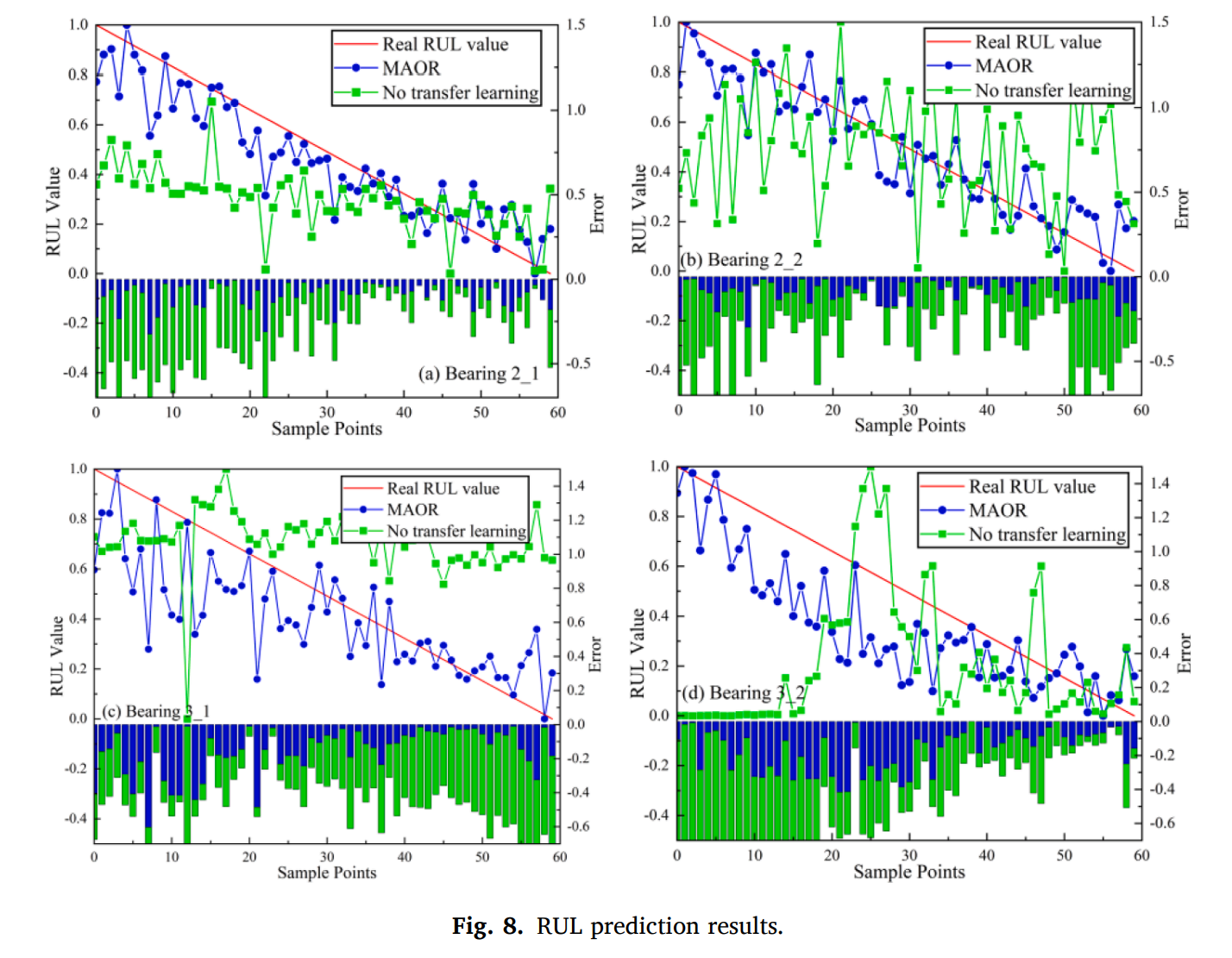
온라인 전이학습이 없는 경우에는 예측 커브가 실제 degradation을 매칭하기 매우 어렵다. 게다가, 예측 값은 모든 태스크 시나리오에서 진동하게 된다. 이는 실제 정확한 예측을 전달하기 어렵다. degradation 지식을 소스 도메인에서만 얻게 된다면 문제가 됨을 보여준다. 또한 파라미터 업데이트를 통한 오프라인 모델은 온라인 모델이 더 정확하게 RUL 을 예측하는것을 유도한다. 전이학습이 없는 모델은 다양한 수도 도메인들이 만들어졌음에도 도메인 invariant feature를 추출하지 못했으며 오프라인 모델의 파라미터 업데이트가 불가능했다. 따라서, MAOR의 온라인 예측은 모든 태스크 시나리오에서 적합함을 보였다. 3_1과 3_2 시나리오에서 early predictions에서는 어느정도 불안정하였지만, later prediction에 대해서는 degradation trend에 적합하였다. 다른 태스크에 대해서, MAOR의 예측 커브는 stable 하였다.
