The two-stage RUL prediction across operation conditions using deep transfer learning and insufficient degradation data 요약
ABSTRACT
다양한 working condition들과 부적절한 degradation 데이터가 progonostic models 퍼포먼스에 악영향을 미친다. 이 문제를 해결하기 위해 2-stage RUL prediction method를 degradation 데이터가 부족하더라도 활용할 수 있게 제안한다. 처음에는 2 레벨의 알람 매커니즘이 FPT를 detect adaptively 하는데 사용된다. 다음으로 deep separable convolutionbal network with double transferable attention mechanism(DSCN-DTAM) 을 통해 크로스 도메인 상의 prognostic model을 구축한다. DSCN-DTAM을 통해서는, 여러가지의 regularization 전략을 통해 모델이 도메인 invariant feature를 추출하는데 도움을 준다. double transferable attention 매커니즘은 degradation 정보를 선택하는데 높은 transferability를 가지게 된다. 마지막으로 제시된 방법은 multiple의 transfer prognostic task 들을 통해 검증되었다.
Introduction
PHM이 최근 중요해 졌음. 이 중에서 RUL은 설비의 failure을 미리 방지하고 shutdown을 줄인다. 최근, RUL 예측 프레임워크는 2단계로 이루어졌다. 첫 번째는 FPT의 결정이고, 이를 통해 degradation 시작점을 결정한 뒤로는 RUL 예측이 시작되게 된다.
Ahmad et al. 은 gradient 기반의 방법으로 FPT를 결정하였고, quadratic regression model을 통해 RUL을 예측하였다.
Pan et al. 은 FPT를 RRMS(Relative Root Mean Square) 을 통해 RUL을 예측하고, EML(Extreme Learning Machine)을 사용하여 학습을 진행하였다.
data-driven 방법의 한계인 manual feature extraction 방법을 극복하고자, 딥러닝 방법의 end-to-end 학습 ability는 prognostic model을 빌드하는데 도움을 주었다.
Li et al. 은 FPT를 2시그마 criterion으로 결정하고, multi-scale CNN을 활용하여 RUL 예측 성능을 높였다.
Yang et al. 은 double CNN을 활용하여 동시에 FPT 결정을 하고 RUL 예측까지 하게 된다.
위의 연구들은 퍼포먼스가 좋았음에도 불구하고, 2가지의 challenging 이슈가 있었다.
첫번째 이슈는 FPT 결정 방법이 고정된 threshold를 가지거나, single identification strategy를 가지고 있었기 때문에 각각의 노이즈와 데이터 분포 차이를 고려하지 못하여 동적으로 변화하지 못하였다.
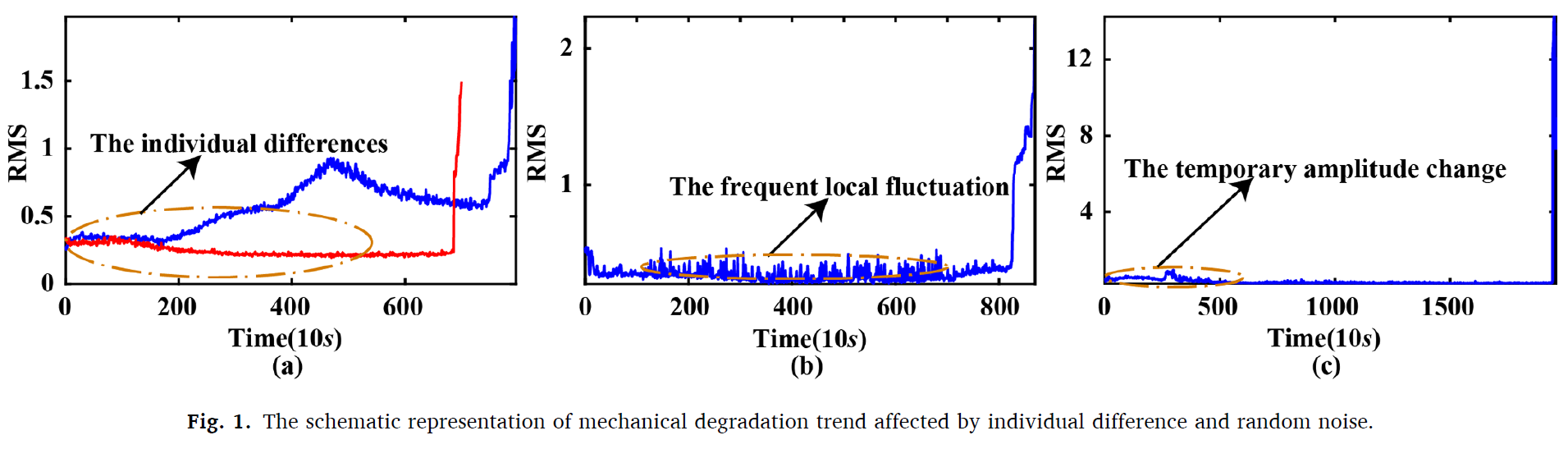
이는 false alarms를 나타내게 한다. degradation information selection과 prognostic model construction을 방해하게 되고 따라서 더욱 stable한 FPT identification 방법이 적절한 FPT를 결정하는데 사용되어야 한다.
두 번째 이슈는 다양한 작동 환경 데이터의 분포가 같아야 한다는 점이다. 다른 작동 환경은 도메인 shift 문제를 야기하고, 그러므로 퍼포먼스의 deteriroation을 만들어낸다.
