Original Paper (Arxiv) : Transformer (https://arxiv.org/pdf/1706.03762)
📥Background
1. vanilla seq2seq
자세한 설명은 seq2seq에 대해 정리한 글 참고 : Sequence to Sequence Learning with Neural Networks (2014)
Seq2Seq (Sequence-to-Sequence) 모델은 입력 시퀀스를 받아 다른 길이의 출력 시퀀스로 변환하는 딥러닝 모델이다. 주로 기계 번역, 문장 요약, 챗봇, 음성 인식 등의 NLP 문제에서 사용된다.
Seq2Seq 기본 구조
Seq2Seq 모델은 Encoder-Decoder 구조로 이루어져 있다.
Encoder
- 입력 시퀀스를 받아 고정된 크기의 context vector로 변환
- 주로 LSTM, GRU, Transformer 등의 RNN 계열 모델이 사용됨
- 문장의 의미를 압축하여 저장하는 역할
Decoder
- Encoder에서 생성된 context vector를 기반으로 출력 시퀀스를 생성
- 하나의 단어를 출력한 후, 다음 단어를 예측하는 방식 (Auto-Regressive)
- RNN 기반 또는 Transformer 기반으로 구현 가능
Seq2Seq 모델의 학습 방식
- 입력 문장 → Encoder로 전달 → context vector 생성
- Decoder가 context vector를 받아 단어를 하나씩 출력
- 출력 단어를 정답과 비교하며 학습 (Teacher Forcing 사용 가능)
2. seq2seq with attention
vanilla seq2seq 에서 encoder가 decoder로 넘기는 context vector의 길이는 항상 고정되어 있기 때문에 입력 문장의 길이가 아무리 길어도 같은 길이의 벡터를 반환하는 문제점이 있었다. 이에 따라 encoder와 decoder를 각각 다음과 같이 개선하였다.
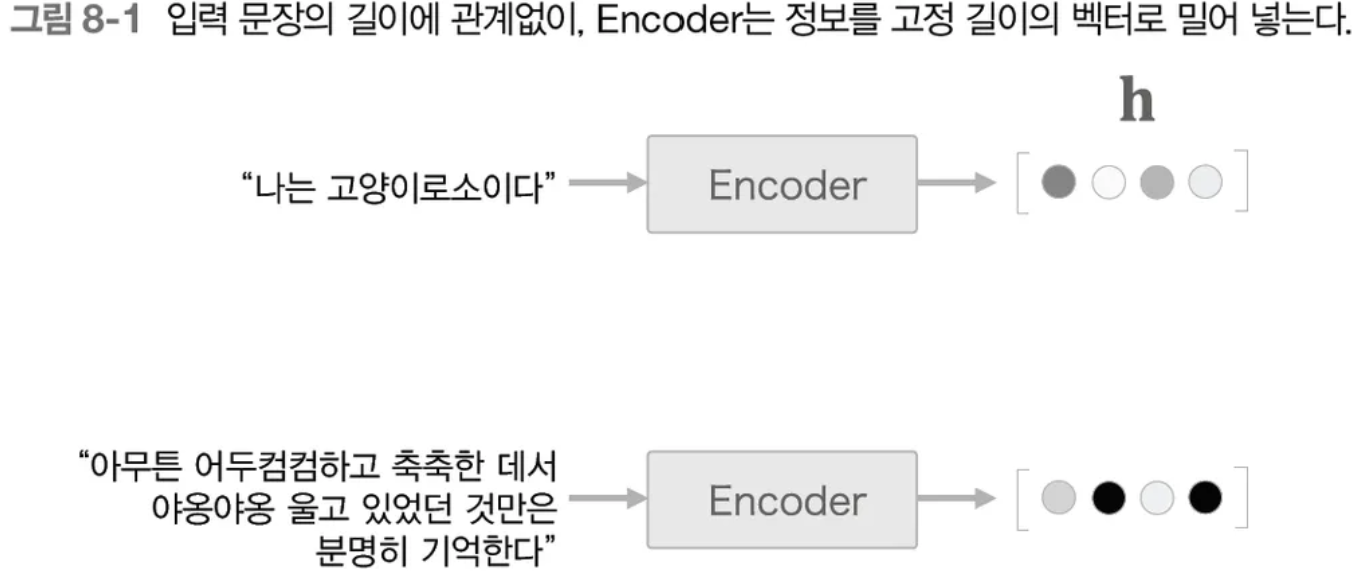
[그림1] vanilla seq2seq의 문제점 (출처 : 밑바닥부터 시작하는 딥러닝2 - 8장)
Encoder
decoder에 마지막 hidden state의 vector만 넘기는 것이 아니라 모든 hidden state vector를 행렬로써 전달
encoder의 경우 아래 설명할 decoder와 다르게 모델의 구조 자체를 바꾼 것은 아니다. 다만, encoder의 출력 길이가 입력 문장의 길이를 반영할 수 있도록 마지막 hidden state vector만 decoder에 넘기는 것이 아니라 모든 hidden state vector를 하나의 행렬로 만들어서 넘기는 방식을 택했다.
