
Original Paper : Prompt Design and Engineering (https://arxiv.org/pdf/2401.14423)
💭Motivation
지난주부터 인턴 생활을 시작하고 태스크를 수행하면서 체계적인 프롬프팅의 중요성에 대해서 새삼 다시 깨닫게 되었다.
기존에 동아리에서 모델 프롬프팅을 진행할 때는 내 요구사항을 두서없이 작성하는 경우가 많았는데, 프롬프트에 따라서 답변이 달라지는 경우가 많았다. 당시에는 "프롬프팅 = 내가 원하는 걸 다 글로 쓰기" 정도로 생각했고 큰 비중을 두지 않았지만, 회사에서 업무를 하면서 전문적인 이해가 필요하다고 느껴 이와 관련된 논문을 읽어보았다.
새로운 방법론에 대한 내용이 아니라 기존의 방법론을 통합한 데에 의의를 두고 있는 논문이므로 가볍게 읽는 것을 추천한다. 더불어 같은 소재에 대한 내용이 여기저기 산발되어 있어 원문의 목차를 그대로 따르지는 않는다는 점을 참고하길 바란다.
📄Paper Review
0. Abstract
프롬프트 설계와 엔지니어링은 LLM의 잠재력을 극대화하기 위해 빠르게 필수적인 영역이 되고 있다. 본 논문에서는 핵심 개념과 함께, Chain-of-Thought, Reflection과 같은 고급 기법과 LLM 기반 에이전트 구축 원리를 소개한다.
1. Introduction
생성형 AI 모델에서 프롬프트란 사용자가 모델의 출력을 유도하기 위해 입력하는 텍스트를 말한다. 이는 단순한 질문에서부터 상세한 설명이나 특정 과업 지시까지 다양하다.
- 이미지 생성 모델(DALL·E 3) : 묘사적인 프롬프트
- LLM(GPT-4, Gemini 등) : 간단한 질의부터 복잡한 문제 진술까지 폭넓게 사용
프롬프트는 일반적으로 지시문, 질문, 입력 데이터, 예시 등으로 구성된다. 이 중 원하는 응답을 얻기 위해서는 최소한 지시문이나 질문이 포함되어야 하며, 나머지 요소들은 선택적이다.
기본적인 프롬프트는 단순히 질문을 던지거나 특정 작업을 지시하는 형태다. 반면, 고급 프롬프트는 더 복잡한 구조를 가지며, 예를 들어 Chain-of-Thought prompting은 모델이 논리적 추론 과정을 따라가며 답변하도록 유도한다.
2. LLMs and Their Limitations
Transformer 아키텍처 기반의 LLM은 방대한 데이터로 사전 학습되어 뛰어난 언어 능력을 보이고 있지만, 본질적인 한계로 인해 활용과 효과성에서 제약을 가진다.
-
일시적 상태
LLM은 지속적인 기억이나 상태를 유지하지 못하므로, 맥락 보존과 관리에는 별도의 소프트웨어나 시스템이 필요하다. -
확률적 특성
동일한 프롬프트에도 매번 응답이 달라질 수 있다. 이러한 변동성은 일관성이 중요한 응용에서 어려움을 초래한다. -
구식 정보
LLM은 사전 학습 데이터에 의존하기 때문에 실시간 정보나 최신 지식을 반영하지 못한다. -
내용 왜곡
그럴듯하지만 사실과 다른 정보를 생성할 수 있으며, 이는 흔히 환각(hallucination)이라 불린다. -
자원 집약성
LLM은 거대한 규모로 인해 막대한 연산 자원과 비용을 필요로 한다. 이는 확장성과 접근성을 제한하는 요인이 된다. -
도메인 특수성
LLM은 본질적으로 범용 모델이지만, 특수 분야의 과업에서는 도메인별 데이터가 필요하다. 그렇지 않으면 전문성을 요구하는 작업에서 성능이 떨어질 수 있다.
3. More advanced prompt design tips and tricks
(1) Chain of Thought (CoT)
모델이 일련의 추론 단계를 따라가도록 강제함으로써 사실적이고 정확한 답변을 하도록 명시적으로 유도한다. 다시 말해, LLM의 암묵적인 추론 단계를 명시적이고 안내된 순서로 변환함으로써, 특히 복잡한 문제 해결 맥락에서 논리적 추론에 기반한 출력을 생성하는 능력을 강화한다.
“Original question?
Use this format:
Q: <repeat_question>
A: Let’s think step by step. <give_reasoning> Therefore, the answer is <final_answer>.”
[그림1] Chain of Thought (출처 : 논문 발췌)
CoT는 주로 다음 2가지 변형으로 나타난다.
