1. Learning Rate Schedules
시간에 따라 learning rate를 변경시키는 것을 learning rate schdule이라고 함
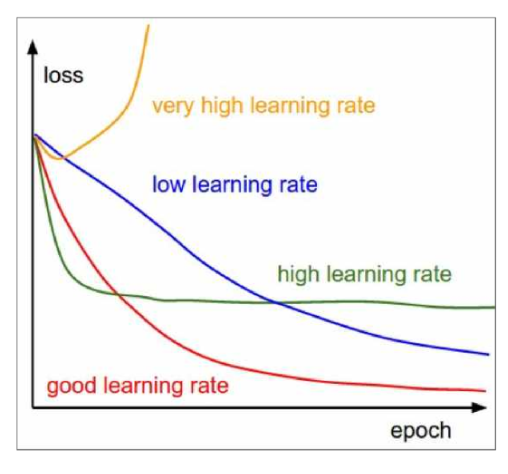
좋은 learning rate 는 큰 값에서 시작해서 epoch이 지나면서 learning rate를 decay 시키는 것
1.1 Step schedule
일정 고정된 epoch에서 decay시켜주는 것
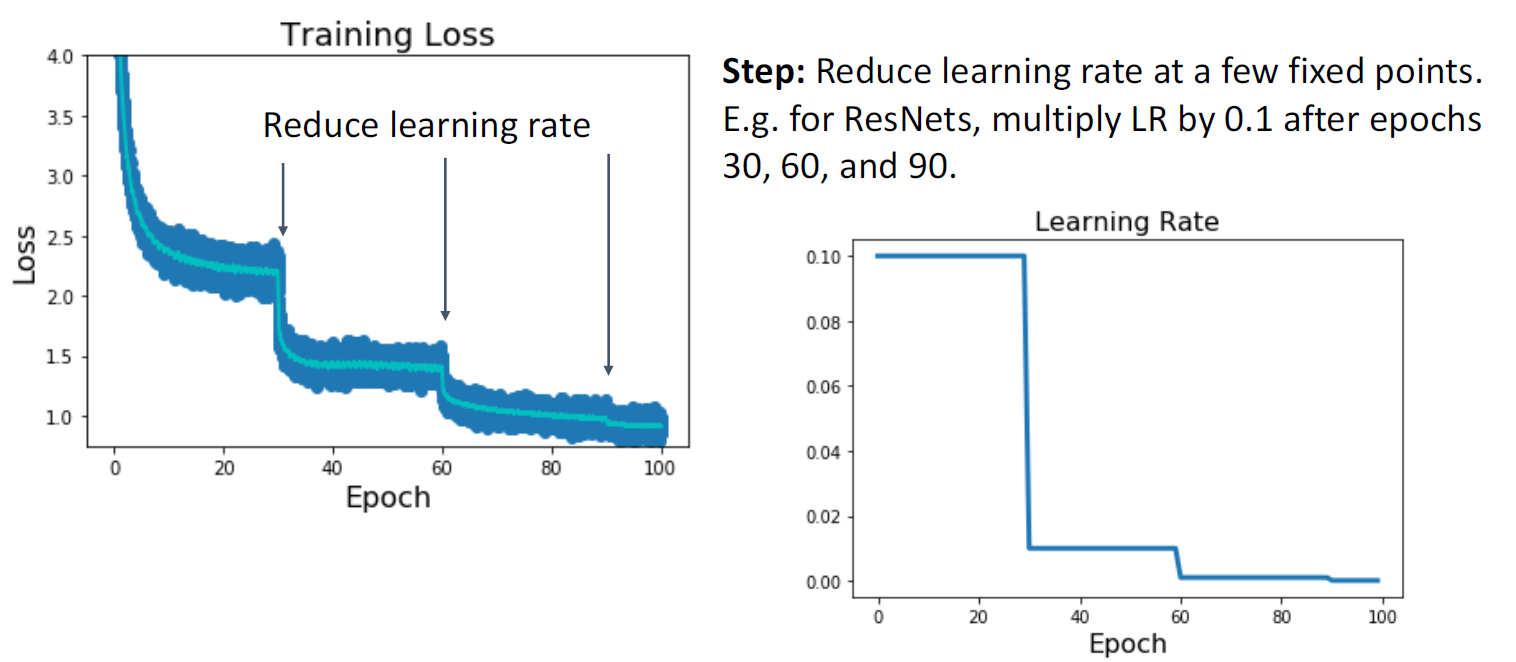 Epoch 간격, step의 learning rate decay 값 등 새로운 hyperparameter가 추가되는 문제가 있음
Epoch 간격, step의 learning rate decay 값 등 새로운 hyperparameter가 추가되는 문제가 있음
1.2 Cosine Schedule
Decay rate이나 epoch 간격을 설정해 줄 필요 없이 공식에 따라 learning rate를 decay시킴
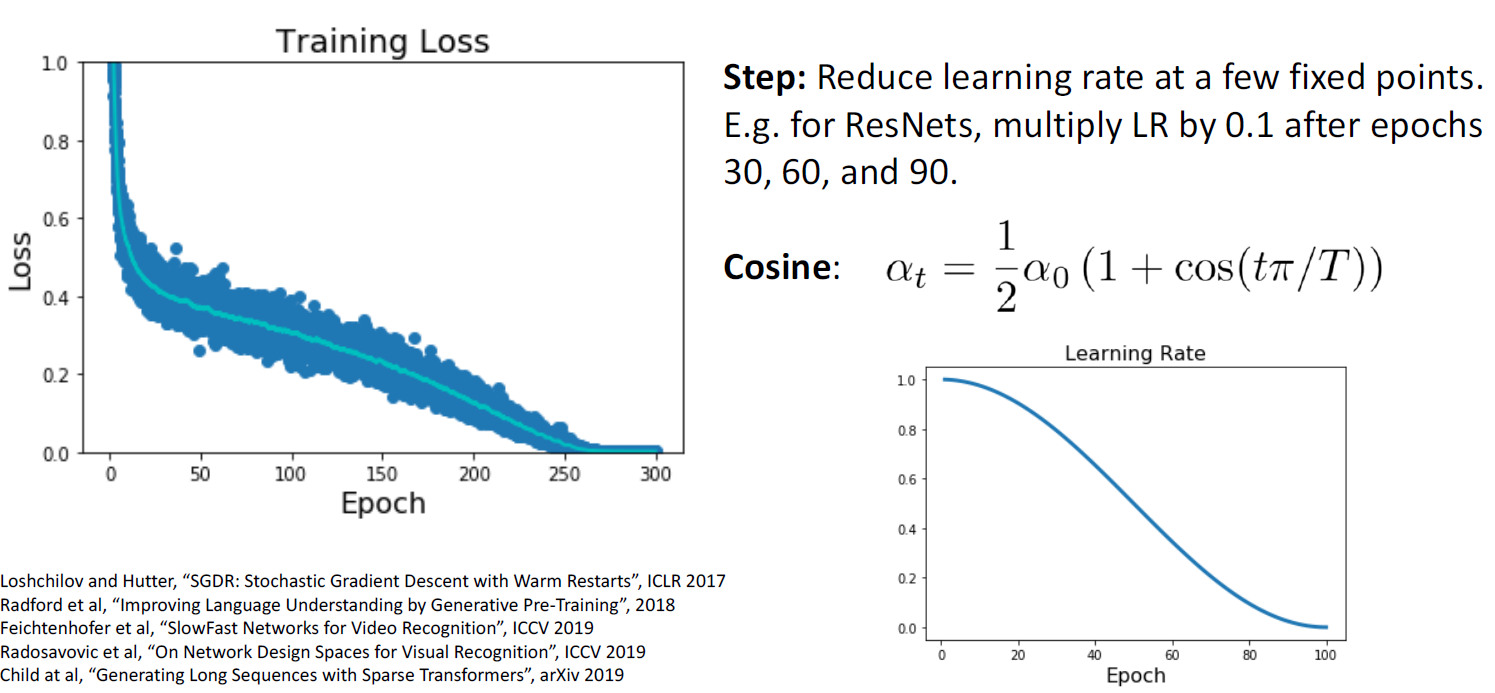
Hyperparameter가 두개로, initial learning rate인 a0와 epoch 수를 결정할 T
-> Hyperparameter 수가 작기 때문에 최근에 많이 사용되고 있음
1.3 Linear schedule
일정 slope를 따라 일정하게 decay 함
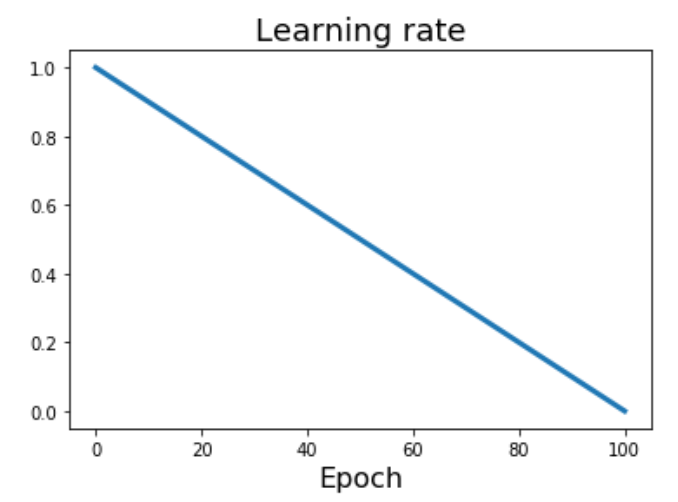
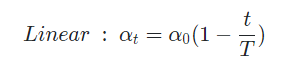
