10장에서는 Neural Networks를 학습시키기 위해, 학습 이전에 필요한 설정들과 트레이닝을 진행하는 동안 필요한 것 알아봄
1. Activation Function
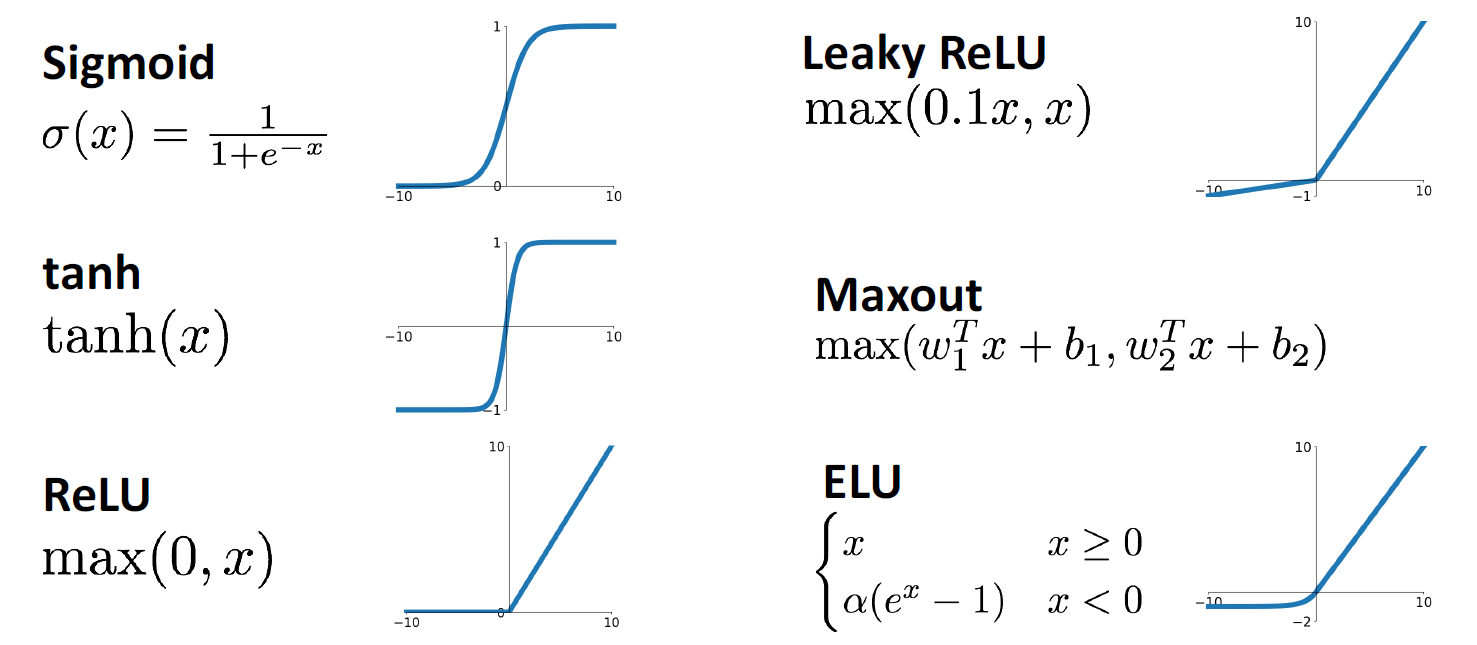
6가지의 방법에 대해 장,단점을 살펴볼 예정
1.1 Sigmoid
전통적으로 사용해온 활성함수로서 0과 1을 확률로 output을 출력
간단하게 nonlinear dependence를 만들기 좋기 때문에 사용하였음
최근 사용하지 않는 이유는 3가지 문제점이 있기 때문
(1) Sigmoid 활성함수에서 x값이 크거나 작을 때 그래디언트값이 0으로 수렴하게 flat 하다는 단점
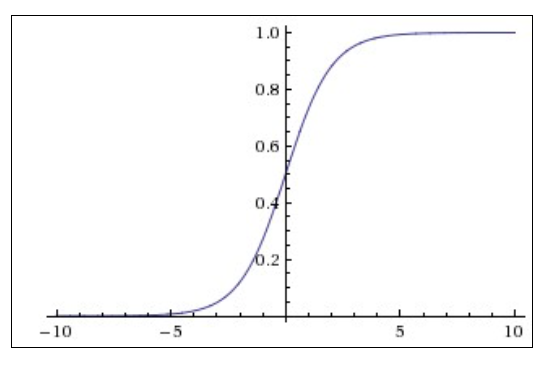 -> Saturated regimes (포화 상태) : deep neural networks에서 layer들의 노드들이 그래디언트가 0으로 수렴하기 때문에 weight에서 업데이트가 거의 되지 않음
-> Saturated regimes (포화 상태) : deep neural networks에서 layer들의 노드들이 그래디언트가 0으로 수렴하기 때문에 weight에서 업데이트가 거의 되지 않음
(2) Sigmoid output이 zero-centered 되지 않기 때문
이전 Layer에서 sigmoid fn을 사용하면 input X는 positive이고, w의 local gradient는 항상 positive가 됨.