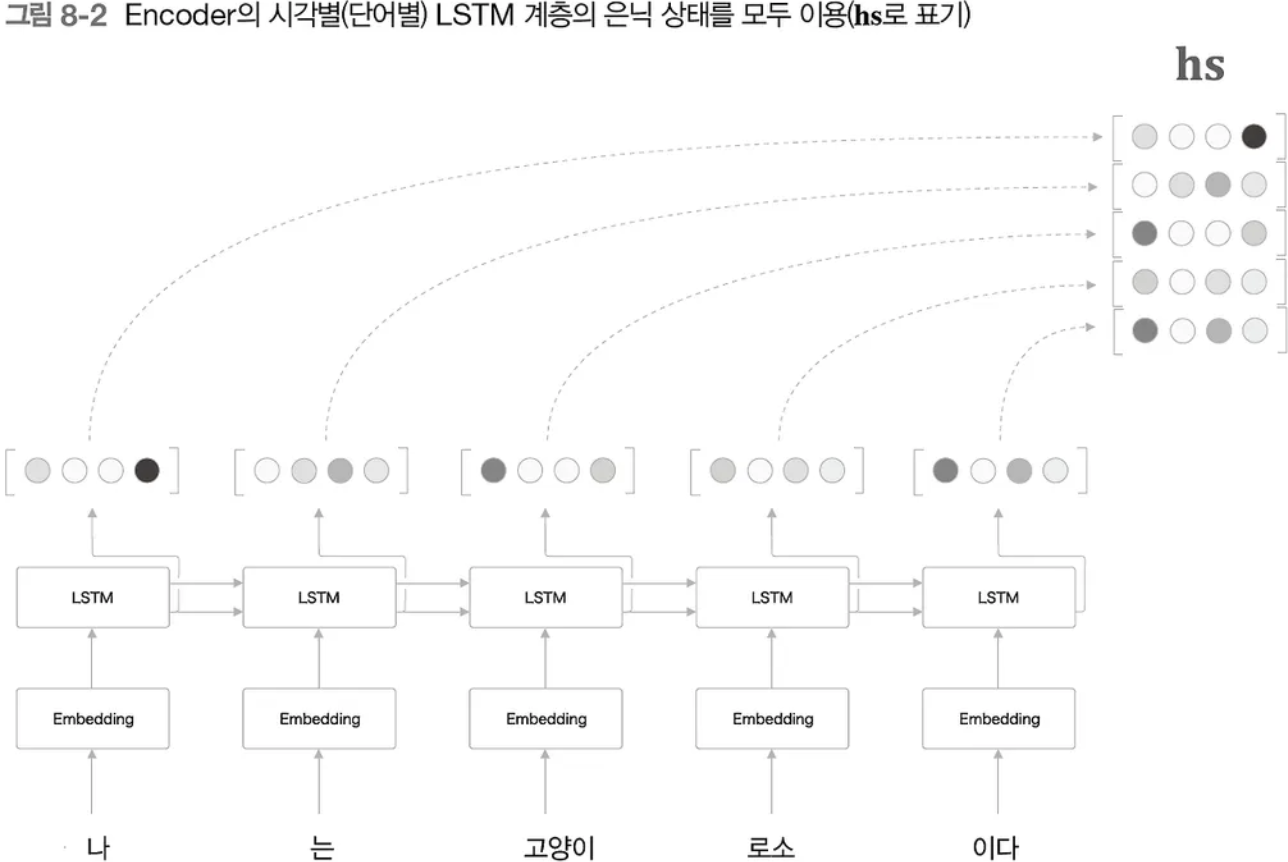
[그림2] seq2seq with attention의 encoder 구조 (출처 : 밑바닥부터 시작하는 딥러닝2 - 8장)
Decoder
(1) 가중치 a 구하는 방법
- Decoder의 LSTM 셀에 각 시점 단어의 임베딩 벡터와 이전 시점 LSTM의 은닉 상태 벡터 input
( ※ 이때 1번째 시점의 경우, 이전 LSTM 셀이 없으므로, Encoder의 은닉 상태 벡터를 합친 행렬인hs를 input )
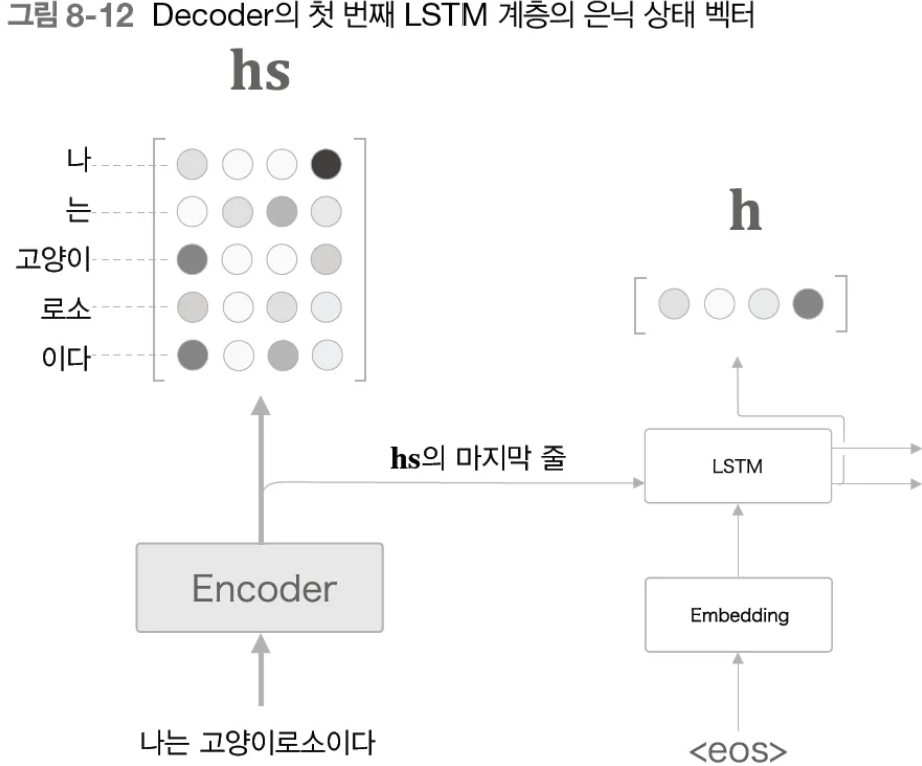
- 1.의 결과로 도출된 LSTM 은닉 상태 벡터
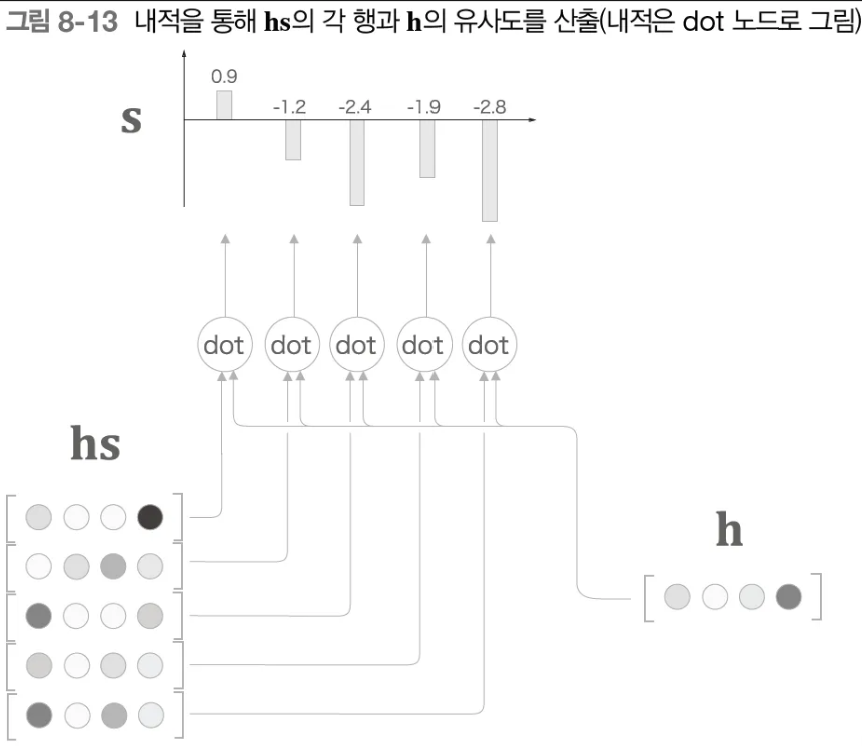
h를hs와 내적하여s도출
→ 각 단어 벡터가 얼마나 비슷한가를 수치로 나타낸 것 (= 두 벡터가 얼마나 같은 방향을 향하고 있는가)