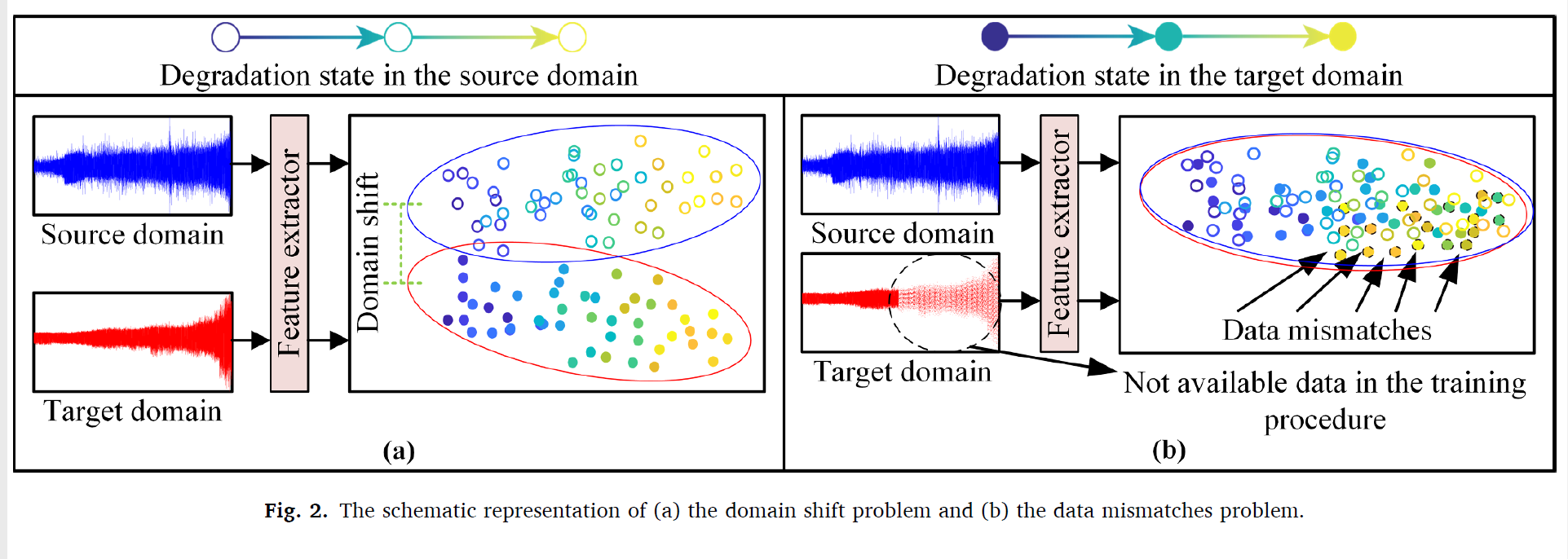
이러한 domain shift의 문제를 해결하기 위해, TL(transfer learning) 을 통해 RUL 예측을 수행하였다.
Costa et al. 은 domain adversarial neural network(DANN) 을 기반으로 한 prognostic method를 만들었고, domain-invariant degradation feature을 학습하였다.
Ragab et al. 은 contrastive adversarial domain adaptation (CADA) 방법을 사용하여 domain shift 문제를 해결하였다.
Ding et al. 은 deep subdomain adaptive regression network(DSARN)을 RUL에 활용하여 cross-domain 시나리오에서 좋은 가능성을 보여줬다.
그러나, TL 기반의 연구들은 다음과 같은 한계가 있다.
1. 부적황학 degradation data에 의한 data mismath 문제에는 해결 할 수 없었다.
2. share 할 수 없는 도메인 간에서의 TL 은 퍼포먼스의 저하를 나타내었다.
이러한 문제를 해결하기 위해서 본 연구는 2 stage RUL 예측 방법을 사용한다.
1. FPT를 각 mechanical entity 에 adaptively 적용한다. 본 방법을 통해 false alarm을 줄일 수 있다. alarm threshold를 동적으로 업데이트를 하고 동시에 통계량 trend를 모니터링한다.
2. deep separable convolutional network의 더블 transferable attention 매커니즘 (DSCN-DTAM) 이 사용되어 도메인 invariant 한 degradation feature들을 알려진 working condition의 complete 한 데이터 및 unseen condition의 불완전에 데이터에서 추출한다.
DSCN-DTAM에서 multiple의 representation regularization 방법론은 domain shift 및 data mismatches를 피하게 해준다. 게다라 더블 transferable attention mechanism 은 untransferable 정보의 영향을 제거하게 한다. 마지막으로, extracted 된 domain-invariant degradation features는 cross-domain RUL 예측에 사용된다.
본 연구의 contribution은 다음과 같다.
1. two-level alarm mechanism 이 디자인되어 자동적으로 entitiy's FPT를 결정한다. 이는 개별 데이터의 variation이나 random noise의 영향에 로버스트 하다.
2. DSCN-DTAM 기반의 prognostic 방법론은 크로스 도메인 갭 및 데이터 미스매치를 다루고 부적절한 degradataion data에 대해서도 잘 작동한다.
3. double transferable attention mechanism 은 동적으로 degradation 정보를 활성화하는데, 이는 high transferability를 가지며, 이는 negative transfer 문제를 피하게 한다.
2. The proposed method
2.1. Problem statement
본 연구는 충분히 라벨된 full-cycle 데이터가 entities를 알고있는 작동 환경에서 주어진다고 가정한다. 소스 도메인은 로 나타낸다.
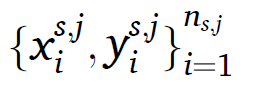
: i 번째 데이터 포인트의 j번째 소스 entitiy
: i 번째 데이터 포인트의 j번째 소스 entitiy의 RUL 라벨
: j번째 소스 entity의 데이터 포인트의 수를 의미한다.
{} target domain 을 라고 함
본 연구의 목적은 2가지로 나타난다.
첫 번째 목적은 FPT 탐지이다. 각 mechanical entities에 대해 적절한 FPT를 탐지하고, 각 variation과 랜덤 노이즈의 interference에 로버스트한다.
두 번째 목적은 cross-domain prognostic 모델로 완전한 소스 도메인 degradation 데이터를 통해 타겟 도메인의 degradation data를 추론한다.
모델 construction을 위해서는 data mismatch 의 문제를 다룬다. 그러므로, 제시된 method는 정확하게 RUL을 예측한다.