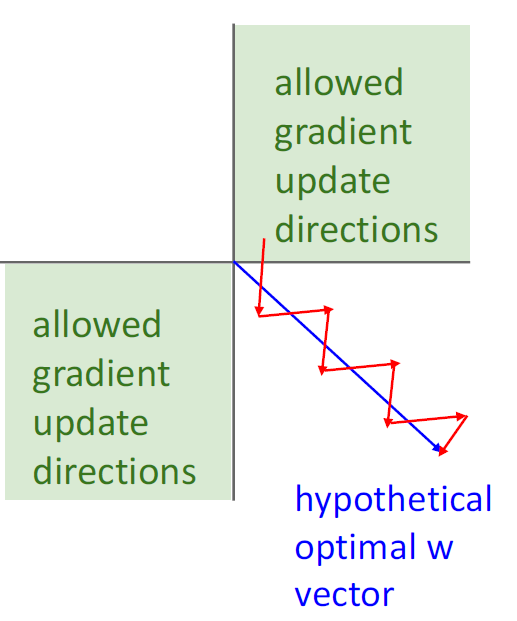
-> Downstream gradient는 항상 upstream gradient의 부호를 따라가게 되고, 모든 weight들이 positive or negative인 방향으로만 업데이트 가능 하여 zigzag patten을 그리며 학습이 느려지게 되는 원인이 됨
(다만 실제로는 minibatch gradient descent의 average sum을 활용하여 학습하기 때문에 all negative, all positive 문제는 줄어듦)
(3)
exp term은 연산 속도가 느림
1.2 Tanh
Scaled and shifted version of sigmoid 임
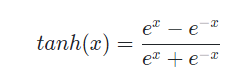
Zero centered 이지만, 여전히 saturation 문제가 있고, exponential term으로 연산속도가 느림
1.3 ReLU
Non-linear 하면서 가장 심플하여 가장 빠른 activation function임
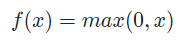
Input이 positive일 때 saturation 문제가 발생하지 않음
Not zero-centered이며 output이 positive 하기 때문에 zig-zag pattern 현상이 있음
Input이 negative면 downstream gradient가 0이 되어 update가 되지 않음
Sigmoid나 Tanh보다 saturation 영역이 적어 ReLU 사용
1.4 Leaky ReLU
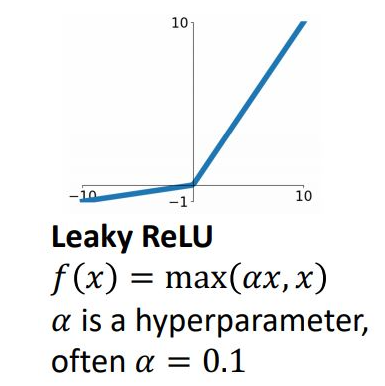
