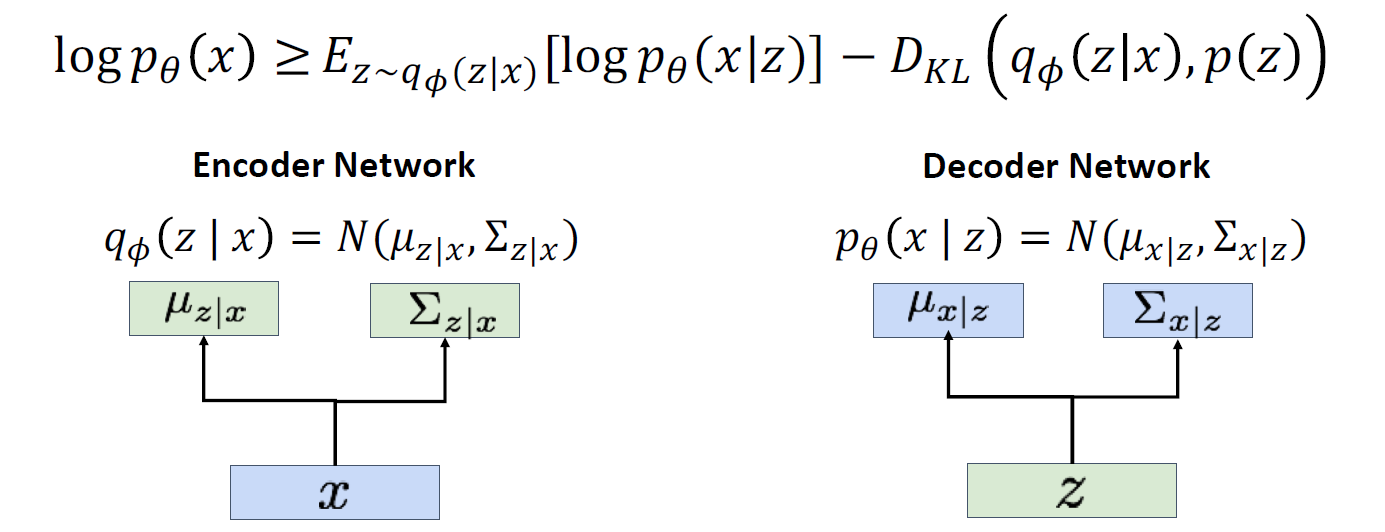Supervised learning : Input X 를 Output Y로 mapping 찾는 것
Unsupervised learning : Data annotation 이 필요 없으며 data의 hidden structer 을 찾는 것
Clustering, PCA, Autoencoder 등의 방법들이 있음.
Discrimiative VS Generative Models
모델 Probability 구조 타입에 따라 구분함
Data : X 이고, Label Y라고 한다면
Discrimiative : p(y/x) 처럼 조건부 확률, 즉 x가 주어졌을 때 y가 나올 확률을 학습함 - supervised 임
Generative : P(x) unsupervised 확률을 학습하는 것
Conditional Generative : P(x/y) y 라벨이 주어졌을 때 x의 확률을 학습 하는 것

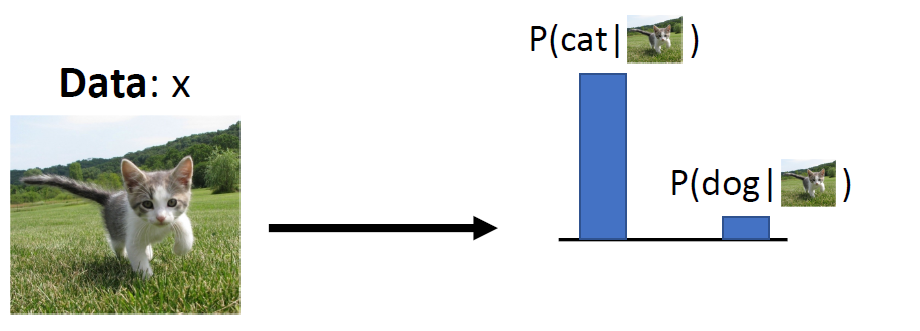
다른 이미지에 따라 competetiton 이 없음
