Original Paper (Arxiv) : seq2seq (https://arxiv.org/pdf/1409.3215)
논문에는 자세히 나와있지 않은 내용들이 많아서 wikidocs를 참고하여 작성함. https://wikidocs.net/24996
📥Background
기존 RNN 모델들의 한계점
(1) 고정된 입력과 출력 길이
- vanilla RNN 모델은 입력과 출력 길이가 동일한 경우에만 효과적으로 동작함.
🔍WHY?
RNN은 각 입력마다 하나의 출력을 생성함. 따라서 입력과 출력의 개수가 서로 대응됨. - 그러나 문장 번역, 요약 등 다양한 자연어 처리 문제에서는 입력과 출력의 길이가 다를 수 있음.
[예시1] 영→한 번역
- 영어 문장 : I love you, too. [4개 단어]
- 한국어 문장 : 나도 너를 사랑해. [3개 단어]
[예시2] 요약
- 입력 : 이 영화는 매우 감동적이며, 특히 마지막 장면이 인상적이다. [8개 단어]
- 출력 : 감동적인 영화 [2개 단어]
(2) 문장 전체를 고려하지 않는 변환
- vanilla RNN 혹은 LSTM의 경우, 단어를 한 개씩 입력받아 즉각적으로 출력하는 방식
- 즉, 문장 전체를 보고 변환하는 것이 아니라 이전까지의 정보만 참고하여 순차적으로 처리함.
- 따라서 긴 문장의 전체 의미를 유지하는 것이 어려움.
📄Paper Review
0 Abstract
- 기존 DNN은 정해진 정답 값들이 많은 경우, 좋은 성능을 보이지만, 하나의 시퀀스를 입력 받아서 새로운 시퀀스로 출력하는 것에는 사용할 수 없음.
- multi-layerd LSTM을 사용함
multi-layered LSTM
- 한 time step에 여러 개의 LSTM을 쌓은 것
- 가중치는 모두 같음
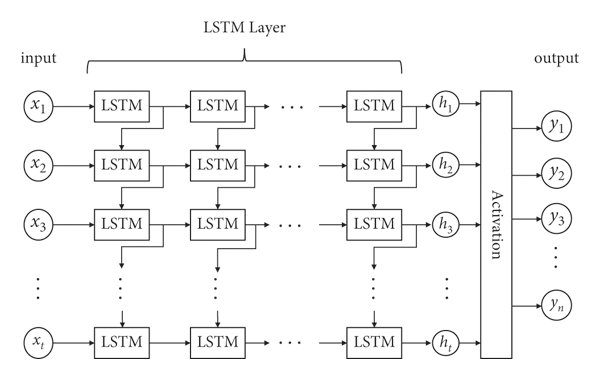
[그림1] multi-layered LSTM (출처 : https://www.researchgate.net/figure/Multilayer-LSTM-network-structure_fig3_361636795)
-
논몬의 주요 결과는 WMT' 14 dataset를 통해 영어를 프랑스어로 번역 하는 작업에서 기존 SMT보다 더 좋은 점수를 냈다는 것임.
🔍SMT (Statistical Machine Translation 통계적 기계 번역)
- 확률 및 통계 모델을 기반으로 문장을 번역하는 기계 번역 방법
- 1990년대부터 2010년대 초반까지 주류로 사용된 방법
- 어떤 문장 S가 주어졌을 때, 가장 가능성이 높은 번역 T를 찾는 것이 목표
한계점
1) 단어 또는 구 단위로 번역하기 때문에 문장 전체의 의미를 고려한 번역이 어려움.
2) 패턴과 확률을 기반으로 번역하기 때문에 긴 문장이나 복잡한 문장을 처리하는 데 한계가 있음. 따라서 한국어-영어 처럼 어순이 크게 다른 언어 간의 정확한 번역이 어려움.
3) 대량의 병렬 데이터(Parallel Corpus)에 의존하기 때문에 충분한 데이터가 없으면 번역 품질이 급격히 저하됨.
