Original Paper (Arxiv) : Wide&Deep (https://arxiv.org/pdf/1606.07792)
📥Background
1. 협업 필터링 (Collaborative Filtering, CF)
"비슷한 사용자 들이 좋아한 아이템을 추천하자"
(1) 원리
- 사용자와 아이템간의 상호작용 기록 (e.g. 클릭, 좋아요, 구매 등)만을 기반으로 추천
- 사용자-아이템 행렬(Interaction Matrix)을 구성하여 행은 사용자, 열은 아이템, 셀 값은 행동 기록 (e.g. 평점, 클릭 여부 등)
(2) 방식
| 종류 | 설명 |
|---|---|
| User-based CF | 나와 비슷한 행동을 한 사용자들이 좋아한 아이템 추천 |
| Item-based CF | 내가 좋아한 아이템과 유사한 아이템을 추천 |
(3) 장점
- 아이템 속성 정보 없이도 추천 가능
- 직관적이고 구현이 간단
(4) 단점
- 콜드 스타트 문제: 신규 유저 및 아이템에 대한 정보 부족
- 희소성 문제: 대부분의 사용자-아이템 조합이 비어 있음 (Sparse Matrix)
2. 콘텐츠 기반 필터링 (Content-Based Filtering)
"사용자가 과거에 좋아한 아이템 과 유사한 아이템을 추천하자.”
(1) 원리
- 아이템의 속성(메타데이터)과 사용자의 과거 행동 기록을 분석
- e.g. 사용자가 공포 영화를 좋아했다면, 유사한 장르/감독/배우가 있는 영화를 추천
(2) 사용 예시
- 영화 추천 시: 장르, 감독, 배우 등의 feature vector를 기반으로 유사도 계산 (cosine similarity 등)
(3) 장점
- 사용자마다 개인화된 추천 가능
- 새로운 아이템도 속성만 알면 추천 가능 → 신규 아이템 콜드 스타트 문제 완화
(4) 단점
- 사용자의 취향이 고정되기 쉬움 (Serendipity 부족)
- 유저 프로파일링이 어렵거나 부정확할 수 있음
📄Paper Review
0. Abstract
추천 시스템에서는 과거의 feature 조합을 외우는 기억(memorization)과 본 적 없는 조합에도 잘 대응하는 일반화(generalization) 두 가지 능력이 모두 중요하다. 기존 선형 모델은 기억력에, 딥러닝은 일반화에 강점이 있다. 본 논문에서는 두 가지 접근을 하나의 구조로 결합한 Wide & Deep 모델을 제안하고, Google Play 앱 추천에 적용하여 성능 향상을 확인했다.
1. Introduction
(1) 기존 방식의 문제점 및 한계점
추천 시스템은 사용자와 아이템간의 상호작용을 예측하는 것이 핵심이다. 특히, 본 논문의 실험에서 다룰 앱 스토어 추천은 로그 데이터와 피처 엔지니어링에 크게 의존한다. 앞서 초록에서 언급한 바와 같이 중요한 요소는 다음 두 가지이다.
- memorization : 복잡한 피처 조합을 잘 기억
- generalization : 이전에 보지 못한 조합에도 잘 대응
기존의 모델들 중에는 다음 2가지를 동시에 충족하는 모델이 없었다.
- Wide models (선형 모델) : memorization에는 강하지만, 새로운 상황에 일반화가 어려움
- Deep models (신경망 기반) : generalization은 잘하지만, 희귀하거나 명시적인 규칙 학습은 어려움
이에 저자는 이 두 모델을 결합한 Wide & Deep 모델을 제안한다. 해당 모델은 다음 2개의 파트를 갖고 있다. wide와 deep을 동시에 학습한 후, 최종 출력은 sigmoid에 통과하여 확률을 예측한다.
- wide part : 명시적 피처 조합 학습 (memorization)
- deep part : 임베딩과 MLP로 일반화 능력 확보 (generalization)
본 모델은 Google Play의 앱 추천 시스템에 실제로 사용되었고, A/B 테스트 결과, 기존 방식보다 앱 설치율이 유의미하게 향상되었다.
2. RECOMMENDER SYSTEM OVERVIEW
본 논문은 Google Play의 앱 추천 시스템 실험 사례를 다루고 있으므로 다음과 같은 개념에 대한 이해가 필요하다.