-> Cosine과 함께 최근 많이 사용
1.4 Inverse Sqrt schedule
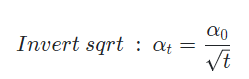
많이 사용하지는 않음
1.5 Constant schedule
가장 흔히 사용하는 방법
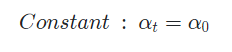
복잡한 learning rate schedule에 비해 model에 따라 성능이 좋을수도, 나쁠 수도 있음
Adam & RmsProp등의 기법을 사용할 때에는 learning rate decay가 중요하지 않아 constant를 사용하기도 함
2. Early Stopping
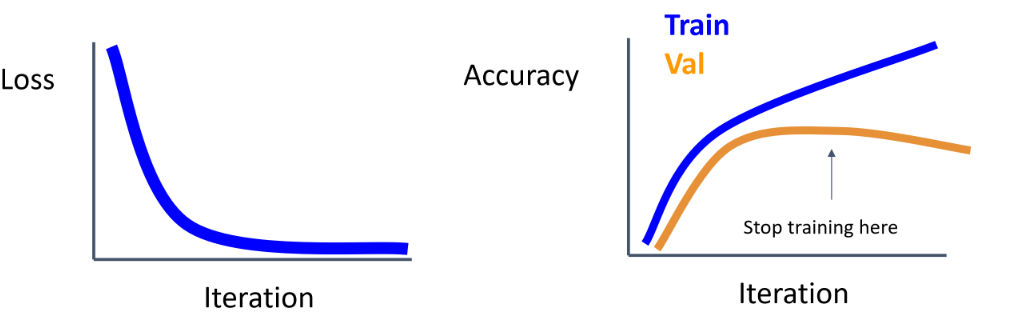
Validation Accuracy가 overfitting 으로 인해 낮아지기 시작할 때 check point를 불러와 모델로 채택함
3. Choosing Hyperparameter
3.1 Grid Search
Hyperparameter의 모든 가능한 경우의 수를 비교 하는 것을 grid search라고 함
3.2 Random Search
일정 범위 내에서 random하게 뽑아 대입하는 과정을 반복
-> 많은 different trials 가 필요함
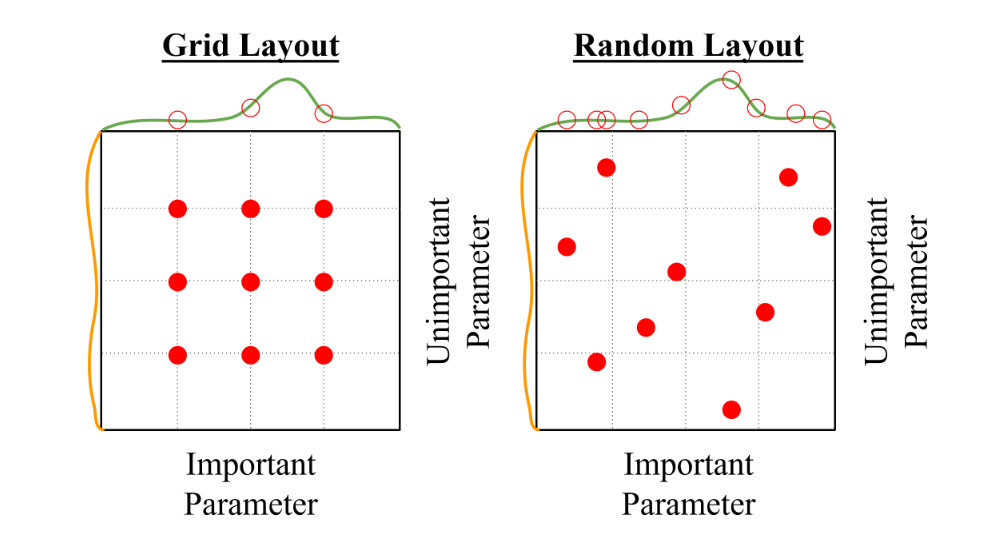
Grid search는 discrete 하게 일정 부분만 탐색이 가능하지만, Random search는 여러 다양한 지점을 탐색할 수 있어 좋은 성능의 지점을 고를 확률이 높아짐
