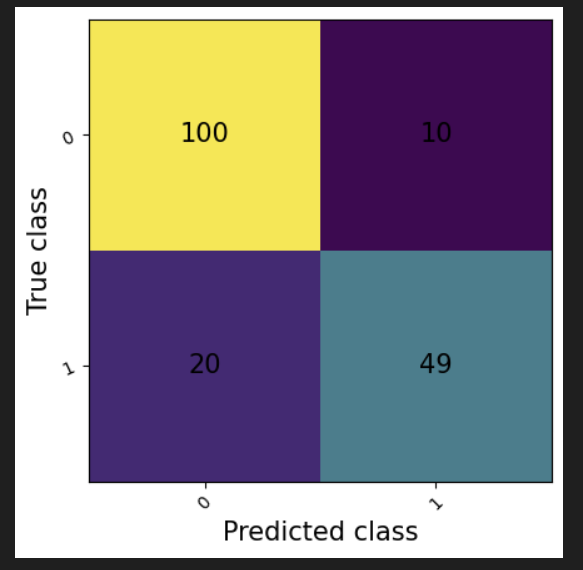
Confusion Matrix 란?
- 모델이 예측한 결과와 실제 결과를 비교해서, 모델이 얼마나 클래스를 잘못 예측하는 지를 살펴보는 지표.
- 분류 모델에서 특히 클래스에 데이터 불균형 문제가 있을 때에, 정확도만 보고 판단하는 것보다 다른 추가 지표를 함께 보는 것이 더 정확한 판단을 할 수 있음.
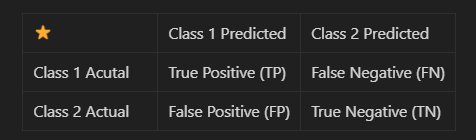
- Binary Classification를 기준으로 생각해보면, Confusion matrix는 총 네 가지 항목으로 구성됨.
- True Positive (TP): 실제값이 Positive이고, 모델이 예측한 값도 Positive인 경우
- False Positive (FP): 실제값은 Negative이고, 모델이 예측한 값은 Positive인 경우
- False Negative (FN): 실제값은 Positive이고, 모델이 예측한 값은 Negative인 경우,
- True Negative (TN): 실제값이 Negative이고, 모델이 예측한 값도 Negative인 경 - 모델이 class 1 분류를 잘하는 것과, class 2 분류를 잘하는 것은 서로 상충관계(trade-off)에 있음. 즉, 어느 한 class의 인식률을 높이기 위해 모델을 학습시키다 보면 나머지 class의 인식률이 낮아질 수 있음.
정확도(Accuracy)
- 모델이 Positive이던 Negative이던 정확히 예측한 결과. (모든 결과 중 맞게 예측한 결과의 비율)
- 클래스 불균형(imbalanced class)이 없는 경우, 단독으로도 유용하지만 클래스 분포가 불균형하다면 다른 지표들도 함께 고려해서 성능을 평가해야 함.
정밀도 (Precision)
- Positive로 예측한 결과 중 실제로 Positive인 결과의 비율
- 모델의 목표에 따라서 정밀도를 높이는 경우가 중요할 수도 있고, 다른 지표를 올리는 게 중요할 수도 있음. 예를 들어, Positive를 스팸 메일인 경우라고 가정해보자. 만약, 스팸 메일이 아닌(Negative) 어떤 중요한 메일을 스팸 메일(Positive)로 잘못 분류(FP)하면 안 되는 모델에서는 정밀도가 높아야 필요한 메일이 스팸 메일로 분류 되는 경우를 최소화할 수 있음. 다만, 정밀도를 높이면 모델은 Positive로 예측하는 경우를 조심스럽게 선택해야 하므로 FP는 줄어들지만 FN도 증가할 수 있기 때문에 재현율이 낮아질 수 있다.
재현율 (Recall)
- 실제로 Positive인 결과 중에서 모델이 Positive로 예측한 비율
- FN은 실제로는 Positive인데 모델이 잘못해서 Negative로 예측한 것이니 False Negative!