1. Zero-Shot CoT
LLM이 문제를 단계적으로 풀어나가도록 유도하여, 추론 과정을 한 걸음씩 설명하게 한다.
2. Manual CoT
명시적이고 단계적인 추론 예시를 템플릿으로 제공해 모델이 더 확실히 추론 기반 출력을 내도록 유도한다. 효과적이지만, 예시를 세심하게 설계해야 하므로 확장성과 유지보수에 어려움이 따른다.
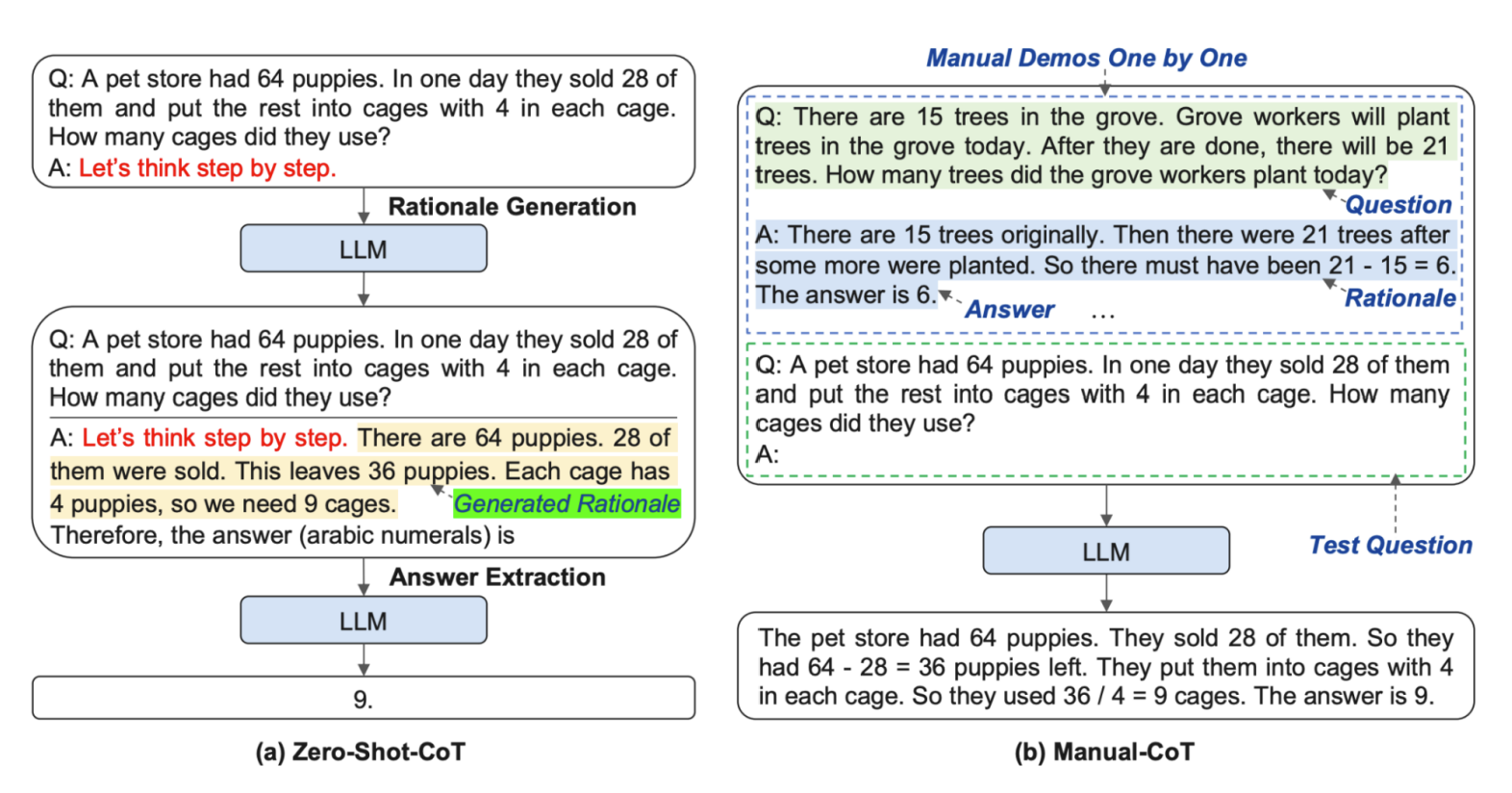
[그림2] Zero-Shot-CoT vs. Manual-CoT (출처 : 논문 발췌)
(2) Getting factual source
생성 모델의 가장 중요한 문제 중 하나는 사실이 아니거나 잘못된 지식을 hallucination 형태로 만들어낼 가능성이 높다는 점이다.
