MODERNTCN: A MODERN PURE CONVOLUTION STRUCTURE FOR GENERAL TIME SERIES ANALYSIS
Abstract
최근 트랜스포머 기반과 MLP 기반의 모델들이 시계열 분석에 널리 활용되는데, conv 기반은 퍼포먼스가 좋지 못했다. 왜 이런지 분석하고 TCN을 최신화해 시계열 태스크에 적합하도록 설계할 것이다. ModernTCN 은 SOTA 퍼포먼스를 보인다.
1. Introduction
convolution 기반의 모델들은 시계열 분석 분야에서 최근 주목을 받지 못했다. 시계열 분석에서 conv 기반의 모델을 사용하는 것은 효율과 퍼포먼스의 밸런스를 제공하는 측면에서 중요하다. 2010년도에는 TCN 기반의 모델들이 주목을 받았지만, 2020년대에서는 트랜스포머와 MLP 기반의 모델들이 퍼포먼스가 비약적으로 증가했다. 특히, global effective fileds(ERFs) 들은 롱텀의 temproal dependency를 잘 잡아 기존의 TCN보다 높은 성능을 보였다.
최근 TCN을 SOTA로 만드려는 노력은 기존의 conv구조를 아주 복잡하게 디자인하는것으로 집중하였는데, conv의 중요성을 무시하였다. 이게 가능한 이유는 ERF의 증가이다.
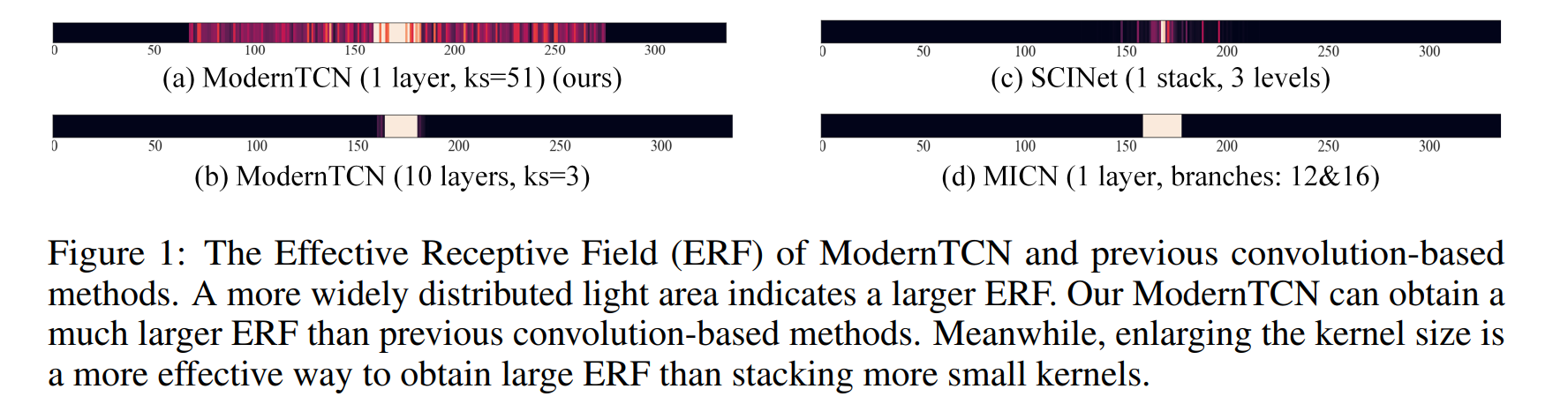
그림에서, EFR가 넓은것은 밝은 점들이 넓게 퍼진것을 의미한다. ModernTCN이 ERF를 기존 conv 모델들보다 더 효과적으로 가져감을 알 수 있다. 또한 모델을 깊게 쌓는것보다 커널 사이즈를 키우는것이 더 효과적이다.