s를 Softmax에 통과시켜 정규화함으로써 가중치 행렬a도출
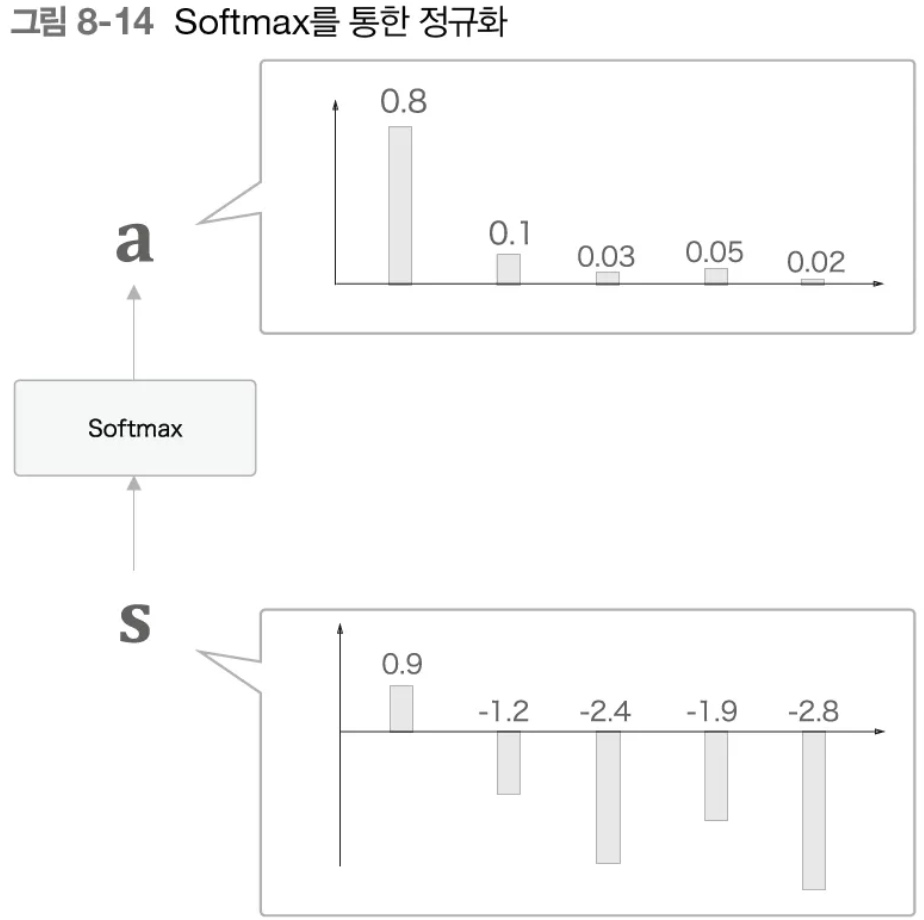
(2) context vector 구하는 방법
앞서 (1)에서 구한 가중치 행렬 a 와 Encoder의 모든 은닉 상태 벡터를 합친 hs를 가중합한다.
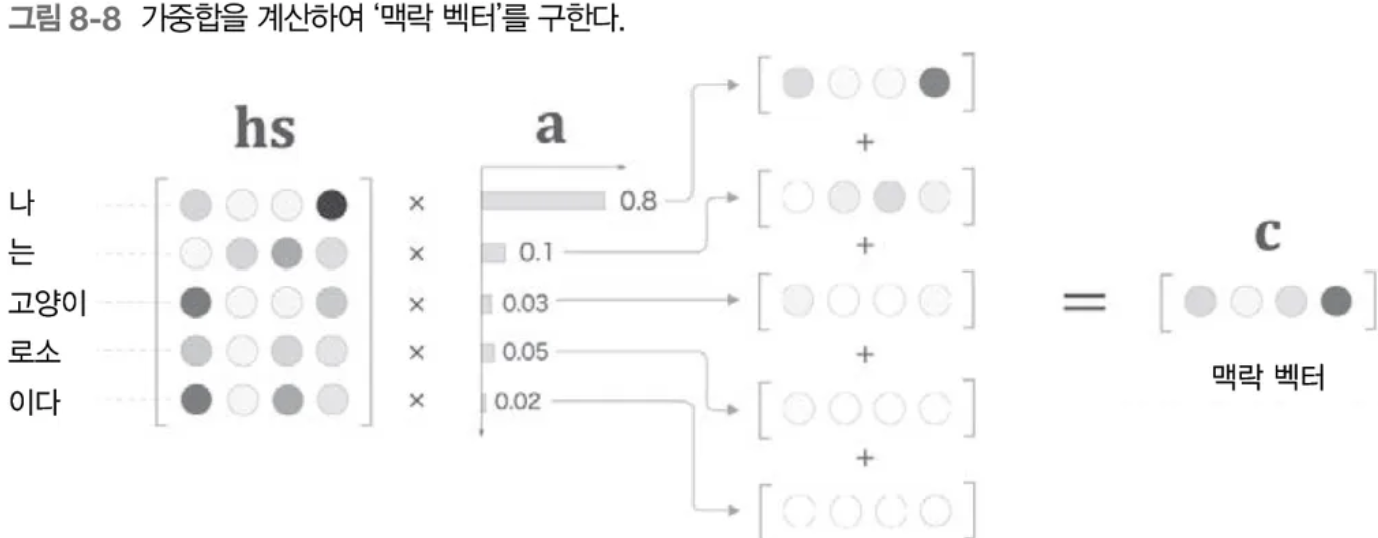
[그림3] seq2seq with attention의 decoder에서 context vector를 구하는 방법 (출처 : 밑바닥부터 시작하는 딥러닝2 - 8장)
❗논문의 발상❗
지금까지는 attention을 RNN의 보정 용도로 사용해왔는데, 그렇다면 RNN을 빼고 attention만으로 Encoder와 Decoder를 구성하는 것은 어떨까?