단지, 다른 label에 따라 competition 이 있음
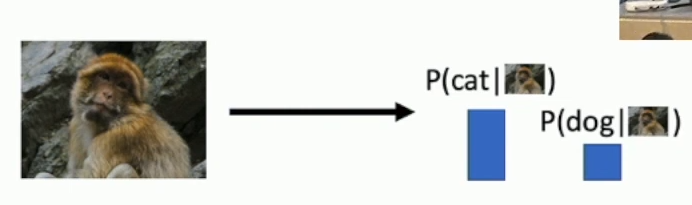
이런 unreasonable input 의 경우에 output은 normalized distribution을 통해 label 확률 값을 내보내며 unreasonable 하다 보이지 않음


모든 possible image가 경쟁하여 각각의 probability mass를 만듦
Visual world 에 대한 이해가 필요함
또한 train data가 unreasonable 하다면 reject 할 수 있음

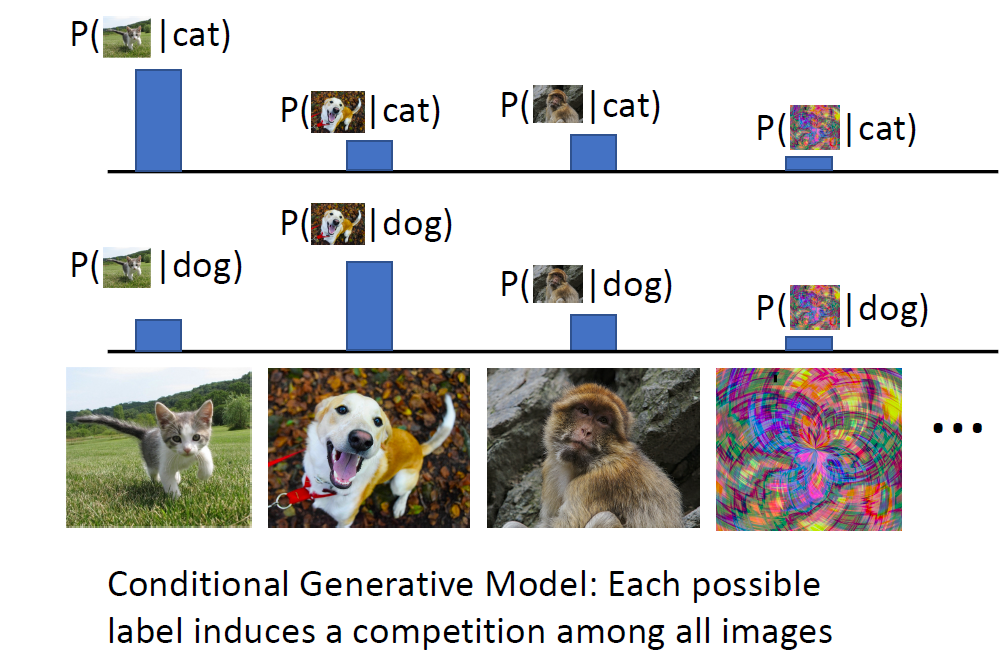
하나의 라벨이 모든 image에 대해 경쟁을 시킴
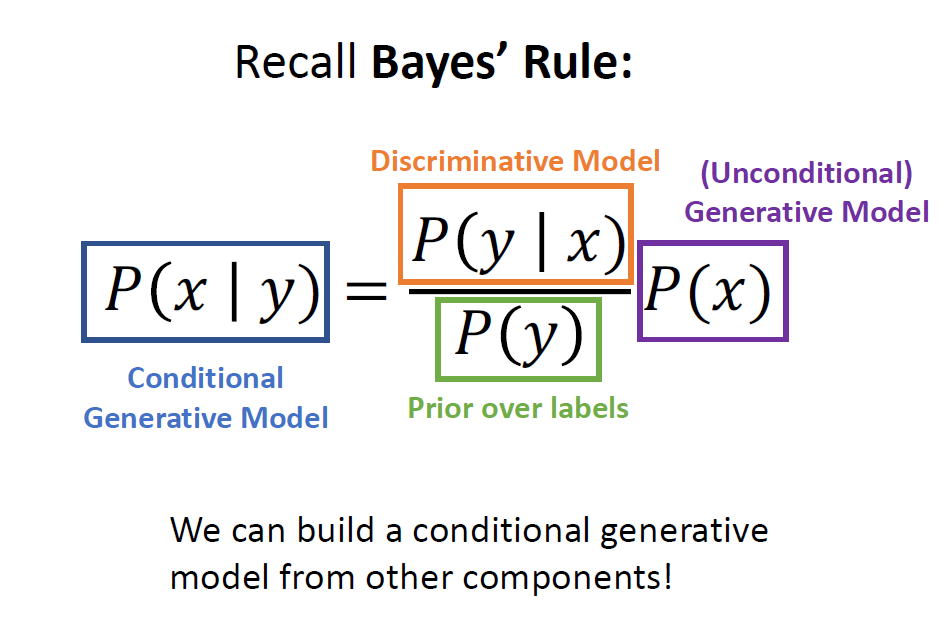
Discriminative model 과 generative model 이 있다면 Conditional Generative model 을 만들 수 있음
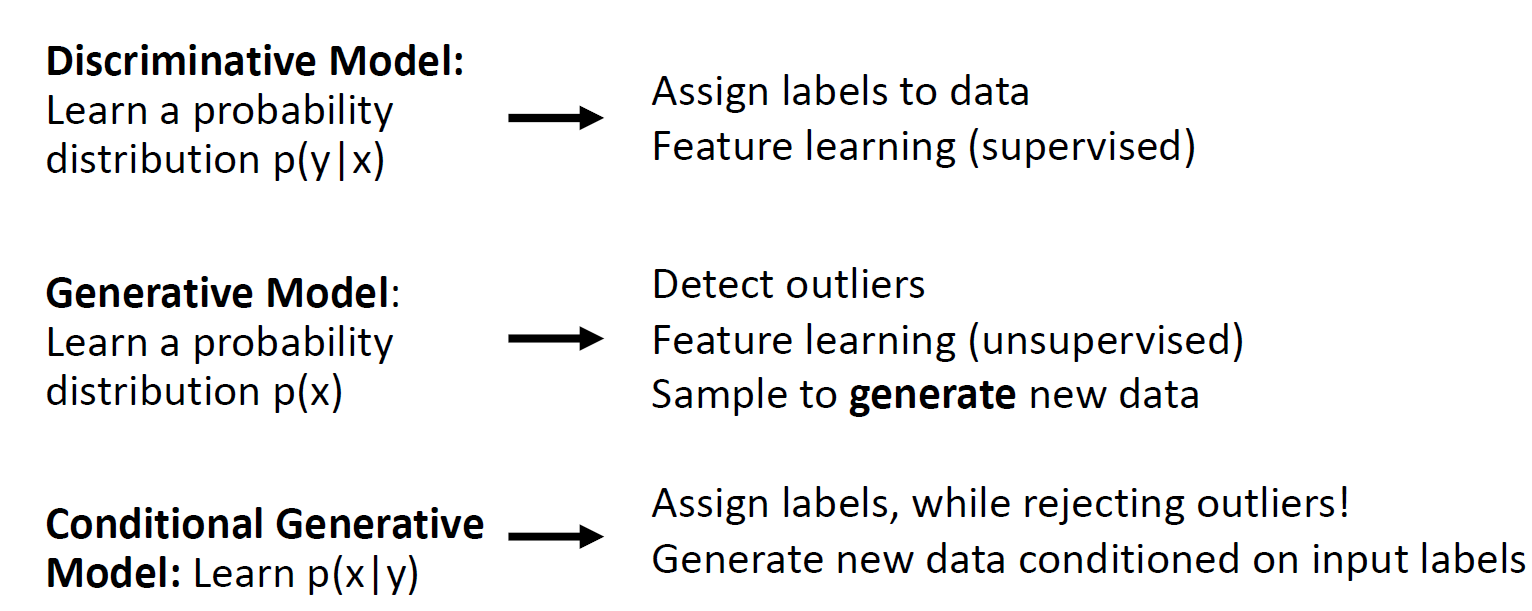