conv는 cross-variable 디펜던시를 캡처하는데 효과적이다. 크로스 variability 는 시계열에서 중요한데, 다변량 시계열 데이터에서 변수간의 의존성을 의미한다. 기존 conv를 이용한 cross-variable 의존성을 고려한 연구의 퍼포먼스가 좋지는 못했지만, cross-variability를 캡처할 수 있음을 보여준다
이들을 통해 우리는 conv 깁반의 모델을 시계열 분석 분야의 궤도에 올려놓고자 한다. 기존의 TCN에 시계열 관련 처리를 통해 시계열 태스크에 적합함을 보인다. modernTCN이 cross-time 과 cross-variable 의존성을 활용할 수 있음을 보인다. 롱텀,숏텀 시계열 예측, imputation, calssification, anomaly detection 총 5가지 태스크에 대해서 분석하였다.
contribution은 다음과 같다.
1. conv 를 시계열에서 어떻게 하면 잘 활용할지에 대한 고찰을 통해 우리의 방법론이 기존 con기반의 모델보다 좋은 퍼포먼스를 보인다.
2. ModernTCN은 SOTA 퍼포먼스를 다양한 시계열 분석 태스크에서 SOTA 퍼포먼스를 보였다.
3. 효율과 퍼포먼스 측면에서 ModernTCN에서 좋은 발란스를 보인다. conv 모델의 효율 중심의 이점을 가져오면서 트랜스포머기반의 모델보다 좋은 SOTA 성능을 보인다.
2. RELATED WORK
2.1 CONVOLUTION IN TIME SERIES ANALYSIS
기존 TCN은 ERFs 의 제한이 있었다. MICN (Wang et al., 2023) 은 causal conv와 멀티 스케일 conv 구조를통해 local과 global correlation을 합쳤다. SCINet은 causal conv의 개념을 없애고, recursive downsample-convolve-interact architecture 을 제안하였다. 이는 시계열을 복잡한 temporal dtnamics로 모델링하였다. 하지만 ERFs의 제한으로 롱텀에 대한 모델링에 어려움이 있었다.
