Fully connected VAE
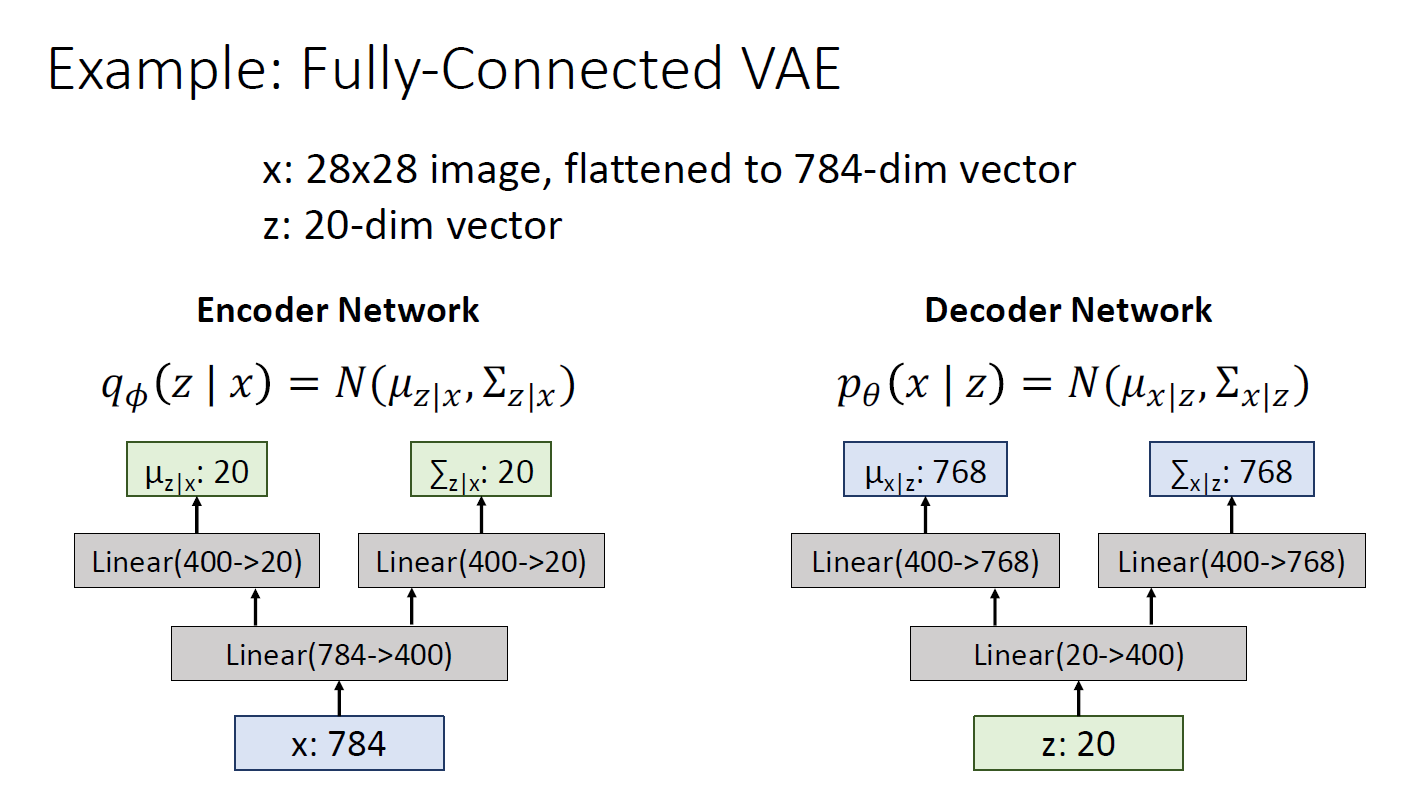
MNIST data에 대해 fully connected VAE 모델 예시
z는 하이퍼 파라미터로 학습 이전에 세팅 해야 함

lower bound를 maximize 하기 위해 첫 번째로 training set에서 mini-batch of data 를 취하고 encoder에 넣음
p(z/x) 가 나오게 되고 이것을 Dkl term(2번째 term)에 집어넣게 됨
(distribution은 diagonal gaussian 이고, p(z) 는 prior distribution 으로 unit gaussian 처럼 간단한 함수로 학습 전 fix함)
이 둘을 통해 kl divergence를 구하면 closed form으로 구할 수 있음


인코더를 통한 pridicted distribution에서 sample을 할 수 있게 되고, 디코더 네트워크에 피드함

decoder network는 이미지 x에 대해 distribution을 예측
E 및 q세타 텀은 인코더에서 예측한 z가 주어졌을 때, p(x/z) 값의 expectation, 즉 복원된 값이 원래랑 같아야 된다고 하며 학습을 진행 함
즉, 파란색 term은 reconstruction을 잘 하는 방향으로 학습을 진행하고 많은 latent information 이 저장되도록 학습하지만, green term은 latent variables이 심플하고 gaussian 이 되도록 학습이 진행되어 일종의 constraint가 됨
trained variational auto encoder로 새로운 data를 제작할 수 있음