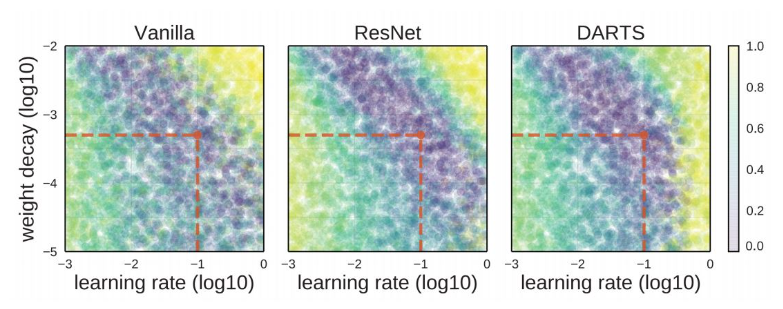
하지만, random search 방법을 통해 많은 hyperparameter 중 최적값을 찾는 것은 GPU 자원을 너무 많이 소모하기 때문에 사용하지 않음
-> 한정된 GPU 자원을 활용한 체계적인 방식으로 hyperparameter 구함
3.3 Hyperparameter tuning process
-
Check initial loss
Weight decay를 사용하지 않고 맨 처음 loss값을 확인함
ex) softmax에서 첫 loss값이 logC가 아니면, 오류가 있는 것 -
Overfit small sample
Regularization 사용하지 않고 5~10정도의 mini-batch로 크기가 작은 데이터셋에 대해 100% train accuracy가 나오도록 학습
작은 set에서 optimization 과정이 잟 되는지 보는 과정
-> 이때 overfit 되지 않는다면, 실제 training set에서 fitting 되지 않을 것임 -
Find Learning Rate that makes loss go down
Step2 에서의 아키텍처에 weight decay를 활용하여 모든 train dataset에 대해 100 iteration train 시켜서, loss가 가장 높게 떨어지는 Learning rate를 찾음
*시도할만한 learning rate : 1e-1, 1e-2, 1e-3, 1e-4
시도할만한 weight decay : 1e-4, 1e-5, 0 -
Coarse grid, train for ~1-5 epochs
