Introduction
What is Learned Index
Learned Index란 Kraska et el.이 만든 모델로, 여러 계층의 머신 러닝 모델로 구성되어 있다. Read query가 주어 졌을 떄, 모델의 middle node는 leaf node를 pointing 해주고, leaf node에서는 CDF로 부터 학습된 정보를 바탕으로 압축된 배열에서 query에서 요구하는 key의 위치를 얘측한다. 주어진 데이터의 분포(CDF)를 학습한 모델은 key의 위치를 높은 정확도를 바탕으로 예측할 수 있고, 이는 in-memory index sturucture에 비해 성능적인 면에서 뛰어나다고 볼 수 있다.
Learned Index and LSM-Tree
LSM-tree의 경우에는, Key-Value 형태로 데이터가 구성되어 있으며, 여러개의 파일에 데이터가 분산되어 저장되어 있다. 각각의 파일에는 메타데이터가 존재하는데, 해당 메타데이터는 Bloom filter에 대한 정보와, Index에 대한 정보이다. 각 메타데이터를 통해 쿼리를 처리하는 성능을 향상시킨다.
LSM-tree는 multi-level 구조로 이루어져있는데, 상위 레벨일수록 하위 레벨에 비해 오래된 데이터가 축척되어 있고, 데이터의 양도 방대하다. 만약, 하위 레벨에서 설정한 임계치(Threshold)보다 많은 데이터가 쌓이게 된다면, merge operation을 통해 상위 레벨로 합병이 된다. Merge process는 데이터가 정렬된 순서로 진행이 되게 되는데, 이는 스토리지에 write되기 전에 single-pass training algorithm 통과시킬 수 있는 기회로도 자리잡게 된다. 하지만 선행 연구된 learned index structure는 single-pass training algorithm을 지원하지 않고, 효율적인 build를 지원하지 않는다. 따라서 해당 연구에서는 정렬된 데이터의 single-pass로 하여금 learned index structure을 build할 수 있는 RadixSpline(RS)를 소개한다.
Construct RadixSpline
Build Spline
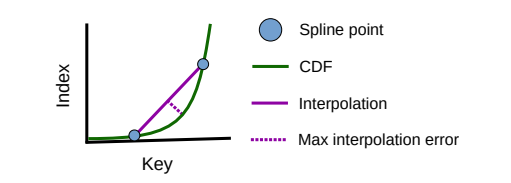
모든 index structure은 look-up key와 position(offset)을 mapping한 structure로 볼 수 있다. Radix Spline Index lookup key와 position을 mapping하기 위해, 우선적으로 spline model S를 만든다. Spline model S는 S(k[i]) = p[i] ± e) error bound e(constant value) 내부에 항상 만족하는 offset이 존재함을 추론하는 model이다.
Model S의 매개변수는 spline points의 집합인데(Knots[s]), 이는 곧 datapoints의 집합을 의미한다. S(x)를 계산하는 연산은 아래와 같이 계산되는데, spline construction algorithm은 다음 논문을 참조하면 된다.
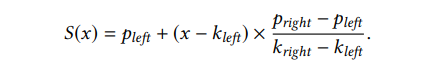
Spline Construction Algorithm Paper: T. Neumann and S. Michel. Smooth interpolating histograms with error guarantees. In Sharing Data, Information and Knowledge, 25th British National Conference on Databases, BNCOD ’08, pages 126–138, 2008.
Build Radix Table
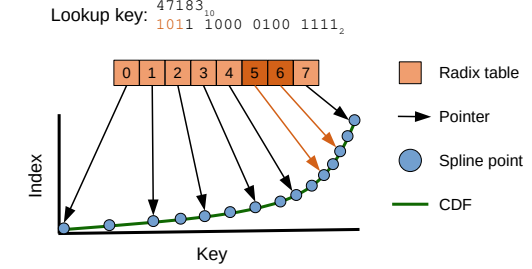
Spline의 생성 후에는, spline points들을 indexing 할 수 있는 radix table을 생성해야 한다. Radix table은 flat uint32_t array로 구성된 자료구조 이며, fixed-length key prefix로 mapping이 되어 있는 구조이다. 생성되는 과정에서 radix table은 radix bits(r)을 매개변수로 받는데, r은 prefix bits를 뜻한다. 가령, r이 18일 경우의 radix table은 총 2r 개의 entry를 가지게 된다. Prefix bit(r)이 커질수록 정확도는 증가하지만, radix table의 크기도 기하급수적으로 커진다. 따라서 table size와 prefix bit 두개의 매개변수의 trade off가 필요하다.
Radix table을 생성하는 과정은 매우 간단하다. 앞서 언급했듯이 2prefix_bit 만큼의 빈공간의 entry를 할당하고, spline을 순회하면서, 새로운 prefix b가 나오면, 해당 prefix에 맞는 radix table entry에 spline point를 insert한다. Spline points가 정렬되어 있기 때문에, radix table도 왼쪽에서 오른쪽으로 prefix에 따라 정렬된 형태를 가지게 된다.
Lookups logic
Lookup logic은 다음과 같다. (아래의 그림을 예시로 든다) 가장 먼저 key의 r-bit prefix를 추출하고(해당 prefix 를 prefix b라고 지칭하자), prefix b를 positioning하고 있는 radix table offset을 찾는다. 이후, radix table의 position b와 b+1이 pointing하는 spline points를 찾는다. 이후, 각각의 spline points로 부터, error bound를 넘지 않는 선까지 binary search를 통해서 찾은 후, (p±e)의 범위에서 query에서 요구하는 key를 binary search로 찾는다.
Conclusion
해당 연구에서는 정렬된 데이터에 적합한 RadixSpline으로 명명하는 새로운 learned index를 소개하였다. RadixSpline은 두개의 hyper parameter를 사용하고, 그렇기 때문에 환경에 따라서 tuning 과정이 어렵지 않다. Future work로는 RadixSpline이 최소한의 user-interaction을 가지고 자동적으로 tuning 하는 방법에 대해 연구할 것이며, 현재는 지원하지 않는 multi-threading을 도입해서 성능을 향상시키는 것에 잠재성을 부여할 것이다.