ReLU에서 negative saturation 문제 해결(hyper parameter alpha를 통해 small positive slop를 갖게 함)
Zero-centered 문제 해결로 dead ReLU 제거
Hyperparameter를 learnable parameter로 바꾼 PReLU(Parametric ReLU)도 존재 : backpropagation 단계에서 alpha 업데이트
Zero Point에서 미분이 불가 *x가 정확히 0인 일은 거의 없기 때문에 무시하고 사용
1.5 Exponential Linear Unit(ELU)
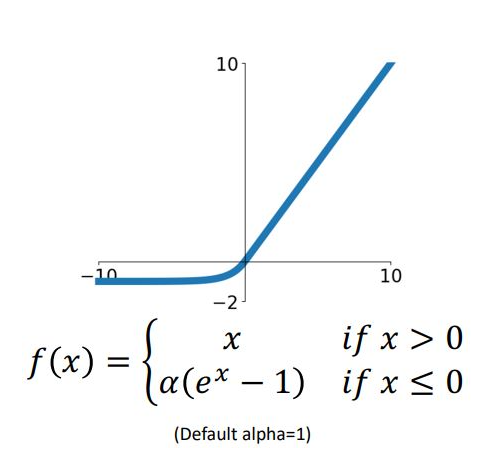
ELU는 ReLU, Leaky ReLU의 not differentialble 한 문제를 해결
Exp term에 의해 연산이 느려지고 hyperparameter alpha 또한 고민거리
1.6 Scaled Exponential Linear Unit (SELU)
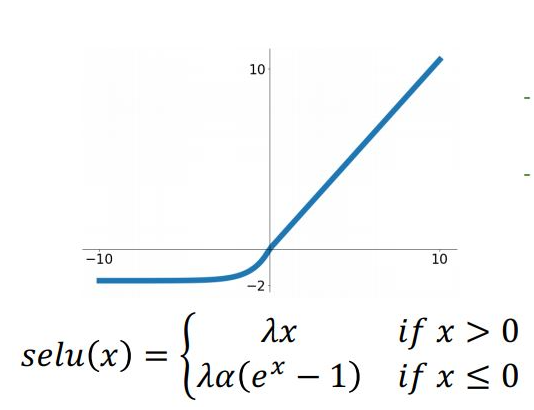
ELU함수의 slop term에 ramda 를 붙여 self-normalizing 되는 alpha, ramda를 제시 (Batch Norm이 필요 없음)
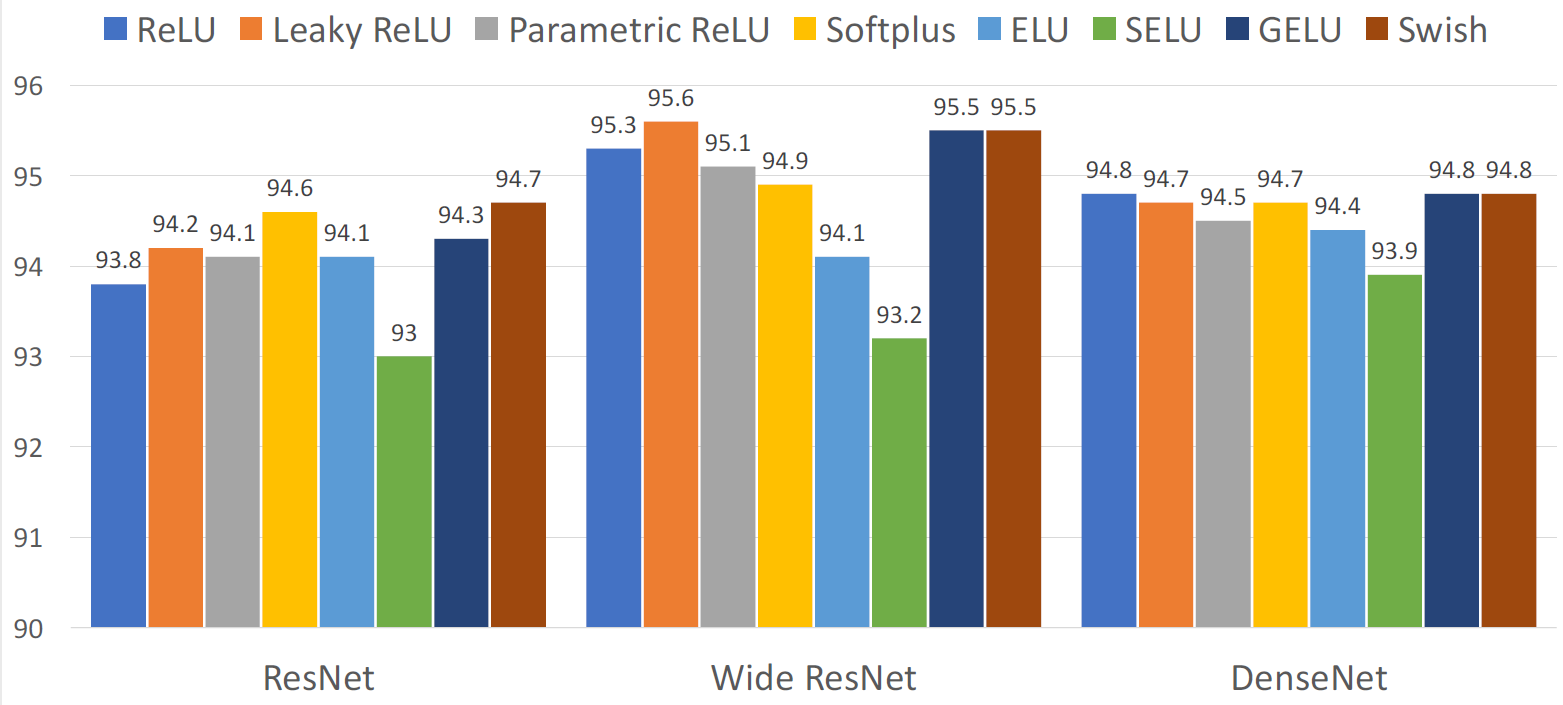
유명한 Networks 에서는 큰 차이가 없기 때문에 ReLU를 사용하는것을 추천
0.1%의 최적화를 위해서 다른 activation 함수를 쓸 수는 있으나, sigmoid와 tanh는 사용하지 말것
2. Data Preprocessing
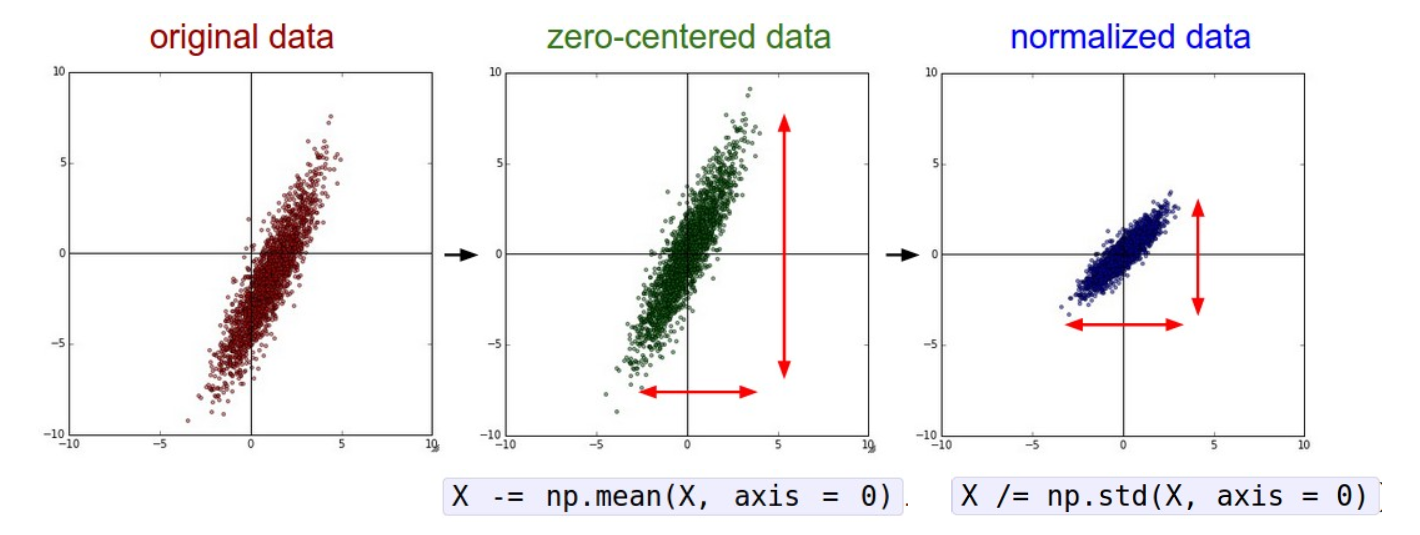