몇 개의 모델에 대해 learning rate와 weight deacay를 적용해 1~5의 epoch를 학습하여 좋은 parameter 정함 -
Refine grid, train longer
가장 괜찮은 모델에 대해 learning rate decay는 사용하지 않고, 10~20 epoch정도 학습시킴 -
Look at learning curve
러닝 커브를 그려보고
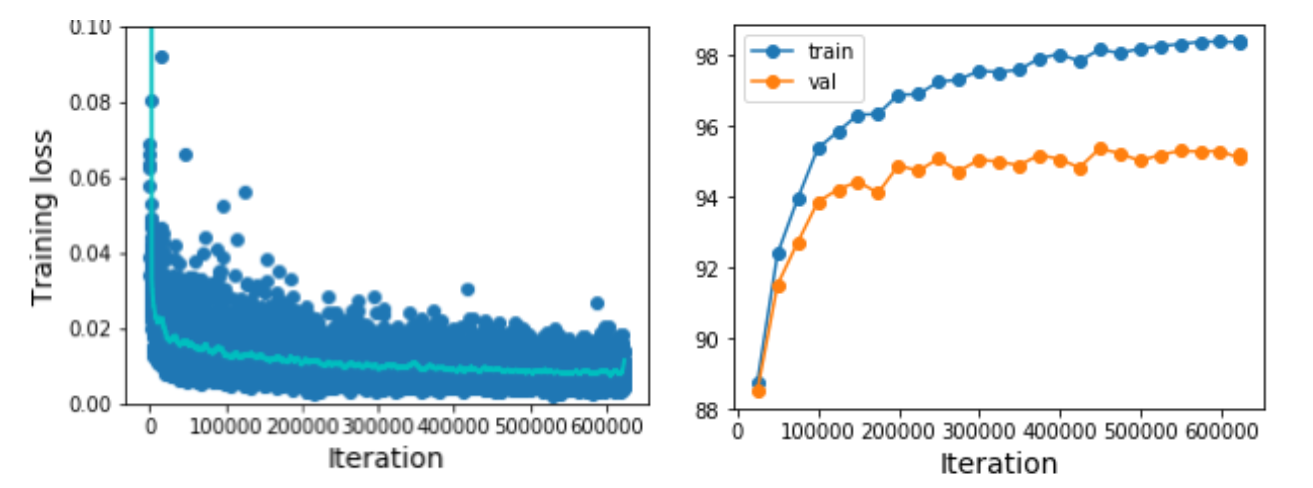 왼쪽 그림과 같이 모든 loss 값을 scatter plot으로 나타내면 noisy
왼쪽 그림과 같이 모든 loss 값을 scatter plot으로 나타내면 noisy
오른쪽 그래프와 같이 loss에 moving average 적용하여 trend 살펴봄
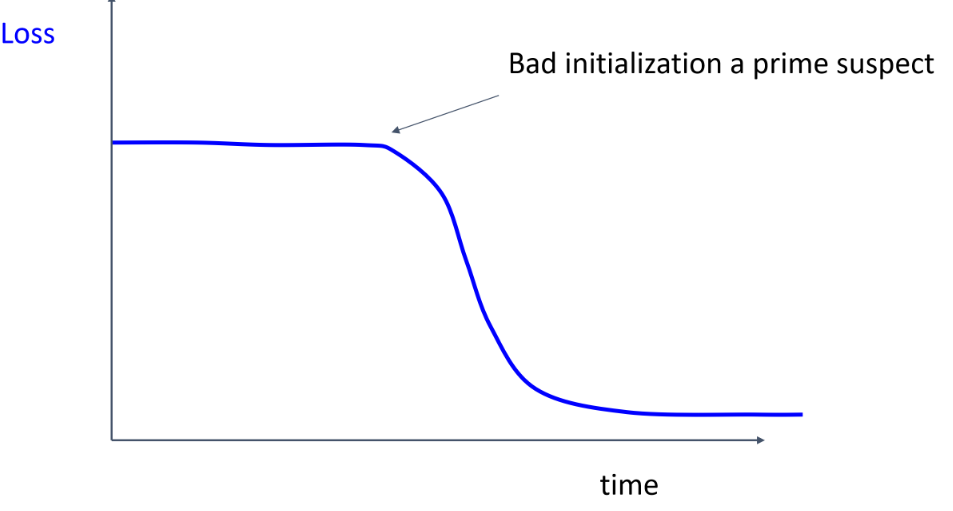
Loss가 평평하다가 갑자기 감소하면, weight initialization이 좋지 못한 것
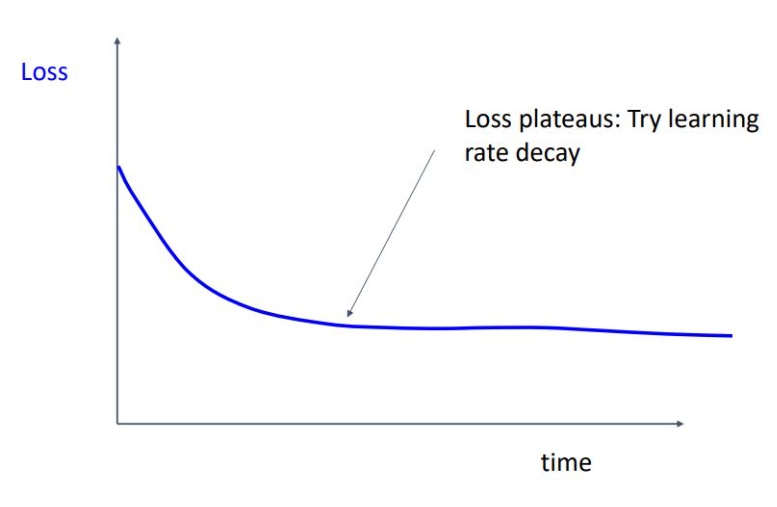
Loss가 감소하다가 더 떨어질 가능성이 있다면 Learning rate decay를 시도하면 됨
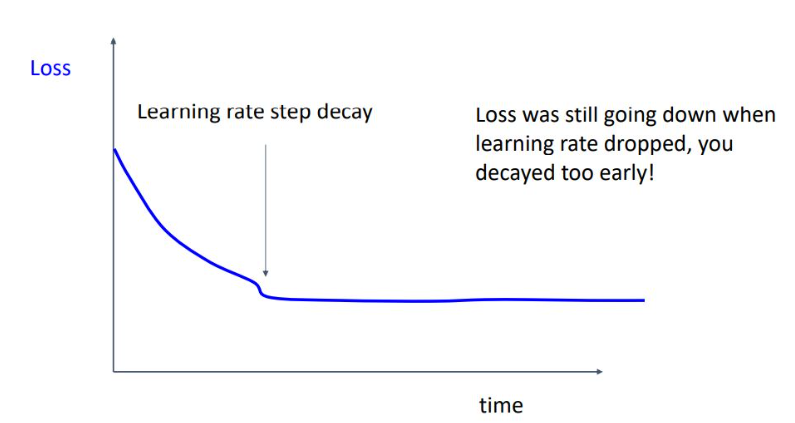
위와 같이 loss가 감소하다가 평평하게 된다면 learning rate decay 너무 빨랐던 것
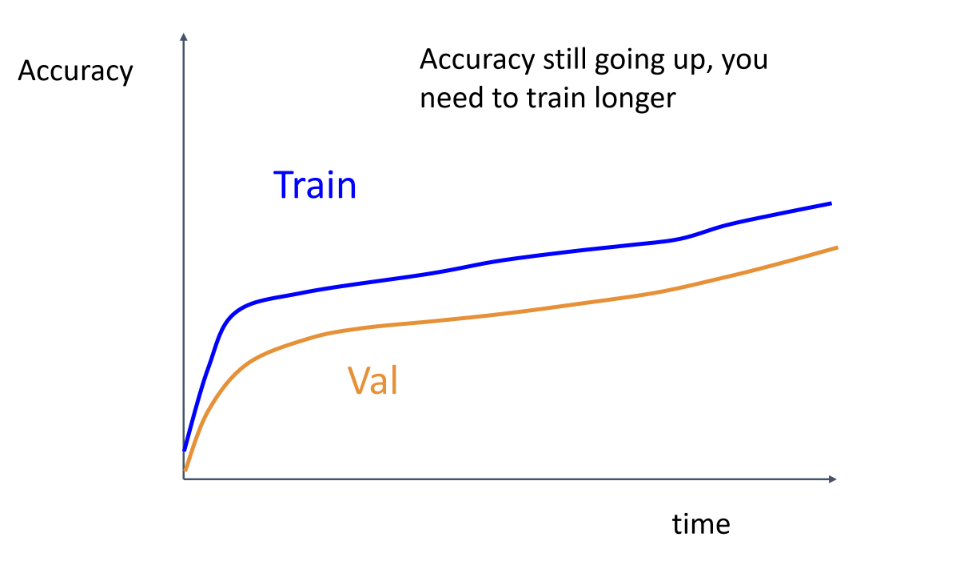
Training 과 validation accuracy가 적당한 간격으로 같이 올라가면 학습이 잘 되고 있다는 뜻