-
seq2seq : BLEU 점수 34.8점
BLEU (Bilingual Evaluation Understudy)
기계 번역 품질을 평가하는 지표- 기존 SMT : 33.3점
- Out-of-Vocabulary 문제로 인해 점수 깎임
-
SMT 시스템의 번역 결과를 seq2seq의 LSTM으로 rerank하여 성능 개선
- 기존 SMT 시스템이 생성한 1000개의 번역 후보를 seq2seq의 LSTM을 이용해 가장 적절한 번역을 선택하는 방식으로 BLEU 점수가 36.5로 상승함.
-
LSTM은 단어 순서에 민감하게 반응하며, 능동태, 수동태의 차이를 잘 일반화하여 학습할 수 있음. 즉, 같은 의미를 지닌 문장이더라도 다양한 문법적 형태로 표현된 문장 패턴을 효과적으로 이해할 수 있음.
-
입력 문장의 단어 순서를 뒤집으면 성능이 향상됨.
🔍WHY?
- vanilla RNN이 그렇듯 LSTM도 장기 의존성 문제를 겪는데, 영어 문장의 구조 상, 중요한 단어 및 정보가 뒤에 나오는 경향이 있음.
- 이를 먼저 처리함으로써 seq2seq의 LSTM 모델이 이를 더 오랫동안 기억하도록 유도함.
- 아래 예시를 보면, 순방향 문장에서는 "movie", "fantastic" 등의 단어가 뒤에 있지만, 역방향 문장에서는 이들이 앞에 있어 이 정보를 유지할 가능성이 높아짐.
- 영어 문장의 특성을 살린 방법이고, 다른 언어에서도 똑같이 좋은 성능을 낸다고 할 순 없음.
[순방향]
- 입력 : I really enjoyed the movie because the story was fantastic.
- 출력 : 나는 그 영화를 정말 재미있게 봤어. 이야기가 환상적이었어.
[역방향]
- 입력 : fantastic was story the because movie the enjoyed really I.
- 출력 : 나는 그 영화를 정말 재미있게 봤어. 이야기가 환상적이었어.
1 Introduction
- 기존 DNN은 음성 인식, 이미지 인식과 같은 어려운 문제에서도 우수한 성능을 발휘함.
- 기존 통계 모델보다 더 정교하고 빠른 연산을 할 수 있음.
- 그러나! DNN은 입력과 타겟이 고정된 차원의 벡터로 인코딩될 수 있는 문제에만 적용할 수 있음. 입력 데이터의 크기가 유동적인 경우, 출력 데이터의 크기가 변하는 경우는 처리하지 못함.
- 따라서 음성 인식을 통한 기계 번역 혹은 질의응답 문제에서는 좋은 성능을 보이지 못하는 등 도메인에 따라 성능 차이를 보임.
→ 도메인에 의존하지 않고 입력 시퀀스를 다른 시퀀스로 잘 변환하는 방식이 필요함
- 해당 논문에서는 encoder와 decoder 방식을 통해 해결하고자 함.
2 Model
- 두 개의 LSTM 구조 사용 : Encoder - Decoder
→ 모델의 파라미터 수를 증가시킬 수 있으면서도 연산 비용은 거의 증가하지 않고 다양한 언어 쌍을 동시에 학습하는 것이 쉬워짐. - 깊은 LSTM이 얕은 LSTM보다 성능이 우수함.
- 0 Abstract 에서 언급한 바와 같이, 입력 문장의 단어 순서를 뒤집음으로써 성능을 향상 시킴
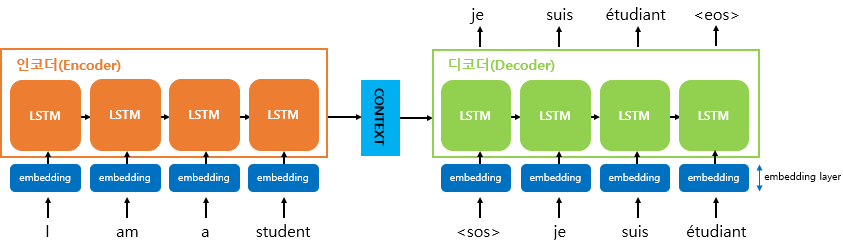
[그림2] seq2seq encdoer-decoder 구조. 좌측 주황색이 encoder, 우측 연두색이 decoder (출처 : 딥 러닝을 이용한 자연어 처리 입문 [https://wikidocs.net/24996])
Encoder
(1) 입력 문장을 단어 단위로 토큰화
(2) 단어 토큰 각각은 LSTM의 각 시점에 입력됨.
