Introduction
Byte-addressable 한 특성을 지닌 non-volatile memory(NVM)이 출시는, storage system의 desing을 바꿔야 하는 계기가 되었다. 선행 연구는 DRAM의 특성을 모방하여 NVM에 적용하는 storage system을 소개하였지만, DRAM의 특성과 NVM이 가지는 특성은 사뭇 다른점이 많아 개선점이 필요하다. 가령, 선행 연구는 NUMA effect를 고려하지 않거나 DRAM에 영향을 끼치는 수준 만을 고려해 설계를 하였다. 하지만 선행 연구와 달리 NVM에 NUMA-aware writes를 적용한다면 DRAM에 적용하는 것 보다 훨씬 크게 영향을 줄 수 있다. 따라서 해당 연구는 high-performance persistent indexes를 desing하는 것에 초점을 두었으며, 이후 persistent range index desing에 사용할 것을 목표로 둔다.
Background
Non-Volatile Memory
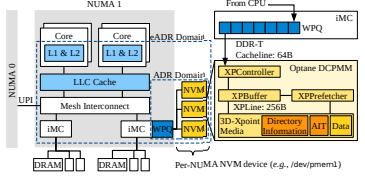
아래 그림은 NVM architecture를 도식화 한것이다. NVM system은 크게 두가지의 persistent domain중 하나를 지원하는데, 두개의 persistent domain은 (1) Asynchronous DRAM Refrash(ADR), (2) enhanced ADR (eADR) mode이다. NVM의 ADR mode에서는 write pending queue(WPQ)를 integrated memory controller(iMC)에 포함이 되어 있으며 이는 persistent domain 에 포함이 된다. 하지만 CPU cache의 volatile한 특성으로 인해, 프로그램은 crash consistency를 위해 memory fence instruction의 한 종류인 cache-line-flush instruction을 사용해야 한다. 따라서, eADR mode에서는 write pending queue(WPQ)를 포함하는 것 이외에도 CPU cache를 persistent domain에 포함시킨다. 하지만 eADR를 아직까지 가능한 기술이 아님으로 현 연구에서는 ADR mode에만 집중한다.
Optane NVM internals
CPU memory controller(iMC)는 Optane NVM과 cache-line granularity(64-byte)로 communication을 한다. 하지만 NVM의 data access granularity는 256-byte이므로, single cache-line size write는 NVM의 data access size보다 작기 때문에 write amplication이 발생한다. 따라서 Optane controller는 write-combining buffer(XPBuffer)와 XPLine prefetcher(XPPrefether)를 도입하였다. 또한 NVM media는 coherence state의 directory정보를 저장하고 있는데, 서로 다른 NUMA domain에 저장되어 있는 정보를 변경하는 coherence state의 modification은 high latency를 유발하고, 이는 cross-NUMA NVM access에 있어서 NVM bandwidth meltdown의 주 원인이 된다.
Design Guidelines for Persistent Indexes
Finding on NVM Hardware
[Prior findings on NVM hardware]
FH1-Prime bottleneck in index structure (Cross NUMA index structure)
FH2-Asymmetric read/write latency and bandwidth (Cause underutilized read)
FH3- Sequential NVM access is preferred (XPPrefetcher and XPBuffer hide NVM latency)
[New findings on NVM hardware]
FH4-NVM's data persistence cost is more expensive than we think
ADR-enabled NVM system은 volatile CPU cache를 포함하고 있기 때문에, persistence instruction인 clwb, sfence등의 instruction이 필요하다. Persistence를 강요하는 것은 매우 느린데, 이는 cache-line-write-back(clwb) instruction이 cache line invalidation과 flushing에 필요한 cost를 모두 동반하기 때문이다.
FH5-Cache coherence protocol impedes NUMA scalability
Single socket은 DIMM slots의 부족함을 야기하기 때문에, multi-socket NUMA system이 도입이 되었고 이는 더 큰 NVM capacity와 high bandwidth를 가능하게 했다. 하지만 remote NUMA access는 매우 느리고, 이는 NVM bandwidth meltdown의 주 원인이 된다. 해당 연구에는 Remote NUMA access의 가장 큰 문제점은 directory coherence protocol으로 발생한다는 것을 발견했다. Remote read operation이 발생하게 되면 coherence state를 Exclusive에서 Shared로 변경하는 작업을 거쳐야 한다(Write operation). 따라서 remote read는 read와 write traffic 모두를 발생시키고, remote read bandwidth가 remote write bandwidth보다 낮다.