Generative model은 outlier를 구한 뒤 feature learning을 진행하고 new data를 generate 함
Condtional generative model 은 label을 assign 하지만 동시에 outlier는 rejecting 함
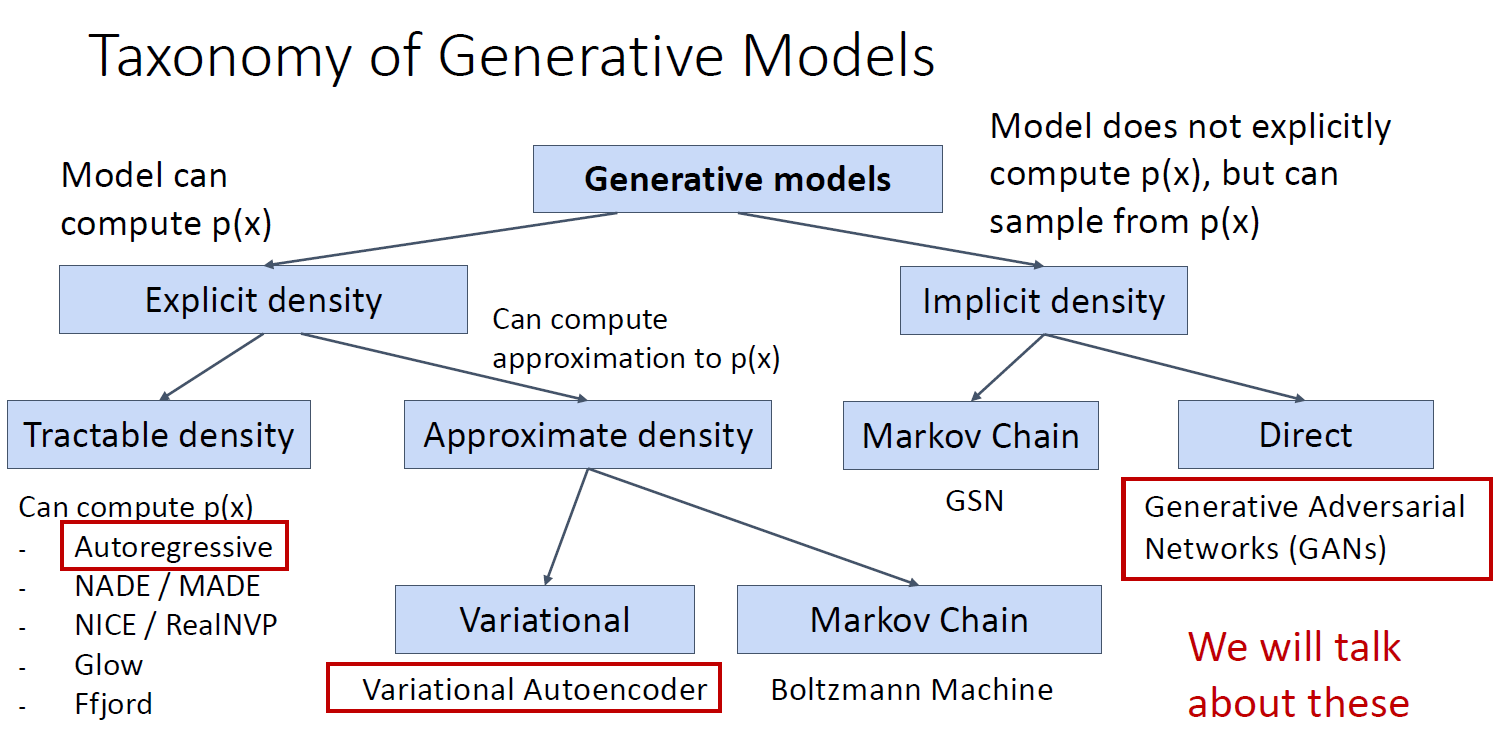
image에 대해 density function을 assign 하기 때문에 학습이 끝난 뒤 인풋을 넣으면 아웃풋으로 likelyhood value가 출력 됨
-> Explicit density function
tractable density : can compute p(x)
approximate density : p(x) is apprioximation
variational autoencoder
markov chain
likelyhood value 는 나오지 않고 model이 훈련 된 뒤에 underlying distribution을 통해 sample이 가능
-> Implicit density function