- Query 생성
- 사용자가 앱스토어를 방문할 때 생성됨
- 포함되는 피처
- 사용자 정보: 국가, 언어, 성별 등
- 컨텍스트 정보: 디바이스, 시간대, 요일 등
- Retrieval 단계 (후보군 생성)
- 전체 앱이 백만 개 이상이므로, 모든 앱을 실시간으로 평가하는 건 불가능하기 때문에 retrieval 단계에서 후보 앱을 소수만 뽑아냄 (e.g. 수십~수백 개)
- 방식 : 규칙 기반 + 머신러닝 모델을 함께 사용
- Ranking 단계 (최종 정렬)
- Retrieval 단계에서 얻은 후보 앱들을 대상으로 정밀한 점수 계산 수행
- 예측 점수(확률) :
- : 사용자 행동 (e.g. 클릭, 설치 등)
- : 다양한 피처들 (e.g. user, context, impression 등)
→ 📍Wide & Deep 모델은 3. Ranking 단계에 사용된다
3. WIDE & DEEP LEARNING
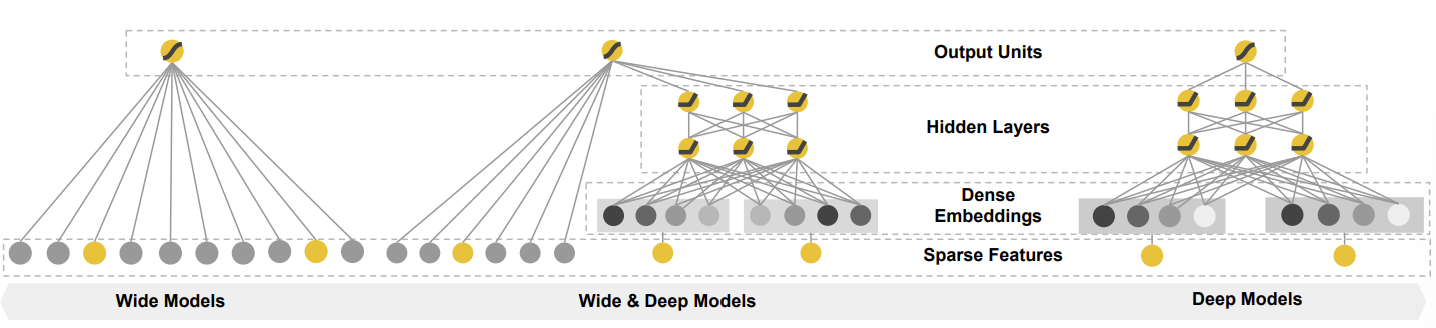
[그림1] Wide & Deep 전체 구조 (출처: 논문 발췌)
3.1 The Wide Component
Introduction 에서 언급한 바와 같이 Wide 파트는 memoriztion을 위한 부분으로, 일반화 선형 모델이 핵심이다. 수식은 다음과 같다.
- : 입력 피처 벡터
- : 학습가능한 가중치
- : bias 항
📍문제는 선형 모델은 피처 간의 상호작용을 직접 표현하지 못한다는 것이다. 따라서 비선형성을 도입하기 위해 교차 피처를 수동으로 설계해줘야 한다.
교차 피처는 다음과 같은 형태로 정의된다.
- 이면 가 에 포함
- 이면 가 에 포함X
예를 들어, 성별이 female이고 언어는 english인 경우에 대해서 다음과 같이 표현할 수 있다.
이렇게 구성된 교차 피처들은 원래의 피처 로 사용되어 전체 수식은 다음과 같이 표현된다.
3.2 The Deep Component
Deep 컴포넌트는 feed-forward 방식의 신경망으로 구성되며, 주로 범주형 피처를 처리한다. 즉, 원래의 문자열 형태(language=en)로 되어 있으며, 모델에 입력되기 위해 다음과 같은 과정을 거친다.
(1) Embedding
범주형 피처는 고차원의 sparse one-hot 벡터 대신, 학습 가능한 저차원의 dense embedding vector로 변환된다.
- 임베딩 차원은 보통 ( O(10) ~ O(100) ) 수준
- 임베딩 벡터는 학습 초기에는 랜덤하게 초기화되며, 모델 학습 과정에서 최종 loss를 최소화하도록 업데이트됨
(2) Feed-forward Neural Network
임베딩된 벡터들을 concatenate한 후, MLP에 입력한다. 각 은닉층에서는 다음과 같은 연산이 이루어진다.