Input 이미지가 2차원상의 점 하나에 대응 시 original data 처럼 분포
zero-centered data는 zero-mean이 되도록 데이터 군집을 모든 차원에 대해 원점으로 이동시킴
*파이토치 이용하면 X -= torch.mean(X, dim=0)
Normalized data는 variable별로 표준편차를 샘플에 대해 나눈 것
Normalize를 한 뒤 위아래와 좌우의 변동성이 균등하게 조절
-> Preprossing을 하면 gradient 계산에 좀 더 유리함
x가 zero-centered 되지 않으면 gradient가 all positive 혹은 all negative가 되어 학습에 좋지 못함
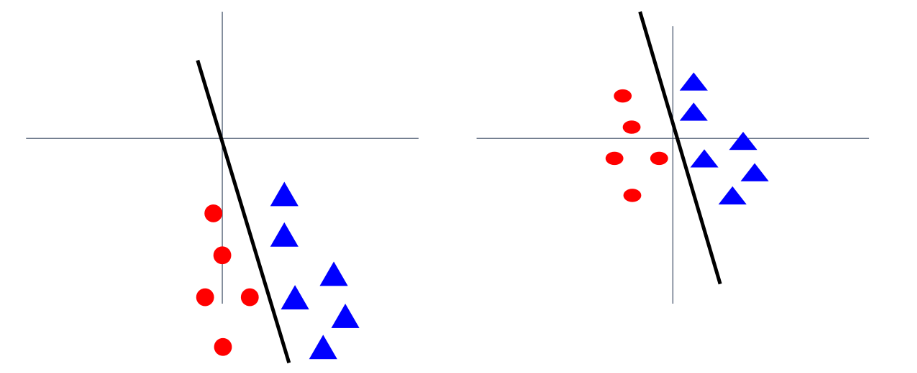
또한 Normalization을 진행하기 전 zero-centered 되어 있지 않은 data라면, slope의 미세한 변화에도 loss가 많이 바뀌게 되고 optimization이 어렵게 됨
반대로, normalize 된 우측의 경우 작은 slope 변화에도 optimization process가 편함
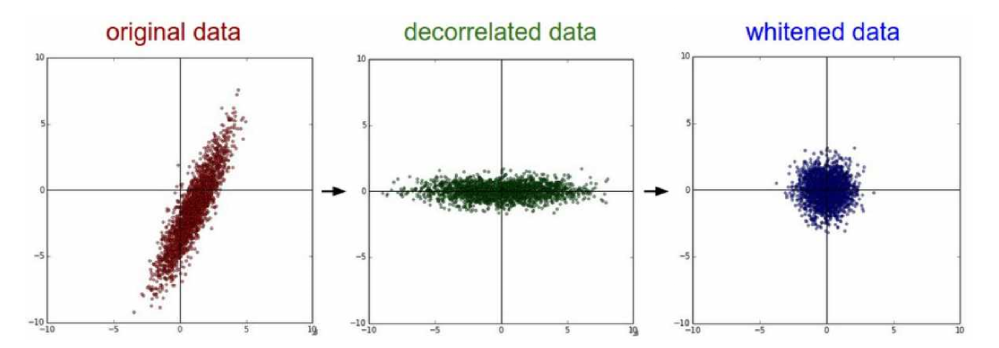
PCA(Decorrelated data)는 correaltion을 제거한 data로, diagonal 성분만 남아있음
Covarience Matrix가 Identity matrix인 경우는 whietened data라 하고, 이는 이미지에서 잘 사용하지 않음
Data Preprocessing for Images
Validation, test set에 대해서도 preprocessing을 함.