markov chain
dirct : directly sample from function
Autoregressive models

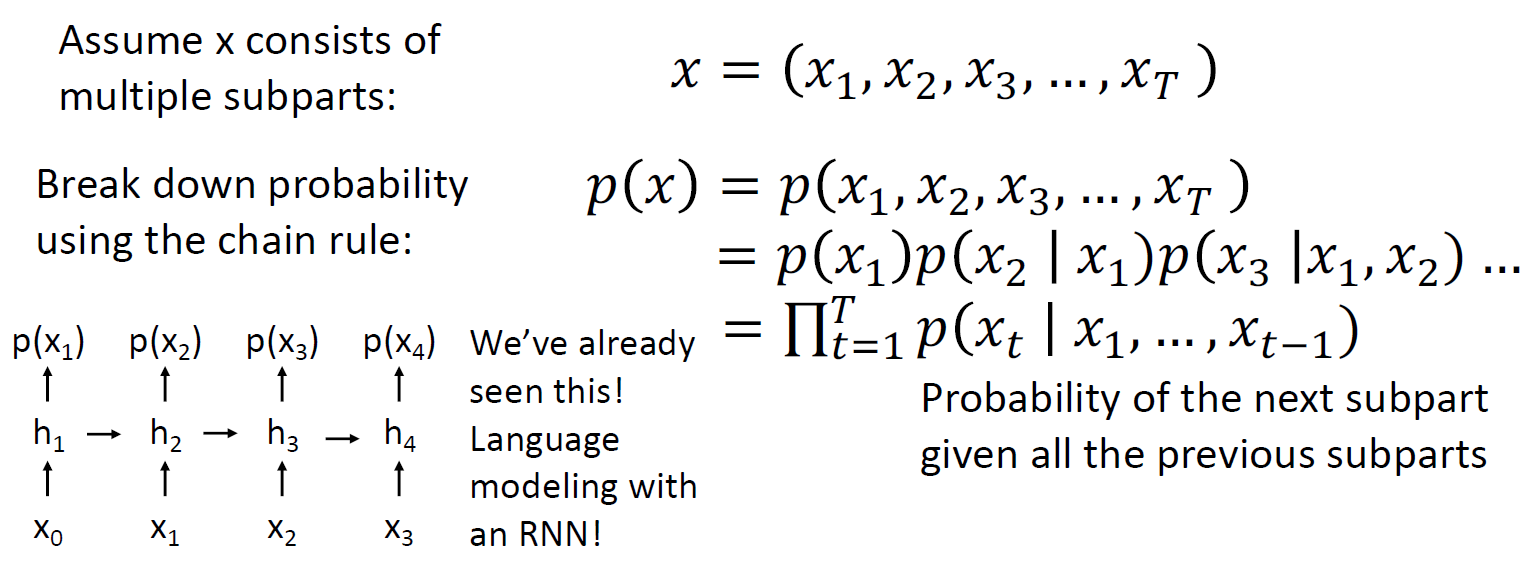
RNN 인풋 토큰을 이용하여 아웃풋이 다시 인풋으로 들어가는 형태로 연산이 됨
RNN 메카니즘을 사용하여 generative model에서 이미지의 explicit density function을 얻을 수 있음
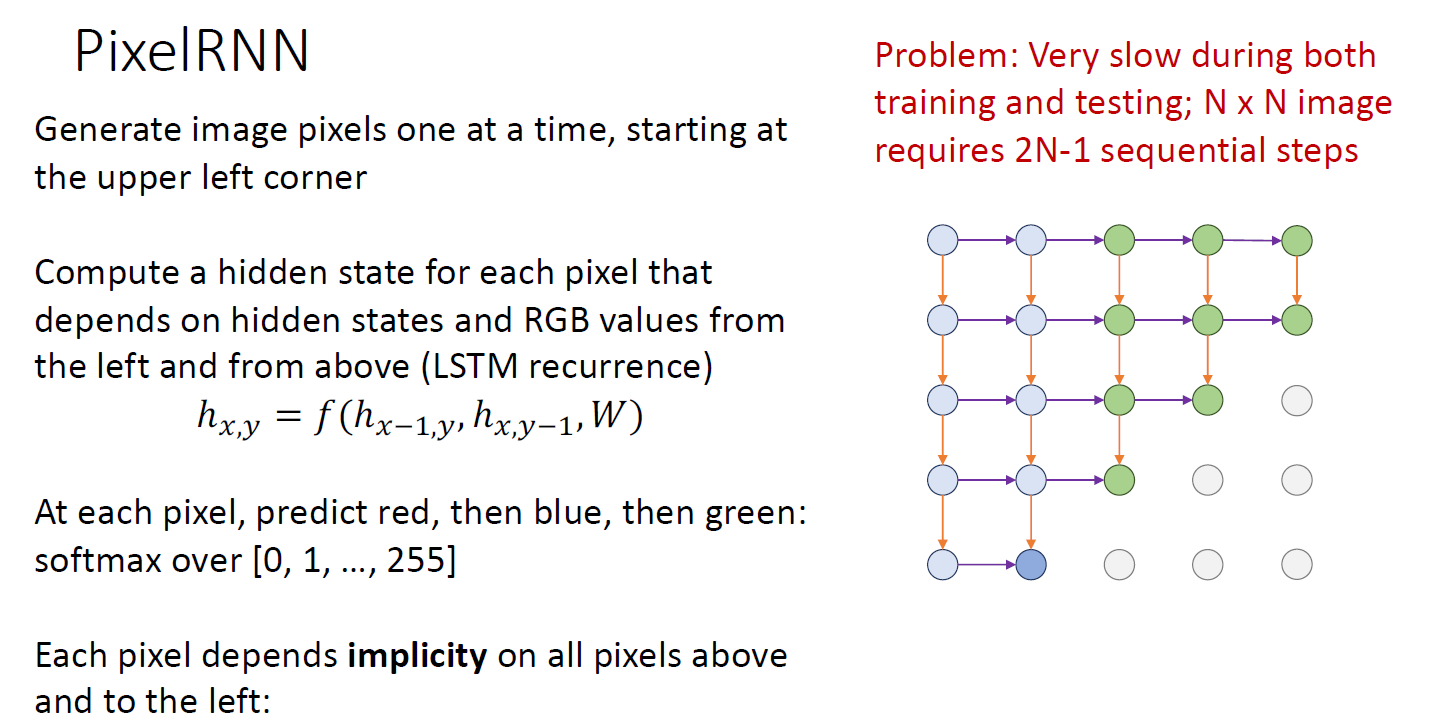
이미지 pixel을 왼쪽 위에서 부터 generate 한다고 하면 RNN hidden state를 계산하는거로 시작하는데, 각 픽셀의 output은 RGB 색상임
pixel의 각 색상 별 value값이 output으로 나오면, softmax를 하게 됨
다음 인접 픽셀 (아래, 우측) 으로 RNN hidden state를 계산하게 됨
diagonal 하게 extend out 해서 color를 generate 하게 됨. RNN structre에 의해 각 pixel 의 각 prediction은 픽셀 위치 기준의 위쪽과 좌측에 의해 implicity하게 depend 하게 됨