1. Prior z 에서 p(z) 구함
2. sampled 된 z를 decoder에 넣어 x distribution을 구함
3. data generation을 위해 x에서 sample을 진행함

cifar 혹은 face 처럼 보이는 이미지들이 generated 됨

prior가 Diagonal Gaussian distribution 이기 때문에 z의 차원이 독립적임
2가지의 다른 z를 feeding하고 이것을 시각화 한다면 horizenal direction 혹은 vertial direction 으로 smooth 하게 숫자가 변화하는 것을 확인할 수 있음
variational auto encoder는 generate data를 배우는 것 뿐만이 아니라 latent code의 represent data를 학습함
따라서 z에 변화를 줌에 따라 이미지 생성하는 것을 변화시킬 수 있고, 이것은 auto aggressive model에 비해 variational auto encoder가 가지는 강점임
이미지 edit 과정
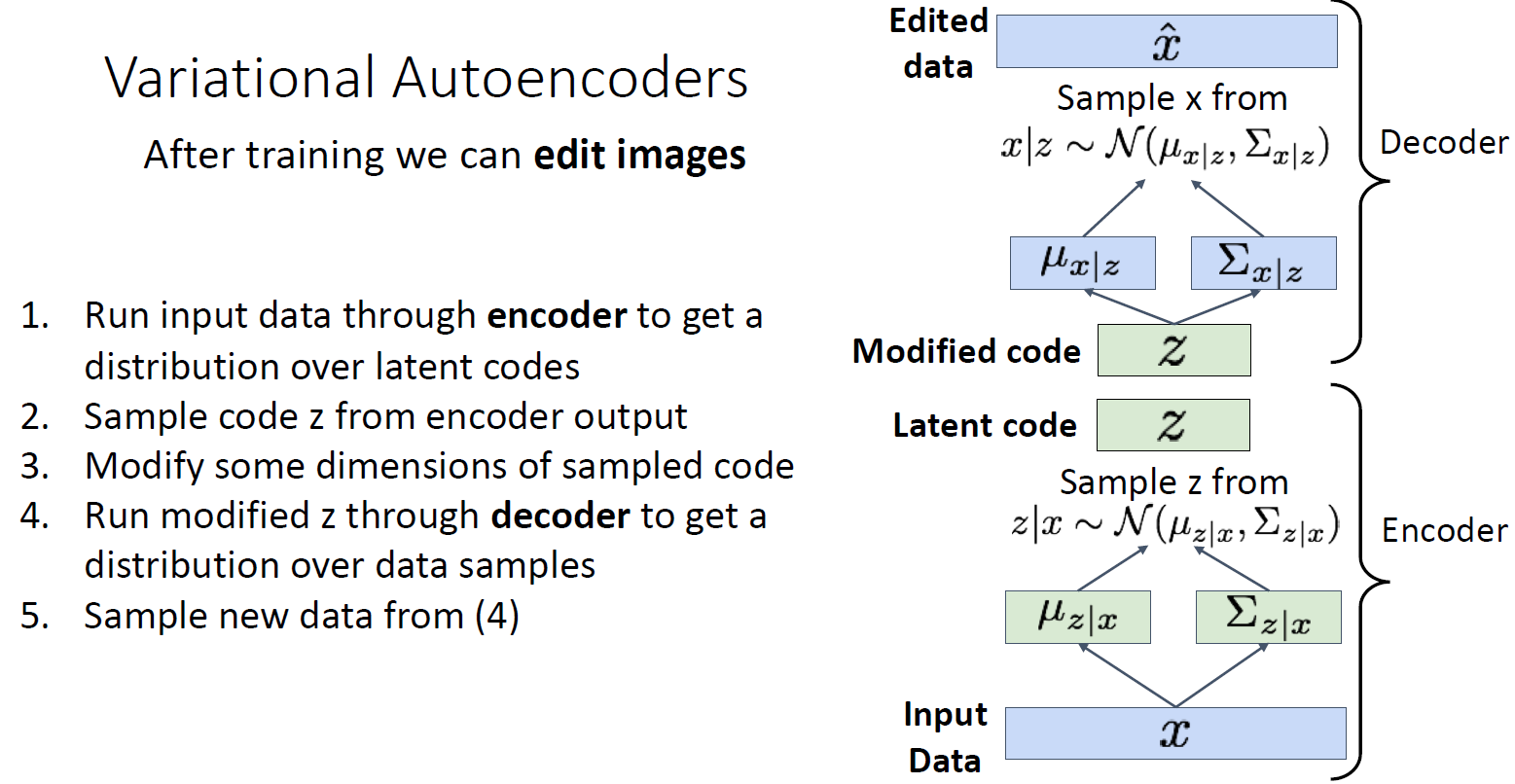
1. train 을 먼저 진행함
2. 이미지 x를 얻었을 때 이것을 edit하고자 하면 encoder에 넣고 latent code z의 distribution을 predict 함
3. latent code 를 sample 할 수 있음
4. 또한 이것을 value를 변형시킨다든지 하는 변형을 함
5. 그리고 decoder 에 넣음
6. generate new data sample