이는 3.1 의 Chain of Thought 방법 뿐만 아니라 올바른 출처를 인용하도록 프롬프트를 작성함으로써 모델을 올바른 방향으로 유도할 수도 있다.
다만, 인용 자체도 환각되거나 지어낼 수 있기 때문에 이 접근에는 심각한 한계가 있다.
“Are mRNA vaccines safe? Answer only using reliable sources and cite those sources.
[그림2] Getting factual source (출처 : 논문 발췌)
(3) Tree of Thought (ToT)
Tree of Thought(ToT)는 최근 연구에서 제시된 것으로, 인간의 인지 과정을 본떠, 문제 해결 경로를 다각도로 탐색하도록 돕는다. 즉, 최종적으로 가장 그럴듯한 해답을 도출하기 전에 가능한 여러 해결책을 고려하는 방식과 유사하다.
(해당 내용은 프롬프팅 설계보다는 구조에 대한 기법이다.)
e.g. 여행 계획 : 항공편, 기차 노선, 렌터카 시나리오 등 다양한 옵션으로 분기하여 각각의 비용과 실행 가능성을 따져본 뒤, 사용자에게 가장 최적의 계획을 제안
생각의 나무(thought trees)
- ToT의 핵심 개념
- 각 가지는 대체적인 추론 경로를 나타내며, 이를 통해 LLM은 다양한 가설을 탐색
- 인간이 여러 시나리오를 저울질한 뒤 가장 가능성 높은 결론에 도달하는 문제 해결 방식을 반영
이러한 추론 가지들을 체계적으로 평가하는 것이 중요
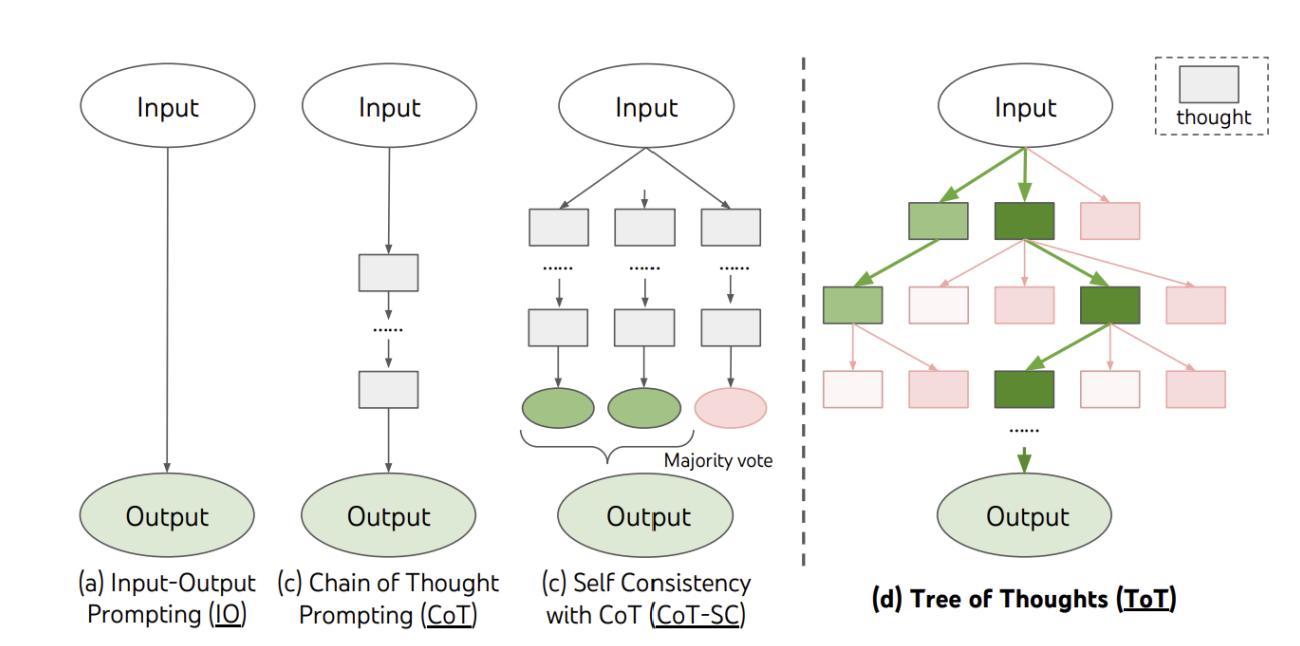
[그림3] Tree of Thought (출처 : 논문 발췌)
(4) Explicitly ending the prompt instructions
GPT 기반 LLM에는 |endofprompt|라는 특별한 메시지가 있는데, 이는 언어 모델에게 해당 코드 이전까지가 프롬프트였고, 이후는 답변 생성 시작 지점이라고 해지시한다. 이를 통해 일반적인 지시문과, 예를 들어 모델이 실제로 작성해야 할 시작 부분을 명확히 구분할 수 있다.