📄Paper Review
0. Abstract
주요 시퀀스 변환 모델의 특징은 다음과 같다.
- 복잡한 RNN 혹은 CNN으로 구성된 Encoder와 Decoder 구조
- 특히, SOTA는 seq2seq with attention
이에 오직 attention 메커니즘만 채택한 Transformer를 제안한다. 2개의 번역 task를 진행한 결과, WMT 영어-독일어 번역 task에서 기존 모델 대비 2점 상승한, BLEU(기계 번역 품질을 평가하는 지표) 28.4점을 기록했다. 또다른 task인 WMT 영어-프랑스어 번역 task에서는 41.8점을 기록하며 단일 모델 SOTA를 세웠다.
1. Introduction
📌 기존 RNN 계열의 언어 모델
vanilla RNN, LSTM, GRU 등의 모델들은 언어모델, 기계번역 등의 시퀀스 모델링 및 변환 문제에서 SOTA를 굳건히 지켜왔고, 이에 따라 RNN 계열의 언어 모델과 encoder-decoder 구조의 영역을 꾸준히 확장했다.
📌 RNN 계열 언어 모델의 한계
RNN 계열의 언어 모델에서 t시점의 RNN cell은 t-1시점의 hidden state인 과 t시점의 input을 사용하여 를 도출한다. 이렇듯 서로 영향을 끼치는 연속적인 성질은 training 시 병렬 연산을 못하는 요인이 되고, 이는 긴 시퀀스를 input으로 받을 때 메모리 부족 등의 문제를 일으킨다.
📌 지금까지의 attention의 활용
attention은 모든 단어를 동시에 고려하여 직접 참조할 수 있다는 점에서 강력한 시퀀스 모델링의 필수적인 요소가 되었다. 그러나 대부분의 경우, attention은 단독으로 사용되지 않고 RNN 계열 모델과 함께 사용되었다.
📌 Transformer : RNN을 배제한 attention 활용
본 논문의 Transformer는 입력과 출력 간의 관계를 학습하는 데 오직 attention 메커니즘만 사용하였다. RNN을 제외함으로써 병렬 처리가 가능해졌고, 그 결과 오직 12시간 동안 12개의 P100 GPU를 통해 병렬적으로 training함으로써 새로운 SOTA로 등극할 수 있었다.
2. Background
📌 Transformer가 등장하기 전까지
RNN, CNN 기반 모델은 여전히 순차적 연산을 사용하여 관계를 학습한다. 하지만 입력과 출력 간 멀리 떨어진 단어 간의 관계를 학습하는 데 한계가 있다.
📌 Transformer의 차별점 : Self-Attention
self-attention은 단일 시퀀스 내의 서로 다른 위치를 참조하여 모든 위치에서 병렬 연산이 가능한 메커니즘이다. 지금까지 attention은 RNN 혹은 CNN과 함께 사용되었다. Transformer는 오직 self-attention에만 의존하여 입출력의 표현을 계산하는 최초의 변환 모델이다.
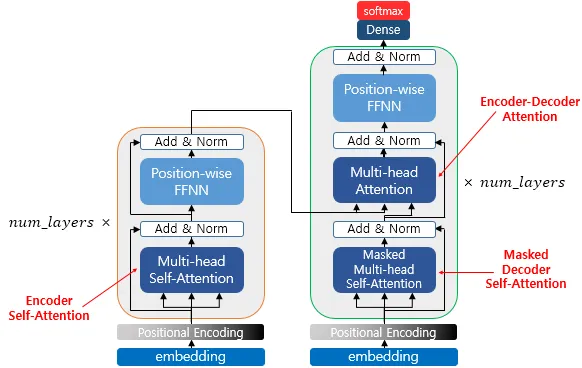
3. Model Architecture
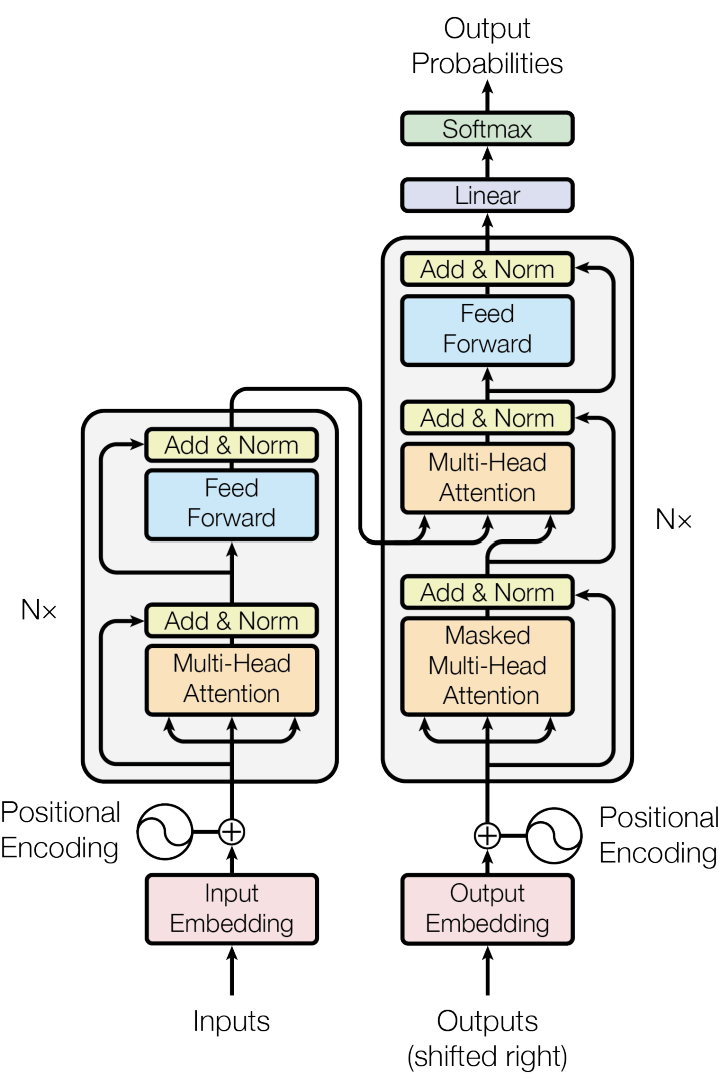
[그림4] transformer - model architecture (출처 : 논문 발췌)
대부분의 경쟁력 있는 시퀀스 변환 모델이 그러하듯 transformer도 encoder-decoder 구조를 갖는다.