따라서 z1에 따라서 어떤 사람은 angry 하게 어떤 사람은 smile 하게 보임
z2에 대해서는 facial 방향이 바뀌게 됨

latent code를 바꿈으로써 generate 하기 때문에 ugly 하게 보임

summary는 위와 같음
-> generated model 이 blurry 하게 보이는 것이 gausian 때문일 것

이런 장단점이 있는 두가지 generative model 을 combine 할 수는 없을까?
VQ-VAE2
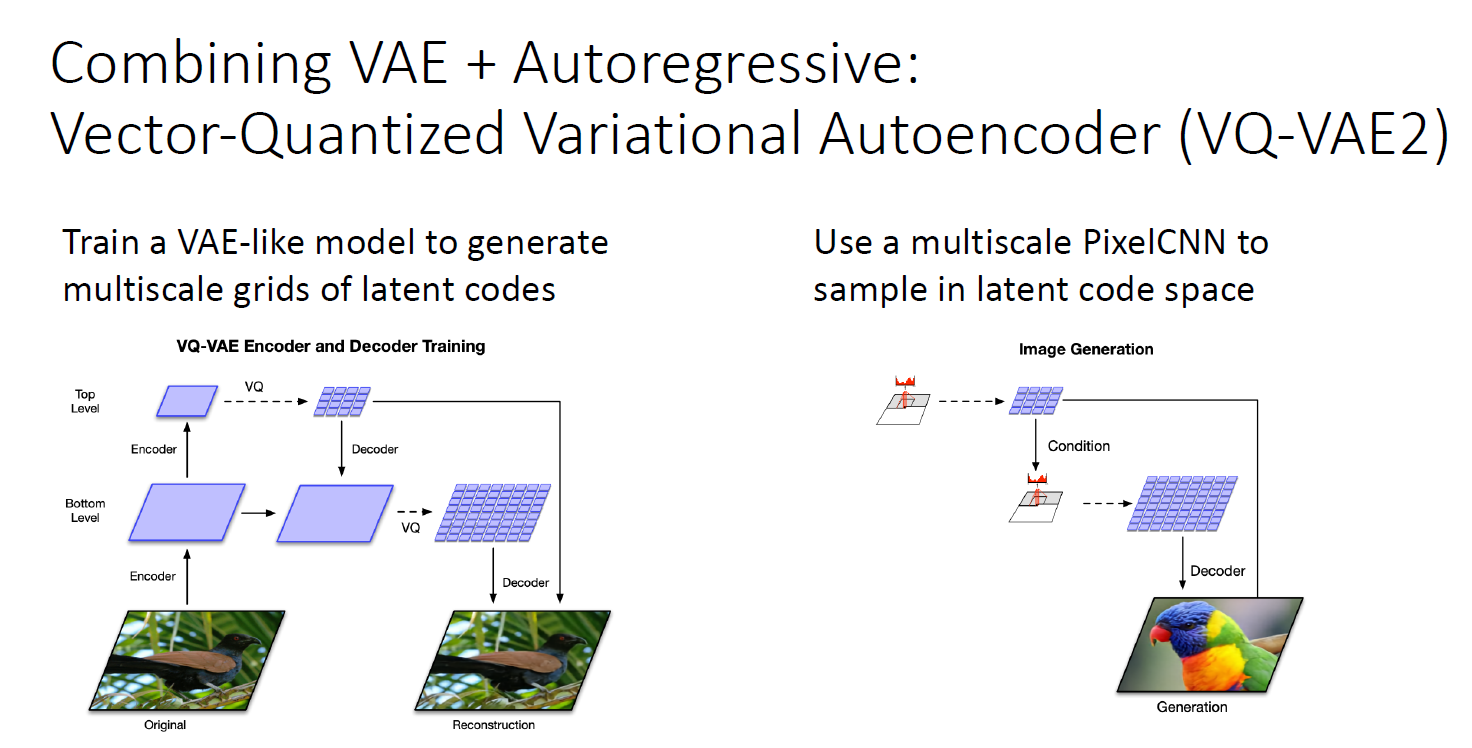
VAE를 학습할 때, latent vector를 학습하는 것이 아닌 latent vector의 multiscale grid를 학습
또한 pixel CNN을 Auto regressive model과 같이 latent code space에서 sample할때 사용함