-
[그림2]를 보면, 단어 토큰이 LSTM에 입력되기 전, embedding 층을 거치는 것을 볼 수 있음.
-
word embedding을 통해 텍스트를 벡터로 바꾸는 과정을 거침

[그림3] embedding layer의 출력값 (출처 : 딥 러닝을 이용한 자연어 처리 입문 [https://wikidocs.net/24996])
-
RNN 구조를 다시 보면, t시점의 셀에 t-1시점의 hidden state와 t시점의 입력벡터를 입력으로 받음.
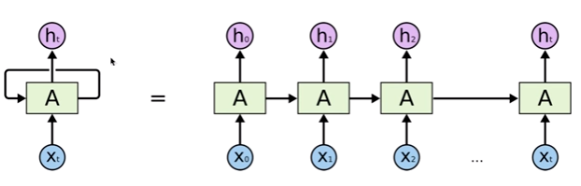
[그림4] RNN 복습 (출처 : Colah's blog [https://colah.github.io/posts/2015-08-Understanding-LSTMs/])
→ 따라서 마지막 시점의 hidden state, 즉 context vetor는 encoder의 모든 hidden state 값들의 영향을 누적해서 받아온 값이기 때문에 모든 단어 토큰들의 정보를 요약해서 담고있다고 할 수 있음.
(3) encoder 마지막 시점의 hidden state (context vector)를 decoder에 넘겨줌
- 모든 단어 토큰의 정보를 담고 있는 context vector를 넘기기
Decoder
= 🔍RNNLM (RNN Language Model)
(1) Decoder의 첫번째 LSTM 셀의 입력
- 초기 입력으로 문장의 시작을 의미하는 심볼
<sos>가 들어감. - 넘겨받은 context vector는 decoder의 첫번째 은닉 상태로 사용됨.
- 따라서 첫번째 셀은 encoder의 context vector와 t시점의 입력값인
<sos>로부터 첫번째 단어를 예측하는 데에 사용함.
(2) LSTM의 hidden state를 Dense layer에 통과
- VGG에서 사용된 FC와 같은 역할을 함. 즉, 출력 차원이 구분해야할 class의 개수가 되도록 함.
- LSTM의 출력, 즉 hidden state는 단어의 감성, 품사, 시제, 문장 내 역할 등을 학습할 수 있도록 고차원 벡터로 표현됨.
[예시]
- 1~10번째 차원 → 감성 정보
- 11~30번째 차원 → 문법 정보
- 31~50번째 차원 → 주제 정보
- 벡터의 차원이 단어 집합의 크기가 되도록 함.
e.g. 프랑스 단어 10,000개로 구성된 어휘(vocab size = 10,000)
→ Dense layer의 출력 크기 : 10,000
(3) 출력 벡터를 softmax를 거쳐 예측값 도출
- 출력 단어로 나올 수 있는 단어들은 다양함. 그 중 하나의 단어를 골라서 예측
- (1)~(2)의 과정을 통해 나온 출력 벡터를 softmax 함수에 통과시켜 각 단어별 확률값을 반환하고, 값이 높은 단어를 출력 단어로 결정함.
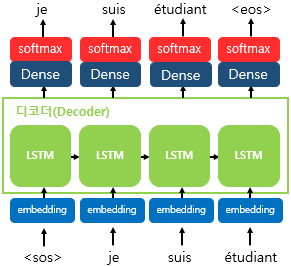
[그림5] Decoder 구조 (출처 : 딥 러닝을 이용한 자연어 처리 입문 [https://wikidocs.net/24996])
(4) t-1시점의 셀이 예측한 단어를 t시점 셀의 입력으로 사용함.