Write a poem describing a beautiful day <|endofprompt|>. It was a beautiful winter day아래 [그림4]의 결과에서 볼 수 있듯, LLM 답변이 프롬프트의 마지막 문장에서부터 이어진다.

[그림4] Special tokens can sometimes be used in prompts (출처 : 논문 발췌)
(5) Being forceful
언어 모델은 항상 친절하고 부드러운 표현에 잘 반응하지는 않는다. 어떤 지시를 정말로 따르게 하고 싶다면, 강한 어조를 사용할 필요가 있다. 예를 들어, 대문자와 느낌표 등은 정말로 효과가 있다.
[그림5] Don’t try to be nice to the AI (출처 : 논문 발췌)
(6) Generate different opinions
(3.5.는 생략)
LLM은 무엇이 참인지 거짓인지에 대한 강한 인식을 가지고 있지 않지만, 서로 다른 의견을 생성하는 데에는 꽤 능숙하다. 이는 어떤 주제에 대해 브레인스토밍을 하거나 다양한 관점을 이해하는 데 유용한 도구가 될 수 있다.
이어지는 예시에서는 온라인에서 찾은 기사를 입력한 뒤 ChatGPT에게 그것에 ‘반대 의견’을 제시하라고 요청한다. 이때 모델을 안내하기 위해 <begin>과 <end> 태그를 사용하였다.
<begin >
From personal assistants and recommender systems to self-driving cars and natural language processing, machine learning applications have demonstrated remarkable capabilities to enhance human decision-making, productivity and creativity in the last decade. However, machine learning is still far from reaching its full potential, and faces a number of challenges when it comes to algorithmic design and implementation. As the technology continues to advance and improve, here are some of the most exciting developments that could occur in the next decade.
1. Data integration: One of the key developments that is anticipated in machine learning is the integration of multiple modalities and domains of data, such as images, text and sensor data, to create richer and more robust representations of complex phenomena. For example, imagine a machine learning system that can not only recognize faces, but also infer their emotions, intentions and personalities from their facial expressions and gestures. Such a system could have immense applications in fields like customer service, education and security. To achieve this level of multimodal and cross-domain understanding, machine learning models will need to leverage advances in deep learning, representation learning and self-supervised learning, as well as incorporate domain knowledge and common sense reasoning.
2. Democratization and accessibility: In the future, machine learning may become more readily available to a wider set of users, many of whom will not need extensive technical expertise to understand how to use it. Machine learning platforms may soon allow users to easily upload their data, select their objectives and customize their models, without writing any code or worrying about the underlying infrastructure. This could significantly lower the barriers to entry and adoption of machine learning, and empower users to solve their own problems and generate their own insights.
3. Human-centric approaches: As machine learning systems grow smarter, they are also likely to become more human-centric and socially aware, not only performing tasks, but also interacting with and learning from humans in adaptive ways. For instance, a machine learning system may not only be able to diagnose diseases, but also communicate with patients, empathize with their concerns and provide personalized advice. Systems like these could enhance the quality and efficiency of healthcare, as well as improve the well-being and satisfaction of patients and providers.
<end>
Given that example article, write a similar article that disagrees with it.(7) Reflection
Reflection의 핵심은 모델이 자신의 출력을 성찰적으로 검토하는 과정에 참여하는 것으로, 이는 인간이 글을 스스로 교정하는 과정과 유사하다. 이 과정에서 모델은 초기 응답을 사실적 정확성, 논리적 일관성, 전반적 관련성 측면에서 평가한다.
Reflection 과정은 구조화된 자기 평가로 이루어진다.
- 초기 응답 생성
- 1.의 출력을 비판적으로 검토하도록 프롬프팅
- 자기 성찰을 통해 모델은 잠재적 오류나 불일치를 식별하고, 더 일관되고 신뢰할 수 있는 수정된 응답을 생성
Reflection 구현의 한계점
자기 평가의 정확성은 모델의 내재적 이해력과 성찰적 과제 학습 여부에 달려 있다. 또한 모델이 응답 품질을 잘못 평가할 경우, 오히려 자신의 오류를 강화할 위험도 있다.