3. Weight Initialization
Weight 학습하기 전 초기값을 설정하는 것은 매우 중요함
ex) W 및 b의 모든 element를 0으로 설정한다면?
-> Forward 계산 시 output이 0이 되고 학습불가
ex) W 및 b의 모든 element를 같은 값으로 설정한다면?
-> 모든 gradient가 같은 크기로 update되기 때문에 "symmetry breaking"을 해야 함
W와 b가 모두 조금씩 달라 모든 노드들이 조금씩 다르게 initialize 해야함
(1) Initialize with small random values
 Weight random number를 가우시안 분포를 가지는 값을 0.01로 스케일링하여(std = 0.01)설정
Weight random number를 가우시안 분포를 가지는 값을 0.01로 스케일링하여(std = 0.01)설정
-> 이런 방식은 작은 network에서는 잘 작동하지만, deep할 때에는 잘 동작하지 않음
 ->Random number로 weight를 initialize 하면 값의 분포가 레이어가 깊어질수록 std가 0에 가까워짐
->Random number로 weight를 initialize 하면 값의 분포가 레이어가 깊어질수록 std가 0에 가까워짐
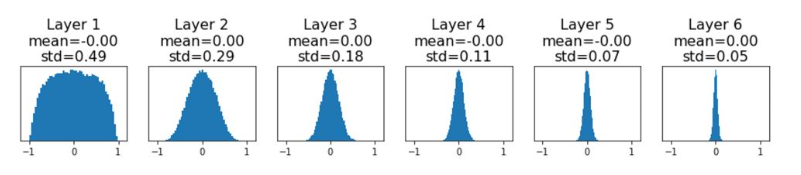 ->W의 gradient 또한 0에 가까워지기 때문에 update가 제대로 이루어지지 않음
->W의 gradient 또한 0에 가까워지기 때문에 update가 제대로 이루어지지 않음
Weight random number를 std=0.05로 설정
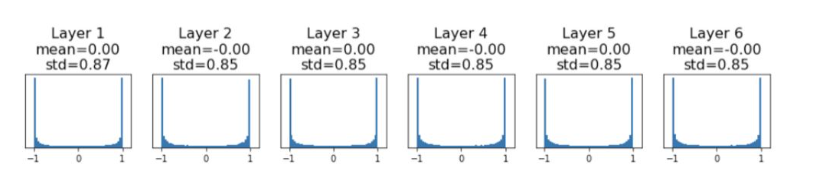 -> tanh activation function과 같이 saturaing regimes에 있음
-> tanh activation function과 같이 saturaing regimes에 있음
weight가 saturate 되어 gradient 0으로 수렴 및 update 이루어지지 않음
(2) Xavier initialization
std를 hyperparameter로 쓰는 것이 아닌 W에 Din을 sqrt하여 나누어 scailing하여 initialize 하는 방법

Input dimension의 사이즈가 클 수록 initialize 하는 값의 분산을 작게 만듦
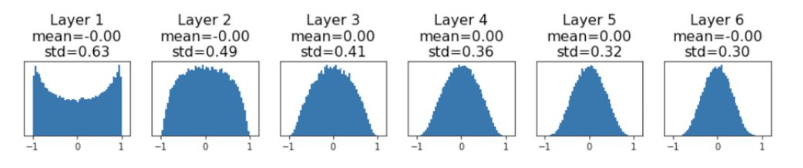 해당 layer의 variance of input에 variance of output을 맞추어 weight initialize 함
해당 layer의 variance of input에 variance of output을 맞추어 weight initialize 함