-
encoder : 입력 시퀀스 를 연속적인 표현 으로 변환한다.
-
decoder : 인코더와 다르게 출력을 한 번에 하나씩 생성한다. 이때, 이전 출력값을 입력값으로 사용하는 auto-regressive 방식을 택한다.
3.1 Encoder and Decoder Stacks
Endoder
-
6개의 동일한 구조의 층으로 구성되어 있는데, 각 층은 2개의 하위 계층을 갖고 있다.
- 1번째 하위 계층 : multi-head self-attention
- 2번째 하위 계층 : Fully connected feed-forward
-
[그림4]에서 볼 수 있듯이 각 하위 계층에 잔차 연결을 수행한 후, 정규화(layer normalization)을 수행한다. 이때, 잔차 연결을 원활하게 하기 위해 임베딩 층을 포함한 모델의 모든 하위 계층에서 출력 차원은 로 고정한다.
→
Decoder
-
encoder와 마찬가지로 6개의 층으로 구성되어 있는데, 하위 계층은 3개로, 2개는 앞서 설명한 encoder의 하위 계층과 동일하다.
-
1번째 하위 계층 : multi-head self-attention : decoder의 input을 처리
→ "masking" : i번째 이후 단어를 보지 못하도록 차단
→ "offset" : i-1번째 단어들까지만 참고하도록 함 -
2번째 하위 계층 : multi-head self-attention : encoder의 output을 처리
-
3번째 하위 계층 : Fully connected feed-forward
-
-
encoder와 동일하게 잔차 연결과 정규화를 수행한다.
3.2 Attention
어텐션 함수는 query와 일련의 key-value쌍을 output으로 매핑하는 과정으로 설명할 수 있다. 이때 Query, Key, Value, Output 모두 벡터로 표현된다. output은 Value들의 가중합으로 계산되며, 각 값에 할당되는 가중치는 Query와 Key 간의 적합도에 의해 결정된다.
3.2.1 Scaled Dot-Product Attention
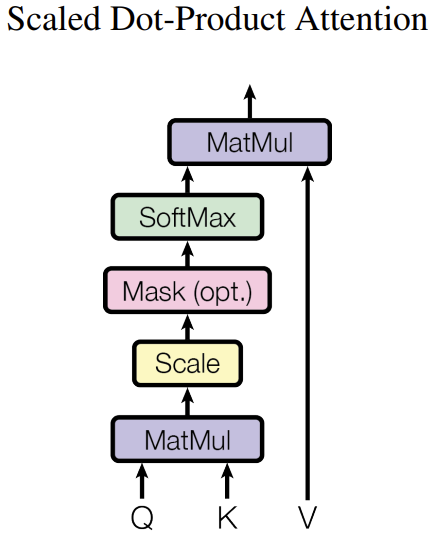
[그림5] Scaled Dot-Product Attention (출처 : 논문 발췌)
hyper-parameters
1. : 인코더의 입력 크기 = 임베딩 벡터 차원 = 디코더 출력 차원
→ 앞서 3.1 의 Encoder 부분에서 설명했듯, 임베딩 층을 포함한 모든 하위계층의 출력 차원은 로 고정
2. : 인코더 & 디코더가 총 몇 층으로 구성되어 있는지
3. : 병렬로 수행한 어텐션 개수
4. : feed-forward 신경망의 은닉층 차원 (입출력층 크기는 )
5. : query와 key의 차원 (= 각각의 가중치 행렬의 열의 개수)
→
6. : value의 차원 (= 가중치 행렬의 열의 개수)
→
(일반적으로 가 동일하기 때문에 = )
논문의 default값
1. = 512
2. = 6
3. = 8
4. = 2048
5. = = 64
(※ 아래 과정은 일반적인 self-attention의 과정이며, 각 Q, K, V의 출처는 이후 설명할 attention의 종류에 따라 다르다.)
- 각각의 가중치 행렬을 곱하여 Q, K, V 행렬 구하기
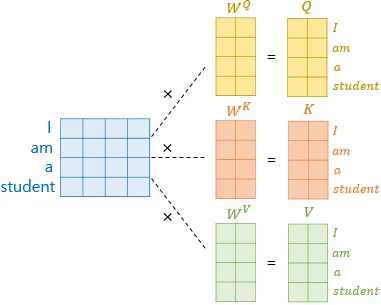
[그림6] Q, K, V 행렬 구하기
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
- Q와 K 내적을 통해 각 단어 간 유사도 측정 :
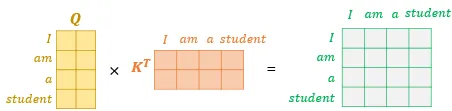
[그림7] Q-K 내적(dot-product)
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
- 스케일링 :
값이 작은 경우엔 연산 속도에 문제가 없지만, 값이 커질수록 내적 값이 커질 수 있기 때문에 이를 조정하기 위해 으로 나눈다.
