Reference
- https://herbwood.tistory.com/2
- https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173
먼저, Object Detection이란?

- 비교
1) Image classification: 이미지 내 존재하는 단일 객체에 대한 클래스를 예측하는 문제
2) Image Localization: 이미지 내 존재하는 단일 객체의 위치를 Bounding Box라고 불리는 사각형을 통해 예측하는 문제
3) Object Detection: 1)+2) = 이미지 내 존재하는 다수의 객체에 대한 위치를 예측하고, 그 동시에 해당 객체가 어떤 클래스를 가지는 지를 예측하는 문제이다.- 모델은 Bounding box의 좌표값과, Confidence score를 반환한다.

- 위 그림의 confidence score = 0.8은 모델이 생성한 bounding box 내의 객체가 오리너구리일 확률이 80%라고 확신하는 것
- 모델은 Bounding box의 좌표값과, Confidence score를 반환한다.
Metrics for Object Detection
1) Confusion Matrix 간단 정리
- Binary Classification를 기준으로 생각해보면, Confusion matrix는 총 네 가지 항목으로 구성됨.
- True Positive (TP): 실제값이 Positive이고, 모델이 예측한 값도 Positive인 경우
- False Positive (FP): 실제값은 Negative이고, 모델이 예측한 값은 Positive인 경우
- False Negative (FN): 실제값은 Positive이고, 모델이 예측한 값은 Negative인 경우,
- True Negative (TN): 실제값이 Negative이고, 모델이 예측한 값도 Negative인 경- Accuracy(정확도): 모든 결과 중, 올바르게 예측한 결과의 비율 (TP+TN/TP+TN+FP+FN)
- Precision(정밀도): Positive로 예측한 결과 중, 올바르게 예측한 결과의 비율 (TP/TP+FP)
- 예) 스팸 메일이 아닌(negative) 중요한 메일을 스팸 메일(positive)로 잘못 분류하면 안 되는 경우
- precision과 recall은 trade-off 관계임- Recall(재현율): 실제로 positive인 것들 중에 모델이 positive로 예측한 결과의 비율 (TP/TP+FN)
- 실제로 positive인 샘플을 놓치지 않는게 중요한 경우, 예: 암 진단, 코로나 진단- F1-score: 정밀도와 재현율의 조화 평균
- 불균형한 데이터셋에서 모델의 성능을 평가할 때 효과적인 지표
2) IoU(Intersection over Union)
-
객체 위치의 정확도를 평가하는 지표

-
Predicted와 ground truth 두 box가 겹쳐지는 영역이 넓을 수록 모델이 객체의 위치를 잘 추정했다는 의미이다. 0과 1사이의 값을 가지며 0.5 이상이면 비교적 올바르게 예측했다고 간주한다.
- threshold 예시: 0.5를 기준으로 true positive와 false positive를 가를 수 있음.
3) AP(Average Precision)
| Rank | Correct? | Precision | Recall |
|---|---|---|---|
| 1 | True | 1.0 | 0.2 |
| 2 | True | 1.0 | 0.4 |
| 3 | False | 0.67 | 0.4 |
| 4 | False | 0.5 | 0.4 |
| 5 | False | 0.4 | 0.4 |
| 6 | True | 0.5 | 0.6 |
| 7 | True | 0.57 | 0.8 |
| 8 | False | 0.5 | 0.8 |
| 9 | False | 0.44 | 0.8 |
| 10 | True | 0.5 | 1.0 |
- 간단한 예시를 들어보자. (ref: medium post, written by Jonathan Hui)
- 전체 데이터셋에 딱 5개의 사과만 들어있다고 가정한다. 모든 이미지에서 사과가 들어있는지의 여부의 predicted confidence level에 따라서 순위를 매긴다.(descending order) (위 표 참고)
- 2nd column은 기준의 prediction 결과이다. - 먼저, Precision과 Recall의 계산 과정부터 확인한다.
- 예) Rank #3
- Precision = TP/TP+FP = 2/3 = 0.67
- 전체 Positive인 샘플 중 내가 올바르게 Positive로 예측한 비율
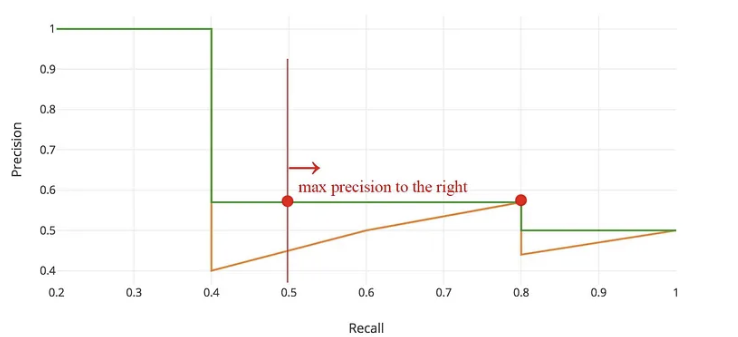
- Recall = TP/TP+FN = 2/5 =0.4 - 표를 다시 확인해보면, Recall은 prediction ranking이 내려감에 따라 증가하고 있다. (TP 개수가 늘어나니까) 반면에 Precision은 지그재그 패턴을 보이면서 증감하고 있다. (TP가 나오면 증가하고 FP가 나오면 감소하고)