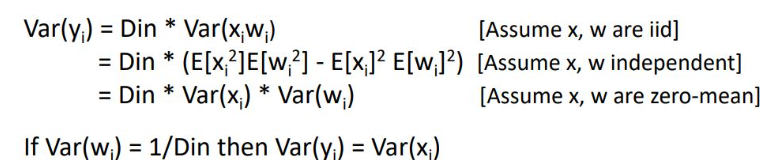
하지만, ReLU에서 문제 발생

ReLU는 데이터 negative 분포를 날려버리는 문제점

deep layer로 갈수록 분포가 0에 수렴하게 되고 마찬가지로 학습이 잘 되지 않게 됨
(3) Kaiming initialization

input에서 절반이 날아가버린것을 보정하기 위해 sqrt term안에 2를 곱해서 0으로 모이지 않게 함
ex) ResNet에서 initialize 하는 방법
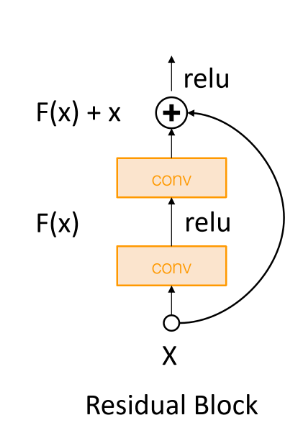 ResNet에서는 +블럭을 지날 때 마다 variance가 커짐
ResNet에서는 +블럭을 지날 때 마다 variance가 커짐
따라서, 첫번째 conv 레이어는 kaming initialization을 사용하고, 두번째 conv 레이어는 weight을 0으로 만들어 variance커지는것 방지
4. Regularization
overfitting 문제를 해결하기 위해 도입
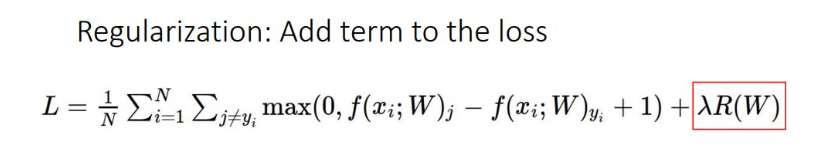 이전에 다뤘던 위의 식에 L1, L2를 선택하여 사용하였었음
이전에 다뤘던 위의 식에 L1, L2를 선택하여 사용하였었음
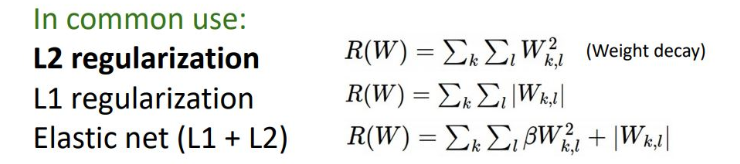
L2가 보통 사용되며, loss function에 regularization term을 추가하여 weights이 취할 수 있는 영역에 제한을 두어 training 방해
DropOut
학습 시 랜덤하게 노드를 삭제하여 overfitting 방지하는 방법
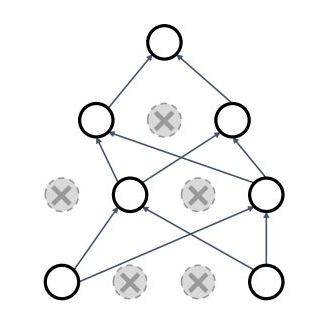
해석1) 여러 neural network 앙상블 트레이닝 과정으로 submodel들 중 정확도가 높은것을 결정
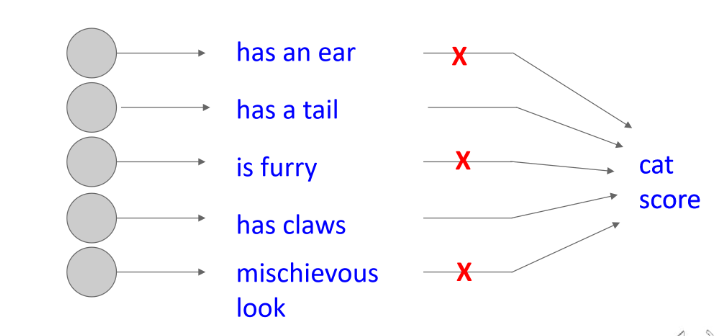
해석2) Randomness를 통해 모든 feature를 학습하지 않고, 같은 것을 배우는것을 방지
하지만, test 과정에서 dropout을 적용하면 output이 달라짐
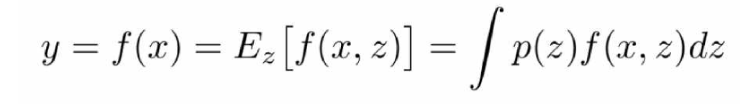
모든 노드를 켜고, output을 z에 대한 expectation으로 보면 위와 같은 식으로 나타남
-> 하지만 실제 구현상에서는 integral 계산이 매우 힘들기 때문에 approximation 진행
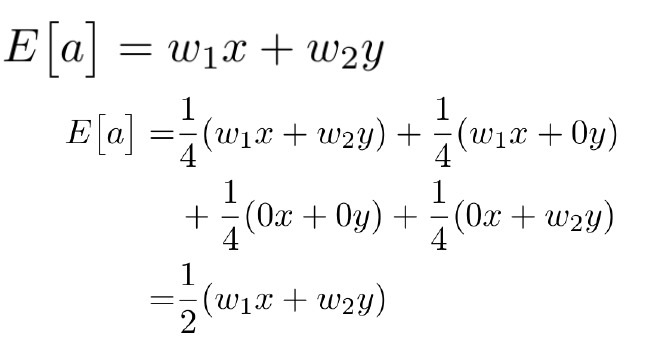
w1과 w2를 켜고 끄는 경우의수와 확률값을 곱하면, 결국 E[a]값에 probability를 곱하게 됨

직관적으로, Train과 Test의 Scale값이 같아지기 위해 중간중간 p를 곱해 scailing을 해 줌을 알 수 있다.
