Introduction
LSM tree는 append 하는 형식으로 write operation을 처리하기 때문에 write 성능에 있어서는 다른 Key-Value 데이터베이스 시스템에 비해 우위를 점한다. 하지만 level structure를 두어 데이터를 관리하기 때문에 read performance 에 있어서는 다른 Key-Value 데이터베이스 시스템에 비해 성능이 좋지 않다. 이는 look up query 또는 range query가 들어오게 되면, query에서 요구하는 key를 포함하는 모든 SSTable을 모두 search 하기 때문이다.
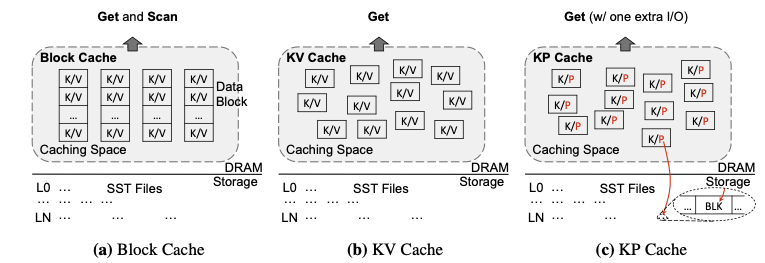
따라서 LSM-based Key-Value 데이터베이스 시스템에 있어서는 적절한 데이터를 caching 하는 policy가 요구된다. Key-Value 데이터베이스 시스템에는 대표적으로 3가지 방법으로 데이터를 캐싱한다. 우선 Key-Value를 모두 캐시에 올리는 방법, Key-Pointer format으로 value를 가르키는 pointer를 해당 key와 같이 캐시에 올리는 방법, 그리고 key를 포함하고 있는 block을 모두 캐시에 올리는 방법이 있다.
현재 존재하는 caching scheme는 앞에서 언급한 세가지의 cache type중 하나 혹은 두개의 type만 고려하여 caching scheme로 사용하고 있다. 따라서 AC-Key, Adpative Caching for KSM-based Key-Value Stores에서는 세개의 cache type의 trade-off 를 고려하여 각각의 이점만을 병합하여 서로 다른 workload에 적합하도록 caching scheme를 설계한다.
Motivation
Caching Key-Value (KV)
우선, Key-Value를 모두 cache에 올리는 방법이다. 캐시에 Key-Value를 모두 올리게 되면, 캐시에서 바로 hit되는 경우 storage I/O를 발생시키지 않고 상대적으로 접근 속도가 빠른 memory에서 value를 읽을 수 있는 장점이 있다. 하지만 LSM-based 데이터베이스는 고정된 크기의 value가 아니며, 크기가 큰 value를 가질수도 있다. 이러한 경우 cache 공간을 비효율적으로 사용하게 되는 단점이 있으며 연속적이지 않은 key를 저장하기 때문에 range query를 지원하지 않는다.
Caching Key-Pointer of Value (KP)
다음으로는 value를 가르키고 있는 Pointer와 key와 매핑하여 cache에 올리는 방법이다. 캐시에 key와 고정크기인 pointer를 매핑하게 올리게 되면, KV policy와 달리 캐시 공간을 상대적으로 효율적으로 사용할 수 있다는 장점이 있다. 하지만 pointer를 통해서 value를 읽어야 하는 작업이 필연적으로 발생하기 때문에, 한 번 이상의 storage I/O가 발생하게 된다. 또한 이 KV와 같은 이유로 range query를 지원하지 않는다.
Caching Data Block
마지막으로, 특정 key가 불리게 되면, 해당 key를 포함하고 있는 data block을 모두 cache에 올리는 방법이다. 이러한 경우 Key-Value가 연속적으로 저장되게 되어 range query를 지원하게 되며, KP policy와 달리 memory에서 hit하게 되면 storage I/O를 발생시키지 않고 query를 처리할 수 있다는 장점이 있다. 하지만 data block은 여러개의 Key-Value 저장하고 있기 때문에 하나의 value보다 크기가 월등히 크다. 따라서 KV policy에서 발생하는 문제점이 극대화 되게 되고 cache 공간을 효율적으로 사용하지 못하게 되어 evict되는 data block이 많아지게 된다. 이러한 경우 cache hit ratio가 매우 낮다.