4.4. Comparison and analysis
1) Comparison with different architectures
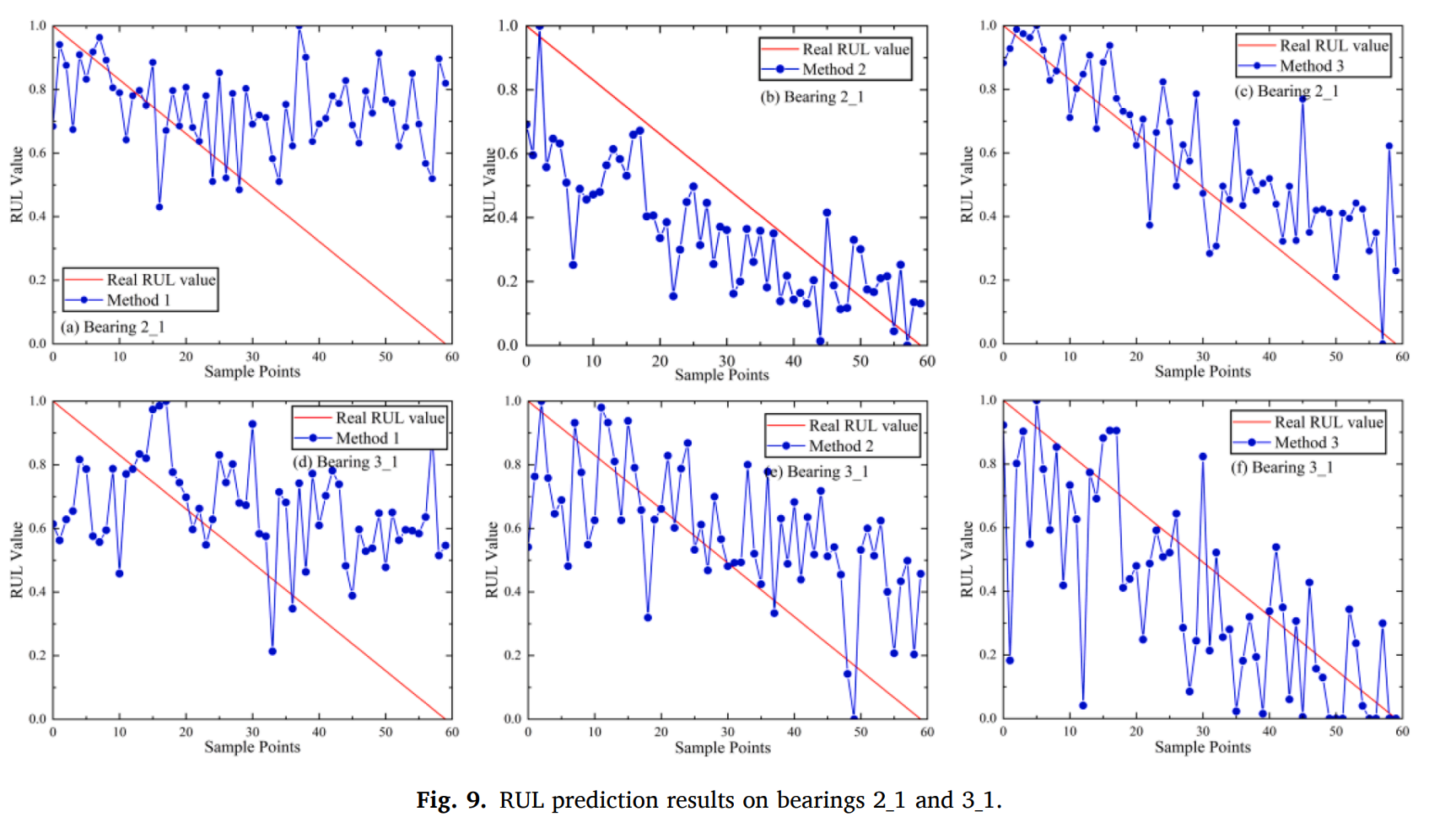
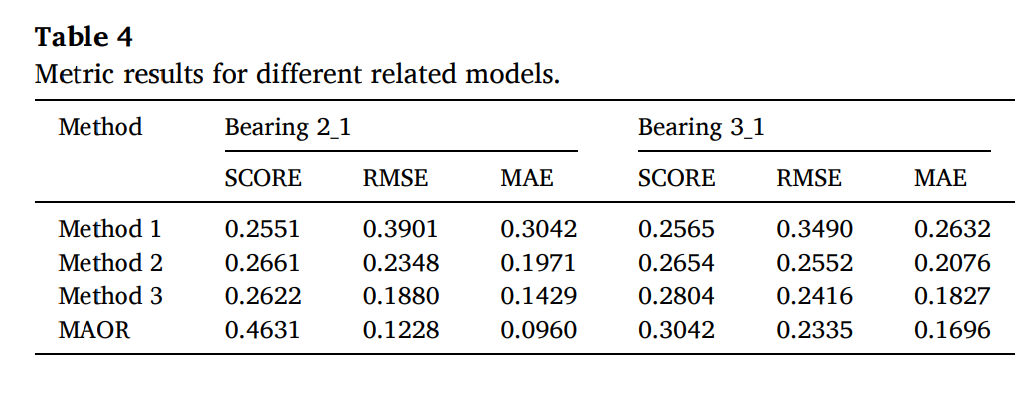
Method 1: without the domain-level adaptation.
Method 2: without the feature-level adaptation.
Method 3: without the online model.
먼저 도메인 레벨의 적응이 없다면 수도 도메인들은 소스 돔메인과 비슷하게 생성되기 때문에 diversity가 부족하게 되고 method1의 결과가 나오게 된다.
하지만, 다양한 수도 도메인들이 다양하다고 해도 domain invariant feature를 추출한다는것은 어렵다. 따라서 특질 레벨의 적응 없이 MADA를 통해 method2의 결과가 나오게 된다.
offline 모델은 online 모델의 fine-tuning 없이 수행된다.
2) Comparison with state-of-the-art methods.
제안된 MAOR의 성능을 평가하기 위해 Method 34,5,와 비교하였다.
Method 4 (Zhuang, Jia, Ding, & Zhao, 2022): A domain
generalization-based model.
Method 5 (Zeng, Li, Jiang, & Song, 2021): A finetuning offline model
with online target data.
Method 6 (Han et al., 2022): An improved regression model of the
homogeneous online transfer learning.