2.2 MODERN CONVOLUTION IN COMPUTER VISION
ViT의 성능을 잡기 위해 modern convolution이 제안되었다. ConvNeXt(Liu et al., 2022d)는 conv 블럭을 트랜스포머와 비슷하게 설계하였다. Global ERF를 잡는 성능을 잡기 위해 RepLKNet(Ding et al., 2022) 은 커널 사이즈를 31x31로 리파라미터 기술을 통해 두었고, SLaK는 커널 사이즈를 51x51로 키워서 2개의 병렬 커널을 다이나믹 sparsity를 두도록 설계했다. 이러한 연구들의 고안하여, 1D conv를 더 시계열 분석 태스크에 적합하게 만들었다.
3 MODERNTCN
3.1 MODERNIZE THE 1D CONVOLUTION BLOCK
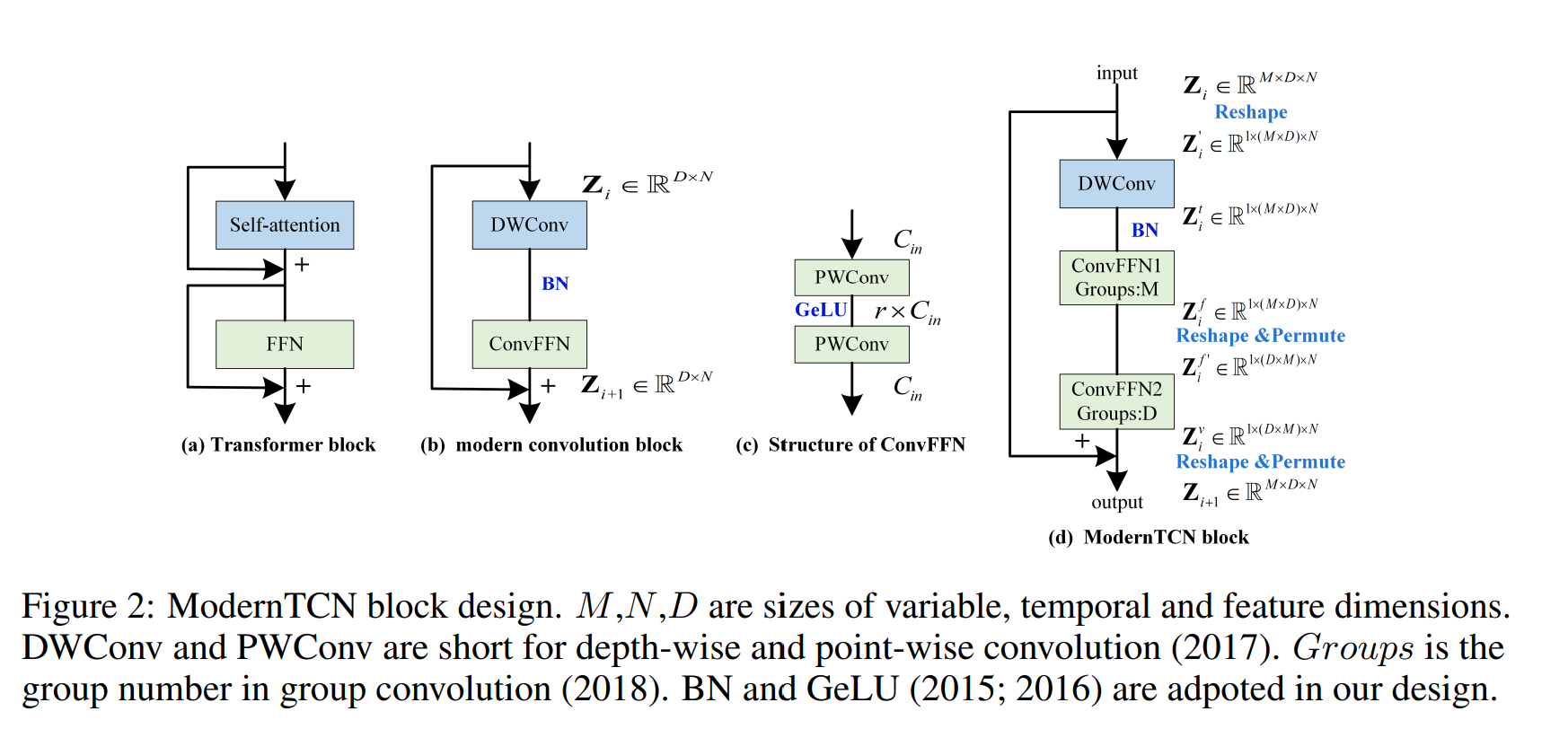
1D conv 블럭을 2.b 와 같이 재디자인 하였다. 여기서 DWConv 는 특질마다의 토큰에 temproal 정보를 얻는 역할을 한다. transformer의 self-attention과 같은 역할이다. ConvFFN은 트랜스포머의 FFN과 비슷한 역할을 하는데, 2개의 PWConvs와 inverted bottleneck 네트워크의 역할을 한다. 이는 인풋 채널보다 r 차원이 넓다. 이 모듈은 각 토큰의 새로운 특질 representation을 개별적으로 학습하는데 도움을 준다.
이 디자인은 temporal과 특질 정보의 mixing을 분리한다. 각 DWConv와 ConvFFN은 하나의 temproal 혹은 특질 차원의 정보를 믹싱하기만 하기 때문에, 이전의 conv는 jointly 각 차원을 믹싱하던것과 다르다. 이 decoupling 은 태스크가 계산 복잡도에서 유리하게 만든다.
이 디자인을 기반으로, 1D conv를 효과적으로 최신화하였다. 그러나 단순히 이런 디자인만으로는 성능 개선이 어렵다. 이 디자인을 시계열 특성을 제대로 고려하지 않았다. 시계열은 다양한 특질 차원과 temproal 차원이 존재하는데, 백본 2.b는 이를 대응하지 못한다. 따라서 다양한 차원에 맞게 수정이 필요하다.