2.2. Methodology overview
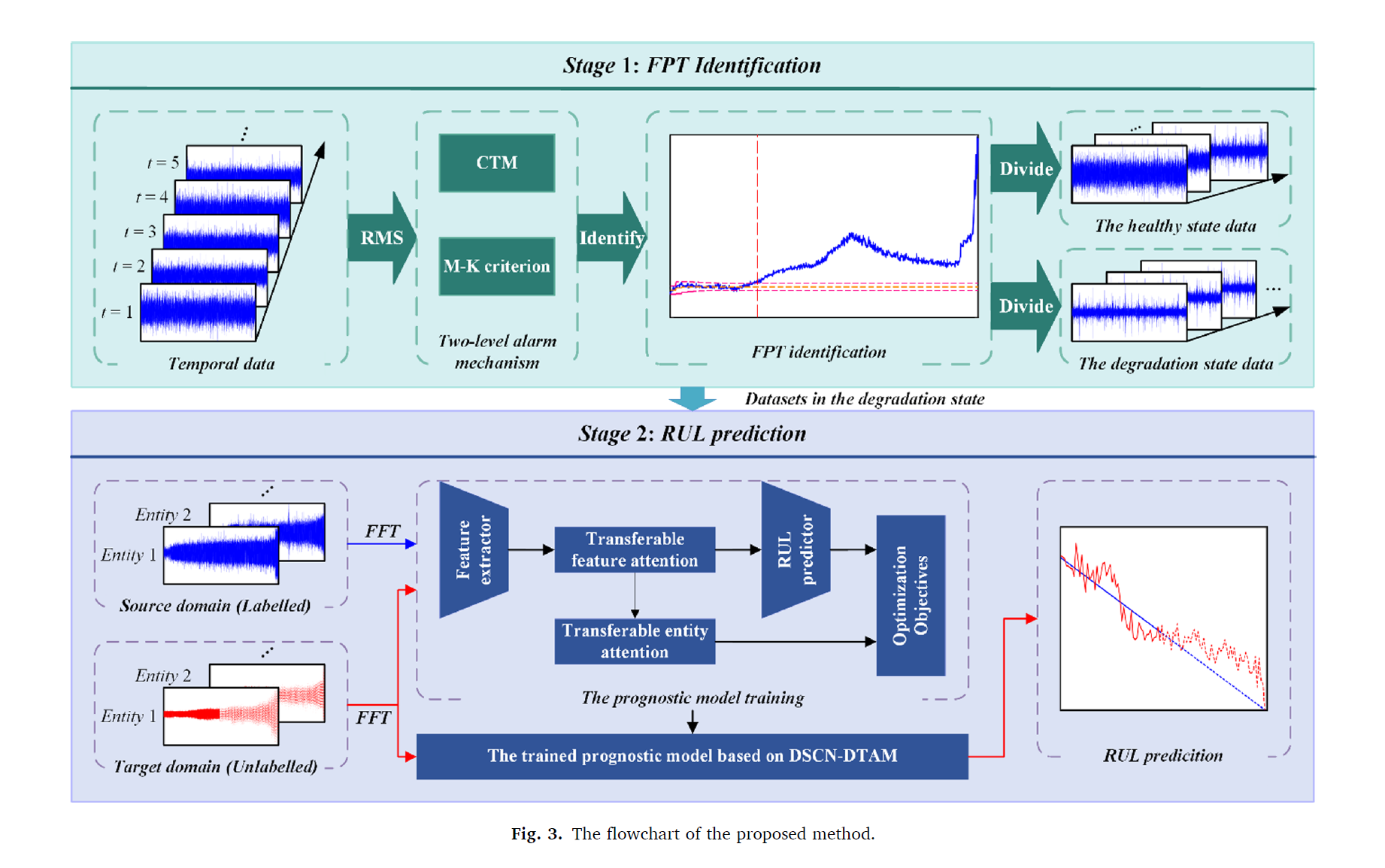
FPT detection 부분 : 모니터링 데이터로부터 RMS를 추출함. 2 레벨의 알람 메카니즘을 사용하여 RMS를 모니터링하고, adaptively FPT를 적용함.
RUL 예측 부분 : DSCN-DTAM을 통해 소스 도메인의 degradation state data는 다음과 같이 라벨됨
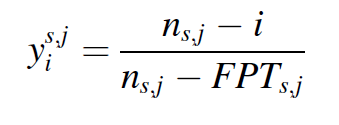
double transferable attention 매커니즘을 통해 degradation의 distribution discrepancy를 줄인다. 본 방법을 통해, domain-invariant한 degradation features가 퍼포먼스를 improve 할 수 있게 한다.
Stage 1 : FPT identification
RUN-TO-FAIL 데이터에서 healty한 정보는 degradataion에 영향을 주지 않는다. 따라서, FPT identification을 통해 degradation sate 의 데이터만 선택하는 것이 중요하다. FPT 디텍션에서의 걸림돌은 frequent local fluctuation과 temporary amplitude change 이다. 또한 데이터 마다의 variation 은 고정된 threshold를 정하는 FPT 탐지에서는 걸림돌이 된다.
따라서 본 연구는 2레벨의 알람 매커니즘을 통해 adaptively FPT를 결정하고, 위의 factors 를 줄인다.
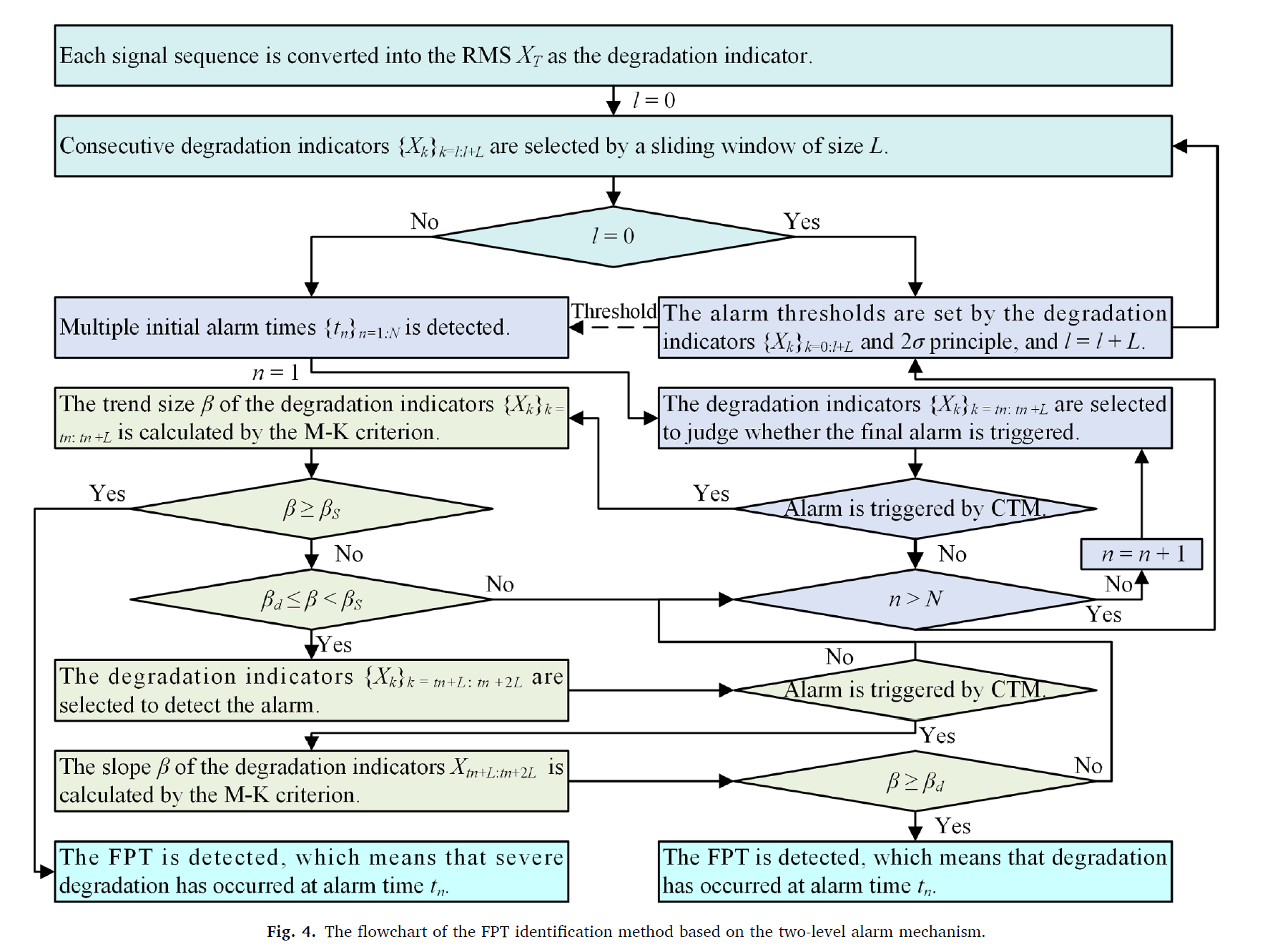
처음에 RMS값을 변환을 했다면, 윈도우 사이즈 L 을 select 한다.