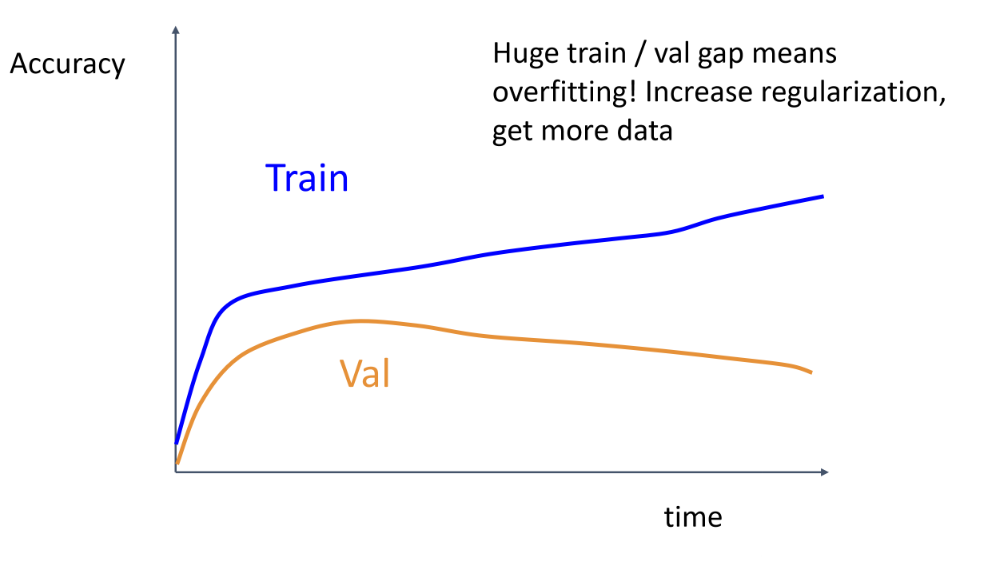
어느 순간 training set의 accuracy만 증가한다면, overfitting을 의미함
-> 해결법으로 L2 regularization 크기를 크게 조절(람다 크게 지정 or data augmentation), 데이터를 더 모으는 방법이 있음
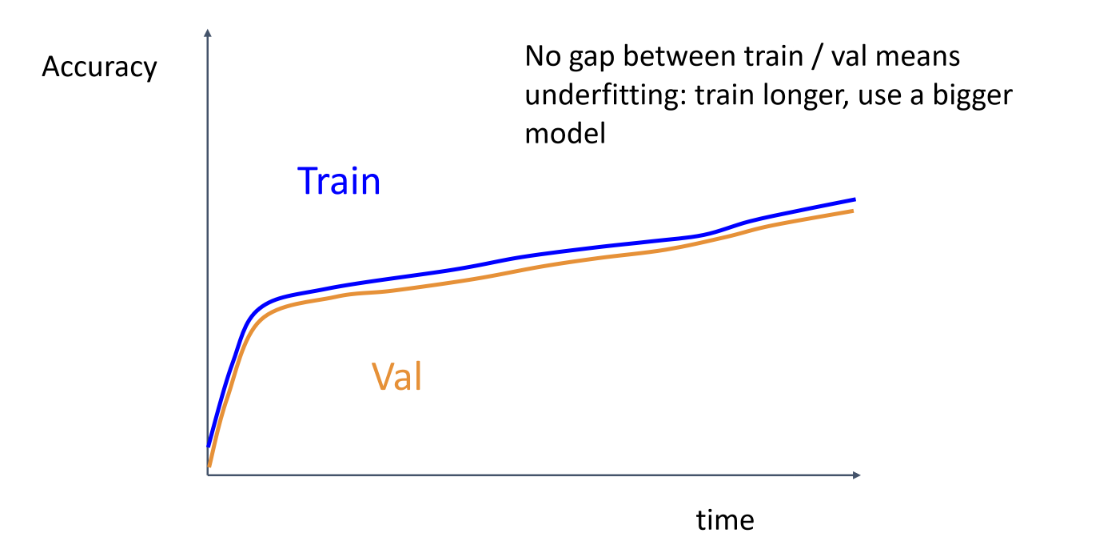
Train과 validation accuracy가 gap이 좁고 같이 올라가면 underfitting을 의심해야 함 -
Goback to step5
Loss curve 해석을 통해 step5로 돌아가 hyperparameter를 다시 설정하고 loss curve를 그리는 과정을 반복하여 최적의 모델 선정
4. Model Ensembles
여러개의 독립적인 모델들을 병렬로 트레이닝 한 뒤, 테스트타임에 결과를 average하고 argmax를 선택
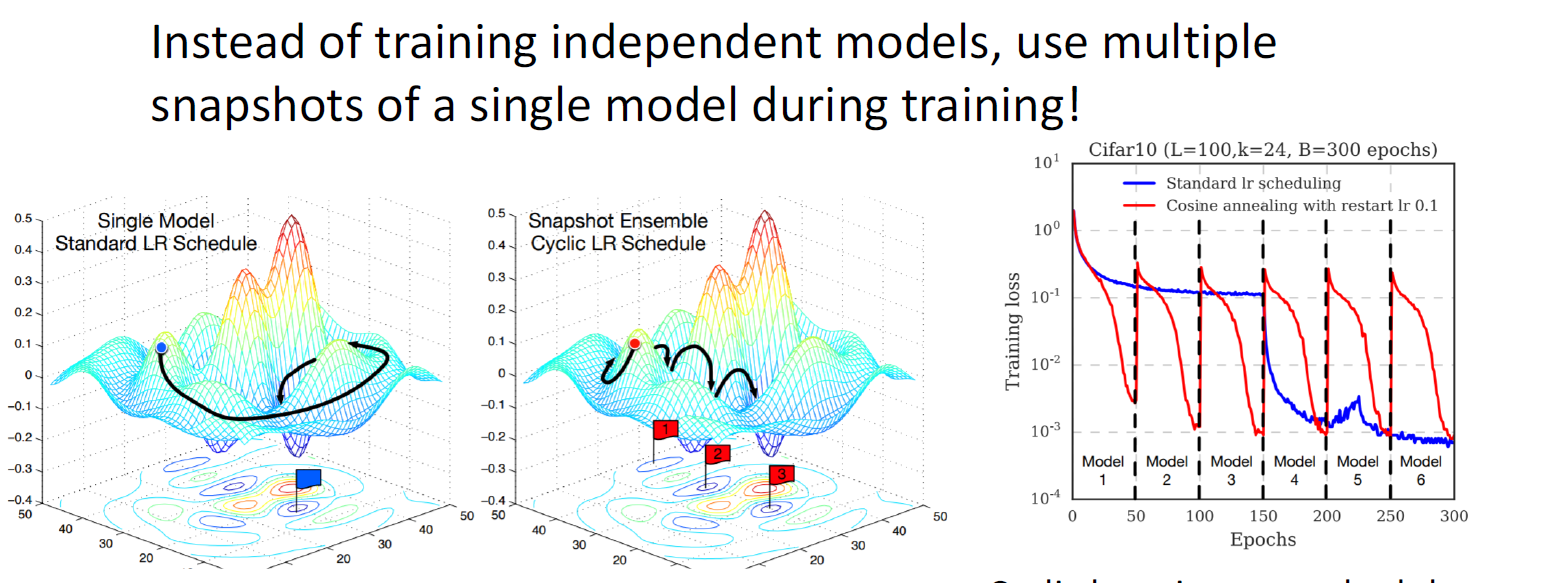
트릭으로 각 독립 모델을 여러개 학습하는 것이 아니라, learning rate schedule을 활용하여 learning rate decay를 준 뒤 특정 시점에 다시 높여주면서 구간별 모델 snapshot을 저장하여 모델 결과를 평균내고, ensemble을 구현
또한, 트레이닝을 끝낸 후의 parameter가 아닌, 트레이닝 시 parameter의 moving average를 테스트에 활용
-> Polyak averaging으로 ensemble효과를 낼 수 있음
5. Transfer Learning