Lesson 1: KV policy와 KP policy의 장점을 결합해서 look up query를 효율적으로 처리하는 방법을 고안해야 한다.
Lesson 2: Block과 KV/KP entries 캐싱하는것은 각각 range query와 look up query를 처리하는 것에 장점을 가지고 있다.
Lesson 3: Caching algorithm 은 LSM Key-Value Store의 고유한 level structure을 고려하여 다른 캐싱된 항목 간에 사용된 DRAM 크기와 storage I/O 수의 차이를 고려해야 한다
Lesson 4: Caching algorithm은 workload에 맞게 변화해야 한다
AC-Key Design
AC-Key는 motivation을 통해 위의 3가지 cache policy를 모두 반영한 데이터베이스 시스템이고, 각각의 cache components의 크기를 dynamic 하게 관리합니다. 각 cache component의 크기는 hierarchical adaptive caching algoritm 와 caching efficiency factor로 인해 관리됩니다. AC-Key의 구성요소는 아래 그림과 같습니다.
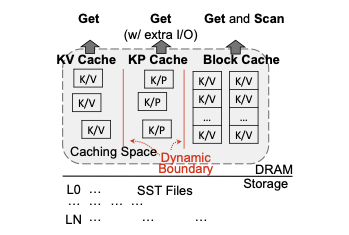
Get Handling
1. Case 1: Hit in KV cache
Query에서 요구하는 key가 KV cache에서 hit 됬을 경우, storage I/O를 발생시키지 않고 value를 return 합니다
2. Case 2: Miss in KV Cache but hit in KP Cache
Query에서 요구하는 key가 KV cache에서는 miss되고 KP cache에서 hit 됫을 경우, 해당 key에 해당하는 data block이 Block Cache에 올라와있는지 검사한다. 그렇지 않다면, data block을 Block Cache에 caching 하고, binary search를 통해서 원하는 key를 return 한다. 또한, KP cache에 있는 Key-Pointer 형식의 cache data를 Key-Value 형태로 변환하여 KV cache에 올린다(Promote policy).
3. Case 3: Miss both in KV Cache and KP Cache
Query에서 요구하는 key가 KV cache에서도 miss되고 KP cache에도 miss 되는 경우, AC-Key는 해당 key가 속해있는 range 범위의 모든 SSTable을 search 한다. 만약 SSTable에서 key가 발견이 될경우 value를 return하고 search 작업을 멈춘다. 또한 해당 Key-Value가 존재하는 block을 pointing하여 Key-Pointer 형태로 KP Cache에 올린다.
SSTable을 search 하는 과정에서, 각각의 SSTable의 Bloom Filter Block이 Block Cache에 올라와있는지 확인한다. 만약 BF block이 cache 되어 있지 않다면, BF block을 Block Cache에 올린다. 또한 만약 BF block을 확인하여 해당 data block 내부에 query에서 요구하는 Key-Value가 존재한다는 가능성이 있다면, Index block과 Data block을 모두 Block Cache에 올린다. BF block, Index Block, Data block은 RocksDB와 유사하게 Block Cache를 공유한다.
Flush Handling
MemTable에는 같은 key의 여러 버전의 value가 쓰여질 수 있다. 따라서, KV cache나 KP cache에는 MemTable에 존재하는 Key-Value보다 최신 버전의 데이터가 아닐 수도 있다. 하지만 look up 과정에서는 MemTable을 우선적으로 search 하기 때문에 cache data가 최신 버전이 아니라도 큰 문제가 없다. 하지만 Flush operation이 수행될 경우에는, MemTable에 있는 데이터가 모두 SSTable Level 0에 저장이 되기 때문에 caching data는 MemTable과 같은 버전의 데이터가 올라와있어야 한다. 따라서 매번 새로운 버전의 데이터가 MemTable에 쓰여질 때 cache data도 최신 버전으로 수정하는 정책을 사용하는 것이 아닌, flush operation이 수행될 때만 cache data를 최신 버전으로 유지하는 정책을 사용한다.
Compaction Handling
Compaction은 상위 레벨의 SSTable이 하위 레벨의 SSTable로 병합되는 과정이다. 이 과정에서 데이터가 저장되어 있는 block pointer와 data block의 변경이 일어난다. 따라서 KP cache와 Block Cache는 compaction operation이 일어나고 난 후 update 되어야 한다. 반면에, KV cache의 경우에는 Key-Value가 그대로 올라가 있어 compaction operation이 수행되고 난 이후에도 수정을 요하지 않는다.