- attention value : softmax 통과 후 V와 곱하기
가중치를 [0, 1] 값으로 반환하기 위해 softmax 함수에 통과시킨다. 이후 V와 곱하여 최종 attention value 행렬을 출력한다.
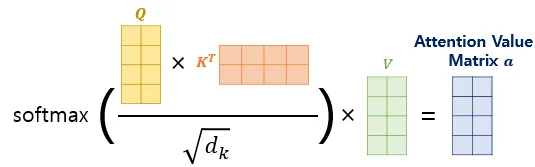
[그림8] softmax 통콰 후 V와 곱하여 attention value 도출
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
최종 수식은 다음과 같다.
각 단계에서 벡터 및 행렬의 차원
1. 입력 : ,
2. :
3. : ← 1.과 2.를 곱한 결과
4. attention value의 차원 : ,
3.2.2 Multi-Head Attention
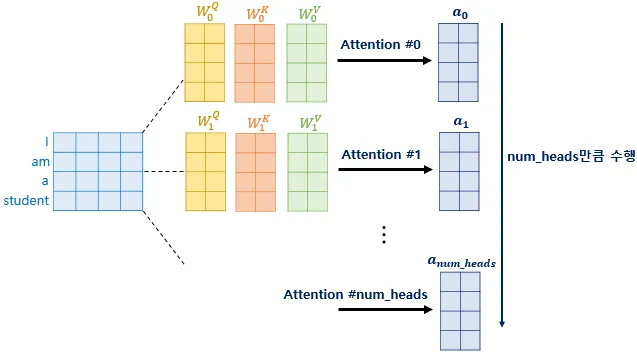
[그림9] multi-head attention 연산
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
-
사용 계기 : 병렬 연산
차원의 를 사용하여 단일 어텐션 연산을 수행하는 것보다 앞서 hyper-parameters에서 정의한 것과 같이 이를 번 선형 변환하여 각각 차원의 벡터로 변환하여 병렬 연산하는 것이 더 효과적이다. -
특징
-
각각의 attention value matrix를 attention head라고 부른다.
-
가중치 행렬 의 값은 8개의 attention head마다 모두 다르다.
-
-
과정
- attention head 합치기 (concatenate)
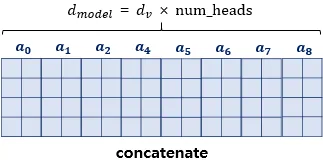
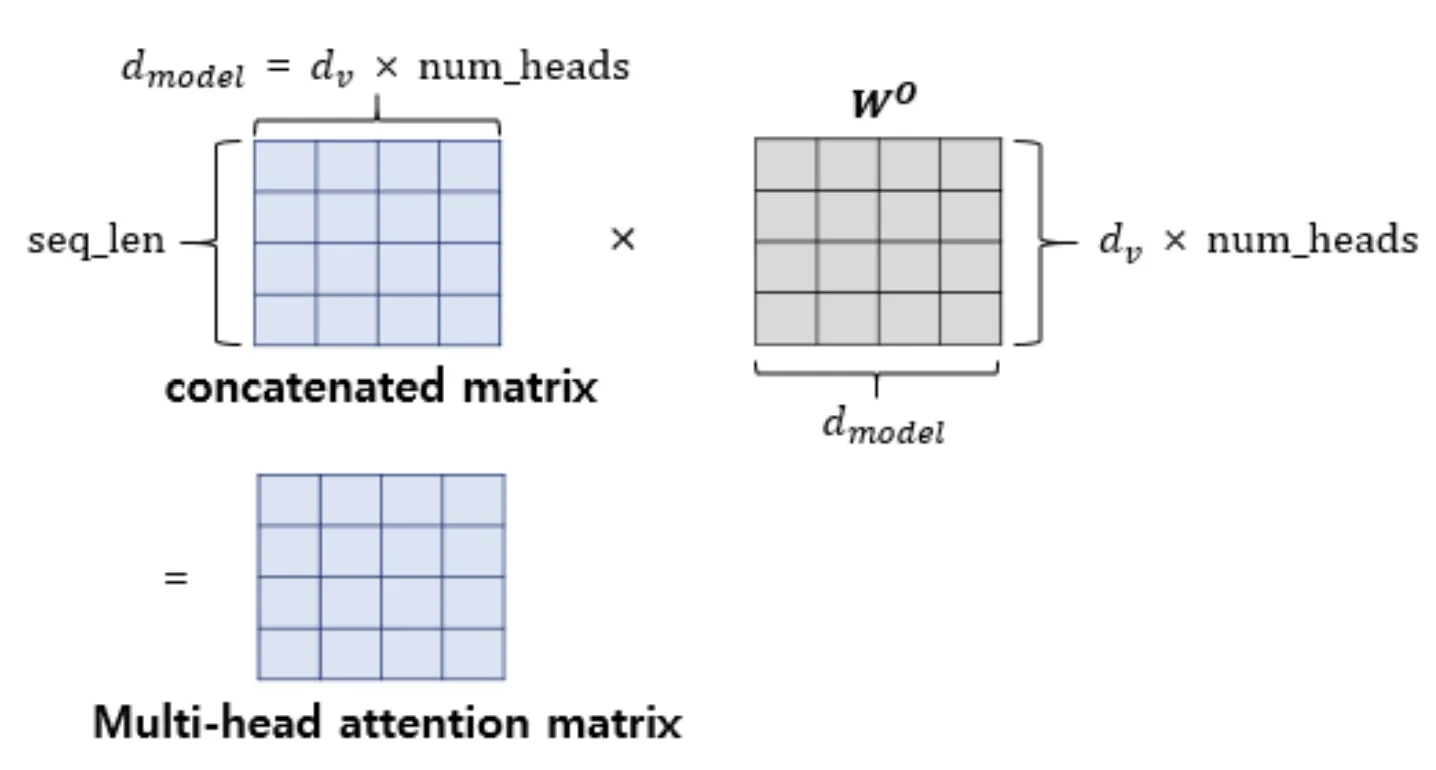
- 가중치 행렬 곱하기 : =
hyper-parameters에서 말한 바와 같이 대부분의 경우 = 이지만, 특정 연구에서는 가 다른 경우가 발생할 수 있다. 따라서 concat된 행렬이 의 차원을 갖게 하기 위해서 를 곱한다.