첫 번째 윈도우 값이라면, 알람 threshold가 2시그마로 설정된다.
다음 윈도우를 인풋으로 넣는다. 이때, 알람이 처음으로 울리는 시점 {}을 detect 한다. 첫 번째로 알람이 울리는 시점이라면, degradation indicators 가 선택되어,CTM에 의해 알람이 트리게 되는지 확인한다. 만약, 알람이 CTM에 의해 트리거 되지 않았다면, 다음 n을 선택하여 알람이 트리거 되는지 확인한다. CTM에 의해 알람이 트리거 됨을 확인하면, M-K criterion에 의해서 trend size 가 계산된다. 이 트랜드 사이즈가 보다 크거나 같으면 FPT가 디텍트 되고, 이는 degradation이 알람 타임 에 degradation이 발생했음을 의미한다. 만약에 값보다 작으면, 값보다 큰지를 확인하고, 이 값보다도 작다면 n을 키우게 된다. 만약 이 값보다 크면 degradation indicators를 다시 select 하고, 알람이 CTM에 의해 트리거된다면, 슬로프 가 M-K criterion에 의해 계산된다. 이것이 보다 크면 FPT가 detect 되게 된다.
결국 위에 알고리즘을 사용한 이유는, RMS indicators 가 지속적으로 알람 threshold를 넘어서는지에 대해 CTM을 통해 판별하고, 즉 랜덤한 노이즈에 의해서 알람이 일시적으로 뛰지 않았다는 것을 본 뒤, 그리고 M-K criterion을 통해 RMS indicator의 트랜드를 판별하여 FPT를 결정하게 되는 것이다. 이러한 방법으로 adaptively FPT를 결정하게 된다.
그런데 결국 이 방법은 RMS의 2시그마를 이용하는 방법하고 다를게 없다. 단지 룰베이스로 노이즈에 로버스트하게 어려운 알고리즘을 사용한 것이다. feature extraction을 고정하는 것이 과연 다양한 상황에서의 degradataion을 표현하기 위해 효과적일까?
Stage 2: RUL prediction
2.4.1. The cross-domain prognostic model based on DSCN-DTAM
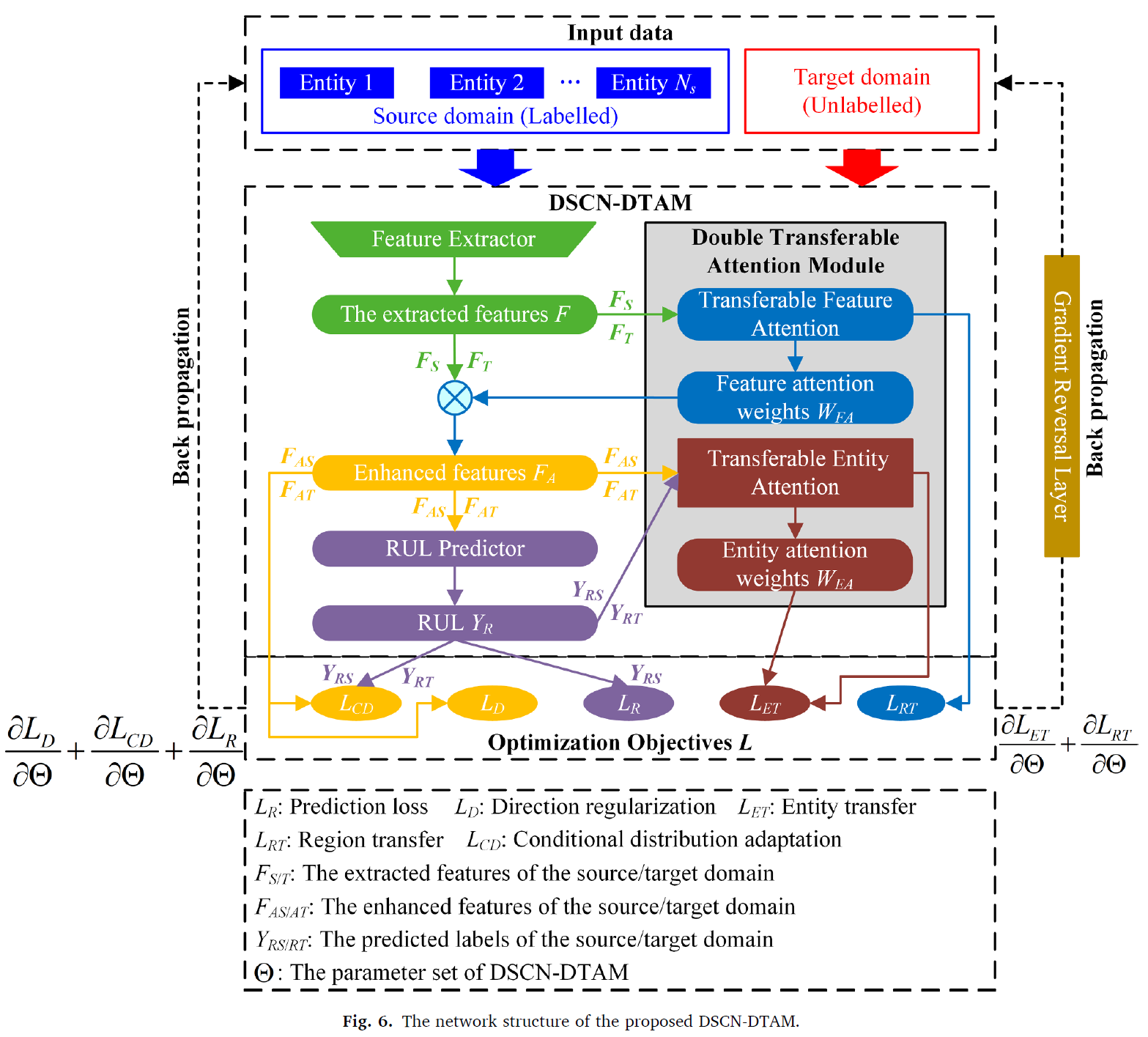
DSCN-DTAM 의 구조는 다음과 같다.