Caching Efficiency Factor
Caching Efficiency Factor란, 특정 cache entries가 가지는 cost와 benefit을 trade off하기 위해 만들어진 수치이다. 즉 cache에 올라와있는 data들의 caching efficiency factor을 계산해서 evict되는 victim을 정할 때 사용되는 수치이고, KV cache, KP cache, Block Cache간의 크기를 dynamic하게 설정하는 것에 사용되는 수치이다. Caching Efficiency Factor을 계산하는 수식은 다음과 같다.


Victim 을 선정하는 수는 𝑒^𝑣로 선정하게 되고, v가 0일 때는 일반적인 가장 마지막에 사용된 하나의 victim만 선정하므로 LRU policy와 같다. 그리고 v가 0보다 커질 때는, victim을 선정하는 수가 많아짐으로 정확한 후보군을 선정하여 evict 할 수 있다.
Hierarchical Adaptive Caching
Hierarchical Adaptive Caching 은 Point Cache(KV Cache, KP Cache)와 Block Cache간의 크기 boundary를 정하기 위해서 사용하는 정책이다. 우선 HAC(Hierarchical Adaptive Caching)에서 쓰이는 Ghost Cache는, real cache에서 evict된 것들의 metadata를 저장하고 있는 cache이다. 즉, 특정 query에 의해 real cache에는 hit되지 못하지만 ghost cache에서 hit이 발생한다면, real cache의 크기가 조금더 컷더라면 real cache에서 hit이 될 수도 있다는 것을 의미하게 된다. 따라서 이러한 원리를 사용하여 Point Cache와 Block Cache간의 boundary를 정하게 된다. Target boundary와 Actural boundary를 정하는 원리는 다음과 같다.
만약, Point Cache의 ghost cache에서 hit이 발생한다면 Point Cache와 Block Cache의 target boundary가 Block Cache 방향으로 이동하여 조금 더 많은 데이터를 Point Cache에 담을 수 있도록 한다. 하지만 만약 실제 데이터가 caching 될 때, target boundary의 크기보다 actual size가 더 커지게 되면 Block Cache의 크기를 줄이는 것이 아니라 Point Cache의 크기를 줄이는 방향으로 설정된다. 반대로 target boundary 보다 actual size가 더 작다면, Block Cache를 evict하는 과정을 통해서 Block Cache의 크기를 줄이고, Point Cache의 크기를 크게 하여 새로운 데이터를 삽입하는 과정을 거친다.
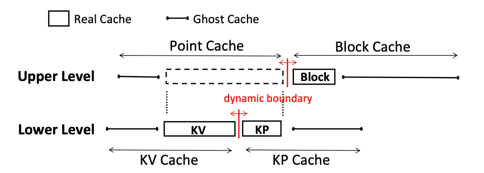
하지만, 여기서 고려해야하는 요소는 하나의 Point Cache에 해당하는 데이터를 caching하기 위해서 Block Cache의 크기를 줄이는 과정에서, 하나의 Block Cache가 evict된다면 이는 cache의 관점에서 봤을 때 trade-off가 성립되지 않는다. 따라서 이러한 경우에는 Point Cache의 ghost cache hit에 의해서 target boundary가 Block Cache 방향으로 이동했을 경우, 하나의 data block 크기 만큼 이동할 때 까지 actual boundary를 이동하지 않는 정책을 사용한다.
Conclusion
Caching은 LSM-tree based Key-Values Stores의 read 성능을 향상시키기 위한 중요 정책이다. Caching policy는 크게 3가지로 나누어 지며, 각각은 Key-Value (KV), Key-Pointer (KP) 그리고 Data Block 을 caching 하는 방법이다. 각각의 cache component의 크기는 dynamic 하게 조절되며 이는 HAC(Hierarchical Adaptive Caching)과 Caching Efficiency Factor 를 이용해서 조절한다. AC-Key는 이러한 방법을 사용해서 서로 다른 3개의 cache component에서 발생할 수 있는 이점을 서로 다른 workload에 맞게 유동적으로 조절할 수 있다.