CNN과 같은 deep learning model 학습 시 많은 양의 data가 필요할 것으로 생각되지만, transfer learning을 활용하여 해결가능
ex) AlexNet

1. 앞서 학습된 모델을 가져옴
2.마지막 FC layer는 삭제하고, 직전 layer들의 weight는 freeze하여 업데이트 하지 않음
3. 현재 학습시킬 data의 feature을 추출함
4. 이 feature를 가지고 간단한 linear classifier 에 넣어 학습
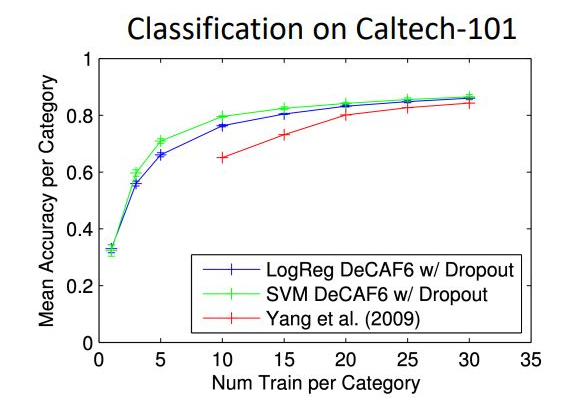
Caltech-101 : dataset의 양이 적음
기존의 dataset만 학습시킨 빨간색 그래프에 비해 transfer learning을 활용한 logistic regressor 와 SVM을 사용하여 train 시킨 모델의 정확도의 차이를 확인 가능
6. Fine Tuning
다운받은 모델의 Weight을 initial weight으로 설정하고, 우리가 가진 dataset으로 훈련시키는 것
이미지가 적을 때에는 feature extraction으로 linear classifier의 간단한 알고리즘으로 마무리 지었다면, 여기서는 모델 weight을 업데이트하여 좋은 성능을 냄

- Feature extraction을 할 때 먼저 transfer learning 을 하게 된다면 baseline 성능이 됨
- 낮은 learning rate를 사용할 것
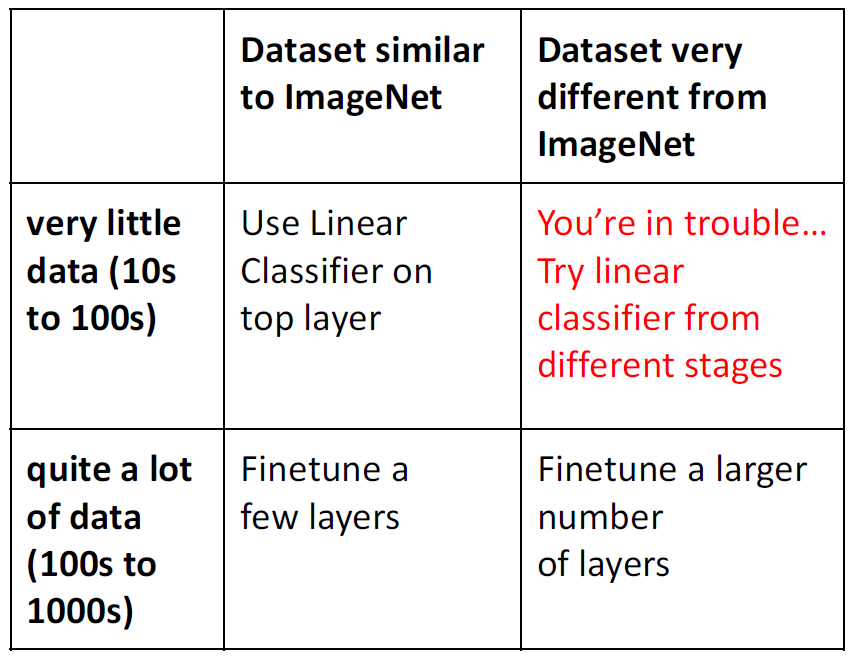