Inverted dropout
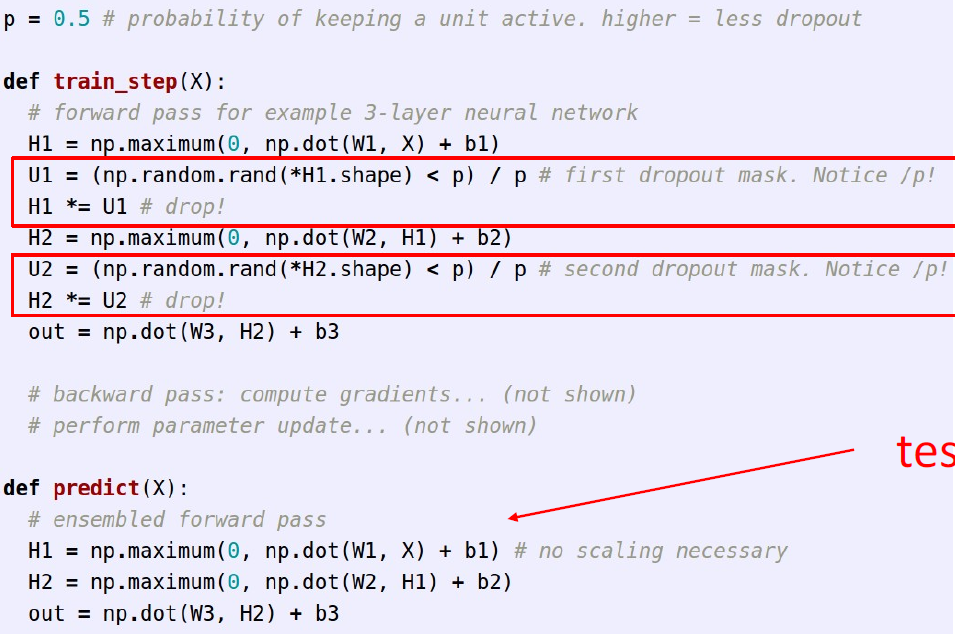 Test시 p로 스케일링 되는 것이 불편하다면, train 과정에서 p로 나누어줘 역으로 스케일링 하는 방법으로, 좀더 보편적
Test시 p로 스케일링 되는 것이 불편하다면, train 과정에서 p로 나누어줘 역으로 스케일링 하는 방법으로, 좀더 보편적
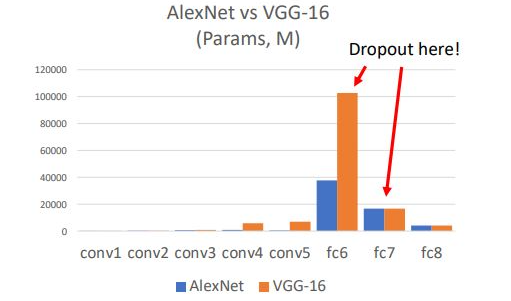 AlexNet 혹은 VggNet에서 많은 parameter들이 사용되는 fc layer에서 dropout을 사용함
AlexNet 혹은 VggNet에서 많은 parameter들이 사용되는 fc layer에서 dropout을 사용함
비교적 최근 GoogleNet, ResNet 에서는 fc layer 대신 global pooling layer를 사용하기 때문에 사용하지 않음
*overfiitng 이 생기는 이유가 결국 많은 hidden layer의 parameter 수가 많기 때문인데 size가 작은 layer에서는 dropout을 사용하지 않음
Regularization Pattern
Dropout은 Randomness를 추가하여 방해함
z는 주로 랜덤 noise를 의미
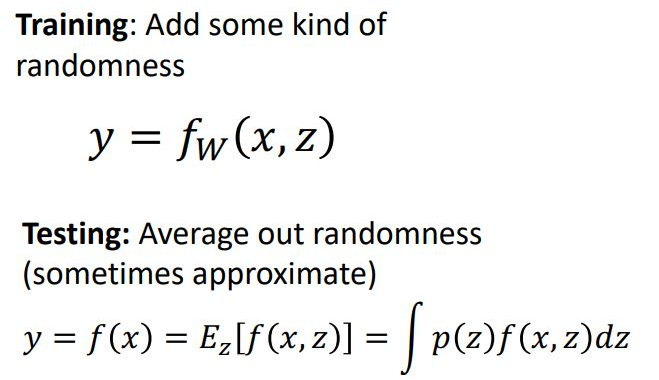
training 시에 시스템에 randomness를 부여하고, test시에는 deterministic하기 위해 randomness를 average out하는 것이 regularization의 pattern
Batch Normalization
mini-batch는 shuffle 되기 때문에 기본적으로 randomness가 추가됨
Batch normalization의 test 시에는 exponentially weighted average vector를 사용하여 randomness를 average out시켜주는 형태임
-> ResNet과 같은 최근의 아키텍쳐에서는 dropout 대신에 L2 weight decay를 사용하여 Batch Normalization을 통해 randomness를 부여
Data Augmentation
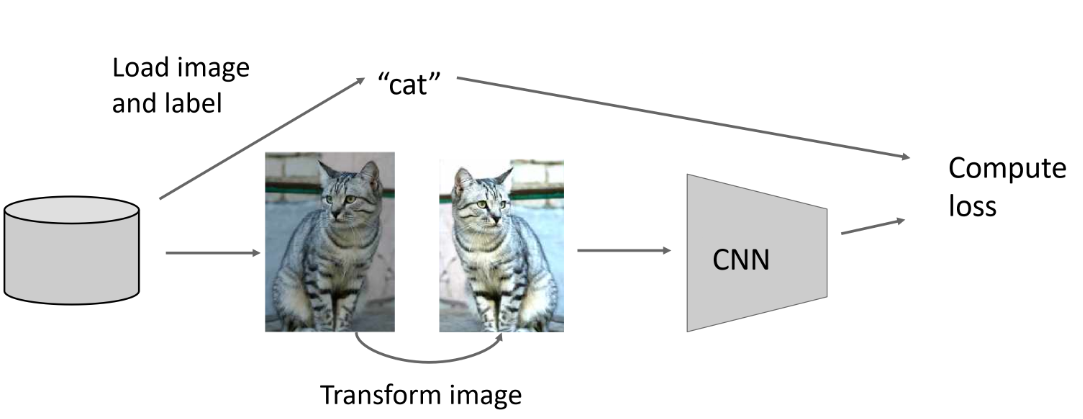 밝기 조절 혹은 좌우 대칭과 같은 transform randomness를 통해 이미지를 augmentation