Guideline for NVM Systems Software
GS1-Persistent memory allocation is very expensive
NVM allocator는 heap metadata crash consistency를 위해 expensive crash consistency mechanism을 이용한다. 가령 PDDK allocator의 경우에는 single allocation을 위해 6개의 flush instruction을 사용한다. 따라서 빈번한 crash consistency operation으로 인해 NVM allocation으로 부터 발생하는 overhead가 커진다. 반면, 해당 연구에서는 NVM memory allocation과 free의 crash consistency를 보장하지 않는 기존의 Jmalloc을 변형시켜 사용하였다. Jmalloc을 사용했을 때의 결과는 PMDK allocator를 사용했을 때 보다 2배 이상 성능이 좋게 나왔다.
GS2-Persistent memory allocation should be NUMA-aware
선행 연구는 index구조를 single socket에 두어 cross-NUMA access로 부터 발생하는 performance degradation을 방지하고자 했다. 하지만 Single DIMM socket으로는 NVM의 capacity와 bandwidth를 최대화 할 수 없고 이는 NUMA socket를 사용하는 취지와 어긋나게 된다. 따라서 해당 연구에서는 NVM bandwidth를 최대화 하기 위해 index는 모둔 NUMA domain에 위치되어야 하고, allocation을 NUMA-local로 하게끔 하여 NVM communication delay를 피하도록 하는 방법을 고안한다. 해당 문제점은 DRAM에서도 똑같이 문제가 되지만, NVM에 적용되는 영향력이 더 크기 때문에 NVM system software 설계에 기반이 되어야 한다.
Guidelines for Persistent Index Algorithm
GA1-Lookup operation should consume minimal NVM bandwidth
B+Tree와 Trie구조의 NVM bandwidth consumption을 고려했을 때, B+Tree를 사용한 index structure의 NVM bandwidth consumption이 7.7x 정도 NVM reads가 많았고, Trie를 사용한 index structure가 3.7x 정도 높은 throughput을 보인다.
GA2-Read Operation should minimize NVM writes
Lookup, scan과 같은 operation은 NVM read만 유발하는 것이 아닌 NVM write도 유발한다. 가령 lock control을 위해 필요한 variable(Mutex, spinlock or reader-writer lock)의 변경이 필요할 때, NVM write를 수행한다.가령 64M lookup operation은 1.4GB의 NVM write를 유발한다(FastFair 기준).
GA3-Write operation should minimize NVM memory allocation
NVM allocator는 high crash consistency overhead와 NVM write bandwidth를 많이 필요로 하고, 이러한 이유로 scalability에서 bottleneck이 생긴다. 따라서 persistent index는 write operation에서 발생할 수 있는, NVM allocation/free의 발생을 최소화 해야한다.
GA4-Write operation should minimize NVM persistence operation
효율적인 crash consistency machanism은 추가적인 NVM write 또는 expensive persistent operation(clwb 또는 sfence)의 사용을 최소화 해야한다. 가령, consistency를 유지할 필요가 없는 데이터는 consistency를 보장하지 않는 방법을 통해 위와 같은 costly operation의 사용을 줄일 수 있다. 이런 machanism을 통해서 NVM write bandwidth를 보장할 수 있고, critical section의 크기를 줄여 latency 관점에서도 우위를 점할 수 있다.
GA5-Scan operation should maximize sequential read to NVM
앞에서 언급했듯이, NVM은 sequential read의 성능이 random read를 수행할 때 보다 더 좋게 나온다. 따라서 fast scan operation을 위해서는 index구조가 prefetcher를 sequential friendly하게 연속적인 메모리 공간을 access하도록 설계해야하고, cache friendly 하게 설계를 해야한다.
Design Guidelines for Concurrency Control
GC1-Maximize concurrent access for both scalability and full NVM bandwidth utilization
Single-thread로는 NVM bandwidth를 모두 활용(fully utilize) 할 수 없다. 선행 연구에 따르면 8개의 write thread와 20개 혹은 그 이상의 read thread가 있어야지 write 와 read bandwidth를 각각 모두 활용할 수 있다고 한다.
GC2-Minimize the blocking time of structual modification operation
Insert 또는 delete operation은 structual modification operation(SMO)를 유발한다. 가령 B+Tree를 예로 들자면 split/merge operation이 해당한다. SMO operation의 경우 상위 노드에도 structure modification이 일어나기 때문에 modification이 일어나는 node는 critical path로 지정해서 다른 thread가 해당 작업이 완료될 때 까지 접근을 못하도록 block을 해야한다. 이러한 mechanism은 NVM performance degradation을 유발한다.
GC3-An index's data size should not affect the operation progress
NVM을 사용하는 주된 원인중에 하나는 large memory capacity를 확보한 하드웨어이기 때문이다. 따라서 persistent index는 large dataset을 처리하는 것을 기반으로 설계를 해야하고, operation도 large dataset을 target으로 하게끔 설계를 해야한다. 반면, L1 cache size data의 크기만 지원하는 HTM을 사용하는 FP-tree 또는, LB+-tree의 경우에는 dataset이 커지게 되면 abort 되는 횟수가 증가하는 것을 알 수 있다. 따라서 NVM을 사용하는 index structure의 경우에는 large dataset을 target으로 설계를 해야한다.