model 이 class로 condition 되었을 때 잘 generate 를 high quality로 generate

고해상도 이미지 또한 너무나 잘 generate 함

이제는 이미지의 density를 계산하는 것이 아니고 approximation 하는 것도 아닌 p(x)로 부터 샘플링하는 방법으로 generation을 하는 GANs 가 있음
Generative Adversarial Networks
likelyhood의 evaluating은 상관하지 않음
단지 probability distribution으로부터 new sample을 하고자 함
setup : 데이터의 분포 p(x) 로 부터 xi의 데이터 가 있다고 가정하고 우리는 여기서 sample을 하고 싶음
Idea : variable auto encoder와 같이 latent variable z를 introduce를 함 (fixed 된 p(z)를 가진 prior를 가정함, uniform distribution이 될 수도, diagonal gaussian, 다른 간단한 distribution일 수도)
우리는 latent variable z 를 우리의 prior distribution에서 샘플을 하고, generation network라고 하는 G(z)에 통과시켜 output sample of data x를 만들어 냄
PG는 이미지의 확률 분포를 implicitly defining 함 (explicitly 하지 못함)
따라서 우리는 generator를 학습하여 실제 Pdata의 distribution이 될 수로 있도록 함
즉, generator를 학습하여, latent variable z의 sample을 generator를 통과했을 때 실제 p data가 되도록 학습시키자 라는 것
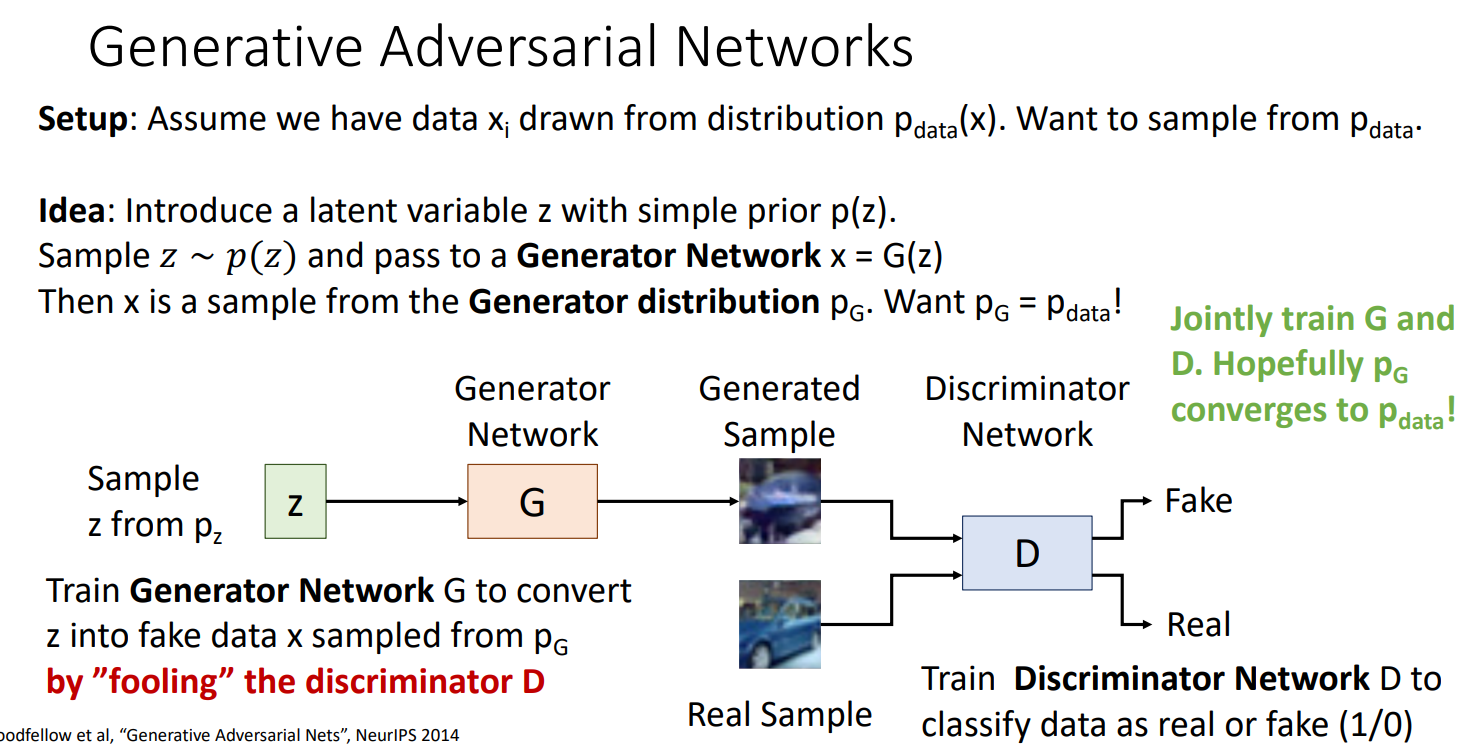
여기서 discriminator network가 나오는데, second neural network를 만들어서 실제 이미지 data로부터 왔는지, generated sample인지를 구분하고자 함
이것은 supervised로 이루어지기 때문에 generated 된 것인지, 실제 이미지인지를 알 수 있음
이 두가지의 네트워크가 경쟁하면서 지속적으로 좋은 성능을 낸다면, Pg가 real data의 pdata에 수렴할 수 있음
따라서 generative adversarial network라고 불리는 이유가 이것임
jointly 학습을 진행함
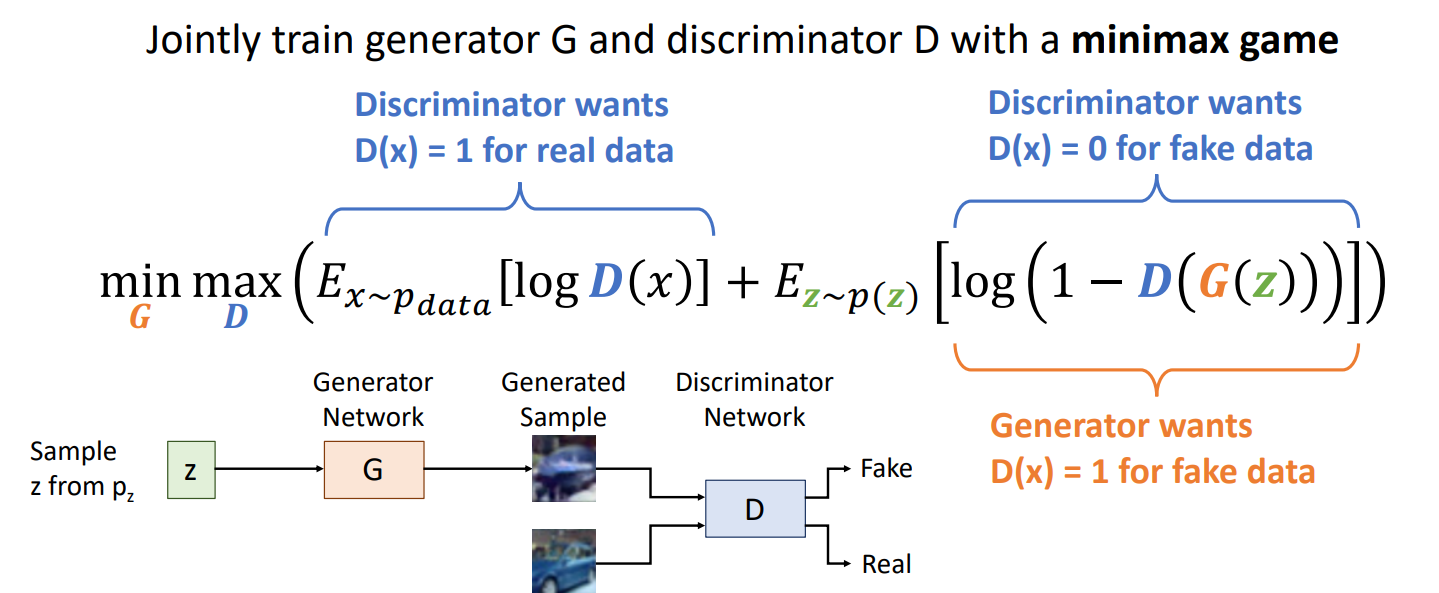
D는 objective function을 maximize 하려고 하고, G는 minimize 하려고 함