밝기 조절 혹은 좌우 대칭과 같은 transform randomness를 통해 이미지를 augmentation

Image를 random하게 crop, scale하여 augemtation하기도 하며, test-time에서는 이미지 세트를 average시키는 형태로 진행함
Color jitter
 RGB pixel에 대해 PCA를 진행하여 조도를 조절하는 방법
RGB pixel에 대해 PCA를 진행하여 조도를 조절하는 방법
DropConnect
Weight에 random으로 zero를 취해주는 방식
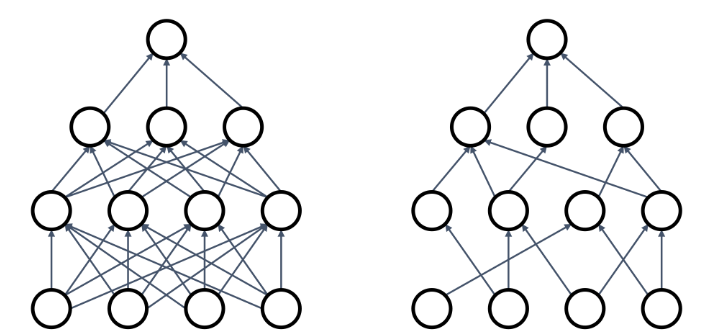
Fractal Max Pooling

Network에 pooling layer에서 receptive field의 size에 randomize를 적용하는 방식으로, Training시 pooling layer에서 kernel size를 2x2 or 1x1 등으로 랜덤으로 취하고 test시 prediction을 averaging 취해서 적용시키는 방식
Stochastic Depth
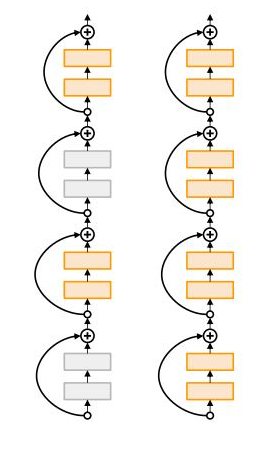
ResNet에서 사용되는 regularization으로 residual block을 skip하는 형태로 randomness 부여
Cutout
 이미지에 일정한 region을 zero로 만들어 randomness 부여하는 방식
이미지에 일정한 region을 zero로 만들어 randomness 부여하는 방식
test시에는 whole 이미지를 사용
MixUp
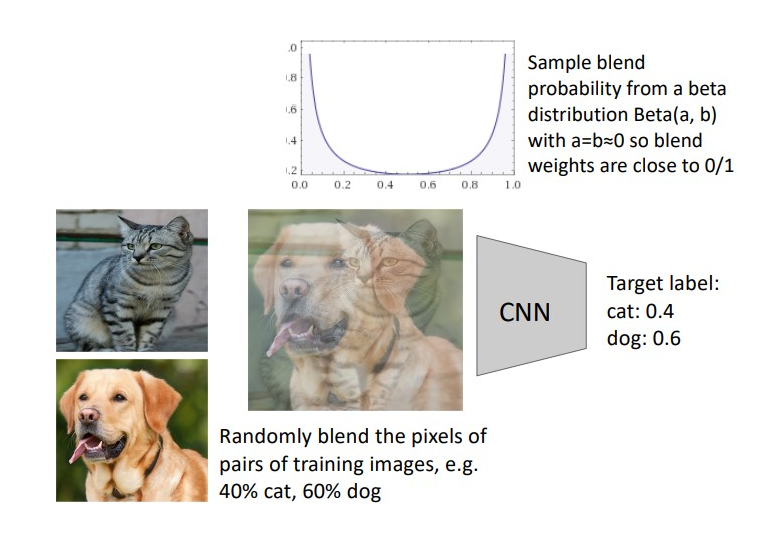 라벨별 training image를 랜덤한 비율로 blend 시키고, sample은 beta distribution을 통해 확률이 결정됨
라벨별 training image를 랜덤한 비율로 blend 시키고, sample은 beta distribution을 통해 확률이 결정됨
Discussion
아주 큰 FC 레이어인 경우 Dropout을 택하는 것을 추천
Batch Normalization과 Data Augmentation은 항상 추천
Cutout과 mixup은 아주 작은 dataset의 classification을 하는 것을 추천