- : 번째 층의 출력 (activation)
- : 가중치 행렬
- : 바이어스 벡터
- : 비선형 활성화 함수 (주로 ReLU 사용)
이 과정을 반복하여 마지막 은닉층까지 진행한 후, 최종 출력은 Wide 컴포넌트와 함께 결합되어 sigmoid 함수를 통과시켜 확률로 출력된다.
3.3 Joing Training of Wide & Deep Model
Wide & Deep 모델은 예측 시 두 모델의 출력을 가중합하여 사용하며, 이를 하나의 공통 logistic loss 함수에 넣어 동시에 학습(joint training)한다.
앙상블과의 차이점
- 앙상블 : 각각의 모델을 따로 학습 → 예측 시점에서만 결과를 결합
- 조인트 트레이닝: 학습 단계에서부터 두 모델을 동시에 최적화 → 파라미터들이 서로 영향을 주며 학습됨
최종 예측 수식 (Logistic Regression)
- : 시그모이드 함수
- : 교차 피처 (cross-product transformations)
- : Deep component의 마지막 은닉층 출력
- : Wide part의 가중치
- : Deep part의 가중치
- : bias 항
Optimizer
- Wide part : FTRL (Follow-The-Regularized-Leader) + L1 정규화
- Deep part : AdaGrad 사용
- 학습은 미니배치 SGD 기반의 backpropagation으로 이루어짐
장점
- Wide와 Deep이 서로를 보완하면서 학습됨
- Deep의 일반화 성능은 유지하면서, Wide가 부족한 부분을 보완
- 전체 모델 크기를 줄이면서도 성능 확보 가능
4. SYSTEM IMPLEMENTATION
Wide & Deep 모델 학습을 위한 추천 파이프라인은 다음의 세 단계로 구성된다.
- Data Generation
- Model Training
- Model Serving
4.1 Data Generation
(1) 입력 데이터
일정 기간 동안의 사용자 행동 데이터 + 앱 노출(impression) 데이터를 사용한다. 각 row는 하나의 앱 노출을 의미하며, 라벨은 아래와 같이 정의된다.
(2) 범주형 피처 전처리 (Categorical Features)
모든 범주형 문자열 피처는 학습 전에 정수 ID로 매핑된다. 이 과정을 통해 vocabulary table이 생성되며, 문자열이 정수로 변환된다. 이때, 특정 피처 값이 최소 등장 횟수를 넘을 때만 vocabulary에 포함된다.
(3) 연속형 피처 전처리 (Continuous Features)
연속형 피처는 누적 분포 함수(CDF) 기반으로 정규화된다. 모든 값은 구간 [0, 1]로 매핑되며, 분위수(quantile) 기준으로 나눠진다.
- : 해당 값이 속한 분위수 (quantile) 인덱스
- : 전체 분위수 개수
분위수 구간은 데이터 생성 시점에 계산되어 저장된다.
이 과정을 통해 모델 학습에 사용될 입력 데이터와 vocabulary가 모두 준비된다.
4.2 Model Training
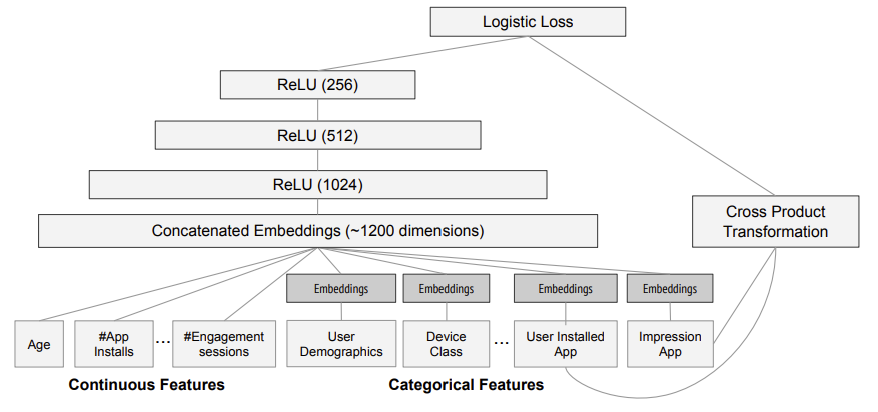
[그림2] 앱 추천 시스템을 위한 Wide & Deep 구조 (출처: 논문 발췌)
(1) 입력 구성
- 입력 데이터와 vocabulary table을 기반으로 sparse + dense 피처를 생성
- 라벨은 앞서 생성된 impression → app install 여부 (0 or 1)
(2) Wide Component 구성
Wide 파트는 사용자가 설치한 앱과 현재 impression 앱 간의 cross-product transformation
(3) Deep Component 구성
- 각 범주형 피처는 32차원 임베딩 벡터로 표현됨
- 모든 임베딩 벡터 + 연속형 피처를 하나의 벡터로 concatenate
→ 약 1200차원의 dense vector가 생성됨
이때 마지막 출력층은 로지스틱 회귀 유닛으로 구성되어 확률을 예측한다.