문장의 끝을 의미하는 심볼인 <eos>가 다음 단어로 예측될 때까지 반복함.
3 Experiment
3.1 Dataset details
- WMT’14 영어-프랑스어 기계 번역 데이터셋
- WMT(Wikipedia Machine Translation) 대회에서 제공하는 대규모 병렬 코퍼스
- 1200만개 문장 : 3억 4800만 개의 프랑스 단어 + 3억 400만개의 영어 단어
- 해당 데이터셋의 경우, 이미 토큰화된 train & test dataset이 공개되어 있고, SMT 시스템의 1000-best 리스트가 함께 제공됨.
→ 0 Abstract 에서 언급한 바와 같이 이를 rerank할 예정 - 모든 OoV는
<UNK>로 대체함.
3.2 ~ 3.3 Model architecture : Decoding and Rescoring, Reversing the Source Sentenctes
- Encoder-Decoder 구조의 LSTM 사용
- 입력: 단어 순서를 뒤집은 영어 문장 (Reverse Input Sentence)
- 디코더: EOS(End of Sentence) 토큰을 이용하여 변환 종료
3.4 Training details
- LSTM
- 4 layers (각각 1000개의 셀)
- 모든 파라미터 초기화 : [-0.08, 0.08]의 uniform distribution
- SGD
- learning rate : 0.7 (5 epochs 이후 매 epoch마다 절반씩 줄여나감)
- epochs : 7.5
- batch : 128개
3.5 Paralleization
(gpu와 관련된 내용으로 생략)
3.6 Experimental Results
(1) BLEU 점수 비교
- Seq2Seq 모델 : 34.8 (*OOV 단어 처리로 인해 일부 페널티 존재)
- 기존 SMT 시스템 : 33.3
→ Seq2Seq 모델이 기존 SMT보다 더 높은 성능
(2) 단어 순서를 뒤집는 기법의 효과
- 입력 문장의 단어 순서를 반대로 정렬하면 학습이 훨씬 쉬워지고 성능이 향상됨.
- 입력과 타겟 문장 간의 단기 의존성이 증가하여 최적화가 쉬워지기 때문
- 실험적으로 입력 순서를 뒤집었을 때 BLEU 점수가 더 높아짐
(3) 깊은 LSTM 모델의 성능 비교
- 깊은 LSTM (4개 층) : 30.6
- 얕은 LSTM (2개 층) : 34.8
→ 더 깊은 LSTM을 사용할수록 번역 품질이 향상됨.
(4) LSTM의 장기 의존성 처리 능력 확인
- Seq2Seq 모델을 사용한 LSTM은 긴 문장에서도 기존 RNN보다 성능이 우수
- 특히, 능동태와 수동태처럼 문법적으로 다른 구조에서도 일관된 표현 학습 가능
4 Conclusion
- LSTM 기반 모델이 기존 SMT 시스템보다 우수한 성능을 보임.
- 입력 문장의 단어 순서를 뒤집으면 학습이 쉬워지고 성능이 크게 향상됨.
- LSTM이 예상보다 긴 문장에서도 성능이 뛰어났음.
- 단순한 접근 방식만으로도 SMT 시스템을 능가할 수 있으며, 추가 연구를 통해 성능을 더욱 향상시킬 수 있음.
- Seq2Seq 모델은 기계 번역뿐만 아니라 다양한 시퀀스 학습 문제에 적용 가능성이 높음.
🤔 내 생각
- 이전에 wikidocs로 깔짝 공부한 적이 있는데, 그때 봤던 내용보다 논문 내용이 더 작아서 당황했음.
- 개념에 대해서 알고만 있다가 논문을 통해 SMT, 문장 내 단어 순서 뒤집기 등 새로운 것들을 접해서 신선했음.