alternating gradient update 를 통해 학습을 함
- D를 Gradient ascent 로 D update
- G를 Gradient descent 로 G update
이를 T까지 반복함
그러나, 이는 각각에 대한 loss를 update 하기 때문에 전체 loss를 동시에 업데이트 하는 것이 아님
일반적으로 loss가 0으로 수렴하는 형태가 아닌, 불규칙한 형태

초반에 generator가 0에 가깝게 G(z) 값이 나올 것이기 때문에 gradient vanishing 문제가 발생할 가능성이 높음
-> 초반에는 loss 식을 변형하여 강한 gradient 를 주는 방법이 있음
Global minimun을 위해서 식의 변형을 하면
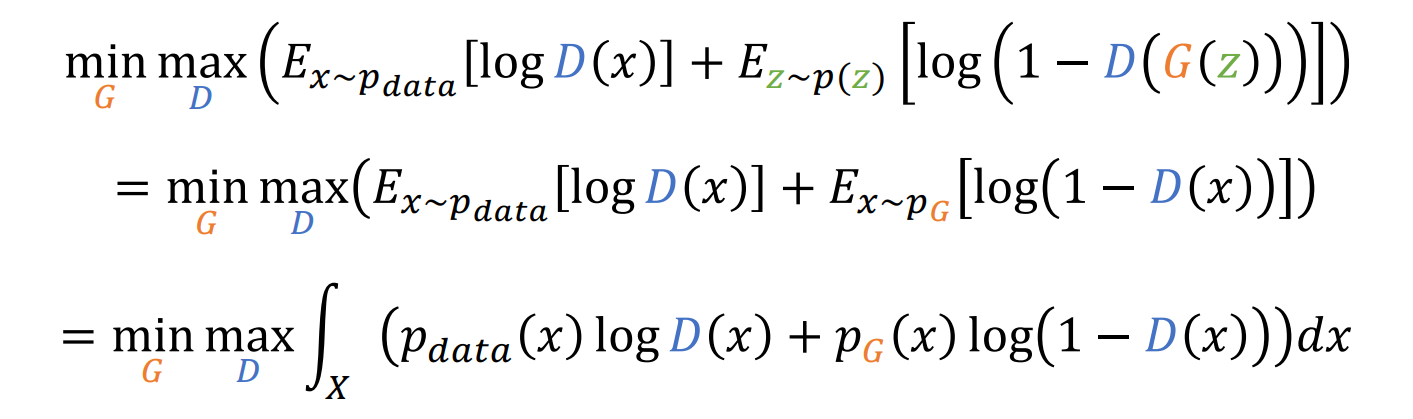
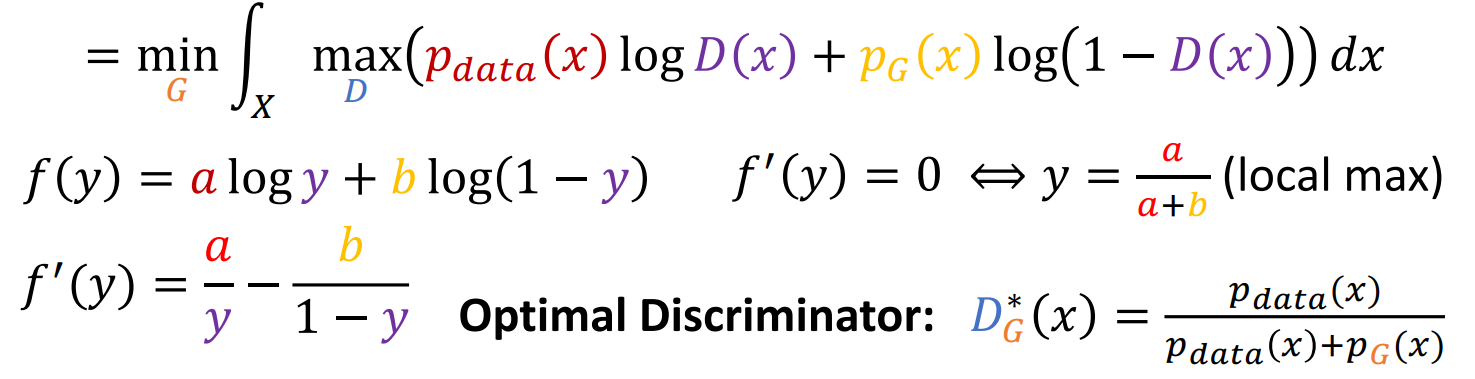
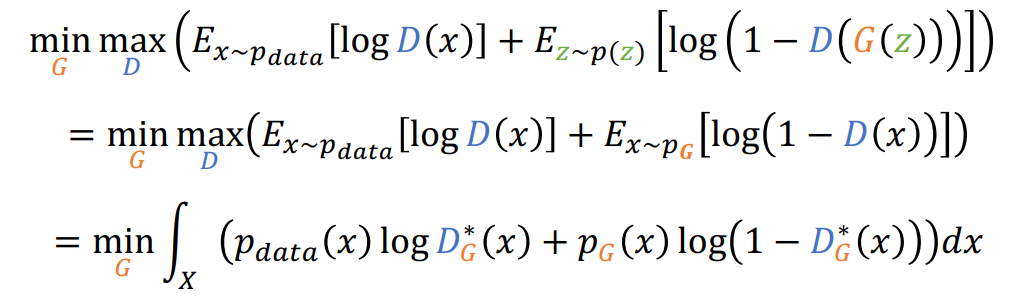
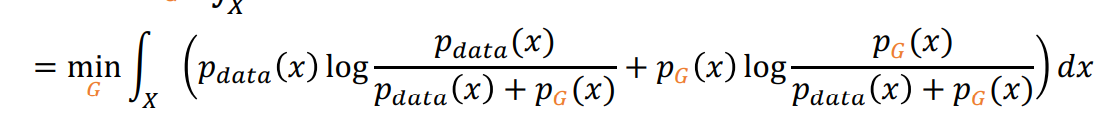
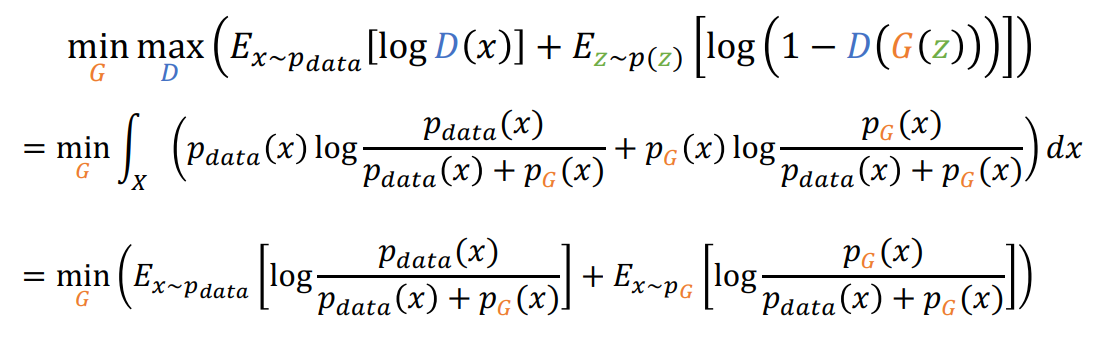
즉 다음과 같이 정리 됨
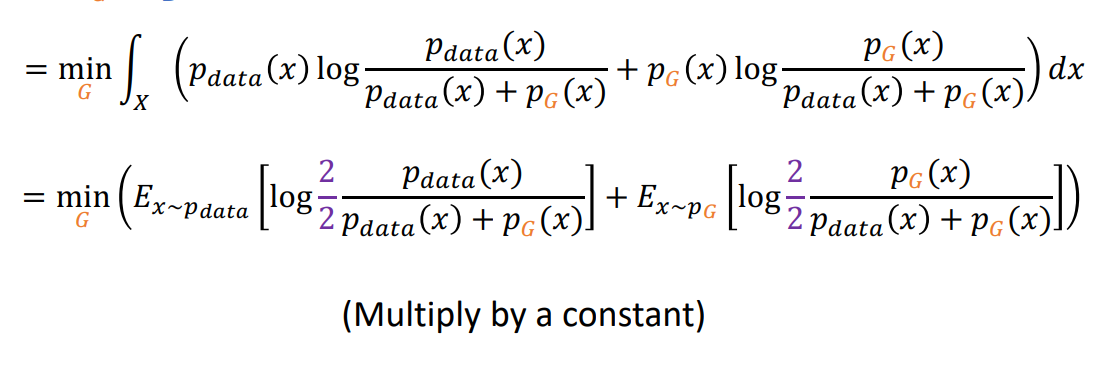
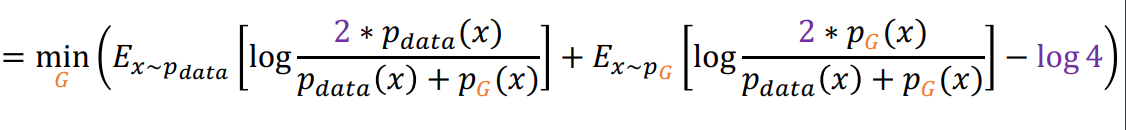
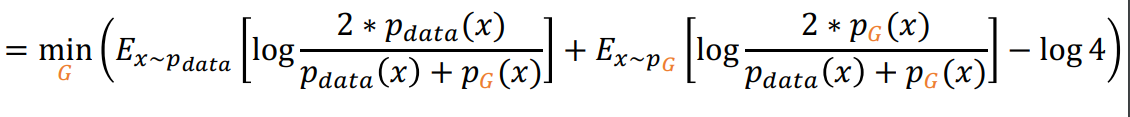