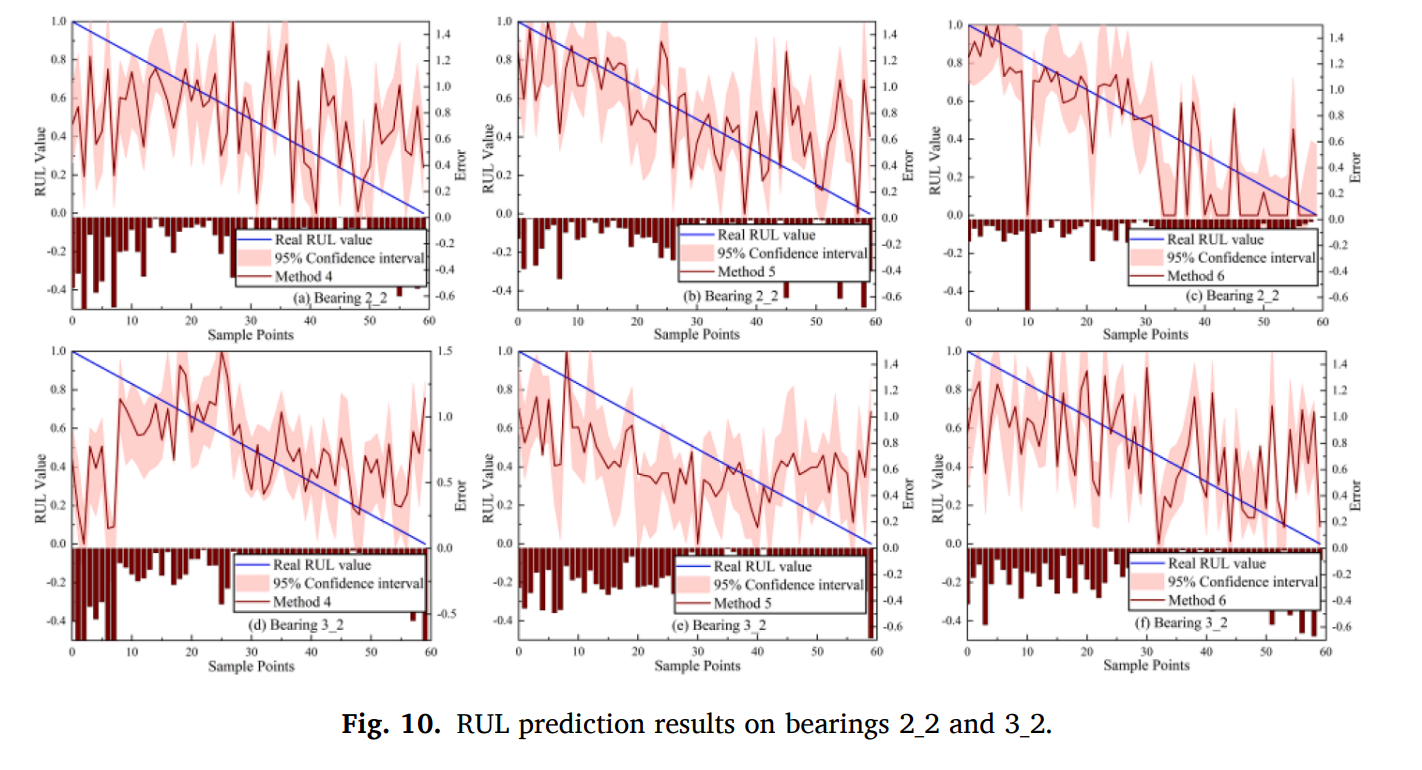
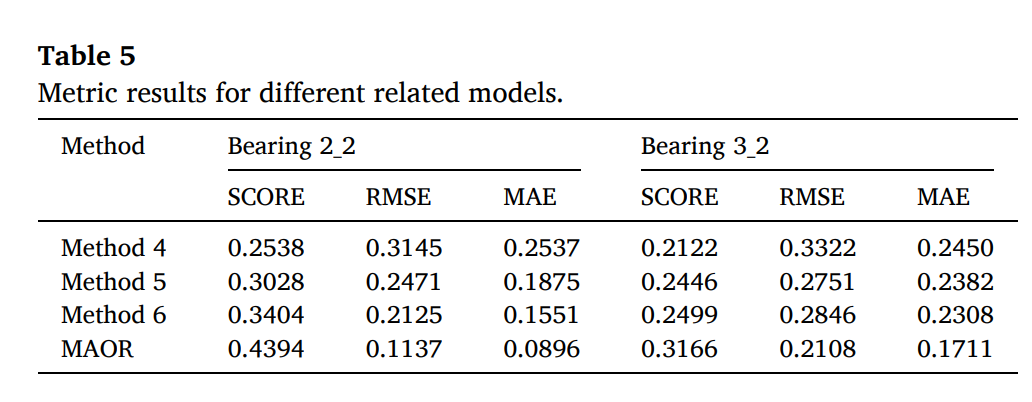
먼저 method 4는 unkown 데이터에 대해서는 호환이 안됨을 보였다. 즉, 도메인 generalization 방법론은 online task에서는 활용성이 없다. 즉, 실제 serial 하게 들어오는 데이터에 대해서 adaptive update를 하는 것이 더 효과적이다.