Dataset의 수와 ImageNet과 비슷한지의 여부에 따라 선택할 수 있는 방법은 다음과 같음
-> ImageNet과 다르게 생긴 data가 수 까지 적으면 linear classifier부터 여러 방식을 적용해 볼 것
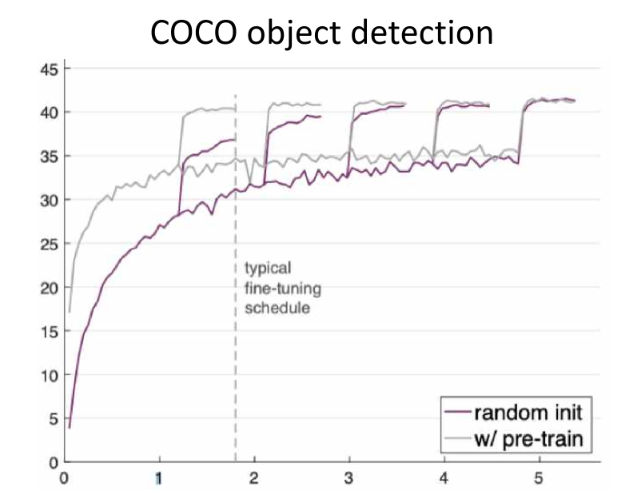
그러나, pretraining 한 것을 transfer learning 한 것이 random initiatiztion으로 training 한 것보다 이론적으로 더 높은 성능을 낸다고 보기는 어려움
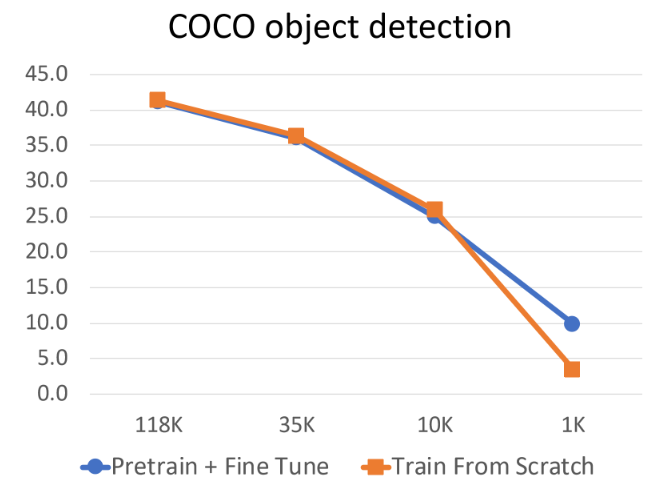
작은 사이즈의 dataset에서는 확실히 trasnfer learning이 효과적이지만, 더 많은 dataset을 확보하는것이 효과적임
6. Distributed training
GPU가 여러개라면 병렬적 학습을 고려
모델 parallelism과 데이터 parallelism 두 가지 방법으로 나뉨
6.1 Model Parallelism
모델 자체를 나누어서 각각의 GPU들이 서로 다른 레이어를 연산하는 것
수직적인 방법
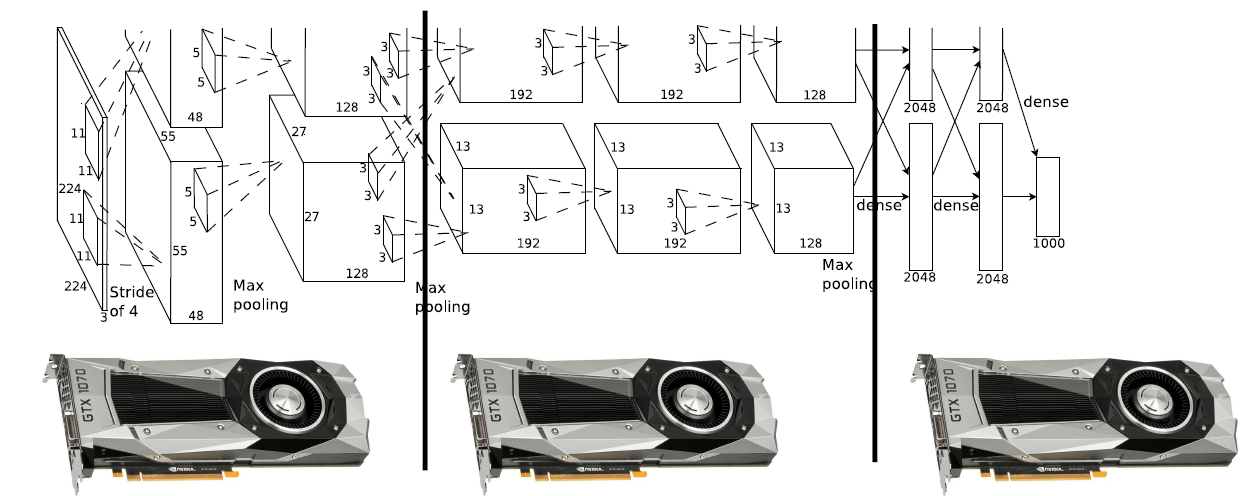
앞 단계의 GPU 연산이 끝날 때 까지 다음 GPU들은 기다려야 하기 때문에 vertical 한 model parallelism은 GPU 자원의 낭비
수평적인 방법

모델의 특정 layer를 parallel하게 나누어서 서로 다른 layer단계들을 학습
-> 윗단 레이어에서 합쳐질 때 layer들 간에 communication과정, 그리고 backpropagation 과정에서 많은 시간 소요됨