3.2 TIME SERIES RELATED MODIFICATIONS
Maintaining the Variable Dimension
CV에서는 RGB에 맞게 3개의 채널을 D 차원에 벡터에 임베딩하고 믹싱하는데 이는 시계열에 맞지 않다. 시계열에서 변수의 독립성은 RGB 채널보다 더 크다. 단순 임베딩 레이어로는 변수 간의 복잡한 의존성을 학습할 수 없다. 또한 임베딩 디자인은 다양한 차원을 무시하는 결과를 낳기 때문에 cross-variable 의존성에 대한 고려를 못한다. 이 이슈를 해결하기 위해 패치화된 variable-independent 임베딩을 제안한다.
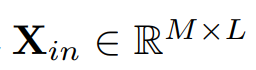
에서, M개의 변수가 있고, 길이가 L인 시계열로 가정한다. N개의 P사이즈의 패치가 패딩으로 생성된다. 패칭 프로세스의 스트라이드는 S이며, 2개의 패치에 대해서는 겹치지 않는 영역의 길이 역할을 한다. 그리고 패치는 D차원의 임베딩 벡터로 변환된다.
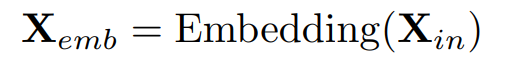
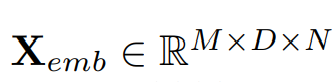
M변수의 D차원의 임베딩벡터가 N개패치로 이루어진 형태다.
unsqueeze 를 하고,
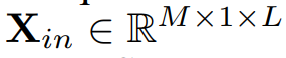
1D conv stem layer에 넣어 1개의 인풋 채널이 D의 아웃풋 패널을 만들도록 한다. 이 과정을 통해 M개의 단변량 시계열이 독립적으로 임베딩 된다. 따라서, 각 변수의 차원은 유지되는 이러한 수정된 구조는 추가적인 변수 차원의 정보를 효과적으로 캡처할수 있도록 한다.
DWConv
DWconv는 temporal 정보를 얻기 위해 제안된 모델이다. 이것은 joint하게 cross-time, cross-variable dependency를 캡처하는데 어려웠다. 따라서 기존의 DWConv를 특질 독립뿐만이 아니라, 특질과 변수 독립으로 만들어서 temproal dependency를 각 단변량 시계열에서 얻도록 한다. 그리고 이것을 큰 커널에 넣어서 ERFs에서 temproal 모델링 능력을 향상시킨다.
ConvFFN
DWConv가 특징과 변수 모두 독립이므로, 이 부분을 보완하기 위해 ConvFFN이 특징과 변수 차원 간의 정보를 혼합한다. 하나의 ConvFFN 레이어만 사용하여 특징과 변수간 의존성을 학습하는 것은 계산 비용이 높고 성능이 좋지 않다. 그룹화된 PWConv (pointwise conv)를 통해 2개의 모듈로 분해해서 ConvFFN1 ConvFFN2 로 분리한다. 이때 각 모듈에 다른 그룹 수를 설정한다. ConvFFN1 은 변수당 새로운 특질 표현을 학습하는 역할을 담당하고, ConvFFN2는 특질당 변수 간 의존성을 포착하는 역할을 담당한다.
따라서, Fig2. d처럼 ModernTCN 블럭을 만든다. DWConv는 temporal 정보를 mix하고, ConvFFN1, ConvFFN2 는 특질과 변수 차원을 믹스한다.
3.3 OVERALL STRUCTURE
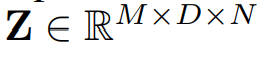
Z 벡터는 위와 같은 차원을 가지며, 다음과 같은 수식으로 나타난다.
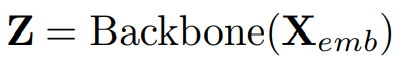
각 ModernTCN 블럭은 residual way로 구성되었기 때문에 다음과 같은 수식으로 i번째 블럭이 나타난다.