바로 좌측 혹은 위에 값에는 explicity 하게 depend 하지만, 이전 state를 담당했던 pixel들에 대해서는 implicity 하게 depend 함
NxN 이미지는 2N-1의 step을 밟게 되고 이런 training 은 아주 느리고, test 또한 느림
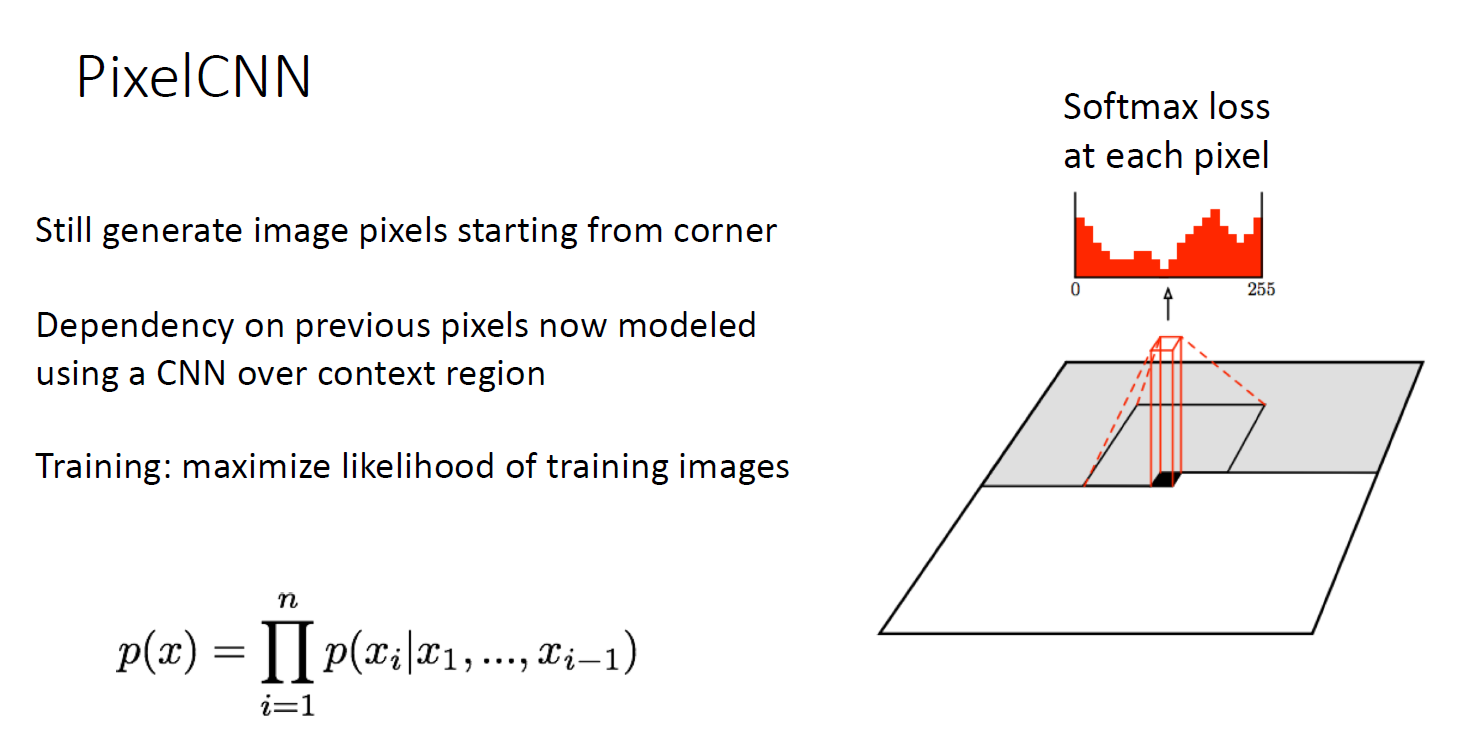
Pixel CNN
RNN을 사용하는 것이 아닌, convolution을 활용하여 acceptive field 를 통째로 연산함
하지만 아직 느림

generated sample인데 traied model 에 의해 만들어졌음
zoomin 하는 순간 이미지 퀄리티가 매우 나쁨을 알 수 있음

explicit density function을 가지고 있기 때문에 test time에 새로운 image 를 넣었을 때 density function을 얻을 수 있음
따라서 evaluate 하기 가장 편함
또한 edge 학습 및 local global structure을 잘 생성함