6.2 Data Parallelism

같은 모델을 사용하지만, 서로 다른 data를 사용하는 것
똑같은 Weight에 대해 forwardpass를 진행하고, gradient 또한 계산
서로의 gradient를 교환하고, 이를 통해 각자의 parameter를 업데이트 함
-> GPU간 communication은 iteration 한 번마다만 필요하며, gradient만 교환하기 때문에 효율적
*GPU가 여러개가 되더라도 해당 방법 그대로 사용 가능
6.3 Mixed Model & Data Parallelism
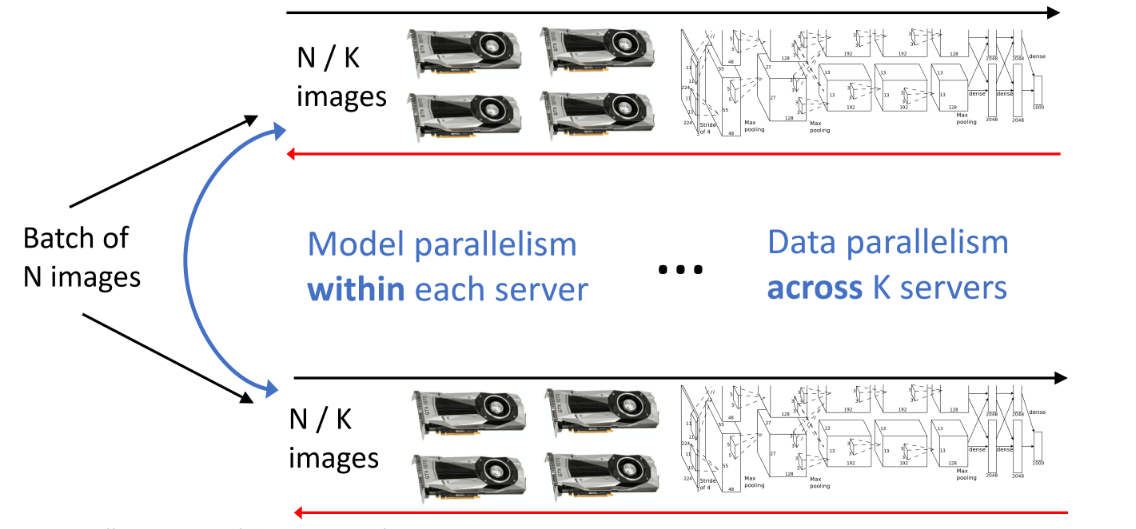
두 가지 parallelism을 모두 활용 가능
6.4 Large-Batch Training
Epoch 수는 똑같이 가져가되, minibatch 사이즈를 키우면 더 적은 iteration으로 1 epoch을 더 빨리 달성할 수 있음
-> Large-batch를 이용하면 더 빨리 모델을 훈련하는 것이 가능
Single GPU일 때 batch size가 N개이고, K개의 GPU의 batch size가 N으로 동일하다면 batch size는 KN임
이때, learning rate도 K배가 늘어나게 설정
처음부터 learning rate가 K배 되면 너무 높기 때문에 schedule을 활용하여 linearly increasing 하는 것을 추천
또한 여러 parameter(weight decay, momentum) 등을 조심해야 하며, batch normalize시에는 각 GPU내부에서만 진행되어야 함