(4) Warm-start Training
- 전체 학습 데이터는 5000억 개 이상
- 새로운 데이터가 들어올 때마다 학습을 다시 시작하면 매우 비효율적이므로, 이전 모델의 임베딩과 선형 가중치를 가져오는 warm-start 기법 사용
(5) 검증 (Dry Run & Sanity Check)
- 학습 완료 후 실제 서빙 전에 dry run을 통해 문제 없는지 확인
- 이전 모델과의 품질 비교도 함께 수행
4.3 Model Serving
학습이 완료된 모델은 실제 사용자 트래픽에 대응하기 위해 model servers에 배포되었다.
요청 처리 흐름
- 앱 retrieval 시스템이 후보 앱 목록을 생성
- Wide & Deep 모델이 사용자 피처와 함께 각 앱을 점수화(score)
- 예측 확률이 높은 순으로 앱을 정렬하여 사용자에게 노출
고속 서빙을 위한 최적화
- 서빙 지연(latency)를 줄이기 위해, 단일 대규모 배치 대신 소규모 배치들을 병렬 처리
- 이를 통해 10ms 수준의 응답 속도를 달성
📍Wide & Deep 모델은 대규모 데이터에도 대응 가능하면서, 실시간 추천 시스템에서도 효율적으로 작동할 수 있도록 설계되었다.
5. EXPERIMENT RESULTS
Wide & Deep 모델의 효과를 검증하기 위해 실제 Google Play 앱 추천 시스템에 적용하여 A/B 테스트를 진행했다. 주요 실험 결과는 다음과 같다
- 실험 환경: Google Play 추천 시스템에 실 서비스 적용
- 비교 모델:
- Wide-only (선형 모델만 사용)
- Deep-only (신경망 모델만 사용)
- Wide & Deep (조인트 모델)
주요 결과
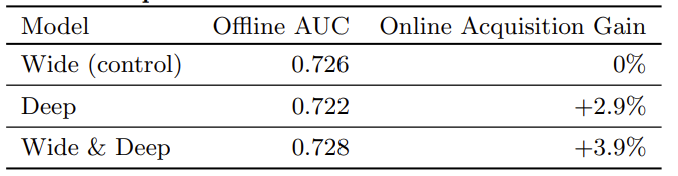
[그림3] 오프라인, 온라인 평가지표. 이때 온라인 평가지표의 경우 wide를 control 그룹으로 두고 계산 (출처: 논문 발췌)
Wide & Deep 모델이 Wide-only와 Deep-only 각각의 성능을 상호 보완하며 앱 설치율에서 가장 우수한 성능을 보였다.
실험 결론
Wide 모델의 memorization 능력과 Deep 모델의 generalization 능력이 결합되면서 사용자 맞춤 추천의 정확도와 실제 전환율(앱 설치율)이 모두 향상되었다.
6. Conclusion
추천 시스템에서 memorization과 generalization은 모두 중요하다.
- Wide 모델은 cross-product transformation을 통해 희소한 피처 조합을 기억하는 데 강점을 가짐
- Deep 모델은 embedding을 통해 이전에 등장하지 않은 피처 조합을 일반화할 수 있음
이 논문에서는 두 모델의 장점을 결합한 Wide & Deep Learning 프레임워크를 제안하고 이를 Google Play 앱스토어의 추천 시스템에 실제 적용한 결과, Wide-only 또는 Deep-only 모델보다 앱 설치율이 유의미하게 향상되었음을 확인했다.
🤔 My Thoughts
- 원래 DeepFM보다 이 논문을 먼저 리뷰했어야 했는데, 미리 적어둔 것을 까먹고 DeepFM부터 다루었다.
- 결국엔 두 마리 토끼를 다 잡으려고 hybrid로 엮었다는 얘기이다.
- 2016년에 발표된 논문이기 때문에 후속 논문들을 읽을 때 참고하는 정도로 가볍게 읽기 좋은 논문이다.
- Wide component에서 수동으로 피처를 조정해야 한다는 점이 사용자로 하여금 매력을 덜 느끼게 하는 요소인듯하다.