하지만, Sequential generation 이라는 점에서 느려서 효율이 떨어짐
Variational Autoencoder
Density function 을 완벽히 계산할 수는 없지만, lower bound는 구할 수 있음. maximize true density 가 아닌, maximize lower bound of density.
(기존의 Non-variational autoencoder)
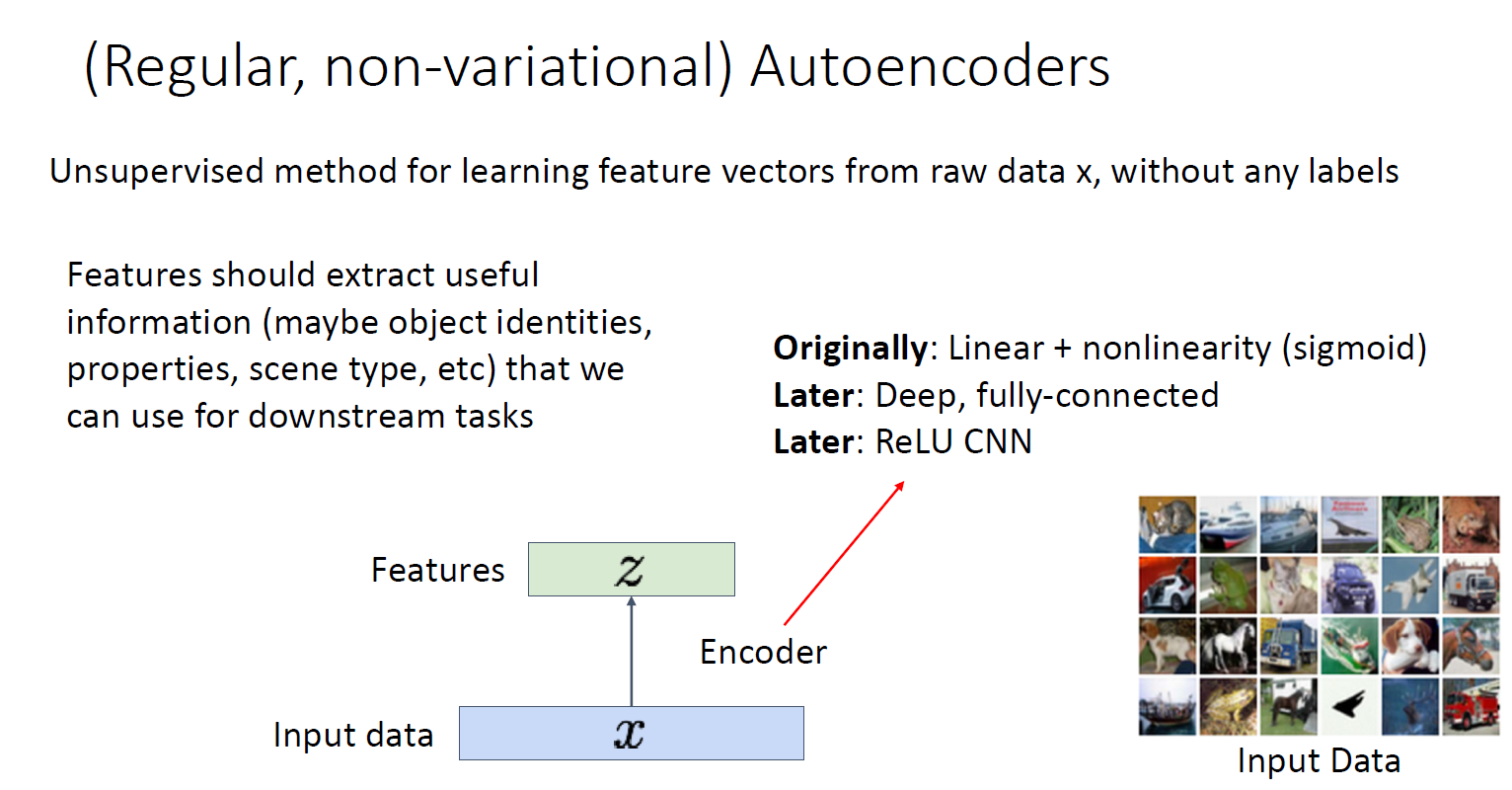
raw data에서 어떻게 feature transform을 할 것인가?
encoder를 통해 latent feature를 뽑아내고, 이것을 decoder를 통해 reconstruct 함
Not probabilistic : No way to sample new data from learned model -> unsupervised기 때문에 labeled 샘플이 없어 새로운 sample을 generate 할 수 없음
variational autoencoder