1. Feature extractor : 독립된 convolutional module을 사용하여 model 복잡성을 낮추고, spatial correlation의 복잡성을 낮췄다.
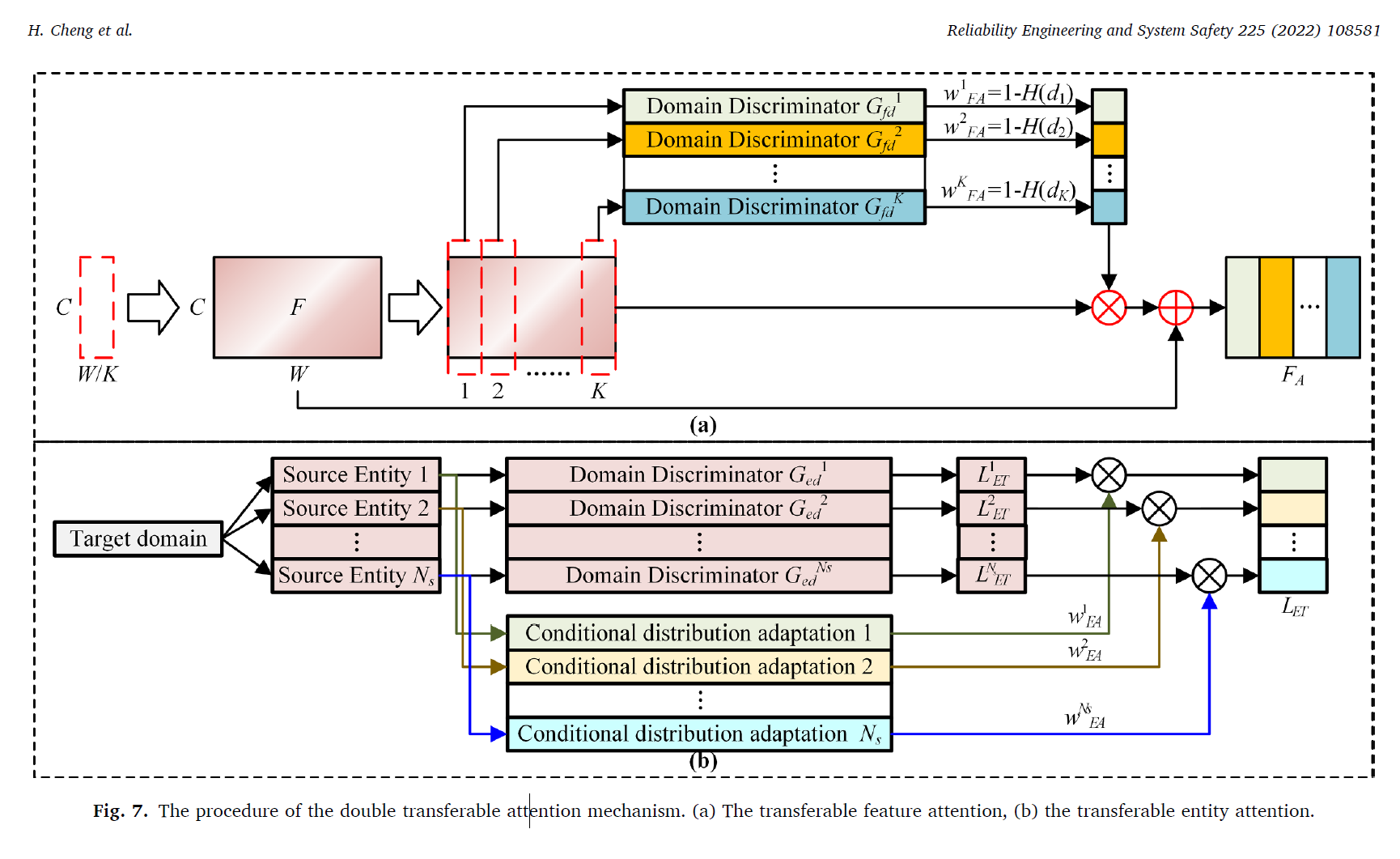
2. double transferable attention mechanism : transferable feature attention & transferable entity attention 으로 구성되어있어, feature의 transferability를 높였다.
Extracted 된 feature F 차원 : X C : channel number W : feature length
degradation feature F 가 K regions로 나뉘게 된다.
그 다음, region-wise domain discriminators {} {k=1,2...K} 가 constructed 된다. 각 discrimator는 distribution discrepancy를 소스도메인과 타겟도메인 사이를 평가한다.
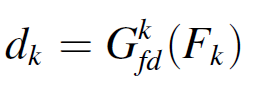
즉, 는 k번 째 feature region 이 소스 도메인에 속할 확률을 의미한다. 이를 통해 feature weight 을 계산한다.
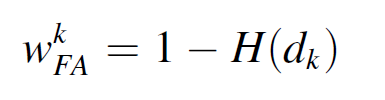
H 함수는 entropy functional인데, extracted features 는 residual mechanism에 의해 weighted 되었고 잘못된 도메인의 negative effect는 다음과 같이 계산된다.
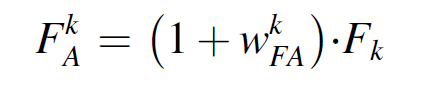
이러한 매커니즘을 통해 더 중요한 attention을 가지고 feature을 select 하게 된다. enhanced degradation features 는 transferable entity attention에 인풋이 된다. 이를 통해 어떤 소스의 information이 activated 되고 활용되는지를 본다. 이 weight이 계산되는 것은 CEOD를 통해 계산된다.
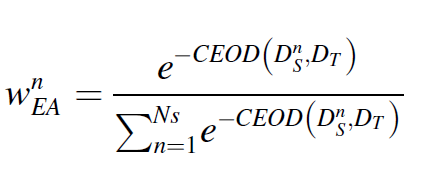
이에 대한 전체 구조는 다음과 같다.
따라서, 각 부분에서 나오는 로스들음 다음과 같다.