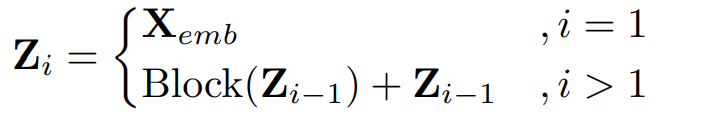
4 EXPERIMENTS
Baselines
Transformer-based models: PatchTST (2023), Crossformer (2023), FEDformer (2022)
MLPbased models: MTS-Mixer (2023b), LightTS (2022), DLinear (2022), RLinear and RMLP (2023a)
Convolution-based Model: TimesNet (2023), MICN (2023) and SCINet (2022a).
Main Results
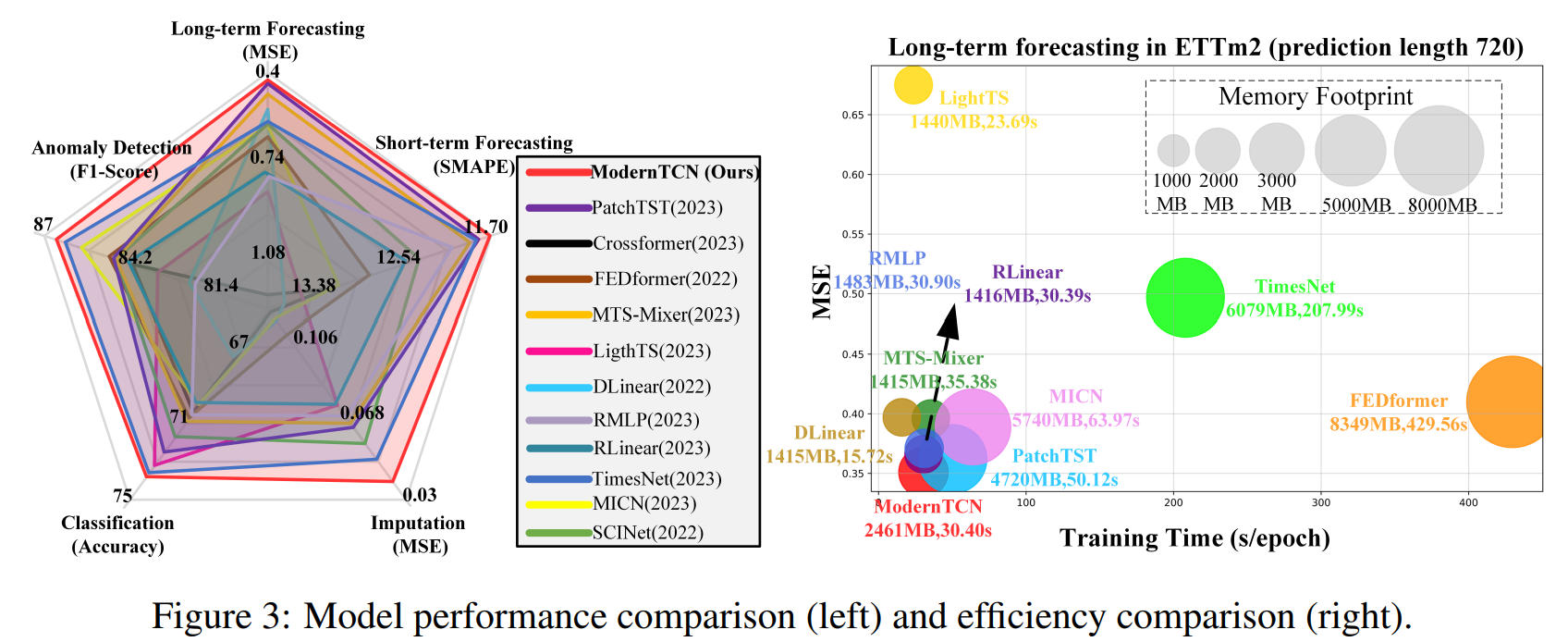
ModernTCN은 개의 매인스트림 분석에서 SOTA 퍼포먼스를 높은 효율로 보였다.