→ 그러나 이러한 한계점에도 불구하고 Reflection이 LLM 발전에 주는 함의는 매우 크다. 자기 평가와 수정 능력을 통합함으로써, LLM은 출력 품질을 스스로 개선할 수 있는 더 큰 자율성을 가지게 된다.
(8) Expert Prompting
Expert Prompting은 LLM이 다양한 분야에서 전문가 수준의 응답을 시뮬레이션할 수 있도록 한다. 이 방법은 LLM이 특정 분야 전문가의 페르소나(persona)를 부여받아, 더 깊이 있고 정교한 답변을 생성하도록 유도하는 데 초점을 둔다.
다중 전문가 전략(multi-expert strategy)
LLM이 여러 전문가의 관점을 고려하고 통합하도록 설계함으로써, 실제 전문가들의 협의 과정을 모방한다. 이로써 응답의 깊이와 폭이 확대될 뿐만 아니라, 복잡한 문제를 다차원적으로 이해하는 능력을 제공한다.
e.g. 의료 관련 질문
- 임상의, 의학 연구자, 공중보건 전문가의 관점을 차례로 반영하도록 프롬프팅
- 다양한 시각을 정교한 알고리즘을 통해 통합하여 질문에 대한 포괄적 이해가 담긴 응답을 산출
이러한 전문가 관점의 합성은 LLM 출력의 사실적 정확성과 깊이를 강화하는 동시에, 단일 관점에서 발생할 수 있는 편향을 완화하여 균형 잡힌 응답을 제공한다.
Expert Prompting 구현의 한계점
- 실제 전문가 지식의 깊이를 시뮬레이션하려면 고도화된 프롬프트 설계와 해당 분야에 대한 세밀한 이해가 필요
- 상충할 수 있는 전문가 의견을 하나의 일관된 응답으로 조율해야 함
→ 그럼에도 불구하고 공학 분야의 정교한 기술적 조언부터, 법률 논의에서의 심층적 분석까지 적용할 수 있다.
(9) Rails in Advanced Prompt Engineering
Rails는 LLM의 출력을 사전에 정의된 범위 안으로 유도하여, 관련성, 안전성, 사실적 정확성을 보장하는 전략적 접근을 의미한다. 이 방식은 Canonical Forms라 불리는 구조화된 규칙이나 템플릿을 활용하는데, 이는 모델의 응답이 특정 기준이나 표준에 부합하도록 하는 틀 역할을 한다.
Rails의 설계와 구현은 응용 목적에 따라 다양하게 달라질 수 있다.
- Topical Rails : LLM이 특정 주제나 도메인에 집중하도록 설계되어, 주제 이탈이나 무관한 정보 삽입을 방지
- Fact-Checking Rails : 검증되지 않은 주장이나 추측을 억제하고 증거 기반 응답으로 유도하여 부정확한 정보 확산 감소
- Jailbreaking Rails : 모델이 운영 제한이나 윤리적 가이드라인을 우회하지 못하도록 하여 오용이나 유해한 콘텐츠 생성을 방지
Rails는 다양한 실제 활용에 적용될 수 있다.
- 교육 도구 : Topical Rails가 콘텐츠의 주제 적합성을 보장
- 뉴스 집계 서비스 : Fact-Checking Rails가 정보의 무결성을 유지
- 상호작용형 애플리케이션 : Jailbreaking Rails를 통해 모델이 바람직하지 않은 행동을 하지 못하도록 방지
Rails의 한계점
- 세밀한 규칙 정의가 필요
- 지나친 제약으로 모델의 창의성을 억누를 위험이 있음
→ 신뢰성, 윤리성을 보장하면서도 창의성과 유연성을 해치지 않는 균형이 중요
4. Conclusion
LLM과 생성형 AI가 진화함에 따라, 프롬프트 설계와 엔지니어링의 중요성은 더욱 커질 것이다. 본 논문에서는 기초부터 정교한 접근법까지 살펴보았으며, 이는 차세대 지능형 애플리케이션을 위한 필수 도구로 자리매김하고 있다.
프롬프트 설계와 엔지니어링이 빠르게 발전하는 만큼, 이러한 자료들은 초기 기법들을 역사적 관점에서 되돌아보게 해줄 것이다.
🤔 My Thoughts
- 사실 다른 논문을 골라서 읽다가 기법 나열에 그치는 수준이라서 본 논문으로 바꿔서 읽었다.
- 아무리 프롬프트 관련 내용을 모아서 정리했다고 해도 여전히 구체성이 부족한 느낌이 크다.
- 추후 패스트캠퍼스, 유튜브 같은 플랫폼에서 강의를 듣고, 손품 팔면서 얻은 정보를 하나의 글에 정리하려고 한다.