- AP(Average Precision)의 일반적 정의는 위 precision-recall curve아래 영역을 의미한다. precision과 recall은 항상 0과 1사이의 값을 가지기 때문에, AP 또한 0과 1사이 값을 가진다.
- 보통, detection에서 AP를 계산하는 경우에는 이 지그재그 패턴을 먼저 smooth하게 만드는 것부터 시작한다. 매 recall 레벨 마다 precision 값을 그 다음 recall 레벨의 maximum precision 값으로 대체한다. (recall = 1부터 왼쪽으로 그려보면 간단하게 이해할 수 있다.)그럼 오렌지색 커브에서 초록색 montonical한 커브(단조함수)로 대체할 수 있다.

- 🤔왜 smoothing 하는 걸까?
- 저자에 의하면 "The calculated AP value will be less susceptible to small variations in the ranking."
- 즉, 지표가 랭킹의 작은 변동에 영향을 덜 받는다는 것을 나타낸다. 다시 말해, 모델의 예측이 조금 바뀌더라도 AP는 상대적으로 안정적으로 유지된다는 것을 의미한다. - 이는 수학적으로 다음과 같이 표현할 수 있다. (replace the precision value for recall with the maximum precision for any recall )
4) Interpolated AP
-
dataset마다 조금씩 다른 AP 계산을 사용하는 경우가 있다. PASCAL VOC2008의 경우, 11-point interpolated AP의 평균이 사용되었다.

-
먼저, recall 값을 0부터 1까지 총 11 points로 나눈다. (0.1 단위) 그리고 이 11개의 recall 값에 대해 평균 maximum precision value를 구한다.
- PASCAl VOC2008 예시에서는 AP=(5x1.0 + 4x0.57+2x0.5)/11 로 계산할 수 있다.
-
만약, 이 매우 작게 나오면 그 다음의 들은 0이 될 것으로 짐작해볼 수 있다. 따라서 maximum precision levels이 무시할 수 있는 수준으로 작게 나오면 그 recall level에서 더 이상 계산을 멈출 수 있다. (어차피 거의 0일테니 더 이상 더하시 않아도 된다는 뜻)
-
PASCAL VOC에 있는 20개의 클래스 각각에 대해 AP를 구하고, 그 AP들에 대한 평균값 또한 도출할 수 있다.
-
하지만, 위와 같은 방식(interpolated AP method)는 덜 정확하고, 매우 작은 AP에 대한 계산 능력을 잃어버린다는 단점이 있다. 따라서 2008년 이후에는 다른 방식의 AP 계산법이 사용된다.
AP - AUC(Area under cuve)
- PASCAL VOC2010-2012에서는 recall 레벨을 11개로만 나누는 것이 아니라, maximum precision value가 감소하는 모든 unique한 recall 레벨에 대해서 precision을 계산한 curve를 사용한다.


- ImageNet도 AUC 방법을 사용한다.
COCO mAP
- COCO 데이터셋에는 101개의 interpolated AP를 이용한고, AP는 multiple IoU (the minimum IOU to consider a positive match)의 평균값이다. 따라서 COCO에서는 AP와 mAP는 차이가 없다.
- AP@[.5:.95]: the average AP for IoU from 0.5 to 0.95 with a step size of 0.05
- AP@.75: AP with IoU=0.75
- COCO 데이터셋에서 사용하는 여러 metrics은 다음과 같다.

mAP in other contexts
- multi-class 분류 모델에서는 각 클래스의 AP를 각각 계산하거나, 각각 계산한 AP의 평균값을 mAP라고도 한다.
- mean Average Precision:
- 강의 시간에는 아래와 같은 그래프로 표현했다.

