HydraList- A scalable In-Memory Index Using Asynchronous Updates and Partial Replication
Paper Review
Introduction
Hardware 기술이 발전함에 따라, 점차 Main Memory 크기가 증가하는 추세를 보이고 있고, 이는 in-memory database의 발전으로 이어지고 있습니다. 따라서 database의 index strucuture의 중요성이 증가하고 있는 추세입니다. Index structure는 크게 시간 복잡도에 따라 총 4개의 구조로 분류할 수 있고, 이는 Hash index structure, tree-based index structure, Trie-based index structure 그리고 위의 3가지를 혼합한 hybrid 구조가 있습니다.
하지만 multicore 환경이 발전함에 따라 시간 복잡도만을 고려해서는 성능적인 부분에서 우위를 점할 수가 없습니다. 따라서 동기화(Synchronization)기법에서 발생하는 overhead의 고려와, NUMA(Non uniform memory architecture) 에 적합한 index structure도 고려를 해야하는 요소로 부각되고 있습니다.
따라서 현대의 기술관점에서 생각했을 때, 앞의 3가지 관점을 모두 고려한 index structure가 높은 성능을 낼 수 있다고 판단이 됩니다. HydraList는 앞에서 언급한 3가지 관점을 모두 고려한 index structure이고, 이로 인해 성능에서 우위를 점할 수 있습니다.
Related Work
1. Reduce Synchronization Overhead
동기화 과정에서 발생하는 overhead를 줄이는 방법중에는 대표적으로 lock coupling method가 있습니다. 하지만 lock coupling method는 lock에 대해서 많은 bus message를 초래하기 때문에 cache coherence traffic이 발생하게 됩니다. 따라서 HydraList에는 각 node마다 version을 두어 동기화 하는 optimistic synchronization technique를 사용합니다. Optimistic synchronization technique는 특정 node에 version을 두어, 다른 thread가 해당 node에 접근하여 version이 맞지 않으면 계속해서 retry를 하는 방법입니다. 이를 통해 cache coherence traffic을 줄일 수 있습니다.
2. Reduce Critical Section
Critical section의 비중이 높아질 수록, 멀티 프로세스를 사용할 때 프로그램의 성능향상은 프로그램의 순차적인 부분(Sequential Part)에 의해 제한된다는 암달의 법칙에 의거하여 성능이 저하됩니다. 따라서 HydraList는 index 구조를 search layer와 data layer로 분리하여 data layer에만 synchronization하게 update를 하고, update된 node를 search layer에 반영할 때는 asynchronization하게 반영하여 critical section의 크기를 최소화 하는 정책을 사용했습니다. 또한 SIMD instruction을 사용하여 data layer에서의 search opeartion 수행을 병렬적으로 처리하여 가속화 합니다.
3. Reduce Cache Miss Ratio
Tree-based index structure인 B Tree의 경우에는 leaf node를 연속된 메모리 공간에 저장하여 cache friendly 한 방법을 사용합니다. 따라서 HydraList의 data layer의 구조도 B Tree의 leaf node 구조와 유사한 방식으로 double linked list로 구성된 slotted node를 이용하여 cache miss를 최소화하는 정책을 사용했습니다. 또한 cache에 reference 되는 크기를 최소화 하기 위해서 크리가 작은 fingerprint hash를 사용하여 cache miss를 최소화 합니다.
4. Reduce Remote Memory Access
HydraList는 NUMA간 remote memory access의 횟수를 최소화 하기 위해서 shared memory크기를 최소화 하는 정책을 사용합니다. 따라서 search layer를 각 NUMA node에 복사하여 search layer의 synchronization 과정에 있어서 remote memory access를 최소화 합니다.