- 실제로 Positive인 샘플을 놓치지 않는 것이 중요한 경우에 높은 재현율을 목표로 할 수 있다. 예를 들면, 암 진단 모델에서 재현율을 높이면 실제로 암(Positive)인데 암이 아니라고(Negative) 판단하는 경우(FN)를 최소화할 수 있음. 다만, 재현율을 높이면 실제로는 Negative인데 Positive라고 잘못 판단하는 경우를 늘릴 수 있음. 즉, 재현율을 높이면 정밀도가 줄어들 수 있다.
F1-score
- 정밀도와 재현율의 조화 평균(harmonic mean)으로 계산되는 지표.
- 정밀도와 재현율이 모두 중요한 경우에 사용됨. 정밀도와 재현율이 모두 높은 경우에 높은 값을 가지고, 둘 중 하나가 낮으면 값이 낮아짐. 즉, 한 쪽이 높고 한 쪽이 낮은 것보다, 둘다 중간에 있는 경우가 F1-score이 더 높음. 따라서, 불균형한 데이터인 경우에 사용하기 좋은 지표이다.
- 정밀도와 재현율은 상충 관계에 있기 때문!
코드 예시
1) sklearn의 classification_report을 사용하기
- 실제값과 예측값을 받아서 각 클래스 별로 평가지표를 계산한 뒤 출력해 준다.
- support: 각 클래스 라벨의 실제 갯수
- macro avg: 각 클래스 별로 동일한 가중치를 부여하는 단순 평균
- weighted avg: 각 클래스에 속하는 표본의 갯수를 이용한 가중 평균
- 0: class = 0이 Positive인 경우의 지표
- 1: class = 1이 Positive인 경우의 지표
from sklearn.metrics import classification_report
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X, y = make_classification(n_samples=1000, n_classes=2, weights=[0.2, 0.8], random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = LogisticRegression(random_state=0).fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
"""
precision recall f1-score support
0 0.91 0.89 0.90 44
1 0.98 0.98 0.98 206
accuracy 0.96 250
macro avg 0.94 0.93 0.94 250
weighted avg 0.96 0.96 0.96 250
"""2) cross_validate를 사용하는 경우
def scores_cv(model, x, y):
"""
model: model to use
x: features
y: output
"""
score_list = ['accuracy', 'precision', 'recall', 'f1']
scores = cross_validate(model, x, y, scoring = score_list, cv = 5) # default = stratifiedKfold
scores_df = pd.DataFrame(scores)
return pd.concat([scores_df, scores_df.apply(['mean', 'std'])])3) neural network 모델을 사용하는 경우, 직접 confusion matrix 계산을 해주어야 함
# for neural network
def cm_to_metrics(cm:np.array) -> tuple:
'''Confusion Matrix to Metrics
cm: confusion matrix of shape (2,2)
'''
(tn, fp), (fn, tp) = cm
accuracy = (tp+tn)/(tp+tn+fn+fp)
precision = tp/(tp+fp)
recall = tp/(tp+fn)
f1 = 2*(precision*recall)/(precision+recall)
return (accuracy, precision, recall, f1)
from metrics import cm_to_metrics
def bcm_results(confusion_results):
'''
confusion_results: 학습&평가할 때 미리 저장해주어야 함.
예)
'''
scores = {
'accuracy': [],
'precision': [],
'recall': [],
'f1': []
}
for bcm in confusion_results:
bcm.plot()
plt.show()
cm = bcm.compute().cpu().numpy()
accuracy, precision, recall, f1 = cm_to_metrics(cm)
scores['accuracy'].append(accuracy)
scores['precision'].append(precision)
scores['recall'].append(recall)
scores['f1'].append(f1)
return scores"""Visualization with confusion matrix"""
from metrics import bcm_results, cm_to_metrics
scores = bcm_results(confusion_results)
scores_df = pd.DataFrame(scores)
pd.concat([scores_df, scores_df.apply(['mean', 'std'])])