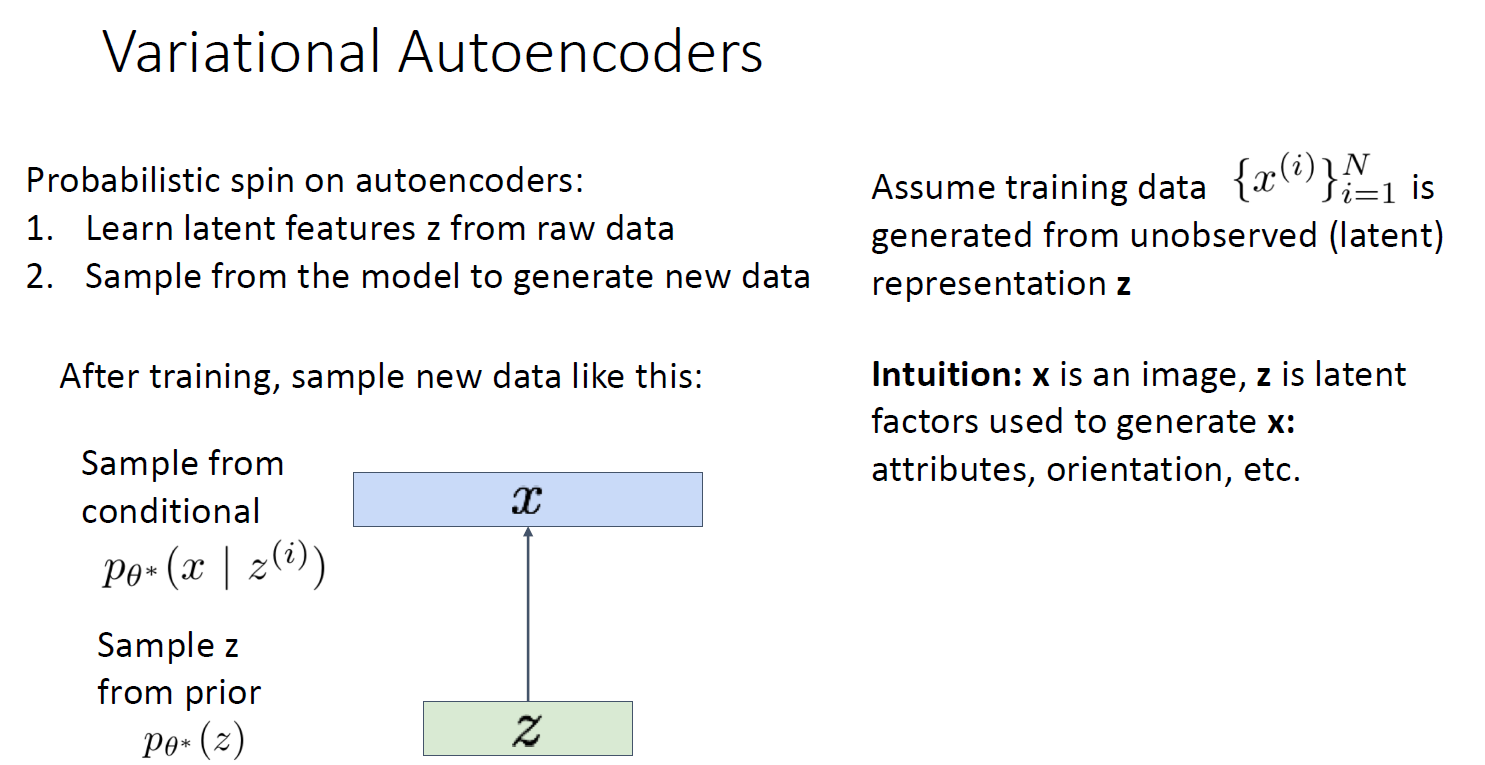
특징으로, latent features를 raw data에서 학습해야 함
또한, 모델을 통해 새로운 data를 generation을 해야 함
Unlabeld sameple을 많이 가지고 있다고 가정하고 각 샘플 x가 latent z 벡터로부터 생성되었다고 가정해보자
p(x/z) output이 image가 아닌, 이미지의 neural network의 distribution 임
p(z) (prior distribution) : 가우시안이라고 가정하면,
p(x/z) : z가 given 일 때 x가 나올 조건부 확률에 대한 pmf
VAE에서는 AE와는 다르게, 가우시안 확률분포에 기반한 확률값으로 나타냄

모델 학습을 위해 maximize likelihood of data를 함
p(x/z)를 학습하기 위해서 각 x에 대해 z를 관측할 수 있다면 가능함
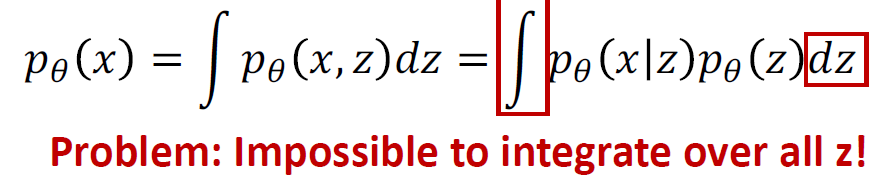
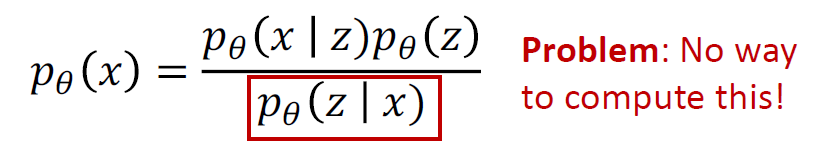