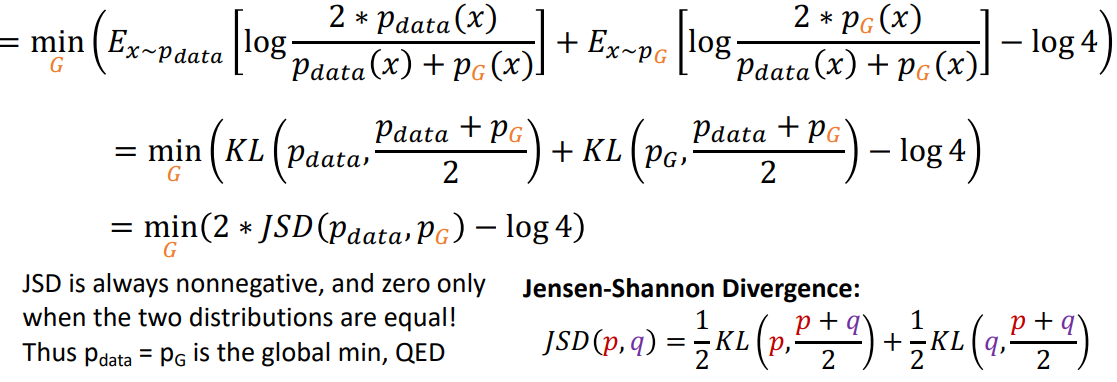
JSD연산이 됨
minmax game 이였던 식이 min형태로 식이 정리가 되어 optimize를 한번에 가능 하게 됨
JSD가 0이 되면 두 distribution이 같게 되고 그렇게 되면 Pdata=Pg 가 되어 global minimum이 됨

따라서 정리하자면 optimal solution, global minimum은 다음과 같이 Dg, Pg 가 각각 되는 경우가 됨
그러나, Pg=Pdata가 실제로 represent 할 수 있는 network인지는 모름
또한, optimal solution 으로 converge 될 수 있는지도 잘 모름

digit number와 face로 부터 다음과 같이 generated 된 샘플 결과가 있음.
DC-GAN
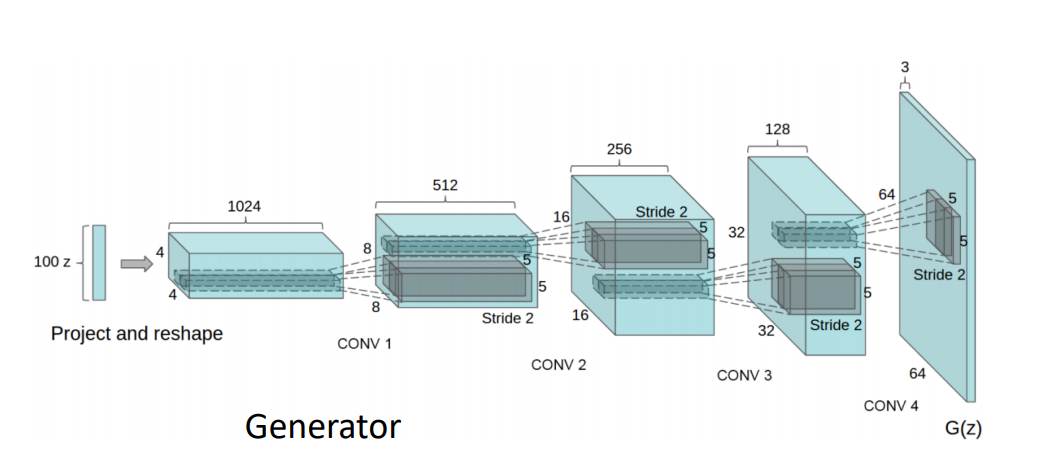
5-layer convolutional network를 generator, discrimator에 사용

샘플들이 좀 더 좋은 결과를 나타냄
Interploation
하지만 이 모델이 더 흥미로운건, latent space에서 interpolation을 할 수 있다는 것임
latent variable z를 take 하여 generator network를 통해 generate 하여 sample x를 만드는데,
sample z 사이를 inearly interpolate 하여 generator network에 넣어 interpolated X image를 만듦
따라서 한 행은 latent space의 interpolation을 의미함

반대 편은 다른 이미지 이기 때문에 중간에 continuously 하기 morphing 하는 것을 알 수 있음
adversarial network는 non-trivial underlying structer를 학습하기 때문에 단순히 2가지 이미지를 합성한것이 아님을 알 수 있음
Vector-math
adversarial network는 vector math로 볼 수 있음