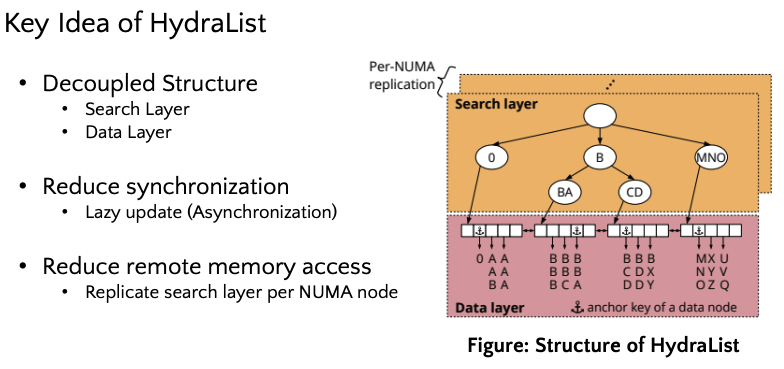
Overview of HydraList
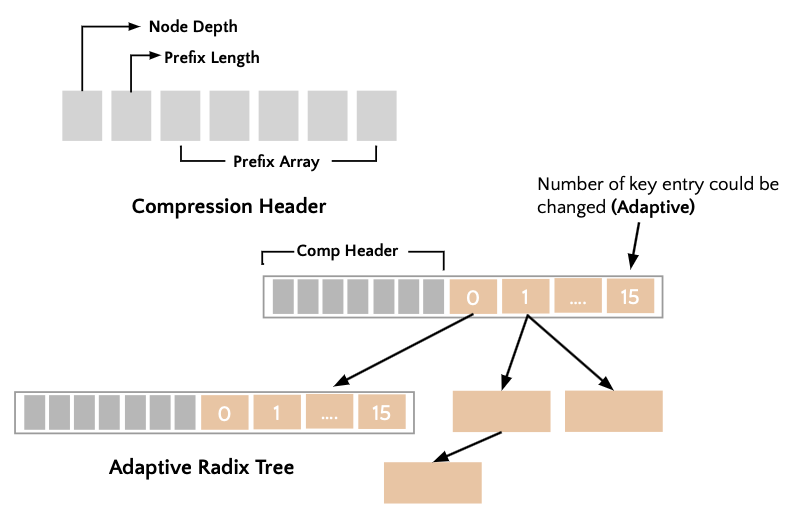
Index structure에 있어서, B Tree와 같은 tree-based index structure을 사용하는 경우, 100만개의 key 중에서 target key를 찾기 위해 최소 26번의 comparision operation을 수행해야 합니다. 이는 데이터가 많아 질수록 성능이 감소하게 됩니다. 따라서 HydraLists는 trie-based index structure인 radix tree를 search layer에 사용합니다. 하지만 단순히 radix tree를 사용했을 경우에는, key length가 늘어날 수록 O(key length)의 시간복잡도를 가지는 radix tree의 성능이 감소하게 됩니다. 따라서 radix tree에 compression 방법을 도입한 ART(Apaptive Radix Tree)를 search layer에 사용합니다. Adaptive radix tree는 아래 그림과 같이 compression header가 있으며, key의 분포에 따라 key entry의 수가 변형되는 특성을 가진 trie-based index structure입니다. 따라서 search layer의 전체 height가 줄어들게 되어, 좋은 look up performance를 기대할 수 있습니다.
하지만 ART의 경우에는 scan operation을 수행했을 때 성능 차원에서 취약점이 발생하기 때문에, HydraList는 해당 취약점을 보안하기 위해서 data layer에는 b tree와 유사하게 slotted doubly linked list구조를 사용합니다. Data layer의 각 slot은 아래 그림과 같이 구성되어 있으며 각각의 구성요소는 다음과 같은 역할을 합니다. Anchor key는 각 data slot의 고유키를 나타내는 지표이고, next pointer와 previous pointer를 통해 double linked list의 구조를 유지합니다. 또한 bitmpa을 활용하여 각 data slot에 저장되어 있는 key-value가 valid 한지를 나타내고, fingerprint array와 permutation array를 이용하여 실제로는 정렬되어 있지 않지만 scan operation에 유리하도록 마치 정렬되어 있는 것 처럼 나타낼 수 있습니다.