P(z/x) 는 이미지가 주어졌을 때 latent variable의 확률을 구하는 것으로 반대의 확률을 구하는 것이고 이것을 직접적으로 구하는 것은 불가능함 따라서 약간의 치팅을 함

인코더와 비슷한 network를 학습시킴
완전히 다른 네트워크지만 marginal distribution이 거의 일치하게 학습하여 bayes rule 에 사용함
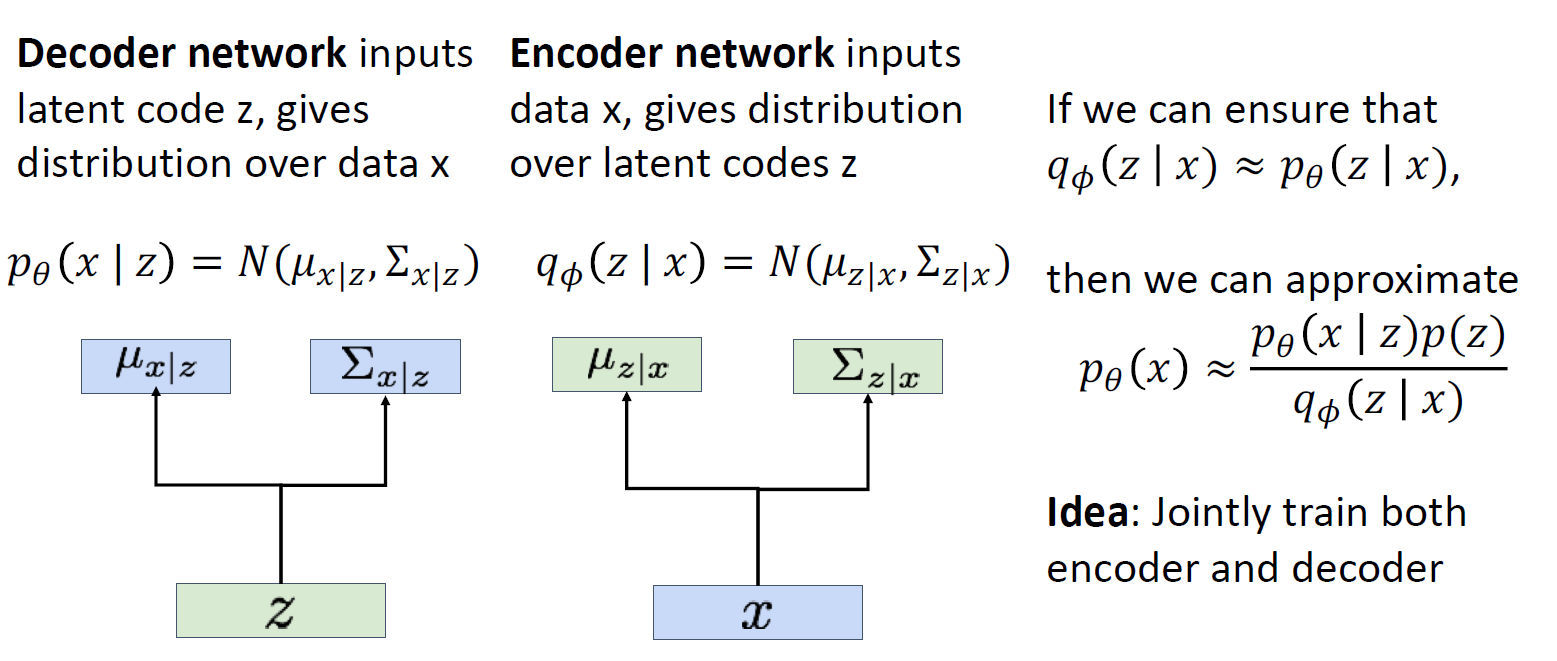
즉, jointly train both encoder and decoder를 함
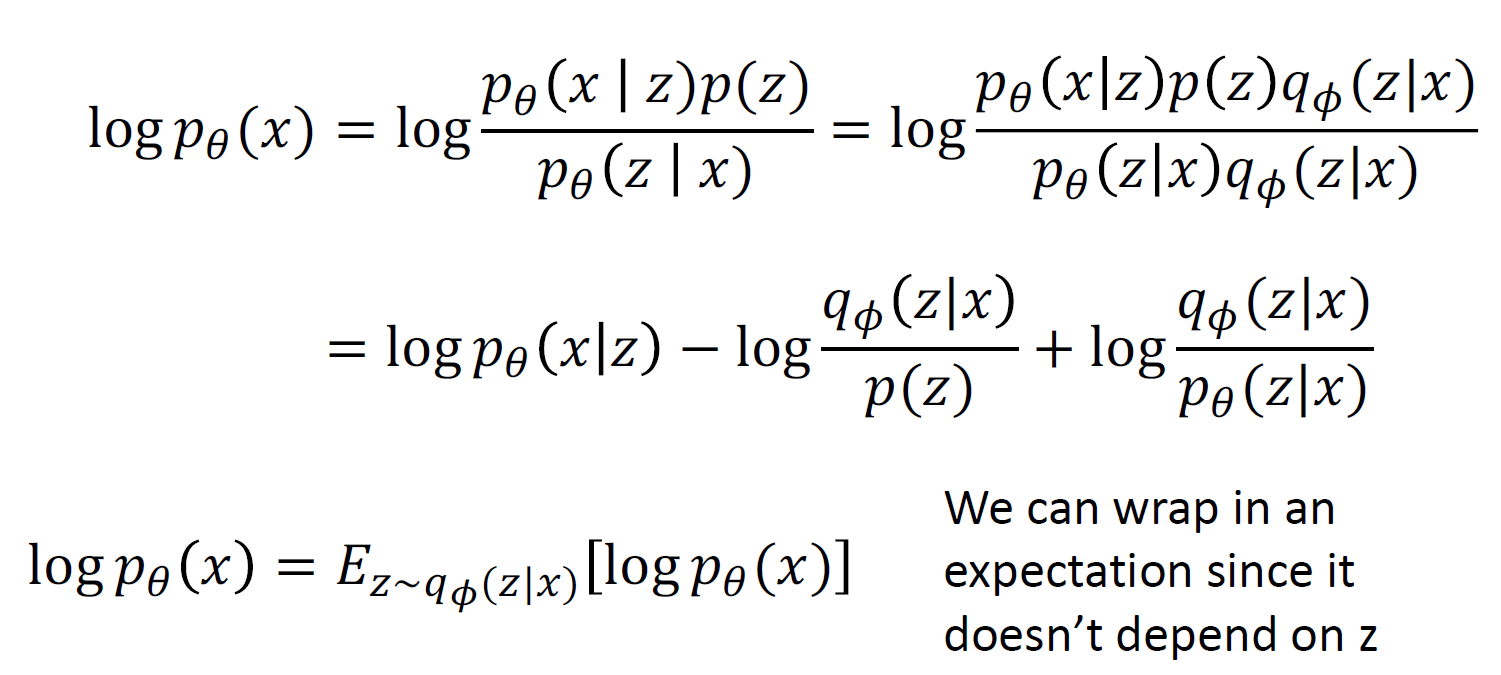
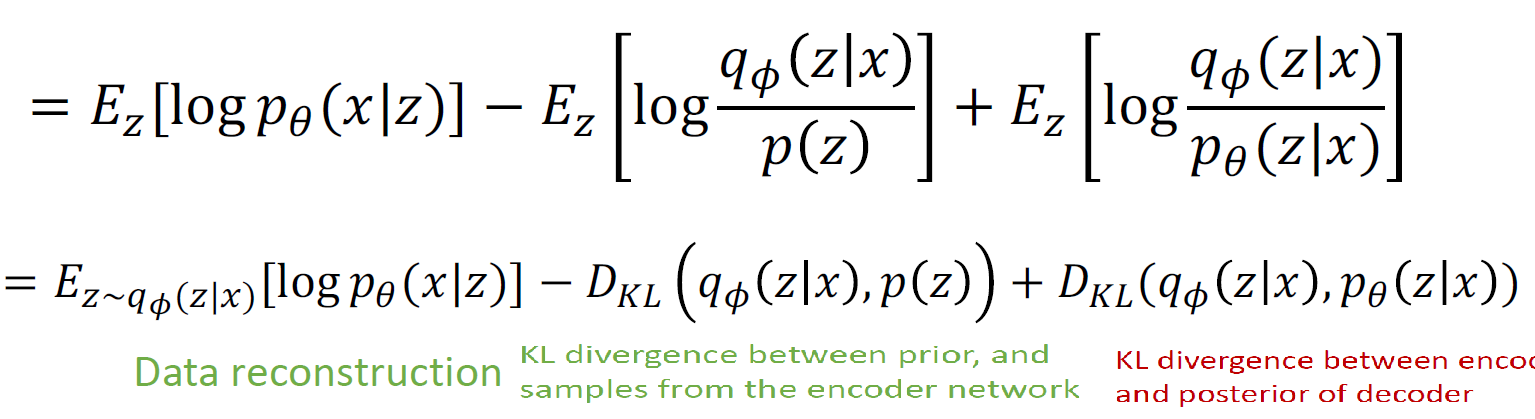
KL term 이 0보다 크므로, 이것을 없애는 것으로 lower bound를 만들 수 있음
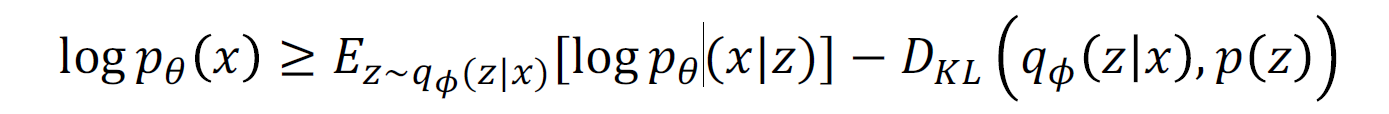
결국, encoder와 decoder를 jointly 하게 학습시켜 data likelyhood의 vartiational lower bound를 maximize 하며 학습을 진행함