1) Prediction loss
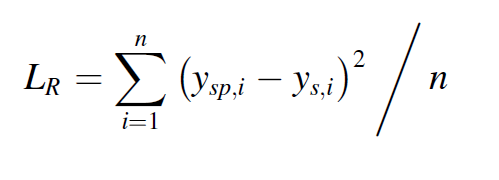
2) Direction regularization
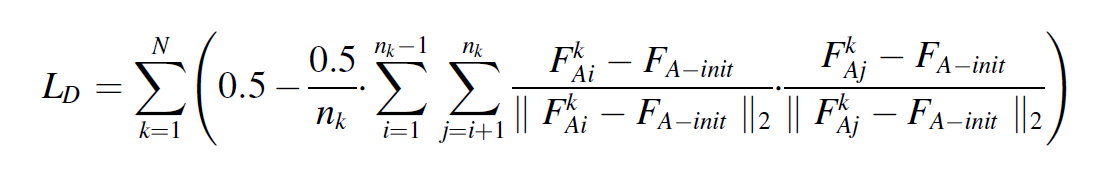
3) Conditional distribution adaptation
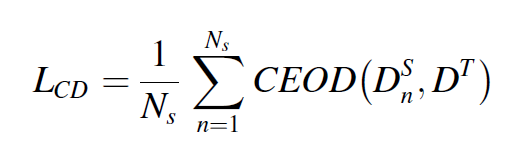
4) Region transfer
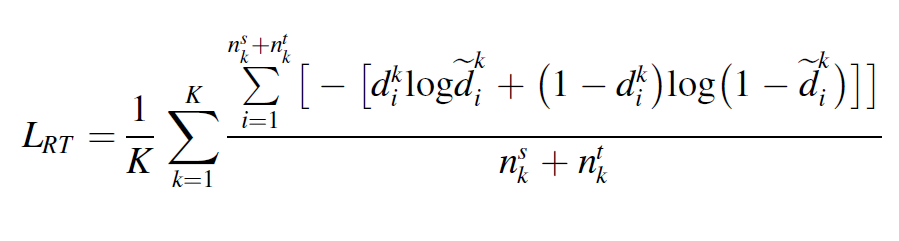
5) Entity transfer
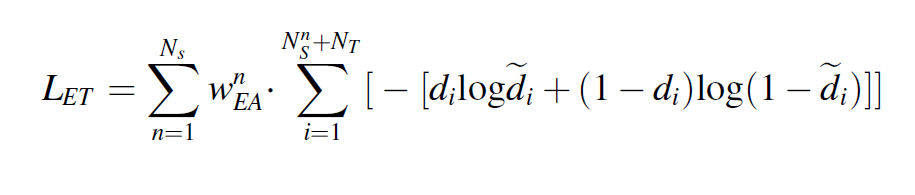
토탈 로스는 다음과 같다.
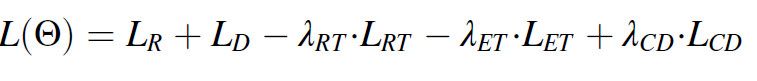
3. Experimental results and discussion
3.1. Dataset description
XJTU-SY Dataset
PHM2012 Dataset
슬라이딩 윈도우의 길이는 15, = 0.002 = 0.015
이는 데이터셋을 미리 보고 판별한 값이다. FPT를 판별하기 위해 소스와 타겟 도메인들의 degradataion stage data를 선택하여 cross-domain prognostic 모델에 넣었다.
3.3.1. Results of FPT identification
3가지 케이스와 본 연구의 방법론을 비교하였다.
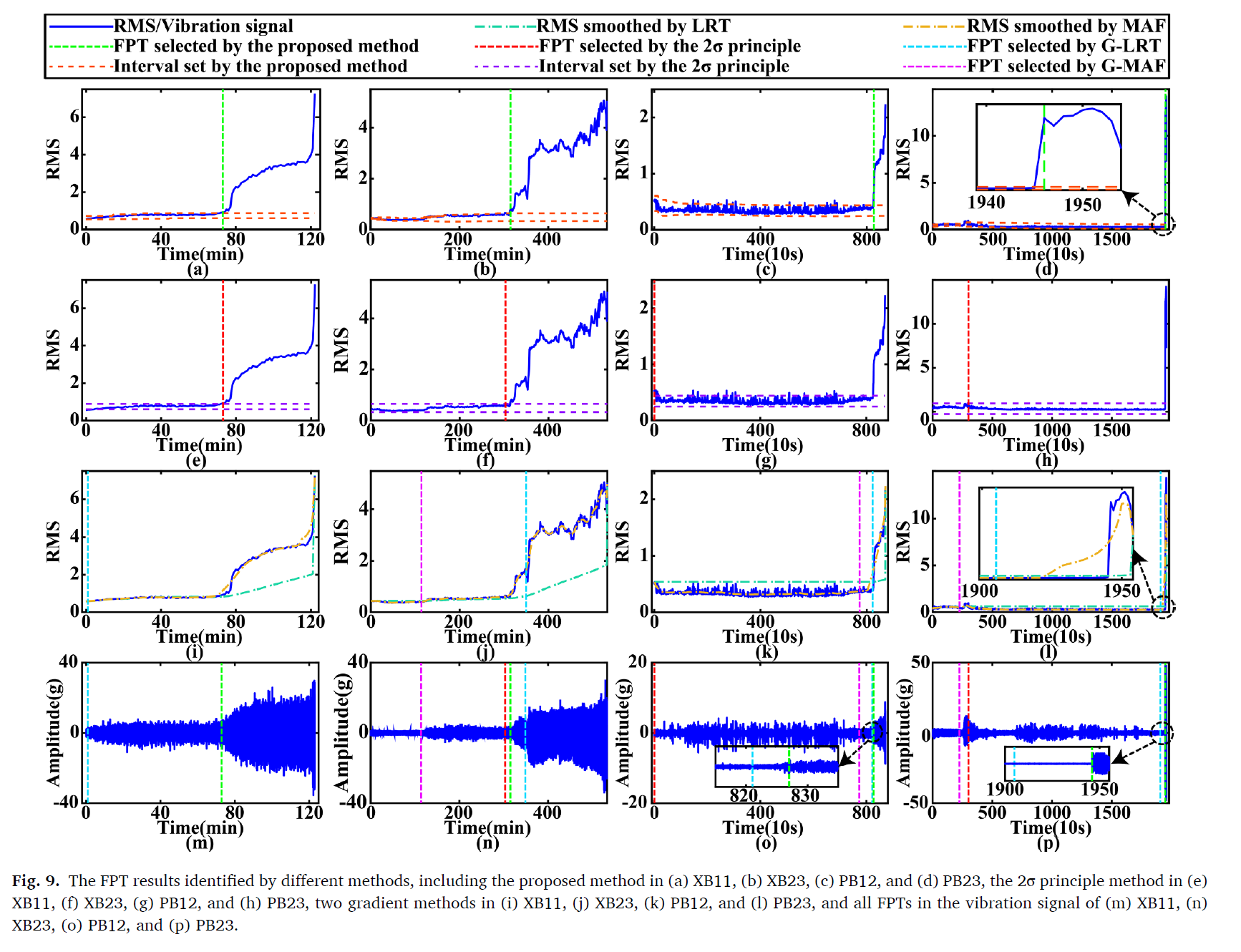
XB11 과 XB23 의 경우, early operating stage 에서 short upward trend 가 있다. 이 트랜드는 시간이 지나면서 안정화 된다. 이는 2가지의 gradient method 에게 잘못된 FPT 디텍션을 나타낸다. PB12에서, random noise가 많이 일어나게 되는데, 2시그마의 경우 잘못된 결과를 나타낸다. PB23또한 마찬가지이다. 다른 3가지 방법론에 비해서 noise 와 anomaly condition에 대해서 더 robust하게 FPT를 detect 함을 보였다.