4.1 LONG-TERM FORECASTING
Setups
Weather (Wetterstation), Traffic (PeMS), Electricity (UCI), Exchange (Lai et al., 2018a), ILI (CDC) and 4 ETT datasets (Zhou et al., 2021). Following (Nie et al., 2023; Zhang & Yan, 2023) 데이터에 대해서 평가하였음
Results

전체적으로 아주 좋은 성능을 보였음. 롱텀 시계열 예측 태스크에서 메모리효율적이며 성능도 좋음.
4.2 SHORT-TERM FORECASTING
Setups
Following (Wu et al., 2023)에서 c Mean Absolute Percentage Error (SMAPE), Mean Absolute Scaled Error (MASE) and Overall Weighted Average (OWA) 측정.
Results
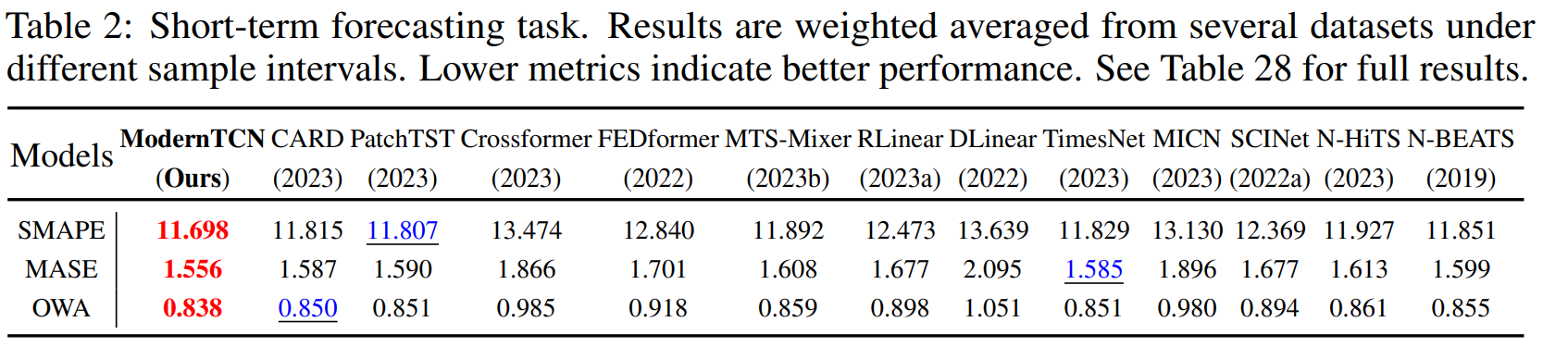
숏텀에서도 SOTA성능을 보였음
4.3 IMPUTATION
Setups
Following (Wu et al., 2023), ETT (Zhou et al., 2021), Electricity (UCI) and
Weather (Wetterstation) 에서 랜덤마스크 비율 {12.5%, 25%, 37.5%, 50%} 설정
Results

마찬가지로 SOTA 성능을 보였음. 특히 cross-variabl이 imputataion 태스크에서 중요한 역할을 하기 때문에 성능이 좋음을 알 수 있다. missing 변수와 남아있는 변수간의 관계를 통해 복원하는데 도움을 주기 때문이다.
4.4 CLASSIFICATION AND ANOMALY DETECTION
Setups
10개의 다변량 데이터를 사용하였다.