- attention head 합치기 (concatenate)
최종 수식은 다음과 같다.
3.2.3 Applications of Attention in our Model
Transformer는 총 3가지 종류의 attention을 사용했다.
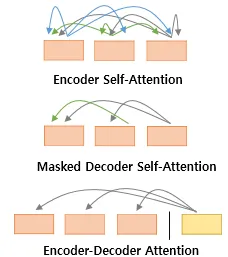
[그림10] transformer에 사용된 attention 종류 3가지
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
[그림11] attention 종류 3가지가 각각 어느 파트에 사용됐는가를 보여주는 이미지
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
1. Encoder self-attention : 인코더에서 사용되는 어텐션
-
역할 : 소스 문장 내에서 단어들끼리의 관계를 학습
(각 단어가 문장에서 어떤 단어와 관계가 깊은 지 파악) -
방향성 : 양방향 = 모든 단어가 서로를 참고할 수 있음
-
출처 : query = key = value (원본 벡터 출처는 같음)
-
동작 방식
- 각 단어의 Query, Key, Value 벡터를 생성
- Query와 Key를 비교하여 어떤 단어가 중요한지 점수(Attention Score) 계산
- Softmax를 적용하여 가중치(확률)로 변환
- Value 벡터를 가중합하여 최종적인 벡터 생성
2. masked decoder self-attention : 디코더의 1번째 하위 계층
- 역할 : 타겟 문장에서 앞쪽 단어만 참고할 수 있도록 마스킹
(현재 예측하는 단어보다 뒤에 오는 단어는 볼 수 없음)
← RNN과 다르게 문장을 통으로 입력하기 때문에 뒤에를 봐버리면 사전 관찰 - 출처 : query = key = value (원본 벡터 출처는 같음)
- 동작 방식
- 기존 Self-Attention과 동일하게 Query, Key, Value 생성
- 단, 현재까지의 단어만 참고 가능하도록 마스킹 적용 (미래 단어 참고 방지)
- Softmax를 적용하여 각 단어의 중요도를 계산
- Value 벡터를 가중합하여 최종적인 벡터 생성
3. encoder-decoder attention : 인코더 벡터를 인풋으로 받는 어텐션
-
역할 : 인코더에서 출력한 context vector를 디코더에서 활용할 수 있도록 연결
→ 디코더의 query 와 인코더의 key, value를 비교하여 가장 관련 있는 정보 찾기
-
출처
- query : from decoder input
- key = value : from encoder output
-
동작 방식
- 디코더에서 Query 생성 (현재까지 예측한 단어 기반)
- query값을 인코더의 output, 즉 context vector를 원본으로 하는 Key와 비교하여 유사도 계산 후, Softmax에 통과
- Value를 가중합하여 최종적인 벡터 생성
→ 디코더가 출력 문장을 더 잘 예측할 수 있도록 도움
3.3 Position-wise Feed-Forward Networks
각 위치에 대해 독립적으로 연산 수행한다. 즉, 각 단어의 벡터가 개별적으로 FFN을 통과하여 이전 단어 혹은 주변 단어와 관계없이 개별적으로 계산된다.
예시 : 4개 단어(토큰)로 구성된 입력 시퀀스
→
다음 3번의 과정을 거친다. - 선형 변환 → ReLU → 선형 변환
- 첫 번째 선형 변환
- 입력 차원:
- 출력 차원:
- 연산:
- 여기서 은 크기의 행렬
- 결과적으로 512차원 → 2048차원으로 확장됨
- ReLU 활성화 함수 적용
- 비선형성을 추가하고, 음수를 제거하는 역할
- 연산:
- 두 번째 선형 변환
- 입력 차원:
- 출력 차원:
- 연산:
- 여기서 는 크기의 행렬
- 결과적으로 2048차원 → 다시 512차원으로 축소됨
3.4 Positional Encoding
RNN 혹은 CNN 모델을 사용하지 않기 때문에 시퀀스의 순서를 나타내기 위해서 추가적인 위치 토큰을 삽입해야 한다. 이를 위해 encoder와 decoder 하단의 입력 임베딩에 "위치 임베딩"을 추가했다.
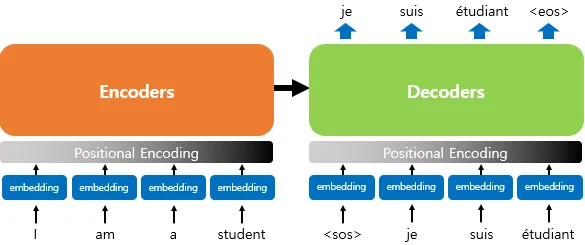
[그림12] encoder와 decoder에서 positional encoding의 위치
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
사인-코사인 기반 인코딩을 사용하여, 차원별로 다른 주파수를 적용했다.
해당 방식은 상대적 위치에 따라 선형성을 유지하여 어텐션 학습에 유리하다. "학습된 위치 임베딩"도 실험했지만, 성능 차이가 거의 없었기 대문에 일반화 가능성이 더 높은 사인-코사인 방식을 채택했다.