FPT 결과가 공개되어 있는 데이터셋인 PHM2012 데이터에 적용해 보면,
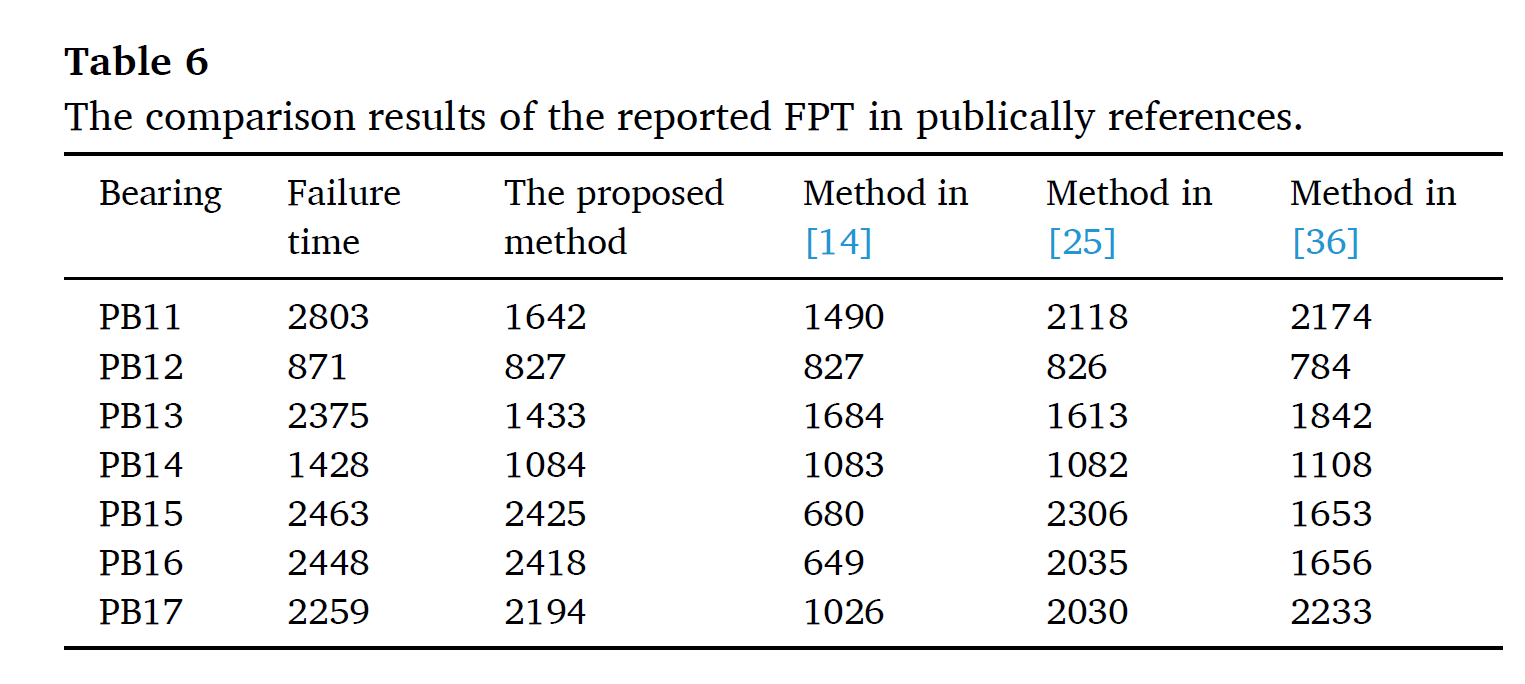
FPT를 직관적으로 더 잘 잡는것을 확인할 수 있다.
3.3.2. Results of RUL prediction
아래의 모델들과 크로스 도메인 상황 하에서 RUL 예측 성능을 비교하였다.