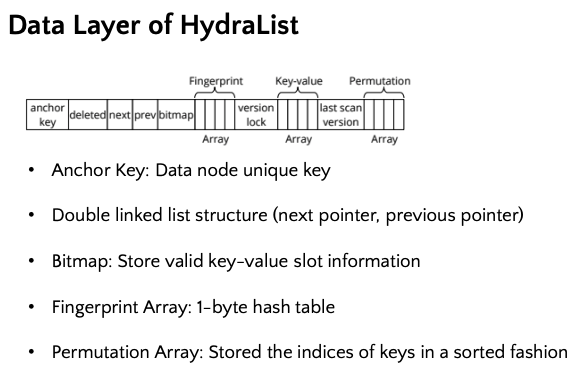
Design of HydraList
1. Jump node and Target node
우선 search operation에서 쓰이는 개념인, jump node와 target node의 개념에 대해서 설명하자면, jump node는 search layer에 의해 query에서 요구하는 key가 있을 법한 node 입니다. 그리고 target node는 실제로 query에서 요구하는 key가 위치하는 node입니다. 따라서 search operation이 수행될 때, 만약 jump node와 target node가 같다면, search operation 의 수행은 종료됩니다. 또한 각 slot의 anchor key는 해당 slot에 있는 key 보다는 항상 크다는 특성을 지니고 있어, search operation을 통해서 reader가 jump node에 안착하게 된다면, 위와 같은 특성에 의해 anchor key가 upper bound인지 lower bound인지를 확인하여 특정 방향으로 target node를 sequential 하게 찾을 수 있습니다.
2. Split and Merge Operation
다음은 data slot의 split과 merge operation입니다. Data slot의 크기가 insert operation에 의해 설정한 임계값을 넘어갈 경우, data slot의 split operation이 수행됩니다. 반대로 delete operation에 의해 설정한 임계값에 비해 작아질 경우, 인접한 data slot간의 merge operation이 수행됩니다. Split operation이 수행되는 과정에서는 split이 일어나는 slot에 lock을 걸고, 해당 data slot의 median key를 새로 생성되는 node의 anchor key로 설정을 합니다. 이후, insert 되는 data를 새롭게 생성되는 data slot에 저장하고, 각 node들의 pointer를 연결해준 후 unlock 합니다.
3. Consistency in HydraList
Data layer의 update가 모두 이루어 진후, async 하게 search layer에 update를 해줍니다. 하지만 data layer와 search layer의 update가 동시적으로 이루어지지 않고 분리되어 일어나기 때문에, 서로 간의 inconsistency가 발생하게 됩니다. 하지만 앞서 언급했던 것과 같이, search layer를 통해 reader는 target node와 인접한 jump node로 이동하기 때문에, reader는 jump node로 부터 sequential 하게 target node를 찾을 수 있기 때문에 consistency를 유지할 수 있습니다. Jump node와 target node간의 거리를 측정한 결과, 대부분의 reader가 target node와 인접한 jump node에 위치하기 때문에, sequential search로 인핸 overhead를 매우 적음을 알 수 있습니다.