method 5는 오프라인 모델을 fine-tuned 하는 방식이 포함되어 있지만, 예측이 unstable하다.
소스데이터와 타겟 도메인의 심한 domain shift에 대해서는 오프라인 모델의 파라미터 초기화가 중요하다. 즉, 학습된 오프라인 모델의 파라미터가 파인튜닝 효과에 영향을 크게 미친다는 의미이다. Method 6은 early stage에서는 예측 성능이 좋았으나, late stage의 예측 에러가 제거하기 어려웠다. 전체적으로 MOAR가 RUL 예측을 online unkown target data streams 에 대해서 효과적으로 예측하였다.
4.5. Visualization
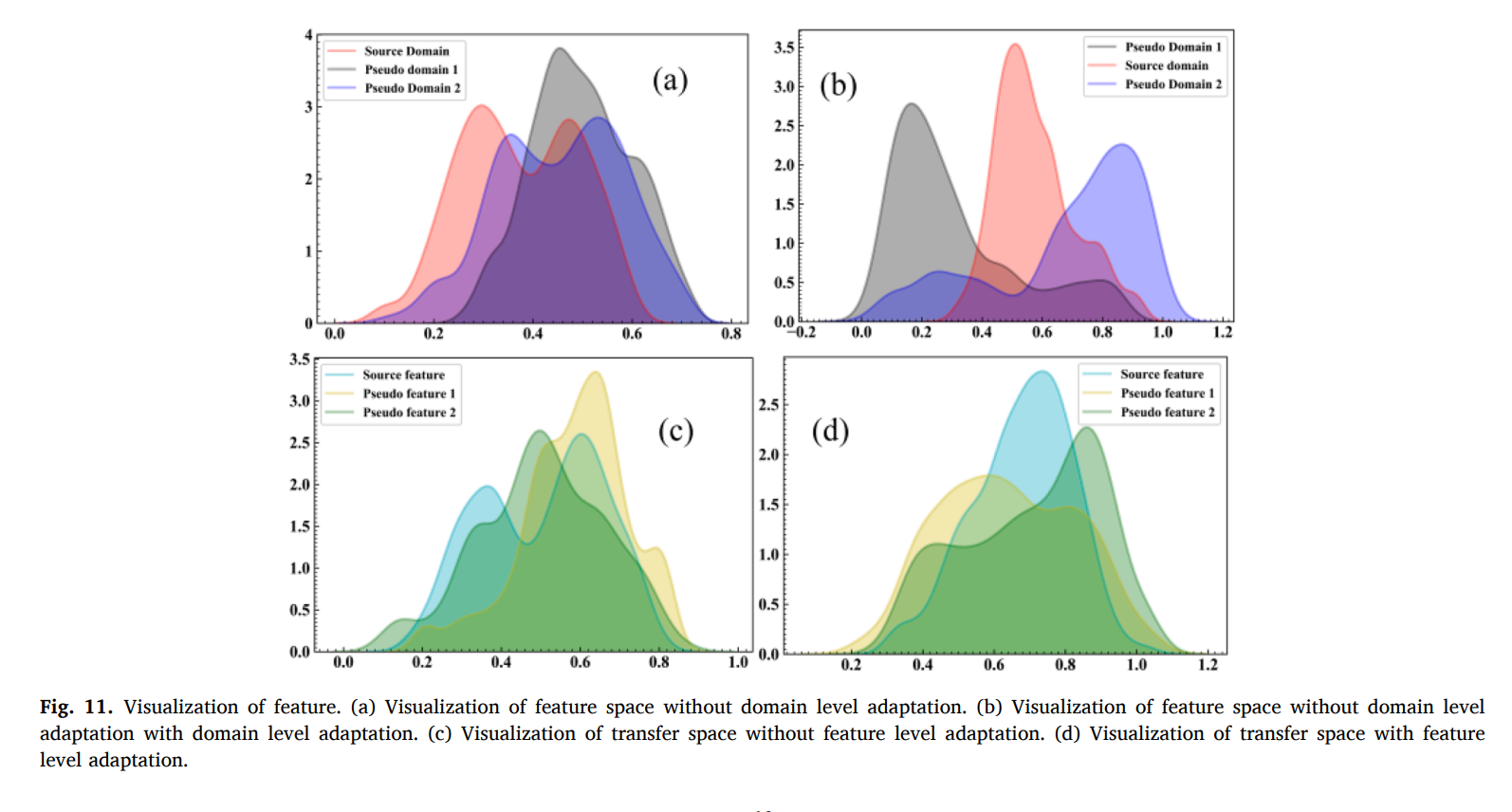
t-SNE를 통해서 feature의 분포를 나타내었다. bearing 2_1을 예시로, 소스도메인과 수도 도메인들간의 특질 분포가 (a)에서 도메인 레벨의 적응이 없을 때 비슷함을 보였다. data augmentation 과정에서 diversirty가 부족함을 나타낸다. (b) 에서는 다양성이 존재함을 보인다.
또한 domain invarinat feature를 추출하는 과정에서, 소스와 수도 도메인의 main peak의 불일치가 나타난다. global adversarial domain adaptation 이 global domain invariant feature를 추출하는데 사용되었으며, anomalous 의 degradation feature의 영향을 주였다. 즉, (d)를 통해서 분포 불일치가 줄어듦을 확인할 수 있다.