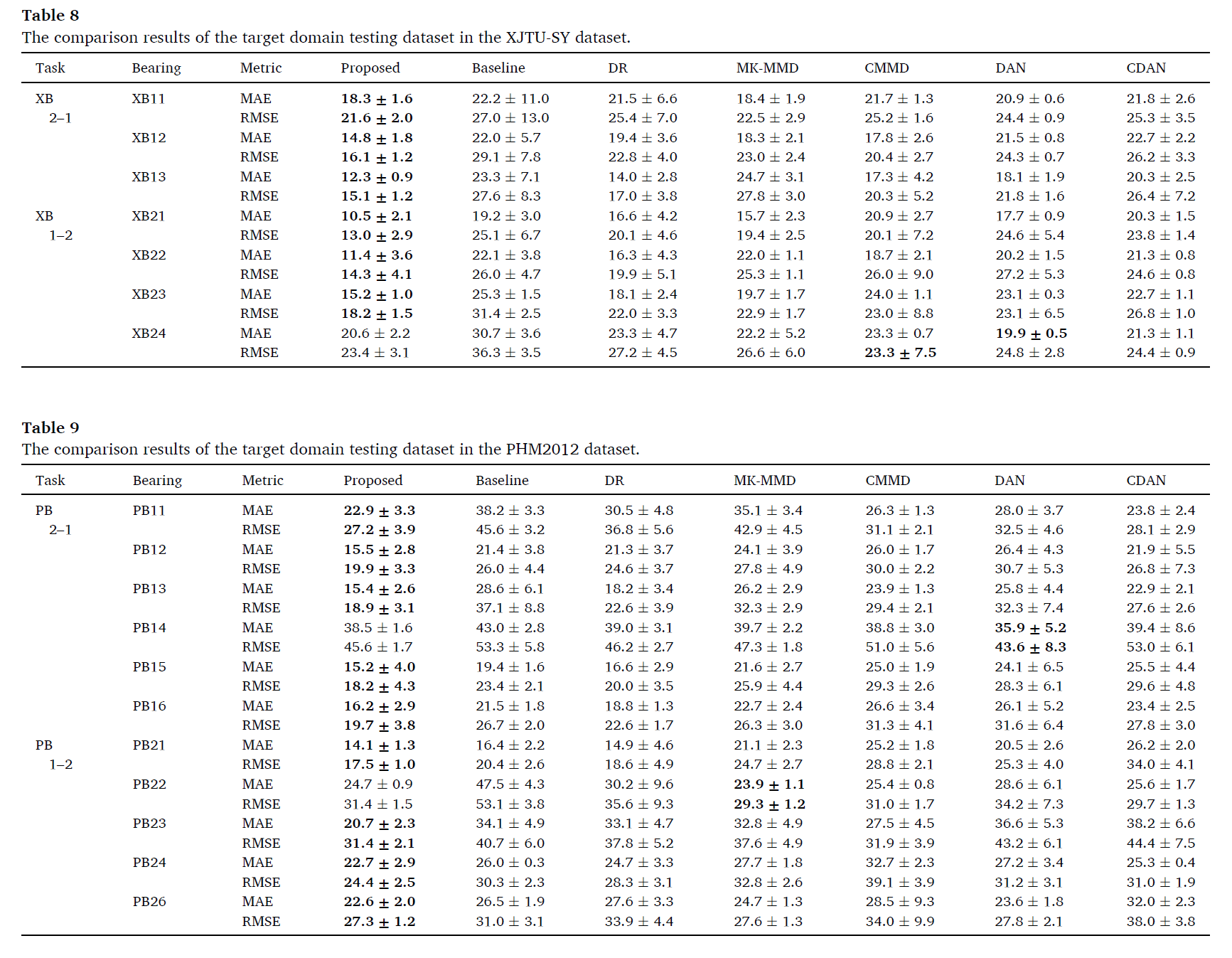
대부분에서 좀 더 좋은 성능을 보임을 확인 할 수 있다. 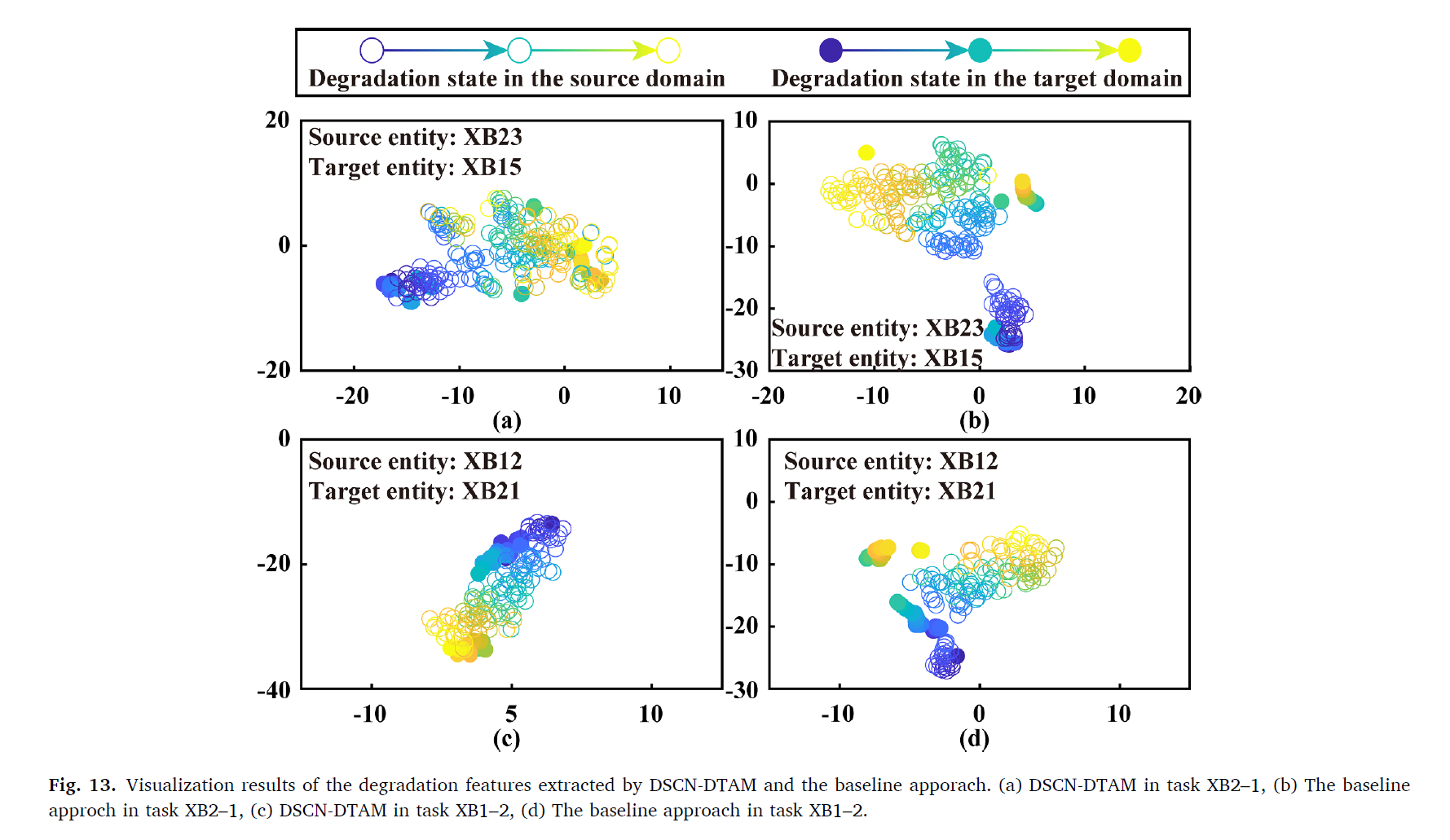
원의 색상은 degradation degree를 나타낸다. (a), (c) 가 베이스라인에 비해 어떻게 degradation feature가 뽑혔는지 보여주게 된다. baseline 에 비해 제시한 방법론이 feature subspace에서 distribution distance를 효과적으로 줄임을 알 수 있다. 이를 통해 high-level의 degradataion features cluster를 구성함을 알 수 있다.