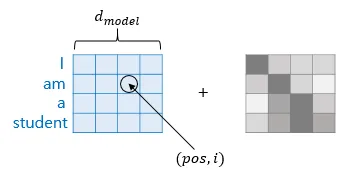
[그림13] positional encoding 방법
(출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [(https://wikidocs.net/35596])
4. Why Self-Attention
self-attention vs. RNN/CNN

[그림14] layer 종류에 따른 연산 복잡도, 병렬화 가능한 연산량, 입출력 간의 경로 길이 비교
(출처 : 논문 발췌)
-
층별 전체 연산 복잡도 : 낮음
-
병렬화할 수 있는 연산량 : 적음
= 하나의 병렬 연산 블록 내에서 수행해야 하는 연산량 -
입력-출력 간의 경로 길이 : 짧음
장기 의존성을 학습하는 것은 시퀀스 변환 문제에서 중요한 요소 중 하나이다. 장기 의존성을 많이 학습할 수록 더 좋은 예측을 할 수 있는데, 이에 영향을 끼치는 요인 중 하나가 순전파 및 역전파 신호가 통과하는 경로이다. 다시 말해, 네트워크 내에서 입력-출력 간의 경로가 짧을수록, 장기 의존성을 학습하기 쉬워진다.
5. Training
5.1 Training Data and Batching
📌 토큰화(Tokenization) 방법
- BPE (Byte-Pair Encoding): 자주 등장하는 문자열 패턴을 토큰 단위로 인코딩하는 방법
- WordPiece: BPE와 유사하지만, 더 최적화된 방식으로 단어를 서브워드 단위로 분할
📌 데이터셋 정보
- 영어-독일어: 450만 문장(BPE, 37,000개 토큰 어휘)
- 영어-프랑스어: 3,600만 문장(WordPiece, 32,000개 토큰 어휘)
📌 배치 구성
- 비슷한 길이의 문장끼리 묶어 배치 생성
- 각 배치 = 약 25,000개의 소스 토큰 + 25,000개의 타겟 토큰 포함
5.2 Hardware and Schedule
8개의 NVIDIA P100 GPU가 장착된 단일 머신에서 모델을 훈련하였다.
- Base 모델 (논문 전반에 걸쳐 설명된 하이퍼파라미터 사용)
- 학습 스텝당 연산 시간: 약 0.4초
- 총 학습 스텝 수: 100,000 스텝
- 총 학습 시간: 12시간
- Big 모델 (Table 3의 마지막 줄에 설명됨)
- 학습 스텝당 연산 시간: 약 1.0초
- 총 학습 스텝 수: 300,000 스텝
- 총 학습 시간: 3.5일
5.3 Optimizer
- Adam 사용
hyper-parameters
- 1차 모멘트 계수:
- 2차 모멘트 계수:
- 수식 안정화를 위한 작은 값:
- 초반 warm-up 단계에서는 학습률을 선형적으로 증가시킴
- 이후에는 스텝 수의 역제곱근 비율로 감소
- warm-up 스텝 수:
→ 초반에는 학습률을 천천히 증가시켜 안정적인 학습을 유도하고, 이후에는 점진적으로 감소시키는 방식
5.4 Regularization
- 잔차 드롭아웃
- 각 하위 계층의 출력에 드롭아웃을 적용한 후,
이를 입력과 더한 후 정규화 수행 - 임베딩과 위치 인코딩의 합에도 드롭아웃 적용
- Base 모델에서 드롭아웃 비율:
- 라벨 스무딩
- 스무딩 값:
- 단점: Perplexity 증가 (모델이 확신을 덜 가지도록 학습됨)
- 장점: BLEU 점수 및 모델 정확도 향상
최종 결과
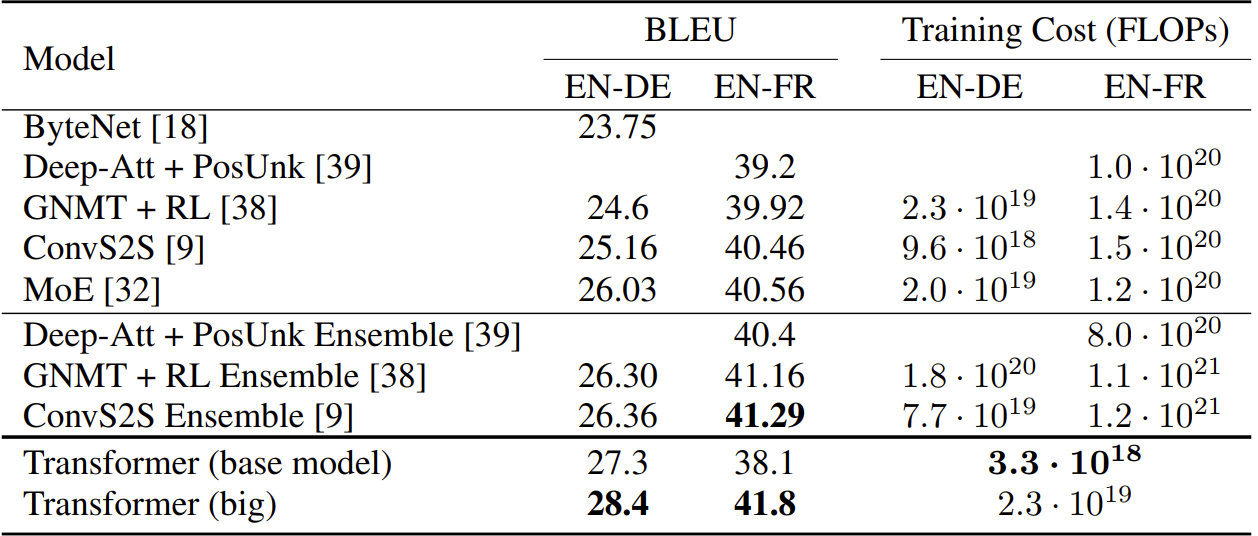
[그림15] 영-독, 영-프 데이터셋에 대한 모델별 BLEU 값
(출처 : 논문 발췌)
🤔 My Thoughts
- seq2seq with attention을 공부한 다음에 transformer를 공부했었는데, 당시 self-attention 개념이 너무나도 생소해서 완전히 학습하는 데에 오랜시간이 걸렸었다.
- 무엇보다 query, key, value 개념이 어려웠다.
- attention만 갖고 오는 생각은 어떻게 했을까... 구글인들은 참 똑똑해들..
참고 문헌
- 밑바닥부터 시작하는 딥러닝2 - 8장
- 딥러닝을 이용한 자연어 처리 입문 - 16장 (https://wikidocs.net/35596)