각각의 표정들의 latent space의 z vector를 average하고, 그것을 generator를 통해 나타낸 값이 3가지 결과임
z verctor에서 각각의 값을 연산하고 generator를 하면 다음과 같은 결과를 나타냄
웃는, 여자 에서 여자가 빠지고, 남자라는 latent z vector 가 더해져 결국 웃는 남자라는 결과가 나옴
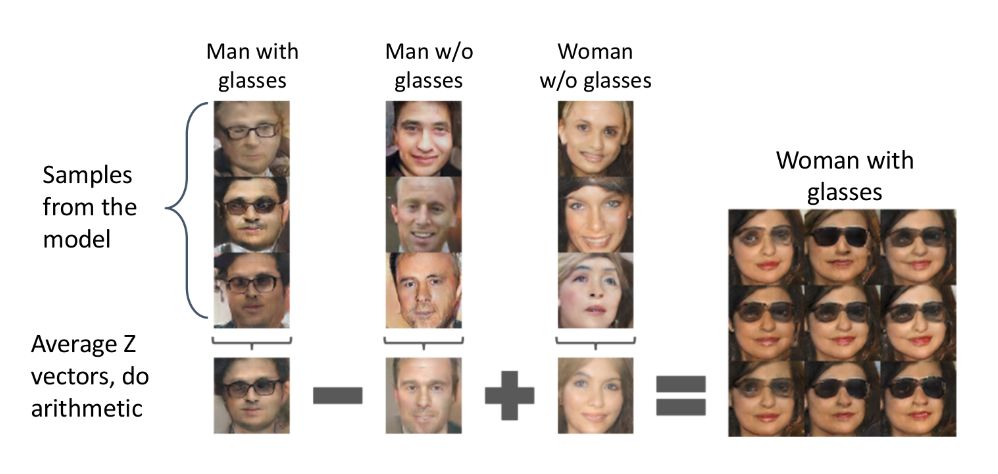
아래도 선글라스 남자에서 선글라스가 빠지고 그것에 여자가 더해짐
Conditional GANs
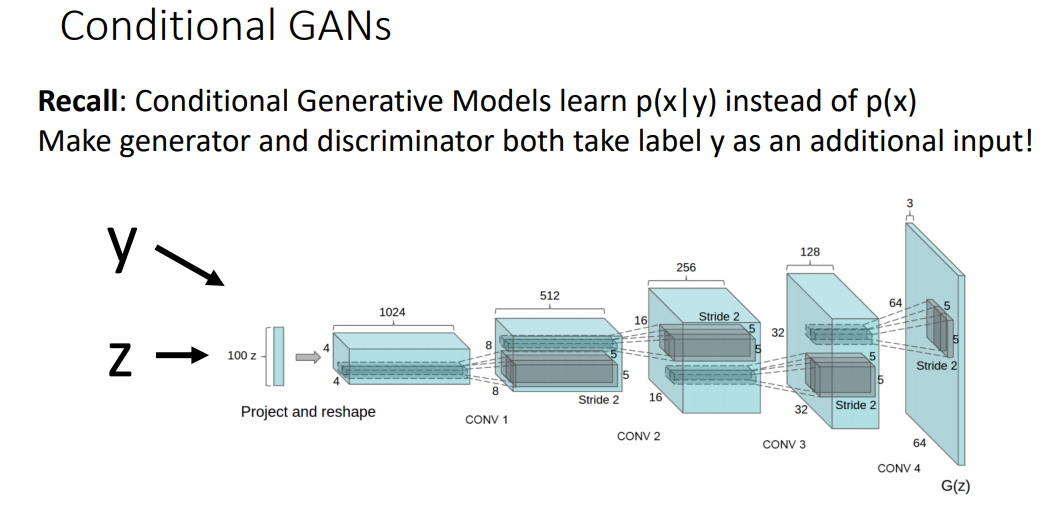
기존 GAN 과 다르게 train data로 학습시켜 비슷한 data를 output으로 generate 하는 것이 아닌, 어떤 label을 generate 할 지 정함
따라서, label y를 input으로 추가함

기존 batch normaliztion에서 γ, β에 label을 추가함(여기서는 y가 예시로 들어감)
Test 시 label을 지정하면 그것에 맞는 이미지 생성

Spectral normalization 을 이용해 label에 맞는 이미지 생성

self - attention으로도 잘 학습을 진행

비디오 까지도 생성 가능

conditioning 을 label에서 text까지 가능함

자기 자신 이미지를 upsampling 도 가능

이미지를 다른 형태의 이미지로, 색을 입히거나 2d-3d로 변환 등등
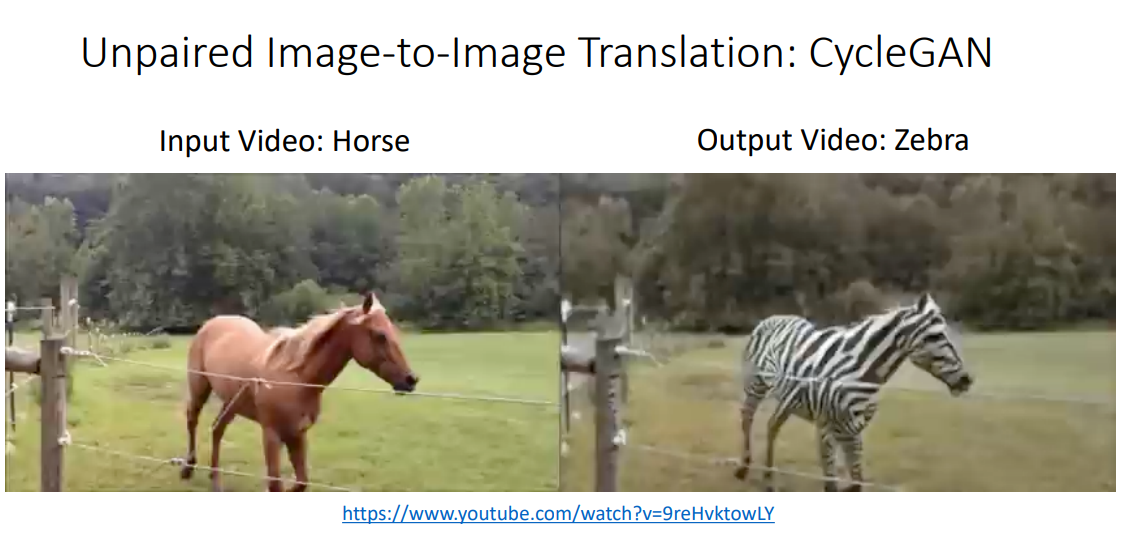
갈색 말을 얼룩말로 변환시키기도 함

이미지의 부분을 label map을 만들어 나누고 이를 이미지화 할 수 있음
semantic map과 style 이미지를 합치는 것

이미지 뿐만이 아니라, 사람들의 이동 경로를 예측하기도 함
GAN Summary

3가지 방법을 모두 살펴보았음
아주 많은 application이 가능하고, 높은 퀄리티의 이미지를 만들 수 있었음