5. Conclusion
본 연구에서는 MAOR을 제안하여서 온라인 unknown 타겟 데이터에 대해서 RUL 예측을 수행하기 위해서 수도 도메인 확장을 수행하였다. 타겟 데이터 stream에서 각 라운드마다 오프라인-온라인 예측 프레임워크를 통해 온라인 전이 예측을 수행하였다. 새로운 수도 도메인들의 다양한 샘플들은 적응적으로 수도 도메인 확장을 통해 생성되었고, 도메인 레벨의 adaptation이 다양한 분포를 갖도록 하였다. 추가적으로, 2스테이지의 멀티소스 적대 회귀 아키텍처를 제안하였고, 특질 레벨의 적응을 통해 degradation features 추출 과정에서 constraint로 적용하여 더 generalized 도메인 invariant 특질을 추출하도록 유도하였다. 온라인 예측 과정에서는 오프라인-온라인 프레임워크를 통해서 온라인 타겟 데이터 streams가 제안되었으며, 온라인 모델이 adaptive weighting 을 통해 업데이트되었다. 2개의 베어링 케이스들은 MAOR에 대해서 효과적임을 보였고, MAOR의 RUL 예측퍼포먼스가 효과적임을 보였다. 수도 도메인들의 확장에 따른 계산량의 기하급수적인 증가를 고려하여, 추후 연구에서는 서브도메인 정보를 포함한 RUL 예측을 수행하고, 메타 러닝 프레임워크를 통해 적은 smaples에서도 효과적으로 RUL 예측을 수행하고자 한다.