PACTree Overview
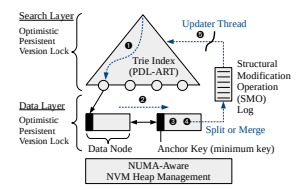
앞에서 언급한 PAC guideline에 따라 현 연구는 trie-based internal node(search layer)와 B+tree style의 leaf node(data layer)를 병합한 hybrid range index를 제시한다. PACTree에서는 search layer와 data layer를 decouple하게 관리를 하는 정책을 채택하고, 이러한 mechanism을 통해 packed NVM access를 수행하도록 한다. 또한 decouple하게 관리함에 있어서 asynchronous하게 관리를 하여 SMO operation에서 발생하는 blocking time을 최소화한다. PACTree는 optimized persistent version of ART인 PDL-ART를 search layer로 사용하고, data layer으로는 slotted leaf node 구조를 사용한다.
ART Primer
ART는 radix tree의 varient이고, 이는 space overhead를 줄인 index structure이다. Radix tree는 많은 poiner chasing을 요구하고, space under-utilization한 index structure이지만, 각각의 node에 여러개의 entry를 두어 space efficiency하게 하고 path compression을 통해 pointer chasing을 최소화 하게 설계한 것이 ART이다. ART는 ROWEX를 반영했는데, 이는 write를 수행할때는 각 node에 exclusive atomic operation을 수행해 consistent하게 유지를 하였고, read를 수행할 때는 non blokcing하게 두었다.
Index Architecture
[Search Layer]
Search Layer는 GA1에서 언급한 바와 같이 minimal NVM bandwidth를 유지하기 위해 trie index structure를 사용한다. Trie structure은 space efficiency한 data structure 일뿐만 아니라, partial key만 comparision을 수행하기 때문에 NVM read bandwidth를 minimal하게 유지하는 장점이 있다.
[Data Layer]
Data Layer는 double linked list 형태로 이루어진 B+tree like leaf nodes로 이루어 져있다. 각각의 node는 다수의 key-value를 저장하고 있으며, 각 node에 insert, delete, update operation을 가능하게 하여 expensive persistent memory allocation을 피하는 정책을 사용한다. 또한 B+-tree의 optimization을 반영하여 fingerprinting과 permutation array를 사용하여 scan operation의 efficiency를 극대화 한다.
Concurrency Control
[Read-optimized concurrency control]
현 연구에서는 read-optimized concurrency control을 위해 optimistic version lock을 사용한다. Optimistic version lock은 node에 version을 두어 특정 read thread가 node에 access하기 전의 version과 node에 access하여 data를 읽은 후의 version을 비교하여, 각각의 version이 일치하지 않는 경우에는 retry하는 정책이다. 이는 GA2에서 언급한 바와 같이, mutex 또는 spinlock과 같은 lock variable의 변경이 read thread에 요구되지 않기 때문에 read operation이 부가적인 NVM write를 수행하지 않는다. 또한 HTM based approach와 달리, node의 size에는 민감하게 작용되지 않기 때문에 footprint와 같은 metadata들이 추가되어도 영향이 없다.
[Asynchronous structual modification]
HydraList와 유사한 방법으로, 여러개의 노드들이 변경되어야 하는 search layer의 경우에는 asynchornization하게 update를 하고, data layer의 경우에는 노드들이 변경이 된다고 하더라도 추가적인 allocation/free가 특정한 상황에만 일어나기 때문에(merge/split), data layer에는 synchronization하게 update를 한다. 또한 search layer에는 modification이 적용되지 않았기 때문에 inconsistency를 유발할 수 있는데, 해당 연구는 ephemeral inconsistency tolerable design을 적용해 search layer의 inconsistency가 data layer의 inconsistency로 이어지지 않게 한다. 즉, adjacent한 data layer에 위치한 node에 jump를 하여 여기서 부터 sequential search를 통해 query에서 원하는 key-value를 lookup 할 수 있는 것이다.
Crash Consistency
[Mostly log-free crash consistency]
PACTree는 crash consistency를 위해 expensive logging technique을 사용하지 않는다. 대신에, data node에 valid bitmap을 두어 consistency를 유지한다. Valid bitmap은 write로 이해 쓰여진 data의 valid 유무를 체크하는 bitmap이며 이를 통해 해당 data가 valid한지 판단한다.
[Selective persistence in a data node]
FH4에서 언급한 바와 같이, consistency를 유지할 필요가 없는 data node에는 crash consistency를 위한 persistent한 정책을 사용하지 않는다. 가령, fast scan operation을 위해 존재하는 permutation array와 같은 경우에는 recomputed 될 수 있기 때문에 crash consistency를 적용하지 않는다.