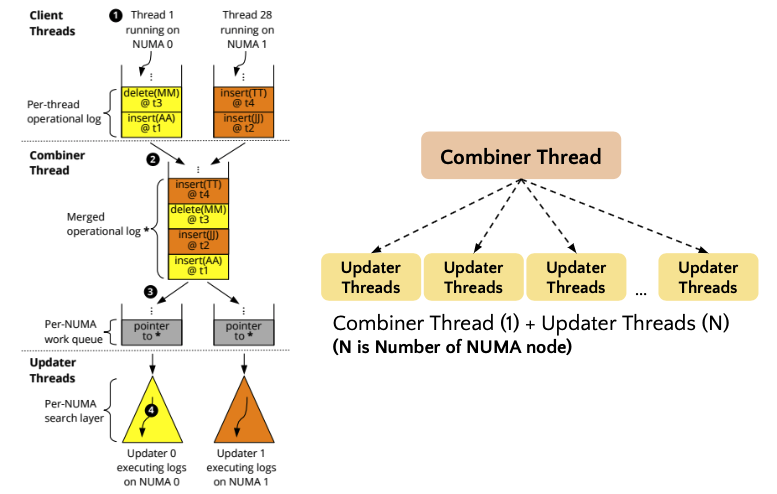
4. Decouple synchronization in HydraList
다음으로는, search layer에 async하게 update되는 과정을 설명 드리겠습니다. HydraList에서는 cross NUMA traffic을 최소화 하기 위해서, NUMA node마다 per thread operation log을 통해 operation 정보를 저장합니다. 이후, combiner 라는 background thread를 사용해서, 각각의 NUMA thread에서 저장된 operation log를 시간 순서대로 병합하는 과정을 가집니다. 시간 순서대로 병합하는 이유는 consistency를 유지하기 위함입니다. 이후 updater background thread를 사용하여 merge 된 operation log를 각 NUMA node에 replication 되어 있는 search layer에 dequeue하는 과정을 통해서 update 합니다. 따라서 background로 돌아가는 총 thread 수는 하나의 combiner thread와 NUMA node 수 만큼의 updater thread로 이루어져, 총 n+1 개의 background thread가 돌아가게 됩니다.
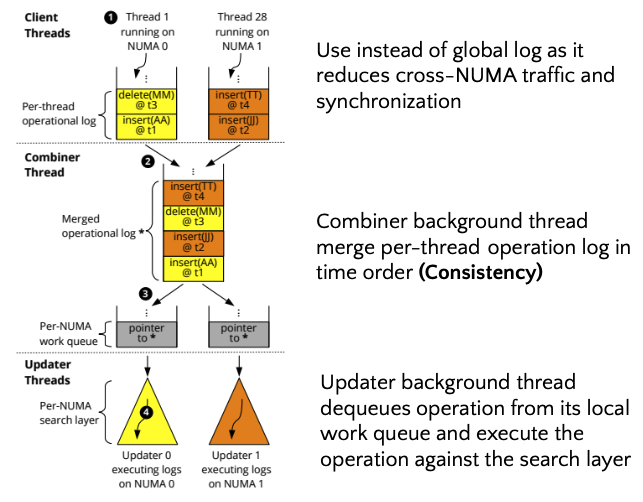
5. Concurrency Control in HydraList
마지막으로, HydraList에서 concurrency control 하는 방법에 대해서 설명드리겠습니다. HydraList는 앞서 related work에 언급한 Optimistic version locking protocol을 사용합니다. 하지만 해당 protocol은 retry하는 과정에서 abort가 많이 발생하여 core 간의 contention이 일어나는 문제점이 있습니다. 따라서 HydraList에는 backoff scheme를 두어, 특정 임계 값 이상 retry가 일어난다면, 임의적인 period 동안 retry 하지 않는 정책을 도입하여 contention을 최소화 하는 방법을 사용했습니다.
Conclusion
HydraList의 key idea는 search layer와 data layer로 나눠서 데이터를 관리한다는 것입니다. 또한 각 layer에 대해 동기화 방법이 다르게 적용되어 multicore 환경에서 가장 큰 문제점인 contention overhead를 줄입니다. 그리고 각 NUMA node 마다 search layer를 복제하여 remote memory access의 비율을 최소화 하여 overhead를 줄입니다. 그러므로, HydraList는 multicore 환경에서 scalable 하고 다양한 workload에 versatile한 특성을 지닐 수 있습니다.