Results
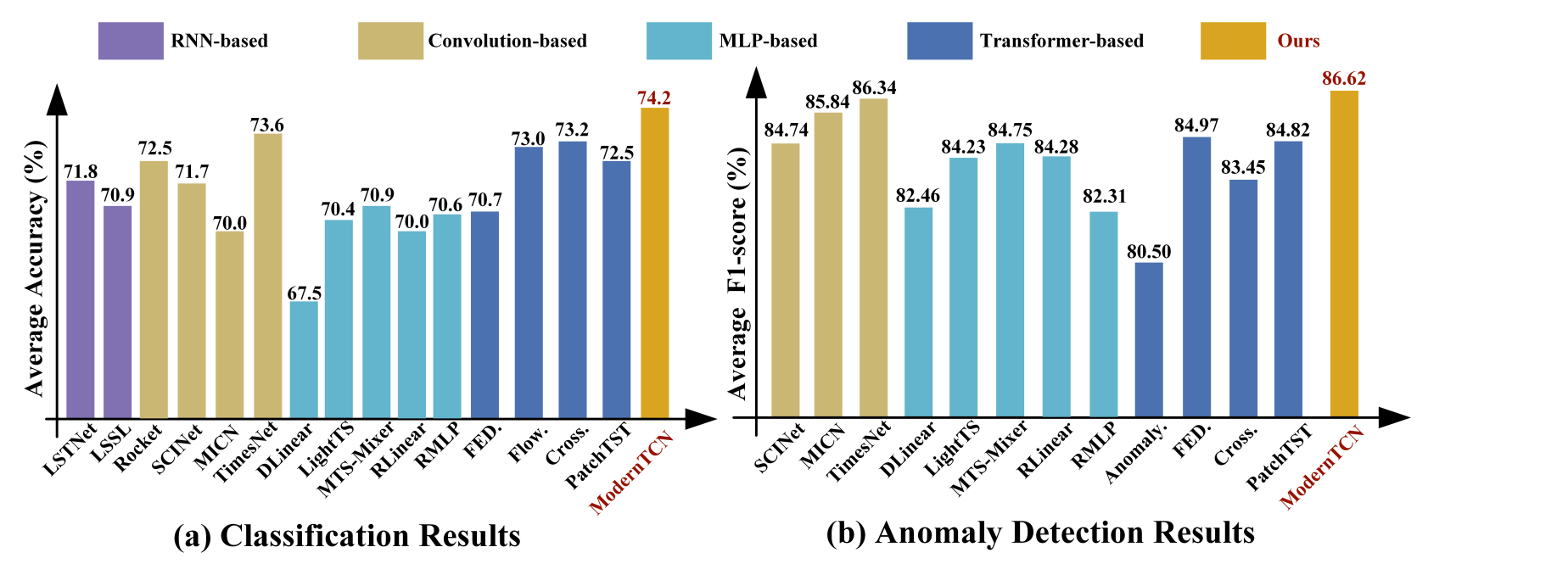
두 태스크 다 SOTA 퍼포먼스 달성하였음
5 MODEL ANALYSIS
5.1 COMPREHENSIVE COMPARISON OF PERFORMANCE AND EFFICIENCY
Summary of Experimental Results : 제안 방법론이 SOTA 퍼포먼스를 5개의 태스크에서 달성함을 확인하였음. 이는 task에 대한 일반화 성능이 높으며 conv가 시계열 분석에서 효과가 있음을 보였다. 제안 방법론은 퍼포먼스 뿐 아니라, 효율측면에서 효과가 좋다. 또한 기존의 conv 방법론보다 훨씬 큰 마진으로 성능의 향상을 이루어냈다.
Compared with Transformer-based and MLP-based Models : 퍼포먼스와 효율을 모두 고려하자면, ModernTCN이 시계열분석에서 효율적이다.
Compared with TimesNet (2023) : TimesNet이 5개의 메인스트림태스크에서 우수한 성능을 보였었다. 이 모델또한 conv 기반의 모델이고, CV의 발전에 따라 시계열에 적용한 방법이다. 하지만 목적을 달성하는 방법이 달랐다. TimesNet은 1D 시계열을 2D 공간으로 전이하였고, 시계열을 2D ConvNets 인 CV 방법론으로 수행하였다. 그렇기 때문에 추가적인 메모리와 리소스를 요구한다. 하지만 우리의 제안 방법론은 시계열을 특징을 통한 1D conv를 수행하고 추가적인 모듈이 존재하지 않는다. 그러므로, 더 효율이 좋으며 퍼포먼스가 좋을수 밖에 없다.
5.2 ANALYSIS OF EFFECTIVE RECEPTIVE FIELD (ERF)
제안 방법론은 커널 사이즈를 높이며 ERF가 높아졌는데, 다음 수식에 따르면 커널 사이즈에 비례하며, 레이어 사이즈에는 루트에 비례한다.

따라서 커널사이즈를 키우는것이 퍼포먼스 확장에 유리하다.
이전 Conv 연구에서는 복잡한 구조를 통해서 ERF를 늘렸는데, 이것은 pure conv 구조가 아닐 뿐더러, ERF를 분석하기 힘들다. Fig.1 과 같이 우리의 방법론은 기존의 연구들보다 더 좋은 ERF를 가지고 이는 좋은 퍼포먼스로 이어진다.
5.3 ABLATION STUDY
Ablation of ModernTCN Block Design

다음과 같이 각 모듈들을 제외하면 성능이 떨어지는 것을 볼 수 있다.
Ablation of Cross-variable Component
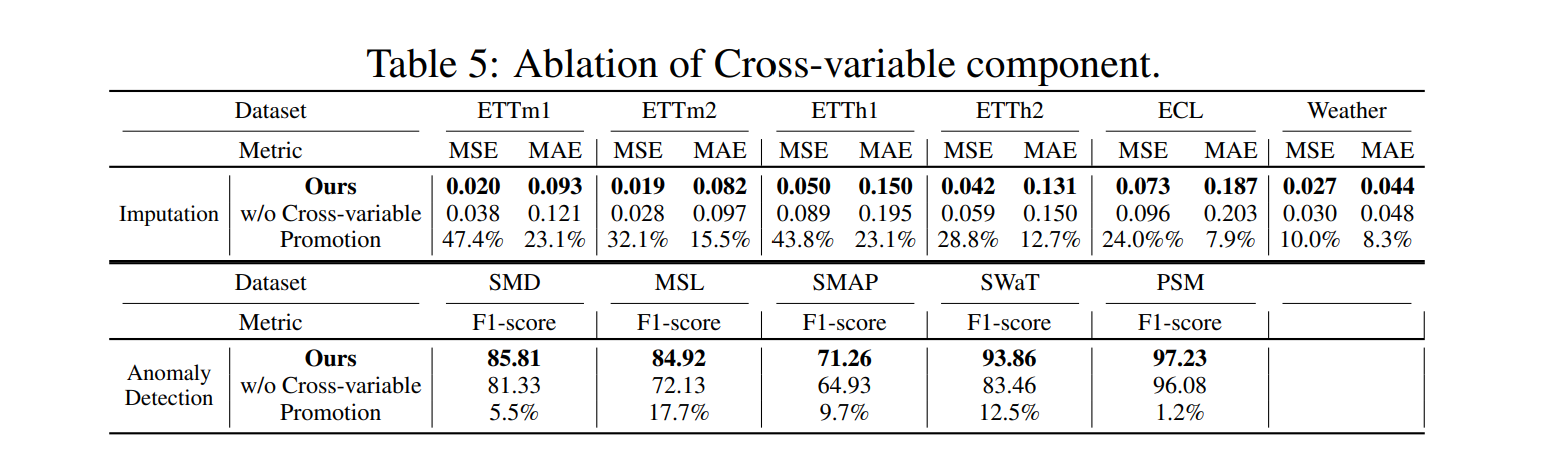
제안 방법론의 ConvFFN2 cross-variable 컴포넌트의 역할이 중요한 역할을 차지하는지 확인하기 위해 실험을 진행하였다. ConvFFN2 없이는 성능 저하가 일어났다.
6 CONCLUSION AND FUTURE WORK
제안 방법론은 convolution 을 시계열에서 어떻게하면 더 잘 활용할지에 대한 고찰로 제안되었다. TCN 블럭을 최신화하고 시계열에 맞게 수정하여 시계열 분석 분야에서 다시 고려되게끔 하였다. 실험 결과는 ModernTCN의 태스크 일반화 성능이 효과적임을 보였다. ModernTCN 은 conv 기반의 모델의 효율을 유지하였으며, 더 좋은 퍼포먼스를 보였다. 따라서 추후 시계열 분석 분야에서 conv의 중요성에 대한 연구가 활발해지길 희망한다.
